基于MNIST数据集的手写数字识别(简单全连接网络)
目录
一,模型训练
1.1 数据集介绍
1.2 简单神经网络结构介绍
1.3 定义神经网络的层结构
1.4 神经网络的前向传播过程
1.5 数据预处理
1.6 加载数据
1.7 模型初始化
1.8 模型训练过程
1.9 保存训练好的模型参数
二,代码解析
2.1 定义模型
2.2 加载模型
2.3 预处理
2.4 预测
2.5 显示结果
三,测试
3.1 测试方法
3.2 测试结果
四,总结
五,完整代码
5.1 模型训练部分代码
5.2 模型测试部分代码
一,模型训练
1.1 数据集介绍
MNIST 数据集由 60,000 张图像构成的训练集和 10,000 张图像组成的测试集构成,其中的图像均为 28×28 像素的灰度图,涵盖 0 - 9 这 10 个阿拉伯数字,且数字书写风格、大小、位置多样。它源于美国国家标准与技术研究所(NIST)的数据集,经过归一化和中心化处理。MNIST 数据集是图像识别研究领域的经典数据集,常用于开发和评估图像识别算法与模型,也是机器学习课程中常用的教学案例,许多高性能卷积神经网络模型在该数据集测试集上准确率可达 99% 以上,充分展现出其在机器学习领域的重要价值和广泛应用。
1.2 简单神经网络结构介绍
简单神经网络由输入层、隐藏层和输出层构成,输入层接收原始数据,如 MNIST 数据集中图像数据;隐藏层对数据进行加工处理,通过神经元加权求和与激活函数提取特征;输出层根据任务输出结果,分类任务中神经元数量对应类别数。其工作原理包含前向传播和反向传播,前者传递数据得出结果,后者依据误差调整权重偏置以优化模型。
在本文中,没有使用到卷积神经网络,文中网络的数据流为:
图像像素→fc1→ReLU→fc2→分类结果。
这种结构是处理 MNIST 数据集的经典模型,通过两层全连接网络完成手写数字识别任务。
1.3 定义神经网络的层结构
self.fc1 = nn.Linear(28 * 28, 128) # 全连接层1:输入784(28x28像素),输出128
self.fc2 = nn.Linear(128, 10) # 全连接层2:输入128,输出10(对应0-9数字分类)
self.relu = nn.ReLU() # ReLU激活函数,引入非线性- 输入层:接收 28×28 像素的图像(展平为 784 维向量)
- 隐藏层:128 个神经元,使用 ReLU 激活函数引入非线性
- 输出层:10 个神经元,对应 0-9 的数字分类
1.4 神经网络的前向传播过程
x = x.view(-1, 28 * 28) # 将输入图像展平为一维向量
x = self.relu(self.fc1(x)) # 通过第一层并应用ReLU激活
x = self.fc2(x) # 通过第二层,输出分类得分输入图像(28×28) → 展平为784维向量 → 全连接层(784→128) → ReLU激活 → 全连接层(128→10) → 输出分类得分
1.5 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 将图像转换为Tensortransforms.Normalize((0.1307,), (0.3081,)) # 归一化处理(均值和标准差基于MNIST数据集)
