Go语言爬虫系列教程(一) 爬虫基础入门
Go爬虫基础入门
1. 网络爬虫概念介绍
1.1 什么是网络爬虫
网络爬虫(Web Crawler),又称网页蜘蛛、网络机器人,是一种按照一定规则自动抓取互联网信息的程序或脚本。其核心功能是模拟人类浏览网页的行为,通过发送网络请求、解析响应内容,批量获取目标数据。爬虫广泛应 用于数据采集、搜索引擎索引构建、竞品分析、学术研究等领域。
我们可以把互联网比作一张大网,而爬虫便是在网上爬行的蜘蛛。把网的节点比作一个个网页,爬虫爬到这就相当于访问了该页面,获取了其信息。可以把节点间的连线比作网页与网页之间的链接关系,这样蜘蛛通过一个节点后,可以顺着节点连线继续爬行到达下一个节点,即通过一个网页继续获取后续的网页,这样整个网的节点便可以被蜘蛛全部爬行到,网站的数据就可以被抓取下来了,这也是为什么爬虫会用spider表示了。
1.2 核心工作流程
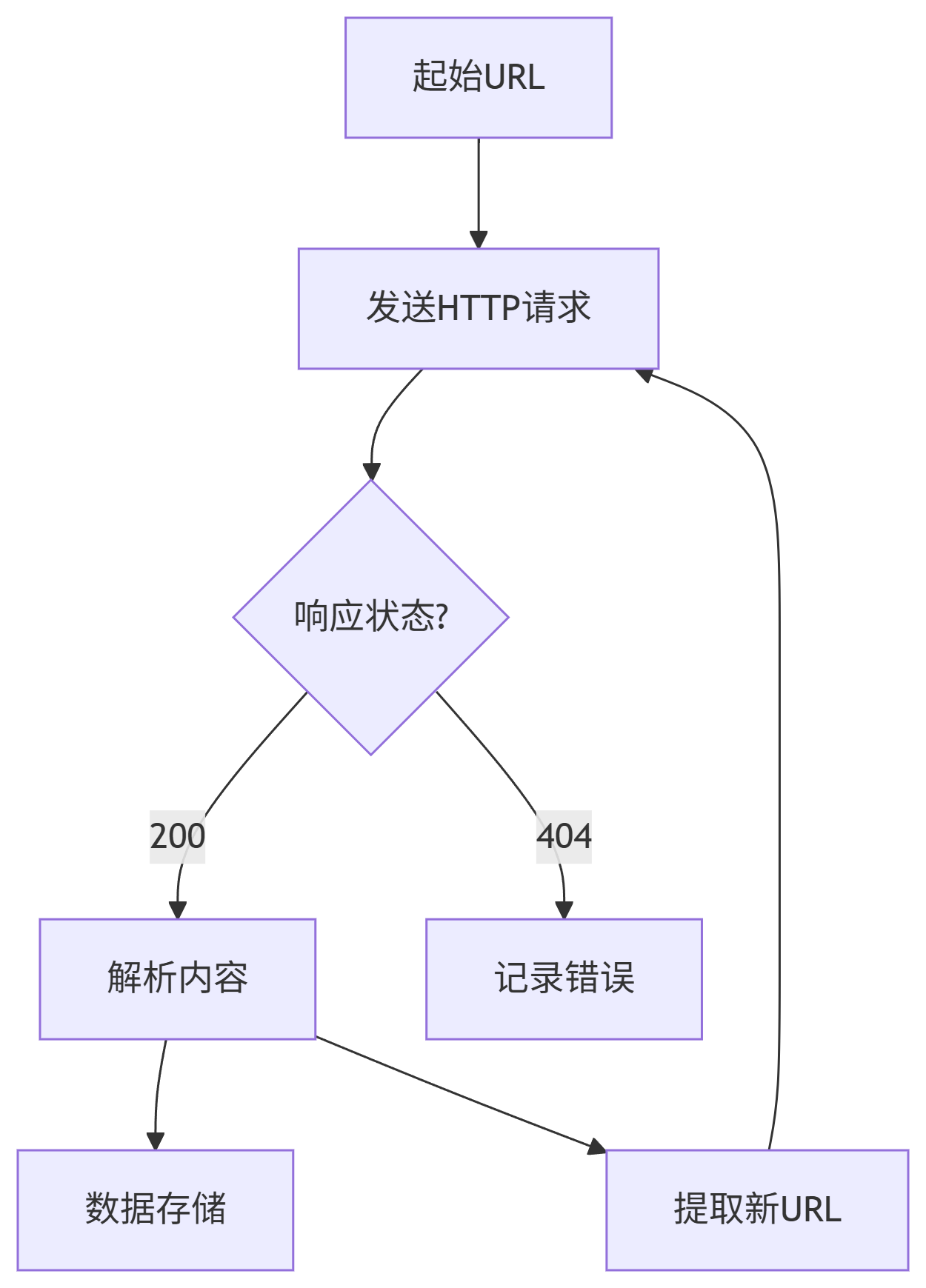
爬虫的工作流程可概括为以下 5 个关键步骤,:
-
发送 HTTP 请求
- 向目标网站的 URL 发送请求(如
GET/POST),模拟浏览器请求网页数据 - 就像你在浏览器地址栏输入网址并按下回车键
- 示例:使用
curl https://example.com命令或Go代码中的http.Get("https://example.com")
- 向目标网站的 URL 发送请求(如
-
获取响应内容
- 接收服务器返回的响应,通常包含网页的 HTML/JSON 数据、状态码、响应头等
- 类似于你看到网页在浏览器中加载出来
- 关键点:检查状态码(200表示成功,404表示页面不存在)和内容类型(HTML/JSON/XML等)
-
解析数据
- 从响应内容中提取所需信息,如标题、正文、图片链接等
- 想象你在阅读报纸,但只关注特定的新闻或广告
- 方法:
- HTML解析:使用Go的
goquery库(类似jQuery) - JSON解析:使用Go的
encoding/json库 - 正则表达式:使用
regexp包匹配特定模式
- HTML解析:使用Go的
-
数据存储
- 将提取的数据保存到本地或数据库中,便于后续分析和使用
