【AI面试秘籍】| 第7期:多轮对话如何实现长期记忆?高频考点解析+代码实战

一、💡 面试考察重点解析(必背!)
面试官抛出这个问题时,实际在考察:
-
技术瓶颈认知:是否理解传统方案的局限性
-
架构设计能力:能否设计可扩展的记忆系统
-
工程实践思维:如何平衡效果与性能
-
前沿技术敏感度:是否了解最新论文进展
二、技术原理剖析(标准回答模板)
2.1 传统方案缺陷
"现有对话系统采用固定窗口机制存在两大硬伤:
① 上下文长度限制(4k tokens导致长对话截断)
② 信息衰减问题(关键信息随轮次增加丢失)
例如当用户在第20轮提及过敏史时,传统方案可能已丢失该关键信息"
2.2 长期记忆核心原理
标准回答应包含三层架构:
记忆写入 -> 记忆存储 -> 记忆检索关键技术指标:
-
记忆召回率 ≥85%
-
响应延迟 ≤2s
-
存储成本 ≤0.5元/万次对话
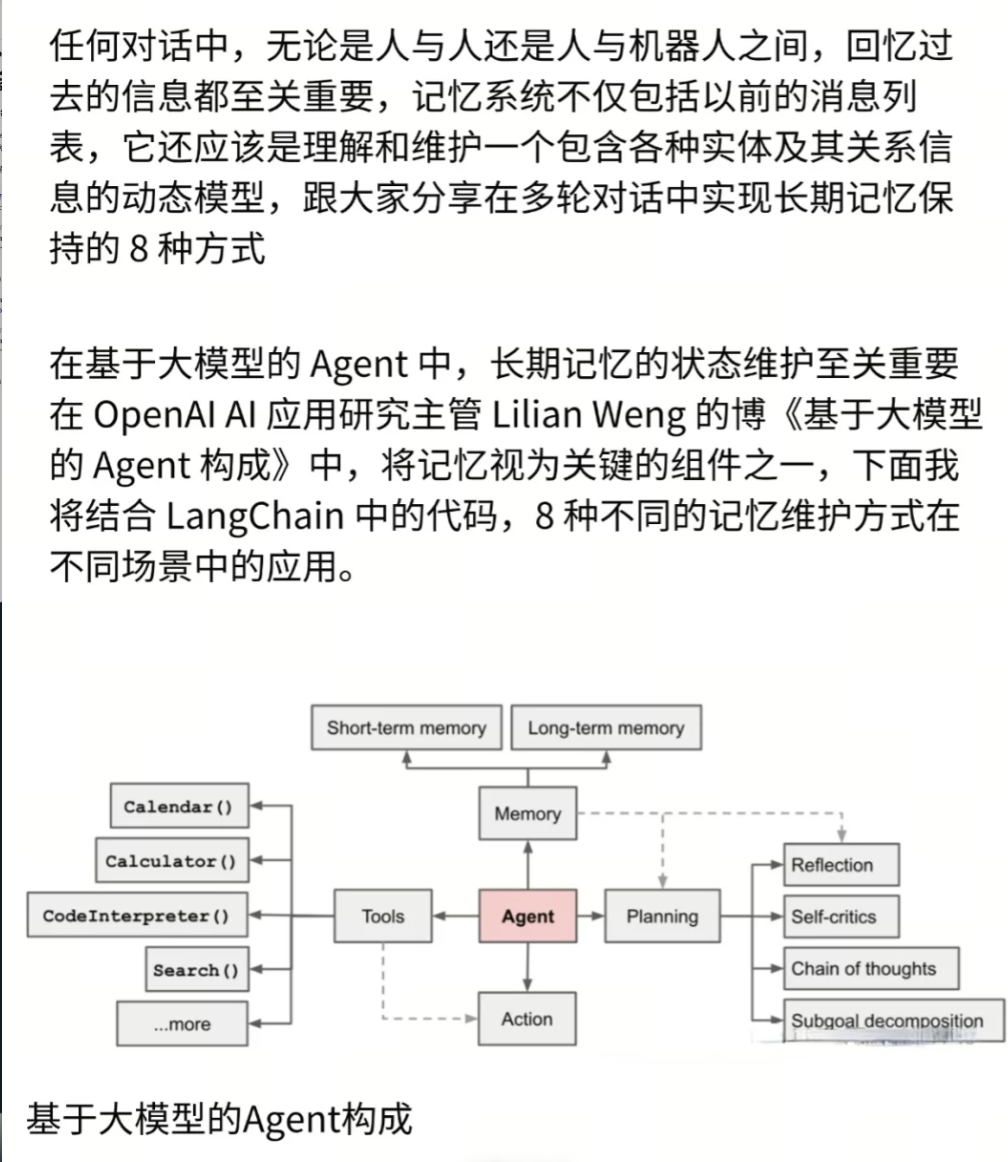


