B站PWN教程笔记-10
前言:因为内容比较零散,我会尽量分类,但是还是不保准,有点琐碎了。
一个学习堆的很好网站
国外师傅的堆教程:Preface | heap-exploitation
堆管理器是如何工作的
堆管理器的部分细节
这部分内容在视频后部分讲的,感觉可以写在这里,就写在了这里。
只有程序第一次执行malloc,堆管理器才会初始化。不执行第一条malloc的时候用vmmap来看,实际上是不存在堆段。假如malloc了0x100,操作系统实际会多申请0x10存储控制数据(x64)。
pwngdb的fastbin指令,可以让我们看出来最小的堆的所占空间大小。
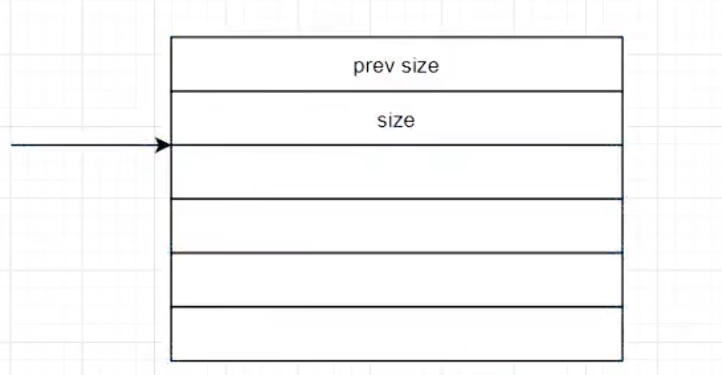
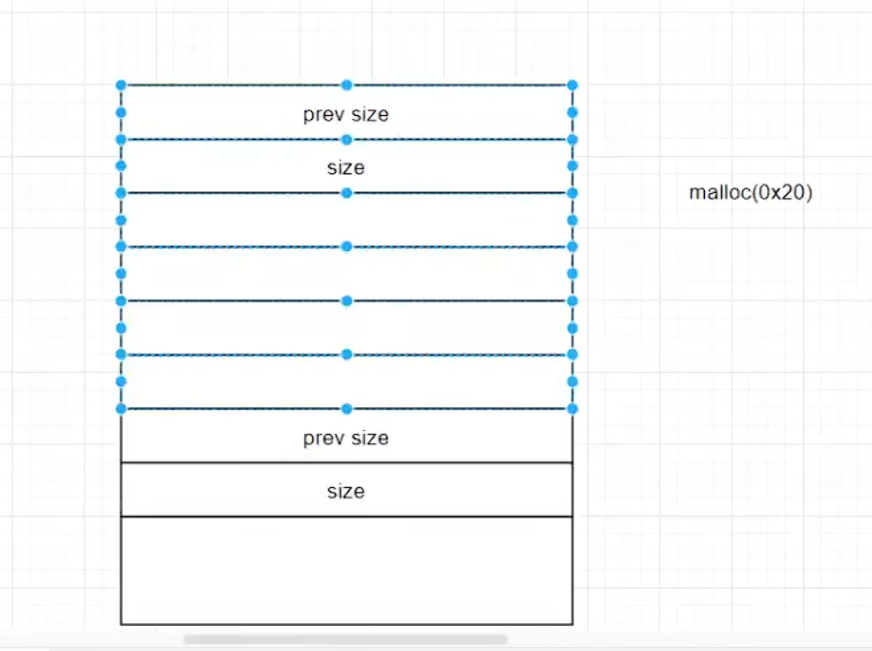
malloc函数返回的指针,实际指向的位置如图所示。(这里注意,堆是从低地址往高地址生长,图中上面是低地址,下面是高地址,数据填充是自上而下)
在pwngdb,可以使用heap查看堆空间。也可以用p+指针查看某个指针保存的地址。为啥这里有这么多堆(实际程序只有1个malloc),实际上一些缓冲区,如printf,默认的话就是从堆里面申请空间作为缓冲区的。
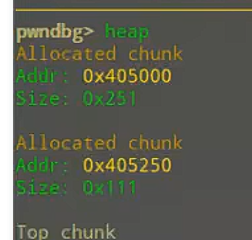
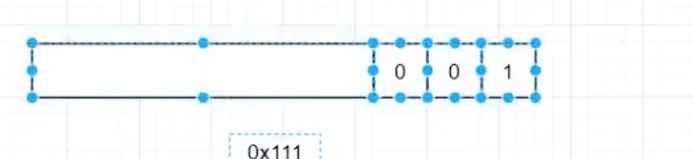
这里有一个疑问,申请的0x100,为什么size却是0x111?答案有点让我想不到,因为后三位如图所示。
其实这里也可以看出来gdb是通过读取size来获取heap大小的。
三个关键词

首先理解一下进程和线程。进程是操作系统分配资源(如虚拟内存),一个进程有许多线程。
arena
在主线程,堆申请到的内存会组合为一个arena。一个进程可以有多个arena,因为一个进程可能有多个线程。一个arena对应4个bins。

多线程可以并发执行任务。但是CPU单核的话只能支持单线程。就算看着是多个线程一起执行,那也是CPU极快在不同线程之间跳转的结果。
因为每个线程都需要自己的资源空间,所以每个线程都有一个自己的arena。
