Megatron系列——流水线并行
内容总结自:bilibili zomi 视频大模型流水线并行
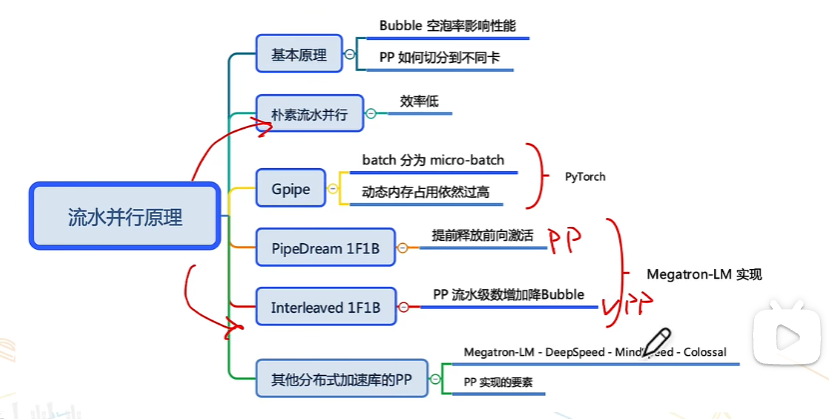
注:这里PipeDream 1F1B对应时PP,Interleaved 1F1B对应的是VPP
1、朴素流水线并行
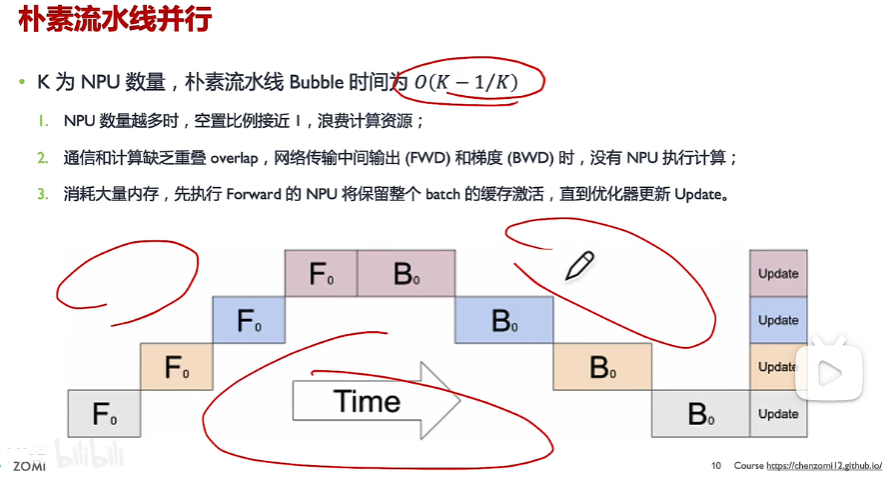
备注:
(1)红色三个圈都为空泡时间,GPU没有做任何计算
