【python爬虫】python+selenium实现Google Play Store应用信息爬虫+apk下载
实验要求:利用python+selenium实现Google Play Store应用信息爬虫+apk下载。
其中:
1、热门应用列表包含200个app,需要点击右侧按钮滑动产生下一页数据,所以需要Selenium来控制页面操作。
2、每个应用的爬虫信息包括:app名、详情页链接、应用评分、评论数、下载量。
实验使用的各个工具版本
selenium 4.1.1
chrome浏览器版本 125.0.6422.113 (查看方式:浏览器右上角——设置——关于chrome)
chromedriver 125.0.xx
因为selenium4.x版本与selenium3.x版本的api略有不同,版本与api调用不匹配会造成警告或报错,建议选用4.x版本的。
selenium安装与使用
Selenium是一个功能强大的自动化测试工具,主要用于Web应用程序的测试和网页爬虫,比如用于爬取网页上的数据,抓取网页内容、分析页面结构、提取信息等。
Selenium使用教程: selenium入门超详细教程——网页自动化操作
在pycharm终端执行:
# 安装4.1.1版本
pip3 install selenium==4.1.1
安装chromedriver
安装chromedriver需要注意浏览器版本对应问题。
如果自己的chrome浏览器版本很新,上面的教程里没有对应的网站,可以去这个网站里找下载链接——Chrome for Testing availability
在这里选择合适版本的chromedriver,打开对应网址即可下载。
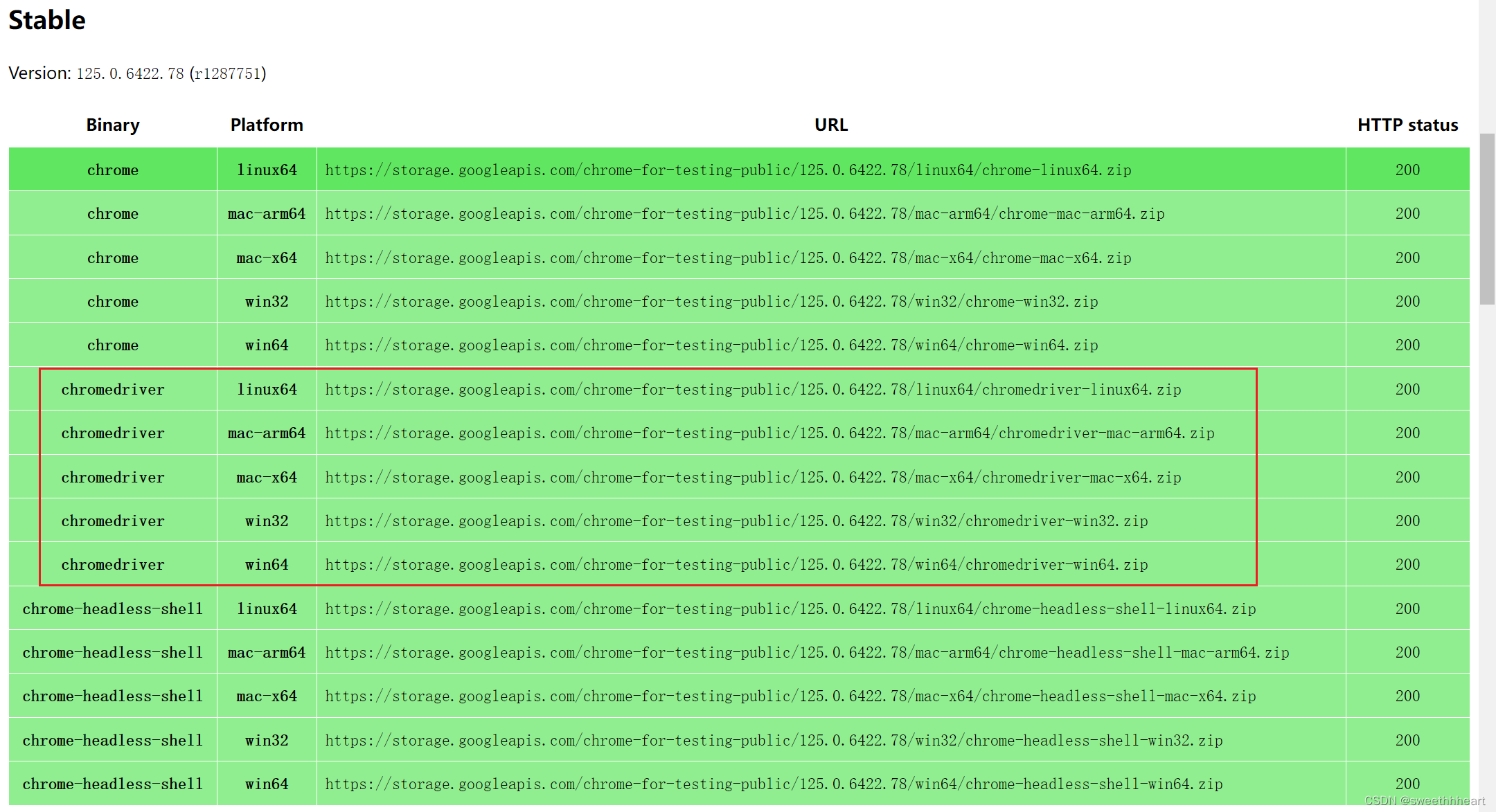
注:如果下载了对应版本的chromedriver,运行driver.get()时还是有网页闪退问题,需要检查selenium版本是否安装了较高的版本,我实验时最开始安装的4.21.x会有闪退的情况,后面卸载了重装了一个4.1.1版本的selenium,解决了闪退问题。
//卸载selenium
pip uninstall selenium
//下载4.1.1版本
pip3 install selenium==4.1.1
google play store热门应用列表爬虫
使用chromedriver打开网页
【注意这里是selenium4.x版本的写法 如果你的selenium是3.x版本可能代码略有不同】
代码中需要先指定chromedriver的存放位置。然后在初始化webdriver时传入参数service=s。
如果爬虫过程中需要最大化窗口(小窗口遮挡了某些元素时,比如遮挡了Button不能点击,无法获取对应数据,需要改变初始窗口大小),需要在打开网站之前进行窗口大小设置。
# 指定chromedriver存储地址
chromedriver_path = r"D:\ChromeDriver\chromedriver.exe"
# 初始化 ChromeDriver 服务
s = Service(chromedriver_path)
# 初始化 WebDriver
driver = webdriver.Chrome(service=s)
# 必须最大化窗口 不然不能点击按钮滑动界面
driver.maximize_window() #最大化窗口
# 指定要爬虫的网站地址
target_web_site = 'https://play.google.com/store/apps'
# 指定要爬虫的网站地址
target_web_site = 'https://play.google.com/store/apps'# 打开页面
page = driver.get(target_web_site)
控制网页滑动到指定位置
因为我需要的数据在页面下方,所以打开网页后还需要下滑一些距离,这样方便调试时观察。
# 设置滚动一定的像素距离
pixels_to_scroll = 300
driver.execute_script(f"window.scrollTo(0, {pixels_to_scroll});")
time.sleep(2)
注意爬虫时要尽量等待页面加载完成,以免数据没有渲染出来。
使用css选择器定位元素
在爬虫获取数据时,通常需要定位到信息所在的标签,然后通过标签的某个属性拿到信息的具体值。这个过程可以通过下面几种方式完成,但都需要driver.find_elements方法实现。
1、XPath
通过在页面上定位需要的标签值,然后右键——copy——选择copy xpath

2、CSS selector
同理,通过在页面上定位需要的标签值,然后右键——copy——选择copy selector
3、标签名
适用于标签名很特殊的情况,比如很多嵌套div的结构中出现了a标签,就可以直接指定a标签找到对应元素。
copy到对应筛选方式的值之后,在代码中执行:
(我这里复制的是css selector)
