计网实验笔记(一)CS144 Lab
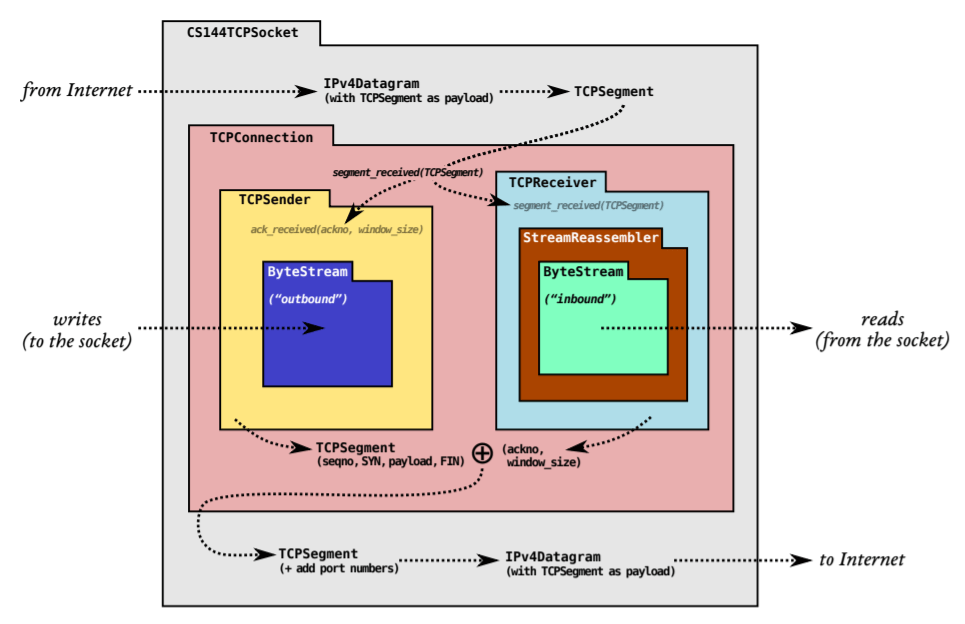
- Lab0
ByteStream: 实现一个在内存中的 有序可靠字节流 - Lab1
StreamReassembler:实现一个流重组器,一个将字节流的字串或者小段按照正确顺序来拼接回连续字节流的模块 - Lab2
TCPReceiver:实现入站字节流的TCP部分。 - Lab3
TCPSender:实现出站字节流的TCP部分。
checkpoint 1-3 首先实现一个简易但保留了核心语义且 (almost fully) standards-compliant 的 TCP Protocol,可以与其他 (工业级的) TCP 实现相互通信。
lab0
实现一个流重组器,一个将字节流的字串或者小段按照正确顺序来拼接回连续字节流的模块
该实验引导我们以模块化的方式构建一个 TCP 实现。
流重组器在 TCP 起到了相当重要的作用。迫于网络环境的限制,TCP 发送者会将数据切割成一个个小段的数据分批发送。但这就可能带来一些新的问题:数据在网络中传输时可能丢失、重排、多次重传等等。而TCP接收者就必须通过流重组器,将接收到的这些重排重传等等的数据包重新组装成新的连续字节流。
丢失
重复
顺序不对
“可靠字节流”的含义(在这个实验中):
- 保序 (Order Preserving): 字节按照写入的顺序被读取。
- 可靠 (Reliable): 写入的字节最终都能被读取出来,不会丢失或损坏(因为是在内存中,不像网络传输)。
- 有界内存 (Bounded Memory) / 流量控制 (Flow Control): 这是这个实验的一个关键点。ByteStream 对象有一个容量 (capacity) 限制,代表它在任何时刻最多能在内部存储多少字节(这些字节是已经被写入但尚未被读取的)。这防止了对象无限消耗内存。
- 有限流 (Finite Stream): 写入方可以发出一个“结束 (close)”信号,表示不会再有新的字节写入。读取方在读取完所有已写入的字节后,会到达“文件结束 (End Of File - EOF)”状态。
核心任务:
-
实现位置: 在提供的 src/byte_stream.hh 和 src/byte_stream.cc 文件中实现 ByteStream 类。
-
接口实现: 需要完整实现 ByteStream 类提供的公共接口 (public interface),包括:
-
写入方接口 (Writer Interface):
- push(std::string data): 尝试将 data 中的字节写入流中。关键: 只能写入不超过当前 available_capacity() 的字节数。
- close(): 标记流的输入结束,之后不能再 push。
- is_closed(): 返回流是否已被关闭。
- available_capacity(): 返回当前还能向流中写入多少字节(即 capacity 减去当前已缓冲但未读取的字节数)。
- bytes_pushed(): 返回从流创建开始累计写入的总字节数。
-
读取方接口 (Reader Interface):
- peek(): 查看(但不移除)当前缓冲区中可读的字节,返回一个 std::string_view。
