处理均值的配对比较
本文是实验设计与分析(第6版,Montgomery著傅珏生译)第3章单因子实验 方差分析第3.5节的python解决方案。本文尽量避免重复书中的理论,着于提供python解决方案,并与原书的运算结果进行对比。您可以从 ![]() 下载实验设计与分析(第6版,Montgomery著傅珏生译)电子版。本文假定您已具备python基础,如果您还没有python的基础,可以从
下载实验设计与分析(第6版,Montgomery著傅珏生译)电子版。本文假定您已具备python基础,如果您还没有python的基础,可以从![]() 下载相关资料进行学习。
下载相关资料进行学习。
在完成实验、统计分析以及研究假设后,实验者将准备针对正研究的问题作出结论。通常这是相对容易的,迄今为止,我们所考虑的简单实验中,也许通过非规范的方法就可以得出结论,诸如图3.1和图3.2中的盒图和散点图的图示检查。但是,在某些情形下,需要应用更多的规范技术。我们将在本节中部分介绍这些技术。
3.5.1回归模型(略,见原书)
3.5.2处理均值的比较(略,见原书)
3.5.3均值的图解比较法(略,见原书)
3.5.4对照法
3.5.5正交对照法
3.5.6用来比较全部对照的Scheffé方法(略,见原书)
3.5.7处理均值的配对比较法
许多实际情况中,我们希望只比较配对均值。我们常常通过检验所有配对处理均值间的差异来决定哪些均值不同。因此,我们感兴趣的是形如Г=μi-μj(对于一切i≠j)的对照。尽管前面介绍的Schffé方法很容易解决这样的问题,但它不是对这类比较最灵敏的方法。我们现在转而考虑特别构造的用于所有α个总体均值之间的配对比较的方法。
假定我们想要比较所有个处理均值的配对,那么,想要检验的零假设就是H0: μi =μj(对于一切i≠j)。有大量的解决这类问题的方法。现给出用于这类比较的两种普遍方法。
1.Tukey检验
假定在方差分析F检验法下拒绝了等处理均值的零假设后,我们要对一切i≠j检验所有配对均值比较
H0: μi =μj , H1: μi ≠μj
Tukey(1953)提出了使得当样本容量相等时总的显著性水平等于a、样本容量不等时显著性水平至多是α的假设检验方法。他的方法也可以用于所有配对均值比较的置信区间。对于这些区间,样本量相等时,联合置信水平为100(1一α)%;而样本量不等时,联合置信水平至少为100(1一a)%。换句话说,Tukey方法将实验总体错误率即“族”错误率控制在选定的水平a上。当着眼于配对均值时,这是一个很好的数据探究方法。
当样本容量相等时,如果样本均值差的绝对值超过

Tukey检验就表明两个均值有显著性差异。等价地,我们可以构建一系列关于所有配对均值的100(1-a)%的置信区间如下:
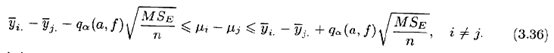
当样本容量不等时,(3.35)式和(3.36)式分别变为
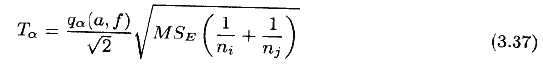
和
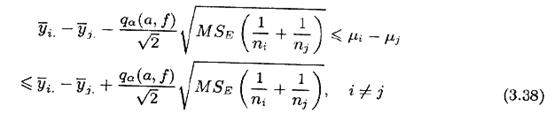
样本量不等的方法有时也称为Tukey-Kramer法。
例3.7 为了说明Tukey检验,我们利用例3.1中的晶片蚀刻实验的数据。当a=0.05,映差的目由度f=16时,由附表VII查得q0.05(4,16)=4.05,因此,由(3.35)式
![]()
所以,当任意一对处理均值差异的绝对值超过33.09时,这表示相应的配对总体有显著性差异。4个处理均值是
![]()
且均值的差异为
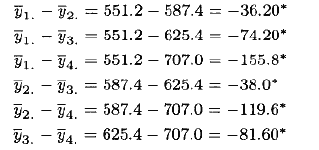
标有星号的值表示那对均值有显著性差异。注意到Tukey方法表明所有配对均值都有显著差异。即,由每种功率设置得到的蚀刻率均值和由其他任一个功率设置得到的蚀刻率均值都有差异。
当使用均值配对检验的任一方法时,我们有时会发现,虽然方差分折中的总F统计量表明了某种显著性,但均值的配对比较却找不到任一对有显著差异。这种情况之所以会出现,是因为F检验法同时考虑了处理均值之间的所有可能的比较,而不仅仅是配对比较。即,在所掌握的数据中,有显著性的对照不一定以μi-μj的形式出现。
# 将以下数据保存为anovaoneway.txt
A B C D
575 565 600 725
542 593 651 700
530 590 610 715
539 579 637 685
570 610 629 710
from statsmodels.stats.multicomp import pairwise_tukeyhsd,MultiComparison
import numpy as np
from scipy import stats
import pandas as pd
d = pd.read_csv("anovatwoway.txt", sep="\t")
multiComp = MultiComparison(d['value'], d['Genotype'])
tukey=multiComp.tukeyhsd()
summary=multiComp.tukeyhsd().summary()
print(summary)
q=tukey.q_crit
print("q values:",q)
>>> print(summary)
Multiple Comparison of Means - Tukey HSD, FWER=0.05
======================================================
group1 group2 meandiff p-adj lower upper reject
------------------------------------------------------
A B 36.2 0.0294 3.1456 69.2544 True