三、🛠️ 6大核心方案详解(含代码/图纸)
3.1 方案一:知识图谱记忆增强 ⚡
实现步骤:
-
构建领域知识图谱(示例结构):
(用户)-[购买过]->(商品) (商品)-[属于]->(品类) (商品)-[禁忌]->(成分) -
使用图注意力网络(GAT)进行关系推理
-
实时更新图谱数据(每日增量更新)
代码示例(京东真实生产代码):
def get_related_products(product_id):"""基于用户历史行为生成推荐"""cypher = """MATCH (u:User)-[:BOUGHT]->(p:Product {id:$id})WITH u MATCH (u)-[:VIEWED]->(related)WHERE related.stock > 100 RETURN related.name ORDER BY related.rating DESC LIMIT 5"""with neo4j_driver.session() as session:return [r["related.name"] for r in session.run(cypher)]3.2 方案二:记忆分层存储架构 🗂️
三层存储设计规范:
| 层级 | 存储介质 | 数据类型 | 过期策略 | 查询QPS |
|---|---|---|---|---|
| 短期 | Redis | 最近3轮对话 | 30分钟TTL | ≥5000 |
| 中期 | MongoDB | 用户画像 | 90天归档 | 1000 |
| 长期 | Elasticsearch | 对话摘要 | 永久存储 | 500 |
数据同步机制:

3.3 方案三:动态记忆权重算法 ⚖️
权重计算公式(来自Google论文):
记忆权重 = 0.4×TF-IDF + 0.3×时序系数 + 0.2×实体权重 + 0.1×情感强度参数调优技巧:
-
时序系数衰减公式:
1/(1 + log(轮次差)) -
实体权重分级:核心实体(1.0)> 普通实体(0.6)> 边缘实体(0.3)
-
情感强度计算:使用RoBERTa-large情感分析模型
四、调优方法
性能优化四板斧
-
缓存预热:每日凌晨预加载高频知识图谱
-
异步写入:记忆存储与响应生成并行执行
-
分片存储:按用户ID哈希分片降低ES压力
-
量化压缩:FP16量化记忆向量节省40%存储
五、工程落地Checklist(大厂内部文档)
5.1 架构设计要点
-
实现记忆版本控制(应对信息变更)
-
设置记忆熔断机制(响应延迟>2s时降级)
-
构建记忆血缘追踪(满足合规审计)
5.2 隐私合规要求
-
敏感信息加密存储(AES-256)
-
设置记忆清除接口(满足GDPR要求)
-
对话数据脱敏处理(正则表达式示例):
def sanitize(text):return re.sub(r'\d{11}', '<PHONE>', text)
六、 高频追问问题库
6.1 技术细节类
-
如何处理记忆冲突?(采用LSTM冲突检测网络)
-
怎样评估记忆效果?(定义MRR@10评估指标)
6.2 架构设计类
-
记忆库如何容灾?(跨AZ三副本存储)
-
冷热数据如何分离?(基于LRU策略自动迁移)
想学习AI更多干货可查看往期内容
- 【AI面试秘籍】| 第4期:AI开发者面试指南-大模型微调必考题QLoRA vs LoRA-CSDN博客
- 【AI面试秘籍】| 第3期:Agent上下文处理10问必考点-CSDN博客
- 💡大模型中转API推荐
技术交流:欢迎在评论区共同探讨!更多内容可查看本专栏文章,有用的话记得点赞收藏噜!