- pop(uint64_t len): 从缓冲区中移除(消耗)len 个字节。
- is_finished(): 返回流是否已结束(即已被 close() 并且所有写入的字节都已被 pop())。
- has_error(): 返回流是否处于错误状态(在这个 Checkpoint 中可能不太会用到,但在后续网络部分会有关)。
- bytes_buffered(): 返回当前缓冲区中有多少字节(已写入但未 pop)。
- bytes_popped(): 返回从流创建开始累计读取(pop)的总字节数。
-
-
流量控制实现: 必须严格遵守 capacity 限制。push 操作不能写入超过 available_capacity() 的数据。当读取方 pop 数据后,available_capacity() 应该相应增加。
-
流的长度: 流的总长度可以远超其 capacity。只要写入方写入数据后,读取方及时 pop 数据,使得缓冲区的字节数不超过 capacity,就可以持续传输大量数据。
-
单线程假设: 不需要考虑多线程并发读写的问题。
-
测试: 使用 cmake --build build --target check0 命令来运行自动化测试。
-
性能要求: 通过测试后会进行速度基准测试。实现需要达到至少 0.1 Gbit/s(100 Mbps)的速度。
lab1
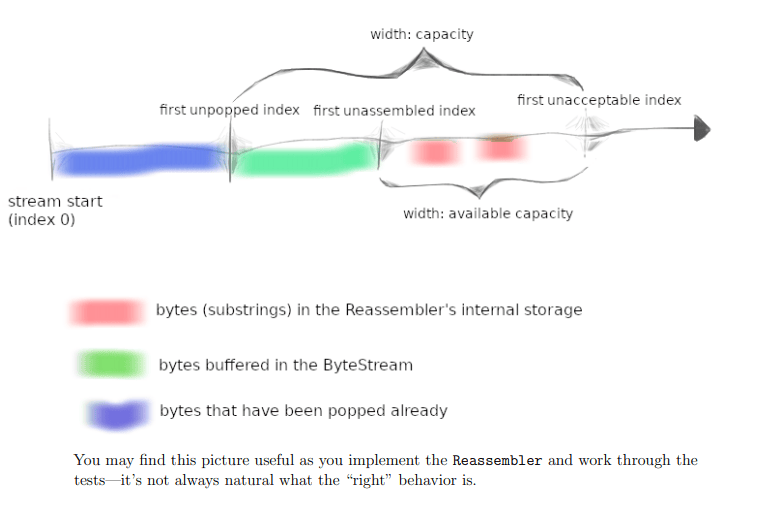
绿色的部分是我们实现的bytestream
红色是乱序的待写入的数据
核心任务:实现 Reassembler
- 输入: 接收带有起始索引 (first_index) 的数据子串 (data)。这些子串可能乱序、重复、有重叠地到达。
- 处理:
- 存储 (Buffering): 需要存储那些暂时无法写入输出流(因为前面的字节还没到)但又在容量范围内的数据子串。
- 重组 (Reassembly): 将收到的子串“拼接”起来。
- 去重 (Handling Duplicates/Overlap): 确保同一个字节只存储一次,即使收到了包含它的重叠子串。
- 按序输出 (Ordered Output): 一旦某个字节成为流中下一个连续的字节,就立即将其写入 ByteStream 的写入端。
- 输出: 一个可靠的、按序的字节流 (ByteStream),供上层应用读取。
- 限制: 内存使用受“容量 (capacity)”限制。
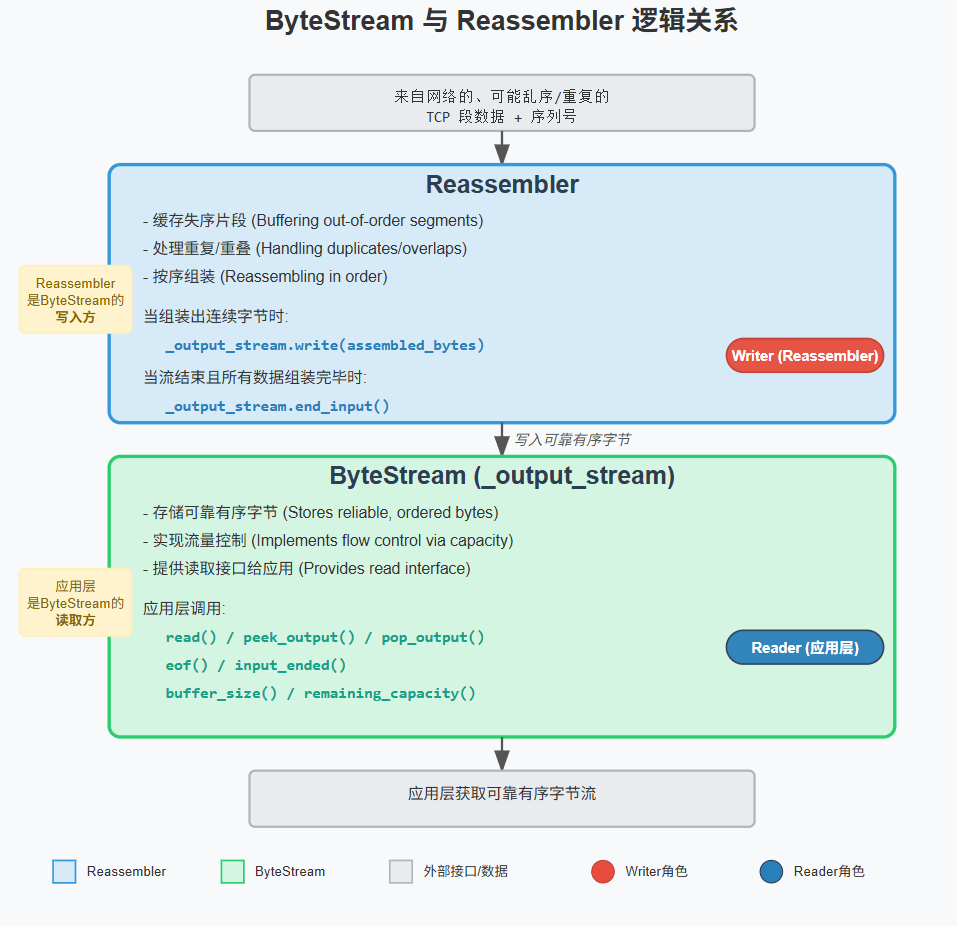
核心目标:
将收到的、可能乱序、重复、有间隙的数据子串 (substrings,每个都带有其在原始完整流中的起始字节索引 first_index),重新组装成一个连续、有序的字节流,并将其写入到底层的 ByteStream 中。同时,需要管理容量限制。
核心数据结构选择:
通常会选择一种能够高效存储和检索这些数据片段的数据结构。常见的选择包括:
-
std::map<uint64_t, std::string>或std::map<uint64_t, SubstringInfo>:key: 子串的first_index。value: 子串数据本身,或者一个包含子串数据、长度等信息的结构体。- 优点: 自动按
