Pytorch学习笔记(二十二)Audio - Audio I/O
这篇博客瞄准的是pytorch官方教程中的的音频部分,主要介绍如何使用 TorchAudio 的基本 I/O API 检查音频数据、将其加载到 PyTorch Tensors 中并保存 PyTorch Tensors。
原先的网站进入后会自动跳转到下面的链接:
- 官网链接:https://docs.pytorch.org/audio/stable/tutorials/audio_io_tutorial.html
完整网盘链接: https://pan.baidu.com/s/1L9PVZ-KRDGVER-AJnXOvlQ?pwd=aa2m 提取码: aa2m
Import package
import torch
import torchaudioprint(torch.__version__)
print(torchaudio.__version__)
【Note】:这里可能会遇到 import torchaudio 失败的情况,出现如下包错,通常是因为torch和torchaudio版本对不上导致的,查看下面的链接找到正确的版本然后重新pip安装即可:
- 版本对照:https://docs.pytorch.org/audio/main/installation.html#compatibility-matrix
OSError: /root/miniconda3/envs/torch/lib/python3.10/site-packages/torchaudio/lib/libtorchaudio.so: undefined symbol: _ZNK3c105Error4whatEv
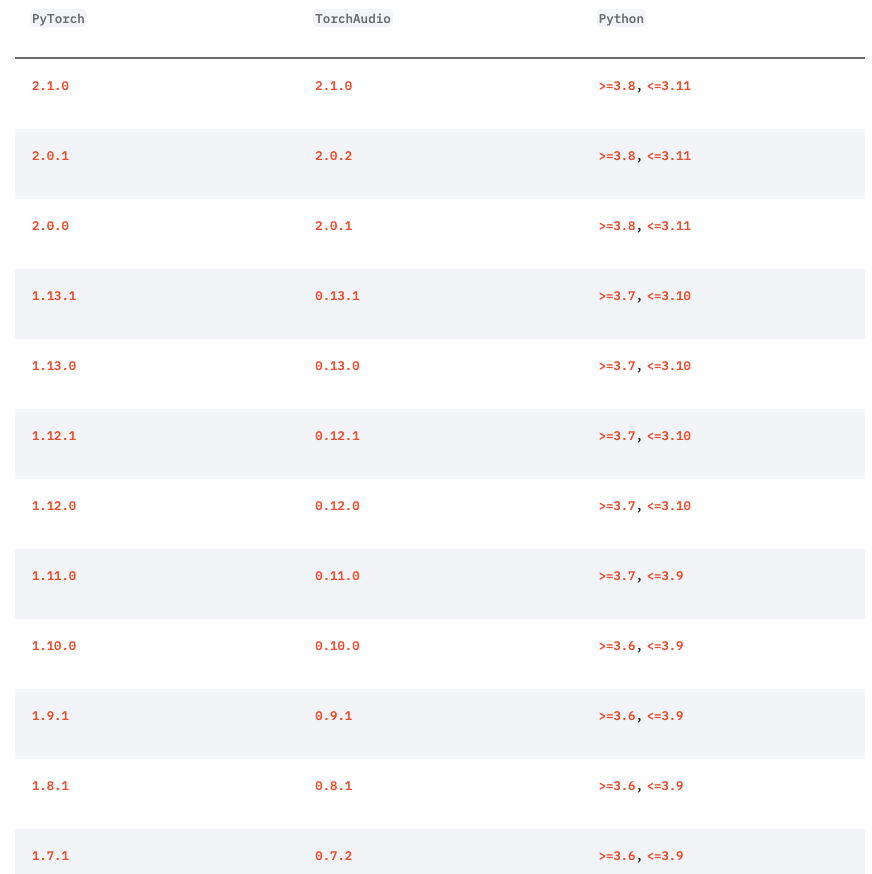
我这里使用的是 torch==2.0.0和torchaudio==2.0.1
(torch) $ pip install torchaudio==2.0.1
导入其他剩余的包:
import io,os,tarfile,tempfileimport boto3
import matplotlib.pyplot as plt
import requests
from botocore import UNSIGNED
from botocore.config import Config
from IPython.display import Audio
from torchaudio.utils import download_asset
Preparation
安装第三方依赖库:
(torch) $ pip install boto3
下载数据
SAMPLE_GSM = download_asset("tutorial-assets/steam-train-whistle-daniel_simon.gsm")
SAMPLE_WAV = download_asset("tutorial-assets/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav")
SAMPLE_WAV_8000 = download_asset("tutorial-assets/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042-8000hz.wav")
定义wrapper:
def _hide_seek(obj):class _wrapper:def __init__(self, obj):self.obj = objdef read(self, n):return self.obj.read(n)return _wrapper(obj)
Querying audio metadata
使用 torchaudio.info() 对象传入一个文件路径可以将其转换成torch对象,然后就可以直接用print函数将其对象信息打印出来。
metadata = torchaudio.info(SAMPLE_WAV)
print(metadata)metadata = torchaudio.info(SAMPLE_GSM)
print(metadata)
Querying file-like object
url = "https://download.pytorch.org/torchaudio/tutorial-assets/steam-train-whistle-daniel_simon.wav"
with requests.get(url, stream=True) as response:metadata = torchaudio.info(_hide_seek(response.raw))
print(metadata)
【Note】:传递类文件的对象时,info 不会读取所有数据,而是仅从头读取部分数据。对于给定的音频格式,可能无法检索正确的元数据(包括格式本身)。但可以传递 format 参数来指定音频的格式。
Loading audio data
url = "https://download.pytorch.org/torchaudio/tutorial-assets/steam-train-whistle-daniel_simon.wav"
with requests.get(url, stream=True) as response:metadata = torchaudio.info(_hide_seek(response.raw))
print(metadata)
加载音频文件
waveform, sample_rate = torchaudio.load(SAMPLE_WAV)