arena 是堆管理器的内存分配区,而malloc_state是描述和管理这个分配区的核心数据结构
看fast bins后面有个[NFASTBINS],这个是可以人为修改的,默认是7。
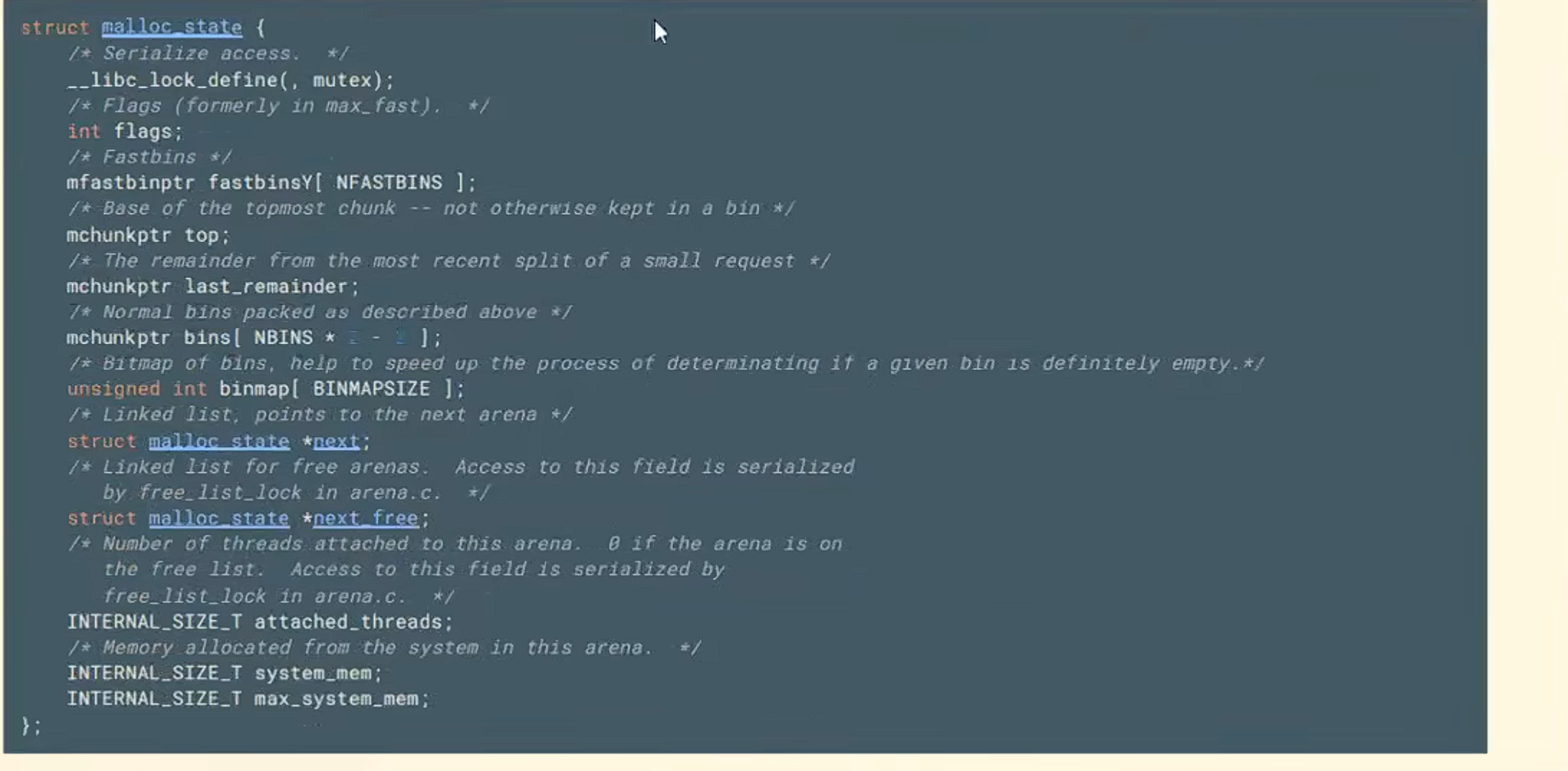
剩下三个bin就在那一个bins里面储存。
chunk
下图是PPT截图。

首先看这样一个场景,malloc函数返回的是一个指针,大方框是arena,小方框是我们申请的内存。实际上我们申请到的内存要大于0x400.而且返回的指针并不是指在开头位置,而是中间的某个位置。

这块区域就是chunk,chunk是我们执行malloc分配到的单位,也是内存分配的最小单位,也是用户获取内存的最小单位。
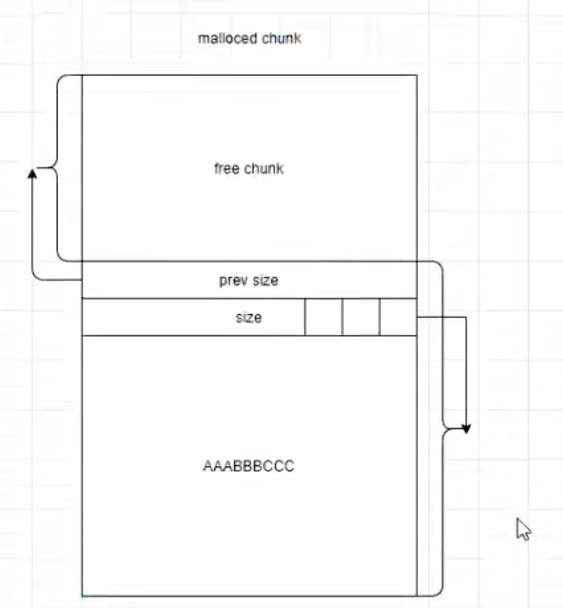
下面是一个malloced chunk的标准结构。前面两行都是控制信息,后面是数据区。这里要注意,free后内存不会直接返还给操作系统。原因之一就是直接返还给操作系统,就是直接在系统内存上操作,需要操作硬件,本身就是消耗资源。不能反复的消耗资源(这也是缓冲区设计的原因之一)。这也是堆管理器刚开始问操作系统要了大量内存的原因,后续操作只需要用户和堆管理器之间进行对话即可。

malloced chunk
这还是最简单的一种情况。
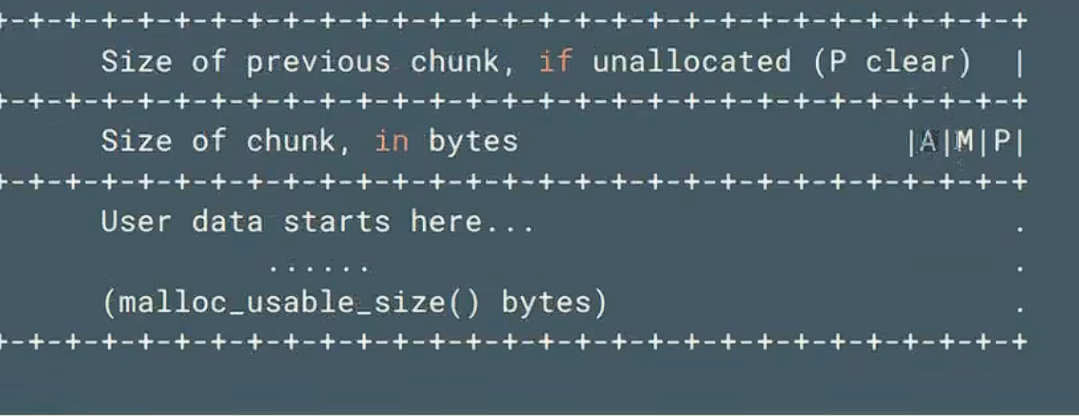
下面是一个详细的介绍。第一个控制字符,prev size,保存的是上面没有被分配的堆的内存。size,保存的是这一个malloced chunk的尺寸。size的低三位是3个控制字符。至于为什么见下文。AAABBBCC这都是堆内存里面保存的数据了。
. 相邻低地址 chunk 已被分配(in use)
prev_size的值:未定义(通常为任意值或被忽略)。- 原因:当低地址 chunk 处于分配状态时,系统不会通过
prev_size字段来访问它(因为分配中的 chunk 无法被合并)。此时,prev_size字段的空间可能被上层应用或其他数据占用,其值无特殊意义。2. 相邻低地址 chunk 是空闲的(free)