first_index排序,方便查找和合并相邻或重叠的片段。 - 缺点: 每次插入和查找的开销是 O(log N),其中 N 是已存储片段的数量。字符串的存储和拷贝也可能有开销。
-
std::set<SubstringInfo, Comparator>:SubstringInfo: 一个自定义结构体,包含first_index,data,length等,并重载比较运算符(或提供自定义比较器)以按first_index排序。- 优缺点: 类似
std::map。
-
std::vector<bool>或位图 (Bitmask) + 字符缓冲区 (Character Buffer): (更高级,可能更复杂)- 用一个大的
std::vector<bool>(或者位图) 标记哪些字节已经收到。 - 用一个字符数组或
std::vector<char>存储实际的字节数据。 - 优点: 对于密集的、小的片段,可能在空间和查找上更高效。
- 缺点: 管理起来更复杂,特别是处理稀疏的大空隙时。需要处理索引映射。
- 用一个大的
在本讨论中,我们假设使用类似 std::map<uint64_t, std::string> 的思路,因为它在逻辑上比较直观。
私有成员变量 (主要思路):
_unassembled_bytes: (例如std::map<uint64_t, std::string>) 用于存储那些已接收但尚未按序写入ByteStream的数据片段。键是片段的first_index,值是片段的std::string数据。_next_expected_index: (类型uint64_t) 当前期望写入ByteStream的下一个字节的索引。这是重组的关键指针。_output_stream: (类型ByteStream&或std::shared_ptr<ByteStream>) 对底层ByteStream的引用或指针,Reassembler会将组装好的数据写入这里。_capacity: (类型size_t)Reassembler能够缓冲(即_unassembled_bytes和_output_stream中未被读取的字节之和)的最大字节数。_eof_received_flag: (类型bool) 标记是否收到了带有is_last_substring标志的片段。_eof_index: (类型uint64_t) 如果收到了is_last_substring,记录该流的结束字节索引(即最后一个字节的索引 + 1)。_bytes_pending_count: (类型size_t) 记录当前在_unassembled_bytes中存储的字节总数,用于容量管理。
insert(uint64_t first_index, std::string data, bool is_last_substring) 实现思路和考虑情况:
最新的实验指导函数签名由旧版的void StreamReassembler::push_substring(const string &data, const uint64_t index, const bool eof)换成了insert但是区别不大
旧版实验备份仓库
- 初步过滤和容量检查:
- 完全超出容量: 如果