绘制音频波形
def plot_waveform(waveform, sample_rate):waveform = waveform.numpy()num_channels, num_frames = waveform.shapetime_axis = torch.arange(0, num_frames) / sample_ratefigure, axes = plt.subplots(num_channels, 1)if num_channels == 1:axes = [axes]for c in range(num_channels):axes[c].plot(time_axis, waveform[c], linewidth=1)axes[c].grid(True)if num_channels > 1:axes[c].set_ylabel(f"Channel {c+1}")figure.suptitle("waveform")plot_waveform(waveform, sample_rate)
绘制频域图
def plot_specgram(waveform, sample_rate, title="Spectrogram"):waveform = waveform.numpy()num_channels, num_frames = waveform.shapefigure, axes = plt.subplots(num_channels, 1)if num_channels == 1:axes = [axes]for c in range(num_channels):axes[c].specgram(waveform[c], Fs=sample_rate)if num_channels > 1:axes[c].set_ylabel(f"Channel {c+1}")figure.suptitle(title)plot_specgram(waveform, sample_rate)
播放音频
Audio(waveform.numpy()[0], rate=sample_rate)
Loading from file-like object
I/O 函数支持类文件对象,允许从本地文件系统内外的位置获取和解码音频数据。
下载音频文件
url = "https://download.pytorch.org/torchaudio/tutorial-assets/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav"
with requests.get(url, stream=True) as response:waveform, sample_rate = torchaudio.load(_hide_seek(response.raw))
plot_specgram(waveform, sample_rate, title="HTTP datasource")
加载音频文件
tar_path = download_asset("tutorial-assets/VOiCES_devkit.tar.gz")
tar_item = "VOiCES_devkit/source-16k/train/sp0307/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav"
with tarfile.open(tar_path, mode="r") as tarfile_:fileobj = tarfile_.extractfile(tar_item)waveform, sample_rate = torchaudio.load(fileobj)
plot_specgram(waveform, sample_rate, title="TAR file")
从S3中下载音频文件
bucket = "pytorch-tutorial-assets"
key = "VOiCES_devkit/source-16k/train/sp0307/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav"
client = boto3.client("s3", config=Config(signature_version=UNSIGNED))
response = client.get_object(Bucket=bucket, Key=key)
waveform, sample_rate = torchaudio.load(_hide_seek(response["Body"]))
plot_specgram(waveform, sample_rate, title="From S3")
Tips on slicing
作者在这一小节中提供了两个使用tips
num_frames和frame_offset参数会将解码限制在输入的相应片段上;- 使用 vanilla Tensor 切片(即
wave[:,frame_offset:frame_offset+num_frames])可以实现相同的结果。但是,提供 num_frames 和 frame_offset 参数效率更高;
frame_offset, num_frames = 16000, 16000 url = "https://download.pytorch.org/torchaudio/tutorial-assets/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav"
print("Fetching all the data...")
