【datawhale 组队学习】task01 第一章LLM介绍
目录
- chatgpt
- LLaMA
- deepseek
- Qwen
- ChatGLM
- LLM能力和特点
- 涌现能力(emergent abilities)
- 基座模型(foundation model)支持多元应用
- 支持对话作为统一入口的能力
- RAG
- **RAG工作流程**
- LangChain
- LangChain的核心组件
- 六个核心部件
- 大模型开发的一般流程
- exp
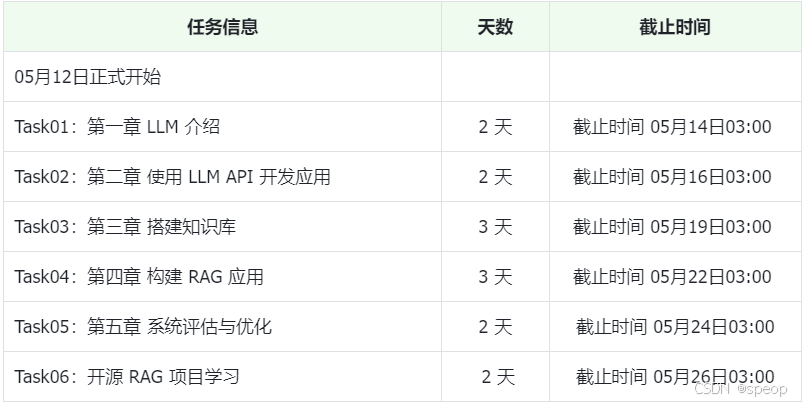
时间安排如下
国外的知名 LLM 有 GPT、LLaMA、Gemini、Claude 和 Grok 等
国内的有 DeepSeek、通义千问、豆包、Kimi、文心一言、GLM 等。
涌现能力:尽管这些大型语言模型与小型语言模型(例如 3.3 亿参数的 BERT 和 15 亿参数的 GPT-2)使用相似的架构和预训练任务,但它们展现出截然不同的能力,尤其在解决复杂任务时表现出了惊人的潜力,这被称为“涌现能力”
GPT-3 可以通过学习上下文来解决少样本任务,而 GPT-2 在这方面表现较差。
语言建模的研究:
- 20世纪90年代统计学习方法
- 2003强大神经网络模型,深度学习的思想融入到语言模型中
- 2018transformer架构的神经网络模型 通过大量文本数据训练这些模型,使它们能够通过阅读大量文本来深入理解语言规则和模式,就像让计算机阅读整个互联网一样,对语言有了更深刻的理解,极大地提升了模型在各种自然语言处理任务上的表现。
大模型由三个阶段构成:
- 预训练(Scaling Law
- 后训练(Scaling Law
- 在线推理(Scaling Law
随着各阶段计算量的增加,大模型的性能不断增长。
chatgpt
chatgpt
解码器(decoder)是模型中负责生成输出(比如文本)的部分
GPT 模型(生成式预训练语言模型)的基本原则是通过语言建模将世界知识压缩到仅解码器 (decoder-only) 的 Transformer 模型中,这样它就可以恢复(或记忆)世界知识的语义,并充当通用任务求解器。
它能够成功的两个关键点:
- 训练能够准确预测下一个单词的 decoder-only 的 Transformer 语言模型
- 扩展语言模型的大小
GPT 系列已形成 知识型 与 推理型 两大技术分支。

多模态能力:能够分析和理解用户提供的图片、音频和视频,实现全面的多模态交互
自定义指令与记忆功能:记住用户之前的交互习惯和偏好,提供个性化体验
GPT 构建器平台:允许用户无需编程创建专用的 AI 助手,支持自定义知识库和行为模式
数据分析与可视化:直接处理和分析上传的数据文件,生成图表和可视化报告
知识型与推理型双模式:可在 GPT-4.5 (知识型) 和 o1/o3 (推理型) 之间切换,满足不同场景需求
思维链展示:在推理型模型中可选择性展示思考过程,帮助用户理解推理步骤


claude

gemini

LLaMA
LLaMA
LLaMA开源地址
