map常用接口及模拟实现
目录
1>容器
2>map的使用
a.概念
b.pair类型介绍
c.构造
d.增删查
e.数据修改
f.构造遍历和增删查
g.迭代器和[]
h.multimap和map的差异
i.Leecode
① 随机链表
② 前K个高频单词
③ 单词识别
1>容器
本篇文章介绍的map底层也是红⿊树,红⿊树是⼀颗平衡⼆叉搜索树。而set是key搜索场景的结构, map是key/value搜索场景的结构
2>map的使用
map和multimap参考⽂档
<map> - C++ Reference
a.概念
map的声明如下,Key就是map底层关键字的类型,T是map底层value的类型,set默认要求Key⽀持⼩于⽐较,如果不⽀持或者需要的话可以⾃⾏实现仿函数传给第⼆个模版参数,map底层存储数据的内存是从空间配置器申请的,⼀般情况下,我们都不需要传后两个模版参数
map底层是⽤红⿊树实现,增删查改效率是 O(logN) ,迭代器遍历是⾛的中序,所以是按key有序顺序遍历的
template < class Key, // map::key_typeclass T, // map::mapped_typeclass Compare = less<Key>, // map::key_compareclass Alloc = allocator<pair<const Key, T> > //map::allocator_type> class map;b.pair类型介绍
map底层的红⿊树节点中的数据,使⽤pair<Key, T>存储键值对数据
typedef pair<const Key, T> value_type;template <class T1, class T2>
struct pair
{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;pair() : first(T1()), second(T2()){}pair(const T1& a, const T2& b) : first(a), second(b){}template<class U, class V>pair(const pair<U, V>& pr) : first(pr.first), second(pr.second){}
};template <class T1, class T2>
inline pair<T1, T2> make_pair(T1 x, T2 y)
{return (pair<T1, T2>(x, y));
}c.构造
map的⽀持正向和反向迭代遍历,遍历默认按key的升序顺序,因为底层是⼆叉搜索树,迭代器遍历⾛的中序;⽀持迭代器就意味着⽀持范围for,map⽀持修改value数据,不⽀持修改key数据,修改关键字数据,破坏了底层搜索树的结构
// empty (1) ⽆参默认构造
explicit map(const key_compare& comp = key_compare(),const allocator_type& alloc = allocator_type());// range (2) 迭代器区间构造
template <class InputIterator>
map(InputIterator first, InputIterator last,const key_compare& comp = key_compare(),const allocator_type & = allocator_type());// copy (3) 拷⻉构造
map(const map& x);
// initializer list (5) initializer 列表构造
map(initializer_list<value_type> il,const key_compare& comp = key_compare(),const allocator_type& alloc = allocator_type());// 迭代器是⼀个双向迭代器