(2)共有4张卡,大batch size下,F0为第1次前向,依次流水线执行。所有stage完成后,再执行第1次反向B0。
(3)所有stage反向传播完计算好梯度后,所有stage同时更新参数
GPU利用率非常低。
2、Gpipe 流水线并行
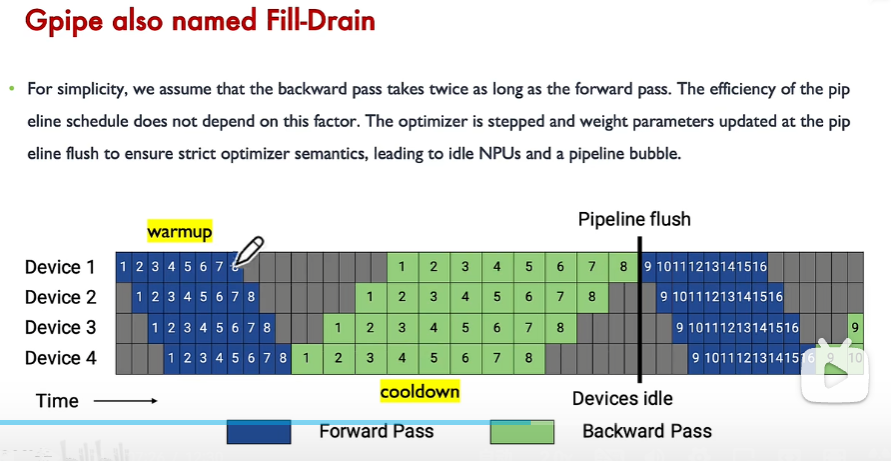
解决办法:
(1)将大的batch size拆分为多个小的micro batch size,如数据1计算完了后,直接进入下一个stage device2计算,无需等待数据8执行完。

空泡率:
(1)micro batch_size越高,空泡率越低