LLaMA 模型也采用了 decoder-only 架构,同时结合了一些前人工作的改进。LLaMA 系列基本上是后续大模型的标杆:
LLaMA 模型使用了大规模的数据过滤和清洗技术,以提高数据质量和多样性,减少噪声和偏见。LLaMA 模型还使用了高效的数据并行和流水线并行技术,以加速模型的训练和扩展其中 405B 参数模型是首个公开的千亿级开源模型,性能对标 GPT-4o 等商业闭源模型。
- Pre-normalization 正则化:为了提高训练稳定性,LLaMA 对每个 Transformer 子层的输入进行了 RMSNorm 归一化,这种归一化方法可以避免梯度爆炸和消失的问题,提高模型的收敛速度和性能;
- SwiGLU 激活函数:将 ReLU 非线性替换为 SwiGLU 激活函数,增加网络的表达能力和非线性,同时减少参数量和计算量;
- 旋转位置编码(RoPE,Rotary Position Embedding):模型的输入不再使用位置编码,而是在网络的每一层添加了位置编码,RoPE 位置编码可以有效地捕捉输入序列中的相对位置信息,并且具有更好的泛化能力。
- 分组查询注意力(GQA,Grouped-Query Attention):通过将查询(query)分组并在组内共享键(key)和值(value),减少了计算量,同时保持了模型性能,提高了大型模型的推理效率。
deepseek
deepseek 目前采用的主要改进如下:
- 多头潜在注意力 (MLA,Multi-head Latent Attention) :通过将键值 (KV) 缓存显著压缩为潜在向量来保证高效推理的同时不降低效果。
- DeepSeekMoE,通过稀疏计算以经济的成本训练强大的模型。
- 一系列推理加速技术
Qwen
Qwen 系列均采用 decoder-Only 架构,并结合 SwiGLU 激活、RoPE、GQA 等技术。中文能力相对来说非常不错的开源模型。
目前,已经开源了 7 种模型大小:0.6B, 1.7B, 4B, 8B, 14B, 32B 的 Dense 模型和 30B-A3B, 235B-A22B 的 MoE 模型;
8B 以下模型的上下文长度为 32k,8B 以上模型的上下文长度为 128k。
Qwen3 进一步增强了模型性能,改进了推理能力和指令遵循能力,同时保持了低资源部署的高效性,使其在长文本理解和复杂任务处理方面具有更强的优势。支持思考模式和非思考模式之间无缝切换。覆盖 119 种语言和方言。强化了模型的代码能力,Agent 能力,以及对 MCP 的支持。
同时还开源了代码模型和数学模型:
Qwen2.5-Coder: 1.5B, 7B, 以及即将推出的 32B;
Qwen2.5-Math: 1.5B, 7B, 以及 72B。
ChatGLM
GLM 系列模型是 清华大学和智谱 AI 等 合作研发的语言大模型.
GLM-4-9B-Chat 支持多轮对话的同时,还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等功能。

LLM能力和特点
涌现能力(emergent abilities)
