Dify+Ollama+Deepseek+BGE-M3来搭建本地知识库实操
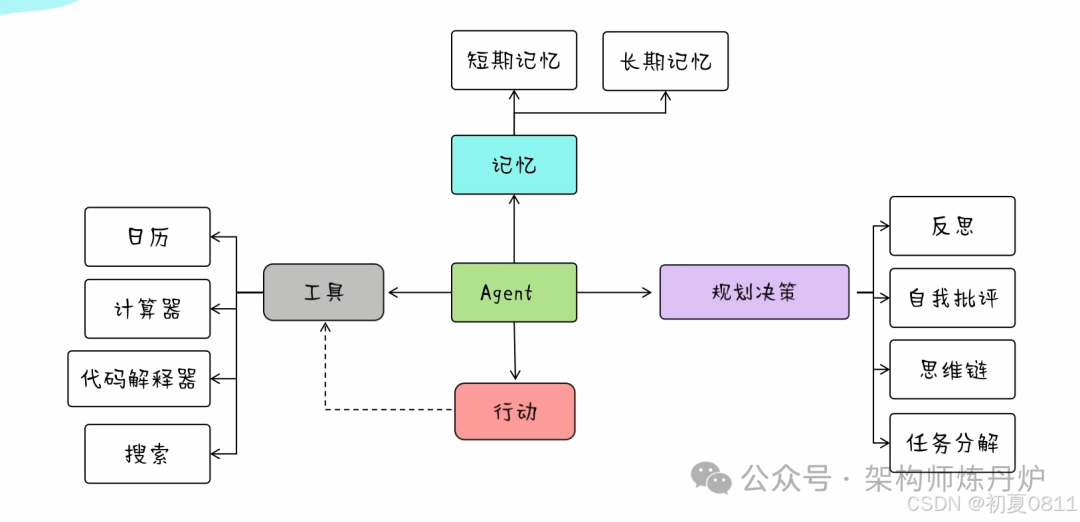
智能体(Al Agent)是大模型与业务应用的桥梁,智能体=大模型+知识库+业务系统API+工作流编排
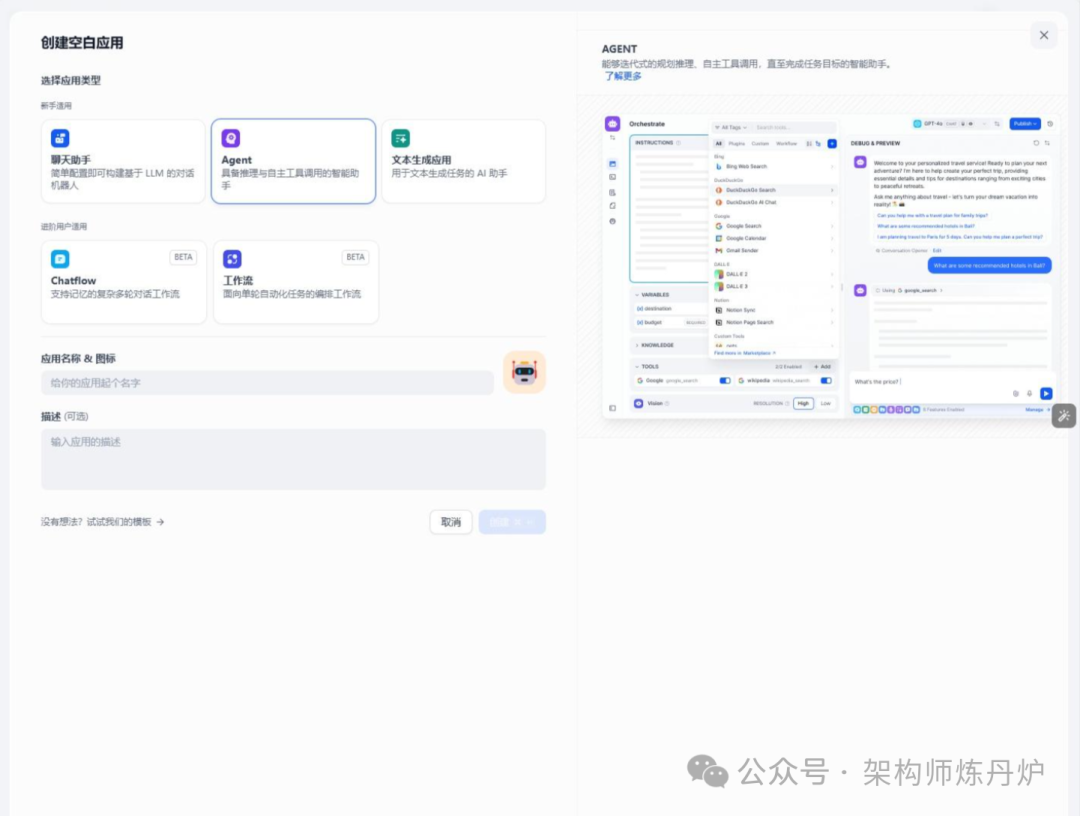
第一步 创建智能体应用
点击 左侧“创建空白应用",在如下界面中点击”Agent“。 给名称和图标,创建完成。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
第二步 配置智能体的模型
点击上一步中创建好的智能体,点击去 “去设置”, 就可以输入申请的API Key或者本地大模型。