(2)m个micro-batch前向结束时,内存达到峰值,不断增加m可能导致内存不够。解决办法为重计算,即部分层不存储中间结果,在计算梯度时再重新计算中间结果。
(3)MFU 模型利用率提高
3、1F1B PP(非交错式)
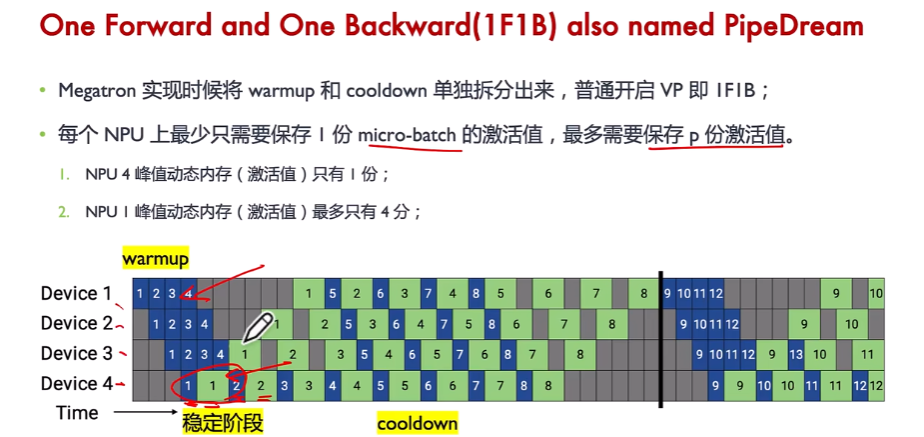
备注:
(1)在最后一个stage,即NPU4上可以看到,1次前向1次反向,交替进行,因此叫做1F1B。这个NPU上只保存了1份激活值,即前向中间结果,及时反向后释放。而NPU1最多有4份