first_index已经远超_next_expected_index + _capacity,或者first_index + data.length()超过了这个范围,并且data的有效部分也无法放入,则可能需要丢弃整个或部分data。- 情况1:完全丢弃。 如果新片段的起始位置
first_index大于或等于_next_expected_index + _capacity(即完全在可接受窗口之外),则丢弃。 - 情况2:部分截断(头部)。 如果
first_index小于_next_expected_index(即部分数据是已经处理过的重复数据),则需要将data从_next_expected_index - first_index处开始截取,并更新first_index为_next_expected_index。 - 情况3:部分截断(尾部)。 如果
first_index + data.length()超过了_next_expected_index + _capacity,则需要将data截断,只保留在容量窗口内的部分。
- 情况1:完全丢弃。 如果新片段的起始位置
- 如果
data为空,在截断后可能无需进一步处理。
- 完全超出容量: 如果
截断后的新的data需要迭代和旧的区间进行合并。
-
处理
is_last_substring标志:- 如果
is_last_substring为true:- 设置
_eof_received_flag = true。 - 记录流的结束索引
_eof_index = first_index + data.length()。
- 设置
- 如果
-
合并/存储新片段到
_unassembled_bytes:
这是最复杂的部分,需要处理新片段与_unassembled_bytes中已存在片段的各种关系。-
迭代
_unassembled_bytes: 查找与新片段[first_index, first_index + data.length())可能发生重叠或相邻的已存片段。 -
情况4:完全重复/被覆盖。 如果新片段完全被一个已存在的片段覆盖,或者新片段与已存在的片段完全相同,则可以忽略新片段(或只更新
is_last_substring信息)。 -
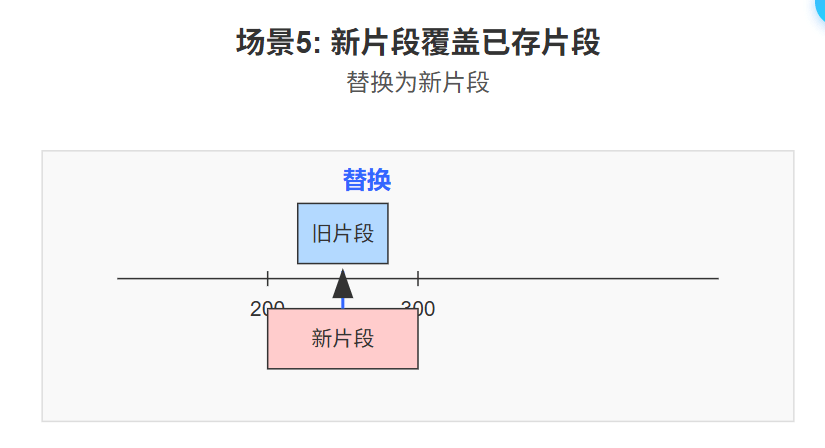
情况5:新片段覆盖已存片段。 如果新片段完全覆盖了一个或多个已存在的片段,则移除那些被覆盖的旧片段,并(可能在合并后)插入新片段。
-
情况6:部分重叠。
- 新片段与旧片段头部重叠:
new_start < old_start && new_end < old_end && new_end > old_start。可能需要将新片段的非重叠部分与旧片段合并,或者调整新片段的起始和数据。 - 新片段与旧片段尾部重叠:
new_start > old_start && new_start < old_end && new_end > old_end。类似处理。 - 旧片段包含新片段: (已在情况4处理)
- 新片段包含旧片段: (已在情况5处理)

- 新片段与旧片段头部重叠:
-
情况7:新片段与旧片段相邻可合并。
- 如果新片段的尾部
first_index + data.length()正好是某个已存片段的old_first_index。 - 如果某个已存片段的尾部