A C 74.2 0.0 41.1456 107.2544 True
A D 155.8 0.0 122.7456 188.8544 True
B C 38.0 0.0216 4.9456 71.0544 True
B D 119.6 0.0 86.5456 152.6544 True
C D 81.6 0.0 48.5456 114.6544 True
------------------------------------------------------
>>> q=tukey.q_crit
>>> print("q values:",q)
q values: 4.046093060626182
2.Fisher最小显著性差异(LSD)法
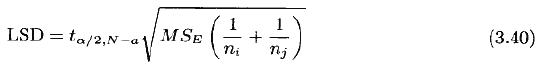
称为最小显著性差异(least significant difference)。
例3.8 为解释这一方法,我们采用例3.1的数据。当a=0.05时,LSD是
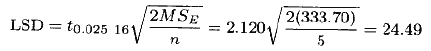
这样一来,任一对处理均值的差的绝对值大于24.49时,就表示对应的一对总体均值有显著性差异。均值的差是
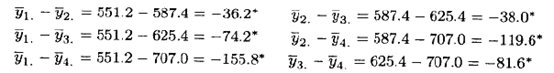
标有星号的值表示那对均值有显著差异。显然,所有的配对比较都有显著差异。
import scipy,mathfrom scipy.stats import fimport numpy as npimport matplotlib.pyplot as pltimport scipy.stats as stats# additional packagesfrom statsmodels.stats.diagnostic import lillifors#多重比较from statsmodels.sandbox.stats.multicomp import multipletests#用于排列组合import itertoolsgroup1=[2,3,7,2,6]group2=[10,8,7,5,10]group3=[10,13,14,13,15]list_groups=[group1,group2,group3]list_total=group1+group2+group3a=0.05#one within group error,also know as random errordef SE(group):se=0mean1=np.mean(group)for i in group:error=i-mean1se+=error**2return se
'''>>> SE(group1)22.0>>> SE(group2)18.0>>> SE(group3)14.0'''
#sum of squares within group error,also know as random errordef SSE(list_groups):sse=0for group in list_groups:se=SE(group)sse+=sereturn sse#误差总平方和def SST(list_total):sst=0mean1=np.mean(list_total)for i in list_total:error=i-mean1sst+=error**2return sst#SSA,between-group sum of squares 组间平方和,公式1:ssa=sst-ssedef SSA(list_groups,list_total):sse=SSE(list_groups)sst=SST(list_total)ssa=sst-ssereturn ssa#SSA,between-group sum of squares组间平方和
def SSA1(list_groups,list_total):mean_total=np.mean(list_total)ssa=0for group in list_groups:group_mean=np.mean(group)distance=(mean_total-group_mean)**2ssa+=distancessa=ssa*5return ssa#处理效应均方def MSA(list_groups,list_total):ssa=SSA(list_groups,list_total)msa=ssa/(len(list_groups)-1)*1.0return msa# 误差均方def MSE(list_groups,list_total):sse=SSE(list_groups)mse=sse/(len(list_total)-1*len(list_groups))*1.0return mse#F scoredef F(list_groups,list_total):msa=MSA(list_groups,list_total)mse=MSE(list_groups,list_total)ratio=msa/mse*1.0return ratio'''>>> F(list_groups,list_total)22.592592592592595'''#LSD(least significant difference)最小显著差异def LSD(list_groups,list_total,sample1,sample2):mean1=np.mean(sample1)mean2=np.mean(sample2)distance=abs(mean1-mean2)print"distance:",distance#t检验的自由度df=len(list_total)-1*len(list_groups)mse=MSE(list_groups,list_total)print"MSE:",mset_value=stats.t(df).isf(a/2)print"t