hashicorp raft源码分析(一、项目介绍与Leder选举实现)
hashicorp raft源码分析(一、项目介绍与Leder选举实现)
本文基于 hashicorp/raft
v1.7.3版本进行源码分析API手册:https://pkg.go.dev/github.com/hashicorp/raft
源码地址:hashicorp/raft
raft论文中文解读:https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.md
在阅读文章前需要有一定的 raft 基础, 不然直接看源码会一头雾水.
一、项目背景:什么是 Raft?
在聊代码结构前,先简单回顾 Raft 算法的基本思想:
-
Raft 是一种分布式一致性算法(Consensus Algorithm),用于在分布式系统(如集群、多节点存储系统)中保证数据一致性和高可用性。
-
相比 Paxos 更易理解、易实现,Raft 将一致性问题分解为:
- Leader 选举(Leader Election):集群中选出一个 Leader 节点负责日志复制。
- 日志复制(Log Replication):Leader 接收客户端写请求,记录到自己的日志,并同步到 Follower 节点。
- 安全性(Safety):确保所有节点最终状态一致,防止脑裂、日志冲突。
Hashicorp 的 Raft 是 Raft 论文(In Search of an Understandable Consensus Algorithm)的Go语言实现,被广泛应用在:
- Hashicorp 的 Consul、Vault、Nomad
- 类似 etcd(另一个 Raft 实现)
二、项目结构
github.com/hashicorp/raft/ 相关核心目录与代码
├── fuzzy // 用来模拟测试 启动一个集群, 启动多个raftNode 节点。
├── bench // 包含基准测试,用于评估 Raft 的性能。
├── raft.go // 【核心文件】Raft 状态机、主逻辑(选举、日志复制核心循环)
├── api.go // 对外暴露的核心 API(Raft 接口定义)
├── config.go // Raft 节点配置(超时、选举、日志等参数)
├── file_snapshot.go // 基于文件的快照(Snapshot)实现
├── fsm.go // 有限状态机(Finite State Machine)接口定义
├── future.go // 异步操作的 Future 模式实现(请求结果回调)
├── log.go // Raft 日志结构(LogEntry、日志压缩等)
├── log_store.go // 日志存储接口(BoltDB、内存存储、文件存储实现)
├── net_transport.go // 网络层抽象(TCP、TLS、Inmem 传输实现)
├── observer.go // 事件监听器(观察者模式,监控集群状态变化)
├── raft_test.go // 单元测试、集成测试(非常重要,覆盖所有场景)
├── snapshot.go // 快照管理(压缩日志、持久化状态)
├── stable_store.go // 持久化存储接口(稳定存储 Raft 日志、任期等)
├── transport.go // 网络传输接口定义(RPC 调用,消息传递)
└── util.go // 辅助函数(随机数、时间戳、Debug 工具)
关键子目录/文件说明:
raft.go:核心!实现了Raft算法的主要逻辑,包括:- 节点状态切换(成为候选人、领导者、跟随者)
- 心跳机制(Leader发送心跳维持领导权)
- 选举定时器(触发选举)
- 日志复制(Leader向Follower同步日志)
- 状态机应用(
FSM.Apply())
log.go&log_store.go: Raft日志的存储与管理:Log结构体(Index、Term、Command)LogStore接口(持久化日志的Append()、Get()等)- 默认内存实现(
inmem_store.go)和BoltDB实现(raftboltdb/)用于持久化
fsm.go:有限状态机接口,使用者需实现:Apply(logEntry []byte) interface{}(应用日志到状态机)Snapshot() (FSMSnapshot, error)(创建快照)Restore(snapshot io.ReadCloser) error(从快照恢复)
snapshot.go&file_snapshot.go: 快照的创建、传输、恢复逻辑:SnapshotSink(写快照到文件)SnapshotStore接口(支持文件系统、内存快照)
transport.go&net_transport.go:网络通信层Transport接口(AppendEntries()、RequestVote()等RPC)- 基于TCP的默认实现(
NetTransport),封装了encoding/gob序列化
future.go: 异步操作机制:- 提交日志(
raft.Apply())时返回Future对象 - 可阻塞等待操作结果(成功/失败)
- 提交日志(
整体结构特点:
- 接口与实现分离:如
LogStore、SnapshotStore、Transport等关键组件均为接口,方便替换存储引擎(内存/BoltDB)或网络层(TCP、自定义) - 分层清晰:
- 最底层:
StableStore(任期、投票持久化)、LogStore(日志存储) - 中间层:
Raft状态机(选举、日志复制) - 上层:
FSM(业务状态机,由用户实现)
- 最底层:
- 大量使用Go的
goroutine+channel:- 后台心跳/选举定时器
- 处理RPC调用
- 日志异步复制
三、Leader选举

在raft算法中,典型的领导者选举在本质上是节点状态的变更。具体到raft源码中,领导者选举的入口函数就是run(),在raft.go中以一个单独的协程运行,来实现节点状态的变更
在下面的实现代码中,可以看到Follower、Candidate和Leader3 种节点状态都有分别对应的功能函数
func (r *Raft) run() {for {select {case <-r.shutdownCh:r.setLeader("")returndefault:}switch r.getState() {case Follower:r.runFollower()case Candidate:r.runCandidate()case Leader:r.runLeader()}}
}
1.1 follower跟随者运行逻辑
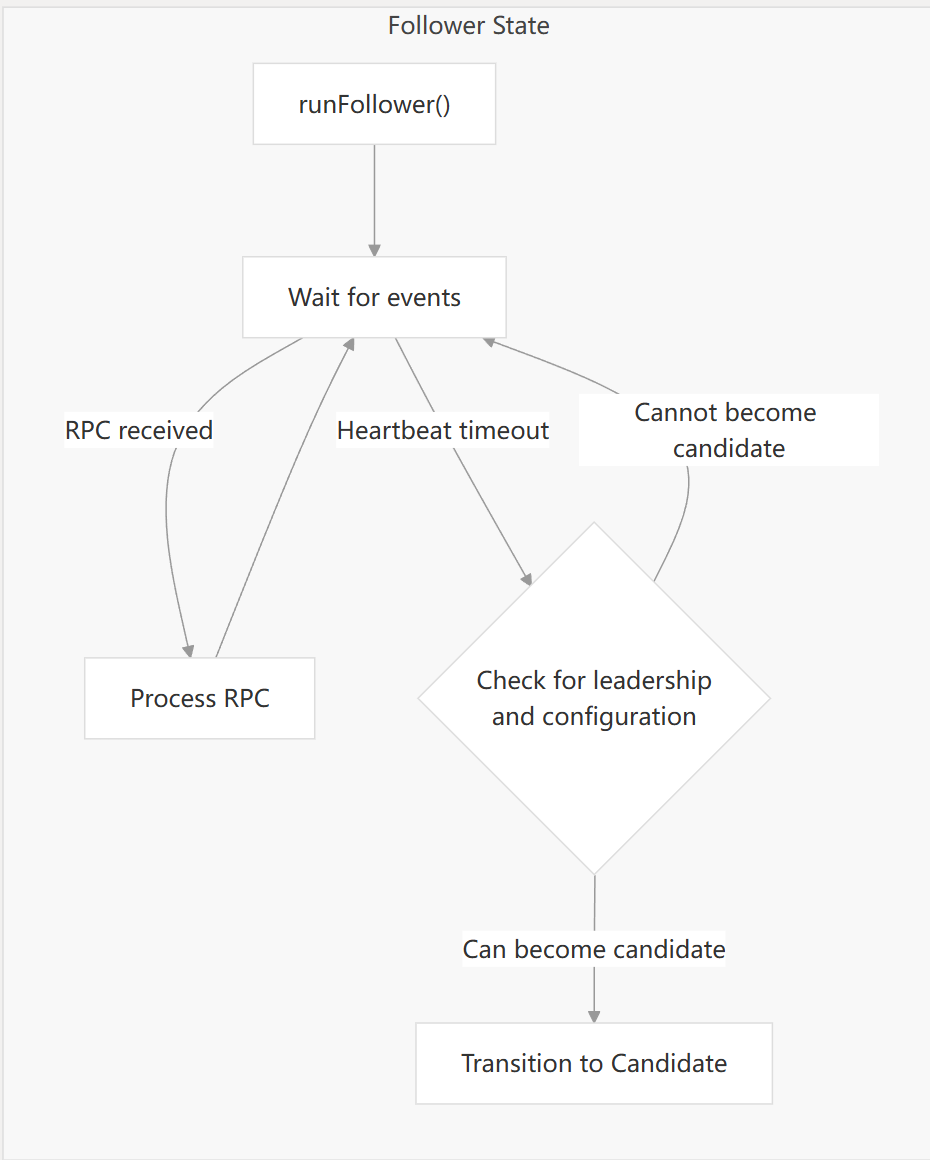
主要处理逻辑:
-
接收 RPC 请求 (
<-r.rpcCh): 这是 Follower 接收外部通信的主要方式。当收到 RPC 时,将其交给r.processRPC方法处理。Follower 主要处理以下几种 RPC:AppendEntriesRequest: 接收 Leader 发来的日志条目同步请求或心跳信号。RequestVoteRequest: 接收 Candidate 发来的投票请求。RequestPreVoteRequest: 接收 Candidate 发来的预投票请求(如果启用了 Pre-Vote 优化)。InstallSnapshotRequest: 接收 Leader 发来的快照传输请求。TimeoutNowRequest: 接收强制立即超时的请求。
-
接收配置变更请求 (
<-r.configurationChangeCh): Follower 节点不能发起配置变更。因此,收到此类请求时,直接回复ErrNotLeader错误。 -
接收日志应用请求 (
<-r.applyCh): Follower 节点不能直接处理外部的日志应用请求。日志的应用是由 Leader 驱动的commitIndex前进后,由 Raft 内部机制完成的。因此,收到此类请求时,也直接回复ErrNotLeader错误。 -
心跳定时器超时 (
<-heartbeatTimer): 这是 Follower 检测 Leader 是否存活的关键机制。-
定时器超时后,首先重新启动一个新的随机化心跳定时器。
-
然后,检查距离最后一次与 Leader 成功通信的时间 (
r.LastContact()) 是否超过了心跳超时时间。 -
如果最近与 Leader 有过联系 (时间差小于超时时间): 说明 Leader 仍然活跃,这只是一个正常的定时器事件,Follower 继续保持 Follower 状态,循环继续。
-
如果最近与 Leader 没有联系 (时间差大于等于超时时间):
说明 Leader 可能已经失效或网络有问题,Follower 认为 Leader 失联。
-
清空当前已知的 Leader 信息。
-
进行选举资格检查:
在转换为 Candidate 发起选举之前,Follower 会检查自己是否有资格参与选举:
- 检查是否有已知的配置 (
r.configurations.latestIndex == 0)。如果没有,无法选举,记录警告并继续等待。 - 检查当前节点是否在稳定的配置中拥有投票权 (
!hasVote(r.configurations.latest, r.localID))。如果配置已稳定 (latestIndex == committedIndex) 但自己没有投票权,则不能发起选举,记录警告并继续等待。
- 检查是否有已知的配置 (
-
如果通过选举资格检查 (有已知配置且自己有投票权):
- 记录警告日志,表明心跳超时并即将开始选举。
- 更新状态指标。
- 将节点状态设置为 Candidate (
r.setState(Candidate))。 - 退出
runFollower函数 (return)。这将导致外部调用者(通常是 Raft 的主协程)检测到状态变化,并调用处理 Candidate 状态的函数 (runCandidate),开始新的选举流程。