涌现能力是一种令人惊讶的能力,它在小型模型中不明显,但在大型模型中特别突出。类似物理学中的相变现象,涌现能力就像是模型性能随着规模增大而迅速提升,超过了随机水平,也就是我们常说的 量变引起质变。
涌现能力可以与某些复杂任务有关,但我们更关注的是其通用能力。接下来,我们简要介绍三个 LLM 典型的涌现能力:
-
上下文学习 允许语言模型在提供自然语言指令或多个任务示例的情况下,通过理解上下文并生成相应输出的方式来执行任务,而无需额外的训练或参数更新。
-
指令遵循 通过使用自然语言描述的多任务数据进行微调,也就是所谓的 指令微调。LLM 被证明在使用指令形式化描述的未见过的任务上表现良好。这意味着 LLM 能够根据任务指令执行任务,而无需事先见过具体示例,展示了其强大的泛化能力。
-
逐步推理 小型语言模型通常难以解决涉及多个推理步骤的复杂任务,例如数学问题。然而,LLM 通过采用 思维链(CoT, Chain of Thought) 推理策略,利用包含中间推理步骤的提示机制来解决这些任务,从而得出最终答案。据推测,这种能力可能是通过对代码的训练获得的。
基座模型(foundation model)支持多元应用
借助于海量无标注数据的训练,获得可以适用于大量下游任务的大模型(单模态或者多模态)。这样,多个应用可以只依赖于一个或少数几个大模型进行统一建设。
大语言模型是这个新模式的典型例子,使用统一的大模型可以极大地提高研发效率。相比于每次开发单个模型的方式,这是一项本质上的进步。
支持对话作为统一入口的能力
在自然语言处理领域,它可以帮助计算机更好地理解和生成文本,包括写文章、回答问题、翻译语言等。
在信息检索领域,它可以改进搜索引擎,让我们更轻松地找到所需的信息。
在计算机视觉领域,研究人员还在努力让计算机理解图像和文字,以改善多媒体交互。
通用人工智能(AGI):AGI 是一种像人类一样思考和学习的人工智能。LLM 被认为是 AGI 的一种早期形式
RAG
RAG 的主要方法是检索外部数据,并在生成步骤中传递给 LLM。这样,LLM 就可以使用外部数据来增强生成的结果,从而提高应用程序的性能和准确性。
新的模型架构:检索增强生成(RAG, Retrieval-Augmented Generation)
整合了从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精准的答案,从而显著提升了回答的准确性与深度。
RAG解决了LLM的哪些问题
- 信息偏差/幻觉:LLM 有时会产生与客观事实不符的信息。RAG 通过检索数据源,辅助模型生成过程,确保输出内容的精确性和可信度,减少信息偏差。
- 知识更新滞后性:LLM 基于静态的数据集训练。RAG 通过实时检索最新数据,保持内容的时效性,确保信息的持续更新和准确性。
- 内容不可追溯:LLM 生成的内容往往缺乏明确的信息来源.RAG 将生成内容与检索到的原始资料建立链接,增强了内容的可追溯性,从而提升了用户对生成内容的信任度。
- 领域专业知识能力欠缺:LLM 在处理特定领域的专业知识时,效果可能不太理想。RAG 通过检索特定领域的相关文档,为模型提供丰富的上下文信息,从而提升了在专业领域内的问题回答质量和深度。
