【AI论文】健康的大型语言模型(LLMs)?——评估大型语言模型对英国政府公共健康信息的掌握程度
摘要:随着大型语言模型(LLMs)的广泛应用,为了在实际应用中取得成功,详细了解它们在特定领域的知识变得至关重要。这在公共卫生领域尤为重要,因为无法检索到相关、准确且最新的信息可能会对英国居民产生重大影响。然而,目前关于LLMs对英国政府公共健康信息了解程度的研究还很少。为了解决这一问题,本文引入了一个新的基准测试集——PubHealthBench,该基准测试集包含通过自动化流程生成的超过8000个问题,用于评估LLMs在公共卫生查询中的多项选择题回答(MCQA)和自由形式回答能力。我们还发布了一个新的数据集,其中包含提取的英国政府公共健康指导文档,这些文档作为PubHealthBench的源文本。在PubHealthBench上对24个LLMs进行评估后,我们发现最新的私有LLMs(GPT-4.5、GPT-4.1和o1)具有高度的知识掌握度,在MCQA设置中的准确率超过90%,并且超过了仅使用搜索引擎进行粗略搜索的人类表现。然而,在自由形式回答设置中,所有模型的性能均有所下降,没有模型的得分超过75%。因此,尽管有迹象表明,最先进(SOTA)的LLMs作为公共卫生信息的来源正变得越来越准确,但在提供公共卫生主题的自由形式回答时,可能仍然需要额外的保障措施或工具。Huggingface链接:Paper page,论文链接:2505.06046
研究背景和目的
研究背景
随着大型语言模型(LLMs)技术的飞速发展,其在各个领域的应用日益广泛,包括医疗健康、公共政策、教育等。在公共健康领域,LLMs因其强大的自然语言处理能力,被寄予厚望能够改善公共健康信息的获取、分析和传播方式。然而,目前关于LLMs对英国政府公共健康信息掌握程度的研究相对较少,尤其是针对最新、最全面的公共健康指导文档的系统性评估更是匮乏。
公共健康指导是英国居民和专家做出个人、专业和临床决策的重要信息来源。随着LLMs的广泛应用,如何准确评估其对公共健康指导的理解和掌握程度,成为了一个亟待解决的问题。此外,由于公共健康指导经常更新,且不同机构和地区发布的指导可能存在差异,这对LLMs系统准确掌握最新、最全面的公共健康信息构成了挑战。
研究目的
本研究旨在通过构建一个新的基准测试集(PubHealthBench),系统评估LLMs对英国政府公共健康信息的掌握程度。具体研究目的包括:
- 构建全面的基准测试集:收集并整理英国政府发布的公共健康指导文档,构建一个包含超过8000个问题的基准测试集,涵盖选择题(MCQA)和自由形式回答两种形式,以全面评估LLMs在公共健康领域的表现。
- 评估多种LLMs:在PubHealthBench上评估24种不同的LLMs,包括最新的私有模型和开源模型,以了解它们在公共健康信息掌握方面的差异和优劣。
- 分析模型性能:通过详细分析模型在不同类型问题(如按主题分类、按受众分类)上的表现,揭示LLMs在公共健康信息掌握方面的优势和不足。
- 提供实践指导:基于评估结果,为公共健康领域LLMs的应用提供实践指导,帮助决策者了解何时以及如何安全地使用LLMs来获取公共健康信息。
研究方法
数据收集与预处理
研究团队从英国政府网站(gov.uk)上收集了超过1000份公共健康指导文档,涵盖了HTML和PDF两种格式。通过预处理和分块技术,将这些文档转换为适合生成MCQA问题的文本块。PDF文档的处理尤为复杂,研究团队采用了两阶段管道方法,结合GPT-4o-mini vision LLM进行文本提取和格式转换。
问题生成
利用Llama-3.3-70bn-Instruct模型,研究团队为每个文本块生成了两个MCQA问题,每个问题包含一个正确答案选项和六个错误干扰选项。通过链式思考(Chain of Thought, CoT)提示和JSON格式输出,确保生成的问题格式统一且易于处理。
自动化错误检测与采样
为了确保基准测试集的质量,研究团队采用LLMs对生成的问题进行自动化错误检测。通过构建一个包含五类常见错误的分类体系,并利用Llama-3-70bn-Instruct模型进行初步筛选,将错误率从约16%降低至约8%。最终,研究团队保留了约8090个MCQA问题,构成了PubHealthBench基准测试集。
人工专家质量保证
为了进一步确保基准测试集的质量,研究团队邀请了人类专家对随机抽取的800个问题进行人工审核。通过两轮审核流程,评估了问题的有效性和答案选项的合理性,并据此对基准测试集进行了微调。