4、1F1B interleaving VPP(交错式)
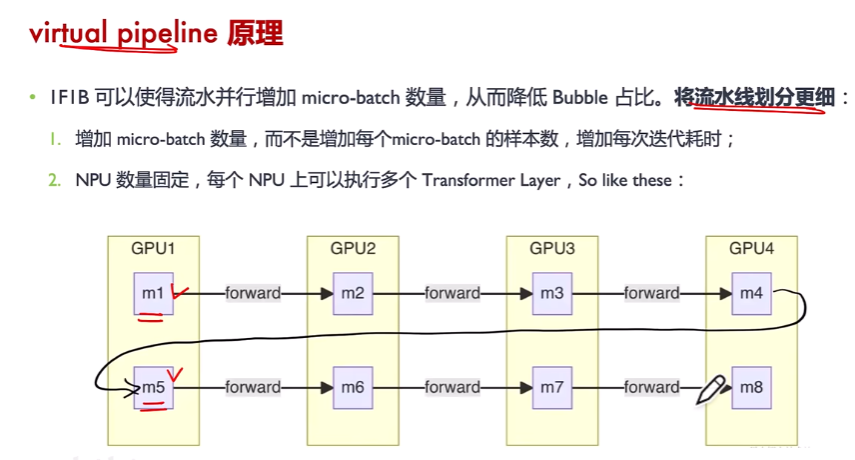
要持续降低bubble占比,有上图两种方式,第二种方式为将每张卡上搞多个stage。
(1)如NPU1负责第1层和第5层。按照原来的1F1B的方法,若有4张卡,分4个stage,则每张卡负责连续的2层,如NPU1负责1-2层,当数据1过来,需要在NPU1上经过2层计算后才到第二张卡。反而通过本方案,数据1过来后,只要经过1层计算,马上到第二张卡,第二张卡及以后的等待时间变短了。