A Survey of Learning from Rewards:从训练到应用的全面剖析
A Survey of Learning from Rewards:从训练到应用的全面剖析
你知道大语言模型(LLMs)如何通过奖励学习变得更智能吗?这篇论文将带你深入探索。从克服预训练局限的新范式,到训练、推理各阶段的策略,再到广泛的应用领域,全方位展现LLMs奖励学习的奥秘,快来一探究竟吧!
📄 论文标题:Sailing AI by the Stars: A Survey of Learning from Rewards in Post-Training and Test-Time Scaling of Large Language Models
🌐 来源:arXiv:2505.02686 [cs.CL] + 链接:https://www.arxiv.org/abs/2505.02686
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
近年来,大语言模型(LLMs)发展迅速,从最初依赖预训练扩展,逐渐转向后训练和测试时扩展。在这一转变过程中,“从奖励中学习”成为关键范式,它如同夜空中的星星,指引着LLMs的行为。
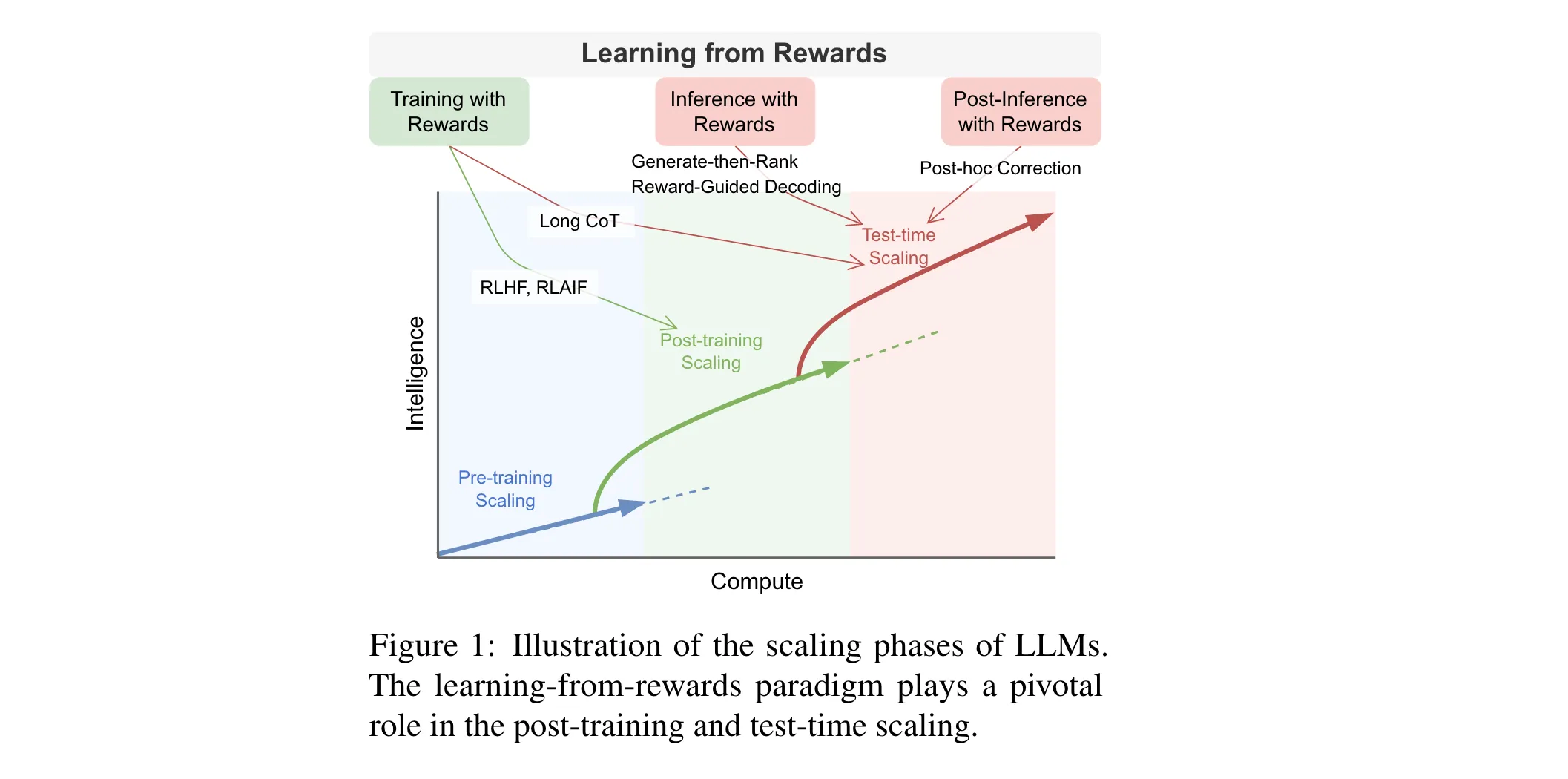
1. 从奖励中学习的分类框架
为了更好地理解“从奖励中学习”,论文构建了统一概念框架。语言模型根据输入生成输出,奖励模型评估输出质量并给出奖励信号,学习策略则利用这些信号调整语言模型或输出。基于此框架,从奖励来源、奖励模型设计、学习阶段和学习方式四个维度对现有方法进行分类。
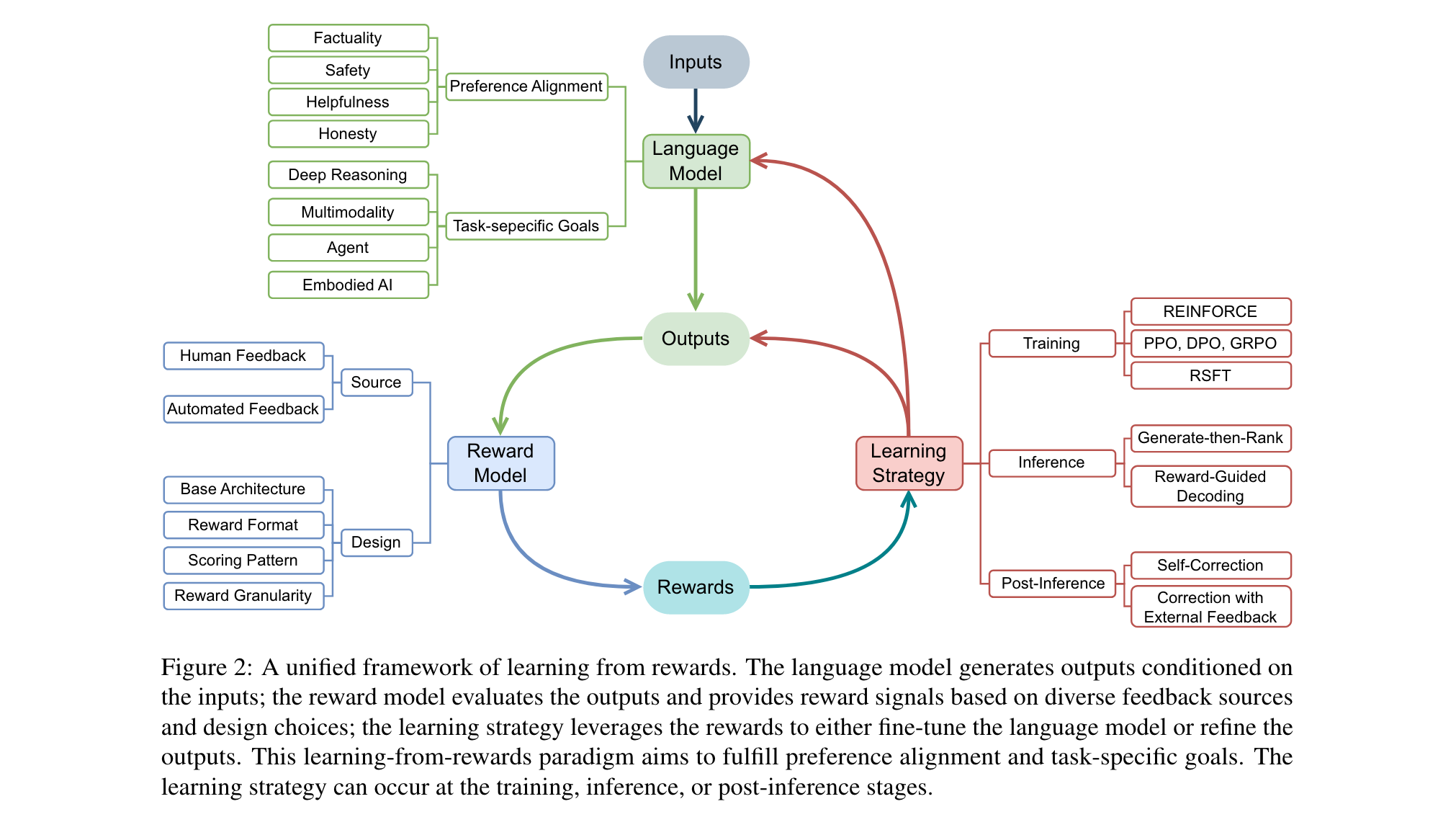
1. 奖励来源:主要有人类反馈和自动反馈。人类反馈基于人类判断,质量高但资源消耗大;自动反馈包括自我奖励、训练模型、预定义规则、知识和工具等,可扩展性强,但在可解释性等方面存在局限。