模型评估
研究团队在PubHealthBench上评估了24种不同的LLMs,包括GPT-4.5、o1、Gemini-2.0-Flash等最新私有模型,以及Phi-4、Command-R等开源模型。评估过程中采用了零样本提示(zero-shot prompting)方法,并模拟了真实世界中用户与聊天机器人交互的场景,禁止模型访问外部工具或信息库。对于自由形式回答部分,研究团队利用GPT-4o-Mini作为评判者(Judge LLM),根据原始文本和正确答案对模型的回答进行二分类评估。
研究结果
MCQA基准测试结果
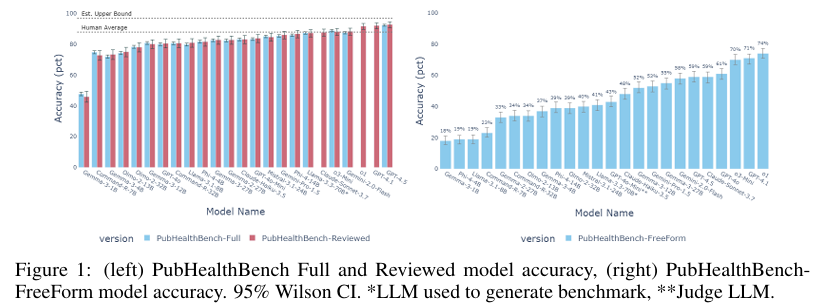
在MCQA基准测试中,最新的私有模型(如GPT-4.5、o1)表现出色,准确率均超过90%,甚至超过了人类基准线(88%)。这些模型在各个主题领域和受众群体上的表现均较为稳定,显示出对公共健康信息的全面掌握。相比之下,开源模型虽然也表现出一定的知识掌握程度,但整体准确率较低,多数模型准确率在75%-85%之间。
自由形式回答基准测试结果
在自由形式回答基准测试中,所有模型的性能均出现显著下降,最高准确率仅为74%(o1模型)。这表明,在没有选项提示的情况下,模型需要更强的回忆和推理能力来准确回答公共健康问题。此外,研究还发现,推理模型(如o1、o3-Mini)在自由形式回答中的表现相对较好,这可能与它们在处理复杂任务时的优势有关。
模型性能差异分析
通过进一步分析模型在不同类型问题上的表现,研究团队发现,模型在公共健康指导面向普通公众的部分表现最好,而在面向临床和专业人员的部分表现相对较差。这可能与公共健康指导面向不同受众群体的复杂性和专业性有关。此外,研究还发现,较小的开源模型在生成自由形式回答时更容易出现幻觉(hallucination),即生成与原始文本不一致的信息。
研究局限
尽管本研究在评估LLMs对英国政府公共健康信息掌握程度方面取得了显著进展,但仍存在以下局限性:
- 数据覆盖范围有限:本研究仅涵盖了英国政府发布的公共健康指导文档,且主要关注英语语言文档。这可能导致评估结果在其他国家或语言环境下的适用性受限。
- 问题类型单一:本研究主要采用了MCQA和自由形式回答两种问题类型进行评估,可能无法全面反映LLMs在公共健康领域的实际应用能力。未来研究可以考虑引入更多类型的问题(如多轮对话、图像问题等)以更全面地评估模型性能。
- 评判者模型局限性:本研究采用GPT-4o-Mini作为评判者模型对自由形式回答进行评估,尽管该模型在评估过程中表现出色,但仍可能存在一定的主观性和误差。未来研究可以考虑采用更客观、更全面的评估方法(如人工审核与自动评估相结合)来提高评估结果的准确性。
- 模型更新与维护:由于公共健康指导经常更新,LLMs需要定期重新训练以保持对最新信息的掌握。然而,本研究并未涉及模型更新与维护方面的内容,未来研究可以进一步探讨如何有效地更新和维护LLMs以适应不断变化的公共健康信息环境。
未来研究方向
基于本研究的发现和局限性,未来研究可以在以下几个方面展开:
- 拓展数据覆盖范围:收集更多国家或地区的公共健康指导文档,并考虑多语言环境下的评估,以提高评估结果的普适性和国际比较性。
- 引入更多问题类型:设计更多类型的问题(如多轮对话、图像问题、情境模拟等)以更全面地评估LLMs在公共健康领域的实际应用能力。
- 优化评判者模型:探索更客观、更全面的评估方法(如结合人工审核与自动评估)以提高自由形式回答评估的准确性。同时,可以考虑开发专门的评判者模型以适应不同类型问题的评估需求。
- 研究模型更新与维护机制:探讨如何有效地更新和维护LLMs以适应不断变化的公共健康信息环境。这可能涉及定期重新训练模型、引入增量学习技术或开发自适应学习机制等方面的研究。
- 关注模型偏见与伦理问题:深入研究LLMs在公共健康领域应用中可能存在的偏见和伦理问题(如信息准确性、隐私保护、责任归属等),并提出相应的解决方案和应对策略。
综上所述,本研究通过构建PubHealthBench基准测试集,系统评估了LLMs对英国政府公共健康信息的掌握程度,并揭示了模型在公共健康领域的优势和不足。未来研究可以在拓展数据覆盖范围、引入更多问题类型、优化评判者模型、研究模型更新与维护机制以及关注模型偏见与伦理问题等方面展开,以推动LLMs在公共健康领域的进一步发展和应用。