这时第一张卡可以做数据2的计算。
完整的图如下:
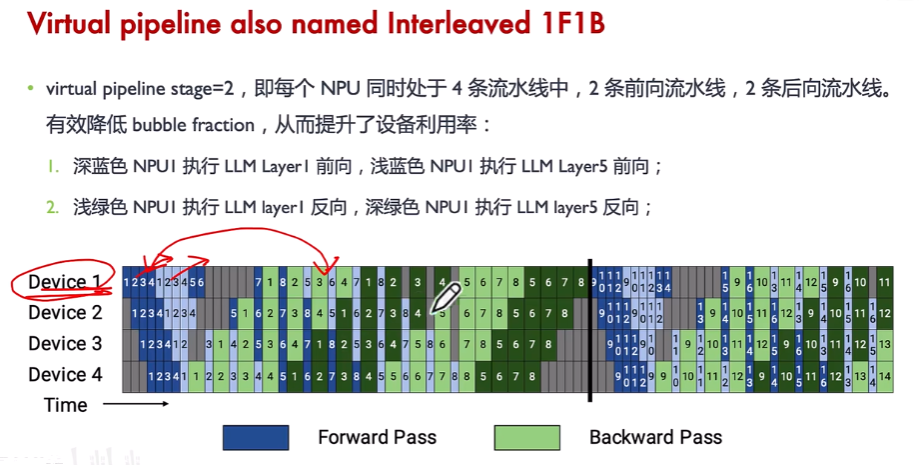
(1)这里横坐标为时间线,如第1时刻,只有NPU1在做数据1的计算,第4时刻NPU1在做数据4计算,NPU4在做数据1的计算。
(2)第5时刻,NPU4已经完成数据1的计算了,按照上一张图的说法,意味着数据1已经完成了第4层的计算,这时候可以回到第一张卡做数据1的第5层前向计算了。这时NPU2还在做数据4的第一层前向计算。其他的可以见图所示。