old_first_index + old_data.length()正好是新片段的first_index。 - 在这些情况下,可以将它们合并成一个更大的片段,并更新
_unassembled_bytes和_bytes_pending_count。 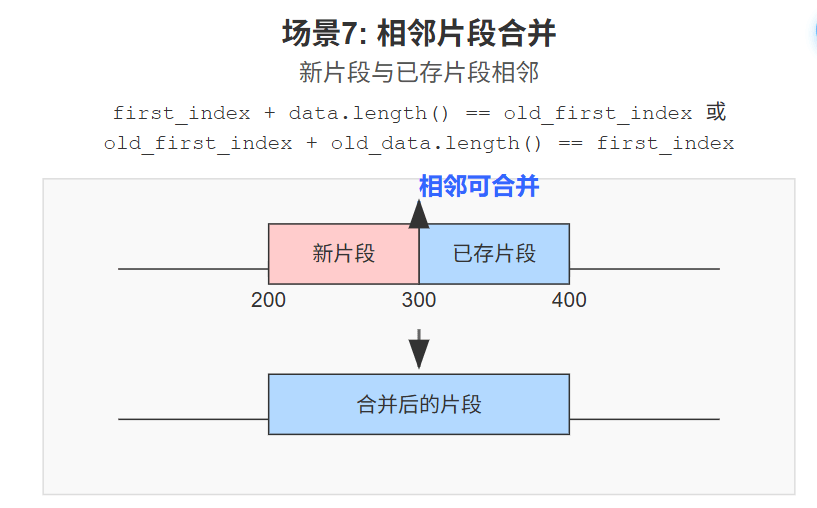
- 如果新片段的尾部
-
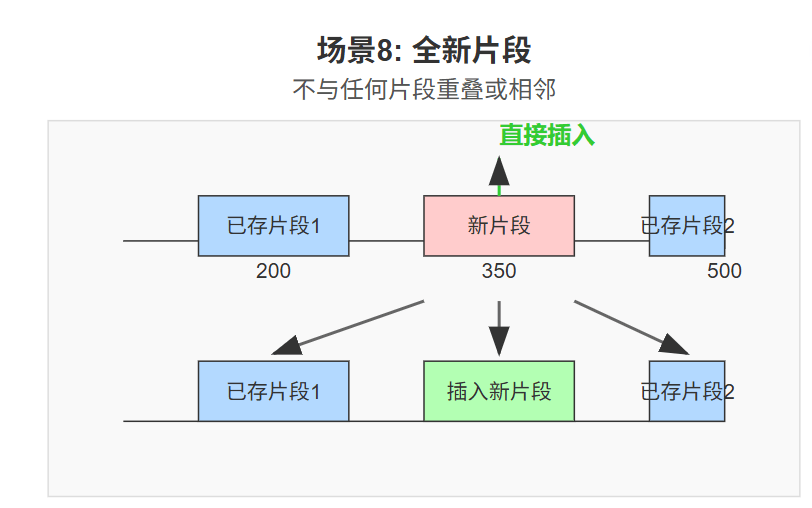
情况8:新片段是全新的,不与任何片段重叠或相邻。 直接将其插入
_unassembled_bytes,并更新_bytes_pending_count。 -
容量管理: 在插入或合并时,要确保
_bytes_pending_count加上_output_stream.buffer_size()不超过_capacity。如果超出,可能需要根据策略丢弃一些已缓存的、离_next_expected_index最远的片段。 (实验指导中提到==“Bytes that lie beyond the stream’s available capacity. These should be discarded.”==,这通常指新到来的片段,但如果内部缓冲已满,也需要有策略。)
-
-
尝试将数据写入
_output_stream:- 在每次成功
insert(或合并)后,检查_unassembled_bytes的头部(即_unassembled_bytes.begin(),如果使用std::map)。 - 情况9:可以写入数据。 如果
_unassembled_bytes中存在一个片段,其first_index正好等于_next_expected_index:- 将该片段的数据通过
_output_stream.write()写入。注意,write()可能不会接受所有数据(因为ByteStream也有容量限制)。 - 更新
_next_expected_index为已成功写入ByteStream的字节数加上之前的_next_expected_index。 - 从
_unassembled_bytes中移除已完全写入的部分(如果只写入了一部分,则更新该片段的first_index和data)。 - 更新
_bytes_pending_count。 - 循环此过程: 可能写入一个片段后,使得下一个片段也变得连续了,所以需要循环尝试写入,直到没有更多连续数据可写,或者
_output_stream写满了。
- 将该片段的数据通过
- 在每次成功
-
处理 EOF 条件:
- 情况10:可以结束输入。 如果
_eof_received_flag为true,并且_next_expected_index大于或等于_eof_index(意味着所有在 EOF 标记之前的数据都已成功组装并写入ByteStream),则调用_output_stream.end_input()。
- 情况10:可以结束输入。 如果

其他成员函数的实现思路:
reader(): 返回对_output_stream的只读引用。bytes_pending(): 返回_bytes_pending_count。 (实验指导中提到这个函数仅用于测试,不要为此添加额外状态。如果_bytes_pending_count是为了容量管理而自然维护的,那就可以直接返回。否则,可能需要遍历_unassembled_bytes来计算)。