- 常用存储方式:
- 文本文件(CSV、JSON):简单直接,适合小数据量
- 数据库(MySQL、MongoDB):结构化存储,支持查询
- 云存储(S3、OSS):大规模数据存储
-
跟进链接
- 从当前页面中提取新的URL,加入待爬队列,循环处理以抓取更多相关页面
- 就像你阅读一本书,发现参考文献后决定再去查阅那些书籍
- 实现方式:使用队列或集合存储未访问的URL,确保不重复爬取
1.3 爬虫的典型应用场景
-
搜索引擎:
- Google、百度通过爬虫抓取全网页面,构建索引库
- 实现原理:定期爬取互联网页面,提取关键词和内容,建立倒排索引
- Go语言优势:高并发能力使其能同时处理大量网页请求
-
数据分析与市场研究:
- 爬取电商平台价格、评论数据进行竞品分析
- 案例:某电商可以通过爬虫监控竞争对手的价格变动,及时调整自身定价策略
- 实现方式:针对特定网站设计爬虫,定期抓取并分析数据变化
-
内容聚合:
- 新闻聚合平台收集各大媒体最新报道
- 技术要点:提取正文、去重、分类、时效性处理
- 使用Go的协程可实现高效的并发爬取多个新闻源
-
学术研究数据采集:
- 收集科研论文、专利信息或公开数据集
- 例如:分析某领域研究热点趋势、引用关系网络
- 需注意学术平台的使用条款和访问限制
-
自动化监控:
- 监控网站内容变更、价格波动、库存变化
- 实际应用:房产网站监控新房源、机票价格跟踪
- Go实现:结合定时任务(cron)和爬虫,实现自动化监控和通知
1.4 爬虫的分类
根据不同的维度,爬虫可分为多种类型:
按抓取策略分类
| 类型 | 核心算法 | 适用场景 | Go 实现要点 |
|---|---|---|---|
| 广度优先 (BFS) | 队列 (FIFO) | 全站爬取(如搜索引擎) | 使用 channel 实现 URL 队列 |
| 深度优先 (DFS) | 栈 (LIFO) | 单页面深度数据挖掘 | 递归实现页面跳转 |
| 最佳优先 | 优先级队列 | 重点数据优先抓取 | 实现评分函数排序 URL |
| 广度优先爬虫示意: |
第1层:首页A
第2层:A链接到的页面B、C、D
第3层:B、C、D链接到的新页面...