(3)第9时刻,数据1已经完成完整的8层前向计算,在NPU4上可以做反向传播,执行1F1B了。其他的类似。
空泡率:

5、其他的流水线并行
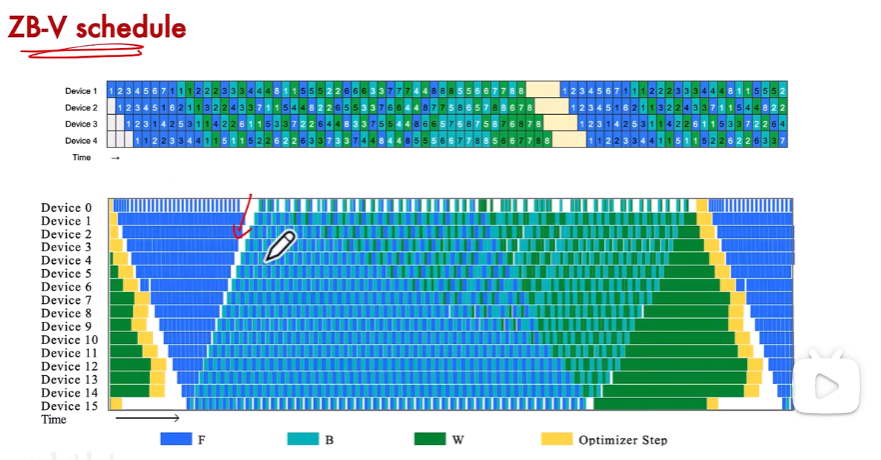
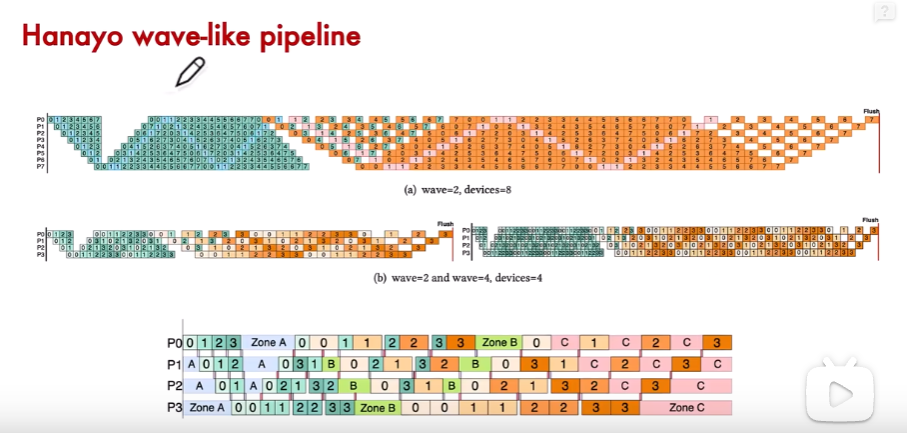
6、分布式PP实现方案
是所有并行中最难的,分为以下两种实现方式:




7、PP 代码实现
(1)模型实例化构建
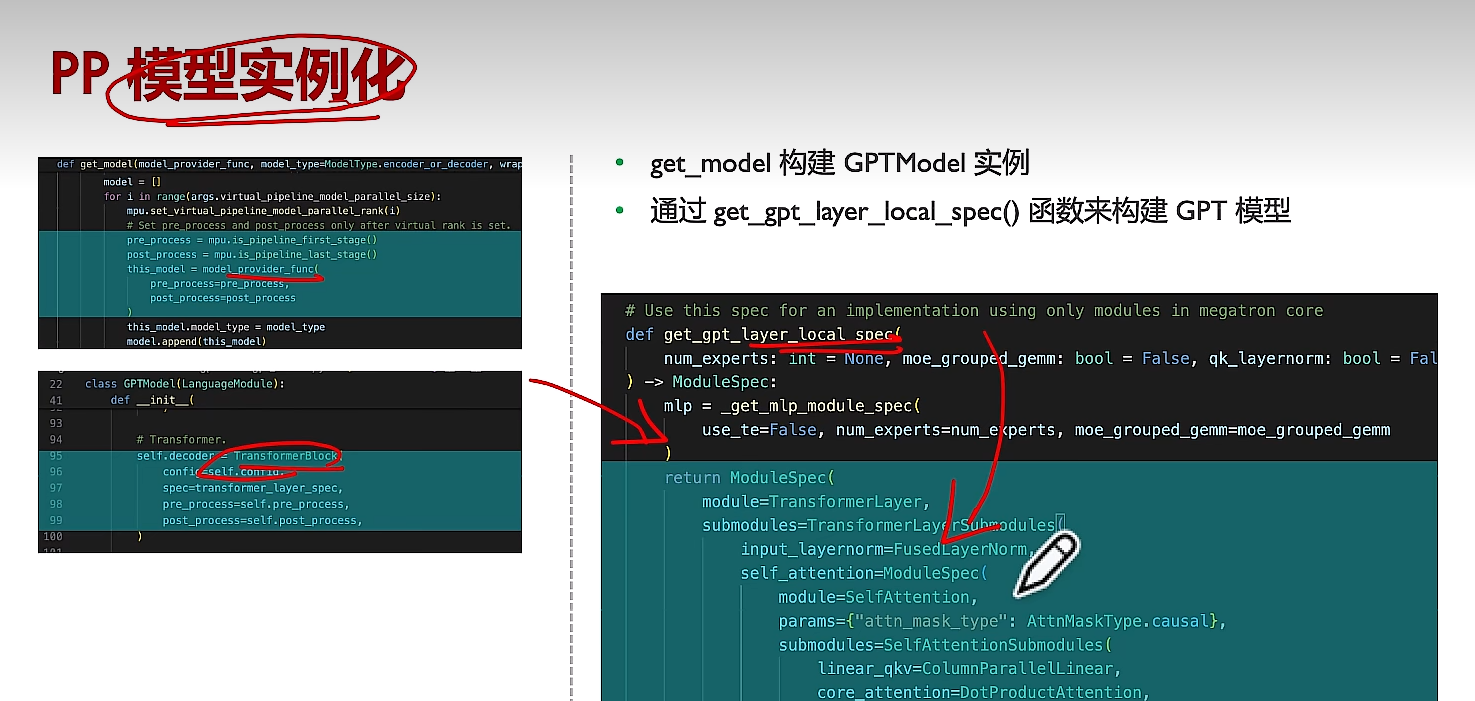