API key是指去deepseek等官网申请账号并获取一个key,但是这个会收费而且知识库内容会暴露在网上,不安全。
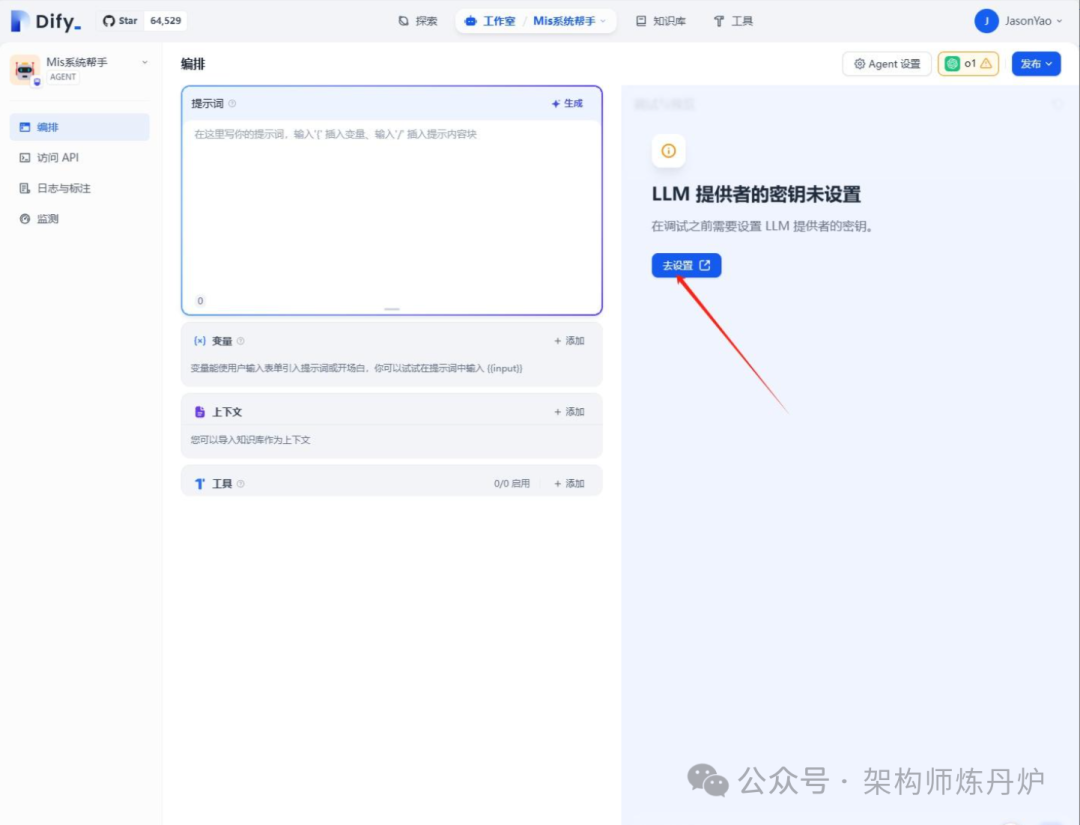
本文采用的是本地大模型,所以选择Ollama。
2.1 配置LLM
创建智能体的时候,可以通过"去设置"来添加模型,如下图,点击模型供应商然后点击Ollama下面添加模型按钮。
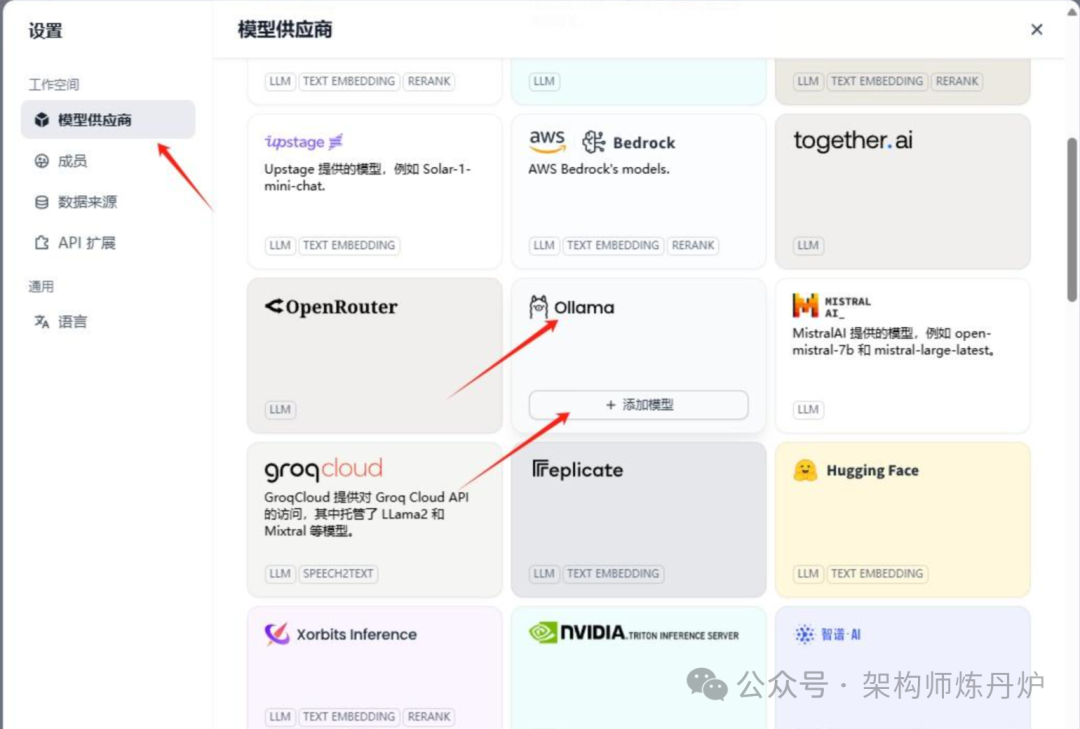
当然也可以点击右上角的账户名,然后在菜单里面点击设置,就可以打开上图的设置页面来添加或者维护模型。
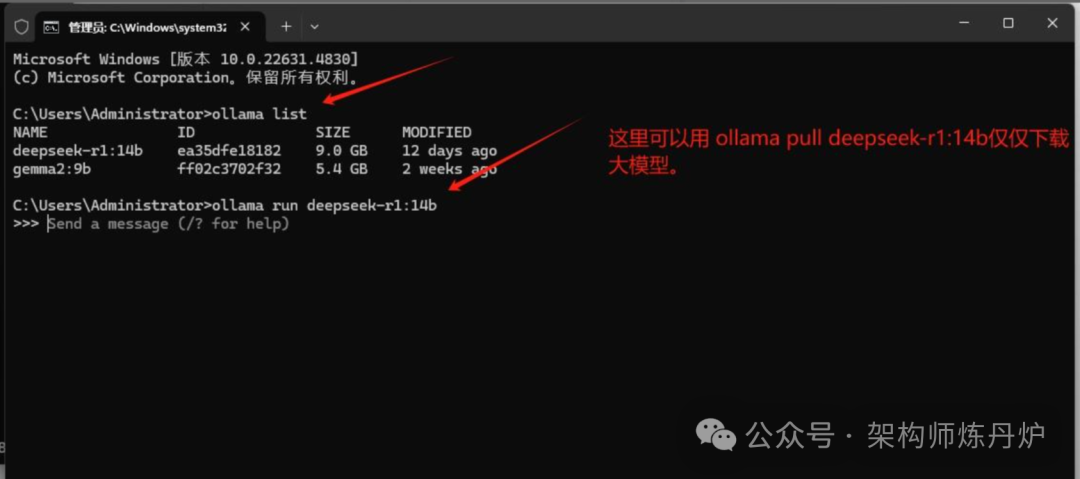
