高并发内存池(三):TLS无锁访问以及Central Cache结构设计
目录
前言:
一,thread cache线程局部存储的实现
问题引入
概念说明
基本使用
thread cache TLS的实现
二,Central Cache整体的结构框架
大致结构
span结构
span结构的实现
三,Central Cache大致结构的实现
单例模式
thread cache向Central Cache申请空间的接口
前言:
在上篇文章中,我们完成了thread chche整体结构的设计。以及项目的整体框架也已经有所了解了。
对于该项目,高并发内存池:主要分为三层结构,thread cache,Central Cache以及Page Cache。对于 thread cache,每个线程独享一个thread cache,申请资源时,优先找对应的thread cache,其中涉及到内存对齐规则的映射。
本篇会用到的知识:TLS线程局部存储,单例模式,慢开始反馈调节算法。
一,thread cache线程局部存储的实现
现在我们已经实现了thread cache的大致结构:申请空间,释放空间。
问题引入
但是现在还面临一个问题:
在多线程环境下,如何让当前的前程 只看到其对应的thread cache??其他线程的无法看到。也就是如何实现每个线程独享一个 thread cache对象???
这时就需要使用到Thread Local storage(线程局部存储),简称TLS。
概念说明
线程局部存储(TLS),是一种变量的存储方法,这个变量在它所在的线程内是全局可以访问的,但是不能被其他线程访问到,这样就保证了数据的线程独立性。而熟知的全局变量是所有线程都可以访问的,这样就不可避免需要锁来控制,从而增加了控制成本和代码复杂度。
基本使用