深度优先爬虫示意:
首页A → A链接到的页面B → B链接到的页面E → E链接到的页面...↓(回溯后)↓A链接到的页面C → ...
按技术架构分类
-
单机爬虫:
- 在单个主机上运行,适合小规模数据采集
- 优势:实现简单,部署方便
- 局限:爬取速度和规模有限
- Go实现:利用goroutine实现并发爬取,提高单机效率
-
分布式爬虫:
- 通过多台主机协作,并行处理大量 URL
- 适用:搜索引擎、大型数据服务公司
- 技术挑战:URL分配策略、任务调度、结果合并
- Go实现:结合消息队列(如Kafka)和微服务架构
按目标网站交互方式分类
-
静态网页爬虫:
- 直接获取HTML内容并解析
- 适合:内容直接包含在源代码中的网站
- 优势:实现简单、速度快
- 示例:
goquery库解析HTML
-
动态网页爬虫:
- 需处理JavaScript渲染的内容
- 适合:现代SPA(单页应用)网站
- 实现方式:
- 使用无头浏览器(如Chrome Headless)
- 分析并模拟API请求
- Go工具:可结合
chromedp库实现浏览器自动化
1.5 法律规范与伦理道德
虫开发不仅是技术问题,更涉及法律和伦理边界。负责任的爬虫开发者应当:
-
遵守
robots.txt协议:网站通过robots.txt声明禁止爬虫抓取的页面(如User-Agent: * Disallow: /private/),爬虫需遵守规则以避免滥用。 -
限制请求频率:过度频繁的请求会增加服务器负担,需设置合理的请求间隔(如每次请求间隔 1 秒)。
-
尊重版权:不得抓取受保护的内容(如付费文档、用户隐私数据),避免侵权。
-
避免过度爬取: 只获取确实需要的数据,不进行无目的大规模爬取,考虑使用网站提供的官方API(如有)替代爬虫
-
识别与处理个人敏感数据: 若爬取内容含个人可识别信息(PII),需慎重处理并遵守数据保护法规,实施数据匿名化处理
2. HTTP协议基础
爬虫本质上就是模拟浏览器请求,并获取相应信息,所以写爬虫之前,我们还需要了解一些HTTP的基础知识。
2.1 HTTP简介
HTTP(HyperText Transfer Protocol,超文本传输协议) 是互联网上应用最广泛的应用层协议,用于客户端(如浏览器)与服务器之间的数据通信。它基于 TCP/IP 协议,定义了客户端如何向服务器发送请求、服务器如何响应请求,以及数据传输的格式和规则。
HTTP的特点:
- 无状态 - 服务器不会保存客户端的历史请求信息(解决方案:Cookie/Session)
- 基于请求-响应模型 - 客户端发起请求,服务器返回响应
- 支持多种数据类型 - 文本、图片、视频、应用程序等
HTTP就像你去餐厅点餐。点餐(请求)时,你需要明确告诉服务员(服务器)你想要什么菜(资源),怎么做(请求体)。服务员记下后去后厨,然后把菜(响应体)送到你桌上。每次点菜都是独立的,服务员不会记得你上次点了什么(无状态)。如果是你经常去的店铺,老板跟你也很熟悉,知道你要点什么菜(有状态)
2.2 HTTP 请求结构详解
一个完整的HTTP请求由三部分组成:请求行、请求头和请求体。
# 请求行
GET /index.html HTTP/1.1 # 方法 + URL + 协议版本 # 请求头(键值对,描述请求信息)
Host: www.example.com # 目标服务器域名
User-Agent: Mozilla/5.0 # 客户端标识
Accept: text/html,application/xml # 可接受的响应类型
Content-Type: application/json # 请求体格式(仅 POST/PUT 等方法有)
Cookie: sessionId=12345 # 会话信息 # 请求体(仅 POST/PUT 等方法才存在)
{ "name": "clown", "age": 30 }请求方法详解
每种HTTP方法都有特定用途,在爬虫开发中需根据目标网站的API设计选择合适的方法:
| 方法 | 用途 | 爬虫应用场景 | 是否有请求体 |
|---|---|---|---|
GET | 获取资源 | 抓取网页内容、下载图片、获取API数据 | 否 |
POST | 提交数据(创建资源) | 表单登录、发送搜索参数、上传文件 | 是 |