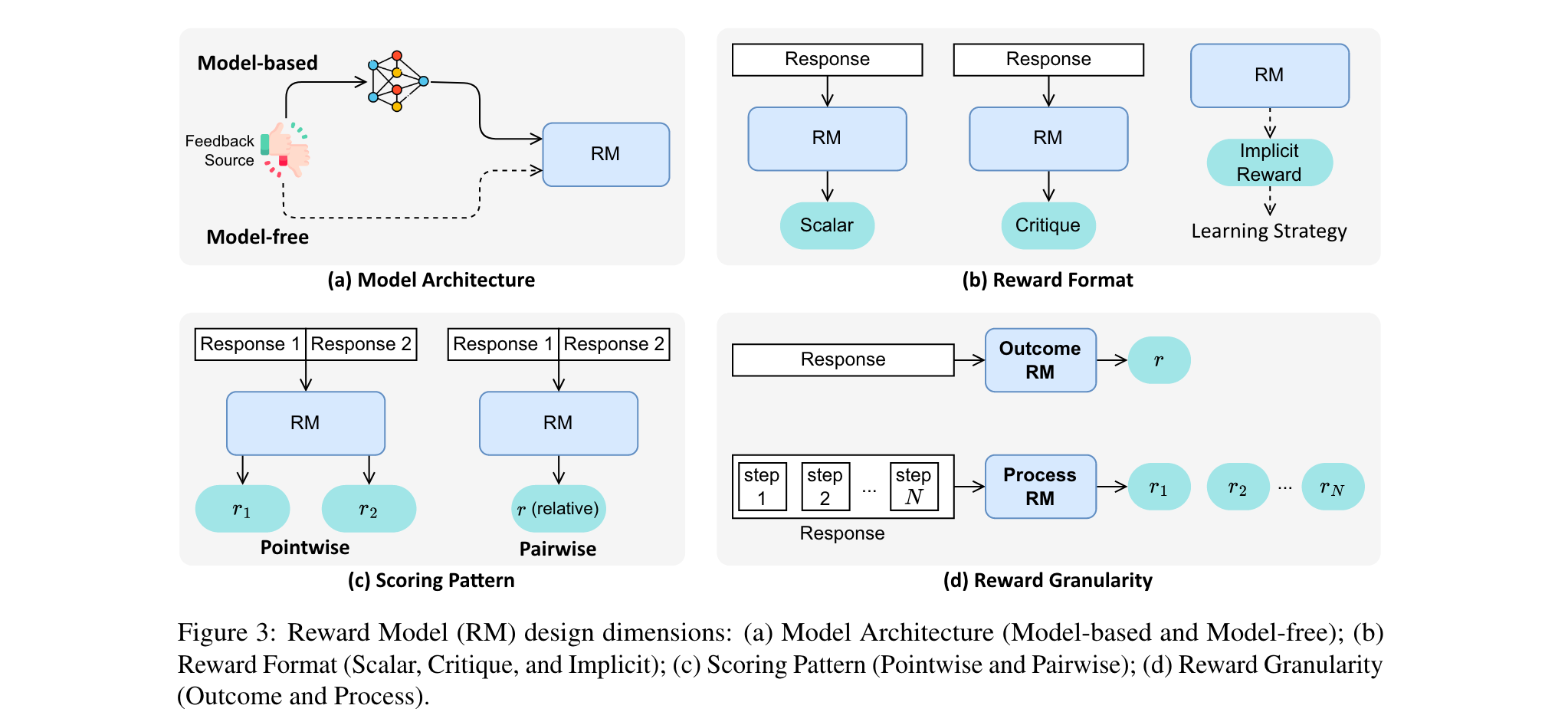
2. 奖励模型设计:涵盖模型架构(基于模型和无模型)、奖励格式(标量、评论和隐式)、评分模式(逐点和成对)和奖励粒度(结果级和过程级)四个关键维度。不同的设计选择会影响奖励模型的性能和应用场景。
3. 学习阶段:学习从奖励中发生在语言模型生命周期的不同阶段,包括训练时用奖励信号微调模型、推理时引导模型输出以及推理后优化输出,每个阶段都有其独特的作用和方法。
4. 学习方式:分为基于训练的策略(如强化学习和监督微调)和无训练的策略(如生成 - 排序、奖励引导解码和推理后校正),两种方式各有优劣,适用于不同的情况。
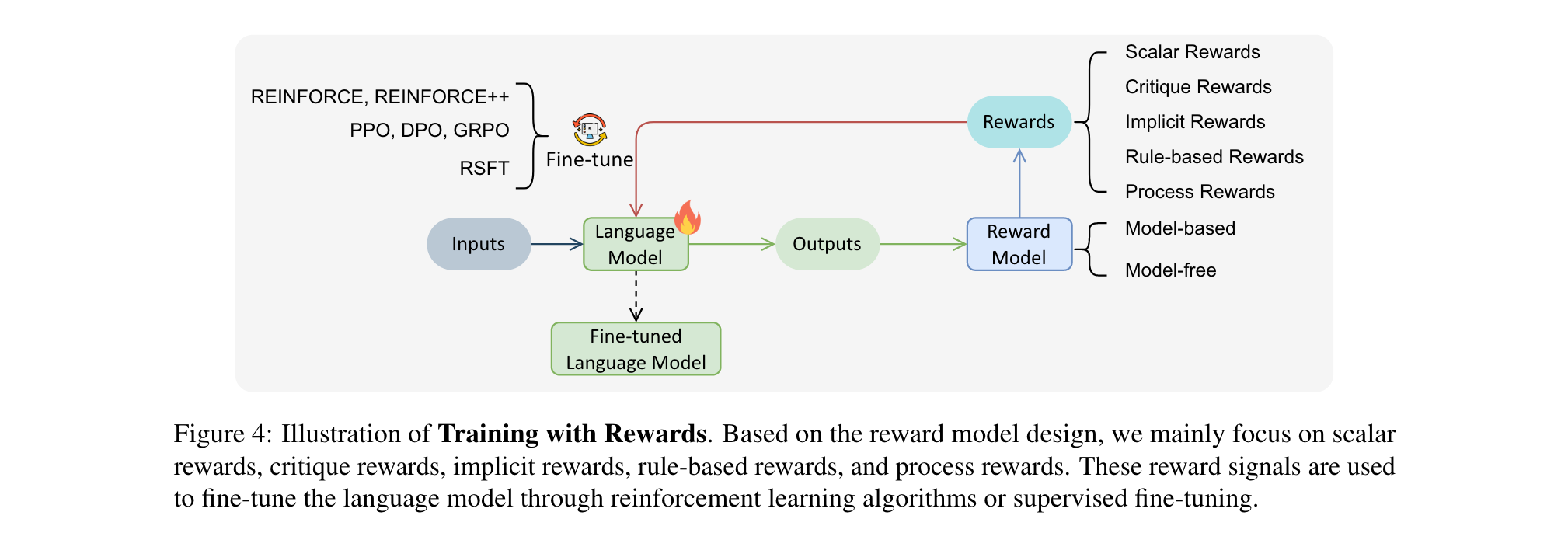
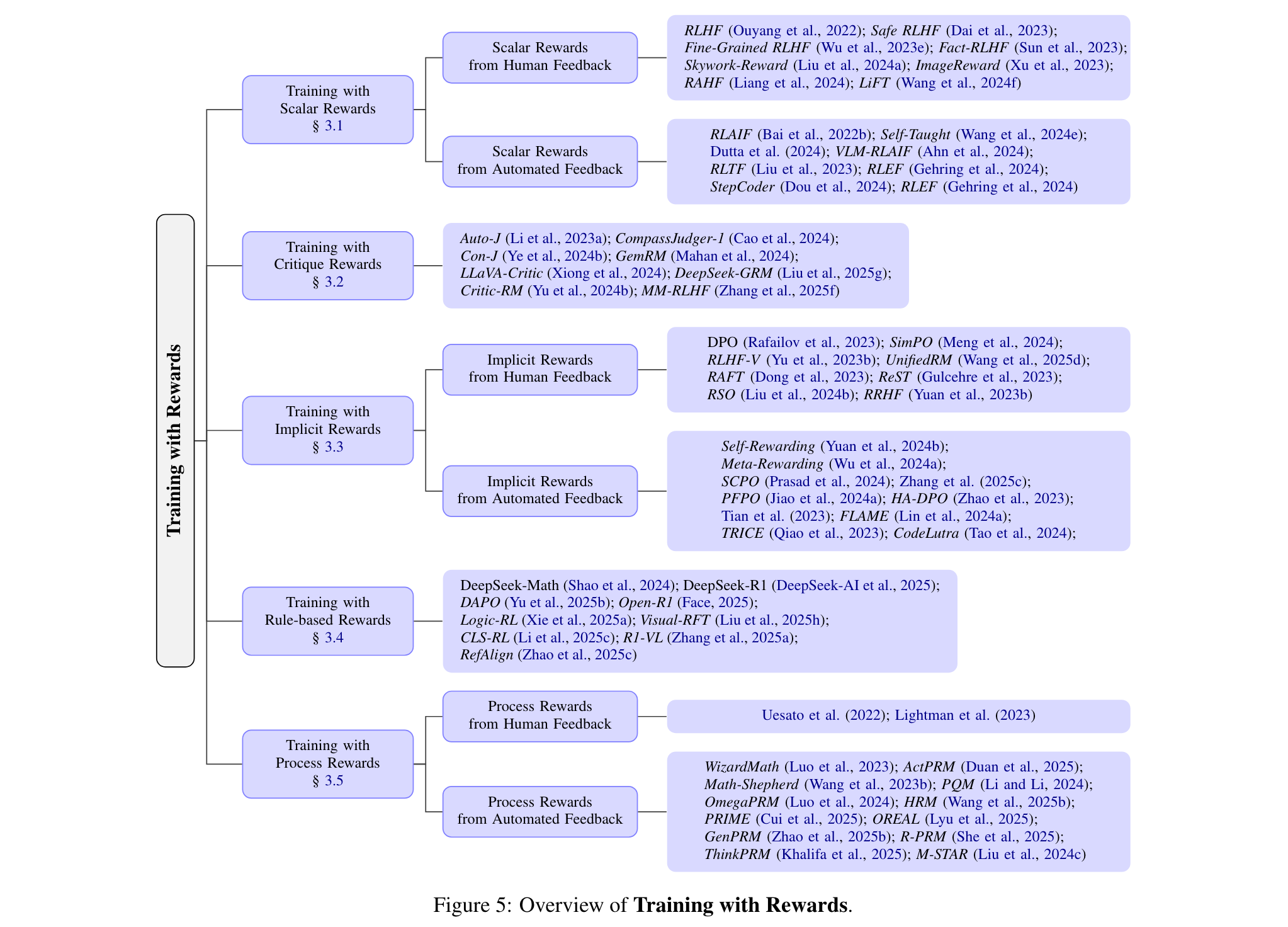
2. 训练时的奖励学习