使用到的函数:TlsAlloc,TlsSetValue,TlsGetValue,TlsFree
当然,在使用线程局部存储时,除了使用上述Windows提供的API函数,还可以使用 Microsoft VC++ 编译器提供的如下方法定义一个线程局部变量:
__declspec(thread) int g_mydata =1
示例:
#include <iostream>
#include <Windows.h>
#include <thread>
__declspec(thread) int g_mydata = 1;
void task1()
{while (true){++g_mydata;Sleep(1000);}
}void task2()
{int n = 10;while (n--){std::cout << "g_mydata=" << g_mydata <<",线程ID为:" << std::this_thread::get_id() << std::endl;}
}//TLS线程局部存储的使用示例
void testTLS()
{std::thread t1(task1);std::thread t2(task2);t1.join();t2.join();
}int main()
{//TestFiedMemoryPool();testTLS();return 0;
}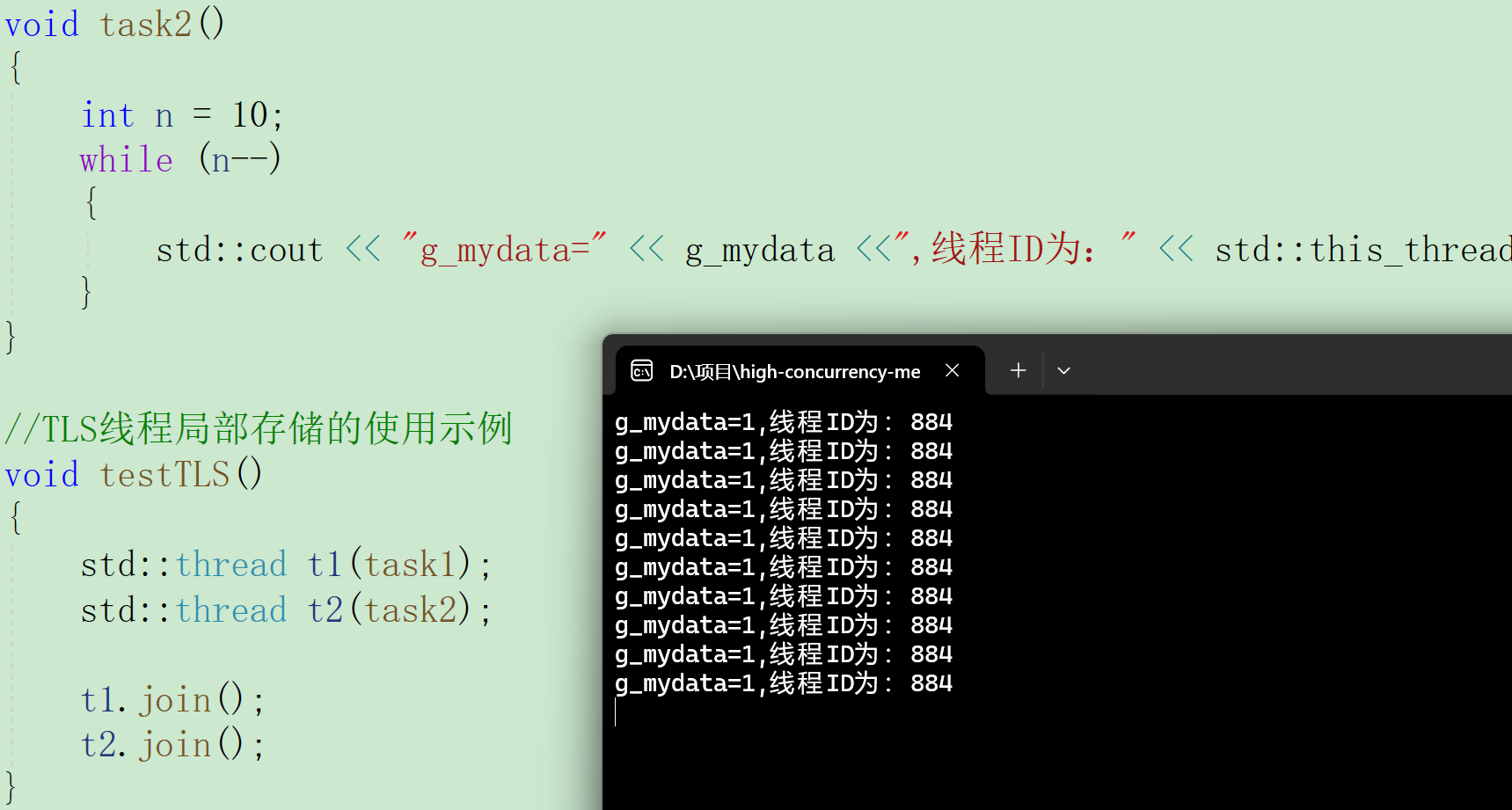
可以看到,一个线程 在对该数据进行修改时,另一个线程看到的数据不变。这就是线程局部存储,每个线程只能看到自己对应的数据,不能看到其他线程的。
thread cache TLS的实现
现在通过TLS,就可以实现 每个线程独享一个thread cache,并且其他线程 无法获取到。
