【数据结构】map_set前传:二叉搜索树(C++)
目录
二叉搜索树K模型的模拟实现
二叉搜索树的结构:
Insert()插入:
InOrder()中序遍历:
Find()查找:
Erase()删除:
参考代码:
二叉搜索树K/V模型的模拟实现:
K/V模型的简单应用举例:
二叉搜索树的局限性:
二叉搜索树(Binary Search Tree)又称二叉排序树,它在二叉树的基础上有如下特性:
若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
它的左右子树也分别为二叉搜索树
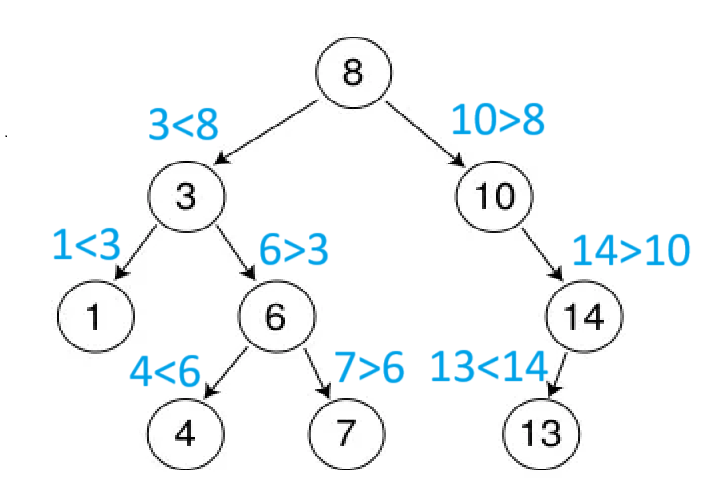
并且它不允许有重复值,如果在上面的二叉搜索树中再插入6,就会插入失败
本篇会在模拟实现的过程中带着大家学习
二叉搜索树有K模型和K/V模型两种,下面一一实现
二叉搜索树K模型的模拟实现
二叉搜索树的结构:
对于一个二叉树的节点,都有一个值,一个左子树,一个右子树
template<class K>
struct BTreeNode
{BTreeNode(K key):_left(nullptr),_right(nullptr),_key(key){}BTreeNode* _left;//左子树BTreeNode* _right;//右子树K _key;//值
};二叉树中只需要有一个根节点,就能扩展出来左子树和右子树
template<class K>
class BTree
{
public:typedef BTreeNode<K> Node;
private:Node* _root = nullptr;
};Insert()插入:
二叉搜索树的插入函数返回值是bool类型,这是为了判断插入是否成功。何时会失败呢?当要插入的新值在树中已经有时,就会插入失败(二叉搜索树不会有重复值)。
假如要在下面这棵树插入2,就会是如下过程

指针走到一个空节点时,就代表可以插入了
bool Insert(const K& key)//插入新数据,bool返回值来判断插入是否成功(因为二叉搜索树是不允许有相同数据的)
{if (_root == nullptr)//如果根节点为空,就把值赋给根节点{_root = new Node(key);return true;}Node *cur = _root, *parent = nullptr;//双指针走法,这样可以找到要赋值节点的父亲while (cur){parent = cur;if (key > cur->_key)//如果要插入的值比当前节点大,就往右走cur = cur->_right;else if (key < cur->_key)//如果插入的值比当前节点小,就往左走cur = cur->_left;elsereturn false;//如果相同,就返回false}cur = new Node(key);//把值赋给curif (key > parent->_key)//判断cur应该放到父亲的左边还是右边parent->_right = cur;elseparent->_left = cur;return true;
}可以看到实现中除了cur指向当前节点的指针外,还有一个指向父亲节点的指针,这是为了什么呢?