prev_size的值:存储前一个空闲 chunk 的大小(以字节为单位)。- 用途:当当前 chunk 被释放时,系统会通过
prev_size字段找到前一个空闲 chunk,并尝试合并它们(称为 向前合并)。3. 特殊情况:第一个分配的 chunk
- 低地址无有效 chunk:
prev_size字段可能被设置为 0,或用于其他内部标记(如内存管理器的头部信息)。- --豆包
prev_size, 如果该 chunk 的物理相邻的前一地址 chunk(两个指针的地址差值为前一 chunk 大小)是空闲的话,那该字段记录的是前一个 chunk 的大小 (包括 chunk 头)。否则,该字段可以用来存储物理相邻的前一个 chunk 的数据。这里的前一 chunk 指的是较低地址的 chunk
作者:HAPPYers
链接:https://www.jianshu.com/p/484926468136
来源:简书
首先按照现在的知识,一个chunk至少也不会小于8字节(x86),因为起码有俩控制内容,这就已经2*4字节了。所以size至少也得是8,8对应的二进制数据是1000,size至少也是以8为单位,所以size最后三位一定是0.与其存放一堆无用的0,倒不如用作控制字符。
补充:其实内存的分页对齐是末尾3十六进制数字(1.5字节)为0对齐。
其中的A指的是是否为主线程的arena,M代表是否为mmap段分配。P的值是判断是否是malloc chunk,P=0表示前一个chunk是free chunk,P=1则表示正在被用。(fast bin的P就是1,为啥呢,理解为既然要快,它就不可以和前面的chunk合并)
freechunk
这分很多类型,慢慢的来学习吧。我们先给大致结构绘画一下。
small-bin/unsorted bin
首先一个chunk被free,里面的数据不会被清空(和磁盘删除文件一个道理)。fd和bk是两个指针,这个我们后期再了解。
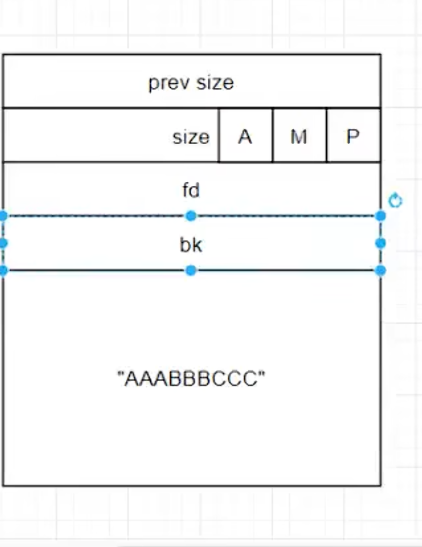
当他被释放的时候,P假如刚好是0会发生什么事情呢?