//线程局部存储::TLS机制
//每个线程只能看到自己的thread cahce
__declspec(thread) threadCache* pTLSThreadCache = nullptr;刚开始,每个线程启动时,我们都是通过 thread cache对象来进行申请空间,同时释放空间的。所以,我们可以再增加两个接口,申请空间,会先找到对应 的thread cache对象,再调用其申请空间的接口。同样,释放空间也是如此。代码如下:
//相当于对thread cache做了一层封装
//申请size大小的空间
static void* ConsurrentAlloc(size_t size)
{if (pTLSThreadCache == nullptr){pTLSThreadCache = new threadCache;}return pTLSThreadCache->Allocate(size);
}//释放空间接口
static void ConcurrentDealloc(void* ptr, size_t size)
{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);
}二,Central Cache整体的结构框架
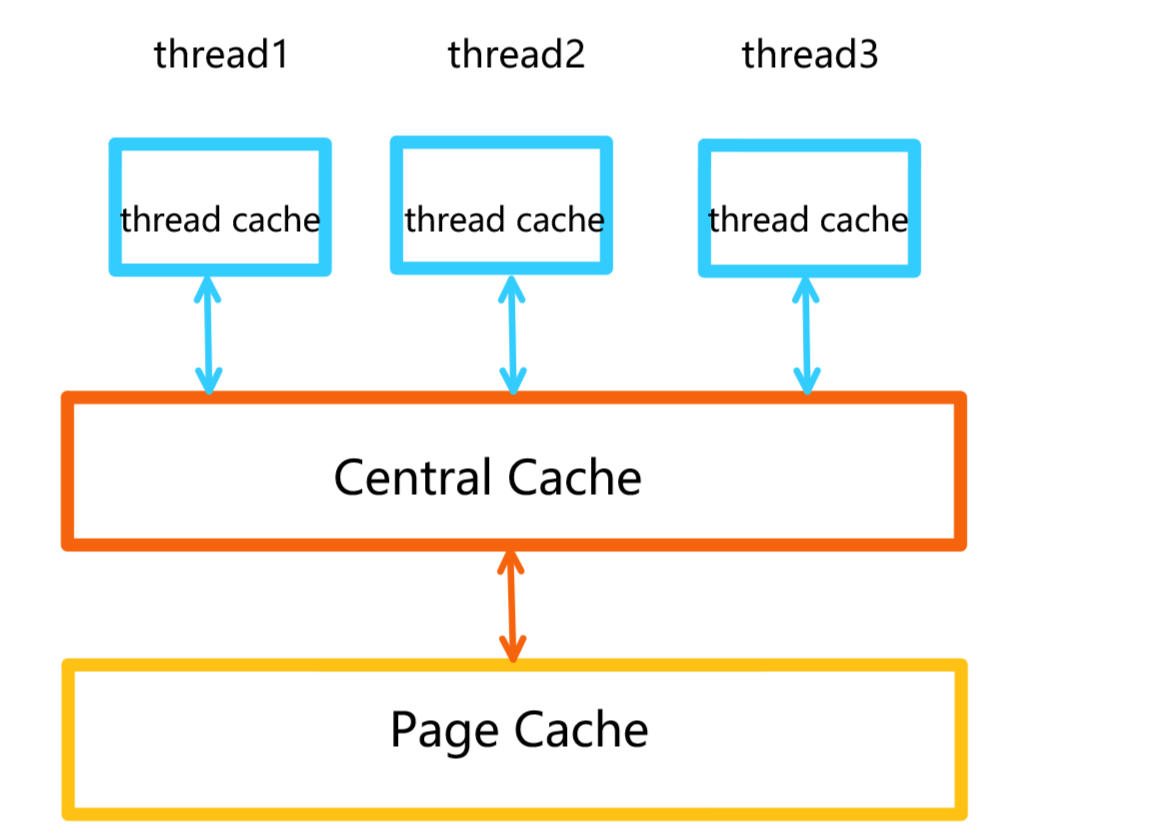
Central Cache做为该项目第二层的结构,它起到均衡调度的作用。
大致结构
Central Cache的结构和thread cache的结构相似,也使用哈希桶的设计结构 。
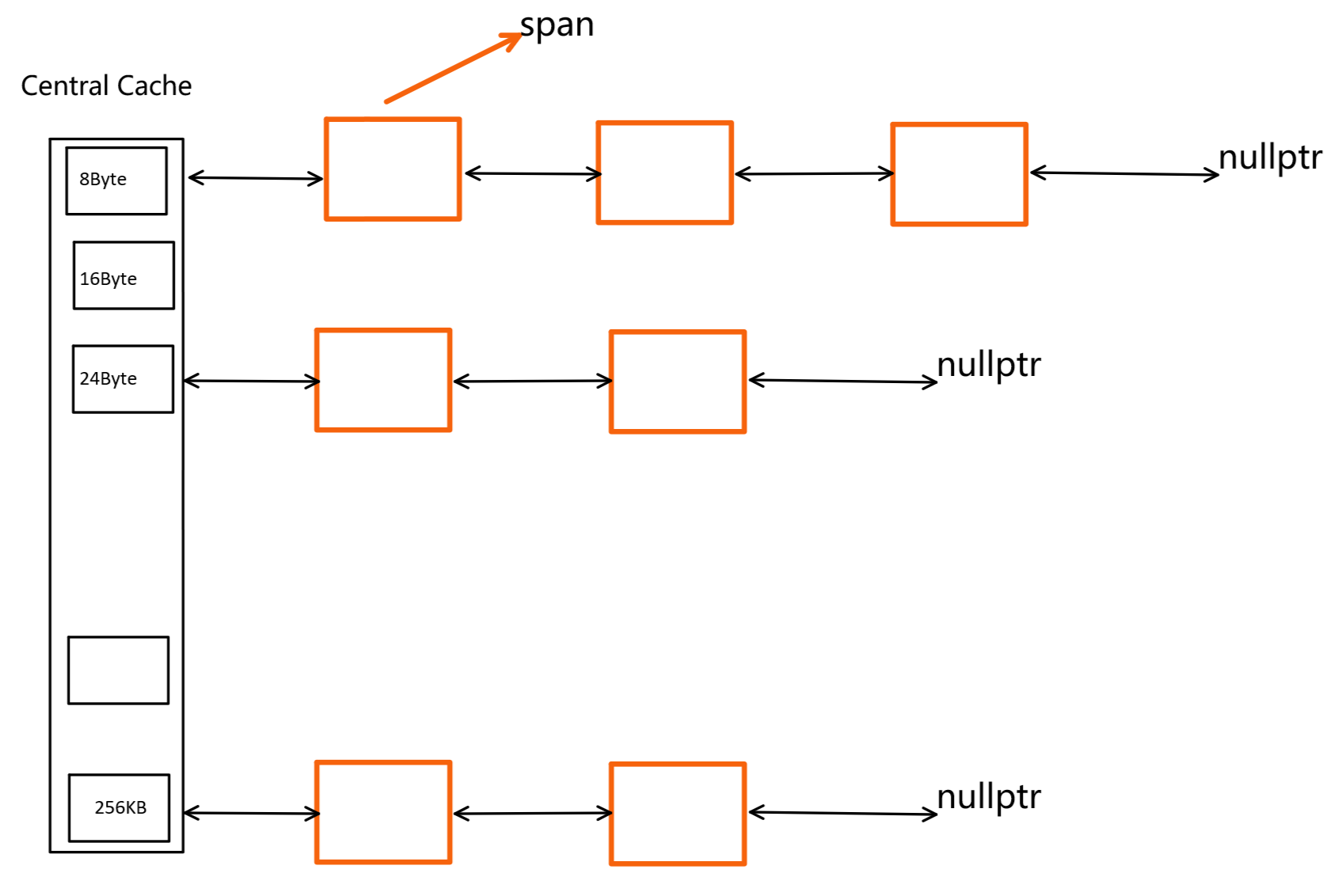
如上图,Central Cache设计的时候,和thread cache的内存对齐规则是一样的。
为什么要这样设计???
