超详细Kokoro-82M本地部署教程
经测试,Kokoro-82M的语音合成速度相比于其他tts非常的快,本文给出Windows版详细本地部署教程。
这里提供原始仓库进行参考:https://github.com/hexgrad/kokoro
一、依赖安装
1.新建conda环境
conda create --n kokoro python=3.12
conda activate kokoro2.安装GPU版本torch
由于要用到CUDA的模型能力生成语音,记得安装GPU版本的torch
记得按照自己电脑CUDA版本进行安装or向下兼容
安装网址:https://pytorch.org/
示例(CUDA12.4):
conda install pytorch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 pytorch-cuda=12.4 -c pytorch -c nvidia3.手动安装espeak-ng依赖
前往espeak-ng的官方GitHub仓库地址:https://github.com/espeak-ng/espeak-ng
①点击Releases
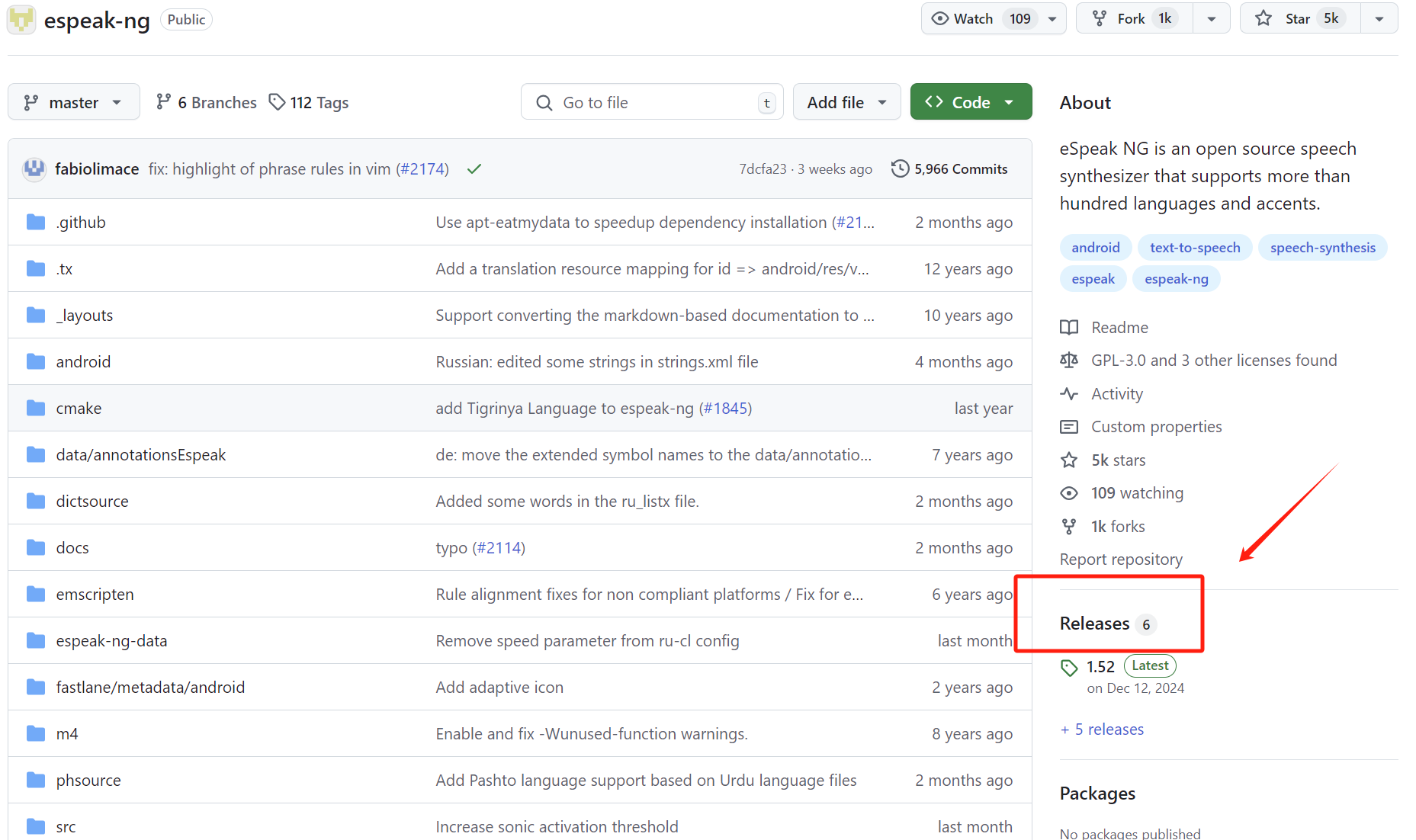
②下翻找到1.51
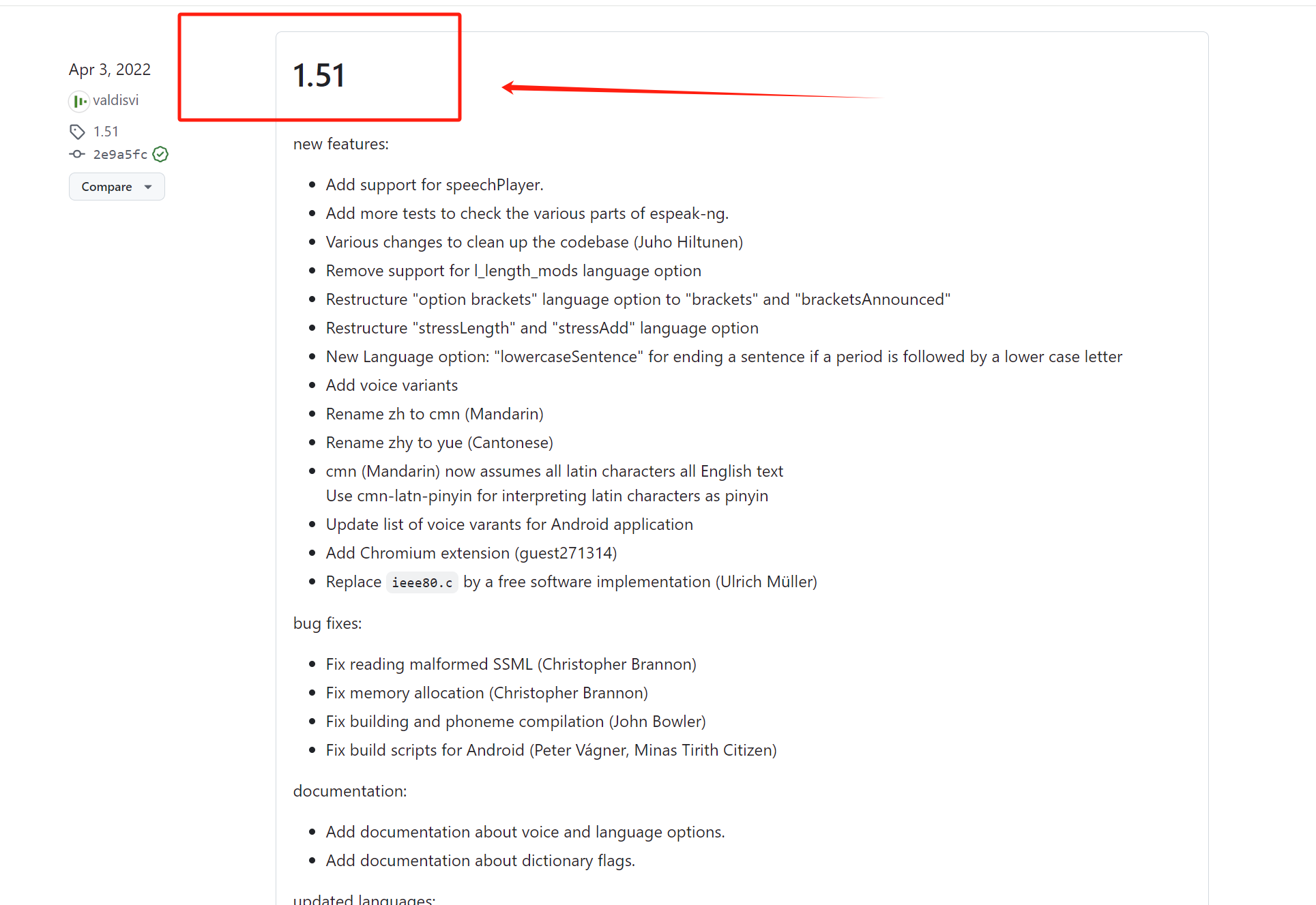
③找到Assets
根据自己的电脑版本选择.msi文件,我的是X64的系统所以下载了espesk-ng-X64.msi
下载后直接双击运行即可,一直点同意就行,这个安装很简单且快
4.其他依赖安装
pip install kokoro
pip install ordered-set
pip install cn2an
pip install pypinyin_dict
二、模型下载
我下载了kokoro-v1.0和kokoro-v1.1,但是最后好像只用到了v1.1,可以根据需要进行选择