iterator->a bidirectional iterator to const value_type
// 正向迭代器
iterator begin();
iterator end();
// 反向迭代器
reverse_iterator rbegin();
reverse_iterator rend();d.增删查
map增接⼝,插⼊的pair键值对数据,跟set所有不同,但是查和删的接⼝只⽤关键字key跟set是完全类似的,不过find返回iterator,不仅仅可以确认key在不在,还找到key映射的value,同时通过迭代还可以修改value
Member types
key_type->The first template parameter(Key)
mapped_type->The second template parameter(T)
value_type->pair<const key_type, mapped_type>// 单个数据插⼊,如果已经key存在则插⼊失败,key存在相等value不相等也会插⼊失败
pair<iterator, bool> insert(const value_type& val);// 列表插⼊,已经在容器中存在的值不会插⼊
void insert(initializer_list<value_type> il);// 迭代器区间插⼊,已经在容器中存在的值不会插⼊
template <class InputIterator>
void insert(InputIterator first, InputIterator last);// 查找k,返回k所在的迭代器,没有找到返回end()
iterator find(const key_type& k);// 查找k,返回k的个数
size_type count(const key_type& k) const;// 删除⼀个迭代器位置的值
iterator erase(const_iterator position);// 删除k,k存在返回0,存在返回1
size_type erase(const key_type& k);// 删除⼀段迭代器区间的值
iterator erase(const_iterator first, const_iterator last);// 返回⼤于等k位置的迭代器
iterator lower_bound(const key_type& k);// 返回⼤于k位置的迭代器
const_iterator lower_bound(const key_type& k) const;e.数据修改
map第⼀个⽀持修改的⽅式是通过迭代器,迭代器遍历时或者find返回key所在的iterator修改,map还有⼀个⾮常重要的修改接⼝operator[],但是operator[]不仅仅⽀持修改,还⽀持插⼊数据和查找数据,所以他是⼀个多功能复合接⼝
这里需要注意从内部实现⻆度,map这⾥把我们传统说的 value 值,给的是T类型,typedef 为 mapped_type。⽽ value_type 是红⿊树结点中存储的 pair 键值对值,Key是键的类型,T是值的类型
(⽇常使⽤我们还是习惯将这⾥的T映射值叫做value)
Member types
key_type->The first template parameter(Key)
mapped_type->The second template parameter(T)
value_type->pair<const key_type, mapped_type>// 查找k,返回k所在的迭代器,没有找到返回end(),如果找到了通过iterator可以修改key对应的mapped_type值