])将 PIL 图像(H×W×C,0-255)转换为 PyTorch 张量(C×H×W,0.0-1.0),使用 MNIST 全局统计量(均值 0.1307,标准差 0.3081)对张量进行标准化,使数据符合标准正态分布,将原始图像转换为神经网络可高效处理的标准化张量
1.6 加载数据
# 加载MNIST训练数据集
# 'data':数据存储路径
# train=True:加载训练集
# download=True:若数据不存在则自动下载
# transform:应用上述的数据预处理
train_dataset = datasets.MNIST('data', train=True, download=True, transform=transform)
# 创建数据加载器,设置批处理大小和随机打乱
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)1.7 模型初始化
# 模型初始化
model = SimpleNet() # 创建网络模型实例
criterion = nn.CrossEntropyLoss() # 定义损失函数(交叉熵损失,适用于多分类问题)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 定义优化器(SGD+动量)模型:SimpleNet() 实例化神经网络,用于处理 MNIST 图像分类任务。
损失函数:nn.CrossEntropyLoss() 计算预测结果与真实标签的差异,适用于多分类问题。
优化器:optim.SGD 配置随机梯度下降(带动量)算法,用于更新模型参数,学习率为 0.01,动量为 0.5。
1.8 模型训练过程
输入数据 → 模型预测 → 计算损失 → 计算梯度 → 更新权重 → 重复直至收敛
epochs = 5 # 训练轮数
for epoch in range(epochs):model.train() # 设置模型为训练模式(启用Dropout等)for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad() # 梯度清零,防止累积output = model(data) # 前向传播,获取模型预测loss = criterion(output, target) # 计算损失值loss.backward() # 反向传播,计算梯度optimizer.step() # 更新模型参数# 每100个批次打印一次训练进度if batch_idx % 100 == 0:print(f'Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} 'f'({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')深度学习的核心训练逻辑(五个步骤)是固定的:
1. 清零梯度 → 2. 前向传播计算预测 → 3. 计算损失 → 4. 反向传播计算梯度 → 5. 更新参数
- 梯度清零:避免梯度累积(每个批次独立计算)。
- 前向传播:输入数据通过模型得到预测结果。
- 损失计算:使用交叉熵损失函数评估预测误差。
- 反向传播:计算损失对参数的梯度。