就会和上面的堆发生合并.原先的堆数据还在,但是相当于磁盘删除文件一样,上面的控制信息之类被从堆控制器抹除了。
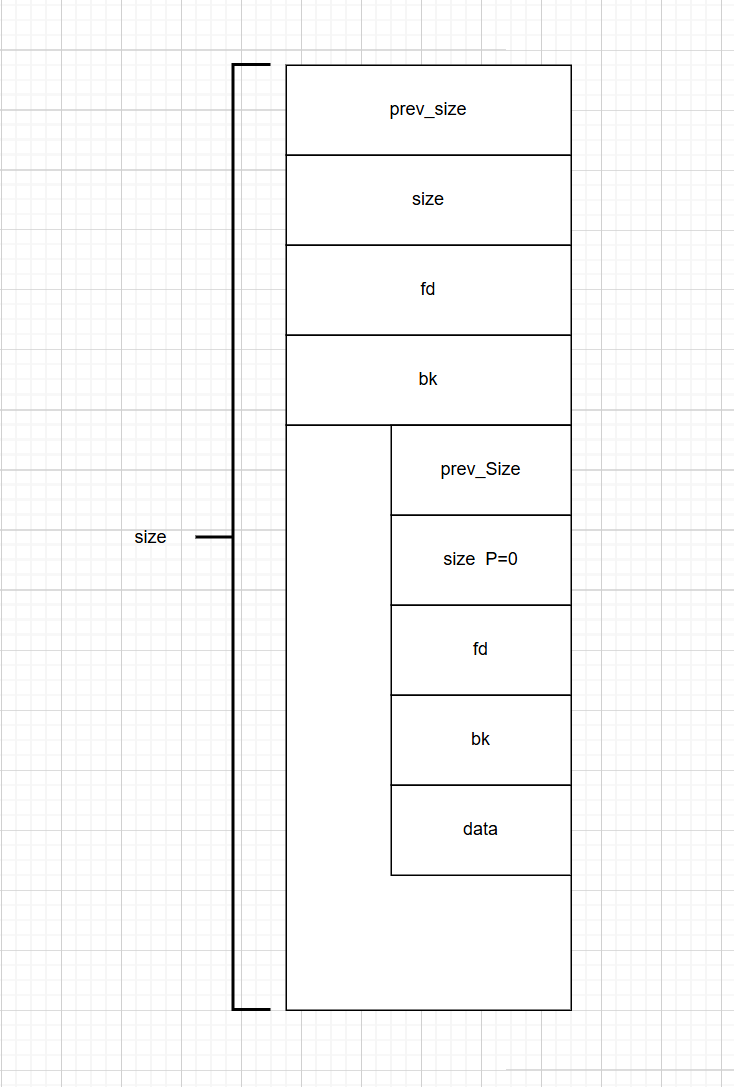
large_bin free chunk
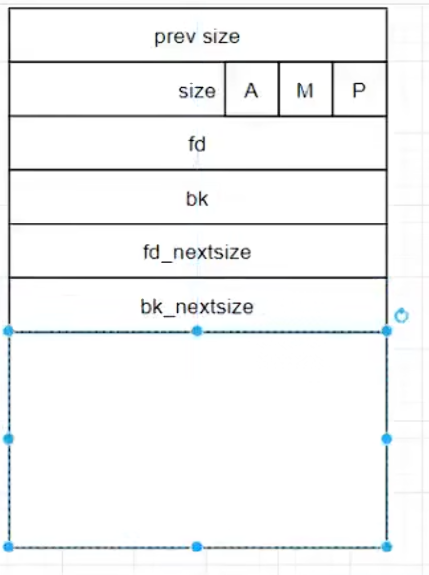
fast bin free chunk
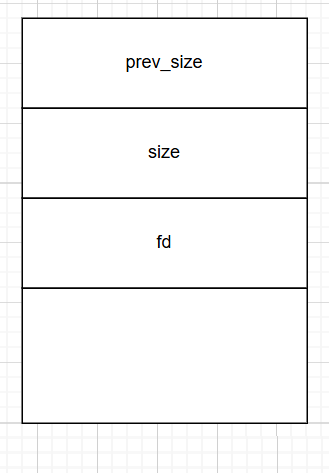
chunk在glibc的实现
这只是一个定义。可以看到chunk是被定义为结构体,但是其实这结构体有时候并不是全用。具体还有堆管理器的实现代码,在这里就先暂时不那么深入讲解。

chunk结构详解
prev_size的复用
假设现在要free上面的chunk