如果没有父亲节点,直接将值赋给cur,那cur此时只是个局部变量,不会到树中
并且我们需要父亲节点的值来判断到底是要插入到左树还是右树(虽然在遍历时就已经判断好是走左树还是右树,但下面并不知道)
InOrder()中序遍历:
在本篇开始时就说过,二叉搜索树也叫二叉排序树,这是因为它在用中序遍历走时,正好是升序排列
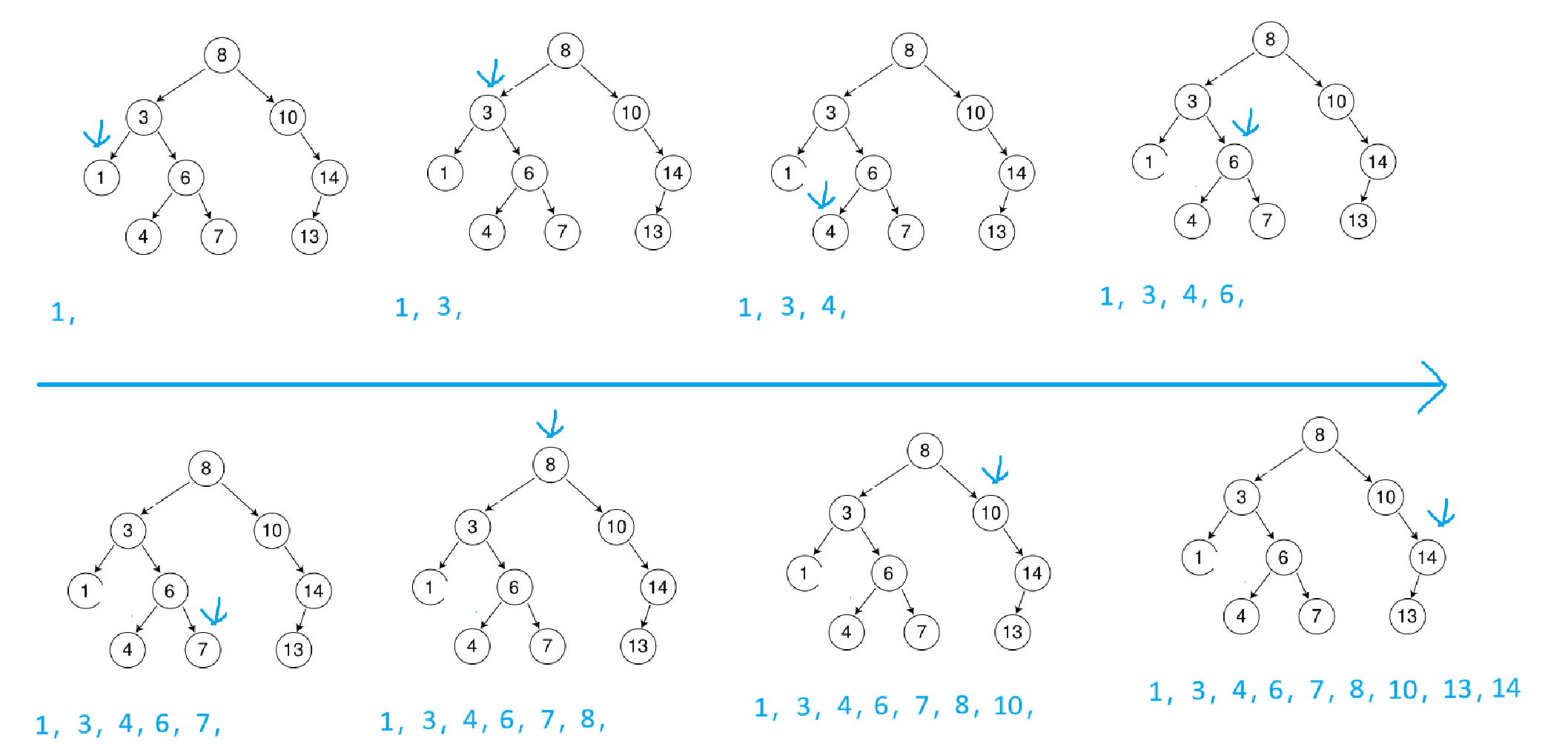
所以在打印一个二叉搜索树时,一般就会用中序遍历打印
void _InOrder(Node* root)//递归实现中序遍历
{if (root){_InOrder(root->_left);cout << root->_key << " ";_InOrder(root->_right);}}
void InOrder()//中序遍历
{_InOrder(_root);//因为要递归,而且用户调用不到_root,所以要再创个用于递归的函数cout << endl;
}为什么这里还要再搞一个_InOrder函数呢?