-
-
-
接收关闭信号 (
<-r.shutdownCh): 当 Raft 节点被要求关闭时,收到此信号,函数直接返回,结束主循环和 Follower 状态的运行。
相关源码:
// runFollower 在 Follower 状态下运行主循环。
func (r *Raft) runFollower() {didWarn := false // 是否已经发出警告(没有已知节点或不在配置中)leaderAddr, leaderID := r.LeaderWithID() // 获取当前已知的 leader 地址和 IDr.logger.Info("entering follower state", "follower", r, "leader-address", leaderAddr, "leader-id", leaderID) // 记录进入 Follower 状态的日志metrics.IncrCounter([]string{"raft", "state", "follower"}, 1) // 增加 Follower 状态的计数器// 生成一个随机的心跳超时定时器。使用随机超时是为了防止所有 follower 同时超时并转换为 candidate。heartbeatTimer := randomTimeout(r.config().HeartbeatTimeout)// 循环,直到节点不再是 Follower 状态for r.getState() == Follower {r.mainThreadSaturation.sleeping() // 表示主线程当前处于空闲状态// 使用 select 语句监听多个 channelselect {case rpc := <-r.rpcCh:r.mainThreadSaturation.working() // 表示主线程开始工作r.processRPC(rpc) // 处理 rpc 请求, 这里有投票、传输日志、传递快照的 RPC 请求case c := <-r.configurationChangeCh:r.mainThreadSaturation.working()// 收到配置变更请求// 因为不是 leader,拒绝所有操作c.respond(ErrNotLeader) // 回复 "不是 Leader" 错误case a := <-r.applyCh:r.mainThreadSaturation.working()// 收到日志应用请求// 因为不是 leader,拒绝所有操作a.respond(ErrNotLeader) // 回复 "不是 Leader" 错误// .....忽略非核心代码......case <-heartbeatTimer:r.mainThreadSaturation.working()// 心跳超时// 重新启动心跳定时器hbTimeout := r.config().HeartbeatTimeout // 获取配置的心跳超时时间heartbeatTimer = randomTimeout(hbTimeout) // 生成新的随机超时定时器,randomTimeout 防止多个 Follower 同时超时发起选举,造成网络风暴(split vote)。// 检查最近是否与 leader 有过成功联系lastContact := r.LastContact() // 获取最后一次联系的时间if time.Since(lastContact) < hbTimeout {// 如果最后一次联系时间小于心跳超时时间,说明最近收到过 leader 的心跳,继续循环continue}// 心跳失败!转换为 Candidate 状态lastLeaderAddr, lastLeaderID := r.LeaderWithID() // 获取最后已知的 leader 地址和 IDr.setLeader("", "") // 清空 leader 信息if r.configurations.latestIndex == 0 {// 如果最新的配置索引为 0,表示还没有任何已知的配置if !didWarn {r.logger.Warn("no known peers, aborting election") // 记录警告日志:没有已知的节点,中止选举didWarn = true // 设置警告标志,避免重复警告}} else if r.configurations.latestIndex == r.configurations.committedIndex &&!hasVote(r.configurations.latest, r.localID) {// 如果最新的配置索引等于已提交的配置索引,并且当前节点在最新的配置中没有投票权if !didWarn {r.logger.Warn("not part of stable configuration, aborting election") // 记录警告日志:不在稳定的配置中,中止选举didWarn = true // 设置警告标志,避免重复警告}} else {// 满足选举条件metrics.IncrCounter([]string{"raft", "transition", "heartbeat_timeout"}, 1) // 增加心跳超时的计数器if hasVote(r.configurations.latest, r.localID) {// 如果当前节点在最新的配置中有投票权r.logger.Warn("heartbeat timeout reached, starting election", "last-leader-addr", lastLeaderAddr, "last-leader-id", lastLeaderID) // 记录警告日志:心跳超时,开始选举r.setState(Candidate) // 设置节点状态为 Candidatereturn // 退出 runFollower 函数,开始选举流程} else if !didWarn {// 当前节点没有投票权,并且之前没有发出过警告r.logger.Warn("heartbeat timeout reached, not part of a stable configuration or a non-voter, not triggering a leader election")didWarn = true}}case <-r.shutdownCh:// 收到关闭信号return // 退出 runFollower 函数}}
}// hasVote 检查给定的服务器 ID 在给定的配置中是否拥有投票权。
//
// 参数:
// configuration: Configuration 类型,表示集群的配置。
// id: ServerID 类型,表示要检查的服务器的 ID。
//
// 返回值:
// bool 类型,如果服务器拥有投票权则返回 true,否则返回 false。
func hasVote(configuration Configuration, id ServerID) bool {// 遍历配置中的所有服务器for _, server := range configuration.Servers {// 检查当前遍历到的服务器的 ID 是否与要查找的 ID 匹配if server.ID == id {// 如果 ID 匹配,则检查该服务器的投票权 (Suffrage) 是否为 Voter (投票者)return server.Suffrage == Voter // 如果是 Voter,则返回 true}}// 如果遍历完所有服务器都没有找到匹配的 ID,或者找到的服务器不是 Voter,则返回 falsereturn false
}
processRPC 处理请求逻辑
func (r *Raft) processRPC(rpc RPC) {// 检查RPC请求的头部信息,如果检查失败,则返回错误响应。if err := r.checkRPCHeader(rpc); err != nil {// 向RPC请求发送者返回错误响应。rpc.Respond(nil, err)return}// 根据RPC请求中的命令类型进行不同的处理。switch cmd := rpc.Command.(type) {// 处理追加日志条目请求。case *AppendEntriesRequest:r.appendEntries(rpc, cmd)// 处理请求投票请求。case *RequestVoteRequest:r.requestVote(rpc, cmd)// 处理请求预投票请求(预投票用于在节点成为候选人之前检查是否能获得多数投票)。case *RequestPreVoteRequest:r.requestPreVote(rpc, cmd)// 处理安装快照请求(用于将快照数据传输到其他节点)。case *InstallSnapshotRequest:r.installSnapshot(rpc, cmd)// 处理立即超时请求(用于触发节点的超时操作)。case *TimeoutNowRequest:r.timeoutNow(rpc, cmd)// 如果收到未知的命令类型,则记录错误日志并返回错误响应。default:r.logger.Error("got unexpected command","command", hclog.Fmt("%#v", rpc.Command))rpc.Respond(nil, fmt.Errorf(rpcUnexpectedCommandError))}
}
hashicorp raft server/client 是使用 msgpack on tcp 实现的 rpc 服务, 关于 hashcrop raft transport server/client 的实现原理没什么可深入的, 请直接看代码实现. msgpack rpc 的协议报文格式如下.

