GTC2025——英伟达布局推理领域加速
英伟达GTC2025大会于今年3月18日举行,会上NVIDIA CEO黄仁勋展示了其过去所取得的成就,以及未来的布局目标——通过纵向扩展(scale out)和横向扩展(scale up)解决终极的计算问题——推理。本文将回顾NVIDIA在近年来的多项成就,并结合GTC2025大会上黄仁勋主题演讲的内容,解析英伟达最新的技术动态,并分析当前硬件行业开发者的挑战与机遇。
一、GTC会议介绍
GTC会议,全称GPU Technology Conference(GPU技术大会),是由NVIDIA主办的全球顶级科技开发者盛会。GTC最早于2009年举办,每年一届,已成为GPU计算、人工智能(AI)、深度学习、高性能计算、自动驾驶、数据中心、工业仿真、图形渲染、边缘计算以及元宇宙等相关领域前沿技术的重要发布和交流平台。
近十年来,GTC大会持续聚焦于AI算力的竞赛与全球技术布局。自2017年推出集成Tensor Core的Volta架构以来,英伟达正式开启了AI专用计算新时代,GPU在深度学习、AI训练及推理加速中的优势日益凸显。自2022年起,黄仁勋在GTC大会上接连发布了H100(Hopper)、GH200(Grace Hopper超级芯片)、B100/B200(Blackwell)等重磅产品,并围绕自动驾驶(Orin平台)、智能生物医疗(Clara平台)、元宇宙协作(Omniverse平台)、生成式AI等前沿行业应用展开主题阐述,进一步巩固了NVIDIA在全球AI训练领域无可撼动的领先地位。
GTC2025于2025年3月17日至21日在美国加利福尼亚州圣何塞的McEnery会议中心隆重举行。黄仁勋在Keynote演讲中将GTC从"AI行业的伍德斯托克摇滚音乐节"的比喻升级为"AI行业的超级碗",反映了该会议在全球科技领域的重要地位。本届大会包含超过1,000场专题演讲,邀请了2,000位演讲嘉宾,近400家企业参展,涵盖的track极为广泛,包含1)具身AI与机器人;2)Agentic AI;3)量子计算;4)数字中心与云基础设施;5)生成式AI应用;6)科学计算与模拟;7)OpenUSD与数字孪生;8)自动驾驶与交通技术;9)网络安全;10)企业生产力与自动化等等主题。

图1 GTC2025在美国加州圣何塞举行
黄仁勋认为,AI正在经历三个发展阶段,生成式AI->代理AI->具身AI,目前AI已进入代理AI阶段,这一阶段的特点是AI系统能够自主规划、推理并完成复杂任务。黄仁勋强调,业界此前对AI算力需求增长放缓的判断是错误的,尤其是针对中国DeepSeek开发的能在较少芯片上运行的新AI模型的说法。算力市场需求仍然强劲,机器人、智能驾驶等落地应用场景火热增长。然而推理和训练的需求很不同,主题演讲中多次提及Agentic AI与推理,并强调了推理能力在端侧的重要性:“训练在乎的是时间,推理在乎的是成本”。本文将从“推理”出发,围绕黄仁勋在GTC2025的主题演讲展开讨论。

图2 GTC2025黄仁勋主题演讲现场
二、关键技术概述
黄仁勋将如今的大模型厂商比作一个AI工厂,它原材料是GPU和电力,产品是token。传统的逻辑推理大模型推理相比于传统大模型带来了更高的token要求:用户希望更快、更廉价的token,可以在相比以往成本几乎不变的前提下更好地解决问题;企业希望提升token产生的速度,以产生更多的token获取利润。但受限于能源问题,必须提高单位能源下的token产出数量。作为AI工厂设备提供方的NVIDIA为此提出了他们的野心——纵向扩展(scale up)和横向扩展(scale out)。