如果直接在InOrder中递归遍历,就需要用户在调用函数时就传根节点过去,但根节点是private类型,用户访问不到,所以这里要在成员函数中调用传了根节点的函数来实现递归
Find()查找:
查找和插入的思想类似,就是用需要查找的值来对比当前节点,如果比当前节点大,就进入右子树,如果小,就进入左子树,如果相等,就返回true
bool Find(const K& key)//查找某个值
{Node* cur = _root;while (cur){if (key > cur->_key)//如果比当前节点大,就去右子树找cur = cur->_right;else if (key < cur->_key)//如果比当前节点小,就去左子树找cur = cur->_left;elsereturn true;}return false;
}Erase()删除:
这是二叉搜索树实现中最难的部分,因为它分为多种情况
最简单的一种,就是删除叶子节点,因为它没有孩子需要顾虑,直接释放再给置空就好
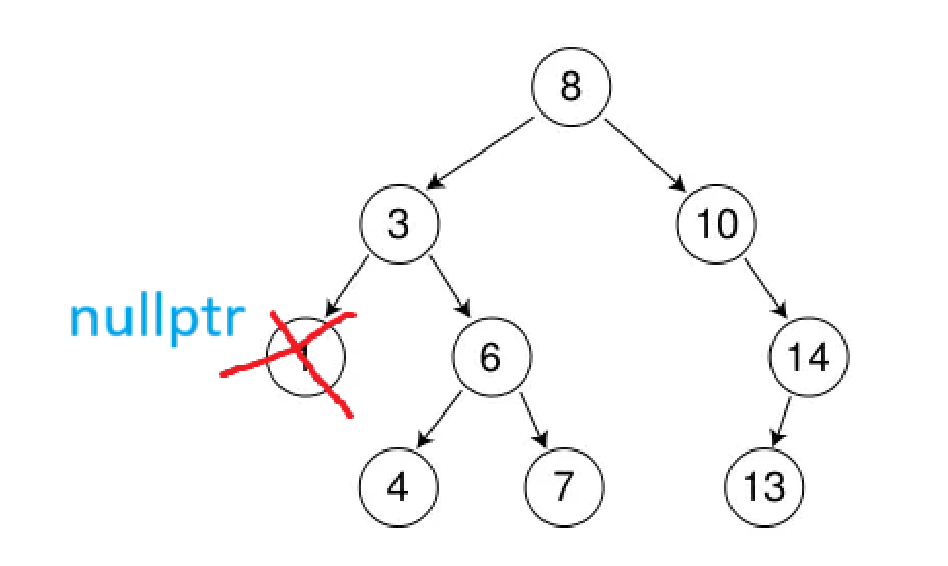
如果当前节点左子树有孩子,右子树没有孩子,就需要先找到当前节点的父亲,判断当前节点是在父亲的左树还是右树,再让父亲的左/右树指向当前节点的左子树,当然,别忘了释放当前节点
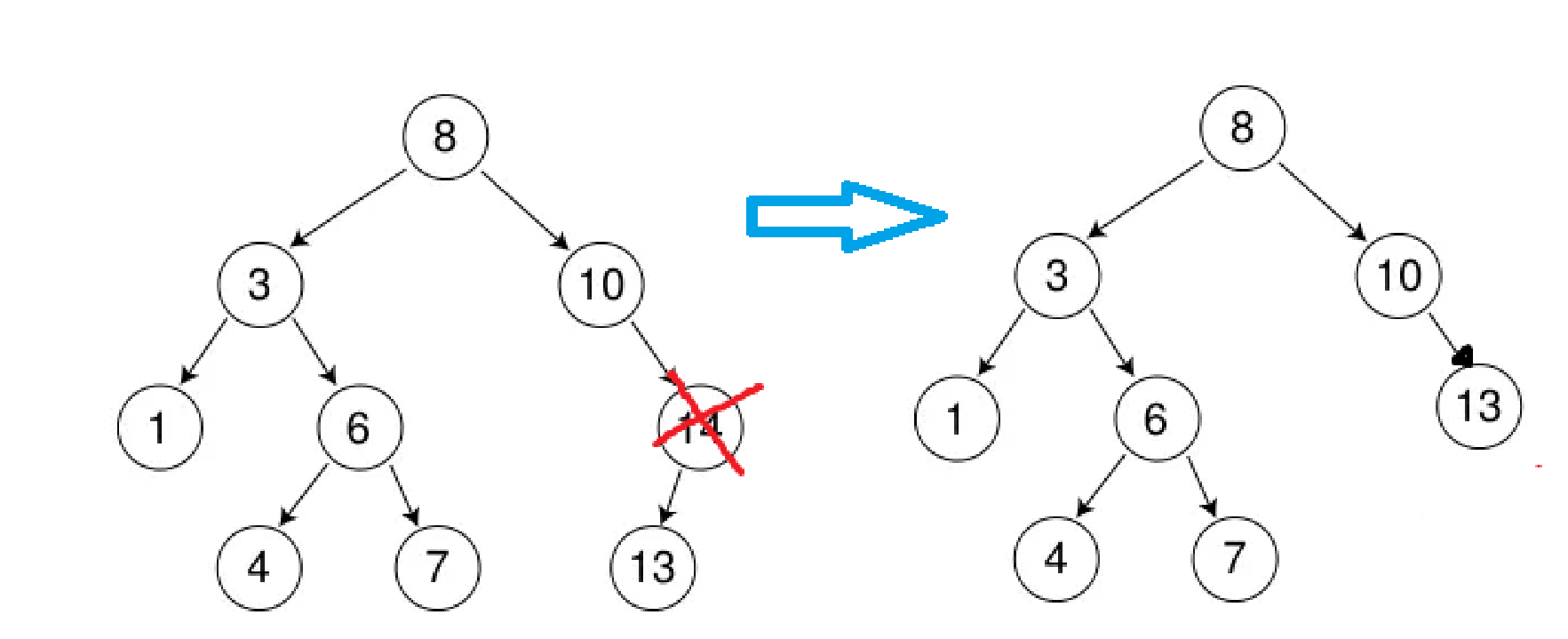
如果当前节点的右子树有孩子,左子树没有孩子,就需要先找到当前节点的父亲,判断当前节点是在父亲的左树还是右树,再让父亲的左/右树指向当前节点的右子树,再释放当前节点。和上面正好相反
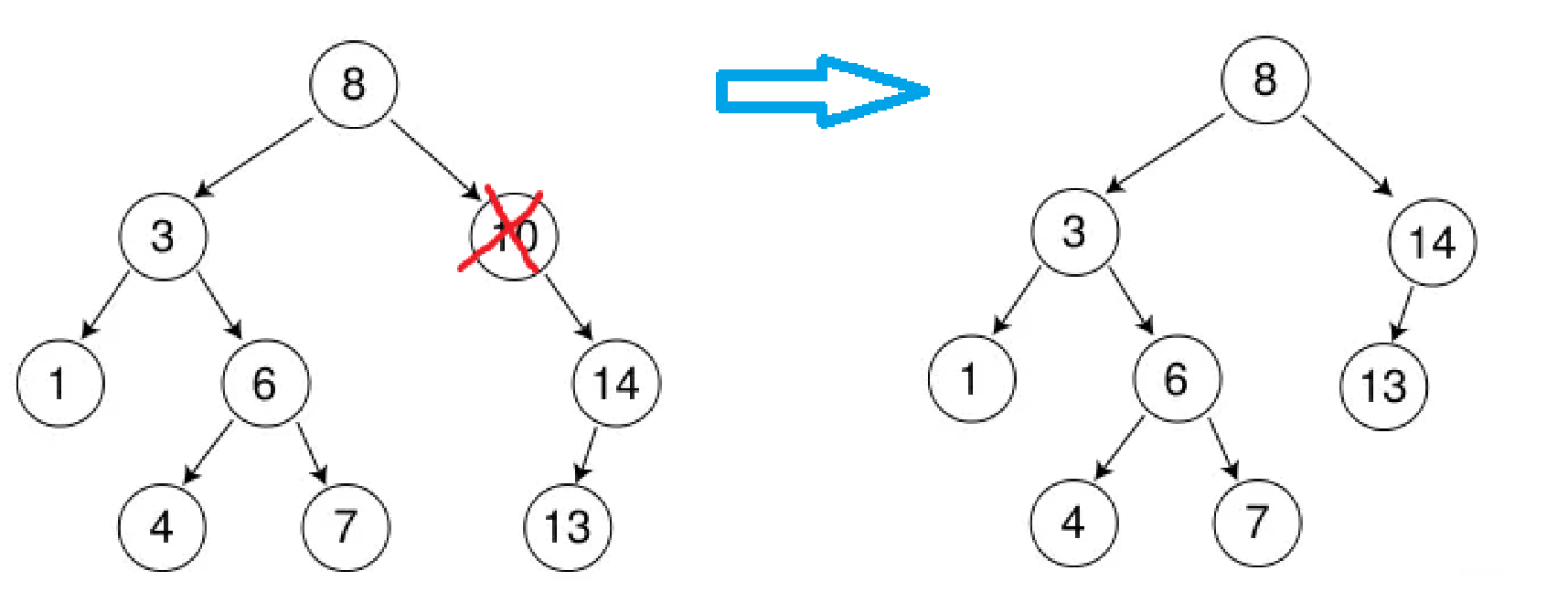
两边都没有节点的情况就可以被划分在这两个里面的任意一个,因为不管哪个,都是要让父亲指向空
最棘手的情况是当前节点的左右子树都有孩子,也就是要找一个能满足左边比它小,右边比它大的替代值,这时要上哪边找呢?