在训练阶段,奖励学习有助于使LLMs更好地与人类偏好对齐,并提升测试时的推理能力。主要训练算法包括REINFORCE、PPO、DPO等。根据奖励设计不同,可分为以下几类:
- 标量奖励训练:通过训练专门的奖励模型或直接从源数据提取标量奖励。如RLHF基于人类偏好训练奖励模型,RLAIF则利用AI反馈替代人类标注,还有许多研究将其扩展到多模态任务。
- 评论奖励训练:使用生成式奖励模型生成自然语言评论,相比标量奖励更具灵活性和可解释性。例如Auto-J、CompassJudger-1等模型,还有一些采用混合结构的奖励模型。
- 隐式奖励训练:奖励信号隐含在训练数据结构中。像DPO通过对数似然差异编码隐式奖励,还有基于RSFT的方法,通过筛选高质量样本进行训练。
- 基于规则的奖励训练:依据特定规则验证输出获得奖励,如DeepSeek-R1通过定义准确性和格式奖励,使语言模型获得长思维链能力,后续有许多研究在此基础上进行扩展。
- 过程奖励训练:关注模型推理轨迹的中间步骤,采用过程奖励模型(PRM)进行评估。早期依赖人类注释,现在越来越多利用自动反馈,如WizardMath用GPT-4标注数学推理步骤。