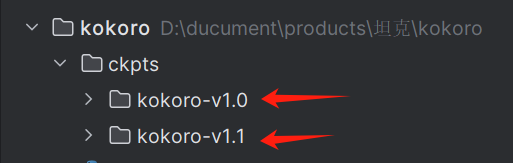
export HF_ENDPOINT=https://hf-mirror.com # 引入镜像地址huggingface-cli download --resume-download hexgrad/Kokoro-82M --local-dir ./ckpts/kokoro-v1.0huggingface-cli download --resume-download hexgrad/Kokoro-82M-v1.1-zh --local-dir ./ckpts/kokoro-v1.1三、代码测试
官方仓库没有给单独测试的python代码,这里给出:
(可以修改sentence部分为自己想转语音的文字)
import torch
import time
from kokoro import KPipeline, KModel
import soundfile as sfvoice_zf = "zf_001"
voice_zf_tensor = torch.load(f'ckpts/kokoro-v1.1/voices/{voice_zf}.pt', weights_only=True)
voice_af = 'af_maple'
voice_af_tensor = torch.load(f'ckpts/kokoro-v1.1/voices/{voice_af}.pt', weights_only=True)repo_id = 'hexgrad/Kokoro-82M-v1.1-zh'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model_path = 'ckpts/kokoro-v1.1/kokoro-v1_1-zh.pth'
config_path = 'ckpts/kokoro-v1.1/config.json'
