ElasticSearch父子关系数据建模
nested object的建模,有个不好的地方,就是采取的是类似冗余数据的方式,将多个数据
都放在一起了,维护成本就比较高
每次更新,需要重新索引整个对象(包括跟对象和嵌套对象)
ES 提供了类似关系型数据库中 Join 的实现。使用 Join 数据类型实现,可以通过
Parent / Child 的关系,从而分离两个对象
父文档和子文档是两个独立的文档
更新父文档无需重新索引整个子文档。子文档被新增,更改和删除也不会影响到父文档和
其他子文档。
要点:父子关系元数据映射,用于确保查询时候的高性能,但是有一个限制,就是父子数
据必须存在于一个shard中
父子关系数据存在一个shard中,而且还有映射其关联关系的元数据,那么搜索父子关系数
据的时候,不用跨分片,一个分片本地自己就搞定了,性能当然高
父子关系
定义父子关系的几个步骤
- 设置索引的 Mapping
- 索引父文档
- 索引子文档
- 按需查询文档
设置 Mapping
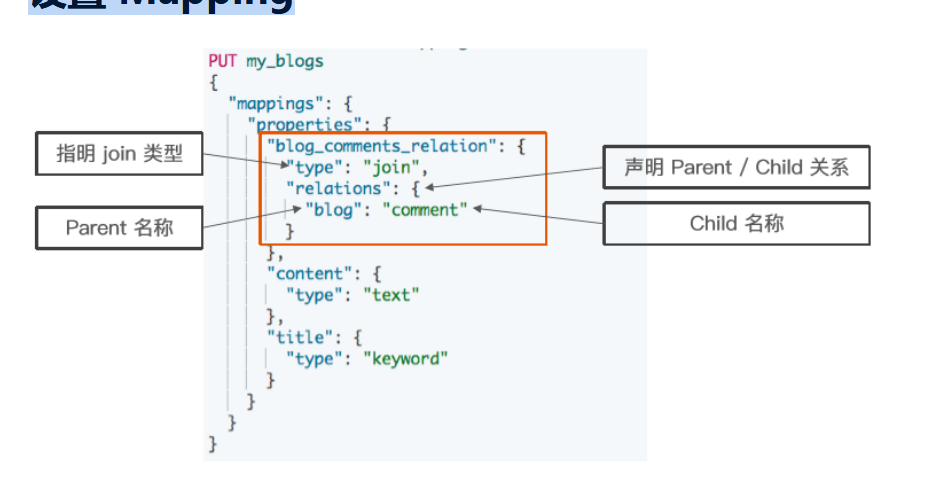
1 DELETE my_blogs
2 # 设定 Parent/Child Mapping
3 PUT my_blogs
4 {
5
6 "mappings": {
7 "properties": {
8 "blog_comments_relation": {
9 "type": "join",
10 "relations": {
11 "blog": "comment"
12 }
13 },
14 "content": {
15 "type": "text"
16 },
17 "title": {
18 "type": "keyword"
19 }
20 }
21 }
22 }索引父文档
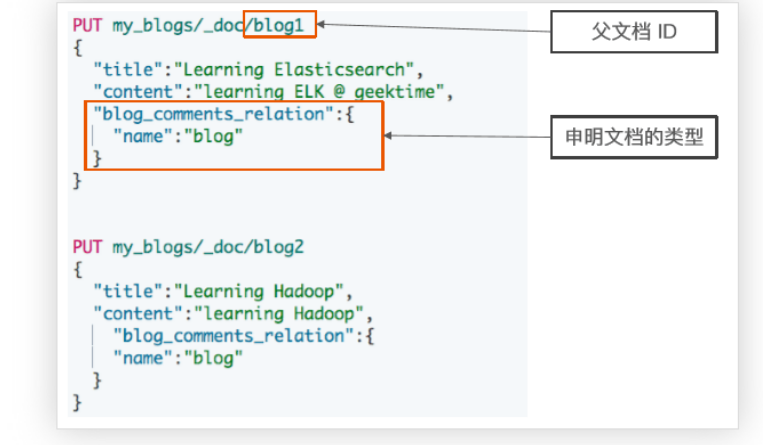
1 PUT my_blogs/_doc/blog1
2 {
3 "title":"Learning Elasticsearch",
4 "content":"learning ELK is happy",
5 "blog_comments_relation":{
6 "name":"blog"
7 }
8 }
9
10 PUT my_blogs/_doc/blog2
11 {
12 "title":"Learning Hadoop",
13 "content":"learning Hadoop",
14 "blog_comments_relation":{
15 "name":"blog"
16 }
17 }
索引子文档
父文档和子文档必须存在相同的分片上
确保查询 join 的性能
当指定文档时候,必须指定它的父文档 ID
使用 route 参数来保证,分配到相同的分片
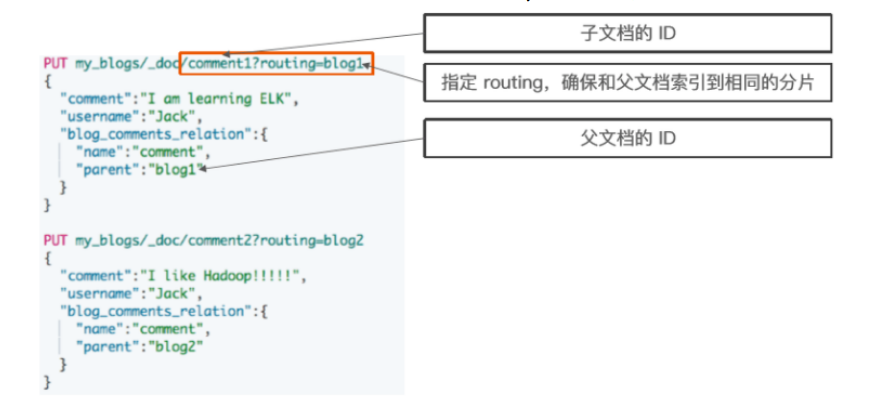
#索引子文档
1 PUT my_blogs/_doc/comment1?routing=blog1
2 {
3 "comment":"I am learning ELK",
4 "username":"Jack",
5 "blog_comments_relation":{
6 "name":"comment",
7 "parent":"blog1"
8 }
9 }
10
11 PUT my_blogs/_doc/comment2?routing=blog2
12 {
13 "comment":"I like Hadoop!!!!!",
14 "username":"Jack",
15 "blog_comments_relation":{
