小白的LLM学习记录(一)
主要技术依次:
预训练基础模型——基座
微调SFT——
检索增强生成RAG——
prompt提示词——顶端策略
为什么微调和RAG?
通用大模型在训练时不会包括所有数据集,因而在特定领域与隐私项目中不能很好的解决问题,微调和RAG即在通用大模型的基础上,对模型的精细化准确回答进行优化保证。
什么是RAG?
RAG——Retrieval-Augmented Generation
检索+增强+生成——即LLM+Search system
用户提出问题后先进入一个数据库的检索环节,再生成prompt提示词,进入LLM,然后由LLM生成回答,具体的流程如下图:
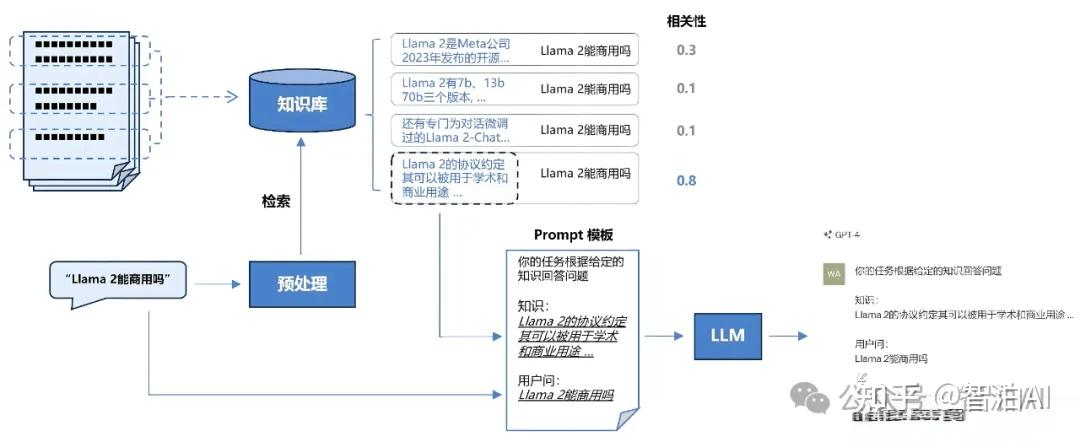
主要涉及的技术内容不包括大模型LLM本身结构的修改,而是直接在前面构架一个检索框架。这个检索框架的知识库一般是文件或者文档资料,构建为向量数据库存储,索引构建是重要环节。主要的技术步骤包括:
文件加载load;
文本切片『简单文本通过换行符,空格等,复杂文本则基于NLP工具(这里还不知道是什么)/基于BERT中的NSP训练任务,设置相似度阈值,按顺序判断是否需要截断(也不知道是什么)』
Embedding编码(这里需要一个算法将输入转为向量,而且在整个RAG中这种转化规则必须保持一致,即用户问题的转换和对数据文件的转换编码策略要一致);
存入向量数据库。
但是RAG会存在问题:
1.检索片段不全面引起的回答偏差;——如何优化?重排序/分布式部署
2.延时问题:如何提速
什么是微调SFT?
应用的场景一般是问答式模型部署,例如心理咨询和法律顾问
用的是数据标签归类,对模型LLM结构调整
选择微调的模型一般8B左右,中等项目70B已经非常可以。