其实左右都能找到,即左子树的最右节点或右子树的最左节点,它们都符合代替后右大,左边小的规则
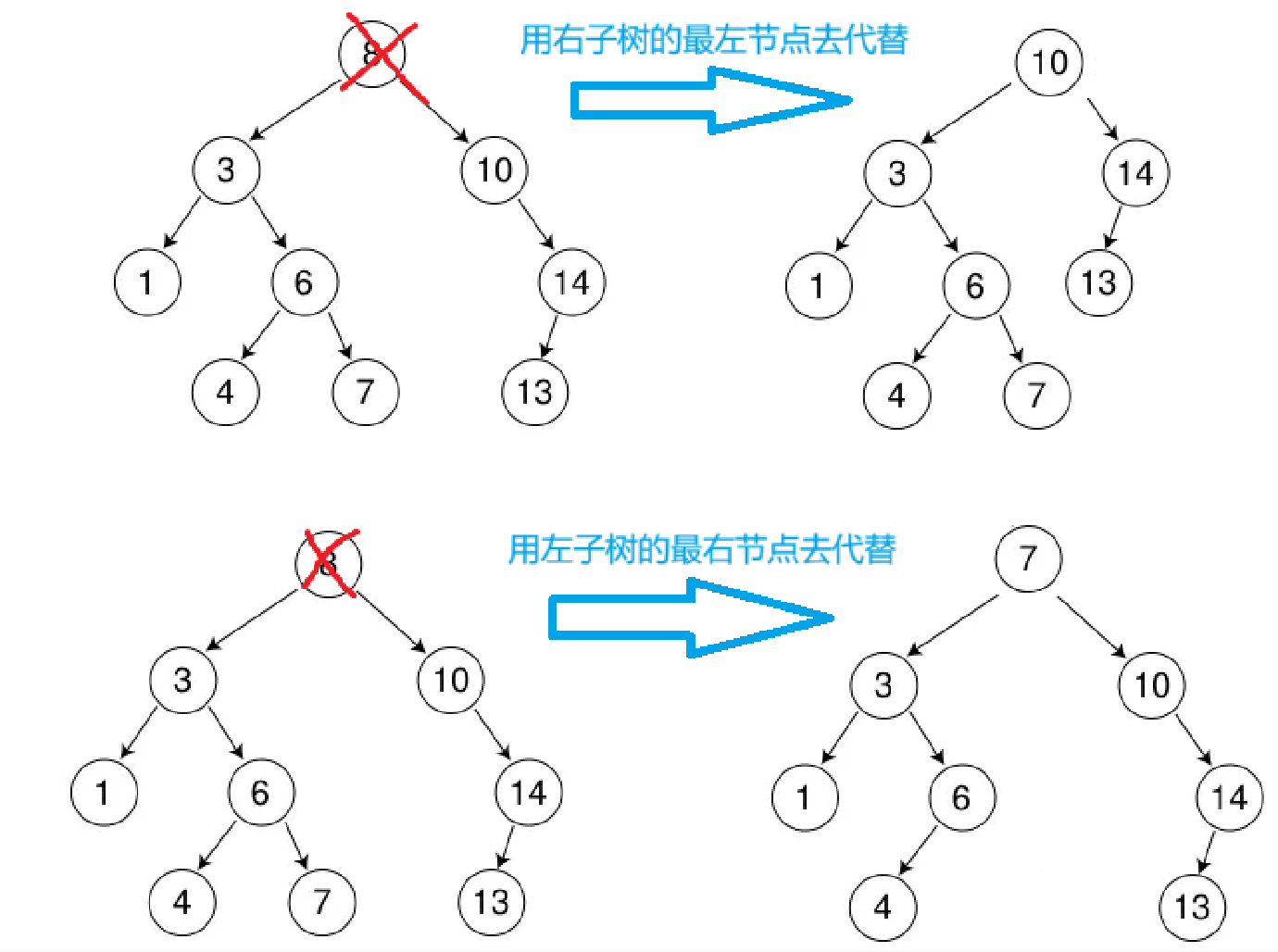
当然,Erase的返回值也是bool类型,如果给的是一个树中根本没有的值,就需要返回false
bool Erase(const K& key)//删除某个值(节点)
{//找到要删除的那个值Node* cur = _root, * parent = nullptr;while (cur){if (key > cur->_key){parent = cur;cur = cur->_right;}else if (key < cur->_key){parent = cur;cur = cur->_left;}else//此时为找到要删除的节点{if (cur->_left == nullptr)//左子树为空{if (parent == nullptr)//如果删除的是根节点_root = cur->_right;else if (parent->_left == cur)//如果此时要删除的节点是在父亲的左边parent->_left = cur->_right;//就让父亲的左子树变成删除节点的右子树else//如果此时要删除的节点是在父亲的右边parent->_right = cur->_right;//就让父亲的右子树变成删除节点的右子树delete cur;}else if (cur->_right == nullptr)//右子树为空{if (parent == nullptr)//如果删除的是根节点_root = cur->_left;else if (parent->_left == cur)//如果此时要删除的节点是在父亲的左边parent->_left = cur->_left;//就让父亲的左子树变成删除节点的左子树else//如果此时要删除的节点是在父亲的右边parent->_right = cur->_left;//就让父亲的右子树变成删除节点的左子树delete cur;}else//如果左右子树都有,就用右子树的最左节点或左子树的最右节点{//这里我用的是右子树的最左节点,所以先找到最左节点和最左节点的父亲Node* RTree = cur->_right;Node* RTreeparent = cur;while (RTree->_left){RTreeparent = RTree;RTree = RTree->_left;}cur->_key = RTree->_key;//将最左节点的值给要删除的节点//此时变成删除最左节点if (RTreeparent->_left == RTree)//如果最左节点是在父亲的左边RTreeparent->_left = RTree->_right;//就把父亲左子树变成删除节点的右子树(因为左子树肯定没有了)else//如果最左节点是在父亲的右边RTreeparent->_right = RTree->_right;//就把父亲右子树变成删除节点的右子树delete RTree;//最后删除这个最左节点}return true;}}return false;
}参考代码:
template<class K>
struct BTreeNode//二叉树的节点
{BTreeNode(K key,V value):_left(nullptr),_right(nullptr),_key(key),{}BTreeNode* _left;//左子树BTreeNode* _right;//右子树K _key;//键值
};template<class K>
class BTree
{
public:typedef BTreeNode<K> Node;bool Insert(const K& key)//插入新数据,bool返回值来判断插入是否成功(因为二叉搜索树是不允许有相同数据的){if (_root == nullptr)//如果根节点为空,就把值赋给根节点{_root = new Node(key);return true;}Node *cur = _root, *parent = nullptr;//双指针走法,这样可以找到要赋值节点的父亲while (cur){parent = cur;if (key > cur->_key)//如果要插入的值比当前节点大,就往右走cur = cur->_right;else if (key < cur->_key)//如果插入的值比当前节点小,就往左走cur = cur->_left;elsereturn