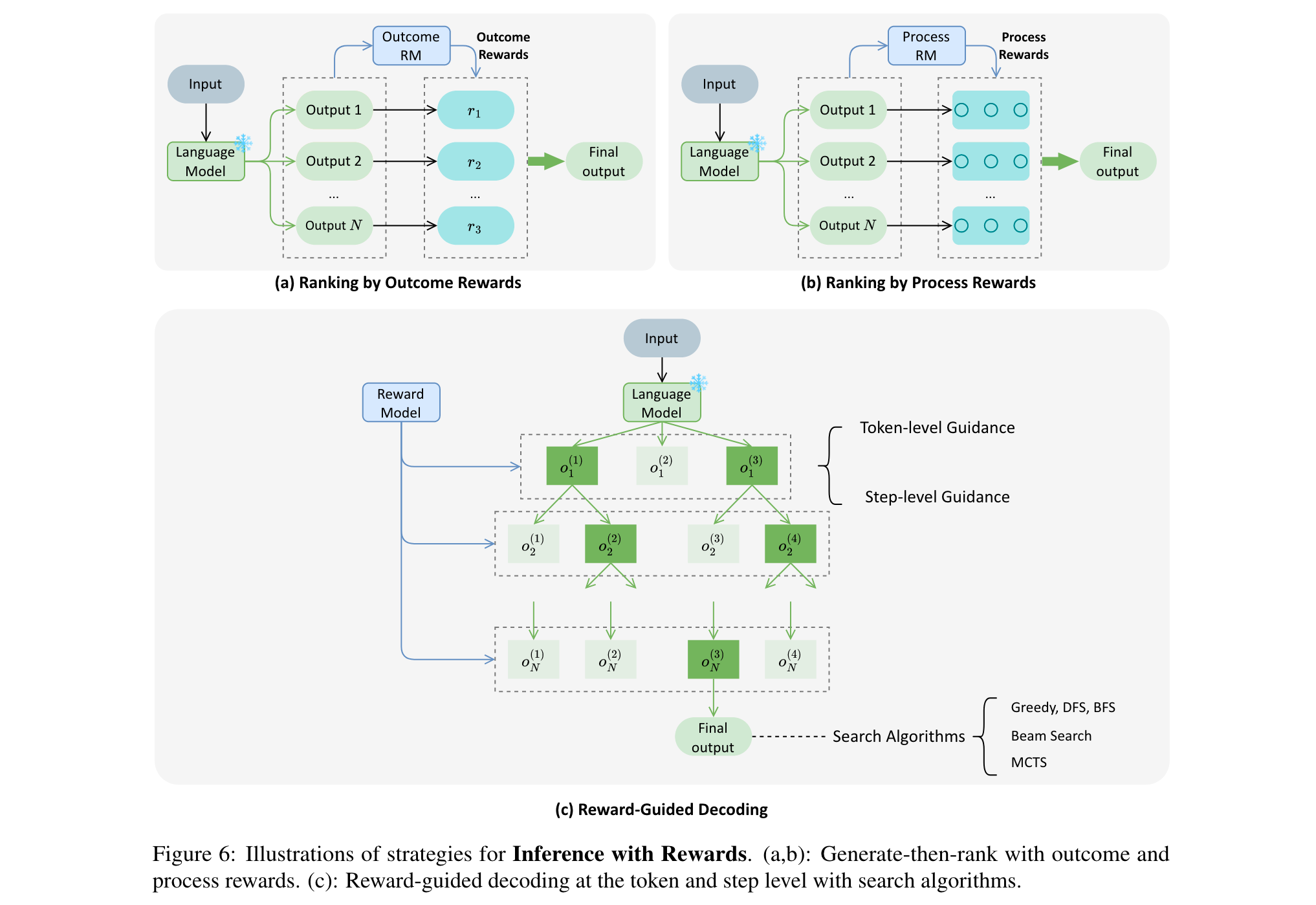
3. 推理时的奖励学习
推理时的奖励学习为调整模型行为提供了灵活、轻量级的机制,主要包括生成 - 排序和奖励引导解码两种策略。
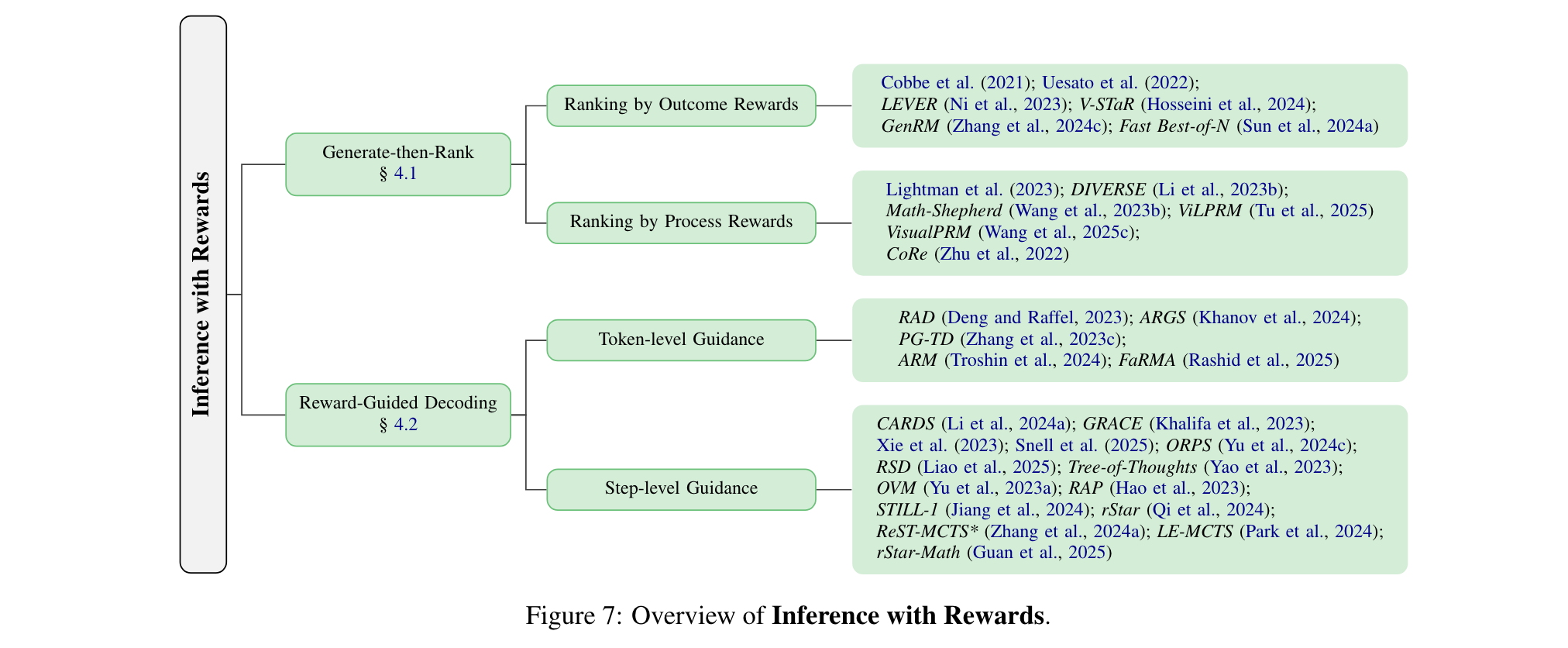
1. 生成-排序:从语言模型中采样多个候选响应,用奖励模型评分后选择最佳输出。根据奖励粒度,分为基于结果奖励排序(如Cobbe等人训练二元结果奖励模型评估数学解答)和基于过程奖励排序(如Lightman等人用过程奖励模型评估数学解答步骤),后者能更好地区分候选响应。
2. 奖励引导解码:将奖励信号紧密融入语言模型的生成过程,根据引导粒度分为令牌级引导(如RAD结合令牌可能性和标量奖励调整输出)和步骤级引导(如GRACE用奖励模型评估推理步骤正确性,引导模型选择更准确的推理路径),能实现对输出质量的精细控制。