- 假设thread cache中下标为n的桶为空时,在向下一层申请的时候,由于Central Cache采用相同的规则,所以此时直接去Cental Cache的下标为n的桶的申请。
- Central Cache为thread cache分配内存空间,如果同时有多个线程来访问,由于Central Cache是属于所有线程,所以每个线程在申请内存空间的时候,就会存在线程安全问题,是需要加锁的。
- 如果两个线程访问的是同一个桶,那么就会存在锁竞争,一个线程申请完了,才能让另一个线程申请。
- 但是如果两个线程访问的是不同的桶,那么就不会存在锁竞争,可以认为是这两个线程是并行申请的,效率就会大大提高。
- 所以,Central Cache是需要加锁访问的,但是不是整体进行加锁的。而每个桶拥有一把锁,访问同一个桶时才会 存在锁的竞争。
span结构
与thread cache结构不同的是:
- thread cahce中,每个桶的后面挂的是一个个的小内存块。比如按照4Byte对齐,对应桶中都是一个一个4Byte的内存块(的地址)。
- 而Central Cache是为每一个thread cache分配空间的,所以他所管理的内存块更大。每个哈希桶中挂的是一个一个的span。所谓span,就是管理以页为单位的大块空间。这里一页的大小按照8KB计算。
- 一个span,可能包含多个页,也可能包含一个页。
span如何管理这大块内存??
自由链表!!!没错,仍然是按照自由链表的方式。将这一大块内存,切分成很多个小块内存,然后使用链表的形式组织起来!!!如下图:
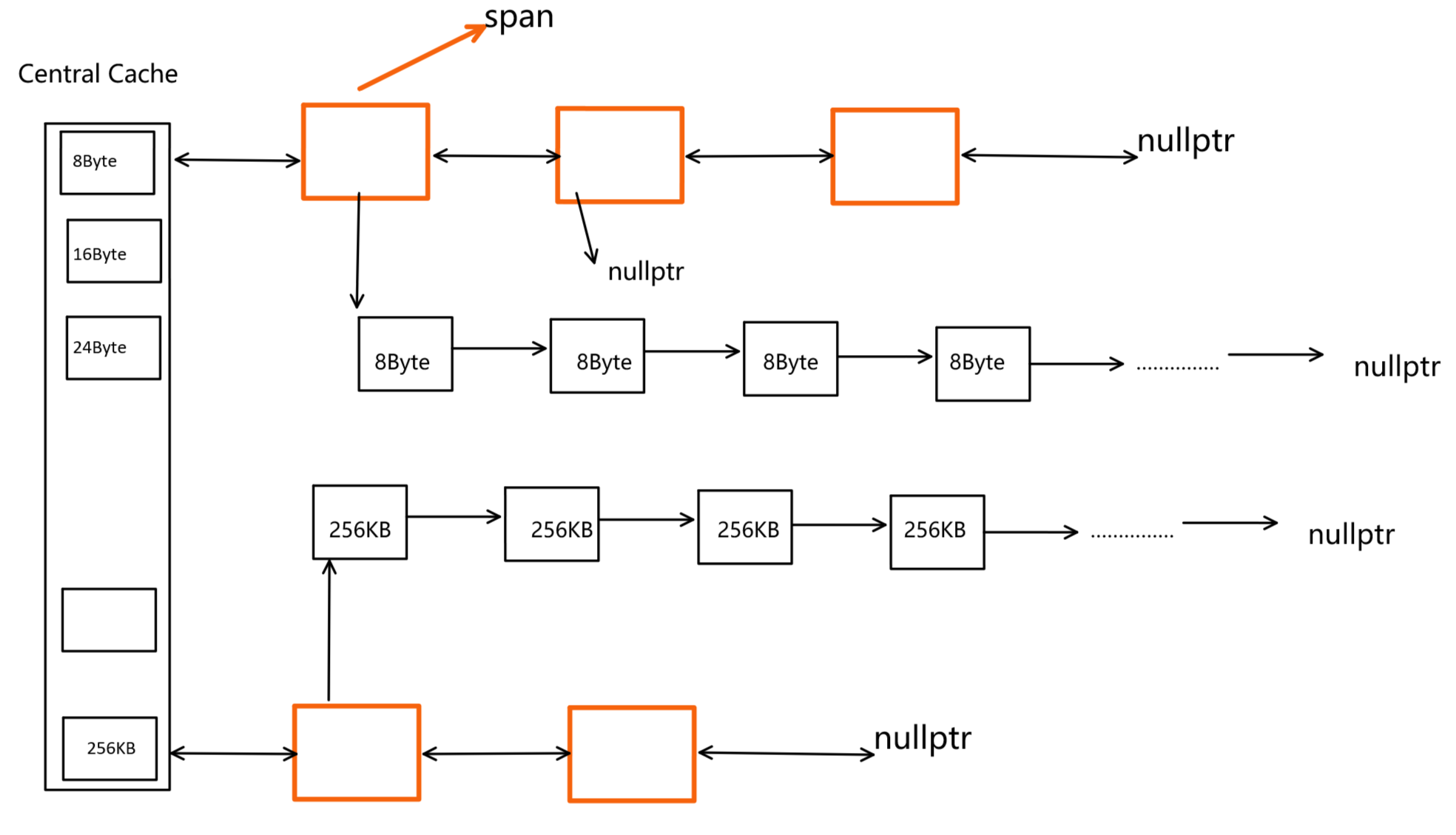
每个span按照对应的对齐规则,将大块内存切分成对应的小块内存,并使用自由链表组织起来。
所以,对于一个span,可能包含多个内存块,也可能分配出去了一部分,剩余一部分,也可能全部都分配出去了,剩余为空 。
那么我们如何可以知道某个span中,分配出去多少内存???
- 所以,在 span结构中,我们需要增加一个变量usecount,来记录有多少内存块分配出去了。记录这个变量的目的是,当span这个结构完全被还回来的时候,我们就可以将它还给下一层了。
- 所以,当上层thread cache申请内存块的时候,就让对应span的usecount++。当上层thread cache归还内存块的时候,就让对应span的usecount--。
- 当usecount=0时,说明这个span的内存块已经全部还回来了。那么此时就可以将该内存块 返回给下一层 了。
- 当将span向一层返回的时候,在Central Cache中,就需要将对应哈希桶中对应的span删除。如果哈希桶中的span按照单链表的形式存储,删除操纵会比较麻烦。所以我们可以设置成双向链表的结构,删除操作的时间复杂度是O(1)
span结构的实现
通过上述部分,了解到Central Cache的大致框架后,接下来,就是各部分的代码实现。
要实现Central Cache的结构,首先就是对span结构的实现。
span——管理以页为单位的大块内存,每个span包含页的个数不同,我们需要记录一个 span有多少页,变相的就记录了这大块内存的大小。同时还需要记录起始页号。
