MYSQL 的缓存策略(四)
一. MySQL 缓存方案用来干什么
1.作用
缓存用户定义的热点数据,用户直接从缓存获取热点数据,降低数据库的读写压力
2.场景分析
- 内存访问速度是磁盘访问速度的10万倍(数量级)
- 读的需求远远大于写的需求
- mysql自身缓冲层跟业务无关
- mysql作为项目主要数据库,便于统计分析
- 缓存数据库作为辅助数据库,存放热点数据
3. mysql 主从复制
MySQL 主从复制是指一个 主库(Master) 将数据的更新操作同步到一个或多个 从库(Slave) 的机制
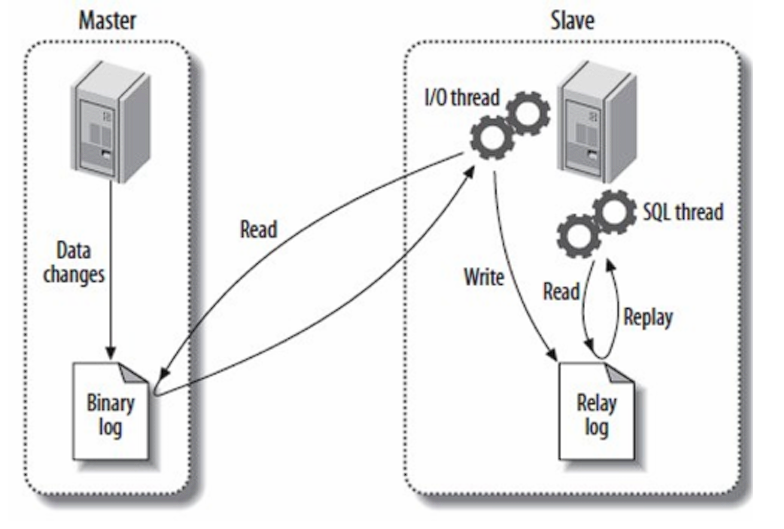
| 阶段 | 描述 |
| 1. 主库记录 binlog | 所有写操作都会写入 binary log 日志 |
| 2.从库 I/O 线程读取 binlog | 从库连接主库,读取 binlog 并保存为 relay log(中继日志) |
| 3.从库 SQL 线程执行 relay log | 将 relay log 转为 SQL 在从库中执行,实现数据同步 |
4.为什么需要缓冲层
缓冲层,本质上是指在系统和慢速设备(如磁盘)之间加一个高速中间存储区域(一般在内存),目的是提高系统整体性能和减少资源消耗
mysql 有缓冲层,它的作用也是用来缓存热点数据,这些数据包括索引、记录等;mysql 缓冲层是 从自身出发,跟具体的业务无关;这里的缓冲策略主要是 lru;
二. 提升 MySQL 读写性能的方式
1.MySQL 读写分离
读写分离是一种优化策略,通过将主库用于处理写操作,从库用于处理读操作,实现负载均衡与高并发处理能力。借助主从复制机制,从库拥有与主库一致的数据。应用程序可通过中间件或代码逻辑,将写请求导向主库,读请求导向从库。
2.连接池
数据库连接属于 “重量级资源”,频繁创建与关闭连接会耗费大量时间。连接池通过复用连接,显著提升性能,其优点包括:
- 减少连接建立与销毁的时间开销。
- 控制最大连接数,防止数据库过载。
- 支持连接健康检查、空闲回收等机制。
3.异步连接
传统数据库操作多为同步阻塞模式,而异步连接可使应用程序在执行 SQL 查询时不处于阻塞状态,进而提升响应效率:
- 应用线程发出 SQL 请求后,无需等待数据库返回结果,即可立即执行其他逻辑。
- 待数据库准备好结果后,通过回调或事件通知进行处理。此方式适用于高并发场景,如 Web 服务、异步任务处理。
三. 缓存方案解决一致性问题
1.Redis 和 MySQL 一致性状态分析
| 状态编号 | MySQL 状态 | Redis 状态 | 问题 |
| ① | 有 | 无 | 缓存穿透,需从数据库读取后写入缓存 |
| ② | 无 | 有 | 读取到脏数据,存在严重一致性问题 |
| ③ | 有 | 有(不一致) | 缓存未更新,读到旧数据,数据不一致 |
| ④ | 有 | 有(一致) | 正确状态 |
| ⑤ | 无 | 无 | 正确状态 |
我们期望仅存在状态 4 和 5 ,关键在于避免状态 2 和 3 ,并修复 状态 1
读取流程:先读取缓存,若存在则直接返回(无需访问 MySQL);若不存在,则访问 MySQL,若 MySQL 中有数据则返回并同步至缓存,若 MySQL 中也无数据,则说明整个系统都不存在该数据。
写策略:
安全为主(强一致)策略:先删除缓存,再写入数据库。即先执行 del key 删除 Redis 缓存,再更新 MySQL 数据。优点是能确保缓存为旧数据,不会读到脏数据;缺点是在并发场景下可能造成缓存击穿(刚删除缓存就被读取) 。