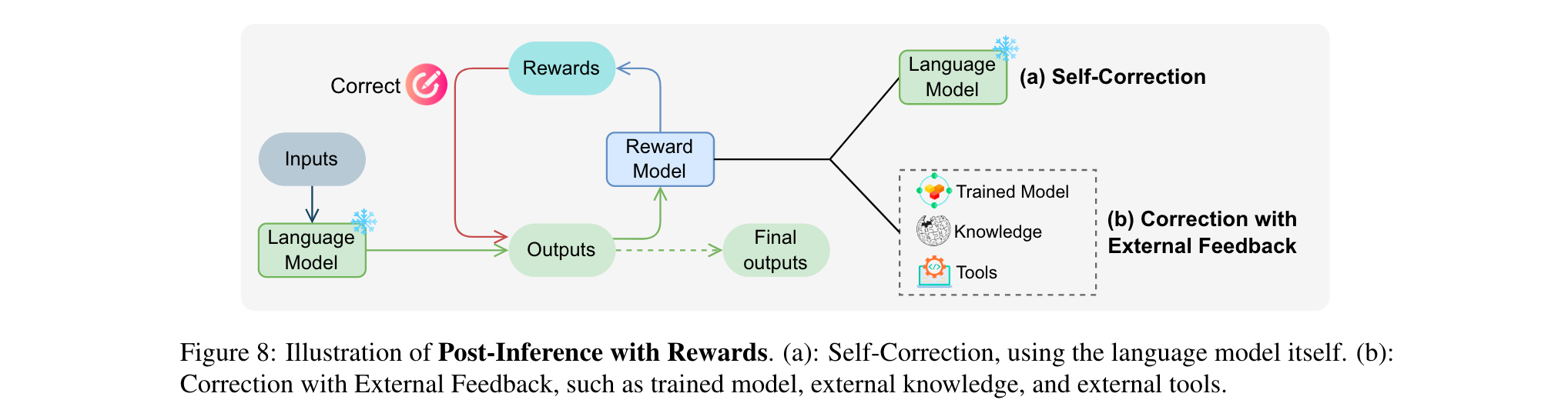
4. 推理后的奖励学习
推理后奖励学习旨在利用奖励信号校正和优化模型输出,分为自我校正和外部反馈校正。
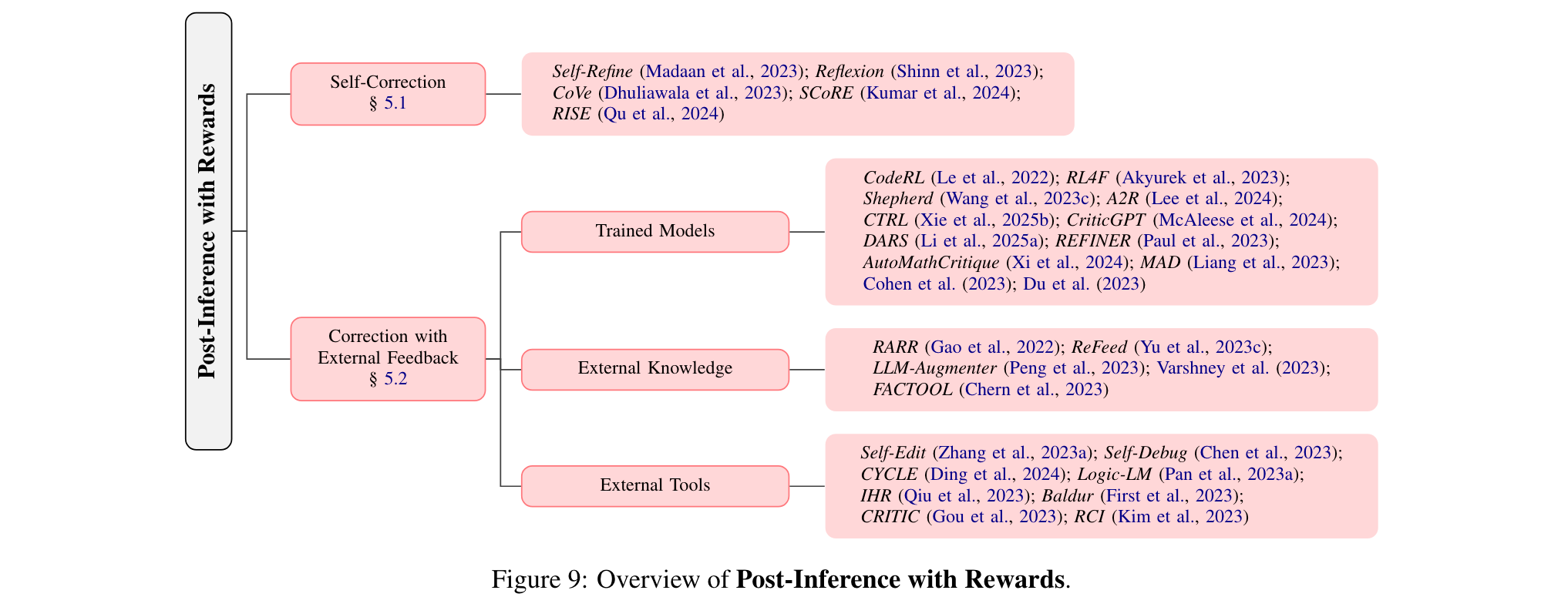
1. 自我校正:利用语言模型自身评估和修正输出,如Self-Refine让语言模型对自己的输出提供反馈,Reflexion还会维护记忆库辅助后续生成。
2. 外部反馈校正:借助更强大的训练模型、外部知识或工具提供反馈。例如CodeRL用训练的批评模型指导代码生成,RARR基于外部知识的证据推导混合奖励,Self-Edit利用代码编译器反馈优化语言模型。
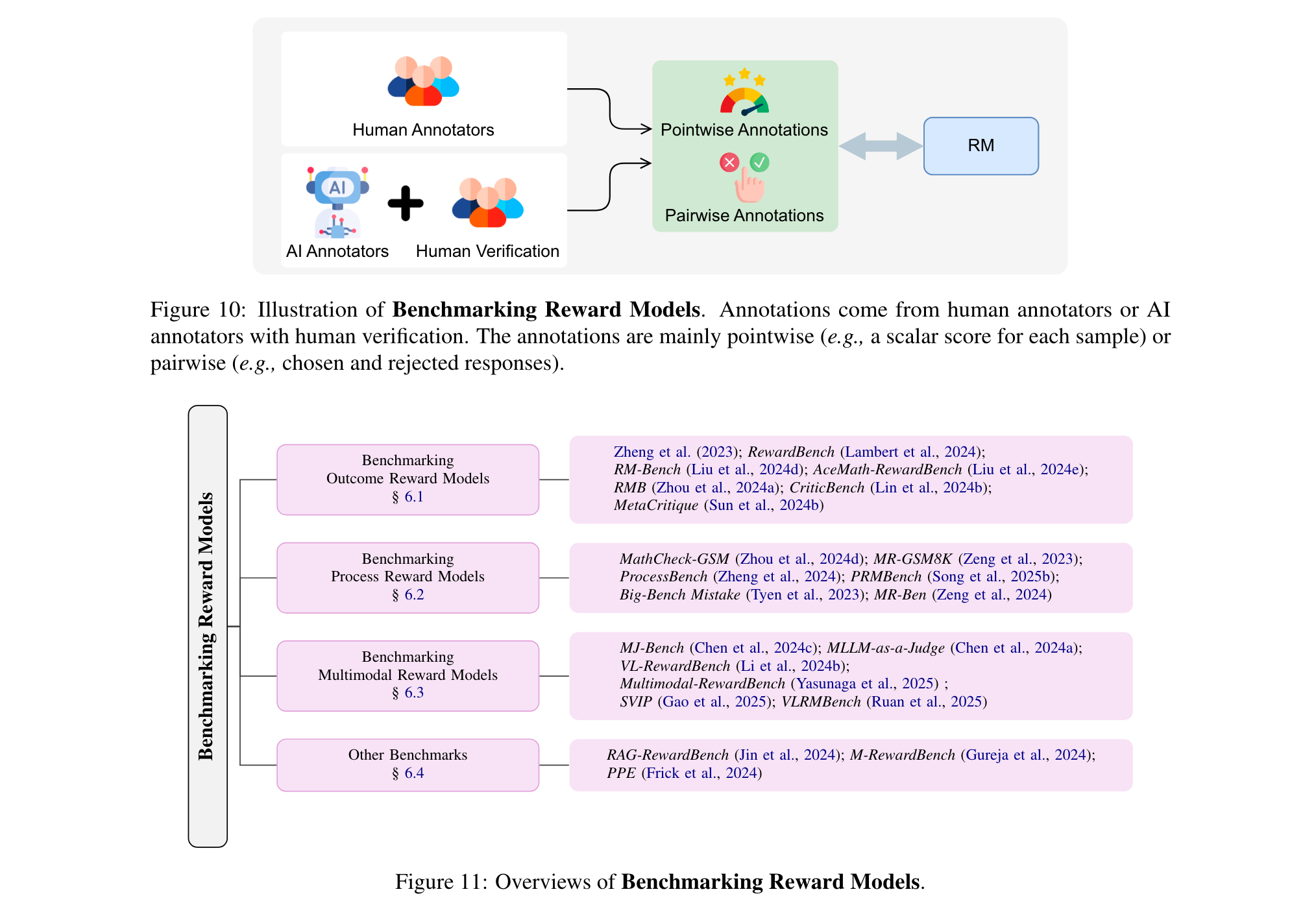
5. 奖励模型的基准测试
