FedTracker:为联邦学习模型提供所有权验证和可追溯性
一、文献背景与作者信息
本文所介绍的研究成果来自论文《FedTracker: Federated Learning Ownership Verification and Traceability via Multi-Grained Fingerprinting》,发表于TDSC。该论文聚焦于联邦学习(Federated Learning, FL)中的知识产权保护问题,提出了一种新颖的框架“FedTracker”,用于实现联邦学习模型的所有权验证与数据源可追溯性。
随着AI模型训练成本的持续上升和数据隐私保护法规的日益严格,如何在保护数据隐私的前提下,确保模型开发者的权益(如模型所有权)并能追踪潜在的数据泄露来源,成为了学术界和工业界亟需解决的核心问题。FedTracker正是在此背景下提出的创新工作。
二、研究动机
1. 联邦学习的兴起与挑战
联邦学习是一种分布式机器学习技术,各参与方(如企业或设备)在不共享原始数据的前提下,共同训练一个全局模型。这种方法有效解决了数据隐私与所有权问题。然而,联邦学习系统也面临以下挑战:
-
知识产权保护难:本地模型贡献不可见,导致难以确权;
-
数据源可追溯性弱:一旦模型被非法泄露或误用,缺乏机制确定责任方;
-
多种攻击威胁存在:如模型窃取、水印移除、模型逆向等。
因此,亟需设计一种既能验证模型归属、又可追溯训练来源的新方法。
三、FedTracker框架设计与工作原理
FedTracker是一个联邦水印框架(federated watermarking framework),旨在通过**多粒度指纹(multi-granular fingerprinting)**实现模型所有权验证(Ownership Verification, OV)与可追溯性(Traceability, TC)两大核心目标。
1. 总体结构
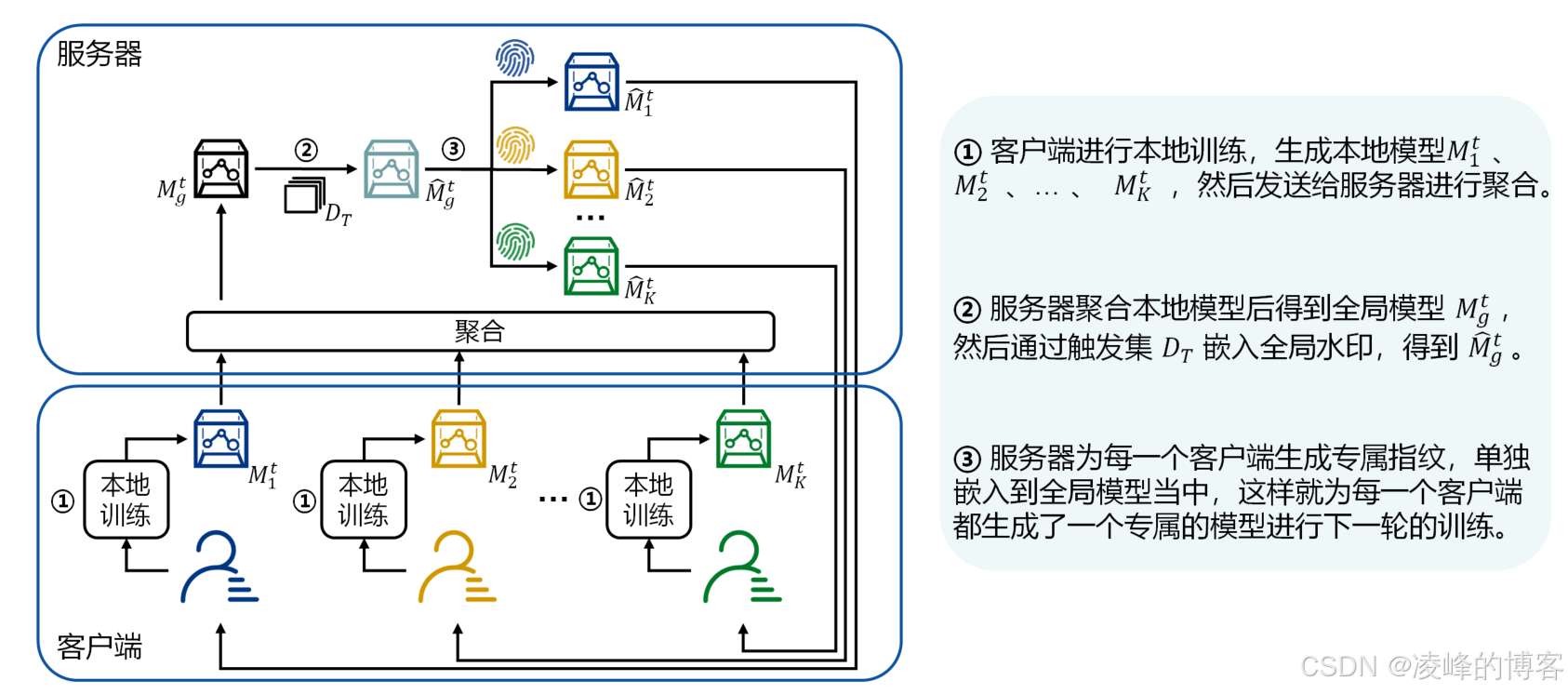
FedTracker的结构如图所示,主要由以下四个模块组成:
-
Global Identifier Embedding(全局身份嵌入):实现模型级水印用于所有权验证;
-
Local Fingerprint Embedding(本地指纹嵌入):实现客户端级的细粒度标识,用于追溯性;
-
Federated Training Process(联邦训练过程):以标准联邦学习流程为基础,整合嵌入机制;