PUT | 更新资源(覆盖完整资源) | 更新用户信息(少用于爬虫) | 是 |
DELETE | 删除资源 | 删除用户上传内容(少用于爬虫) | 否 |
HEAD | 仅获取响应头(不获取正文) | 检查资源是否存在、获取文件大小 | 否 |
OPTIONS | 获取服务器支持的方法列表 | 跨域请求前的预检(CORS) | 否 |
Go爬虫中的应用示例:
// GET请求示例
resp, err := http.Get("https://example.com")// POST请求示例
data := strings.NewReader(`{"username":"test","password":"123456"}`)
resp, err := http.Post("https://example.com/login", "application/json", data)// 自定义请求(任何方法)
req, err := http.NewRequest("HEAD", "https://example.com/large-file.zip", nil)
resp, err := http.DefaultClient.Do(req)
重要请求头及其作用
在爬虫开发中,正确设置请求头对成功获取数据至关重要:
| 请求头名称 | 作用 | 爬虫注意事项 |
|---|---|---|
User-Agent | 标识客户端类型(浏览器/爬虫) | 模拟真实浏览器避免被屏蔽,如Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 |
Referer | 表示请求来源页面 | 部分网站通过验证Referer防盗链,需模拟正确来源 |
Cookie | 存储用户会话信息 | 爬取需登录的页面时必须设置,常需先模拟登录获取 |
Accept | 指定可接受的响应内容类型 | 设置为text/html获取网页,application/json获取API数据 |
Accept-Language | 首选语言 | 国际网站可能根据此返回不同语言内容 |
Authorization | 身份验证信息 | API访问常用,如Bearer <token> |
| Accept-Encoding | 支持的压缩方式 | 这个是用来控制输出的字符编码的,在爬虫中如果遇到输出结果乱码,就需要取消这个参数 |
| Accept-Language | 首选语言 | 获取特定语言内容:Accept-Language: zh-CN,en;q=0.9 |
| 除了以上的一些请求参数,还有一些网站自有的的请求参数,用来验证请求是否合法的,例如: |
- 小红书的 x-s、x-t等参数
- 抖音的a_bogus、msToken等参数
Go代码中设置请求头示例:
req, err := http.NewRequest("GET", "https://example.com", nil)
if err != nil {log.Fatal(err)
}// 设置User-Agent模拟Chrome浏览器
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/91.0.4472.124")
// 设置Referer
req.Header.Set("Referer", "https://example.com/")
// 设置Cookie
req.Header.Set("Cookie", "sessionId=abc123; userId=123456")client := &http.Client{}
resp, err := client.Do(req)
2.3 HTTP响应(Response)结构详解
由 状态行、响应头、响应体(可选) 三部分组成。
# 状态行
HTTP/1.1 200 OK # 协议版本 + 状态码 + 原因短语# 响应头(键值对,描述响应信息)
Content-Type: text/html; charset=utf-8 # 响应体格式
Content-Length: 12345 # 响应体字节数
Set-Cookie: sessionId=67890; Max-Age=3600 # 设置客户端 Cookie