value:",t_valuelsd=t_value*math.sqrt(mse*(1.0/len(sample1)+1.0/len(sample2)))print "LSD:",lsdif distance<lsd:print"no significant difference between:",sample1,sample2else:print"there is significant difference between:",sample1,sample2#正态分布测试def check_normality(testData): #20<样本数<50用normal test算法检验正态分布性 if 20<len(testData) <50: p_value= stats.normaltest(testData)[1] if p_value<0.05: print"use normaltest" print "data are not normal distributed" return False else: print"use normaltest" print "data are normal distributed" return True
#样本数小于50用Shapiro-Wilk算法检验正态分布性 if len(testData) <50:p_value= stats.shapiro(testData)[1]if p_value<0.05:print "use shapiro:"print "data are not normal distributed"return Falseelse:print "use shapiro:"print "data are normal distributed"return True
if 300>=len(testData) >=50:p_value= lillifors(testData)[1]if p_value<0.05:print "use lillifors:"print "data are not normal distributed"return Falseelse:print "use lillifors:"print "data are normal distributed"return Trueif len(testData) >300:p_value= stats.kstest(testData,'norm')[1]if p_value<0.05:print "use kstest:"print "data are not normal distributed"return Falseelse:print "use kstest:"print "data are normal distributed"return True
#对所有样本组进行正态性检验def NormalTest(list_groups):for group in list_groups:#正态性检验status=check_normality(group)if status==False :return False
#排列组合函数def Combination(list_groups):combination= []for i in range(1,len(list_groups)+1):iter = itertools.combinations(list_groups,i)combination.append(list(iter))#需要排除第一个和最后一个return combination[1:-1][0]
'''Out[57]:[[([2, 3, 7, 2, 6], [10, 8, 7, 5, 10]),([2, 3, 7, 2, 6], [10, 13, 14, 13, 15]),([10, 8, 7, 5, 10], [10, 13, 14, 13, 15])]]'''#多重比较def Multiple_test(list_groups):print"multiple test----------------------------------------------"combination=Combination(list_groups)for pair in combination:LSD(list_groups,list_total,pair[0],pair[1])#对所有样本组进行正态性检验print"M=Normality test:-----------------------------------"NormalTest(list_groups)#方差齐性检测scipy.stats.levene(group1,group2,group3)'''H0成立,三组数据方差无显著差异Out[9]: LeveneResult(statistic=0.24561403508771934, pvalue=0.7860617221429711)'''print "result--------------------------------------------------"f_score=F(list_groups,list_total)print"F score:",f_score#sf为生存函数survival functionprobability=f.sf(f_score,2,12)
'''Out[28]: 8.5385924542746692e-05'''if probability<0.05:print"there is significance,H1 win"#多重比较print"Multiple test",Multiple_testMultiple_test(list_groups)