AAAI-2025 | 中科院无人机导航新突破!FELA:基于细粒度对齐的无人机视觉对话导航

-
作者:Yifei Su, Dong An, Kehan Chen, Weichen Yu, Baiyang Ning, Yonggen Ling, Yan Huang, Liang Wang
-
单位:中国科学院大学人工智能学院,中科院自动化研究所模式识别与智能系统实验室,穆罕默德·本·扎耶德人工智能大学,卡内基梅隆大学电气与计算机工程系,腾讯 Robotics X
-
论文标题:Learning Fine-Grained Alignment for Aerial Vision-Dialog Navigation
-
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/32758/34913
-
代码链接:https://github.com/yifeisu/FELA
主要贡献
-
数据集构建:开发了一种半自动标注流程,构建了第一个大规模细粒度空中视觉对话导航(FG-AVDN)数据集,提供了实体与地标之间的细粒度跨模态对齐。
-
方法提出:提出了一种新颖的细粒度实体-地标对齐(FELA)方法,通过精确的语义网格表示和三个辅助任务(地标旋转边界框预测、地标语义预测、实体-地标对比学习),显式地学习实体与地标之间的对齐。
-
性能提升:通过大量实验验证了显式实体-地标对齐学习对空中视觉对话导航(ANDH)任务的有效性,FELA在成功率(SR)上比现有技术提高了3.2%,在目标进展(GP)上提高了4.9%。
研究背景
-
语言引导导航的重要性:语言引导导航是机器人通过与人类交流完成任务的一个基础且具有挑战性的问题。近年来,虽然在该领域取得了一定进展,但大多数研究集中在地面机器人上,而无人机(空中机器人)在该领域的研究相对较少。
-
空中视觉对话导航(AVDN)任务:AVDN任务要求无人机根据与人类的对话历史导航到目标位置,为无人机的应用(如食品配送和野外搜索救援)提供了新的机会。然而,该任务存在两个独特挑战:一是俯视图中的地标具有几何多样性,难以感知小或窄的物体;二是俯视图包含更多地标,容易分散无人机对目标实体的注意力。