所谓纵向扩展,就是更强的集中式计算,让一个机架内集成更多的GPU或使其中的GPU具有更强的算力,它解决的是一个机架内的问题;横向扩展就是,让AI工厂内的所有GPU总体的产能最高,它解决的是数据工厂内多个机架沟通的问题。为此,英伟达提出了他们的最新解决方案——Dynamo和CPO。
(一)Dynamo
Dynamo是一个开源的推理服务框架,起到更高层次的、专门为大规模AI工作负载设计的运行时和编排管理系统。它是英伟达为应对AI规模化时代提出的一个关键软件基础设施组件,可以认为是AI工厂的大脑。Dynamo的核心任务是高效地管理和调度在数千个GPU上运行的复杂和庞大的模型所需的一切资源,是提高现有AI工厂投入产出比、面向未来模型容量更大计算需求更高情形的前瞻性解决方案。主要包括以下功能:
(1)分离式预填充和解码推理:将大型语言模型(LLM)的处理和生成阶段分离到不同的GPU上,从而提高每个GPU的吞吐量。简单来说,就是将任务拆分,让一组GPU处理数据,另一组GPU生成最终输出。
(2)动态GPU调度:根据需求的波动动态调度GPU,以优化性能。
(3)LLM感知请求路由:避免KV缓存的重新计算成本。通过减少不必要的KV缓存重新计算释放GPU资源。
(4)加速异步数据传输:在GPU之间加速异步数据传输,以减少推理响应时间。
(5)KV缓存跨内存层级管理:将KV缓存分布在数千个GPU上,并跨越不同的内存层级进行卸载,以提高系统吞吐量。
(6)智能路由器:在多GPU推理部署中合理分配每个token,确保在预加载和解码阶段均衡负载,避免瓶颈。
(7)GPU规划器:可以自动调整预加载和解码节点,依据日内需求波动动态增加或重新分配GPU资源,进一步实现负载均衡。
(8)改进的NCCL:NCCL的新算法使得小token传输延迟降低4倍,从而显著提高推理吞吐量。
通过上述优化,提升AI工厂单个机架构成的互联系统的产量。作为对比,将传统的管理多服务器的框架Hopper用于GPU最多管理8个,英伟达最新的NV Link技术可以管理72个GPU,并且在Dynamo的加持下,可以更好的在AI工厂和用户间取得平衡(图3高亮处),帮助AI工厂获取利润。
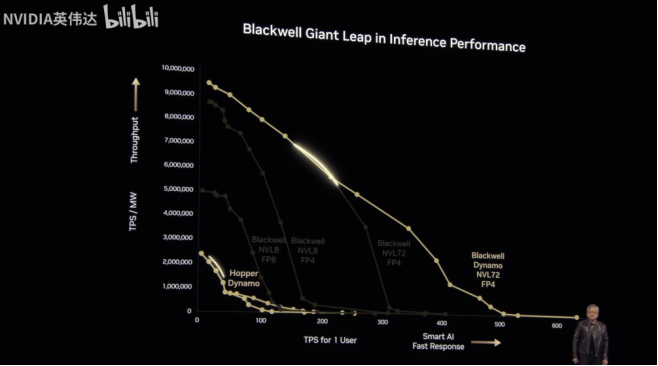
图3 Dynamo效果对比:横轴表示AI响应速度(用户端)、纵轴表示单位功耗下的计算能力(AI工厂端)
(二)CPO
Dynamo是NVIDIA为解决纵向扩展问题的答卷。然而将至数十万个GPU连在一起的挑战在于连接速度。目前单个机架内GPU的连接通常使用铜缆连接,这种方案比较可靠、能效极高、成本极低,速度可达1.8 TB/s,但适用范围仅限一两米以内,并不适用于横向扩展。CPO便是为解决以上问题被提出的。
黄仁勋表示,NVIDIA光子学团队携手产业伙伴推动CPO联合创新,包括首款采用微环谐振器调制器(Micro Ring Modulators,MRM)1.6Tbps硅光CPO芯片,首个采用TSMC制程3D堆叠硅光子引擎,搭载了高输出功率激光器和直连光纤连接器。CPO技术可以取代传统的可插拔光学收发器,使光纤直接连接到交换机,大幅减少数据中心的功耗。据英伟达测算,该技术可降低40MW的功耗,并提高AI计算集群的网络传输效率,为未来超大规模AI数据中心奠定基础。
NVIDIA CPO交换机内部涉及到的技术细节,如图4所示,包括EIC、PIC、3D封装、光耦合可插拔光连接器、光学模组、外置激光器模块、激光器芯片封装、interposer等。对于Quantum-x硅光CPO交换机而言,各组成部分是通过interposer中介实现互联的。除了中间的交换芯片(Quantum-X800 ASIC),周围的chiplet(硅光引擎)均为3D垂直堆叠:这些chiplet上层是EIC——电芯片,下层是PIC(Photonic IC)。

图4 NVIDIA CPO交换机