appendEntries 同步日志
appendEntries 函数是 Raft 协议中 Follower 节点处理 Leader 发来的 AppendEntriesRequest 的核心方法。它的主要职责是根据 Leader 的请求更新 Follower 的状态、日志和提交索引。
核心流程:
- 初始化响应: 创建一个
AppendEntriesResponse并设置默认值(通常是失败),包含当前节点的 Term 和最后一个日志索引。使用defer确保函数退出时发送响应。 - Term 检查:
- 如果 Leader 的 Term 小于当前节点的 Term,则拒绝请求并返回(Follower 的 Term 在响应中)。
- 如果 Leader 的 Term 大于当前节点的 Term,或者当前节点不是 Follower (且不是领导权转移中的 Candidate),则更新当前节点的 Term 为 Leader 的 Term,并转换为 Follower 状态。
- 记录 Leader 信息: 保存 Leader 的地址和 ID。
- 日志一致性检查:
- 如果请求包含
PrevLogEntry(> 0),则获取当前节点日志中相同索引条目的 Term。 - 将获取到的 Term 与 Leader 请求中的
PrevLogTerm进行比较。 - 如果不匹配,说明日志发生分歧,拒绝请求,设置
NoRetryBackoff为 true,并返回。 - 如果无法获取到
PrevLogEntry索引处的日志(例如索引越界或存储错误),也拒绝请求,设置NoRetryBackoff为 true,并返回。
- 如果请求包含
- 处理新日志条目:
- 如果请求包含
Entries,遍历 Leader 发来的条目。 - 查找与当前节点日志发生冲突或 Leader 独有的新条目的起始点。
- 如果发现冲突(相同索引但 Term 不同),删除当前节点从冲突点开始的所有后续日志条目。如果在删除范围内的配置变更日志被移除,则回退最新的配置信息。
- 将 Leader 发来的从冲突点或当前节点最后一个日志索引之后开始的条目视为新的,并将其追加到日志存储中。
- 处理新追加的日志条目中的配置变更类型。
- 更新当前节点的最后一个日志索引和 Term。
- 如果请求包含
- 更新提交索引:
- 如果 Leader 的
LeaderCommitIndex大于当前节点的CommitIndex,则更新当前节点的CommitIndex为min(LeaderCommitIndex, 当前节点的最后一个日志索引)。 - 如果最新的配置变更日志索引小于等于新的提交索引,则将最新的配置提升为已提交配置。
- 将已提交但尚未应用的日志条目应用到状态机,
processLogs应用日志。
- 如果 Leader 的
- 设置成功并更新最后联系时间: 如果所有检查和操作都成功完成,将响应的
Success字段设置为 true,并更新记录最后一次与 Leader 成功联系的时间(用于重置选举定时器)。
简单说 appendEntries() 同步日志是 leader 和 follower 不断调整位置再同步数据的过程.
// appendEntries 在收到AppendEntries RPC调用时被触发。
// 这个函数必须只在Raft的主线程(事件循环)中调用,以避免并发问题。
func (r *Raft) appendEntries(rpc RPC, a *AppendEntriesRequest) {// 使用 metrics 记录 appendEntries RPC 处理的时间。defer metrics.MeasureSince([]string{"raft", "rpc", "appendEntries"}, time.Now())// 初始化 AppendEntries 响应结构体。// 默认设置为失败,并包含当前节点的Term和最后一个日志条目的索引。resp := &AppendEntriesResponse{RPCHeader: r.getRPCHeader(), // 获取标准的RPC头部信息Term: r.getCurrentTerm(), // 响应中包含当前节点的TermLastLog: r.getLastIndex(), // 响应中包含当前节点的最后一个日志索引Success: false, // 初始设置为失败NoRetryBackoff: false, // 初始设置为允许重试退避}var rpcErr error // 用于存储处理过程中可能发生的错误// 使用 defer 确保在函数退出前发送响应。defer func() {rpc.Respond(resp, rpcErr)}()// 规则 1: 如果请求的Term小于当前节点的Term,则忽略该请求。// Leader的Term比Follower旧,说明该Leader已失效。if a.Term < r.getCurrentTerm() {return // 直接返回,不处理旧Term的AppendEntries}// 规则 2: 如果请求的Term大于当前节点的Term,或者当前节点不是Follower且不是正在进行领导权转移的Candidate,则更新Term,并转换为Follower状态。// 这是Raft的核心规则:看到更高的Term总是意味着过时,必须回退到Follower状态。if a.Term > r.getCurrentTerm() || (r.getState() != Follower && !r.candidateFromLeadershipTransfer.Load()) {r.setState(Follower)r.setCurrentTerm(a.Term)resp.Term = a.Term // 更新响应中的Term为新的当前Term}// 记录Leader的地址和ID。if len(a.Addr) > 0 {r.setLeader(r.trans.DecodePeer(a.Addr), ServerID(a.ID))} else {r.setLeader(r.trans.DecodePeer(a.Leader), ServerID(a.ID))}// 规则 3: 验证前一个日志条目的匹配性(Log Consistency Check)。// Leader在AppendEntries请求中包含新条目紧前一个条目的索引(PrevLogEntry)和Term(PrevLogTerm)。// Follower必须检查自己日志中对应索引的条目Term是否与Leader一致。if a.PrevLogEntry > 0 { // PrevLogEntry == 0 表示这是第一个日志条目,不需要检查前一个lastIdx, lastTerm := r.getLastEntry() // 获取当前节点的最后一个日志条目索引和Termvar prevLogTerm uint64 // 用于存储当前节点 PrevLogEntry 索引处的日志条目的Termif a.PrevLogEntry == lastIdx {// 如果 Leader 的 PrevLogEntry 恰好是当前节点的最后一个日志条目prevLogTerm = lastTerm // 直接使用最后一个日志条目的Term} else {// 如果 Leader 的 PrevLogEntry 不是当前节点的最后一个日志条目,需要从日志存储中获取var prevLog Log// 尝试获取 PrevLogEntry 索引处的日志条目if err := r.logs.GetLog(a.PrevLogEntry, &prevLog); err != nil {// 这种情况下,Leader应该回退并发送更早的日志,所以设置 NoRetryBackoff = trueresp.NoRetryBackoff = truereturn}prevLogTerm = prevLog.Term // 获取到日志条目,记录其Term}// 如果请求体中上次 term 跟当前 term 不一致, 则直接写失败.if a.PrevLogTerm != prevLogTerm {// Term 不匹配时,Leader 需要回退并发送更早的日志,所以设置 NoRetryBackoff = trueresp.NoRetryBackoff = truereturn}}// 规则 4: 处理新的日志条目。// 如果请求中包含新的日志条目 (a.Entries)if len(a.Entries) > 0 {start := time.Now() // 记录开始处理日志条目的时间// 删除任何冲突的条目,并跳过任何重复的条目。lastLogIdx, _ := r.getLastLog() // 获取当前节点的最后一个日志索引 (可能与 getLastEntry 不同,取决于实现细节,这里用于比较)var newEntries []*Log // 用于存放真正需要追加的新条目// 遍历 Leader 发送的日志条目for i, entry := range a.Entries {// 如果当前 Leader 条目的索引大于当前节点的最后一个日志索引,// 说明从这里开始的所有条目都是 Leader 新增的,可以直接追加。if entry.Index > lastLogIdx {newEntries = a.Entries[i:] // 将剩余的条目标记为需要追加的新条目break // 跳出循环,后续只处理 newEntries}// 如果 Leader 条目的索引不大于当前节点的最后一个日志索引,// 说明当前节点可能已经有了这个索引的条目,需要检查是否冲突。