Date: Mon, 12 May 2025 12:00:00 GMT # 响应生成时间# 响应体(资源内容,如 HTML、JSON、图片二进制数据)
<!DOCTYPE html><html><body>Hello World!</body></html>
响应内容的处理策略
根据Content-Type,爬虫需采用不同处理策略:
| 内容类型 | 常见用途 | Go处理方法 |
|---|---|---|
text/html | 网页内容 | 使用goquery或Go标准库解析HTML |
application/json | API数据 | 使用encoding/json库解析 |
text/plain | 纯文本数据 | 直接读取字符串处理 |
image/* | 图片内容 | 保存为文件或使用image包处理 |
application/pdf | PDF文档 | 保存为文件,使用第三方库解析 |
2.4 HTTP状态码详解与爬虫处理策略
HTTP状态码是服务器对请求处理结果的标识,对爬虫行为有重要指导意义:
| 状态码 | 含义 | 爬虫处理策略 |
|---|---|---|
| 2xx - 成功 | ||
| 200 OK | 请求成功 | 常规处理,解析响应内容 |
| 201 Created | 资源创建成功 | POST请求后确认资源创建(少用于爬虫) |
| 204 No Content | 成功但无返回内容 | 适用于只需确认操作成功的场景 |
| 3xx - 重定向 | ||
| 301 Moved Permanently | 永久重定向 | 更新URL缓存,访问新地址 |
| 302 Found | 临时重定向 | 跟随重定向但不更新缓存 |
| 304 Not Modified | 内容未变化 | 可使用本地缓存(配合If-Modified-Since头) |
| 4xx - 客户端错误 | ||
| 400 Bad Request | 请求格式错误 | 检查请求参数和格式 |
| 401 Unauthorized | 未认证 | 需添加/更新认证信息(如登录) |
| 403 Forbidden | 拒绝访问 | 可能触发反爬机制,考虑降低请求频率或更换IP |
| 404 Not Found | 资源不存在 | 检查URL是否正确,可从链接源更新URL |
| 429 Too Many Requests | 请求过多 | 降低请求频率,实现自动退避算法 |
| 5xx - 服务器错误 | ||
| 500 Internal Server Error | 服务器内部错误 | 通常非爬虫导致,可稍后重试 |
| 502 Bad Gateway | 网关错误 | 可能是服务器过载,稍后重试 |
| 503 Service Unavailable | 服务暂时不可用 | 实现指数退避重试策略 |
| Go中的状态码处理示例: |
resp, err := http.Get(url)
if err != nil {log.Printf("请求失败: %v", err)return
}
defer resp.Body.Close()switch resp.StatusCode {
case http.StatusOK: // 200// 正常处理body, err := io.ReadAll(resp.Body)// ...处理内容case http.StatusMovedPermanently, http.StatusFound: // 301, 302// 处理重定向newLocation := resp.Header.Get("Location")log.Printf("重定向到: %s", newLocation)// 访问新URL...case http.StatusNotFound: // 404log.Printf("页面不存在: %s", url)// 可能需要更新URL库或移除此URLcase http.StatusTooManyRequests: // 429log.Printf("请求频率过高,等待后重试")// 实现退避算法time.Sleep(30 * time.Second)// 重试...case http.StatusInternalServerError: // 500log.Printf("服务器错误,稍后重试")// 实现延迟重试// ...