MRM是CPO的关键技术之一,是一种光调制技术,将电信号转换为光。硅光领域主要有两类调制器:MRM和Mach-Zehnder(MZM)。其中MZM常见于可插拔光收发器,基于这种方案的光通过波导,切分成两个并行的部分,再应用电场去做调制,改变光的相位,然后再结合构成单波导。而MRM则基于环形波导,如果光在环内谐振构成驻波,则会提取出来,过滤出来的波长用于后续处理分析。MRM具备更紧凑的特点,相比MZM的损失也更低;不过通常MRM对温度较为敏感,所以还需要配合更精准的温度控制电路。
基于上述技术,NVIDIA推出Spectrum-X和Quantum-X交换机。其中Spectrum-X以太网平台是专为多租户超大规模AI工厂设计,带宽密度达传统以太网的1.6倍,支持全球最大规模超级计算机。Quantum-X光子InfiniBand平台是基于200Gb/s SerDes技术提供144个800Gb/s端口,采用液冷设计高效冷却硅光模块,AI计算架构速度较前代提升2倍,可扩展性增强5倍。
谈及GPU纵向扩展,笔者还想简单聊聊NVIDIA GPU发展路线图。NVIDIA每年发布一次路线图,每两年推出一种架构,每年推出一个新产品线,并不断在关键技术上取得进步。之前NVIDIA相关产品以Rubin科学家命名,下一代产品将于2028年发布,以Feyman科学家命名。该信息主要为“AI工厂的建设方”服务,作用在于安抚市场信息,巩固自身地位。
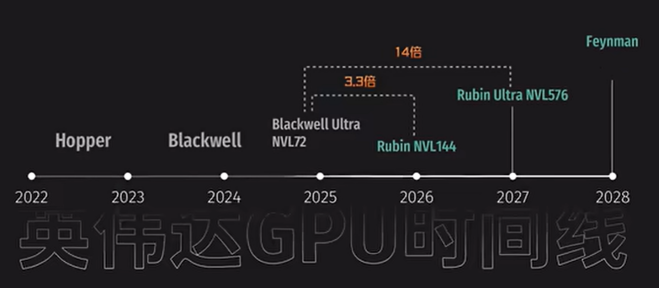
图5 英伟达GPU发布时间线
三、挑战与机遇
虽然GTC名为GPU技术大会,但黄仁勋在其主题演讲中多次强调AI工厂的组建成本与潜在收益,凸显了其商业化落地的重要性。CUDA作为并行计算平台与编程模型,高效驱动其GPU硬件,并与Torch、TensorFlow等主流框架深度绑定,共同构筑了英伟达在模型训练领域的坚实护城河,使得AMD、英特尔等传统GPU厂商及其他ASIC设计者难以望其项背。在此基础上,英伟达的战略重心在于,凭借其在模型训练领域的稳固地位,面向逻辑模型日益庞大、token计算需求激增的推理场景,进一步抢占这块新兴市场。
在推理市场,传统GPU厂商如AMD与英特尔,尽管其单颗GPU可能具备有竞争力的算力,却缺乏如NVIDIA NVLink般高效的互联技术,难以构建大规模、高带宽的计算集群。而对于ASIC设计者,其“需求定义先行、定制设计置后”的模式,在模型算法日新月异的背景下,常面临设计刚完成验证即被新模型迭代所超越的风险。
然而,随着模型推理需求的持续演进、神经网络技术的不断突破以及应用场景的日益丰富,其他GPU厂商和ASIC设计者依然拥有突围的机遇。尽管训练市场目前由NVIDIA主导,其CUDA及NVLink的技术壁垒难以轻易逾越,但推理市场不仅规模更为广阔,场景也更趋分散,且对成本和功耗表现得更为敏感。因此,针对特定推理负载优化的ASIC,尤其是在边缘计算和特定云端推理场景中,仍有巨大的市场空间。例如,在超低功耗边缘推理、特定通信算法加速、专用科学计算以及机器人特定感知与控制模块等领域,为特定算法和数据流精心设计的ASIC,依然有机会在性能、功耗与成本的综合表现上取得显著优势。此外,AI技术仍在飞速发展,新的网络模型、算法及计算范式(如神经形态计算、存内计算等)层出不穷,ASIC凭借其架构定制的灵活性,能够更敏捷地针对这些新兴方向进行创新,从而在特定赛道实现“弯道超车”。
参考资料
[1] GTC2025-黄仁勋主题演讲(nvidia.cn)
[2] 硅谷101-“再造一个CUDA”:英伟达的第二护城河与“超级碗”阳谋【深度解析GTC 2025】(bilibili.com)
[3]4个问题快速看懂NVIDIA Photonics硅光芯片:它对Agentic AI很重要?-电子工程专辑