var storeEntry Log// 尝试从存储中获取当前索引的日志条目if err := r.logs.GetLog(entry.Index, &storeEntry); err != nil {return}// 对比 Leader 条目的Term和当前节点对应索引条目的Termif entry.Term != storeEntry.Term {// 删除从冲突索引到最后一个索引的日志范围if err := r.logs.DeleteRange(entry.Index, lastLogIdx); err != nil {// 删除日志失 r.logger.Error("failed to clear log suffix", "error", err)return}// 如果被删除的范围包含最新的配置变更日志条目,需要回退最新的配置信息if entry.Index <= r.configurations.latestIndex {// 将最新的配置设置为已提交的配置,索引也回退到已提交的索引r.setLatestConfiguration(r.configurations.committed, r.configurations.committedIndex)}// 从当前冲突的条目开始,Leader 的所有条目都视为新的,需要追加。newEntries = a.Entries[i:]break // 跳出循环,后续只处理 newEntries}// 如果索引小于等于 lastLogIdx 且 Term 匹配,说明这个条目是重复的,已经被 Follower 拥有且一致。// 继续循环检查下一个 Leader 条目。}// 如果有需要追加的新条目 (newEntries 列表不为空)if n := len(newEntries); n > 0 {// 将新条目追加到日志存储中。if err := r.logs.StoreLogs(newEntries); err != nil {return}// 处理任何新的配置变更日志条目。 需要在日志条目追加到存储后处理配置变更。for _, newEntry := range newEntries {// 对于每个新追加的条目,检查它是否是配置变更条目,并进行处理。if err := r.processConfigurationLogEntry(newEntry); err != nil {rpcErr = err // 记录RPC错误return}}// 更新当前节点的最后一个日志索引和Term,基于实际追加的最后一个条目。last := newEntries[n-1] // 获取追加的最后一个条目r.setLastLog(last.Index, last.Term) // 更新节点的 lastLog 状态}}// 规则 5: 更新当前节点的提交索引 (Commit Index)。// Leader 在 AppendEntries 请求中包含自己的提交索引 (LeaderCommitIndex)。// Follower 必须将自己的提交索引更新为 min(Leader 的提交索引, 自己最后一个日志条目的索引)。if a.LeaderCommitIndex > 0 && a.LeaderCommitIndex > r.getCommitIndex() {start := time.Now() // 记录开始处理提交的时间// 计算新的提交索引:取 Leader 的提交索引和当前节点最后一个日志索引的最小值。idx := min(a.LeaderCommitIndex, r.getLastIndex())// 更新当前节点的提交索引。r.setCommitIndex(idx)// 如果最新的配置变更日志条目索引小于等于新的提交索引,则表示该配置变更已提交。if r.configurations.latestIndex <= idx {// 将最新的配置设置为已提交的配置,并更新已提交的索引。r.setCommittedConfiguration(r.configurations.latest, r.configurations.latestIndex)}// 重点把 commitIndex 之前的日志提交到状态机 FSM 进行应用日志.。// 从旧的提交索引开始(或0)处理到新的提交索引 idx。r.processLogs(idx, nil) // nil 表示应用到默认的状态机 (或这里没有特定的应用函数)}// 如果执行到这里没有返回错误或因为旧Term/日志不匹配而提前返回,说明 AppendEntries 成功。resp.Success = true// 记录最后一次与Leader成功通信的时间。这用于重置选举超时定时器。r.setLastContact()
}
处理 RequestVoteRequest 投票请求
requestVote 函数处理来自其他 Raft 节点(候选者)的 RequestVote RPC 请求。其核心逻辑是根据 Raft 协议的选举规则决定是否授予投票。
核心流程:
-
前置检查:
- 检查候选者是否在当前配置中(如果提供了 ID)。如果不在且配置不为空,拒绝投票。
- 检查当前节点是否已知有其他领导者。如果已知且请求不是领导权转移,拒绝投票。
-
任期处理:
- 如果请求的任期小于当前任期,忽略该请求(不授予投票)。
- 如果请求的任期大于当前任期,更新当前节点的任期为请求任期,并转变为跟随者状态。更新响应中的任期。
-
投票者检查: 检查候选者是否是当前配置中的投票者(如果提供了 ID)。如果不是投票者且配置不为空,拒绝投票。
-
重复投票检查: 从持久化存储中获取上次投票的任期和候选者。如果在当前请求的任期内已经投过票,并且上次投票的候选者就是本次请求的候选者,则再次授予投票(处理幂等性);否则(投给了其他候选者或任期不同),不授予投票。
-
日志匹配检查:
检查候选者的日志是否至少和本地日志一样新。
- 如果本地日志的最后任期大于候选者的,拒绝投票。
- 如果本地日志的最后任期与候选者的相同,但本地日志的最后索引大于候选者的,拒绝投票。
-
授予投票:
如果通过了所有前面的检查,表示可以授予投票。
- 关键步骤: 在授予投票 之前,将本次投票的任期和候选者 ID 持久化到稳定存储中,确保安全性。
- 设置响应中的
Granted字段为 true。 - 更新本地的最后联系时间。
-
返回: 函数结束,延迟函数发送包含投票结果的响应。
总的来说,requestVote 函数实现了 Raft 协议中跟随者(或其他状态节点)响应候选者投票请求的核心逻辑,包括任期处理、日志匹配检查、投票持久化以及处理配置变更和领导权转移等特殊情况。
// requestVote 是当收到请求投票的 RPC 调用时被调用的函数。
// 该函数实现了 Raft 协议中处理投票请求的核心逻辑,包括检查候选人资格、更新状态、持久化投票信息等。
func (r *Raft) requestVote(rpc RPC, req *RequestVoteRequest) {// 使用 defer 记录该函数的执行时间,用于性能监控defer metrics.MeasureSince([]string{"raft", "rpc", "requestVote"}, time.Now())// 观察并记录请求,用于调试或监控r.observe(*req)// 初始化投票响应结构体resp := &RequestVoteResponse{RPCHeader: r.getRPCHeader(), // 设置 RPC 头部信息Term: r.getCurrentTerm(), // 设置当前节点的任期Granted: false, // 默认不授予投票}var rpcErr error // 用于存储 RPC 调用中的错误// 使用 defer 确保在函数返回时发送响应(无论是否发生错误)defer func() {rpc.Respond(resp, rpcErr)}()// 对于协议版本 < 2 的老版本服务器,需要提供 peers 信息,否则会引发 panic。// peers 信息仅用于生成警告信息。if r.protocolVersion < 2 {resp.Peers = encodePeers(r.configurations.latest, r.trans)}// 获取候选人的地址和 IDvar candidate ServerAddressvar candidateBytes []byte// ........忽略非核心代码........// 如果候选人的任期小于当前节点的任期,直接忽略请求if req.Term < r.getCurrentTerm() {return}// 如果候选人的任期大于当前节点的任期,则更新当前节点的任期,并转为 Follower 状态if req.Term > r.getCurrentTerm() {// 记录日志,说明因收到更高任期的投票请求而失去领导权r.logger.Debug("因收到更高任期的投票请求而失去领导权")r.setState(Follower) // 转为 Follower 状态r.setCurrentTerm(req.Term) // 更新当前任期resp.Term = req.Term // 更新响应中的任期}// 如果候选人是非投票节点(non-voter),且请求的任期高于当前任期,// 则当前节点需要退化为 Follower 并更新任期,但拒绝投票请求。// 这是为了在某些场景下(如节点从 voter 转为 non-voter)允许集群继续运行。