- 参数更新:优化器(SGD)根据梯度更新模型权重。
1.9 保存训练好的模型参数
# 保存训练好的模型参数
torch.save(model.state_dict(), "mnist_model.pth")
print("模型已保存为 mnist_model.pth")二,代码解析
2.1 定义模型
class SimpleNet(nn.Module):def __init__(self):super(SimpleNet, self).__init__()self.fc1 = nn.Linear(28 * 28, 128) # 第一个全连接层:输入784(28x28),输出128self.fc2 = nn.Linear(128, 10) # 第二个全连接层:输入128,输出10(对应0-9数字分类)self.relu = nn.ReLU() # ReLU激活函数,引入非线性特性def forward(self, x):x = x.view(-1, 28 * 28) # 将输入图像展平为一维向量x = self.relu(self.fc1(x)) # 通过第一个全连接层并应用ReLU激活x = self.fc2(x) # 通过第二个全连接层,输出未归一化的分类得分return x模型的定义在模型训练和模型测试里是完全一致的
2.2 加载模型
# 加载模型model = SimpleNet() # 创建模型实例model.load_state_dict(torch.load("mnist_model.pth")) # 加载训练好的模型参数model.eval() # 设置为评估模式(关闭Dropout等训练特有的层)model.eval() 的作用是将 PyTorch 模型设置为评估模式,主要影响以下特殊层的行为
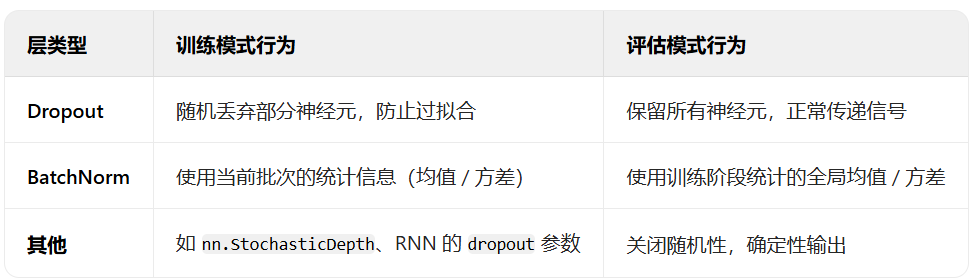
训练时的随机机制(如 Dropout)会导致每次前向传播结果不同,而评估时需要稳定的预测,BatchNorm 在评估时使用训练阶段累积的全局统计量,避免因单个批次数据波动影响结果。
2.3 预处理
# 打开并预处理图片image = Image.open(image_path).convert('L') # 打开图片并转换为灰度图(单通道)# 调整图片大小为28x28(如果需要)if image.size != (28, 28):image = image.resize((28, 28), Image.Resampling.LANCZOS) # 使用高质量重采样算法# 预处理(与训练时相同)transform = transforms.Compose([transforms.ToTensor(), # 转换为Tensor(范围从0-255变为0-1)transforms.Normalize((0.1307,), (0.3081,)) # 归一化处理(使用MNIST数据集的均值和标准差)])# 转换为张量并添加批次维度image_tensor = transform(image).unsqueeze(0) # 添加批次维度(模型期望输入格式:[批次, 通道, 高度, 宽度])2.4 预测
# 预测(关闭梯度计算以提高效率)with torch.no_grad():output = model(image_tensor) # 