model = KModel(model=model_path, config=config_path, repo_id=repo_id).to(device).eval()def speed_callable(len_ps):speed = 0.8if len_ps <= 83:speed = 1elif len_ps < 183:speed = 1 - (len_ps - 83) / 500return speed * 1.1zh_pipeline = KPipeline(lang_code='z', repo_id=repo_id, model=model)
sentence = '你好,这是一个语音合成测试。'
start_time = time.time()
generator = zh_pipeline(sentence, voice=voice_zf_tensor, speed=speed_callable)
result = next(generator)
wav = result.audio
speech_len = len(wav) / 24000
print('yield speech len {}, rtf {}'.format(speech_len, (time.time() - start_time) / speech_len))
sf.write('output.wav', wav, 24000)生成的语音文件会保存到output.wav中,会出现一些红色的警告,如果不是error就不用管,会正常运行的。
运行结果如下:
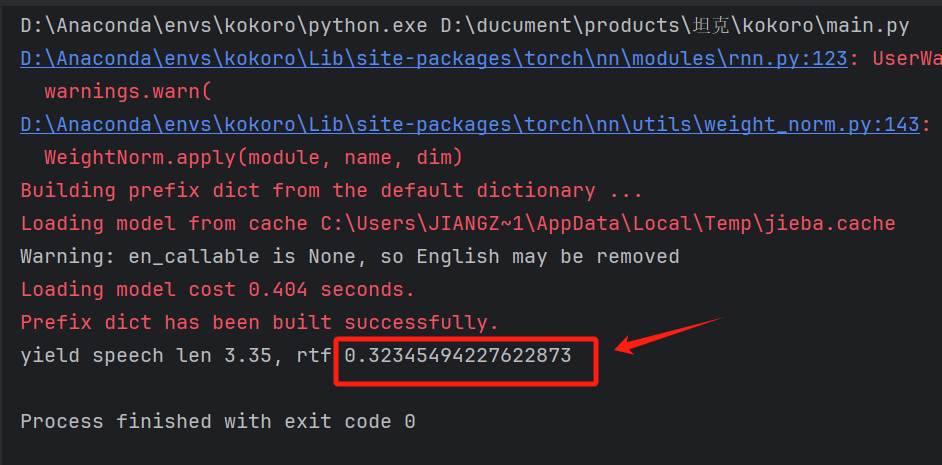
测试结果:
“你好,这是一个语音合成测试。”生成时间0.32秒左右
相比于fish-speech和之前用的edgetts的3~4秒生成时间快了非常多,最终项目选择使用kokoro完成语音合成部分。