// 更多细节可参考 https://github.com/hashicorp/raft/pull/526if len(req.ID) > 0 {candidateID := ServerID(req.ID)if len(r.configurations.latest.Servers) > 0 && !hasVote(r.configurations.latest, candidateID) {r.logger.Warn("拒绝投票请求,因为候选人是非投票节点", "from", candidate)return}}// 检查当前节点在本任期内是否已经投过票// 从稳定存储中获取上一次投票的任期和候选人信息lastVoteTerm, err := r.stable.GetUint64(keyLastVoteTerm)if err != nil && err.Error() != "not found" {r.logger.Error("获取上一次投票任期失败", "error", err)return}lastVoteCandBytes, err := r.stable.Get(keyLastVoteCand)if err != nil && err.Error() != "not found" {r.logger.Error("获取上一次投票候选人失败", "error", err)return}// 如果在本任期内已经投过票,检查是否为同一候选人if lastVoteTerm == req.Term && lastVoteCandBytes != nil {r.logger.Info("收到相同任期的重复投票请求", "term", req.Term)// 如果是同一候选人,则重复授予投票if bytes.Equal(lastVoteCandBytes, candidateBytes) {r.logger.Warn("收到重复的投票请求", "candidate", candidate)resp.Granted = true}return}// 检查候选人的日志是否足够新// 如果当前节点的最后日志条目的任期大于候选人的最后日志任期,则拒绝投票lastIdx, lastTerm := r.getLastEntry()if lastTerm > req.LastLogTerm {r.logger.Warn("拒绝投票请求,因为本节点的最后日志任期更大","candidate", candidate,"last-term", lastTerm,"last-candidate-term", req.LastLogTerm)return}// 如果日志任期相同,但当前节点的最后日志索引大于候选人的最后日志索引,则拒绝投票if lastTerm == req.LastLogTerm && lastIdx > req.LastLogIndex {r.logger.Warn("拒绝投票请求,因为本节点的最后日志索引更大","candidate", candidate,"last-index", lastIdx,"last-candidate-index", req.LastLogIndex)return}// 如果所有检查都通过,则持久化投票信息以确保安全性if err := r.persistVote(req.Term, candidateBytes); err != nil {r.logger.Error("持久化投票信息失败", "error", err)return}// 授予投票resp.Granted = true// 更新最后一次联系时间(用于检测领导者是否存活)r.setLastContact()
}
1.2 candidate 候选者运行逻辑
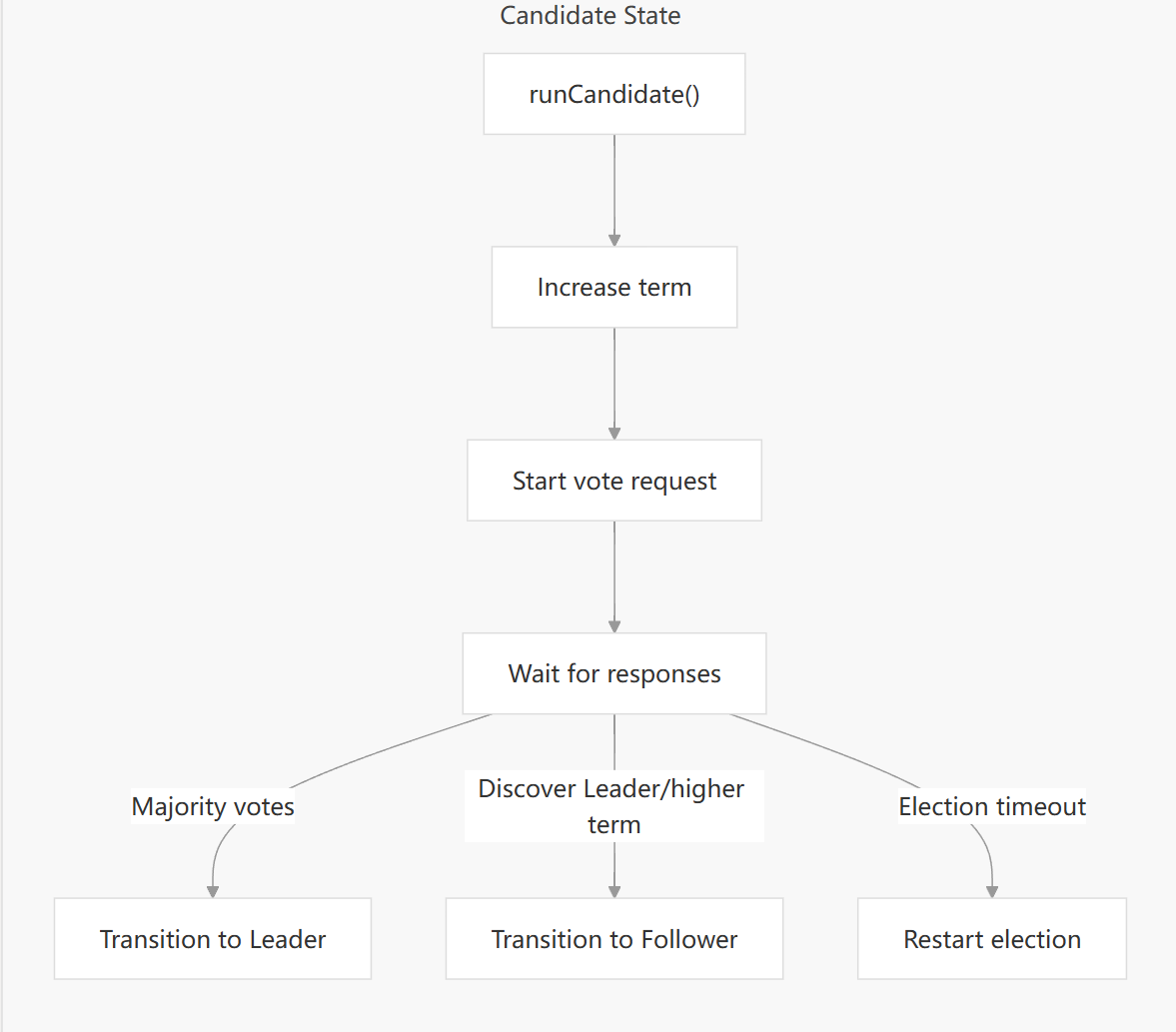
主要流程步骤:
- 任期更新与初始化:
- 节点将当前任期(Term)加一,进入新的任期进行选举。
- 记录日志和更新监控指标,表明进入 Candidate 状态。
- 计算赢得选举所需的多数派票数 (
votesNeeded)。
- 选举阶段选择(预投票 vs. 正式投票):
- 根据配置 (
preVoteDisabled) 和是否为领导权转移 (candidateFromLeadershipTransfer) 决定是先进行 预投票 (Pre-Vote) 还是直接进行 正式投票 (RequestVote)。 - 如果启用预投票且非领导权转移,调用
preElectSelf()发起预投票 RPC,监听prevoteCh。预投票不会改变任期,用于试探是否能获得多数支持。 - 否则,调用
electSelf()发起正式投票 RPC,监听voteCh。正式投票会携带新的任期号。
- 根据配置 (
- 设置选举超时:
- 设置一个随机化的选举超时定时器 (
electionTimer),防止多个 Candidate 同时超时并竞选,减少冲突。
- 设置一个随机化的选举超时定时器 (
- 主循环与事件处理:
- 进入一个循环,持续监听各种事件,直到节点状态不再是 Candidate。
- 使用 select语句同时监听:
- Incoming RPCs (
r.rpcCh): 处理来自其他节点的 RPC 请求(如 AppendEntries、RequestVote 等)。如果收到带有更高任期的 RPC,节点会立即转为 Follower 并更新任期,退出 Candidate 状态。 - 预投票结果 (
prevoteCh):- 如果收到带有更高任期的预投票响应,转为 Follower 并更新任期,退出 Candidate 状态。
- 统计收到的预投票赞成/反对票数。
- 如果获得多数派预投票赞成,认为预投票成功,关闭预投票监听**,**发起正式投票 (
electSelf()),重置选举定时器,开始等待正式投票结果。 - 如果被多数派预投票拒绝,预投票活动失败,继续等待当前的选举超时。
- 正式投票结果 (
voteCh):- 如果收到带有更高任期的投票响应,转为 Follower 并更新任期,退出 Candidate 状态。
- 统计收到的正式投票赞成票数。
- 遍历配置中的 server 集合, 过滤出状态为 Voter 的 server, 最后通过
n/2 + 1公式计算出法定投票数, 简单说就是绝大多数的节点数量.如果获得多数派正式投票赞成,赢得选举,转为 Leader 状态,设置自己为 Leader,退出 Candidate 状态。
- 配置变更请求 (
r.configurationChangeCh): 由于 Candidate 不是 Leader,拒绝此类请求并返回错误。 - 选举超时 (
electionTimer):如果在超时时间内未能赢得选举(无论是在预投票阶段等待,还是在正式投票阶段等待),则认为本次选举失败,函数return。由于外部调用runCandidate的逻辑通常在一个无限循环中,这将导致节点在新的任期中重新开始竞选过程。 - 节点关闭 (
r.shutdownCh): 收到关闭信号,退出循环和函数。
- Incoming RPCs (
- 退出处理:
- 无论通过哪种方式退出
runCandidate函数(成为 Follower、成为 Leader、shutdown、选举超时),都会执行defer中设置的逻辑,将candidateFromLeadershipTransfer标志重置为 false,防止其影响后续的选举行为。
- 无论通过哪种方式退出
相关源码:
// 在 Raft 算法中,当 Follower 心跳超时且满足选举条件时,会进入 Candidate 状态,尝试成为 Leader。
func (r *Raft) runCandidate() {// 1. 更新当前任期(Term),Candidate 总是在新的任期中发起选举term := r.getCurrentTerm() + 1// 记录日志:节点进入 Candidate 状态,并附带当前节点信息和任期号r.logger.Info("entering candidate state", "node", r, "term", term)// 增加监控指标:记录节点进入 Candidate 状态的次数metrics.IncrCounter([]string{"raft", "state", "candidate"}, 1)// 2. 发起选举前的准备:决定是先进行预投票(Pre-Vote)还是直接正式投票(RequestVote)var voteCh <-chan *voteResult // 正式投票结果通道var prevoteCh <-chan *preVoteResult // 预投票结果通道// 检查是否启用预投票机制(pre-vote),并且当前 Candidate 状态不是由领导权转移(Leadership Transfer)触发的// 领导权转移场景下,Raft 协议规定跳过预投票,直接请求投票(避免额外的延迟)if !r.preVoteDisabled && !r.candidateFromLeadershipTransfer.Load() {// 发起预投票(Pre-Vote):询问其他节点是否同意在新任期中投票给自己// 预投票不会真正增加任期号,只是试探能不能赢得选举,避免无效的 Term 增长prevoteCh = r.preElectSelf()} else {// 直接发起正式投票(RequestVote):向其他节点请求在新任期中投票voteCh = r.electSelf()}// 3. 确保领导权转移标志(candidateFromLeadershipTransfer)在函数退出时重置defer func() { r.candidateFromLeadershipTransfer.Store(false) }()// 4. 设置选举超时时间(ElectionTimeout),随机化防止多个 Candidate 同时发起选举electionTimeout := r.config().ElectionTimeoutelectionTimer := randomTimeout(electionTimeout)// 5. 初始化投票计数器preVoteGrantedVotes := 0 // 预投票中获得的赞同票数preVoteRefusedVotes := 0 // 预投票中获得的反对票数grantedVotes := 0 // 正式投票中获得的赞同票数votesNeeded := r.quorumSize() // 计算当选所需的最小票数(多数派,N/2 + 1)// 打印调试日志:显示当前任期需要的最少票数r.logger.Debug("calculated votes needed", "needed", votesNeeded, "term", term)// 6. 主循环:持续处理事件,直到状态不再是 Candidatefor r.getState() == Candidate {// 标记主线程当前处于休眠(等待事件)状态,用于监控线程忙碌程度r.mainThreadSaturation.sleeping()// 通过 select 监听多个通道,处理不同事件select {// 7.1 处理来自其他节点的 RPC 请求(可能是投票响应、日志复制、心跳等)case rpc := <-r.rpcCh:r.mainThreadSaturation.working() // 标记线程从休眠中醒来,开始工作r.processRPC(rpc) // 处理 RPC 请求(如 AppendEntries、RequestVote 等)// 7.2 处理预投票(Pre-Vote)结果监听 prevoteCh 通道,处理预投票结果。