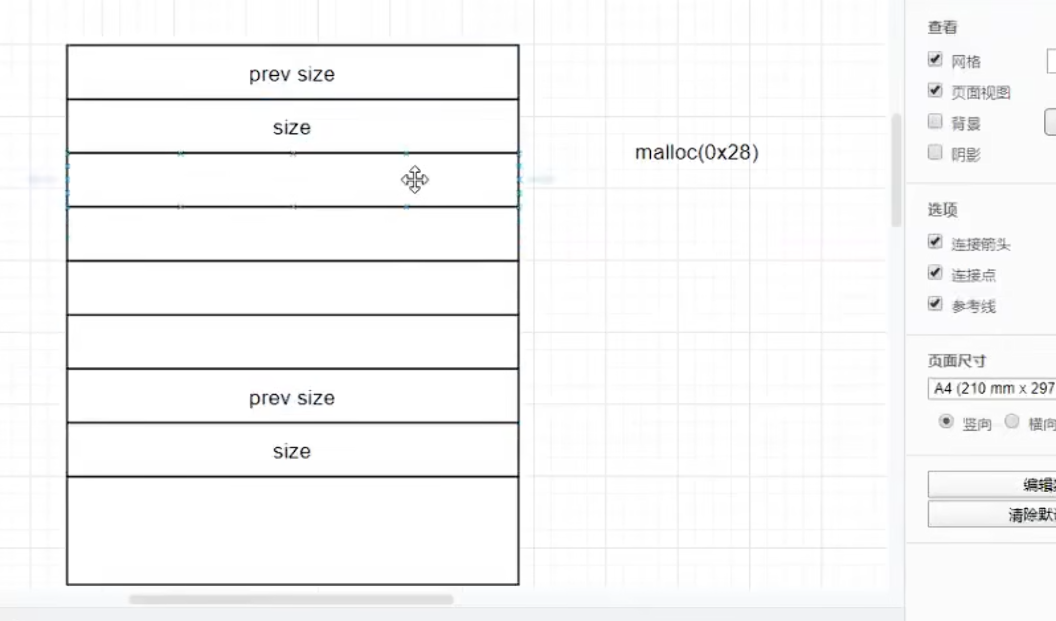
首先说明一下,malloc在找不到free chunk了,才会跟操作系统要。
本来上面的是malloc(0x20),但是如果malloc(0x28),操作系统还是会把这个给我。因为prev_size这块区域会被使用。因为实际上prev_size存储的是free chunk的size,现在上面的chunk已经不是free chunk,自然他也没用了,干脆一块申请过去了。其实从这里可以看出,就算0x20||0X28,得到的空间应该是一样的。同理可得,malloc(0xn8)和malloc(0xn0)得到的内存空间是一样的,因为涉及到pre_size复用问题。
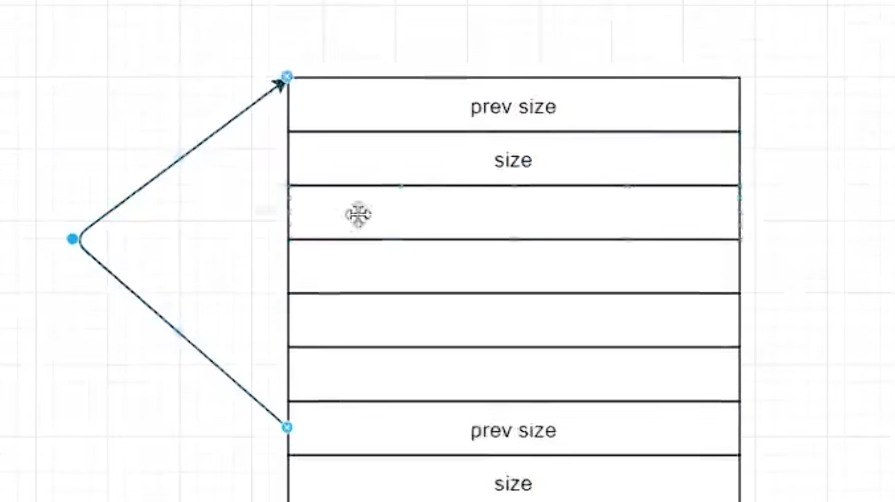
物理链表
