Spark,序列化反序列化
序列化反序列化的定义:
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。
先写一个类
public class Student {
public Student(String name,int age) {
this.name = name;
this.age = age;
}
String name;
int age;
}
在java中,对应的序列化和反序列化的方法是:
1.让这个类实现 Serializable 接口,也就是在代码中补充implements Serializable。
public class Student implements Serializable {
// 省略其他...
}
2.序列化。新建文件输出流对象,并写入要实例化的实例。
Student student = new Student("xiaohua", 10);
// java序列化
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("student_java"));
oos.writeObject(student);
oos.close();
反序列化。通过文件输入流读入文件,并使用ObjectInputStream来进一步实例化对象,然后调用readObject来生成对象。对应的代码如下
// 反序列化:将字节序列转换为内存中的对象
// 1. 创建一个ObjectInputStream对象,构造方法中传入一个InputStream对象
ObjectInputStream studentJava = new ObjectInputStream(new FileInputStream("student_java"));
// 2. 使用ObjectInputStream对象中的readObject方法,读取文件中的对象
Student student1 = (Student) studentJava.readObject();
System.out.println(student1.name + " " + student1.age);
// 3. 关闭ObjectInputStream对象
studentJava.close();
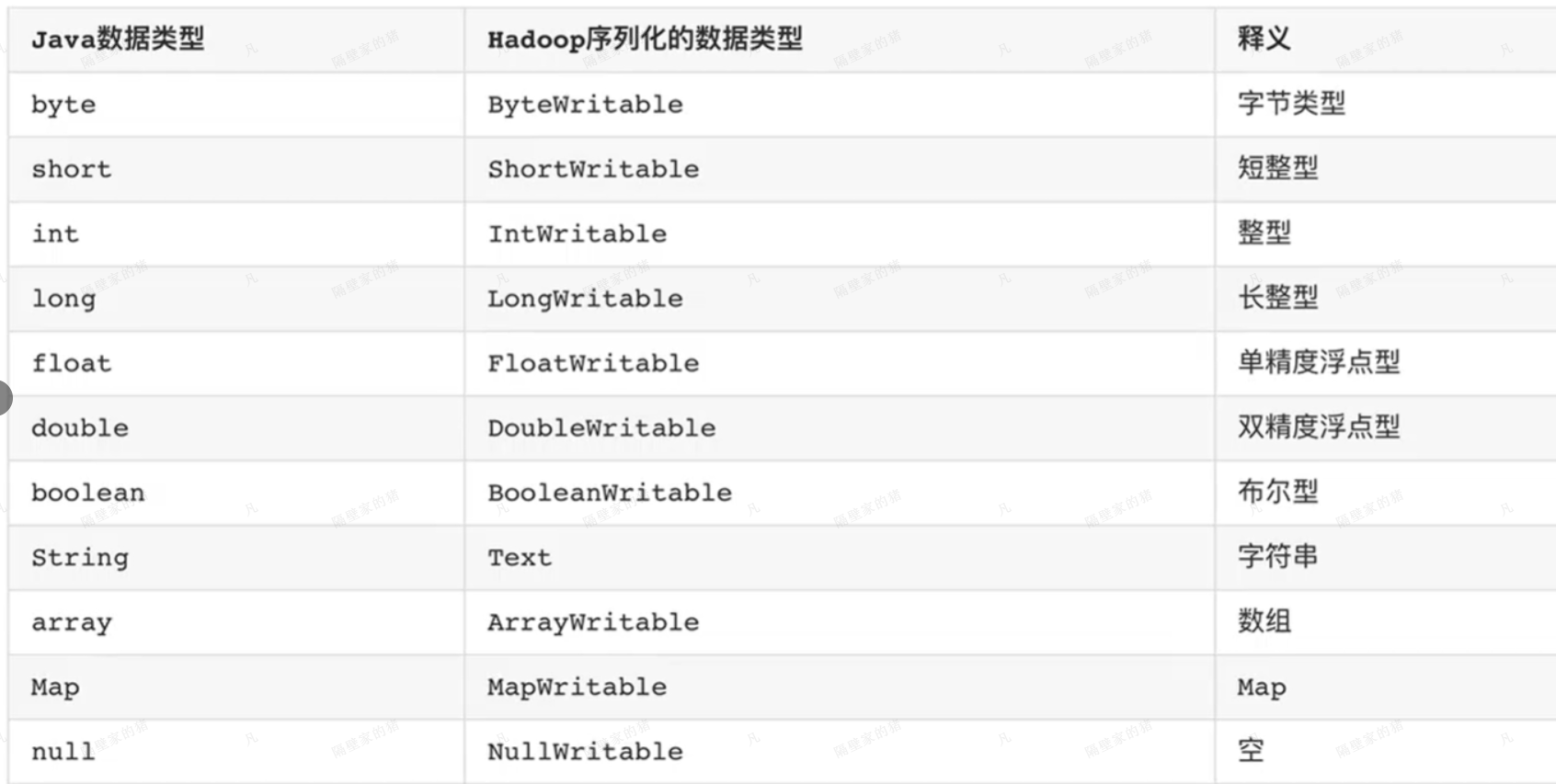
常用的Java的数据类型与Hadoop的序列化的类型对比。
完整代码如下
Student
public class Student implements Writable{
public Student(String name,int age) {
this.name = name;
this.age = age;
}
public Student() { }
public String name;
public int age;
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(name);
dataOutput.writeInt(age);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
name = dataInput.readUTF();
age = dataInput.readInt();
}
}
TestStudent
package com.example.serial;
import java.io.*;
public class TestStudent {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Student student = new Student("小花", 18);
// hadoop序列化
DataOutputStream dos = new DataOutputStream(new FileOutputStream("Student_hadoop.txt"));
student.write(dos);
// hadoop 反序列化
DataInputStream dis = new DataInputStream(new FileInputStream("Student_hadoop.txt"));
Student student1 = new Student();
student1.readFields(dis);
System.out.println(student1.name+ " "+student1.age);
}
}