这里一页按照8KB来计算 。
- 如果是在32位环境下,内存大小为2^32,也就是4GB。总页数=4GB/8KB=2^32/2^13=2^19,大约一共有50多万页,使用int 可以存储。
- 如果是在64位环境 下,内存大小为2^64,总页数=2^64/2^13=2^51,这时候使用int就存不下了。
- 为了解决这种问题,可以使用条件编译,如果是32位环境,使用int。如果是64位,使用long long。
- 但是需要注意的是,在WIN32配置下,_WIN32有定义,_WIN64没有定义。在_WIN64配置下,_WIN32和_WIN64的定义都有。
//管理以页为单位的大块空间
struct span
{size_t _pageID;//该大块空间的起始页号size_t _n = 0;//页的数量span* _next = nullptr;//双向链表的结构span* _prev = nullptr;size_t _usecount = 0;//切好的小块内存,分配给thread cache的个数void* _freelist = nullptr;//管理切分好的小对象
};//Central Cache的每个哈希桶中保存的是span组成的链表
class SpanList
{
public:SpanList(){_head = new span;_head->_next = _head;_head->_prev = _head;}//在指定span前插入一个void Insert(span* pos, span* newspan){assert(pos);assert(newspan);span* prev = pos->_prev;//prev newspan posnewspan->_prev = prev;newspan->_next = pos;pos->_prev = newspan;}//从链表中删除指定的某个spanvoid Erase(span* pos){assert(pos);assert(pos != _head);span* prev = pos->_prev;span* next = pos->_next;prev->_next = next;next->_prev = prev;}
private:span* _head=nullptr;//链表的头指针
public:std::mutex _mtx;//桶锁
};
三,Central Cache大致结构的实现
Central Cache也是一个哈希桶结构,和thread cache采用一样的内存对齐规则。每个桶下面挂的是一个一个的span,而每个span内部也有一个 链表,挂的是切分好的小块内存。
单例模式
对于thread cache,它是每个线程独享的,每个线程只能看到自己的thread cache对象。
对于Central Cache,它是所有线程共享的。我们不希望未来有多个Central Cache,保证整个进程中只有一个Central Cache。所以我们可以通过单例模式来实现。
单例模式是一种设计模式,确保一个类只有一个实例,并提供一个全局访问点。