false;//如果相同,就返回false}cur = new Node(key);//把值赋给curif (key > parent->_key)//判断cur应该放到父亲的左边还是右边parent->_right = cur;elseparent->_left = cur;return true;}void _InOrder(Node* root)//递归实现中序遍历{if (root){_InOrder(root->_left);cout << root->_key << " ";_InOrder(root->_right);}}void InOrder()//中序遍历{_InOrder(_root);//因为要递归,而且用户调用不到_root,所以要再创个用于递归的函数cout << endl;}bool Find(const K& key)//查找某个值{Node* cur = _root;while (cur){if (key > cur->_key)//如果比当前节点大,就去右子树找cur = cur->_right;else if (key < cur->_key)//如果比当前节点小,就去左子树找cur = cur->_left;elsereturn true;}return false;}bool Erase(const K& key)//删除某个值(节点){//找到要删除的那个值Node* cur = _root, * parent = nullptr;while (cur){if (key > cur->_key){parent = cur;cur = cur->_right;}else if (key < cur->_key){parent = cur;cur = cur->_left;}else//此时为找到要删除的节点{if (cur->_left == nullptr)//左子树为空{if (parent == nullptr)//如果删除的是根节点_root = cur->_right;else if (parent->_left == cur)//如果此时要删除的节点是在父亲的左边parent->_left = cur->_right;//就让父亲的左子树变成删除节点的右子树else//如果此时要删除的节点是在父亲的右边parent->_right = cur->_right;//就让父亲的右子树变成删除节点的右子树delete cur;}else if (cur->_right == nullptr)//右子树为空{if (parent == nullptr)//如果删除的是根节点_root = cur->_left;else if (parent->_left == cur)//如果此时要删除的节点是在父亲的左边parent->_left = cur->_left;//就让父亲的左子树变成删除节点的左子树else//如果此时要删除的节点是在父亲的右边parent->_right = cur->_left;//就让父亲的右子树变成删除节点的左子树delete cur;}else//如果左右子树都有,就用右子树的最左节点或左子树的最右节点{//这里我用的是右子树的最左节点,所以先找到最左节点和最左节点的父亲Node* RTree = cur->_right;Node* RTreeparent = cur;while (RTree->_left){RTreeparent = RTree;RTree = RTree->_left;}cur->_key = RTree->_key;//将最左节点的值给要删除的节点//此时变成删除最左节点if (RTreeparent->_left == RTree)//如果最左节点是在父亲的左边RTreeparent->_left = RTree->_right;//就把父亲左子树变成删除节点的右子树(因为左子树肯定没有了)else//如果最左节点是在父亲的右边RTreeparent->_right = RTree->_right;//就把父亲右子树变成删除节点的右子树delete RTree;//最后删除这个最左节点}return true;}}return false;}
private:Node* _root = nullptr;
};二叉搜索树K/V模型的模拟实现:
K模型是指key模型,即只存储一个键值
K/V模型是指key/value模型,在上面的K模型中,节点只会存储一个K类型的key,但在K/V模型中,除了存储key,还会存储一个V类型的value,有什么应用场景呢?