事先我已经安装了Ollama并下载了几个大模型,如果大家没有事先准备好。那先下载安装Ollama,并在命令行工具里面下载运行大模型即可,简单的命令如下:
如果有必要,我可以再写一篇关于Ollama相关的文章,这里不再描述。然后在弹出页面中输入具体内容,如下红色箭头部分不能直接输入 http://localhost:11434
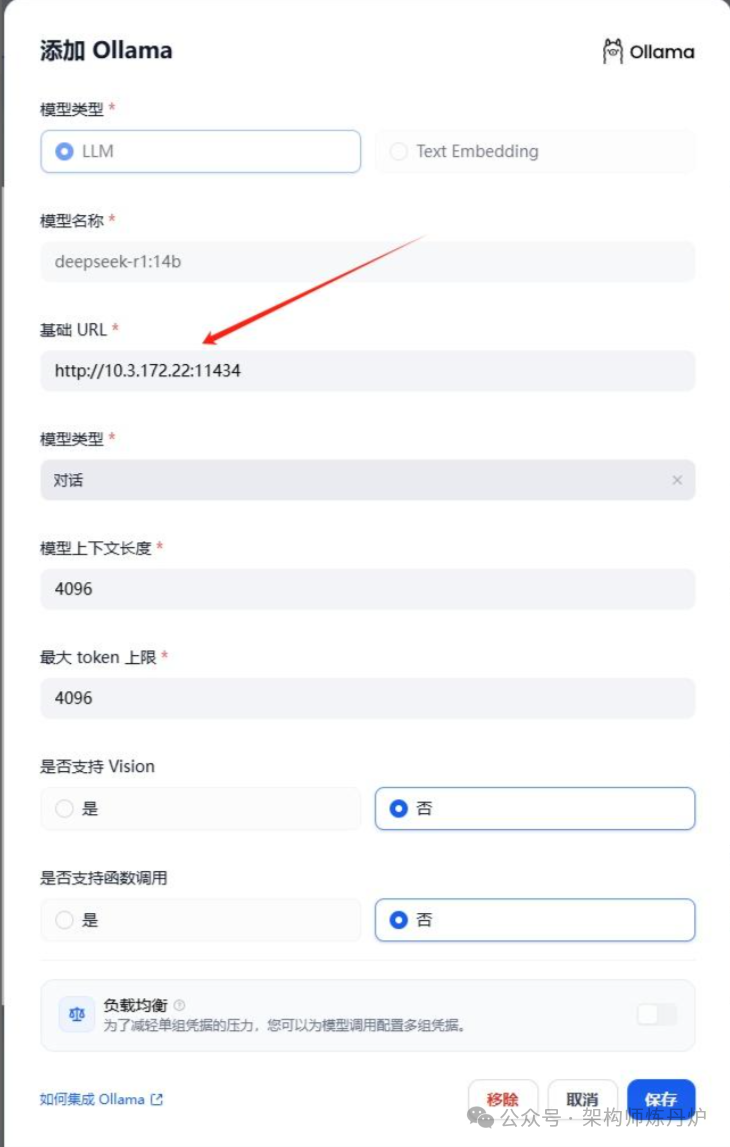
输入localhost,点击保存总是报错"An error occurred during credentials validation: HTTPConnectionPool(host=‘localhost’, port=11434): Max retries exceeded with url: /api/chat (Caused by