//Central Cache的结构和Thread Cache的结构相似
//Central Cache的哈希桶中挂的是一个个的span
//实现成单例模式
class CentralCache
{
public://获取单例对象static CentralCache* GetInstance(){return &_sInst;}//从 Central Cache获取一定数量的对象给thread cache//start,end为输出型参数,n表示希望获得的内存块个数,byte_size表示对应的内存块的大小size_t FetchRangeObj(void*& start, void*& end, size_t n, size_t byte_size);//禁用构造,拷贝构造,赋值重载CentralCache() = delete;CentralCache(const CentralCache&) = delete;CentralCache operator=(const CentralCache&) = delete;
private:SpanList _spanlists[NFREELISTS];static CentralCache _sInst;
};thread cache向Central Cache申请空间的接口
当某个线程申请内存空间,当对应的桶为空时,需要向Central Cache申请。
比如一个线程来向Central Cache申请8字节的内存,Central Cache一定会分配多个8字节的内存块。
多余的会让thread cache保存,下次再申请时,就直接找thread cache,因为访问thread cache是无所的,申请内存能更快。那么Central Cache应该给返回对少个内存块???
方法:慢开始反馈调节算法
1,按照申请的内存大小来决定返回多少个内存块。
如果申请的内存比较小,比如5字节,我们可以多给几个,比如分配给50字节,返回10个 内u才能块。如果申请的内存空间比较大,比如256KB,就不能返回的太多,返回2个或者3个内存块。
所以,当申请的内存块大小为n时,我们需要知道最多给它分配多少个,也就是它的上限。
2,按照使用内存的是否频繁,决定返回多少个内存块
如果给的太多,可能很多都用不上。如果给的太少,可能会导致该线程频繁的找Central Cache申请内存。
- 线程之所以会找Central Cache申请空间,无疑是thread cache对应桶的内存用完了。
- thread cahce有很多的桶,当频繁的为某个桶申请内存时,说明这个桶用的很频繁,我们就一次多给,比如给2倍或者3倍。
- 但是,如何知道一个桶使用的是否频繁呢???我们可以对每个桶,也就是每个自由链表,在自由链表中增加一个变量maxSize=1,表示是否频繁申请。当这个桶第一次向Central Cache申请内存时,就给一块内存,然后让这个桶的maxSize+1,下次申请的时候 ,就给2块,依次类推......也可以将+1换成+2或者+3,这样增长的速度就会变快。当然,这里不能一直+,会有上限的。