- 推理能力限制: 面对复杂问题时,LLM 可能缺乏必要的推理能力,这影响了其对问题的理解和回答。RAG 结合检索到的信息和模型的生成能力,通过提供额外的背景知识和数据支持,增强了模型的推理和理解能力。
- 应用场景适应性受限: LLM 需在多样化的应用场景中保持高效和准确,但单一模型可能难以全面适应所有场景。RAG 使得 LLM 能够通过检索对应应用场景数据的方式,灵活适应问答系统、推荐系统等多种应用场景。
- 长文本处理能力较弱: LLM 在理解和生成长篇内容时受限于有限的上下文窗口,且必须按顺序处理内容,输入越长,速度越慢。RAG 通过检索和整合长文本信息,强化了模型对长上下文的理解和生成,有效突破了输入长度的限制,同时降低了调用成本,并提升了整体的处理效率。
RAG工作流程
RAG 是一个完整的系统。工作流程:数据处理、检索、增强和生成
- 数据处理
- 对原始数据进行清洗和处理。
- 将处理后的数据转化为检索模型可以使用的格式。
- 将处理后的数据存储在对应的数据库中。
- 检索 将用户的问题输入到检索系统中,从数据库中检索相关信息。
- 增强 对检索到的信息进行处理和增强,以便生成模型可以更好地理解和使用
- 生成 将增强后的信息输入到生成模型中,生成模型根据这些信息生成答案。
RAG vs Finetune(微调)
微调: 通过在特定数据集上进一步训练大语言模型,来提升模型在特定任务上的表现。
| 特征比较 | RAG | 微调 |
|---|---|---|
| 知识更新 | 直接更新检索知识库,无需重新训练。信息更新成本低,适合动态变化的数据。 | 通常需要重新训练来保持知识和数据的更新。更新成本高,适合静态数据。 |
| 外部知识 | 擅长利用外部资源,特别适合处理文档或其他结构化/非结构化数据库。 | 将外部知识学习到 LLM 内部。 |
| 数据处理 | 对数据的处理和操作要求极低。 | 依赖于构建高质量的数据集,有限的数据集可能无法显著提高性能。 |
| 模型定制 | 侧重于信息检索和融合外部知识,但可能无法充分定制模型行为或写作风格。 | 可以根据特定风格或术语调整 LLM 行为、写作风格或特定领域知识。 |
| 可解释性 | 可以追溯到具体的数据来源,有较好的可解释性和可追踪性。 | 黑盒子,可解释性相对较低。 |
| 计算资源 | 需要额外的资源来支持检索机制和数据库的维护。 | 依赖高质量的训练数据集和微调目标,对计算资源的要求较高。 |
| 推理延迟 | 增加了检索步骤的耗时 | 单纯 LLM 生成的耗时 |
| 降低幻觉 | 通过检索到的真实信息生成回答,降低了产生幻觉的概率。 | 模型学习特定领域的数据有助于减少幻觉,但面对未见过的输入时仍可能出现幻觉。 |
| 伦理隐私 | 检索和使用外部数据可能引发伦理和隐私方面的问题。 | 训练数据中的敏感信息需要妥善处理,以防泄露。 |
Datawhale 知识库助手
天机-人情世故
LangChain
尽管大型语言模型的调用相对简单,但要创建完整的应用程序,仍然需要大量的定制开发工作,包括 API 集成、互动逻辑、数据存储等等。