// 如果预投票返回的任期高于当前任期,说明有更新的 Leader,节点退回 Follower 状态并更新任期。// 统计预投票的赞同票和反对票:// 如果赞同票达到多数派(preVoteGrantedVotes >= votesNeeded),预投票成功,进入正式投票阶段(发起 electSelf)。// 如果反对票达到多数派(preVoteRefusedVotes >= votesNeeded),预投票失败,等待选举超时后重试。case preVote := <-prevoteCh:// .....忽略非核心代码......// 7.3 处理正式投票(RequestVote)结果case vote := <-voteCh:r.mainThreadSaturation.working()// 7.3.1 如果对方返回更高的任期,说明已有新 Leader,Candidate 放弃竞选,退回 Followerif vote.Term > r.getCurrentTerm() {r.logger.Debug("newer term discovered, fallback to follower", "term", vote.Term)r.setState(Follower)r.setCurrentTerm(vote.Term)return}// 7.3.2 统计正式投票结果if vote.Granted {grantedVotes++ // 赞成票 +1r.logger.Debug("vote granted", "from", vote.voterID, "term", vote.Term, "tally", grantedVotes)}// 7.3.3 检查是否赢得选举(获得多数派投票)if grantedVotes >= votesNeeded {// 赢得选举!成为 Leaderr.logger.Info("election won", "term", vote.Term, "tally", grantedVotes)r.setState(Leader) // 状态切换为 Leaderr.setLeader(r.localAddr, r.localID) // 设置自己为 Leaderreturn // 退出 Candidate 循环,进入 Leader 逻辑}// 7.4 以下 case 都是拒绝非 Leader 请求,因为 Candidate 还不是 Leadercase c := <-r.configurationChangeCh: // 集群配置变更请求r.mainThreadSaturation.working()c.respond(ErrNotLeader) // 返回错误:当前不是 Leader// .....忽略非核心代码......case <-electionTimer:// 选举超时r.mainThreadSaturation.working()// Election failed! Restart the election. We simply return,// which will kick us back into runCandidater.logger.Warn("Election timeout reached, restarting election")returncase <-r.shutdownCh:return}}
}
1.3 leader 领导者运行逻辑
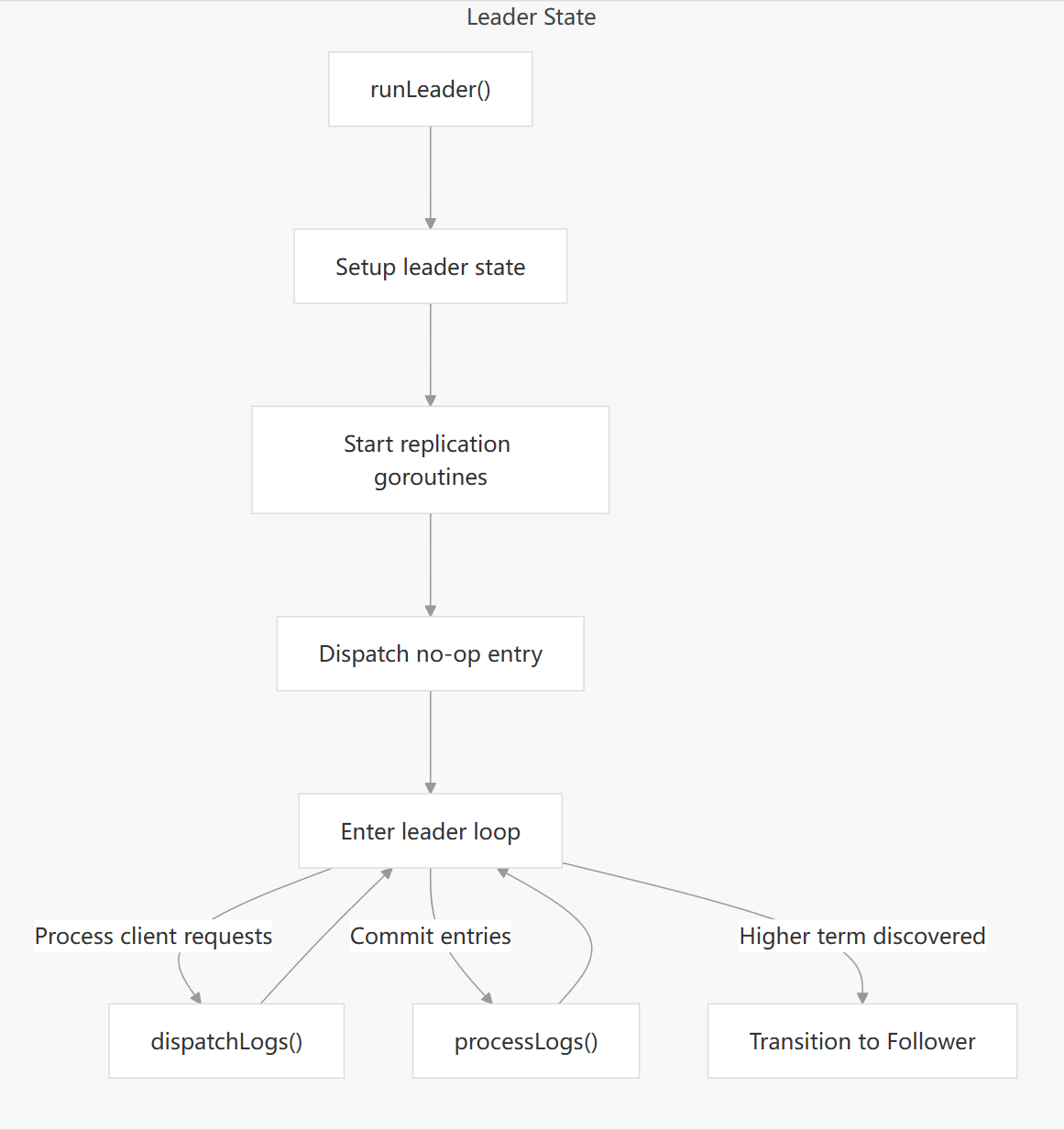
主要逻辑:
runLeader 为 leader 领导者的核心处理方法. 进入该函数说明当前节点为 leader.
startStopReplication启动各个 follower 的 replication, 开启心跳 heartbeat 和同步 replicate 协程.- 构建一个 LogNoop 空日志, 然后通过
dispatchLogs方法发给所有的 follower 副本. 这里的空日志用来向 follower 通知确认 leader, 并获取各 follower 的一些日志元信息. leaderLoop为 leader 的主调度循环.响应 Follower 的复制进度、处理新的客户端请求、复制日志、管理集群配置变更、处理领导权转移、定期验证自身的 Leader 身份,并在需要时触发降级。
相关源码:
// runLeader 运行 Raft 节点处于 Leader(领导者)状态时的主逻辑。
// 它首先进行 Leader 状态的初始化设置,然后进入 leaderLoop 循环,持续处理集群管理工作。
func (r *Raft) runLeader() {// 1. 日志记录:节点进入 Leader 状态,并附带当前 Leader 实例信息r.logger.Info("entering leader state", "leader", r)// 2. 增加监控指标:统计进入 Leader 状态的次数metrics.IncrCounter([]string{"raft", "state", "leader"}, 1)// 3. 通知外部监听者:当前节点已成为 Leader// 通过 leaderCh 管道通知状态变更,overrideNotifyBool 会确保只有 true 值能被推送(防止重复通知)overrideNotifyBool(r.leaderCh, true)// 4. 获取配置中的通知通道(NotifyCh),用于向外部应用发送 Leader 变化通知// 这个 NotifyCh 是由用户创建并传入 Raft 配置的,用于监听 Leader 切换事件notify := r.config().NotifyCh// 5. 如果配置了 NotifyCh,立即推送 Leader=true 信号if notify != nil {select {case notify <- true: // 尝试推送通知case <-r.shutdownCh: // 如果收到关闭信号,确保推送通知(但不阻塞)select {case notify <- true: // 再次尝试推送default: // 无法推送时忽略(防止阻塞 shutdown)}}}// 6. 初始化 Leader 状态结构体(leaderState),包含:// - commitCh:用于通知日志提交事件// - inflight:待提交的日志队列// - replState:每个 Follower 的复制状态机// - notify:待验证请求的回调队列r.setupLeaderState()// 7. 启动后台协程,定期汇报日志存储的年龄(最老日志的时间戳),用于监控日志堆积情况stopCh := make(chan struct{})go emitLogStoreMetrics(r.logs, []string{"raft", "leader"}, oldestLogGaugeInterval, stopCh)// 8. 定义 defer 清理逻辑,当 Leader 降级(step down)时执行,停止相关任务,通知降级defer func() {// .....忽略非核心代码......}()// 9. 启动日志复制机制:启动各个 follower 的 replication, 开启心跳 heartbeat 和同步 replicate 协程.// 这些协程会定期向 Follower 发送 AppendEntries RPC,保持日志同步r.startStopReplication()// 10. 构建一个 LogNoop 空日志, 然后通过 dispatchLogs 方法发给所有的 follower 副本. 这里的空日志用来向 follower 通知确认 leader, 并获取各 follower 的一些日志元信息.noop := &logFuture{log: Log{Type: LogNoop}} // 构造空日志条目r.dispatchLogs([]*logFuture{noop}) // 分发日志,触发复制流程// 11. 进入 Leader 主循环(leaderLoop):持续处理日志复制、心跳、成员管理等核心逻辑// 直到因选举超时、收到更高 Term RPC 等原因降级(step down)r.leaderLoop()
}
startStopReplication
启动日志复制机制:启动各个 follower 的 replication, 开启心跳 heartbeat 和同步日志.
为什么需要 leader 给 follower 发送心跳 ? raft 论文里有说明, 当 follower 在一段时间内收不到 leader 的心跳请求时, 则判定 leader 有异常, 切换到 candidate 进行选举 election.
关于replicate 如何进行日志复制,将在下一篇文章介绍
func (r *Raft) startStopReplication() {for _, server := range r.configurations.latest.Servers {// server 为本实例无需启动 replication 复制副本.if server.ID == r.localID {continue}s, ok := r.leaderState.replState[server.ID]if !ok {s = &followerReplication{...}r.leaderState.replState[server.ID] = s// 启动 replication 复制副本r.goFunc(func() { r.replicate(s) })}}
}func (r *Raft) replicate(s *followerReplication) {...// 启动一个 heartbeat 心跳协程r.goFunc(func() { r.heartbeat(s, stopHeartbeat) })......