前向传播,获取模型输出pred = torch.argmax(output, dim=1).item() # 获取预测的数字(最大值索引)confidence = torch.softmax(output, dim=1)[0][pred].item() * 100 # 计算置信度百分比使用model(image_tensor)对输入的图像张量image_tensor进行前向传播,得到模型的输出output,在这里不计算梯度是因为这里是对于模型的测试,已经不需要想训练模型那样有一个反向传播来修改模型中的权重,在这里是否计算梯度完全不影响输出结果。需要注意的是,在使用torch.no_grad()上下文管理器时,模型的参数不会被更新,因此这段代码通常用于模型的推理阶段,而不是训练阶段。
2.5 显示结果
# 显示结果print(f"\n{'=' * 30}")print(f"预测数字: {pred}")print(f"置信度: {confidence:.2f}%")print(f"{'=' * 30}")# 可视化预测结果plt.figure(figsize=(8, 4)) # 创建8x4英寸的图形窗口# 左侧显示原始图片plt.subplot(1, 2, 1) # 创建1行2列的子图,选择第1个plt.imshow(image, cmap='gray') # 以灰度图显示原始图片plt.title('原始图片') # 设置标题plt.axis('off') # 关闭坐标轴显示# 右侧显示模型输入(归一化后的图像)plt.subplot(1, 2, 2) # 选择第2个子图plt.imshow(image_tensor[0][0], cmap='gray') # 显示模型输入的张量(移除批次和通道维度)plt.title(f'模型输入\n预测: {pred} (置信度: {confidence:.2f}%)') # 设置标题,包含预测结果和置信度plt.axis('off') # 关闭坐标轴显示plt.tight_layout() # 自动调整子图参数,使布局紧凑plt.show() # 显示图形三,测试
3.1 测试方法
如上文代码所示,我这里用的测试图片是自己定义图片,使用电脑自带的paint绘图软件,设置画布为28*28像素,黑底白字,手动写入一个字进行预测
3.2 测试结果
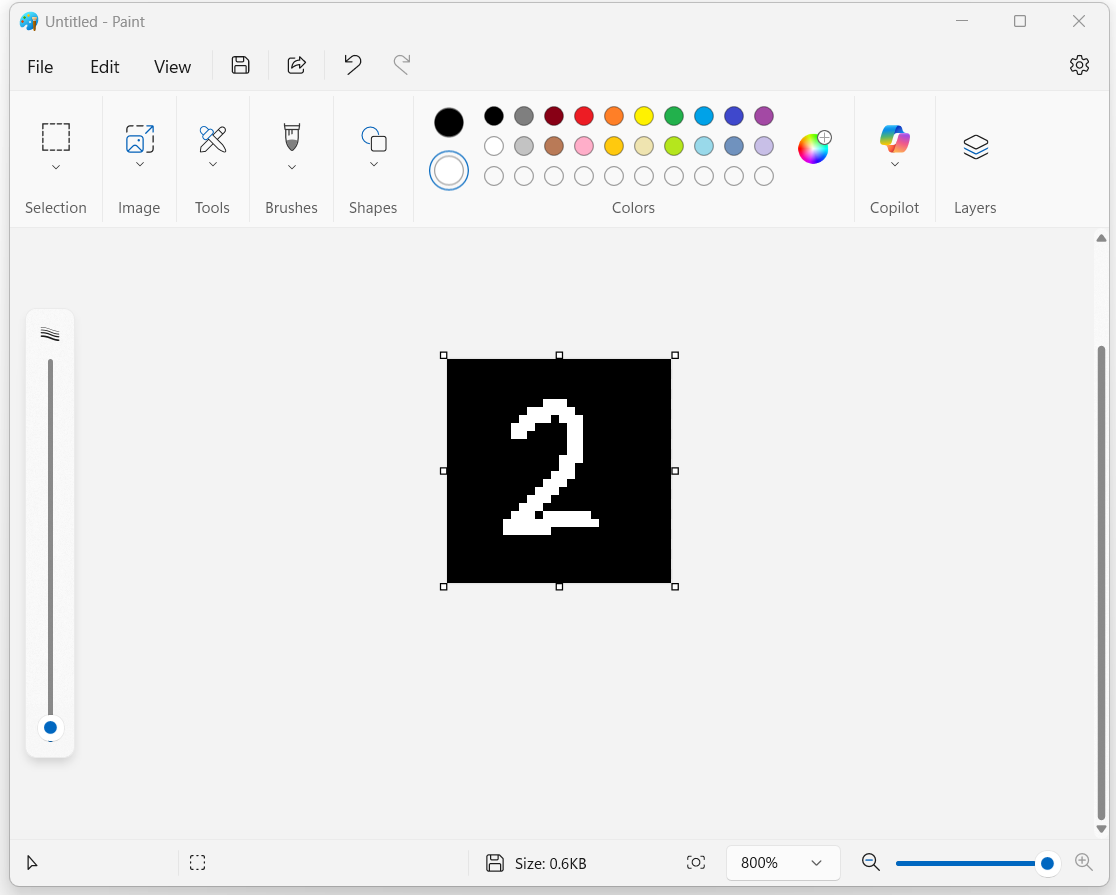

预测2的置信度为98.91%
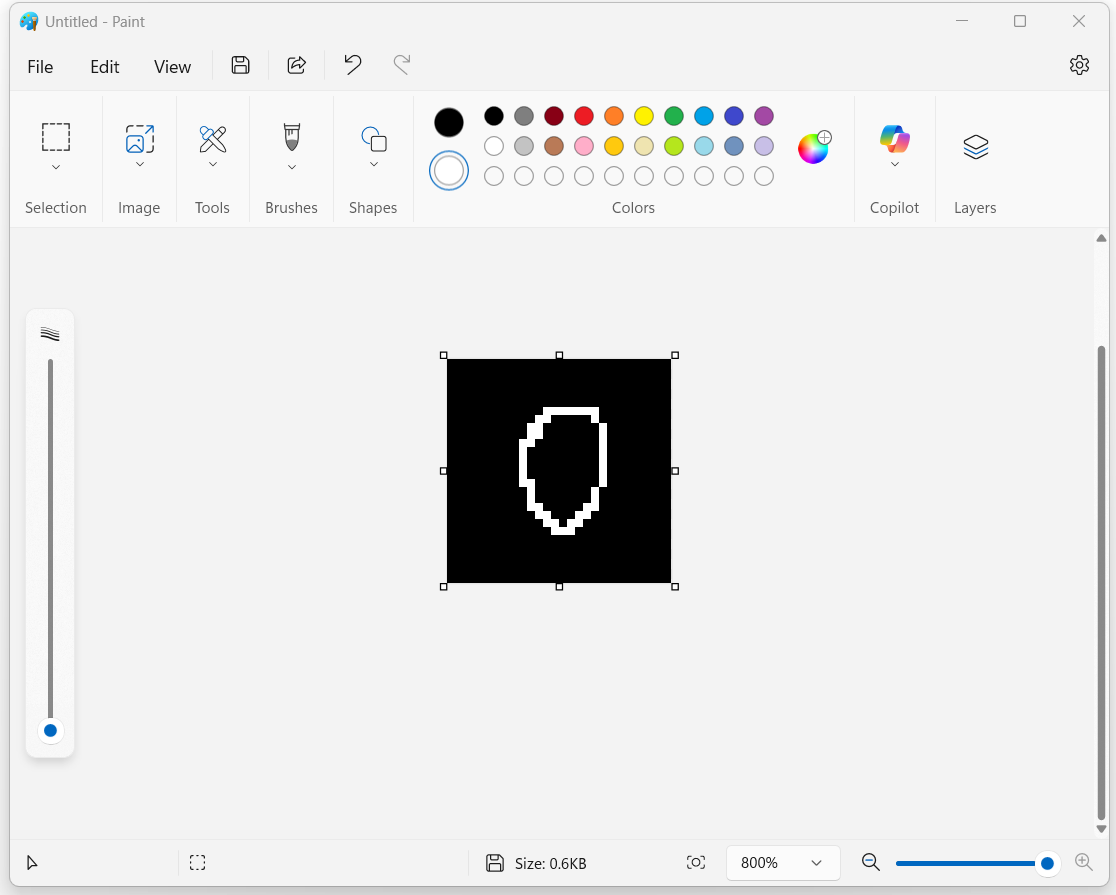

预测0的置信度仅有37.73%
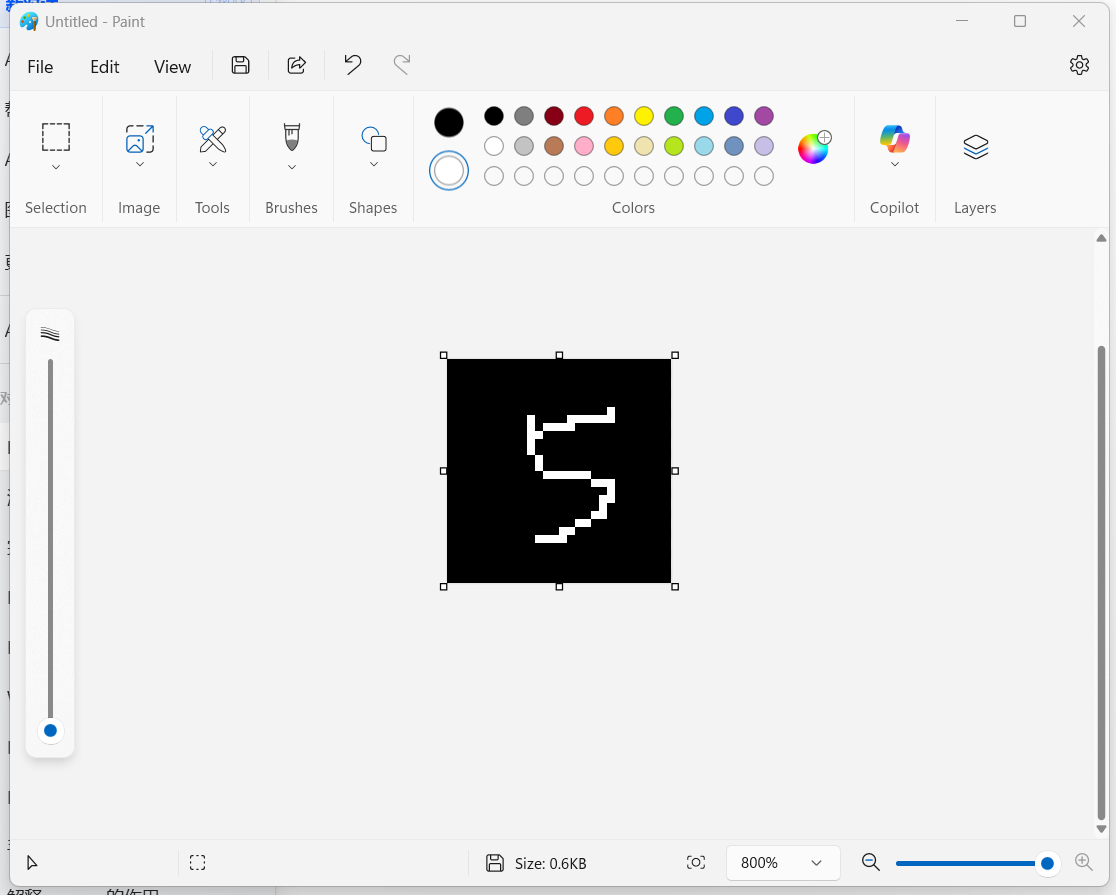
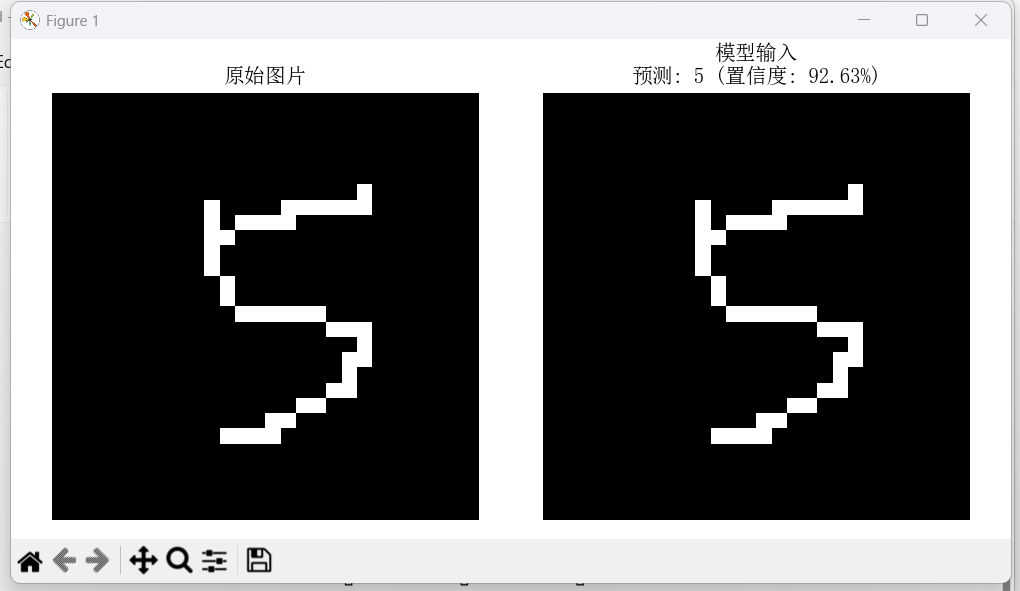
预测5的置信度有92.63%
四,总结
由于此次实验主要是为了学习深度学习基础,采用的是简单全连接网络,模型的训练效果欠佳,简单全连接神经网络(FCN)与卷积神经网络(CNN)在结构和功能上存在显著差异。FCN 中神经元与前后层全连接,缺乏专门的特征提取机制,数据适应性较广,适用于处理简单、低维数据,其结构简单易实现,在简单问题上训练速度快,但处理图像等复杂数据时参数多、计算量大,易过拟合且难以利用数据空间结构。CNN 则通过卷积核与池化操作提取局部特征,神经元仅与局部区域相连,大幅减少参数与计算量,特别擅长处理图像、音频等结构化数据,能自动学习特征,降低过拟合风险,在诸多领域表现出色,不过其网络结构复杂,训练和部署成本高,且解释性较差 。