LangChain 框架是一个开源工具**,充分利用了大型语言模型的强大能力,以便开发各种下游应用。它的目标是为各种大型语言模型应用提供通用接口,从而简化应用程序的开发流程。**可以实现数据感知和环境互动,也就是说,它能够让语言模型与其他数据来源连接,并且允许语言模型与其所处的环境进行互动。
langchain的一个数据流图
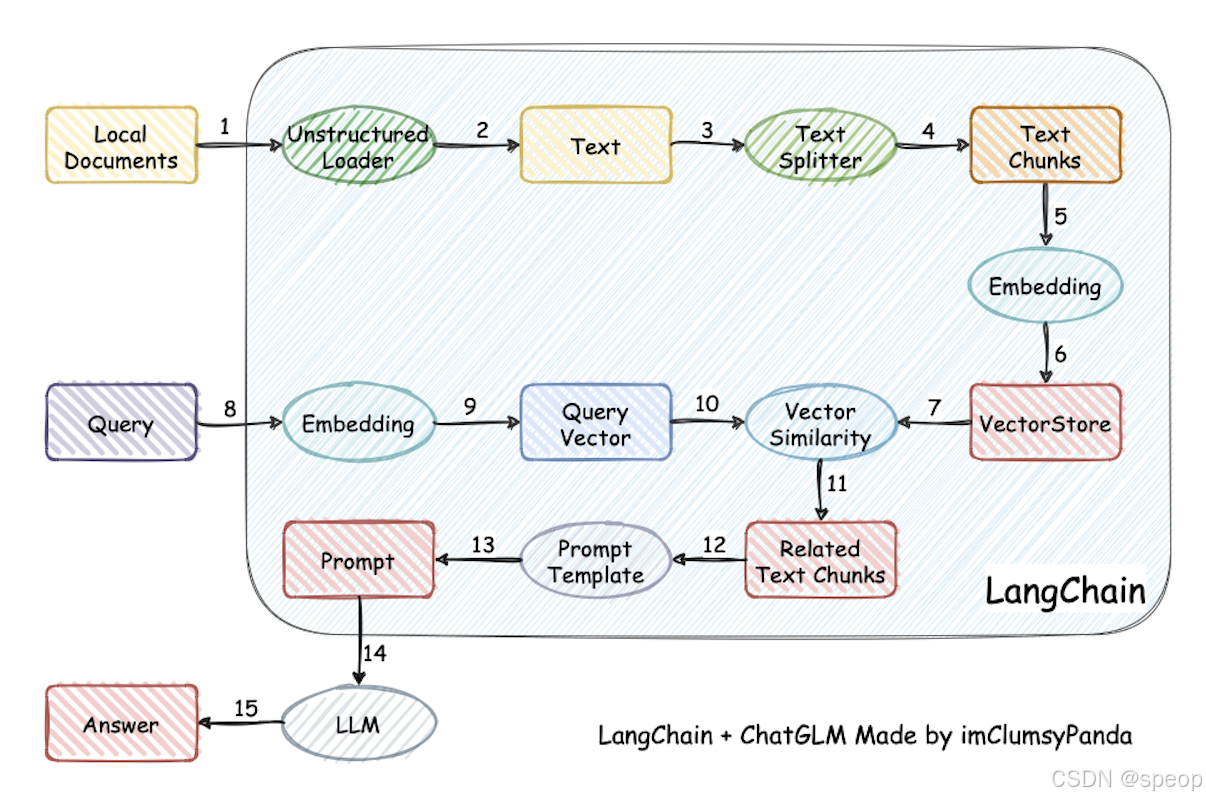
LangChain的核心组件
langchain可以将 LLM 模型(对话模型、embedding 模型等)、向量数据库、交互层 Prompt、外部知识、外部代理工具整合到一起,进而可以自由构建 LLM 应用。
LangChain为两种类型的模型提供接口和集成:
- LLM:将文本字符串作为输入并返回文本字符串的模型。LangChain 不提供自己的 LLM,而是提供了一个标准接口,用于与许多不同的LLM进行交互。
- ChatModel:由语言模型支持将聊天消息列表作为输入并返回聊天消息的模型。虽然聊天模型在底层使用语言模型,但它们暴露的接口有点不同:它们没有暴露“文本输入,文本输出”的 API,而是将聊天消息(ChatMessage)列表作为输入和输出。
[参考资料][1]
六个核心部件
- 模型输入/输出(Model I/O):与语言模型交互的接口
- 数据连接(Data connection):与特定应用程序的数据进行交互的接口
- 链(Chains):将组件组合实现端到端应用。比如后续我们会将搭建检索问答链来完成检索问答。
- 记忆(Memory):用于链的多次运行之间持久化应用程序状态;Memory 组件用于在链之间存储和传递信息,从而实现对话的上下文感知能力。
- 代理(Agents):扩展模型的推理能力。用于复杂的应用的调用序列;使用 LLM 作为大脑自动思考,自动决策选择执行不同的动作,最终完成我们的目标任务。
- 回调(Callbacks):扩展模型的推理能力。用于复杂的应用的调用序列;允许您连接到 LLM 申请的各个阶段。这对于日志记录、监控、流传输和其他任务(添加标签、计算 Token 等)非常有用。
可组合性:借助 LangChain 表达式语言(LCEL),开发者可以轻松地构建和定制 chain,充分利用数据编排框架的优势,包括批量处理、并行化操作和备选方案等高级功能。
输出:LangChain 提供了一系列强大的输出解析工具,确保 LLM 能够以结构化的格式返回信息
检索:LangChain 引入了先进的检索技术,适用于生产环境,包括文本分割、检索机制和索引管道等,使得开发者能够轻松地将私有数据与 LLM 的能力相结合。
大模型开发的一般流程
- 确定目标 应用场景、目标人群、核心价值。
- 设计功能 对于个体开发者或小型开发团队来说,首先要确定应用的核心功能,然后延展设计核心功能的上下游功能;
- 搭建整体架构 绝大部分大模型应用采用特定数据库 + Prompt + 通用大模型的架构。推荐基于 LangChain 框架进行开发。LangChain 提供了 Chain、Tool 等架构的实现,我们可以基于 LangChain 进行个性化定制,实现从用户输入到数据库再到大模型最后输出的整体架构连接。
