利用比较预言机处理模糊的偏好数据
论文标题
ComPO:Preference Alignment via Comparison Oracles
论文地址
https://arxiv.org/pdf/2505.05465
模型地址
https://huggingface.co/ComparisonPO
作者背景
哥伦比亚大学,纽约大学,达摩院
动机
DPO算法直接利用标注好的数据来做偏好对齐,无需进行显式的奖励模型训练。然而偏好数据往往是带噪声的,因为很多情况下“偏好”是主观的,不同的标注者可能会对同一个case做出截然相反的判断;此外实践中也可能会使用诸如点击率、好评率等反馈信息作为衡量好坏的依据,同样造成了部分偏好数据的模糊性;
有研究表明,当偏好数据中的好坏示例模棱两可时,模型难以学习正确偏好,甚至可能发生负优化,具体表现为:
- 冗长啰嗦:模型试图面面俱到以确保不犯错。
- 似然分布偏移:原本受偏好的回答概率下降,而原本不被偏好的回答概率上升
于是作者希望对DPO方法进行优化,提高模糊数据的应对能力
本文方法
本文提出“比较预言机偏好优化”(Comparison Oracle Preference Optimization),专门处理标签不够可靠的模糊样本
一、比较预言机
在经典计算理论和优化算法领域,“Oracle(预言机)”一般泛指抽象的黑盒系统,通常具备以下特点:
- 能够解答特定类型的问题,无需说明具体过程或细节。
- 可以快速、高效地给出问题的答案,帮助算法做出决策。
- Oracle的实际实现方式不固定,可能是人工决策、专家系统、或某个已知的有效算法
“比较预言机”简单来说就是一个用于比较两种回答好坏的黑盒系统,它接受一对模型回答作为输入,然后反馈哪个输入更好。在本文中作者通过调用GPT-4来实现预言机
二、零阶优化算法
在数学中:
- 一阶信息指的是梯度(偏导数)。
- 二阶信息指的是Hessian矩阵(即二阶导数)。
- 零阶信息指的是函数值本身。
所以“零阶优化”就是只用函数值来进行优化的方法,它常用于目标函数不可导(比如黑盒目标)或计算代价过高的场景(比如强化学习)
零阶优化有多种具体实现方式,本文采用了“有限差分法”,通过添加微小扰动确定优化方向
∂ f ∂ x i ≈ f ( x + δ e i ) − f ( x ) δ \frac{\partial f}{\partial x_i} \approx \frac{f(x + \delta e_i) - f(x)}{\delta} ∂xi∂f≈δf(x+δei)−f(x)
ComPO在训练时会对当前模型参数施加多次小幅随机扰动,通过预言机比较扰动前后模型对同一偏好对,判断哪些方向让模型更对齐人类偏好,然后据此更新参数。这个过程类似于黑箱函数的梯度估计:不断尝试参数变化并比较结果好坏,从而近似估计偏好目标的梯度方向。作者证明了,在一定光滑性和梯度稀疏性假设下,该迭代方案收敛到偏好目标的极值点是有保证的