-
Verification & Tracing(验证与追踪):在需要时,提取嵌入的身份信息,实现验证与溯源。
2. 两种指纹机制详解
a. 全局身份(Global Identity)
-
目标:为整个联邦学习模型打上唯一水印,用于模型归属验证。
-
技术手段:将身份信息(如项目ID)以特定方式嵌入训练样本,使得训练出的模型在面对特定触发集(trigger set)时呈现独特的输出分布,从而可用于所有权验证。

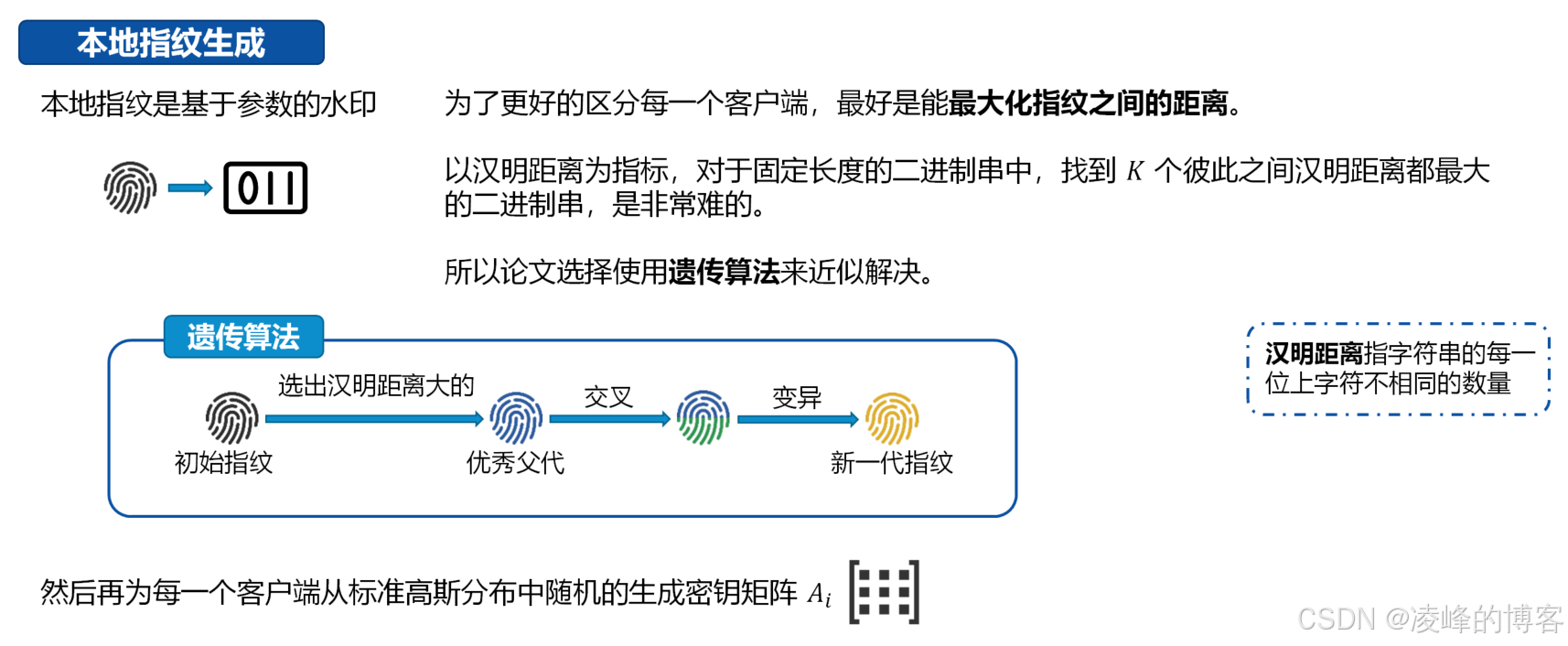
b. 本地指纹(Local Fingerprint)
-
目标:为每个参与方(客户端)打上独特标识,实现数据源追溯。
-
技术手段:对每个客户端的训练数据嵌入不同的指纹信息,最终使得模型包含多种客户端级别的差异性,便于后续溯源。

四、安全性与鲁棒性分析
FedTracker具备如下安全性能:
-
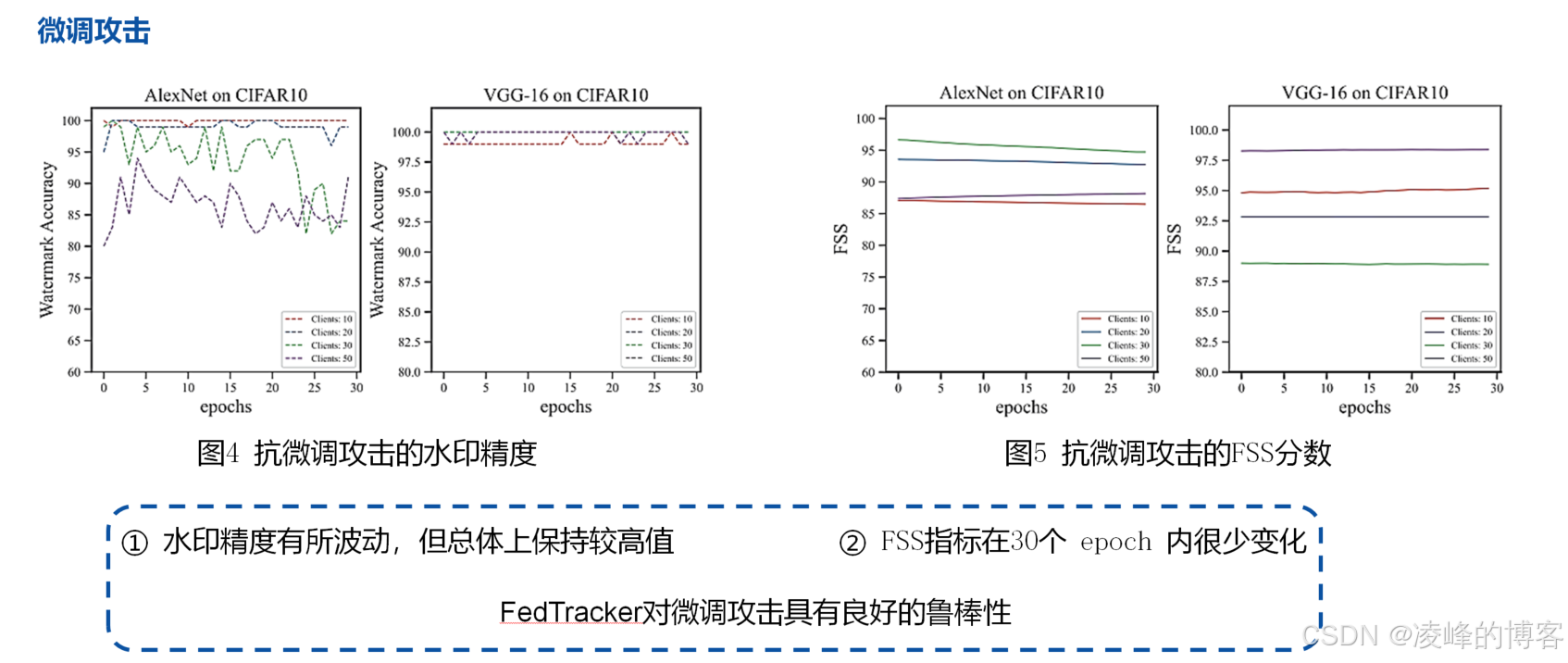
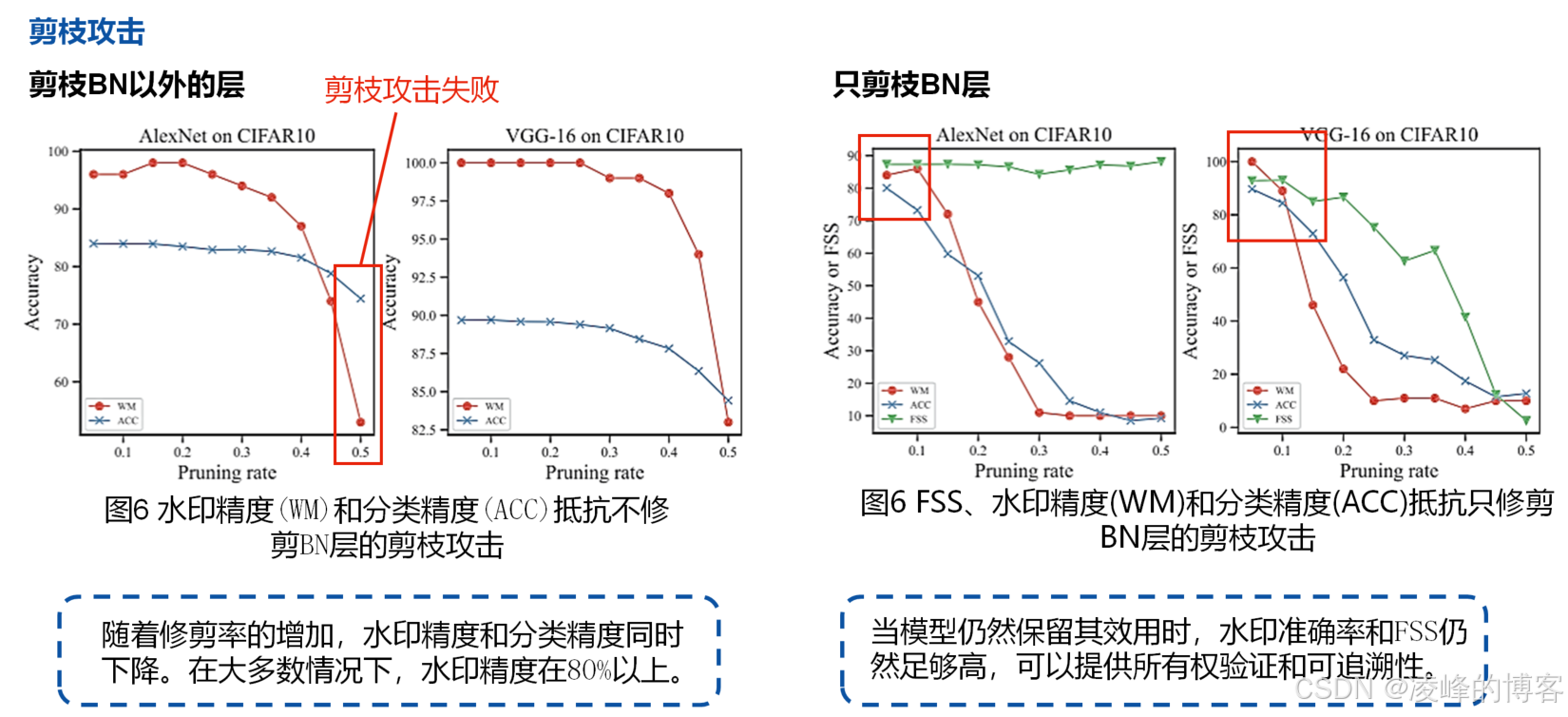
鲁棒性(Robustness):嵌入的信息在常见扰动(如压缩、裁剪、微调)下仍能有效提取;
-