iterator find(const key_type& k);// 结合⽂档对insert返回值的解释
// insert插⼊⼀个pair<key, T>对象
// (1)如果key已经在map中,插⼊失败,则返回⼀个pair<iterator,bool>对象,返回pair对象
// first是key所在结点的迭代器,second是false
// (2)如果key不在在map中,插⼊成功,则返回⼀个pair<iterator,bool>对象,返回pair对象
// first是新插⼊key所在结点的迭代器,second是true
//也就是说⽆论插⼊成功还是失败,返回pair<iterator,bool>对象的first都会指向key所在的迭代器
//那么也就意味着insert插⼊失败时充当了查找的功能,正是因为这⼀点,insert可以⽤来实现operator[]// 需要注意的是这⾥有两个pair,不要混淆了,⼀个是map底层红⿊树节点中存的pair<key, T>另⼀个是insert返回值pair<iterator, bool>
pair<iterator, bool> insert(const value_type & val);
mapped_type& operator[] (const key_type& k);// operator的内部实现
mapped_type& operator[] (const key_type& k)
{// (1)如果k不在map中,insert会插⼊k和mapped_type默认值,同时[]返回结点中存储mapped_type值的引⽤,那么我们可以通过引⽤修改返映射值。所以[]具备了插⼊ + 修改功能pair<iterator, bool> ret = insert({ k, mapped_type() });// (2)如果k在map中,insert会插⼊失败,但是insert返回pair对象的first是指向key结点的迭代器,返回值同时[]返回结点中存储mapped_type值的引⽤,所以[]具备了查找 + 修改的功能iterator it = ret.first;return it->second;
}f.构造遍历和增删查
void test_map1()
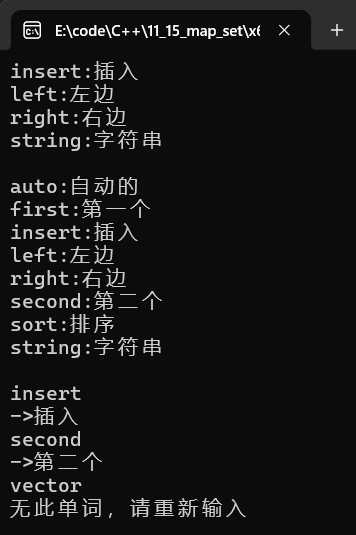
{// initializer_list构造及迭代遍历map<string, string> dict = { {"left", "左边"}, {"right", "右边"},{"insert", "插⼊"},{ "string", "字符串" } };//map<string, string>::iterator it = dict.begin();auto it = dict.begin();while (it != dict.end()){//cout << (*it).first <<":"<<(*it).second << endl;// map的迭代基本都使⽤operator->,这⾥省略了⼀个->// 第⼀个->是迭代器运算符重载,返回pair*,第⼆个箭头是结构指针解引⽤取pair数据//cout << it.operator->()->first << ":" << it.operator->()->second << endl;cout << it->first << ":" << it->second << endl;++it;} cout << endl;// insert插⼊pair对象的4种⽅式,对⽐之下,最后⼀种最⽅便pair<string, string> kv1("first", "第⼀个");dict.insert(kv1);dict.insert(pair<string, string>("second", "第⼆个"));dict.insert(make_pair("sort", "排序"));dict.insert({ "auto", "⾃动的" });// "left"已经存在,插⼊失败dict.insert({ "left", "左边,剩余" });// 范围for遍历for (const auto& e : dict){cout << e.first << ":" << e.second << endl;} cout << endl;string str;while (cin >> str){auto ret = dict.find(str);if (ret != dict.end()){cout << "->" << ret->second << endl;} else{cout << "⽆此单词,请重新输⼊" << endl;}} // 另外,erase等接⼝跟set完全类似
}
g.迭代器和[]
void test_map2()
{// 利⽤find和iterator修改功能,统计⽔果出现的次数string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (const auto& str : arr){// 先查找⽔果在不在map中// (1) 不在,说明⽔果第⼀次出现,则插⼊{⽔果, 1}// (2) 在,则查找到的节点中⽔果对应的次数++auto ret = countMap.find(str);if (ret == countMap.end()){countMap.insert({ str, 1 });} else{ret->second++;}} for (const auto & e : countMap){cout << e.first << ":" << e.second << endl;} cout << endl;string arr[] = { "苹果", "西瓜", "香蕉", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉" };map<string, int> countMap;for (const auto& str : arr){// []先查找⽔果在不在map中// (1) 不在,说明⽔果第⼀次出现,则插⼊{⽔果, 0},同时返回次数的引⽤,++⼀下就变成1次了// (2) 在,则返回⽔果对应的次数++countMap[str]++;} for (const auto & e : countMap){cout << e.first << ":" << e.second << endl;} cout << endl;map<string, string> dict;dict.insert(make_pair("sort", "排序"));// key不存在->插⼊ {"insert", string()}dict["insert"];// 插⼊+修改dict["left"] = "左边";// 修改dict["left"] = "左边、剩余";// key存在->查找cout << dict["left"] << endl;
}大家可以对比一下这几种写法,看哪种适合自己
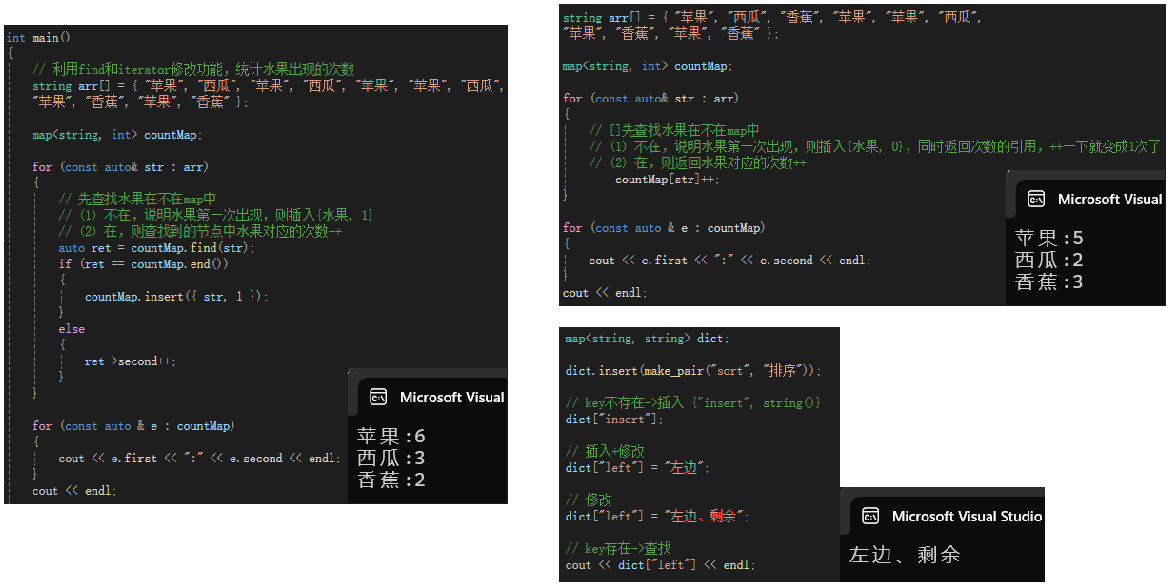
h.multimap和map的差异
multimap和map的使⽤基本完全类似,主要区别点在于multimap⽀持关键值key冗余,那么insert/find/count/erase都围绕着⽀持关键值key冗余有所差异,这⾥跟set和multiset完全⼀样,⽐如find时,有多个key,返回中序第⼀个。其次就是multimap不⽀持[],因为⽀持key冗余,[]就只能⽀持插⼊了,不能⽀持修改
i.Leecode
① 随机链表
138. 随机链表的复制 - 力扣(LeetCode)
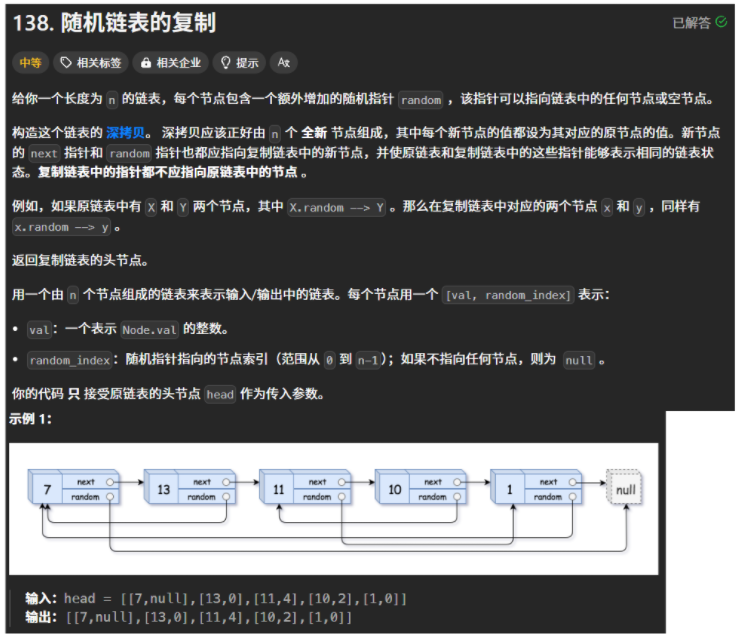
同样这道题我也在那篇文章介绍过,实现的也挺复杂,如果用现在的map解这道题也会简单一些