with requests.get(url, stream=True) as response:waveform1, sample_rate1 = torchaudio.load(_hide_seek(response.raw))waveform1 = waveform1[:, frame_offset : frame_offset + num_frames]print(f" - Fetched {response.raw.tell()} bytes")print("Fetching until the requested frames are available...")
with requests.get(url, stream=True) as response:waveform2, sample_rate2 = torchaudio.load(_hide_seek(response.raw), frame_offset=frame_offset, num_frames=num_frames)print(f" - Fetched {response.raw.tell()} bytes")print("Checking the resulting waveform ... ", end="")
assert (waveform1 == waveform2).all()
print("matched!")
Saving audio to file
将音频数据保存为常见应用程序可解释的格式 torchaudio.save()。此函数接受路径类对象或文件类对象。
传递文件类对象时,还需要提供参数 format 以明确保存格式;对于路径类对象,函数将根据扩展名推断格式;如果要保存到没有扩展名的文件,则需要提供参数 format。
waveform, sample_rate = torchaudio.load(SAMPLE_WAV)def inspect_file(path):print("-" * 10)print("Source:", path)print("-" * 10)print(f" - File size: {os.path.getsize(path)} bytes")print(f" - {torchaudio.info(path)}")print()
保存 WAV 格式数据时,float32 Tensor 的默认编码为 32 位浮点 PCM。参数 encoding 和 bit_per_sample 来更改此行为。例如,要将数据保存为 16 位有符号整数 PCM:
不使用任何编码选项保存。该函数将选择适合所提供数据的编码:
with tempfile.TemporaryDirectory() as tempdir:path = f"{tempdir}/save_example_default.wav"torchaudio.save(path, waveform, sample_rate)inspect_file(path)
保存为 16 位有符号整数线性 PCM 生成的文件占用一半的存储空间,但会损失精度:
with tempfile.TemporaryDirectory() as tempdir:path = f"{tempdir}/save_example_PCM_S16.wav"torchaudio.save(path, waveform, sample_rate, encoding="PCM_S", bits_per_sample=16)inspect_file(path)
使用其他格式保存:
formats = ["flac",# "vorbis",# "sph",# "amb",# "amr-nb",# "gsm",
]waveform, sample_rate = torchaudio.load(SAMPLE_WAV_8000)
with tempfile.TemporaryDirectory() as tempdir:for format in formats:path = f"{tempdir}/save_example.{format}"torchaudio.save(path, waveform, sample_rate, format=format)inspect_file(path)
Saving to file-like object
与其他 I/O 函数类似,可以将音频保存到类文件对象。保存到类文件对象时,需要指定参数 format。
waveform, sample_rate = torchaudio.load(SAMPLE_WAV)buffer_ = io.BytesIO()
torchaudio.save(buffer_, waveform, sample_rate, format="wav")buffer_.seek(0)
print(buffer_.read(16))