- 搭建数据库 大模型应用需要进行向量语义检索。需要收集数据并进行预处理,再向量化存储到数据库中。数据预处理一般包括从多种格式向纯文本的转化,例如 PDF、MarkDown、HTML、音视频等。以及对错误数据、异常数据、脏数据进行清洗。完成预处理后,需要进行切片、向量化构建出个性化数据库。
- Prompt Engineering 需要逐步迭代构建优质的 Prompt Engineering 来提升应用性能。首先应该明确 Prompt 设计的一般原则及技巧,构建出一个来源于实际业务的小型验证集,基于小型验证集设计满足基本要求、具备基本能力的 Prompt。
- 验证迭代 通过不断发现 Bad Case 并针对性改进 Prompt Engineering 来提升系统效果、应对边界情况。 探讨边界情况,找到 Bad Case,并针对性分析 Prompt 存在的问题,从而不断迭代优化,直到达到一个较为稳定、可以基本实现目标的 Prompt 版本。
- 搭建前后端 用 Gradio 和 Streamlit,可以帮助个体开发者迅速搭建可视化页面实现 Demo 上线。
- 体验优化
exp

- 项目目标
- 核心功能
- 确定技术结构和工具
- 数据准备与向量知识库构建
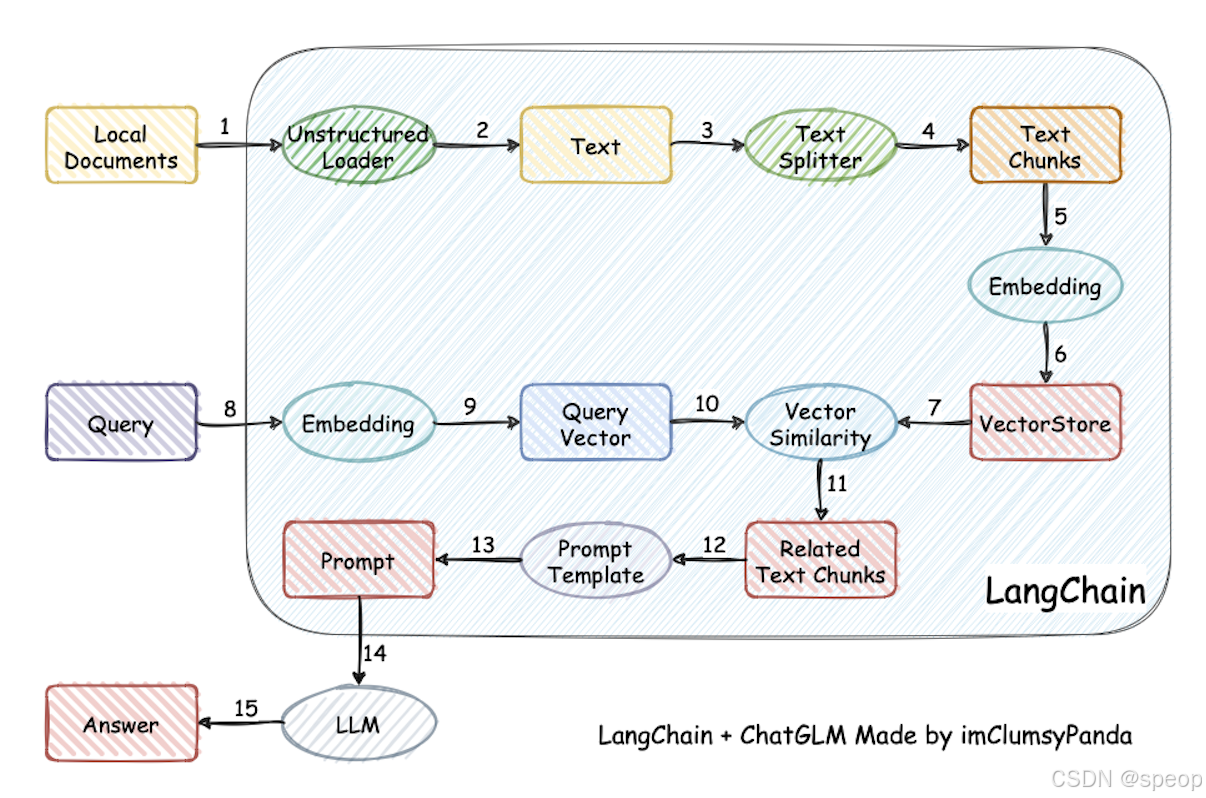
加载本地文档 -> 读取文本 -> 文本分割 -> 文本向量化 -> question 向量化 -> 在文本向量中匹配出与问句向量最相似的 top k 个 -> 匹配出的文本作为上下文和问题一起添加到 Prompt 中 -> 提交给 LLM 生成回答。
- 收集和整理用户提供的文档
- 将文档词向量化 使用文本嵌入(Embeddings)技术 对分割后的文档进行向量化,使语义相似的文本片段具有接近的向量表示。然后,存入向量数据库,完成 索引(index) 的创建。(用户每一次提问也会经过 Embedding,利用向量相关性算法(例如余弦算法)找到最匹配的几个知识库片段,将这些知识库片段作为上下文,与用户问题一起作为 Prompt 提交给 LLM 回答。)
- 将向量化后的文档导入 Chroma 知识库,建立知识库索引
- 大模型集成与 API 连接 集成 GPT、星火、文心、GLM 等大模型,配置 API 连接。编写代码,实现与大模型 API 的交互,以便获取问题回答。
- 核心功能实现
- 构建 Prompt Engineering,实现大模型回答功能,根据用户提问和知识库内容生成回答。
- 实现流式回复,允许用户进行多轮对话。
- 添加历史对话记录功能,保存用户与助手的交互历史。
- 核心功能迭代优化
- 进行验证评估,收集 Bad Case。
- 根据 Bad Case 迭代优化核心功能实现。
- 前端与用户交互界面开发
- 使用 Gradio 和 Streamlit 搭建前端界面。
- 实现用户上传文档、创建知识库的功能。
- 设计用户界面,包括问题输入、知识库选择、历史记录展示等。
[1]:https://cloud.tencent.com/developer/article /2324297