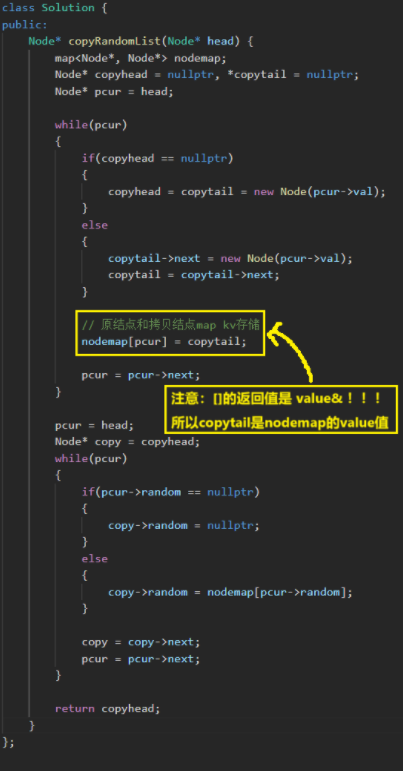
class Solution {
public:Node* copyRandomList(Node* head) {map<Node*, Node*> nodemap;Node* copyhead = nullptr, *copytail = nullptr;Node* pcur = head;while(pcur){if(copyhead == nullptr){copyhead = copytail = new Node(pcur->val);}else{copytail->next = new Node(pcur->val);copytail = copytail->next;}// 原结点和拷贝结点map kv存储nodemap[pcur] = copytail;pcur = pcur->next;}pcur = head;Node* copy = copyhead;while(pcur){if(pcur->random == nullptr){copy->random = nullptr;}else{copy->random = nodemap[pcur->random];}copy = copy->next;pcur = pcur->next;}return copyhead; }
};② 前K个高频单词
692. 前K个高频单词 - 力扣(LeetCode)

这道题的话我前面没有介绍过,但这道题用map解相对来说会容易一点
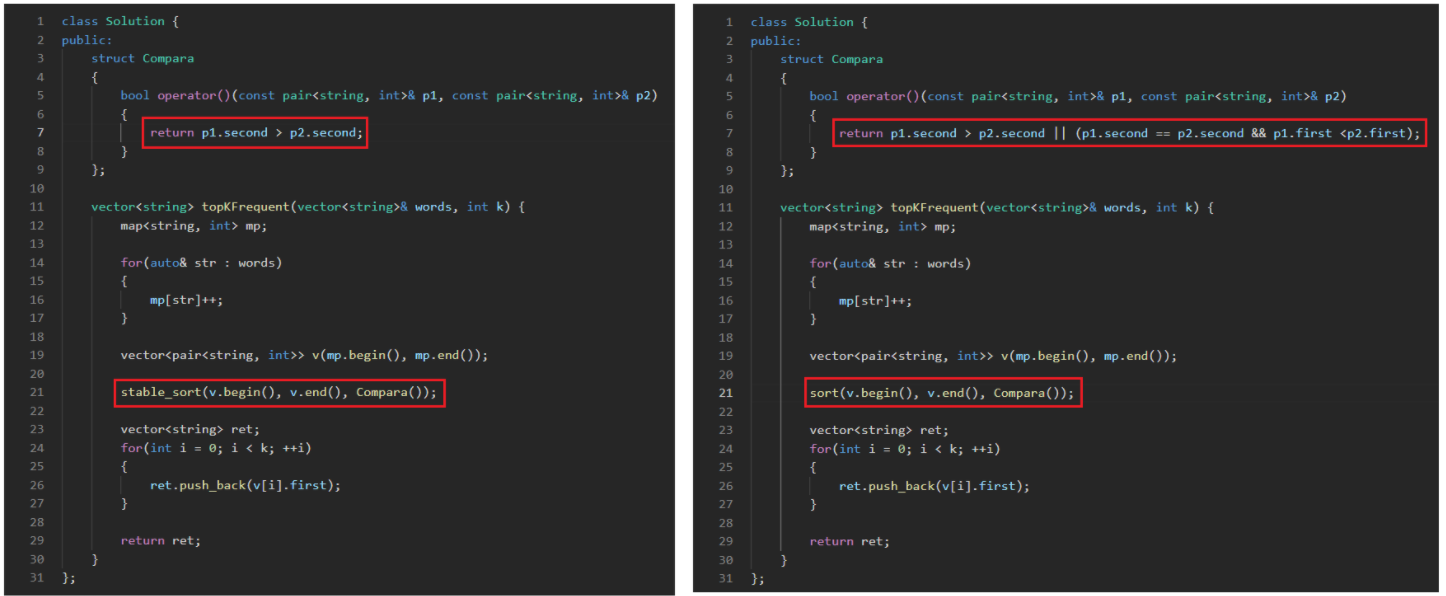
这里需要注意的是排序!!!
这是v使用迭代区间排好序的[apple, apple, pear, pear](根据ASCII码值比较大小)
当使用sort排序时,一旦数据多起来,就可能会导致这样的结果[pear, pear, apple, apple],所以它是不稳定的,不满足我们的需求
方法一:使用stable_sort排序,因为它是稳定排序,那就意味着在比较频率大小的时候,频率相等的话,单词的相对位置不会发生改变,这就完美符合我们的需求,我们的v正好是从小到大排序的,并且符合字典的这个需求
方法二:在写compara函数的时候,加上频率相等比较字母ASCII码值的大小这个条件,也可以完美解决这道题
class Solution {
public:struct Compara{bool operator()(const pair<string, int>& p1, const pair<string, int>& p2){return p1.second > p2.second || (p1.second == p2.second && p1.first <p2.first);}};vector<string> topKFrequent(vector<string>& words, int k) {map<string, int> mp;for(auto& str : words){mp[str]++;}vector<pair<string, int>> v(mp.begin(), mp.end());sort(v.begin(), v.end(), Compara());vector<string> ret;for(int i = 0; i < k; ++i){ret.push_back(v[i].first);}return ret;}
};③ 单词识别
单词识别牛客题霸牛客网
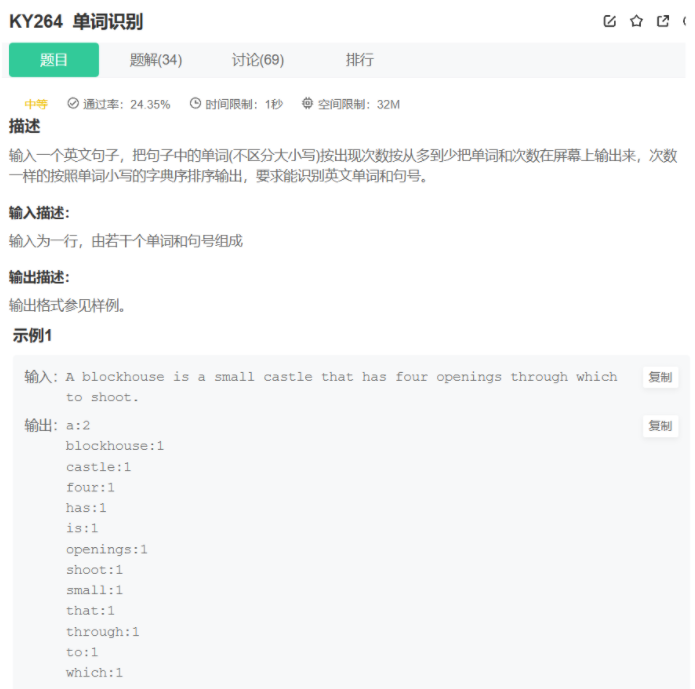
这里要先将这句话里面的单词先提取出来,就是这个步骤会有点麻烦,大家可以看看我的代码理一下思路,剩下的和上一道题类似
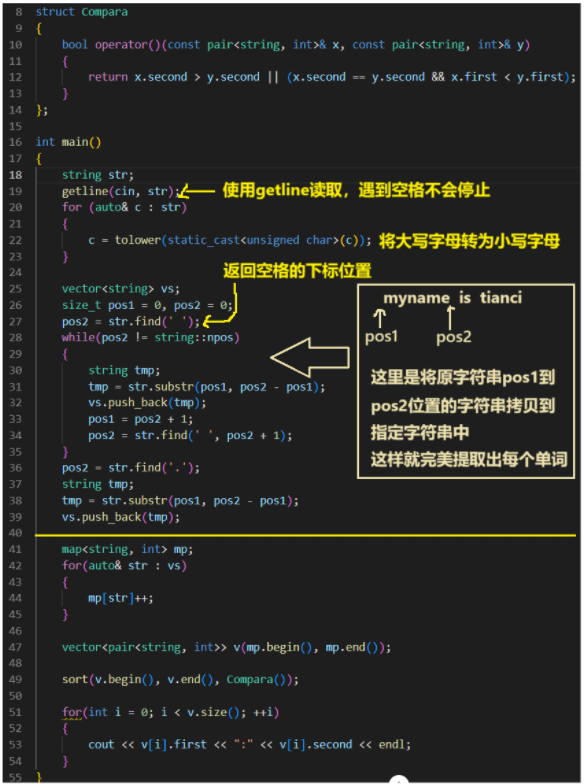
#include <iostream>
using namespace std;