奖励模型在LLMs的后训练和测试时扩展中起着核心作用,因此严格多样的基准测试至关重要。现有基准测试主要依赖专家人工标注或AI标注(经人工验证),涵盖结果奖励模型、过程奖励模型、多模态奖励模型等多个方面的评估,不同基准测试在任务覆盖、评估协议、标注来源和奖励格式等方面存在差异。
6. 应用领域
“从奖励中学习”的策略在多个领域得到广泛应用:
- 偏好对齐:确保LLMs生成符合人类期望的内容,如减少幻觉、保证安全性和提升有用性。
- 数学推理:通过构建奖励模型和采用推理时缩放策略,提升语言模型解决数学问题的能力。
- 代码生成:利用各种奖励信号改进代码语言模型,包括训练奖励模型、引导推理和优化生成代码。
- 多模态任务:应用于多模态理解和生成任务,如视觉问答、图像/视频生成等,提升多模态推理能力。
- 智能体:用于训练和引导LLM智能体,使其能在动态环境中自动执行复杂任务。
- 其他应用:还包括具身AI、信息检索、工具调用、推荐系统、软件工程等领域,推动这些领域的发展。
7. 挑战与未来方向
尽管“从奖励中学习”取得了显著进展,但仍面临诸多挑战:
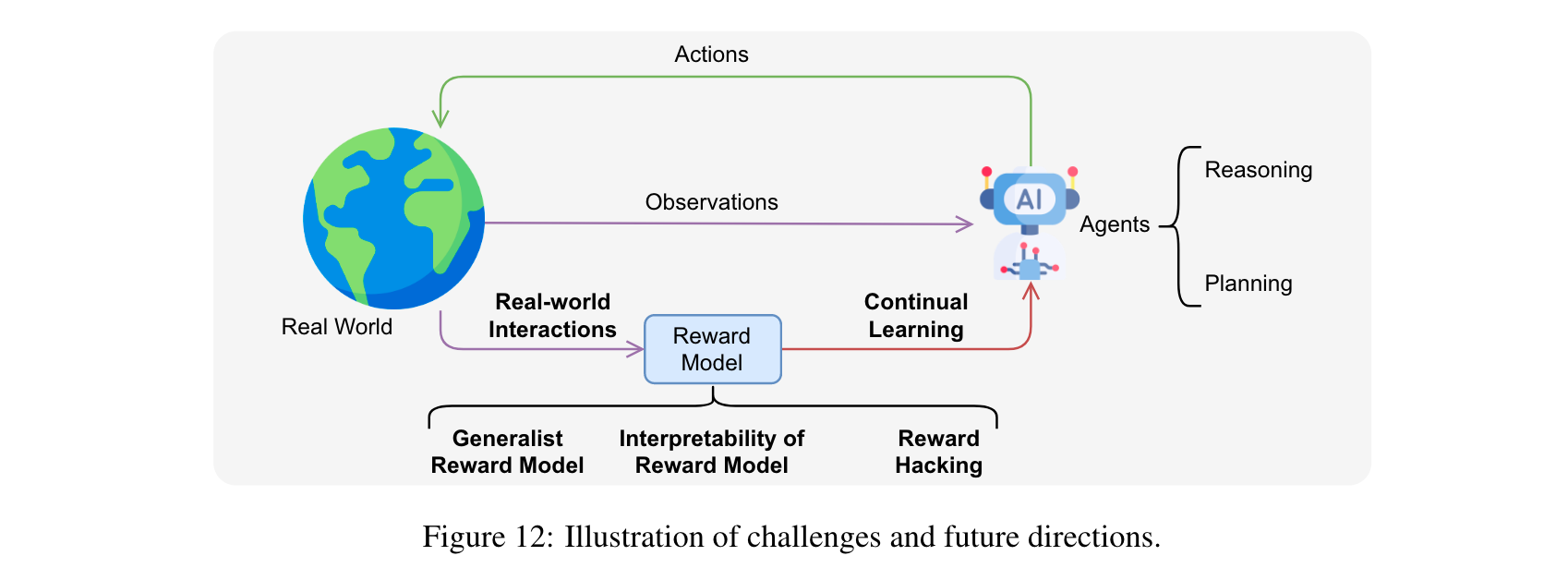
1. 奖励模型的可解释性:大多数奖励模型被视为黑盒,缺乏可解释性,阻碍了人类的信任和监督,需要进一步研究提高其可解释性。
2. 通用奖励模型:现有奖励模型多针对特定领域,泛化能力弱,未来应发展通用奖励模型,以适应不同任务和场景。
3. reward hacking:模型可能利用奖励函数的漏洞获取高奖励,而未真正学习期望行为,需设计更鲁棒的奖励函数等方法来应对。
4. 基于真实世界交互的奖励:当前方法多依赖人类偏好或精心策划的自动反馈,未来应让LLMs从真实世界交互中获取奖励,实现与现实世界的紧密结合。
5. 持续学习:目前的学习策略假设数据集、奖励模型和交互是固定的,难以适应新任务和环境变化,持续学习是未来的重要方向。
“从奖励中学习”为大语言模型的发展带来了新的机遇和挑战。通过深入研究和不断创新,有望推动大语言模型在更多领域取得突破,实现更强大、智能的人工智能。