16 "name":"comment",
17 "parent":"blog2"
18 }
19 }
20
21 PUT my_blogs/_doc/comment3?routing=blog2
22 {
23 "comment":"Hello Hadoop",
24 "username":"Bob",
25 "blog_comments_relation":{
26 "name":"comment",
27 "parent":"blog2"
28 }
29 }
30Parent / Child 所支持的查询
- 查询所有文档
- Parent Id 查询
- Has Child 查询
- Has Parent 查询
# 查询所有文档
2 POST my_blogs/_search
3 {}
4
5 #根据父文档ID查看
6 GET my_blogs/_doc/blog2
7
8 # Parent Id 查询
9 POST my_blogs/_search
10 {
11 "query": {
12 "parent_id": {
13 "type": "comment",
14 "id": "blog2"
15 }
16 }
17 }
18
19 # Has Child 查询,返回父文档
20 POST my_blogs/_search
21 {
22 "query": {
23 "has_child": {
24 "type": "comment",
25 "query" : {
26 "match": {
27 "username" : "Jack"
28 }
29 }
30 }
31 }
32 }
33
34 # Has Parent 查询,返回相关的子文档
35 POST my_blogs/_search
36 {
37 "query": {
38 "has_parent": {
39 "parent_type": "blog",
40 "query" : {
41 "match": {
42 "title" : "Learning Hadoop"
43 }
44 }
45 }
46 }
47 }使用 has_child 查询
返回父文档
通过对子文档进行查询
返回具体相关子文档的父文档
父子文档在相同的分片上,因此 Join 效率高
使用 has_parent 查询
返回相关性的子文档
通过对父文档进行查询
返回相关的子文档
使用 parent_id 查询
回所有相关子文档
通过对付文档 Id 进行查询
返回所有相关的子文档
访问子文档
需指定父文档 routing 参数
1 #通过ID ,访问子文档
2 GET my_blogs/_doc/comment2
3 #通过ID和routing ,访问子文档
4 GET my_blogs/_doc/comment3?routing=blog2更新子文档
更新子文档不会影响到父文档
1 PUT my_blogs/_doc/comment3?routing=blog2
2 {
3 "comment": "Hello Hadoop??",
4 "blog_comments_relation": {
5 "name": "comment",
6 "parent": "blog2"
7 }
8 }嵌套对象 v.s 父子文档
Nested Object Parent / Child
优点:文档存储在一起,读取性能高、父子文档可以独立更新
缺点:更新嵌套的子文档时,需要更新整个文档、需要额外的内存去维护关系。读取性能
相对差
适用场景子文档偶尔更新,以查询为主、子文档更新频繁
文件系统数据建模
思考一下,github中可以使用代码片段来实现数据搜索。这是如何实现的?