K模型场景举例:通过学号查询学生是否存在;注册系统中校验用户名是否已被占用
虽然这些操作用数组遍历也能做到,但遍历是时间复杂度是O(N),而用二叉搜索树后的时间复杂度只有O(logN)
K/V模型场景举例:英汉词典中通过英文单词查找对应的中文翻译
例如key中存apple,value中存苹果,就可以通过找apple来输出苹果
K/V模型的实现只需要在K模型的基础上加上V就可以了
template<class K,class V>
struct BTreeNode
{BTreeNode(K key , V value):_left(nullptr),_right(nullptr),_key(key),_value(value){}BTreeNode* _left;//左子树BTreeNode* _right;//右子树K _key;//键值V _value;//对应数据
};template<class K,class V>
class BTree
{
public:typedef BTreeNode<K,V> Node;bool Insert(const K& key,const V& value)//插入新数据,bool返回值来判断插入是否成功(因为二叉搜索树是不允许有相同数据的){if (_root == nullptr)//如果根节点为空,就把值赋给根节点{_root = new Node(key,value);return true;}Node *cur = _root, *parent = nullptr;//双指针走法,这样可以找到要赋值节点的父亲while (cur){parent = cur;if (key > cur->_key)//如果要插入的值比当前节点大,就往右走cur = cur->_right;else if (key < cur->_key)//如果插入的值比当前节点小,就往左走cur = cur->_left;elsereturn false;//如果相同,就返回false}cur = new Node(key,value);//把值赋给curif (key > parent->_key)//判断cur应该放到父亲的左边还是右边parent->_right = cur;elseparent->_left = cur;return true;}void _InOrder(Node* root)//递归实现中序遍历{if (root){_InOrder(root->_left);cout << root->_key << ":" << root->_value << endl;_InOrder(root->_right);}}void InOrder()//中序遍历{_InOrder(_root);//因为要递归,而且用户调用不到_root,所以要再创个用于递归的函数cout << endl;}Node* Find(const K& key)//查找某个值{Node* cur = _root;while (cur){if (key > cur->_key)//如果比当前节点大,就去右子树找cur = cur->_right;else if (key < cur->_key)//如果比当前节点小,就去左子树找cur = cur->_left;elsereturn cur;}return nullptr;}bool Erase(const K& key)//删除某个值(节点){//找到要删除的那个值Node* cur = _root, * parent = nullptr;while (cur){if (key > cur->_key){parent = cur;cur = cur->_right;}else if (key < cur->_key){parent = cur;cur = cur->_left;}else//此时为找到要删除的节点{if (cur->_left == nullptr)//左子树为空{if (parent == nullptr)//如果删除的是根节点_root = cur->_right;else if (parent->_left == cur)//如果此时要删除的节点是在父亲的左边parent->_left = cur->_right;//就让父亲的左子树变成删除节点的右子树else//如果此时要删除的节点是在父亲的右边parent->_right = cur->_right;//就让父亲的右子树变成删除节点的右子树delete cur;}else if (cur->_right == nullptr)//右子树为空{if (parent == nullptr)//如果删除的是根节点_root = cur->_left;else if (parent->_left == cur)//如果此时要删除的节点是在父亲的左边parent->_left = cur->_left;//就让父亲的左子树变成删除节点的左子树else//如果此时要删除的节点是在父亲的右边parent->_right = cur->_left;//就让父亲的右子树变成删除节点的左子树delete cur;}else//如果左右子树都有,就用右子树的最左节点或左子树的最右节点{//这里我用的是右子树的最左节点,所以先找到最左节点和最左节点的父亲Node* RTree = cur->_right;Node* RTreeparent = cur;while (RTree->_left){RTreeparent = RTree;RTree = RTree->_left;}cur->_key = RTree->_key;//将最左节点的值给要删除的节点//此时变成删除最左节点if (RTreeparent->_left == RTree)//如果最左节点是在父亲的左边RTreeparent->_left = RTree->_right;//就把父亲左子树变成删除节点的右子树(因为左子树肯定没有了)else//如果最左节点是在父亲的右边RTreeparent->_right = RTree->_right;//就把父亲右子树变成删除节点的右子树delete RTree;//最后删除这个最左节点}return true;}}return false;}
private:Node* _root = nullptr;
};K/V模型的简单应用举例:
就拿上面说过的词典来举例,K值是英语单词,V值是对应的中文意思,这样就可以通过查找英语单词来输出中文意思
BTree<string, string> Dict;//二叉搜索树
Dict.Insert("apple", "苹果");//单词插入
Dict.Insert("banana", "香蕉");
Dict.Insert("code", "代码");
Dict.Insert("bug", "虫子");
Dict.Insert("kingdom", "王国");
string eng;//输入的字符串
while (cin >> eng)
{BTreeNode<string, string>* zh = Dict.Find(eng);//找到的节点if (zh != nullptr)cout << zh->_value << endl;elsecout << "词典没有此单词\n";
} 输出结果:(Ctrl+Z是给eng字符串传NULL值)
还可以用K/V模型来统计每个key出现的次数,只要将V的类型设为int,每遇到一次就让V++,就可以统计出每个key所对应的出现次数
string strs[] = { "野兽先辈","想啊,很想啊","王爷","野兽先辈","想啊,很想啊","野兽先辈","想啊,很想啊","极霸矛嘛","想啊,很想啊","野兽先辈","野兽先辈"};
BTree<string, int> cnt;//计数的二叉搜索树
for (const auto& phr : strs)//遍历数组
{if (BTreeNode<string, int>* node = cnt.Find(phr))//如果能在树中找到该字符串node->_value++;//就只需要让它的次数+1elsecnt.Insert(phr, 1);//如果找不到,就创建一个节点,次数是1
}
cnt.InOrder();输出结果:

二叉搜索树的局限性:
一般来讲,二叉搜索树查找数据的效率都是O(logN),但这是数据无序的情况下
如果要放到树中的数据是接近于升序或升序,例如{1,2,3,4,5},在树的结构就会是这样
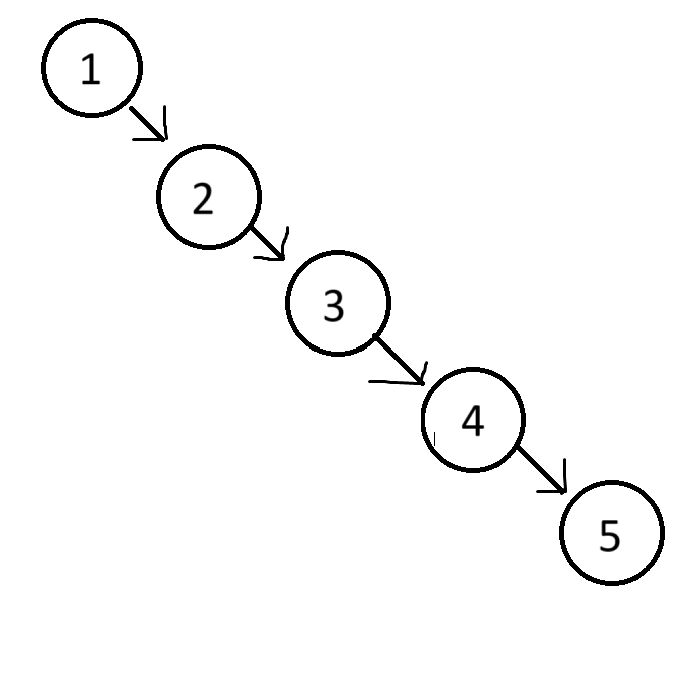
此时再查找5,时间复杂度就成了O(N),和数组对比还有优势吗?
所以实战中都不会仅仅使用二叉搜索树,而是用它的改进版:AVLTree和红黑树
而这两个都是平衡二叉搜索树