实际上很容易理解,就是因为有prevz_size,每一个chunk总可以找到上一个chunk的起始地址,以此类推,就如同一条链条一样。连起来了相邻链表
bin
bin是数组。
就像windows的回收站一样,你不用的chunk放在我这里,等我想用了,我再来拿。bin管理chunk就是用的链表结构,不是说真的打包free chunk真跟垃圾池一样。free chunk还在原来的位置,只不过被标记了,然后在bin链表存了它的相关信息。

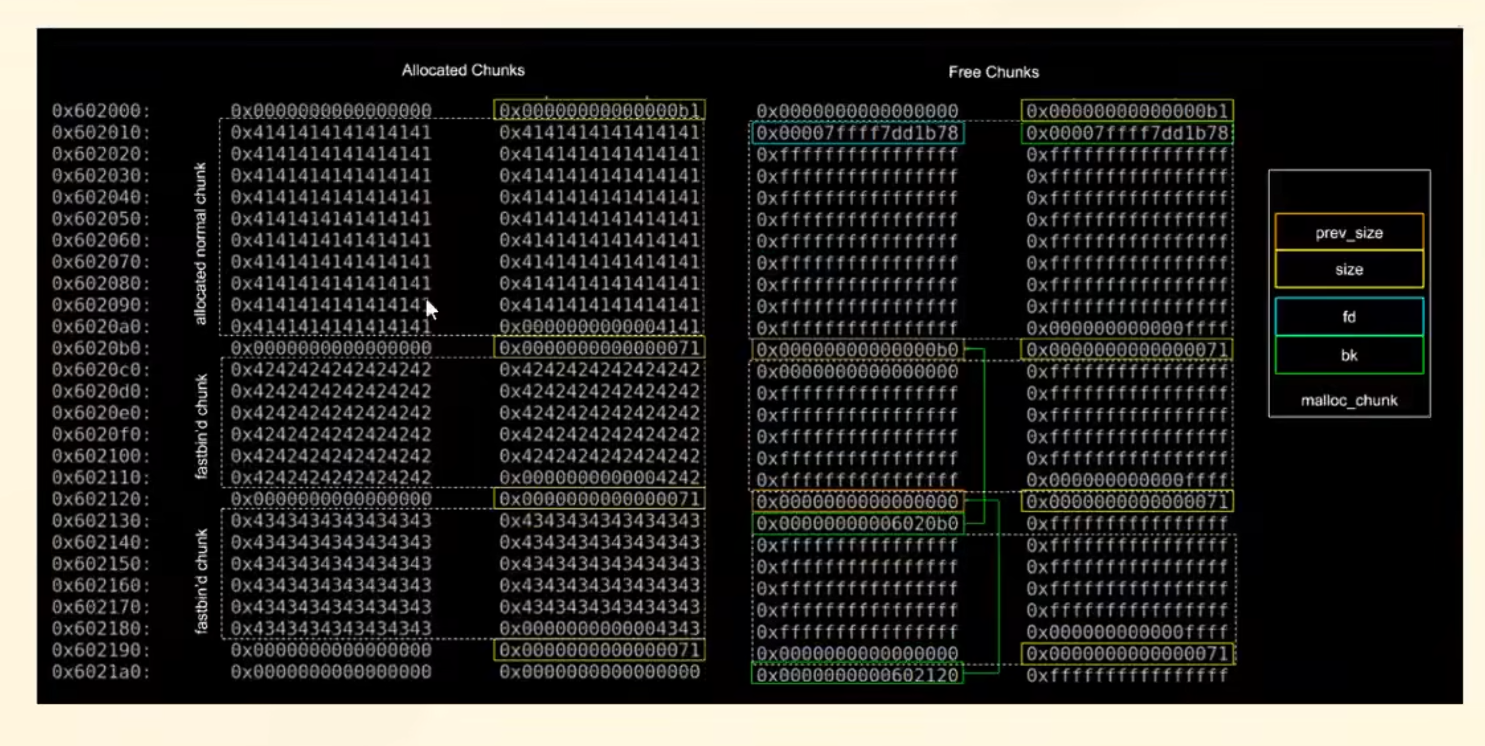
大家看一下实际内存中的chunk。
左边是已经分配了的chunk,可以看到涉及了prev_size的复用,只有一个控制字段。而且末尾是1,代表着:p=1,就是前面的chunk已经被使用了!!!