防攻击能力:抵抗白盒攻击、水印移除、逆向工程等威胁;
-
低影响性:对原始模型性能影响极小(实验证明影响 <1%)。
此外,FedTracker支持模型黑盒访问情况下的验证方式,提升其实用性和部署灵活性。
五、实验结果与应用效果
论文在多个数据集(如CIFAR-10、Fashion-MNIST)和模型架构(如ResNet、LeNet)上验证了FedTracker的有效性。主要实验指标如下:
-
嵌入成功率:> 95%
-
提取准确率:OV和TC准确率均达到90%以上
-
模型性能下降:平均下降 < 0.5%,基本可忽略
此外,论文还验证了FedTracker在不同攻击场景(如模型压缩、精度剪枝、触发集变异等)下的鲁棒性。
六、总结与展望
FedTracker为联邦学习模型的知识产权保护与数据溯源问题提供了一个可行且高效的解决方案,其主要贡献如下:
-
首次将多粒度指纹机制引入联邦学习场景;
-
构建了兼容现有FL流程的水印嵌入与验证系统;
-
提供了理论与实验层面的双重保障,适应多种真实部署环境。
未来展望方面,FedTracker仍可进一步扩展到:
-
更复杂的多任务学习场景;
-
跨设备的异构数据分布;
-
法律法规适配与可解释性增强等方面。