-
现有方法的局限性:现有方法在处理ANDH任务中的细粒度跨模态对齐方面存在不足,主要原因是缺乏实体-地标对齐监督和粗糙的视觉表示。
研究方法
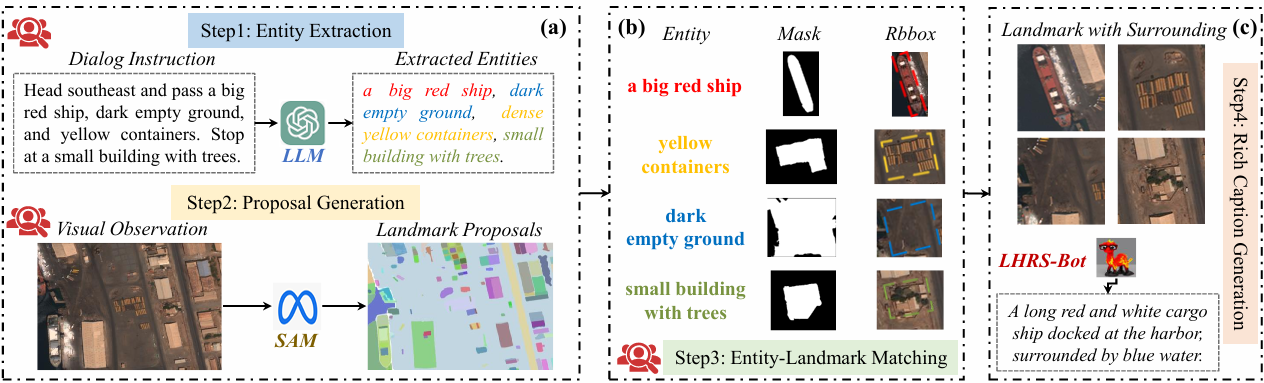
- FG-AVDN数据集构建:
-
半自动实体-地标提取:利用GPT3.5从对话中提取实体,使用SAM生成视觉观察中的地标掩码提议,并通过RemoteCLIP建立实体与地标之间的初始关联,最后进行人工检查和修正。
-
伪实体-地标生成:为了使无人机能够理解开放词汇指令,使用LHRS-Bot为提取的地标生成额外的详细描述,包括地标及其周围环境的详细属性。
-
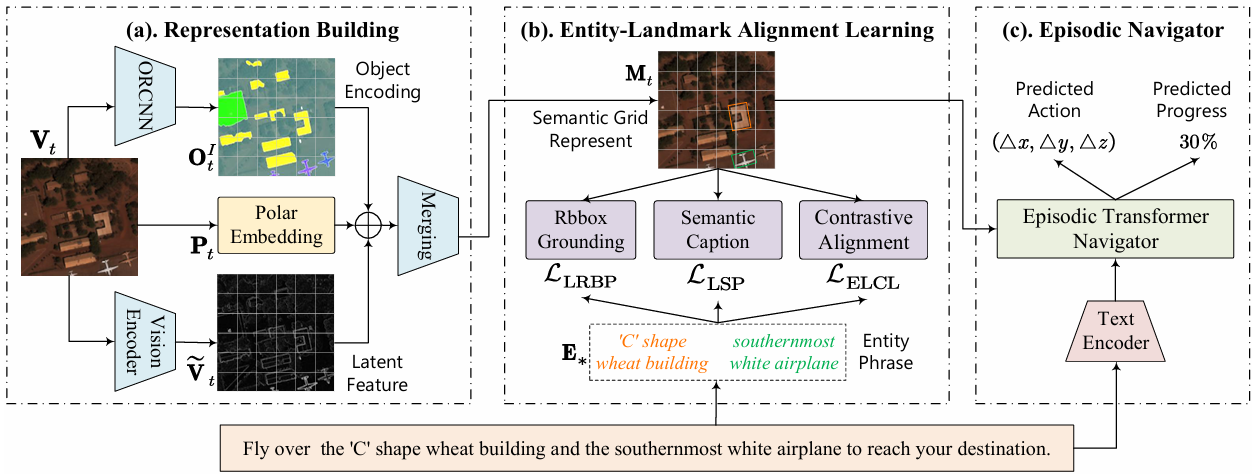
- FELA方法:
-
语义网格表示:构建一个语义网格表示来增强无人机的视觉感知,该表示能够同时捕捉环境的语义和空间结构。具体来说,通过将视觉编码器的最后一层特征、对象编码和位置编码进行合并来获得语义网格表示。
- 实体-地标对齐学习:设计了三个辅助任务来显式地学习实体与地标之间的对齐。
-
地标旋转边界框预测(LRBP):预测基于实体的地标紧凑旋转边界框,以实现更精细的对齐。
-
地标语义预测(LSP):根据视觉图像描述地标,将其建模为区域级的描述任务。
-
实体-地标对比学习(ELCL):在公共特征空间中对齐匹配的实体-地标对,以实现更好的细粒度对齐。
-
-
导航模型:采用周期变换器作为导航器,将指令文本、视觉历史、轨迹历史和语义网格表示输入导航器进行模态融合,然后预测动作。
-
实验
- 实验设置:
-
在ANDH任务上评估所提出的方法,该任务将AVDN数据集划分为6269个子轨迹,并根据场景类型分为训练集、验证集和测试集。
-
评价指标包括成功率(SR)、按路径长度加权的成功率(SPL)和目标进展(GP)。
-
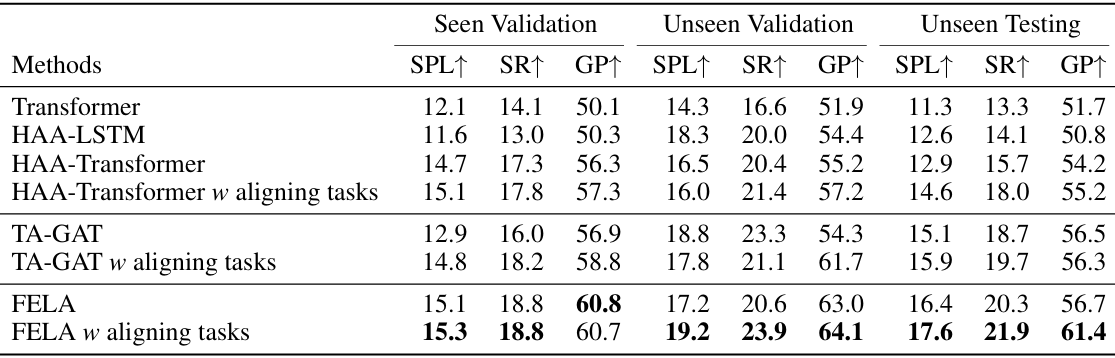