五,完整代码
5.1 模型训练部分代码
# 导入PyTorch库及相关模块
import torch
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化器模块
from torchvision import datasets, transforms # 视觉数据集和数据转换工具
from torch.utils.data import DataLoader # 数据加载器# 定义神经网络模型 - 继承自PyTorch的nn.Module基类
class SimpleNet(nn.Module):def __init__(self):super(SimpleNet, self).__init__() # 调用父类构造函数self.fc1 = nn.Linear(28 * 28, 128) # 全连接层1:输入784(28x28像素),输出128self.fc2 = nn.Linear(128, 10) # 全连接层2:输入128,输出10(对应0-9数字分类)self.relu = nn.ReLU() # ReLU激活函数,引入非线性def forward(self, x):x = x.view(-1, 28 * 28) # 将输入图像展平为一维向量x = self.relu(self.fc1(x)) # 通过第一层并应用ReLU激活x = self.fc2(x) # 通过第二层,输出分类得分return x# 数据预处理流水线
transform = transforms.Compose([transforms.ToTensor(), # 将图像转换为Tensortransforms.Normalize((0.1307,), (0.3081,)) # 归一化处理(均值和标准差基于MNIST数据集)
])# 加载MNIST训练数据集
# 'data':数据存储路径
# train=True:加载训练集
# download=True:若数据不存在则自动下载
# transform:应用上述的数据预处理
train_dataset = datasets.MNIST('data', train=True, download=True, transform=transform)
# 创建数据加载器,设置批处理大小和随机打乱
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)# 模型初始化
model = SimpleNet() # 创建网络模型实例
criterion = nn.CrossEntropyLoss() # 定义损失函数(交叉熵损失,适用于多分类问题)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 定义优化器(SGD+动量)# 模型训练过程
epochs = 5 # 训练轮数