#include <map>
#include <vector>
#include <string>
#include <algorithm>struct Compara
{bool operator()(const pair<string, int>& x, const pair<string, int>& y){return x.second > y.second || (x.second == y.second && x.first < y.first);}
};int main()
{string str;getline(cin, str);for (auto& c : str) {c = tolower(static_cast<unsigned char>(c));}vector<string> vs;size_t pos1 = 0, pos2 = 0;pos2 = str.find(' ');while(pos2 != string::npos){string tmp;tmp = str.substr(pos1, pos2 - pos1);vs.push_back(tmp);pos1 = pos2 + 1;pos2 = str.find(' ', pos2 + 1);}pos2 = str.find('.');string tmp;tmp = str.substr(pos1, pos2 - pos1);vs.push_back(tmp);map<string, int> mp;for(auto& str : vs){mp[str]++;}vector<pair<string, int>> v(mp.begin(), mp.end());sort(v.begin(), v.end(), Compara());for(int i = 0; i < v.size(); ++i){cout << v[i].first << ":" << v[i].second << endl;}
}另外还有一种写法,大家也可以看一下
#include <iostream>
using namespace std;
#include <map>
#include <set>
#include <string>struct Compara
{bool operator()(const pair<string, int>& x, const pair<string, int>& y){return x.second > y.second || (x.second == y.second && x.first < y.first);}
};int main()
{string s;while (getline(cin, s)) {map<string, int> m;string temp;// 分割单词,采用map统计每个单词出现的次数for (size_t i = 0; i < s.size(); ++i) {if (s[i] == ' ' || s[i] == ',' || s[i] == '.') {// 一个单词解析结束if (temp != "")m[temp]++;temp = "";} else {// 注意:题目已说明不区分大小写,那么A和a算是一个单词,故需要将大小写统一temp += tolower(s[i]);}}// 将map中的<单词,次数>放到set中,并按照次数升序,次数相同按照字典序规则排序set<pair<string, int>, Compara> s(m.begin(), m.end());// 将本次统计到的结果按照要求输出for (auto& e : s)cout << e.first << ":" << e.second << endl;cout << endl;}return 0;
}本篇文章到这里就结束啦,希望这些内容对大家有所帮助!
下篇文章见,希望大家多多来支持一下!
感谢大家的三连支持!