在github中也使用了ES来实现数据的全文搜索。其ES中有一个记录代码内容的索引,大致
数据内容如下:
1 {
2 "fileName" : "HelloWorld.java",
3 "authName" : "baiqi",
4 "authID" : 110,
5 "productName" : "first‐java",
6 "path" : "/com/baiqi/first",
7 "content" : "package com.baiqi.first; public class HelloWorld { //code... }"
8 }我们可以在github中通过代码的片段来实现数据的搜索。也可以使用其他条件实现数据搜
索。但是,如果需要使用文件路径搜索内容应该如何实现?这个时候需要为其中的字段
path定义一个特殊的分词器。具体如下:
1 PUT /codes
2 {
3 "settings": {
4 "analysis": {
5 "analyzer": {
6 "path_analyzer" : {
7 "tokenizer" : "path_hierarchy"
8 }
9 }
10 }
11 },
12 "mappings": {
13 "properties": {
14 "fileName" : {
15 "type" : "keyword"
16 },
17 "authName" : {
18 "type" : "text",
19 "analyzer": "standard",
20 "fields": {
21 "keyword" : {
22 "type" : "keyword"
23 }
24 }
25 },
26 "authID" : {
27 "type" : "long"
28 },
29 "productName" : {
30 "type" : "text",
31 "analyzer": "standard",
32 "fields": {
33 "keyword" : {
34 "type" : "keyword"
35 }
36 }
37 },
38 "path" : {
39 "type" : "text",
40 "analyzer": "path_analyzer",
41 "fields": {
42 "keyword" : {
43 "type" : "keyword"
44 }
45 }
46 },
47 "content" : {
48 "type" : "text",
49 "analyzer": "standard"
50 }
51 }
52 }
53 }
54
55 PUT /codes/_doc/1
56 {
57 "fileName" : "HelloWorld.java",
58 "authName" : "baiqi",
59 "authID" : 110,
60 "productName" : "first‐java",
61 "path" : "/com/baiqi/first",
62 "content" : "package com.baiqi.first; public class HelloWorld { // some code... }"
63 }
64
65 GET /codes/_search
66 {
67 "query": {
68 "match": {
69 "path": "/com"
70 }
71 }
72 }
73
74 GET /codes/_analyze
75 {
76 "text": "/a/b/c/d",
77 "field": "path"
78 }
79
80 ###################################################################################
#########################
81 PUT /codes
82 {
83 "settings": {
84 "analysis": {
85 "analyzer": {
86 "path_analyzer" : {
87 "tokenizer" : "path_hierarchy"
88 }
89 }
90 }
91 },
92 "mappings": {
93 "properties": {
94 "fileName" : {
95 "type" : "keyword"
96 },
97 "authName" : {
98 "type" : "text",
99 "analyzer": "standard",
100 "fields": {
101 "keyword" : {
102 "type" : "keyword"
103 }
104 }
105 },
106 "authID" : {
107 "type" : "long"
108 },
109 "productName" : {
110 "type" : "text",
111 "analyzer": "standard",
112 "fields": {
113 "keyword" : {
114 "type" : "keyword"
115 }
116 }
117 },
118 "path" : {
119 "type" : "text",
120 "analyzer": "path_analyzer",
121 "fields": {
122 "keyword" : {
123 "type" : "text",
124 "analyzer": "standard"
125 }
126 }
127 },
128 "content" : {
129 "type" : "text",
130 "analyzer": "standard"
131 }
132 }
133 }
134 }
135
136 GET /codes/_search
137 {
138 "query": {
139 "match": {
140 "path.keyword": "/com"
141 }
142 }
143 }
144
145 GET /codes/_search
146 {
147 "query": {
148 "bool": {
149 "should": [
150 {
151 "match": {
152 "path": "/com"
153 }
154 },
155 {
156 "match": {
157 "path.keyword": "/com/baiqi"
158 }
159 }
160 ]
161 }
162 }
163 }