(2)每个NPU只构建对应offset的layers
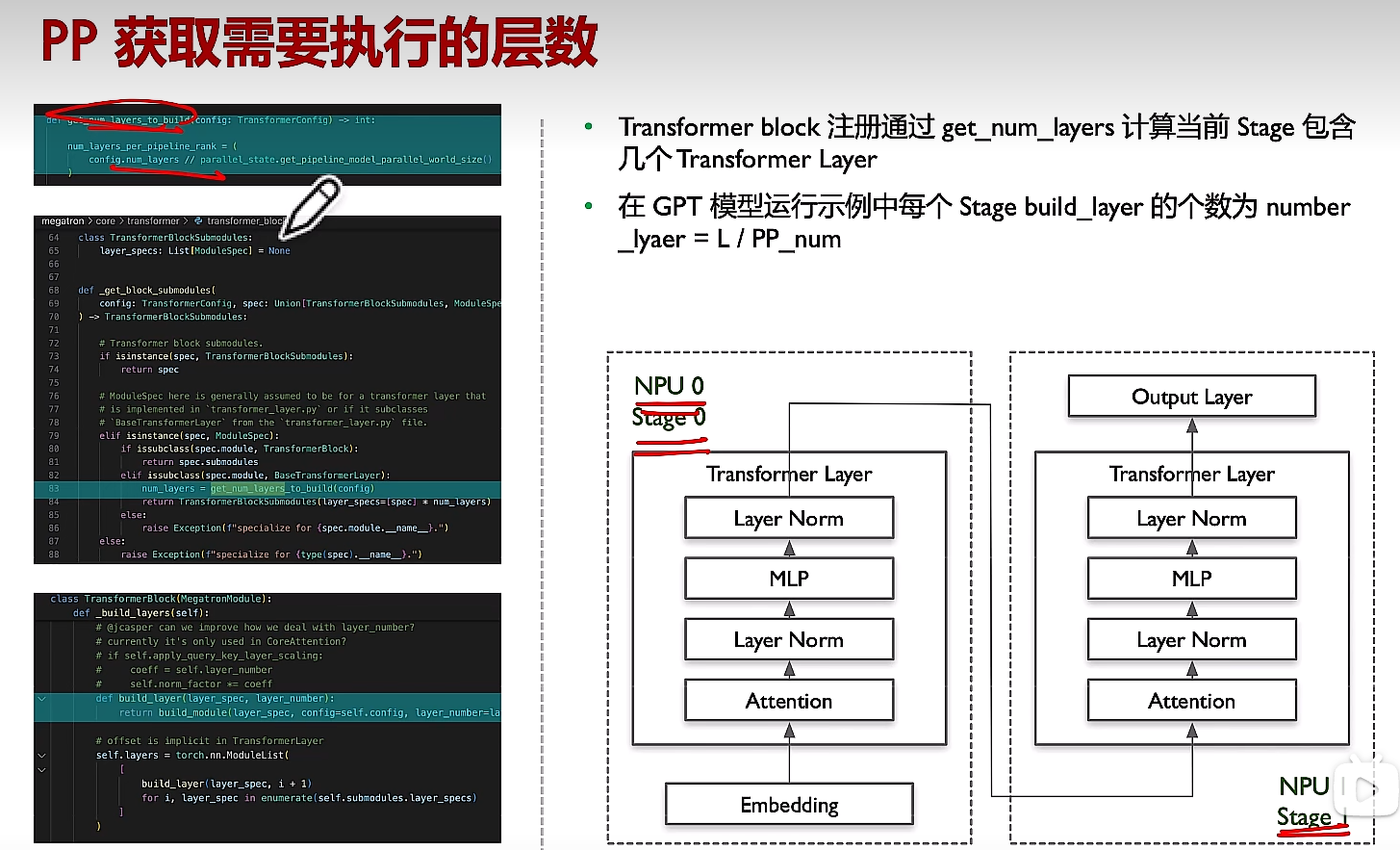
- 每个rank的层数为:总层数//pp数,若只有一层,如何分配?
- embedding和output layer如何分配到第一个NPU和最后一个NPU的,代码在哪里?
(3)确定执行交错式或非交错式的前向反向函数
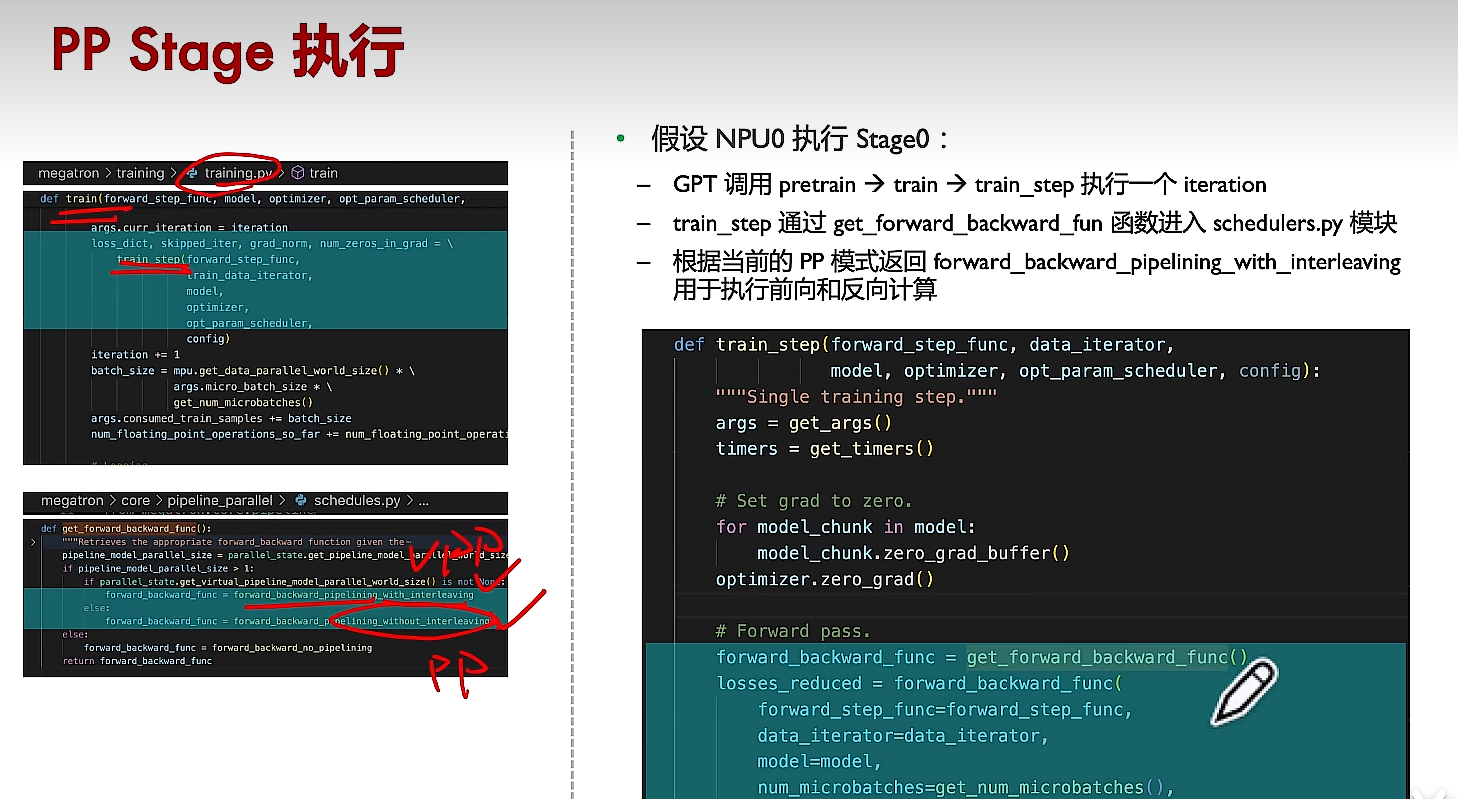