结合这两种情况,计算出的结果,取一个最小值,就是最后应该分配的内存块的个数。
//自由链表中头插一段区间
//start,end
void pushRange(void* start, void* end)
{NextObj(end) = _freelist;_freelist = start;
}
//向Central Cache申请内存
//index表示对应的哈希桶的下标
void* threadCache::FetchMemoryFromCental(size_t index, size_t size)
{//首先计算需要获取多少个内存块//慢开始反馈调节算法size_t batchNum = min(SizeClass::NumMoveSize(size), _freelists[index].MaxSize());//保证batchNum不超过上限if (_freelists[index].MaxSize() == batchNum){_freelists[index].MaxSize()++;}void* start = nullptr;void* end = nullptr;//调用Central Cache接口,返回获取到的内存块的个数//start和end是输出型参数,表示 得到的内存块的起始地址和结束地址//这里actual表示实际得到的内存块的个数// 因为Central Cache的内存块可能不够batchNum个,只是将所有的都返回了size_t actual = CentralCache::GetInstance()->FetchRangeObj(start,end,batchNum,size);assert(actual > 1);//如果只返回了一个内存块,将该内存块直接返回给上层使用if (actual == 1){assert(start == nullptr);return start;}else{//先将start+1到end范围的内存块,保存在对应的哈希桶中//再将start返回给上层使用_freelists[index].pushRange(NextObj(start), end);return start;}
}接下来就是要完成 Central Cache给thread cache分配内存的接口了。也就是FetchRangeObj(start,end,batchNum,size)的接口了。
Central Cache的结构如下图 :每个span管理的是以页为单位的大块内存。一页的大小是8KB。同时每个span内部是切分好的小块内存,以链表的形式管理起来。

我们现在已经计算出:thread cache找Central Cache申请内存时,Central Cache应该分配batchNum个内存块给thread cache。
也就是从对应的哈希桶的某个span中切出batchNum个内存块。但是由于可能之前有多个线程来申请,导致现在有的span为空,有的span有内存块,但是可能不够batchNum个。所以我们实际给的个数可能小于期望获得的个数的。
实现思路:首先找到对应的哈希桶,遍历spanlist链表,找到一个 非空的span。spanlist链表是双向循环带头链表,为了方便遍历,我们可以使用类似于迭代器的实际思路,封装一层。代码如下:
注意:在查找spanlist获取一个非空的span时,可能整个spanlist都为空,此时就需要向下一层Page Cache申请。(这部分代码先不实现,Page Cache实现之后完成该部分)。
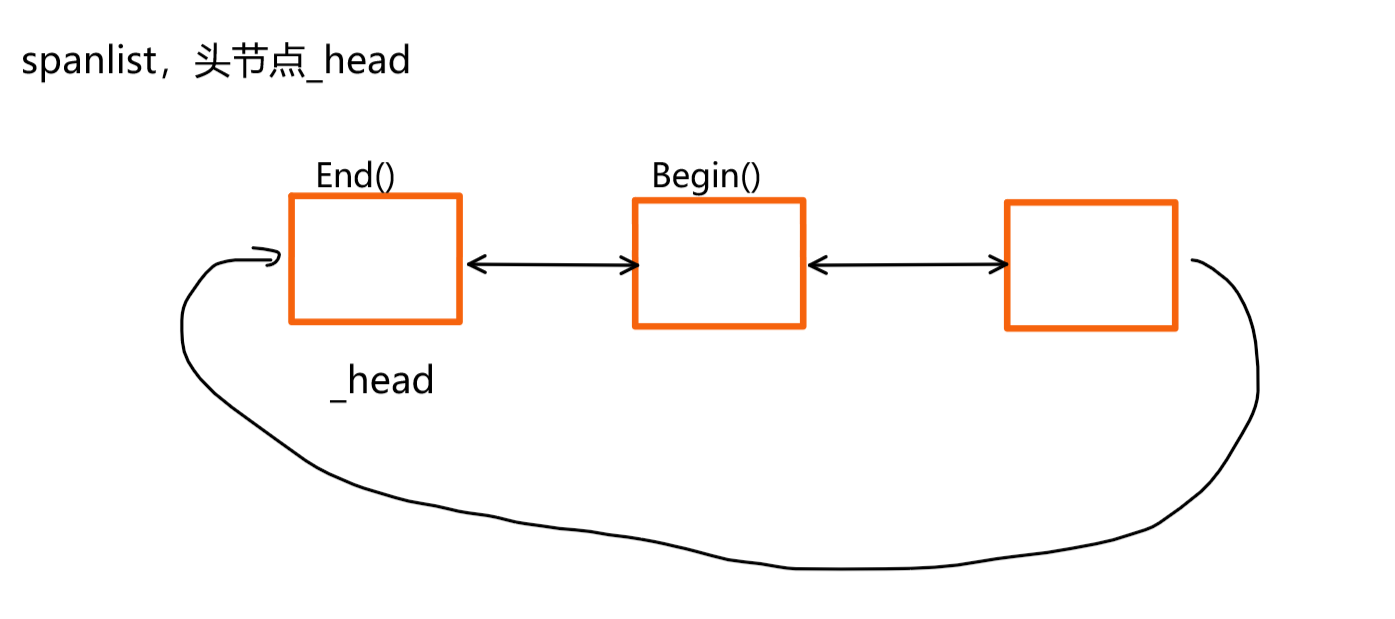
span* Begin(){return _head->_next;}span* End(){return _head;}获取到span之后,就可以遍历span中的_freelist,从中申请batchNum个内存块,如果不够,有多少申请多少。如下图所示:
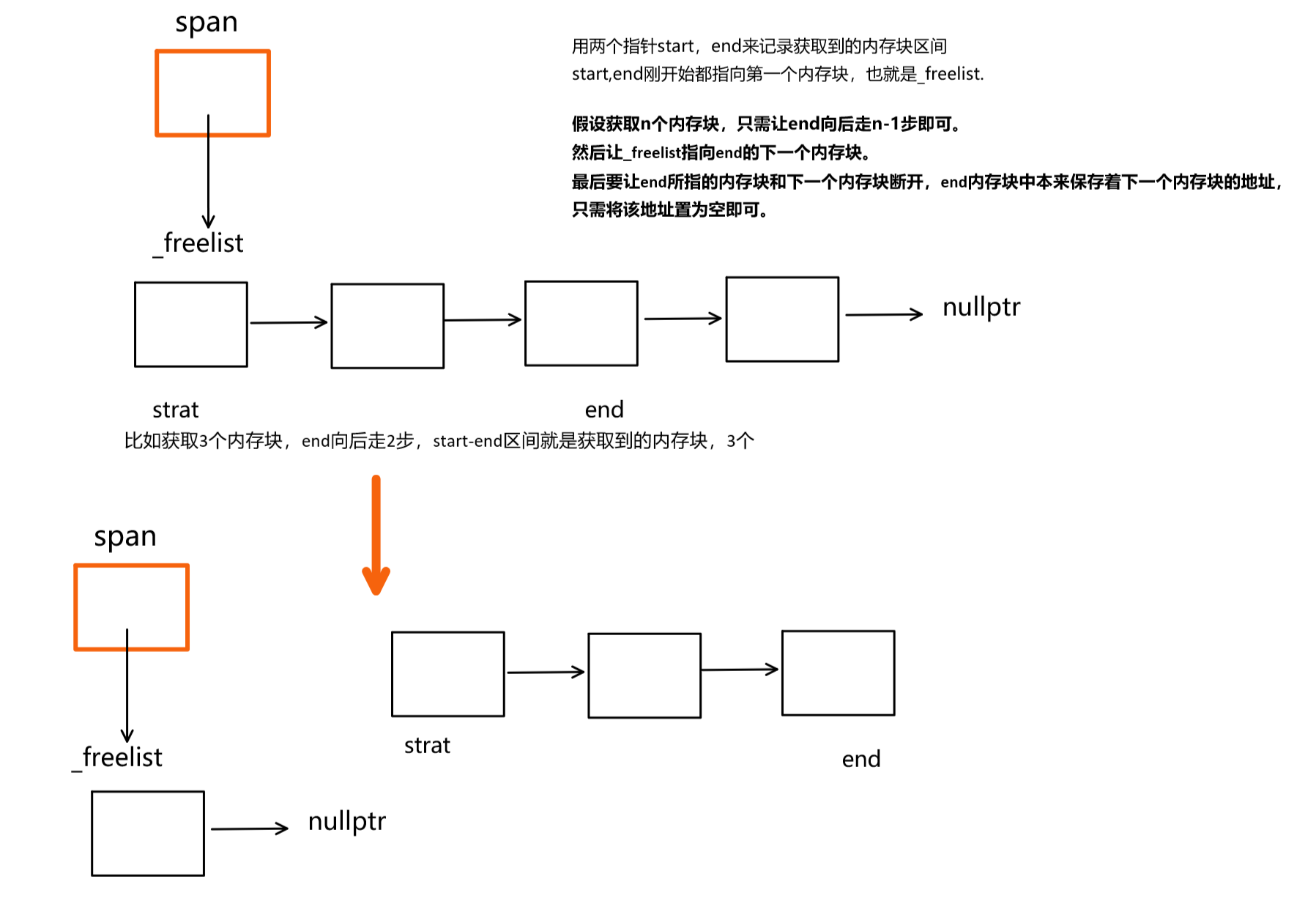
上述情况是span中内存块的个数足够,可能存在不够的情况,所以在end向后移动 的时候,需要判断end不能为空。
//从对应的哈希桶,也就是spanlist中,获取一个非空的span
span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{//...return nullptr;
}//从 Central Cache获取一定数量的对象给thread cache
//start,end为输出型参数,n表示希望获得的内存块个数,size表示对应的内存块的大小
//返回值表示实际获得的内存块的个数
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t n, size_t size)
{//申请的内存块大小为size,先找到对应的哈希桶size_t index = SizeClass::Index(size);//多线程可能会访问同一个桶,需要加锁_spanlists[index]._mtx.lock();//在对应的桶中找到一个非空的spanspan* sp = CentralCache::GetInstance()->GetOneSpan(_spanlists[index], size);assert(sp);assert(sp->_freelist);//从sp中获取n个内存块//start指向第一个内存块,end指向最后一个内存块start = sp->_freelist;end = start;//end向后走n-1步,执行最后一个内存块,但是可能不够n个,需要判空size_t i = 0;size_t actualNum = 1;//记录实际获取到的内存块的个数while (end!=nullptr&&i < n - 1){end = NextObj(end);i++;}//_freelist指向end的下一个内存块sp->_freelist = NextObj(end);//将end与下一个内存块断开连接NextObj(end) = nullptr;_spanlists[index]._mtx.unlock();//返回实际获得的内存块的个数return actualNum;
}源码:
ConcurrentMemoryPool · 小鬼/高并发内存池 - 码云 - 开源中国
本节完!!!