for epoch in range(epochs):model.train() # 设置模型为训练模式(启用Dropout等)for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad() # 梯度清零,防止累积output = model(data) # 前向传播,获取模型预测loss = criterion(output, target) # 计算损失值loss.backward() # 反向传播,计算梯度optimizer.step() # 更新模型参数# 每100个批次打印一次训练进度if batch_idx % 100 == 0:print(f'Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} 'f'({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')# 保存训练好的模型参数
torch.save(model.state_dict(), "mnist_model.pth")
print("模型已保存为 mnist_model.pth")5.2 模型测试部分代码
import torch
import torch.nn as nn
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.pyplot as plt # 重复导入(可删除一个)
plt.rcParams['font.sans-serif'] = ['SimSun'] # 设置中文字体为宋体,确保中文正常显示
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 定义模型(必须与训练时一致)
class SimpleNet(nn.Module):def __init__(self):super(SimpleNet, self).__init__()self.fc1 = nn.Linear(28 * 28, 128) # 第一个全连接层:输入784(28x28),输出128self.fc2 = nn.Linear(128, 10) # 第二个全连接层:输入128,输出10(对应0-9数字分类)self.relu = nn.ReLU() # ReLU激活函数,引入非线性特性def forward(self, x):x = x.view(-1, 28 * 28) # 将输入图像展平为一维向量x = self.relu(self.fc1(x)) # 通过第一个全连接层并应用ReLU激活x = self.fc2(x) # 通过第二个全连接层,输出未归一化的分类得分return xdef predict_image(image_path):# 加载模型model = SimpleNet() # 创建模型实例model.load_state_dict(torch.load("mnist_model.pth")) # 加载训练好的模型参数model.eval() # 设置为评估模式(关闭Dropout等训练特有的层)# 打开并预处理图片image = Image.open(image_path).convert('L') # 打开图片并转换为灰度图(单通道)# 调整图片大小为28x28(如果需要)if image.size != (28, 28):image = image.resize((28, 28), Image.Resampling.LANCZOS) # 使用高质量重采样算法# 预处理(与训练时相同)transform = transforms.Compose([transforms.ToTensor(), # 转换为Tensor(范围从0-255变为0-1)transforms.Normalize((0.1307,), (0.3081,)) # 归一化处理(使用MNIST数据集的均值和标准差)])# 转换为张量并添加批次维度image_tensor = transform(image).unsqueeze(0) # 添加批次维度(模型期望输入格式:[批次, 通道, 高度, 宽度])# 预测(关闭梯度计算以提高效率)with torch.no_grad():output = model(image_tensor) # 前向传播,获取模型输出pred = torch.argmax(output, dim=1).item() # 获取预测的数字(最大值索引)confidence = torch.softmax(output, dim=1)[0][pred].item() * 100 # 计算置信度百分比# 显示结果print(f"\n{'=' * 30}")print(f"预测数字: {pred}")print(f"置信度: {confidence:.2f}%")print(f"{'=' * 30}")# 可视化预测结果plt.figure(figsize=(8, 4)) # 创建8x4英寸的图形窗口# 左侧显示原始图片plt.subplot(1, 2, 1) # 创建1行2列的子图,选择第1个plt.imshow(image, cmap='gray') # 以灰度图显示原始图片plt.title('原始图片') # 设置标题plt.axis('off') # 关闭坐标轴显示# 右侧显示模型输入(归一化后的图像)plt.subplot(1, 2, 2) # 选择第2个子图plt.imshow(image_tensor[0][0], cmap='gray') # 显示模型输入的张量(移除批次和通道维度)plt.title(f'模型输入\n预测: {pred} (置信度: {confidence:.2f}%)') # 设置标题,包含预测结果和置信度plt.axis('off') # 关闭坐标轴显示plt.tight_layout() # 自动调整子图参数,使布局紧凑plt.show() # 显示图形def main():# 直接在这里写你的图片路径image_path = r"C:\Users\10532\Desktop\Study\test\Untitled.png"# 检查文件是否存在try:Image.open(image_path) # 尝试打开文件,检查是否存在except Exception as e:print(f"错误:无法打开图片 - {image_path}")print(f"错误详情:{e}")return # 出错则退出程序predict_image(image_path) # 调用预测函数if __name__ == "__main__":main() # 程序入口点