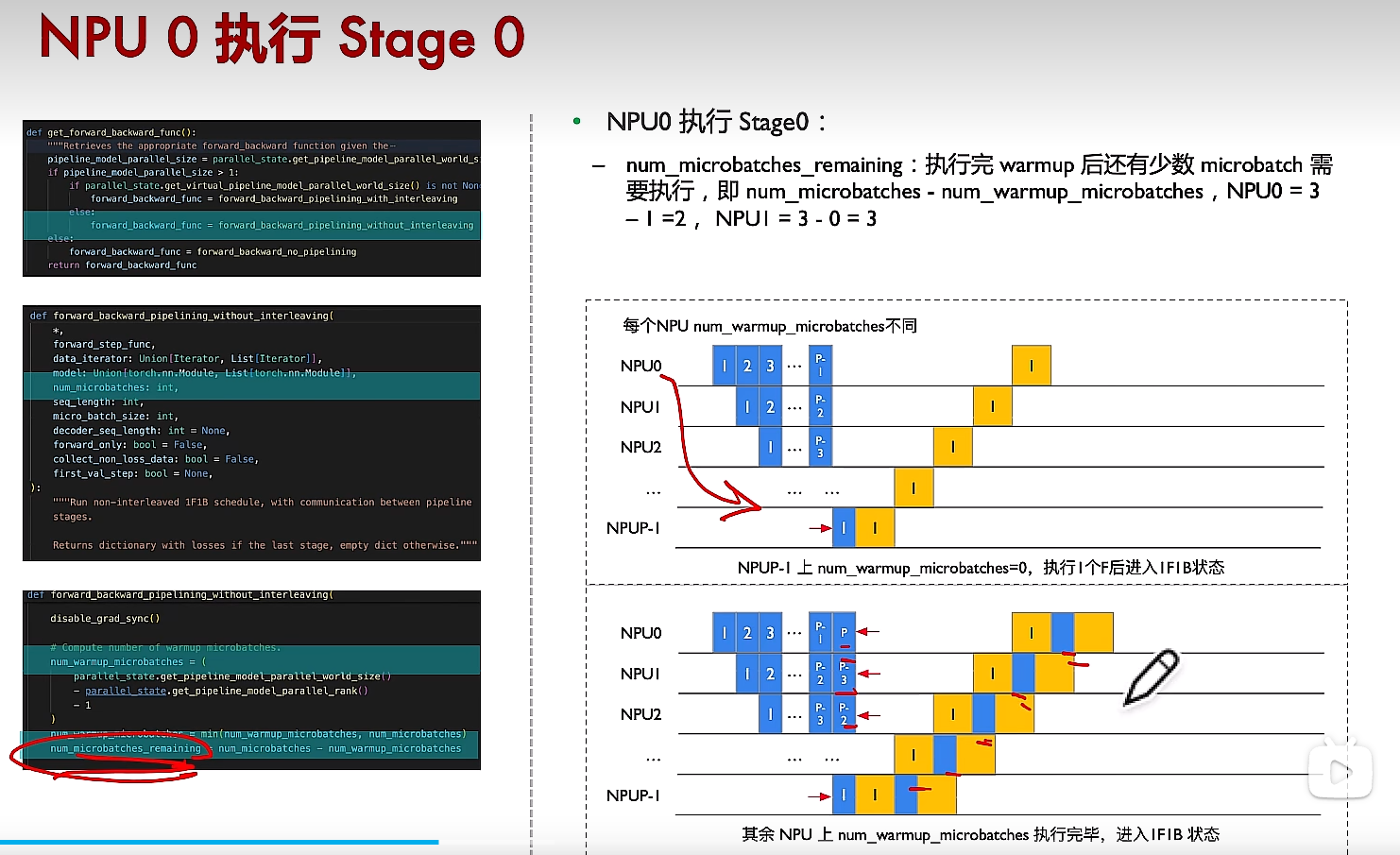
这里面num_microbatches_remaining为对应rank还有多少个micro batchs没有执行完。
(3)3个步骤,接收、前向计算、发送
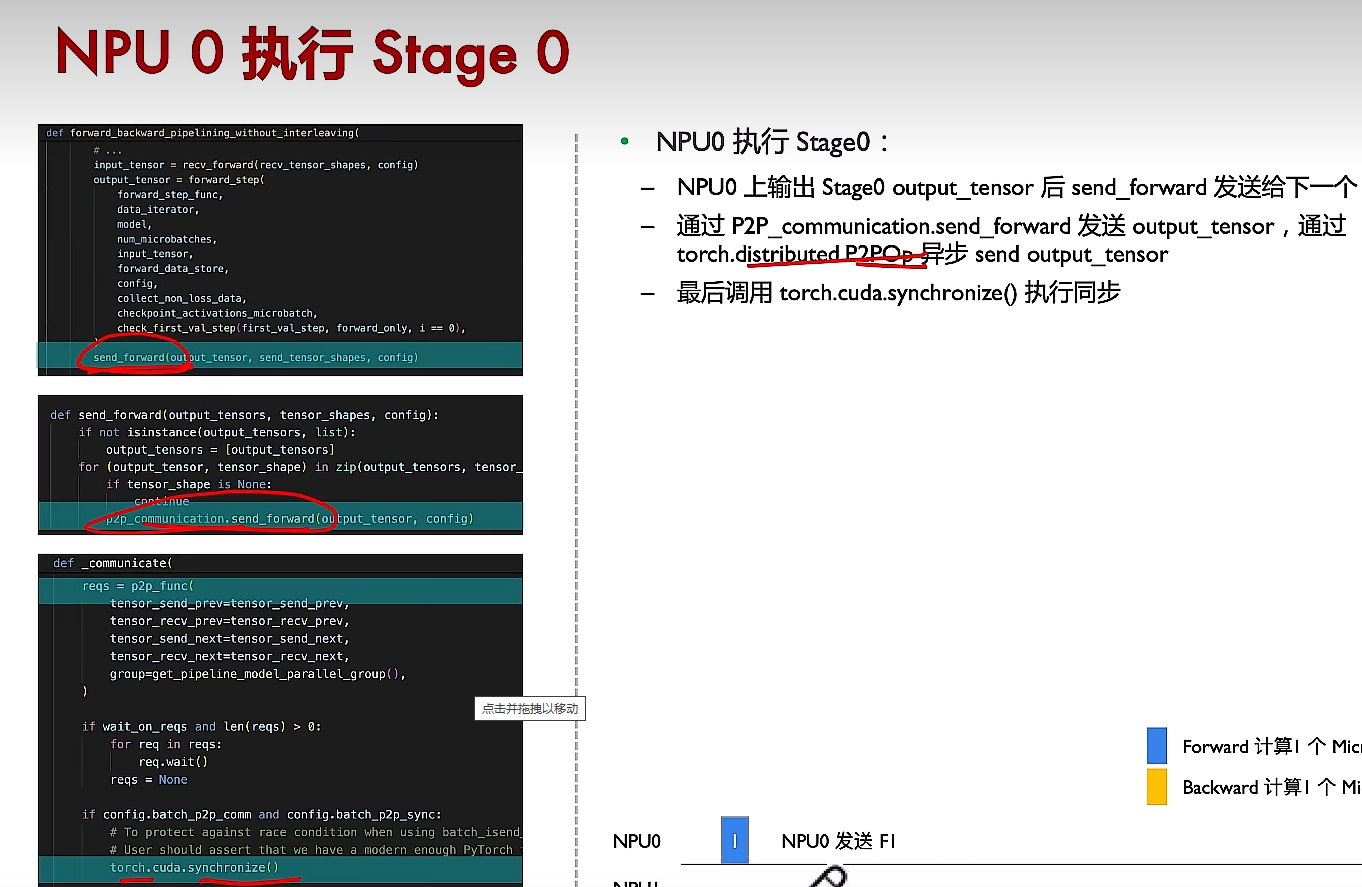
(4)反向传播
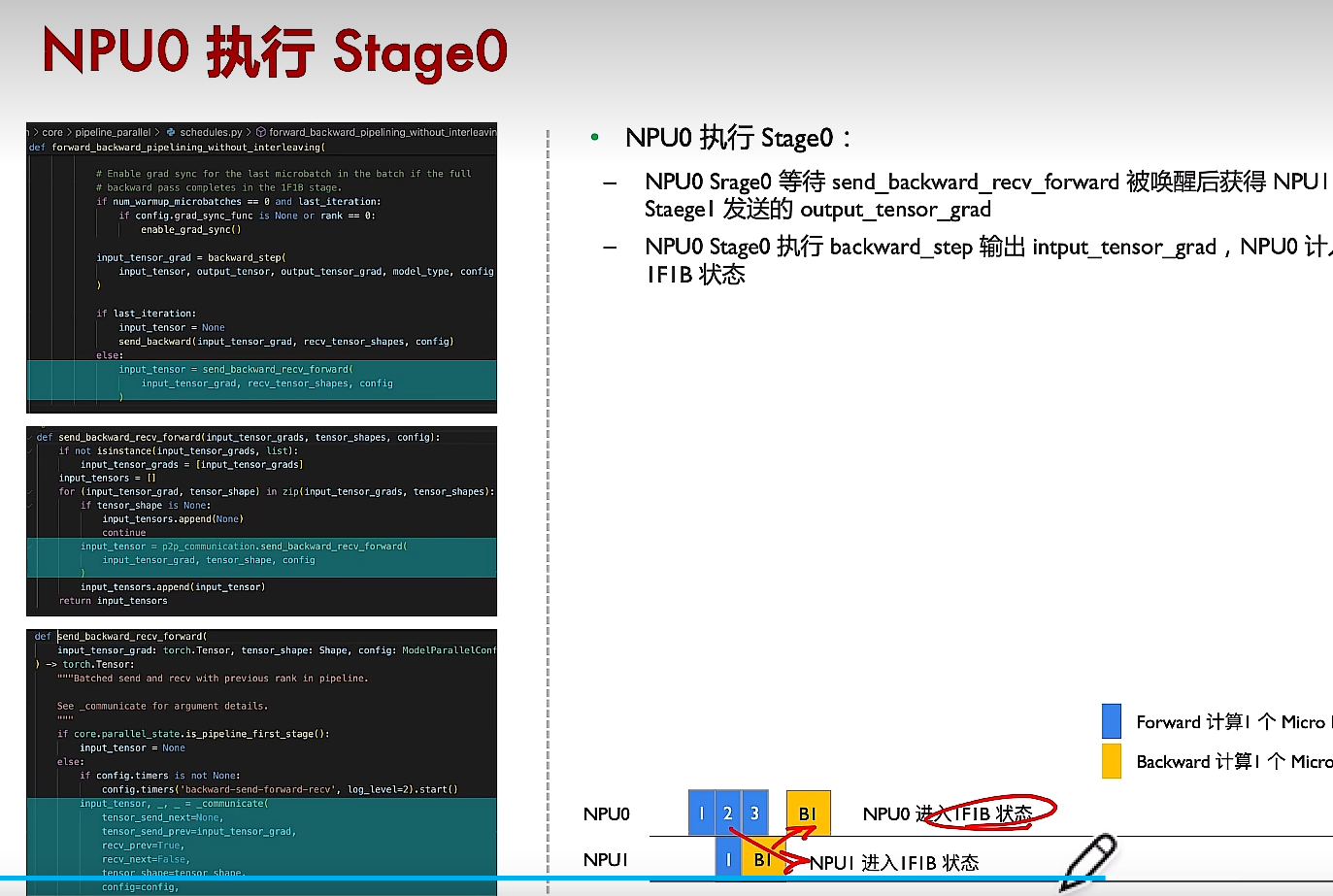
NPU0和NPU1在不断通讯,NPU1完成B1反向传播时,会将结果发给NPU0,同时等待数据2前向计算的结果。