关键考虑点和复杂性:
- 合并逻辑的正确性: 处理各种重叠和相邻情况是
Reassembler最复杂的部分,需要非常小心,避免 bug。 - 迭代器失效: 如果在遍历
_unassembled_bytes(如std::map) 的同时修改它(删除或插入元素),需要注意迭代器失效问题。通常的策略是先收集需要修改的信息,然后再进行实际的修改操作,或者使用 C++17 引入的std::map::merge或extract等更安全的操作(如果允许)。 - 容量管理: 确保在任何时候,==缓冲在
Reassembler内部(_unassembled_bytes)和已写入ByteStream但未被应用读取的总字节数不超过指定的capacity。==这个容量是Reassembler实例的_output.remaining_capacity()和它自己内部缓冲_bytes_pending_count的总和,但实验指导似乎将capacity视为ByteStream和Reassembler内部存储的上限,具体需要看reassembler.hh中capacity的确切定义。通常,Reassembler的容量是指它自己内部能缓冲多少未组装的字节,而它写入的ByteStream有自己的容量。 - 空字符串和边界条件: 处理
data为空字符串,或者first_index恰好在边界上的情况。
简化假设(根据实验指导):
- 实验指导中提到:“You may assume that they don’t exist. That is, you can assume that there is a unique underlying byte-stream, and all substrings are (accurate) slices of it.” 这意味着你不需要处理不一致的重叠 (inconsistent overlaps),即同一个索引位置不会收到内容不同的字节。这简化了合并逻辑。
#include "stream_reassembler.hh"#include <algorithm>
#include <map>using namespace std;StreamReassembler::StreamReassembler(const size_t capacity): _unassembled_bytes(0), _output(make_unique<ByteStream>(capacity)),_capacity(capacity),_next_expected_index(0),_eof_index(UINT64_MAX) {}//! \details This function accepts a substring (aka a segment) of bytes,
//! possibly out-of-order, from the logical stream, and assembles any newly
//! contiguous substrings and writes them into the output stream in order.