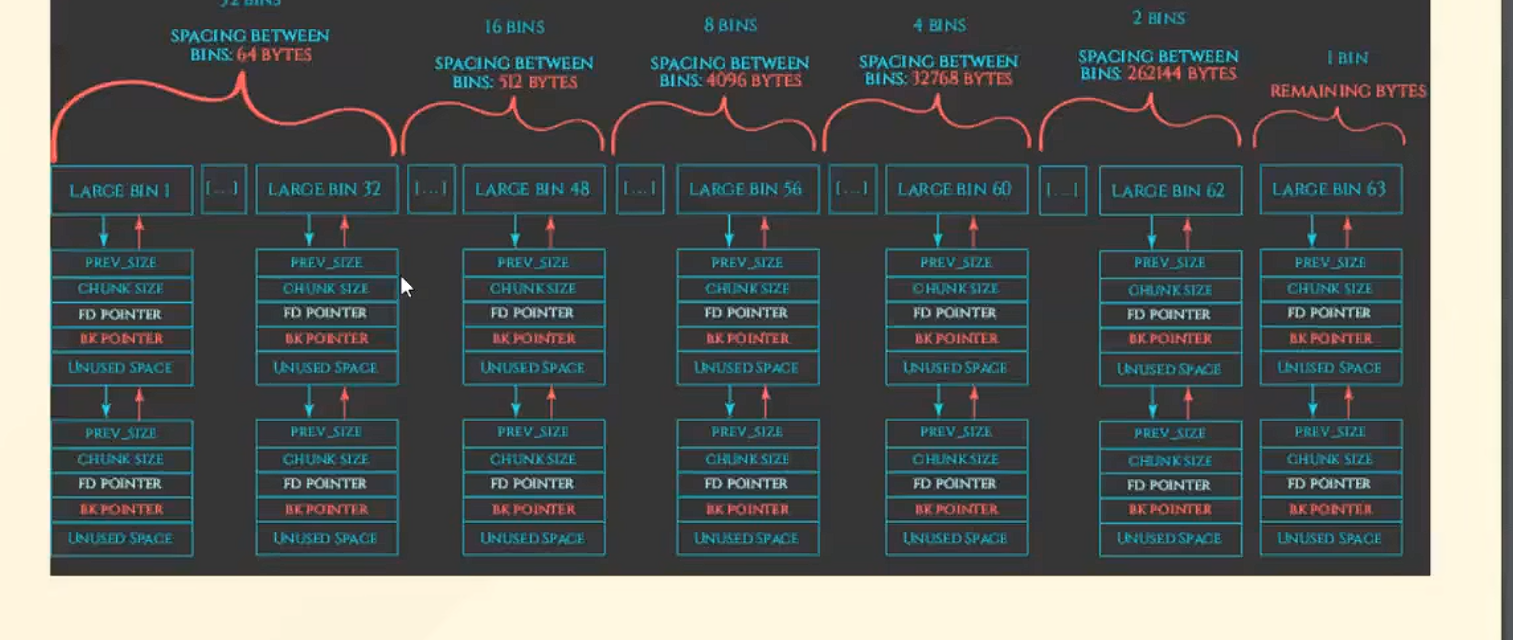
large bin
- SPACING BETWEEN BINS:代表相邻 large bin 之间管理的 chunk 大小差值。比如 “SPACING BETWEEN BINS: 64 BYTES” ,意味着对应这组的相邻 large bin 所管理的 chunk 大小相差 64 字节 。不同组的间距不同,如还有 512 字节、4096 字节等间距,这是为了按不同粒度对大内存块进行分类管理。--豆包
第一行方框内的数字表示size递增的数值。
是进阶内容,题目较少。

和small bin差不多,但是它,每个bin表示一个范围而非一个确定的数字,最后一个bin表示chunk大小自x(一个确定数字)到无限大。
small bins
FIFO:先进先出

就是下面的unsorted bin的不断重复。第一行的是物理完全相邻,但是图片限制无法画在一起
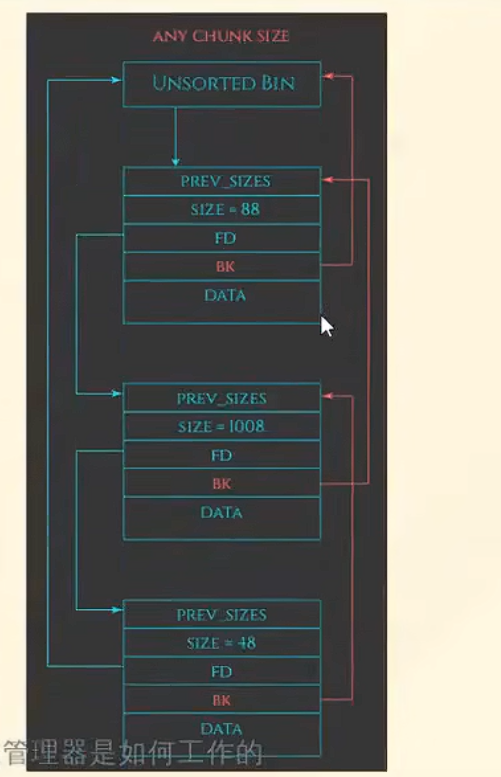
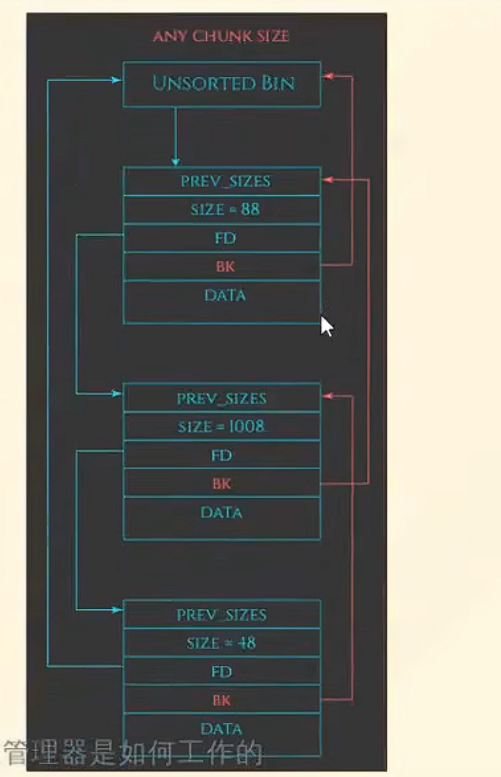
unsorted bin
bins索引从1开始成为bin

只有一个bin。这里也注意,这都是未分类的bin,里面大小是任意值,你只要放不进fast bin,都可以先放在unsorted bin。
如果malloc一个large bin大小了,他会首先在unsorted bin这里查找,并自动合并,触发sorted。没找到的话再去large bin找。
里面的bk实际上没啥用,主要是为small bin服务。
fast bins