- 与现有技术的比较:
-
FELA在未见验证集和测试集上均取得了领先性能。
-
具体来说,FELA在未见验证集上的SR为23.9%,SPL为19.2%,GP为64.1;在未见测试集上的SR为21.9%,SPL为17.6%,GP为61.4。
-
此外,FELA的参数量和计算量仅比之前的最佳方法TG-GAT略有增加,且推理速度为11.7Hz,具有在现实世界中应用的潜力。
-
- 消融研究:
-
不同网格表示构建选项:实验结果表明,仅使用视觉编码或语义编码构建网格表示的性能都不理想,而将两者结合并引入位置编码时,性能达到最佳。
-
不同辅助任务的效果:单独使用每个辅助任务或它们的组合都能对性能产生不同程度的提升。当三个辅助任务同时使用时,性能达到最高,这表明这些任务是互补的,且实体-地标对齐学习对导航泛化能力的提升是有效的。
-
不同语义网格表示尺度的影响:当网格尺度N增加到7时,性能达到最佳;进一步增大N,性能保持不变甚至略有下降。因此,选择N=7作为默认设置。
-
不同实体-地标数据对齐的影响:仅使用从对话中提取的实体-地标对进行对齐学习,就能取得一定的性能提升;进一步引入由LHRS-Bot生成的详细地标描述,性能进一步提高。
-
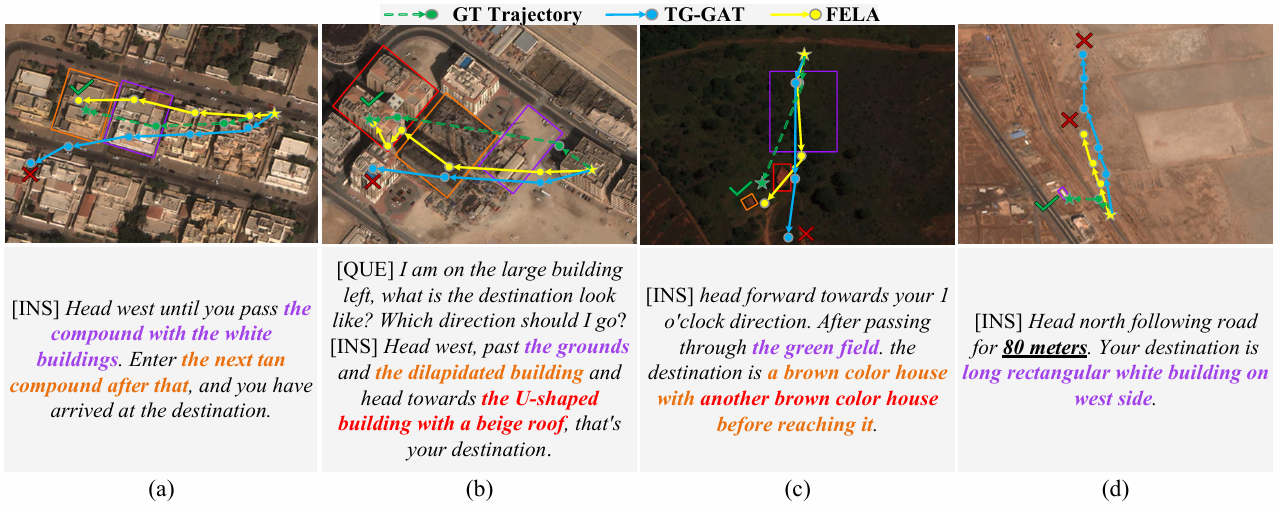
- 定性结果:
-
通过比较FELA和TG-GAT在未见验证集上的预测路径,可以看出FELA在识别和定位目标地标方面表现更好,尤其是在处理具有复杂修饰语的实体短语时。
-
然而,FELA在处理与距离相关的指令时可能会失败,因为缺乏绝对空间感知能力。
-
结论与未来工作
- 结论:
-
本文解决了ANDH任务中一个关键但尚未被充分研究的问题——实体-地标对齐。
-
通过构建FG-AVDN数据集和提出FELA方法,显式地学习实体与地标之间的对齐,实验结果证明了该方法的有效性。
-
- 未来工作:
-
现有导航器的性能仍不令人满意,且在无人机上进行真实世界实验可能存在安全问题。
-
计划继续提高导航器的鲁棒性,然后在未来进行从仿真到现实的部署。
-