void StreamReassembler::push_substring(const string &data, const uint64_t index, const bool eof) {// 如果数据为空但标记了eof,则记录eof位置并检查是否可以结束流if (data.empty()) {if (eof) {_eof_index = index;if (_next_expected_index == _eof_index) {_output->end_input();}}return;}// 计算可接受窗口的边界uint64_t first_unacceptable = _next_expected_index + _capacity - _output->buffer_size();uint64_t first_index = index;uint64_t last_index = index + data.size() - 1;// 情况1: 完全丢弃 - 新片段完全在可接受窗口之外if (first_index >= first_unacceptable) {// 丢弃数据if (eof) {_eof_index = index + data.size();}return;}// 获取数据的有效部分string valid_data = data;uint64_t valid_first_index = first_index;// 情况2: 部分截断(头部) - 如果起始索引小于下一个期望索引if (first_index < _next_expected_index) {// 截断数据前半部分size_t offset = _next_expected_index - first_index;if (offset >= valid_data.size()) {// 数据完全被截断,忽略if (eof) {_eof_index = index + data.size();if (_next_expected_index >= _eof_index) {_output->end_input();}}return;}valid_data = valid_data.substr(offset);valid_first_index = _next_expected_index;}// 情况3: 部分截断(尾部) - 如果数据超出了可接受窗口if (valid_first_index + valid_data.size() > first_unacceptable) {// 截断数据后半部分size_t new_length = first_unacceptable - valid_first_index;valid_data = valid_data.substr(0, new_length);// 如果数据被截断,忽略EOF标志if (eof && index + data.size() <= first_unacceptable) {_eof_index = index + data.size();}} else if (eof) {_eof_index = index + data.size();}// 如果没有有效数据,直接返回if (valid_data.empty()) {return;}// 直接写入输出流(如果是下一个期望的片段)if (valid_first_index == _next_expected_index) {_output->write(valid_data);_next_expected_index += valid_data.size();// 检查未重组队列中是否有可以继续写入的数据while (!_unassembled.empty()) {auto it = _unassembled.begin();if (it->first == _next_expected_index) {_output->write(it->second);_unassembled_bytes -= it->second.size();_next_expected_index += it->second.size();_unassembled.erase(it);} else if (it->first < _next_expected_index) {// 情况4: 完全重复/被覆盖if (it->first + it->second.size() <= _next_expected_index) {_unassembled_bytes -= it->second.size();_unassembled.erase(it);} else {// 情况6: 部分重叠size_t offset = _next_expected_index - it->first;string remaining = it->second.substr(offset);_output->write(remaining);_unassembled_bytes -= it->second.size();_next_expected_index += remaining.size();_unassembled.erase(it);}} else {// 没有连续的数据可写break;}}// 检查是否到达了EOFif (_next_expected_index == _eof_index) {_output->end_input();}return;}// 处理不连续的片段,放入未重组队列// 检查是否和现有数据重叠auto it = _unassembled.lower_bound(valid_first_index);// 检查前一个元素是否有重叠if (it != _unassembled.begin()) {auto prev = prev(it);uint64_t prev_last = prev->first + prev->second.size() - 1;// 情况7: 相邻片段合并if (prev->first + prev->second.size() == valid_first_index) {// 相邻可合并prev->second.append(valid_data);_unassembled_bytes += valid_data.size();// 向后合并it = prev;++it;while (it != _unassembled.end() && prev->first + prev->second.size() >= it->first) {if (prev->first + prev->second.size() < it->first + it->second.size()) {// 情况6: 部分重叠size_t overlap = prev->first + prev->second.size() - it->first;prev->second.append(it->second.substr(overlap));}_unassembled_bytes -= it->second.size();it = _unassembled.erase(it);}return;}// 情况4: 完全重复/被覆盖else if (prev_last >= valid_first_index + valid_data.size() - 1) {// 新数据被完全覆盖,忽略return;}// 情况6: 部分重叠else if (prev_last >= valid_first_index) {// 合并重叠部分size_t overlap = prev_last - valid_first_index + 1;valid_data = valid_data.substr(overlap);valid_first_index = prev_last + 1;if (valid_data.empty()) {return;}}}// 情况5: 新片段覆盖已存片段或情况8: 全新片段// 向后检查重叠while (it != _unassembled.end() && valid_first_index + valid_data.size() > it->first) {// 完全覆盖现有片段if (valid_first_index <= it->first && valid_first_index + valid_data.size() >= it->first + it->second.size()) {// 情况5: 新片段覆盖已存片段_unassembled_bytes -= it->second.size();it = _unassembled.erase(it);}// 部分重叠(尾部)else if (valid_first_index <= it->first) {// 情况6: 部分重叠size_t overlap = valid_first_index + valid_data.size() - it->first;valid_data.append(it->second.substr(overlap));_unassembled_bytes -= it->second.size();it = _unassembled.erase(it);}// 部分重叠(头部)else {// 情况6: 部分重叠size_t overlap = it->first + it->second.size() - valid_first_index;if (overlap < valid_data.size()) {valid_data = it->second + valid_data.substr(overlap);} else {valid_data = it->second;}valid_first_index = it->first;_unassembled_bytes -= it->second.size();it = _unassembled.erase(it);}}// 情况8: 全新片段 - 插入未重组队列_unassembled[valid_first_index] = valid_data;_unassembled_bytes += valid_data.size();
}size_t StreamReassembler::unassembled_bytes() const {return _unassembled_bytes;
}bool StreamReassembler::empty() const {return _unassembled.empty();
}