意义;有时候程序需要频繁申请小内存空间,为了提高效率,独立出一个FAST BIN。有时候unsorted bin遍历的时候也会给fast bin分类了。
当释放的 chunk 不属于 fast bin 大小范围,且不和 top chunk 紧邻时,会先被放入 unsorted bin。后续
malloc操作在 unsorted bin 查找合适 chunk 时,如果取出的 chunk 大于所需大小,就会进行分割。若分割出的剩余部分大小处于 fast bin 大小范围内(一般小于max_fast,默认 64B ) ,这部分就会被分类到 fast bin 中。--豆包
第四行64位下乘以2即可。

形式类似下图,就是大小写在了数组里面。每一个小的就是一个bin!!
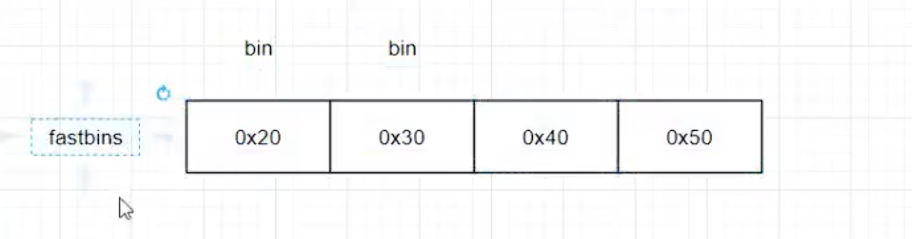
通过fd穿起来。bin指向第一个fd,第二个的fd指向第三个的fd,以此类推。最后一个的fd是null。 而且类似于栈,后进的先出,也就是先分配null指针的那个。malloc获取到是fd的值,fd随后就被用户数据覆盖了
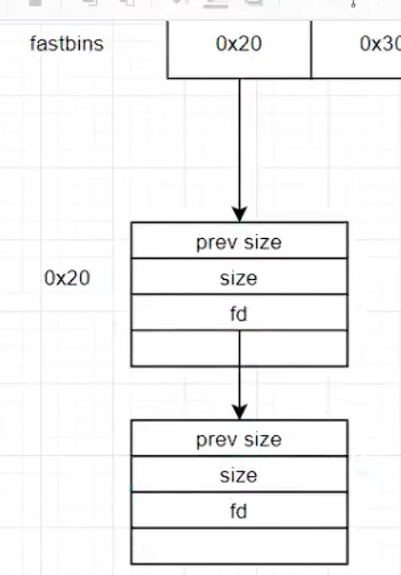
逻辑链表
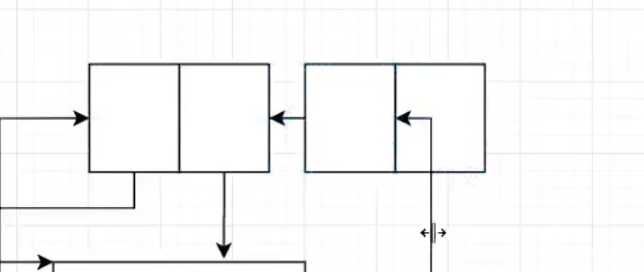
上面介绍的fast bin的一个个bin用指针穿起来的链表就是逻辑链表。物理链表是相邻,逻辑链表是同类。除了fast bin和tcache(暂时不讲这个tcache),其他的链表都是双向链表,如下。bk指向前一个的头,fd指向后一个的头。另外,这也是unsorted的结构。双向链表好处:因为遵循底部压入数据,头部取出数据这样的双向操作。所以可以大大加快速度