}
3. 简单爬虫示例
接下来开始我们,第一个爬虫演示,目标站点是:https://httpbin.org/get ,这个站点响应的内容是我们访问站点的请求体
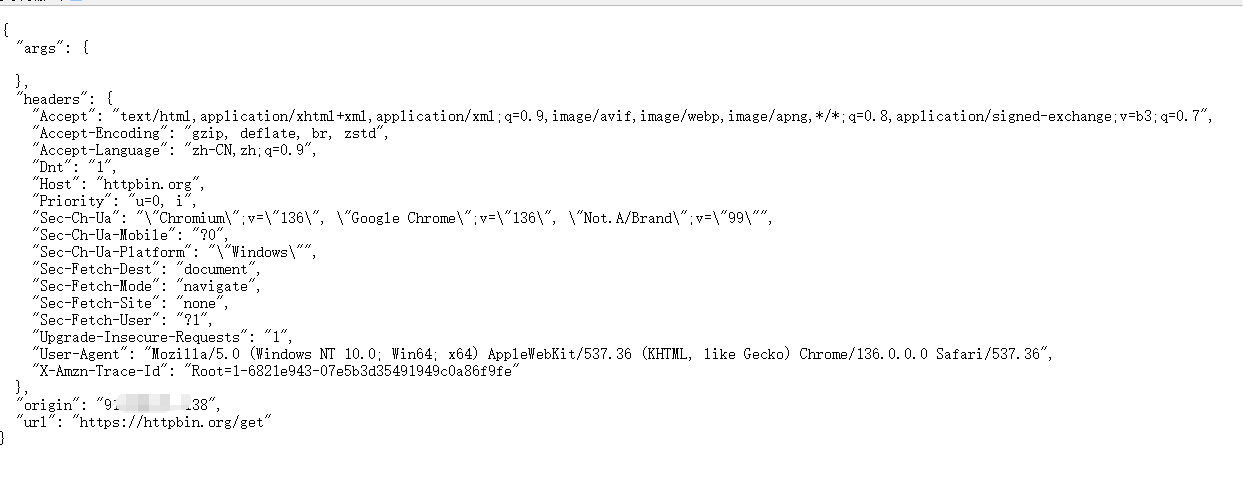
下面就让我用程序来获取这些内容:
package mainimport ("fmt""io""net/http""os"
)func main() {// 目标URLurl := "https://httpbin.org/get"// 发送HTTP GET请求resp, err := http.Get(url)if err != nil {fmt.Printf("访问url错误: %v\n", err)return}defer resp.Body.Close() // 确保响应体最终被关闭// 检查状态码if resp.StatusCode != http.StatusOK {fmt.Printf("请求错误,状态码为: %d\n", resp.StatusCode)return}// 读取响应体body, err := io.ReadAll(resp.Body)if err != nil {fmt.Printf("读取response body错误: %v\n", err)return}//输出响应体fmt.Println(string(body))// 保存到文件file, err := os.Create("output.html")if err != nil {fmt.Printf("创建文件错误: %v\n", err)return}defer file.Close() // 确保文件最终被关闭_, err = file.Write(body)if err != nil {fmt.Printf("写入文件错误: %v\n", err)return}fmt.Println("成功保存文件 output.html")fmt.Printf("内容长度: %d bytes\n", len(body))
}代码解析与要点说明:
-
导入必要包:
net/http- 提供HTTP客户端和服务器实现io- 提供基本I/O操作os- 提供操作系统功能,如文件操作
-
设置目标URL:
url := "https://httpbin.org/get"- 定义要爬取的网页地址- httpbin.org是测试HTTP请求的实用网站,
/get端点返回简单json页面
-
发送GET请求:
resp, err := http.Get(url)- 使用标准库发送HTTP GET请求- 这行代码等同于浏览器在地址栏输入URL并按回车
-
错误处理与资源释放:
- 检查
err != nil确保请求成功 defer resp.Body.Close()- 确保在函数结束时关闭响应体,防止资源泄漏- 资源释放是Go编程的重要实践,尤其在爬虫这类I/O密集型应用中
- 检查
-
状态码检查:
if resp.StatusCode != http.StatusOK- 确认服务器返回200成功状态- 避免处理错误页面(如404页面),确保获得预期内容
-
读取响应内容:
body, err := io.ReadAll(resp.Body)- 将整个响应体读入内存- 适用于小型页面,大文件应考虑流式处理
-
保存到文件:
file, err := os.Create("output.html")- 创建输出文件file.Write(body)- 将响应内容写入文件- 实际爬虫通常会解析内容而非直接保存
-
结果反馈:
- 打印成功消息和内容长度,提供操作反馈