}
// replicate 是一个长期运行的 goroutine,负责心跳机制和将日志条目(log entries)复制到 单个 follower 节点。
func (r *Raft) replicate(s *followerReplication) {// 步骤 1:启动异步心跳线程// 创建一个停止信号通道,用于终止心跳 goroutinestopHeartbeat := make(chan struct{})// 函数结束时关闭该通道,确保心跳 goroutine 退出defer close(stopHeartbeat)// 启动一个 heartbeat 心跳协程// 心跳用于维持 Leader 身份、避免选举超时,但不携带日志数据r.goFunc(func() {// 调用 r.heartbeat 函数,定期发送 AppendEntries RPC(空日志)r.heartbeat(s, stopHeartbeat)})// RPC 模式(标准复制模式)// 在此模式下,Leader 逐条确认(Stop-and-Wait) follower 的日志复制结果
RPC:// 控制变量:标记是否应该停止复制循环shouldStop := falsefor !shouldStop {select {// .....忽略非核心代码......// 情况 3:收到主动触发信号(立即同步日志)case <-s.triggerCh:// 获取最新日志索引lastLogIdx, _ := r.getLastLog()// 调用 replicateTo 同步日志到最新位置shouldStop = r.replicateTo(s, lastLogIdx)// .....忽略非核心代码......// 性能优化判断:是否切换到 Pipeline 模式?// 1. 当前复制 未出错(!shouldStop)// 2. 允许 Pipeline 模式(s.allowPipeline=true)if !shouldStop && s.allowPipeline {// 跳转到 PIPELINE 标签处,进入流式复制逻辑goto PIPELINE}}// 如果循环退出(shouldStop=true),直接结束 replicate 函数return// PIPELINE 模式(流式复制,高性能)// 在此模式下,Leader 连续发送日志、不等待确认(类似 TCP 滑动窗口)
PIPELINE:s.allowPipeline = false// 进入 pipelineReplicate 函数:// 它会:// 1. 持续发送 AppendEntries RPC **不等待响应**// 2. 通过 TCP 连接批量流式发送日志,提高吞吐量// 注意:此模式 **无法优雅处理错误**,一旦出错就回退到 RPC 模式if err := r.pipelineReplicate(s); err != nil {// .....忽略非核心代码......}// 无论成功与否,Pipeline 失败后都回到 RPC 模式// 即:重新启用逐条确认机制,确保健壮性goto RPC
}
leaderLoop
leaderLoop 是 Leader 状态下的大脑,它不断监听和处理各种事件,核心职责包括:响应 Follower 的复制进度、处理新的客户端请求、复制日志、管理集群配置变更、处理领导权转移、定期验证自身的 Leader 身份,并在需要时触发降级。
-
初始化:
- 设置一个
stepDown标志,用于标记 Leader 是否因配置变更(尤其是移除自身)等原因需要降级。 - 初始化 Leader Lease(租约)计时器,用于定期验证 Leader 身份。
- 设置一个
-
进入主循环:
- 节点进入一个无限循环,只要其状态保持为
Leader就会持续运行。
- 节点进入一个无限循环,只要其状态保持为
-
事件驱动处理: 在循环中,通过
select语句监听多个通道,处理来自外部或内部的各种事件:-
接收 RPC 请求 (
rpcCh):处理来自其他节点的 RPC,包括:
- Follower 对 Leader 发送的 AppendEntries RPC 的响应(确认日志复制进度)。
- 来自其他节点的 RequestVote RPC(如果发现更高任期,Leader 会立即降级为 Follower)。
- 其他可能的 RPC。
-
内部降级信号 (
leaderState.stepDown): 收到信号后,Leader 立即转为 Follower 状态,并退出循环。 -
领导权转移请求 (
leadershipTransferCh):- 处理手动触发的领导权转移请求。
- 检查是否已有转移正在进行。
- 选择或确认目标 Follower。
- 启动一个后台协程来执行转移逻辑(通常涉及等待日志同步并向目标 Follower 发送 TimeoutNow RPC)。
- 设置标志防止并行转移,并处理超时或 Leader 自身降级的情况。
-
日志提交通知 (
leaderState.commitCh):- 当有日志条目被多数节点复制成功(达到可提交状态)时收到此通知。
- 更新 Leader 的
commitIndex(已提交日志的最大索引)。 - 检查是否有新的配置变更日志被提交,如果 Leader 自己被移除,则设置
stepDown标志。 - 从待提交队列 (
inflight) 中找出所有已落后于commitIndex的日志。 - 批量应用日志: 将这些已提交的日志批量应用到状态机 (FSM - State Machine),处理其副作用(如配置变更执行)。
- 清理已应用的日志。
- 如果
stepDown标志被设置,根据配置选择关闭节点或降级为 Follower。
-
Leader 验证请求 (
verifyCh):- 这是 Leader Lease 机制的一部分。Leader 定期向 Follower 发送验证请求。
- 处理来自验证请求的响应。如果未能获得多数节点的确认,说明可能已有新的 Leader 出现,当前 Leader 降级为 Follower。
-
用户快照恢复请求 (
userRestoreCh): 处理从用户提供的快照恢复状态的请求。 -
获取配置请求 (
configurationsCh): 处理客户端获取当前集群配置的请求。 -
配置变更请求 (
configurationChangeChIfStable()):- 处理添加或移除节点等集群配置变更请求。
- 将配置变更作为特殊的日志条目追加到 Raft 日志中,并像普通日志一样复制和提交。
-
引导请求 (
bootstrapCh): 拒绝运行时的引导请求,因为 Raft 只在初始状态允许引导。 -
新日志条目请求 (
applyCh):- 处理来自客户端的新的命令或数据请求。
- 批量提交优化: 尝试从通道中一次性读取多个待处理的客户端请求,进行批量处理。
- 如果
stepDown标志已设置,拒绝新的日志请求。 - 将这些新的请求封装成日志条目,追加到 Leader 的日志中。
- 分发日志: 将这些新日志条目分发(通过 AppendEntries RPC)给所有 Follower,驱动日志复制过程。
-
Leader Lease 计时器超时 (
lease):- 定期触发 Leader Lease 检查。
- 调用
checkLeaderLease方法验证 Leader 身份。 - 根据检查结果调整下一个租约检查的间隔,并重置计时器。
- 如果租约验证失败,也可能触发降级。
-
通知通道 (
leaderNotifyCh,followerNotifyCh): 用于唤醒等待特定事件的内部协程。 -
关机信号 (
shutdownCh): 收到信号后,Leader 退出循环并停止运行。
-
-
退出: 循环在以下情况下退出:
- Leader 状态改变为 Follower(因发现更高任期、收到降级信号、Leader Lease 验证失败或自身被移除)。
- 节点收到关机信号。
// leaderLoop 是 Leader 状态下的核心循环。
// 它在 Leader 所有初始化设置完成后被调用,负责处理日志复制、心跳、成员管理等核心逻辑。
func (r *Raft) leaderLoop() {// 1. stepDown 标志:用于判断是否有正在进行的日志操作会导致 Leader 降级// 典型场景:Leader 收到移除自己(RemovePeer)的日志请求,此时不能并行处理其他日志,// 否则提交判断只依赖单个节点(自己),复制目标也不明确(未知的 Peer 集合)。stepDown := false// 2. 初始化 Leader Lease(租约)计时器,用于检查 Leader 是否仍然有效lease := time.After(r.config().LeaderLeaseTimeout)// 3. Leader 主循环:持续运行,直到状态不再是 Leaderfor r.getState() == Leader {// 标记主线程当前处于休眠(等待事件)状态,用于监控线程忙碌程度r.mainThreadSaturation.sleeping()select {// 4.1 处理来自其他节点的 RPC 请求(可能是投票、日志复制、心跳响应等)case rpc := <-r.rpcCh:r.mainThreadSaturation.working() // 标记线程从休眠中醒来,开始工作r.processRPC(rpc) // 处理 RPC 请求(如 AppendEntriesResponse、RequestVote 等)// 4.2 收到降级信号(通常是配置变更导致 Leader 需要下台)case <-r.leaderState.stepDown:r.mainThreadSaturation.working()// 立即降级为 Follower,退出 Leader 循环r.setState(Follower)// 4.3 处理领导权转移(Leadership Transfer)请求:手动切换 Leadercase future := <-r.leadershipTransferCh:// .....忽略非核心代码......// 4.4 处理日志提交事件(commitCh):有新日志被多数派确认case <-r.leaderState.commitCh:r.mainThreadSaturation.working()// 4.4.1 更新本地 commitIndex(已提交日志的最大索引)oldCommitIndex := r.getCommitIndex()commitIndex := r.leaderState.commitment.getCommitIndex()r.setCommitIndex(commitIndex)// 4.4.2 检查新提交的配置日志(Configuration Entry)if r.configurations.latestIndex > oldCommitIndex &&r.configurations.latestIndex <= commitIndex {// 新配置已提交,更新 committedConfigurationr.setCommittedConfiguration(r.configurations.latest, r.configurations.latestIndex)// 如果 Leader 发现自己被移除了(不再是 Voter),标记 stepDownif !hasVote(r.configurations.committed, r.localID) {stepDown = true}}// 4.4.3 批量处理已提交的日志(Group Commit)start := time.Now()var groupReady []*list.Element // 待处理的已提交日志队列groupFutures := make(map[uint64]*logFuture) // 日志索引 -> logFuture 映射var lastIdxInGroup uint64 // 最后一个日志的索引// 遍历 inflight(待提交日志队列),找出所有已达到 commitIndex 的日志for e := r.leaderState.inflight.Front(); e != nil; e = e.Next() {commitLog := e.Value.