效率为主(最终一致)策略:先写入数据库,再异步更新缓存。即先更新 MySQL 数据,然后通过消息队列触发或延迟任务等方式异步更新 Redis。优点是效率更高,适用于读多写少的场景;缺点是存在数据瞬时不一致风险,适用于业务可容忍短时间不一致的情况。
2.同步方案
| 同步方案 | 描述 | 适用场景 |
| 延迟双删 | 更新数据库后,间隔一段时间分两次删除缓存 | 强一致要求较高的场景 |
| 消息队列同步 | 数据库更新后,将消息写入消息队列,异步刷新缓存 | 写操作较多、缓存更新频繁的场景 |
| 订阅 binlog | 监听 MySQL 的 binlog,数据变更时更新缓存 | 大型系统,常使用 Canal/Debezium 工具 |
| 定时刷新 | 通过定时任务刷新缓存数据 | 缓存数据更新频率较低的场景 |
延迟双删原因解释:若线程 A 为查询请求,线程 B 为更新请求,按以下流程操作可能出现问题:
- 线程 B:删除缓存(step 1)
- 线程 A:读取缓存(发现缓存已被删除),从数据库读取旧数据
- 线程 B:更新数据库为新数据(step 2)
- 线程 A:将旧数据写入 Redis(step 3)
结果导致 Redis 又被写入旧数据,造成数据不一致。因此采用延迟双删,可一定程度避免此类问题。
四. 缓存方案问题及解决
1.缓存穿透
指查询数据库和缓存中均不存在的 key(如恶意构造的 user_id=-1),使每次请求都绕过缓存直接访问数据库,导致缓存失效。
解决方案:
- 布隆过滤器(推荐):可拦截非法 key。
- 空值缓存:将查询结果为 null 的 key 存入 Redis,并设置较短过期时间(如 1 - 5 分钟)。
2. 缓存击穿
当某个热点 key 过期瞬间,大量请求同时涌入数据库,使数据库压力剧增,甚至可能导致数据库崩溃,引发服务雪崩。
解决方案:
- 互斥锁机制(分布式锁):只允许一个请求重建缓存,其他请求等待。
- 永不过期 + 异步更新:缓存设置为不过期,后台定时刷新。
- 逻辑过期:在缓存结构中添加时间戳,自主判断是否需异步更新。
3. 缓存雪崩
大量 key 在同一时间失效,致使请求同时访问数据库,可能造成数据库崩溃且系统短时间内难以恢复。
解决方案:
- 过期时间设置随机值(抖动):避免缓存集中失效。
- 热点数据预热:服务重启后预加载缓存。
- 多级缓存:如采用本地缓存 + 分布式缓存的组合。
五.缓存方案的弊端
1. 无法处理多语句任务
Redis 作为缓存系统,无法感知事务范围。在涉及多表写入、回滚逻辑等多语句任务时,缓存不能自动同步状态。因此,对于重要业务,仍应以数据库操作为主,一致性要求高的数据优先从数据库读取。
2. Redis 不支持回滚
Redis 的写入操作立即生效,不像数据库支持事务回滚(遵循 ACID 特性)。一旦数据写入 Redis 后,若后续数据库操作失败,可能出现缓存脏写问题。
应对策略:
- 采用「先删缓存,再更新数据库」的强一致策略。
- 通过消息队列异步补偿缓存更新。
3. Redis 和 MySQL 不一致问题
因网络延迟、并发覆盖、先写缓存再写数据库等操作顺序问题,可能导致 Redis 和 MySQL 数据不一致。
解决办法:
- 延迟双删:先删除缓存,再更新数据库,待数据库写入完成后再次删除缓存。
- 通过 MQ 或 Canal 同步 binlog:实现数据同步。
- 增加缓存版本号机制:避免并发写入时数据被覆盖。