三、性能优化
直接按上述方案优化一个数十亿参数的LLM并不现实,作者为此引入了一系列工程技巧来降低计算开销、提高训练稳定性:
- 限制优化范围: 算法仅对模型输出层权重进行随机扰动和更新,而非调整全量参数
- 梯度归一化与裁剪: 在根据多次随机试探得到偏好提升方向后,算法对估计的更新向量进行归一化处理,并只保留大于某阈值的方向信号,这样能使更新是保持稀疏性、包含主要信号,有助于稳定训练过程,避免因为噪声扰动导致模型参数无谓抖动。
- 自适应步长与跳过策略: 算法动态调整每轮参数更新幅度:如果多次扰动中有相当比例的方向都被预言机判定为改进偏好,则使用较大学习步长更新;反之如果有效信号很少则跳过该轮更新,从而确保面对噪声的鲁棒性与收敛过程的稳定性
四、两阶段训练流程
考虑到并非所有偏好数据都难以学习,作者将ComPO与现有DPO方法结合,对不同难度的数据分阶段训练。具体步骤如下:
-
偏好数据拆分: 首先用一个参考模型对偏好数据进行评估,将数据划分为“清洁”和“有噪”两部分。划分标准是看参考模型对于每个偏好对的判断是否信心足够:如果模型对偏好对中优胜回答的预测概率明显高于劣回答(对数概率差超过阈值),则认为该偏好对是清晰明确的;反之则记为有噪的
-
清洁样本对齐: 对划分出的清洁偏好对,采用DPO进行训练,得到一个初步对齐的模型(记为DPO_clean)
-
噪声样本微调: 在第2步基础上,应用ComPO专门微调有噪声的偏好对
实验效果
测试基准:AlpacaEval 2、MT-Bench、Arena-Hard
评测方法:GPT-4 as judge,比较被测模型与参考答案哪一个更优
评测指标:胜率(WR)、长度控制胜率(LC,对输出长度归一化后再衡量模型质量,以避免模型通过啰嗦取胜)
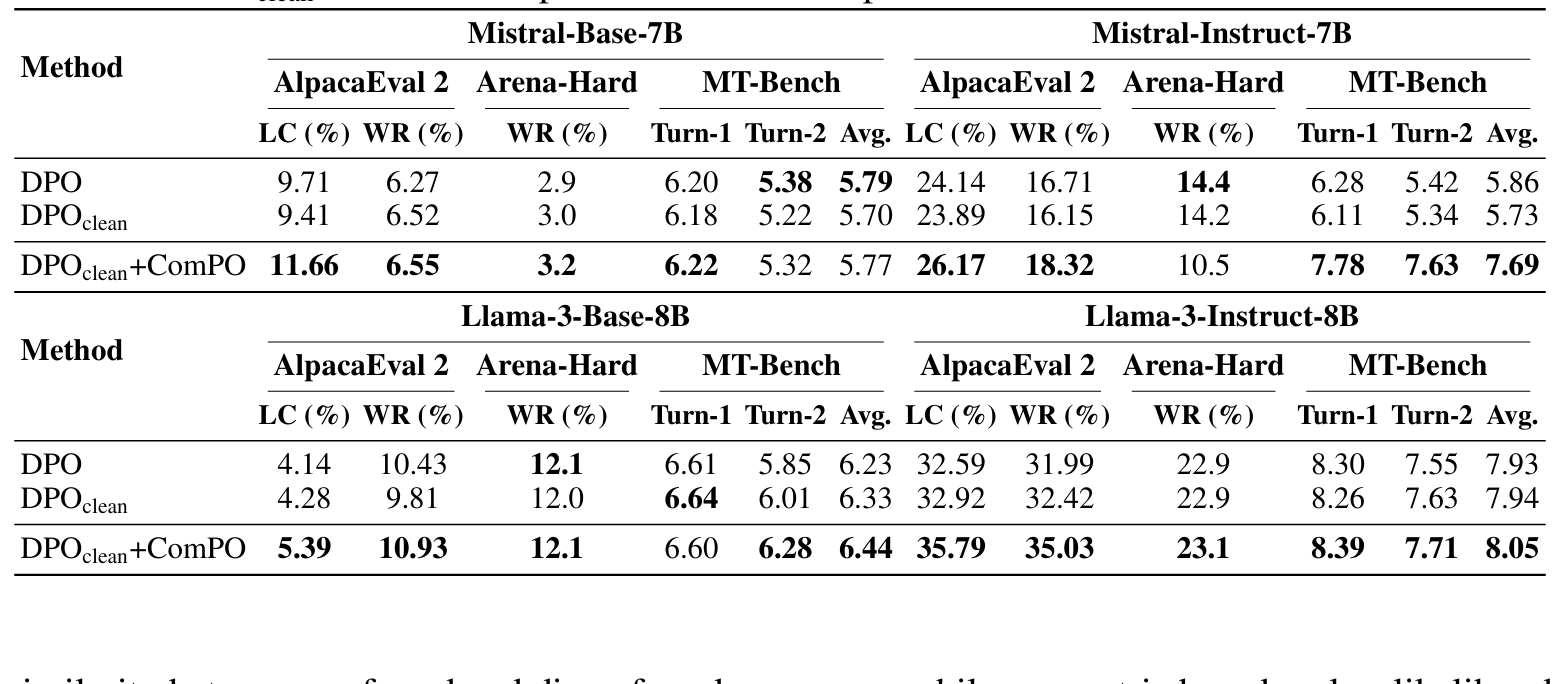
实验结论:
- 整体性能提升: 在多个模型和评测基准上,加入ComPO的模型明显优于仅用原有直接对齐方法的模型
- 缓解冗长倾向: 应用ComPO后模型输出的Length-Controlled胜率显著提高,这表明模型不再为讨好评分而啰嗦作答
- 减轻似然偏移问题: 通过对比训练前后的模型输出概率分布,作者发现ComPO能够显著降低不被偏好回答的生成概率,同时提升被偏好回答的概率。这与之前直接优化方法中报告的反常情况形成鲜明对比,表明ComPO在很大程度上消除了有噪声样本导致的概率质量错位现象。
- 效率与开销: 得益于输出层微调和梯度截断等设计,ComPO方法在实际算力下是可行的。作者报告他们在30张NVIDIA A40 GPU上对9B规模模型运行ComPO算法,每轮采用约1600~1800次随机扰动采样即可取得收敛效果。此外作者还发现,如果仅使用100条噪声偏好数据运行ComPO也能观察到模型性能的提升,这表明哪怕很少量的棘手偏好反馈,经过精细对齐也足以带来显著收益