(*logFuture)idx := commitLog.log.Indexif idx > commitIndex { // 超过 commitIndex 的日志跳过break}// 统计日志提交延迟(从分发到提交的时间)metrics.MeasureSince([]string{"raft", "commitTime"}, commitLog.dispatch)// 加入待处理队列groupReady = append(groupReady, e)groupFutures[idx] = commitLoglastIdxInGroup = idx}// 4.4.4 批量应用已提交日志到状态机(FSM)if len(groupReady) != 0 {r.processLogs(lastIdxInGroup, groupFutures)// 清理已处理的日志,防止重复提交for _, e := range groupReady {r.leaderState.inflight.Remove(e)}}// 统计日志入队耗时(FSM 应用延迟)metrics.MeasureSince([]string{"raft", "fsm", "enqueue"}, start)// 统计本次提交的日志数量metrics.SetGauge([]string{"raft", "commitNumLogs"}, float32(len(groupReady)))// 4.4.5 如果 Leader 发现自己被移除了(stepDown=true)if stepDown {if r.config().ShutdownOnRemove {// 配置要求移除时关闭节点,优雅退出r.logger.Info("removed ourself, shutting down")r.Shutdown()} else {// 否则降级为 Followerr.logger.Info("removed ourself, transitioning to follower")r.setState(Follower)}}// 4.5 处理成员验证请求(verifyCh):检查 Leader 是否仍然有效case v := <-r.verifyCh:// .....忽略非核心代码......// 处理客户端提交的日志条目(新命令)case newLog := <-r.applyCh:r.mainThreadSaturation.working()// 检查领导权转移状态if r.getLeadershipTransferInProgress() {r.logger.Debug(ErrLeadershipTransferInProgress.Error())newLog.respond(ErrLeadershipTransferInProgress)continue}// **批量提交(Group Commit)优化**:// 先将第一个日志条目放入待提交数组ready := []*logFuture{newLog}GROUP_COMMIT_LOOP:// 尝试在短时间内尽可能多地收集更多待提交日志(批量处理)for i := 0; i < r.config().MaxAppendEntries; i++ {select {// 非阻塞尝试从 applyCh 读取更多日志case newLog := <-r.applyCh:// 追加到待提交数组ready = append(ready, newLog)default:// 如果没有更多日志可读,则跳出循环break GROUP_COMMIT_LOOP}}// 判断当前节点是否正在 **降级为 follower(stepDown=true)**if stepDown {// 若是,则拒绝处理新日志,回应“当前不是 Leader”for i := range ready {ready[i].respond(ErrNotLeader)}} else {// 否则,统一 **分发这些日志条目** 到 Raft 状态机处理(复制到 followers)r.dispatchLogs(ready)}// .....忽略非核心代码......case <-r.shutdownCh:return}}
}
dispatchLogs 日志调度派发
dispatchLogs 用来记录本地日志以及派发日志给所有的 follower. 数据来源主要通过leedloop中的applyCh实现新的日志信息
// 处理客户端提交的日志条目(新命令)
case newLog := <-r.applyCh:
- 日志持久化:
- 将日志写入本地磁盘,确保日志的持久化。如果写入失败,Leader 节点会降级为 Follower 节点,并通知调用者操作失败。
- 状态更新:
- commitment.match 来计算各个 server 的 matchIndex, 计算出 commit 提交索引.
- 更新 Leader 节点的匹配索引(
match index),表示本地节点已成功存储日志。 - 更新 Leader 节点的最后日志索引和任期信息。
- 触发日志复制:
- 异步通知所有 Follower 节点的复制器,触发日志复制流程,确保日志被同步到集群中的其他节点。
// dispatchLogs 是 Raft 协议中 Leader 节点用于处理日志分发的核心方法,
// 它的主要功能是将一批待应用的日志写入本地磁盘,标记这些日志为“inflight”(inflight),
// 并开始将这些日志复制到 Follower 节点。
func (r *Raft) dispatchLogs(applyLogs []*logFuture) {// 记录方法开始执行的时间,用于后续性能指标的统计now := time.Now()// 使用 defer 延迟执行性能指标的统计,计算方法执行的总耗时defer metrics.MeasureSince([]string{"raft", "leader", "dispatchLog"}, now)// 获取当前 Leader 的任期(term),用于标记新日志的任期信息term := r.getCurrentTerm()// 获取当前日志的最后索引(lastIndex),用于为新日志分配连续的索引号lastIndex := r.getLastIndex()n := len(applyLogs) // 获取待分发的日志数量logs := make([]*Log, n) // 创建一个日志切片,用于存储待写入磁盘的日志条目// 设置性能指标:记录当前分发的日志数量metrics.SetGauge([]string{"raft", "leader", "dispatchNumLogs"}, float32(n))// 遍历待分发的日志,为每条日志设置索引、任期和时间戳,并标记为“inflight”for idx, applyLog := range applyLogs {applyLog.dispatch = now // 设置日志的调度时间戳,表示日志开始被分发的时间lastIndex++ // 为日志分配新的索引号,递增 lastIndexapplyLog.log.Index = lastIndex // 设置日志的索引号applyLog.log.Term = term // 设置日志的任期号为当前 Leader 的任期applyLog.log.AppendedAt = now // 设置日志的追加时间戳,表示日志被追加到日志存储的时间logs[idx] = &applyLog.log // 将日志条目存储到 logs 切片中,准备写入磁盘r.leaderState.inflight.PushBack(applyLog) // 将日志标记为“飞行中”,表示该日志正在被处理(尚未被所有节点确认)}// 将日志条目写入本地磁盘,确保日志持久化if err := r.logs.StoreLogs(logs); err != nil {// 如果写入失败,记录错误日志r.logger.Error("failed to commit logs", "error", err)// 遍历所有待分发的日志,通知调用者写入失败for _, applyLog := range applyLogs {applyLog.respond(err)}// 如果日志写入失败,Leader 节点主动降级为 Follower 节点,避免继续处理请求r.setState(Follower)return}// 如果日志成功写入本地磁盘,更新 Leader 节点的匹配索引(match index),// 表示本地节点已经成功存储了这些日志r.leaderState.commitment.match(r.localID, lastIndex)// 更新 Leader 节点的最后日志索引和任期信息,表示最新的日志状态r.setLastLog(lastIndex, term)// 通知所有 Follower 节点的复制器(replicator),触发日志复制// 遍历 Leader 节点维护的每个 Follower 节点的复制状态for _, f := range r.leaderState.replState {// 异步通知复制器的触发通道(triggerCh),启动日志复制流程asyncNotifyCh(f.triggerCh)}
}
四、问题
- 问题 1:Raft 如何处理网络分区?
- 解答:Raft 通过领导人选举和多数派机制来处理网络分区。
- 分区形成: 当网络分区发生时,集群可能分裂成多个部分,每个部分都无法与多数节点通信。
- 选举: 在每个分区中,如果 Follower 节点在选举超时时间内没有收到 Leader 的心跳,它们会发起选举。
- 多数派: 只有包含多数节点的分区才能选出新的 Leader。少数派分区中的节点无法赢得选举,因为它们无法获得多数票。
- 旧 Leader: 如果旧 Leader 位于少数派分区,它会因为无法与多数节点通信而退位成 Follower。
- 数据一致性: Raft 保证,即使在网络分区的情况下,也只有一个分区能够提交新的日志条目,从而保证数据一致性。
- 分区恢复: 当网络分区恢复后,少数派分区中的节点会重新加入集群,并从新 Leader 那里同步最新的日志。
- 解答:Raft 通过领导人选举和多数派机制来处理网络分区。
- 问题 2:Raft 如何保证数据一致性?
- 解答:Raft 通过以下机制保证数据一致性:
- 强领导者: 只有 Leader 才能接受客户端请求并生成新的日志条目。
- 日志复制: Leader 将日志条目复制到所有 Follower。只有当多数 Follower 确认收到日志条目后,Leader 才会提交该条目。
- 仅追加日志: 日志条目只能追加到日志末尾,不能修改或删除。
- 选举限制: 只有拥有最新日志的节点才能成为 Leader。
- 提交限制: 只有 Leader 才能推进
commitIndex,且commitIndex只会单调递增。 - 状态机: 所有节点按照相同的顺序应用已提交的日志条目到状态机,保证状态机状态一致。
- 解答:Raft 通过以下机制保证数据一致性:
- 问题 3:Raft 中的
commitIndex和lastApplied有什么区别?- 解答:
commitIndex: 表示已知已提交的最高日志条目的索引。这意味着索引小于或等于commitIndex的所有日志条目都已安全地复制到多数节点,可以应用到状态机。lastApplied: 表示已应用到状态机的最高日志条目的索引。每个节点独立维护自己的lastApplied。- 关系:
lastApplied通常小于或等于commitIndex。当lastApplied小于commitIndex时,表示节点正在将已提交的日志条目应用到状态机。当两者相等时,表示状态机是最新的。
- 解答:
- 问题 4:Raft 如何处理客户端请求的幂等性?
- 解答:Raft 本身不直接处理客户端请求的幂等性。幂等性通常需要在客户端或应用层实现。一种常见的做法是:
- 客户端生成唯一 ID: 客户端为每个请求生成一个唯一的 ID(例如 UUID)。
- 服务器跟踪 ID: 服务器跟踪已处理的请求 ID。如果收到具有相同 ID 的重复请求,服务器可以直接返回之前的结果,而无需重新执行操作。
- 状态机: 在应用层,状态机可以记录已执行的请求 ID,以避免重复执行。
- 解答:Raft 本身不直接处理客户端请求的幂等性。幂等性通常需要在客户端或应用层实现。一种常见的做法是:
五、参考链接
1.Hashicorp Raft实现和API分析
2.hashicorp raft源码学习
3.源码分析 hashicorp raft replication 日志复制的实现原理