# 寻找目标标签的位置 复制选择器
swipeRight_selector = '#yDmH0d > c-wiz.SSPGKf.glB9Ve > div > div > div.N4FjMb.Z97G4e > c-wiz > div > c-wiz > c-wiz:nth-child(3) > c-wiz > section > div > div > div > div > div > div.hWUu9.n1lOjd.CrjwJd.Z3h6Kb.adMLdd > button'
isButtonActive = len(driver.find_elements(by=By.CSS_SELECTOR, value=swipeRight_selector))
控制鼠标悬浮在某个位置
由于我要获取的数据要不断的点击右侧的翻页按钮,且这个按钮在鼠标悬浮之前是隐藏的。
所以我需要在每次翻页之前,把鼠标悬停在这个列表所在的div容器内。

方法与上面定位的一样,然后使用ActionChains的move_to_element实现即可。
# 定位到想要悬停的元素
element_to_hover = driver.find_element(By.CSS_SELECTOR, '#yDmH0d > c-wiz.SSPGKf.glB9Ve > div > div > div.N4FjMb.Z97G4e > c-wiz > div > c-wiz > c-wiz:nth-child(3) > c-wiz > section > div > div > div > div > div')
# 创建 ActionChains 对象
actions = ActionChains(driver)
# 调用 move_to_element 方法来模拟鼠标移动到元素上
actions.move_to_element(element_to_hover).perform()
模拟点击滑动按钮
由于这个排行榜是有限的,需要不断点击右侧按钮获取下一页数据,才能拿到完整的信息,否则信息是不全的,所以在获取数据之前还要控制页面滑动到最后一页。
# 寻找目标标签的位置 复制选择器
swipeRight_selector = '#yDmH0d > c-wiz.SSPGKf.glB9Ve > div > div > div.N4FjMb.Z97G4e > c-wiz > div > c-wiz > c-wiz:nth-child(3) > c-wiz > section > div > div > div > div > div > div.hWUu9.n1lOjd.CrjwJd.Z3h6Kb.adMLdd > button'
isButtonActive = len(driver.find_elements(by=By.CSS_SELECTOR, value=swipeRight_selector))
count = 1
print("len:",isButtonActive)
while isButtonActive>0:actions.move_to_element(element_to_hover).perform()swipeRight_button = driver.find_element(by=By.CSS_SELECTOR, value=swipeRight_selector)swipeRight_button.click()print(f'这是第{count}页...')count += 1time.sleep(1)isButtonActive = len(driver.find_elements(by=By.CSS_SELECTOR, value=swipeRight_selector))
print(f'收集完成 共{count}页数据')
定位热门应用的数据
同上,定位热门应用的列表位置,注意这里用driver.find_elements,加了s,返回值是一个列表。
# 找热门应用
base_css_selector = 'section > div > div > div > div > div > div.aoJE7e.b0ZfVe > div.ULeU3b.neq64b'# 使用列表推导式和 f-string 来构建多个选择器,并找到对应的元素elements = driver.find_elements(by=By.CSS_SELECTOR, value=base_css_selector)# selenium 3.x的写法# elements = driver.find_elements_by_css_selector(base_css_selector)print(f"target_div_len:{len(elements)}")
google play store热门应用列表信息处理
找到对应元素之后,处理元素属性值即可获取信息。
google play store对应apk下载
方法:在APKCombo上根据对应包名(前面爬虫获取的)找到对应的网址进行下载
参考:利用python selenium动态爬取Google play store apks