NewConnectionError(‘<urllib3.connection.HTTPConnection object at 0x7f4a84ce0590>: Failed to establish a new connection: [Errno 111] Connection refused’))"。
问题主要出在docker类似于虚拟机,如果直接写 http://localhost:11434,其实访问的是docker本身的服务,肯定就找不到了。其实当前请求相当于docker要访问主机机器的地址,那就需要把主机的ollama地址暴露出来,步骤如下:
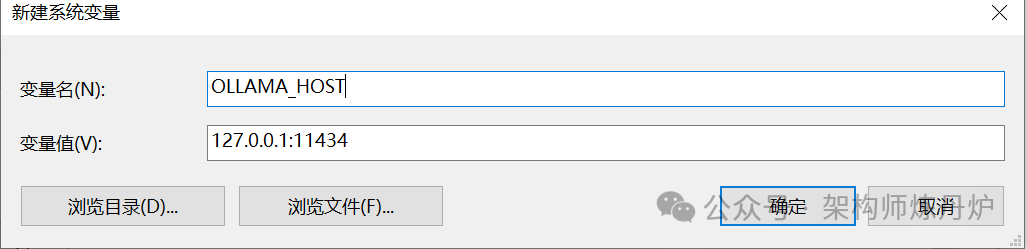
系统变量里面加 OLLAMA_HOST,然后输入局域网地址或者直接输入"0.0.0.0"; 如果是对外的网络地址也行。然后在path里面增加%OLLAMA_HOST%,重启Ollama即可。
2.2 配置知识库Embedding模型
逻辑推理用deepseek大模型, 知识库Embedding不用deepseek,说命中率不高,回答问题效果不好,所以选用BGE-M3。按如下红色箭头命令操作,然后查看一下,模型已经下载完成。
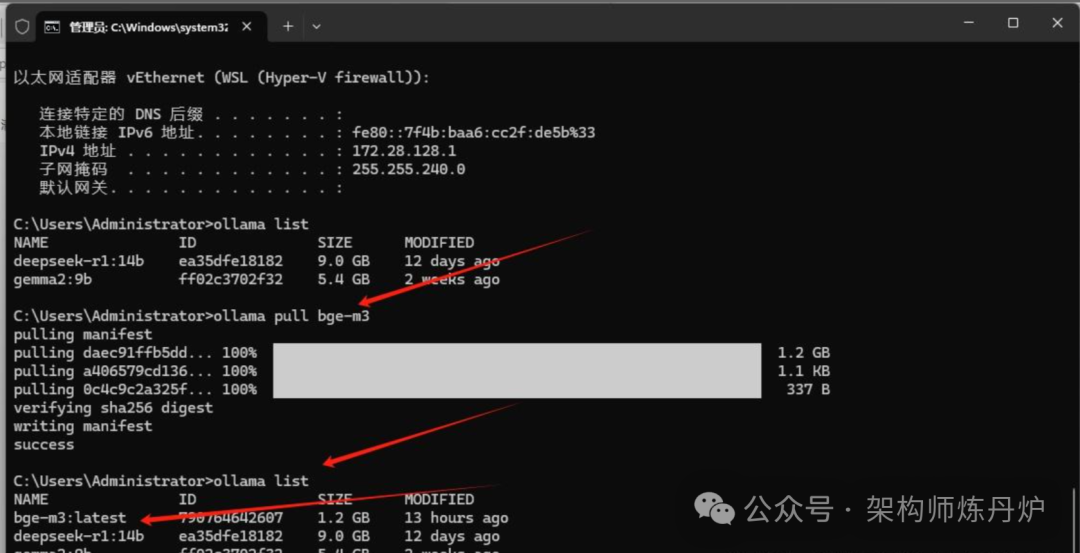
BGE (BAAI General Embedding) 专注于检索增强LLM领域,对中文场景支持效果更好,当然也有很多其他embedding模型可供选择,可以根据自己的场景,在ollama上搜索“embedding”查询适合自己的嵌入模型。
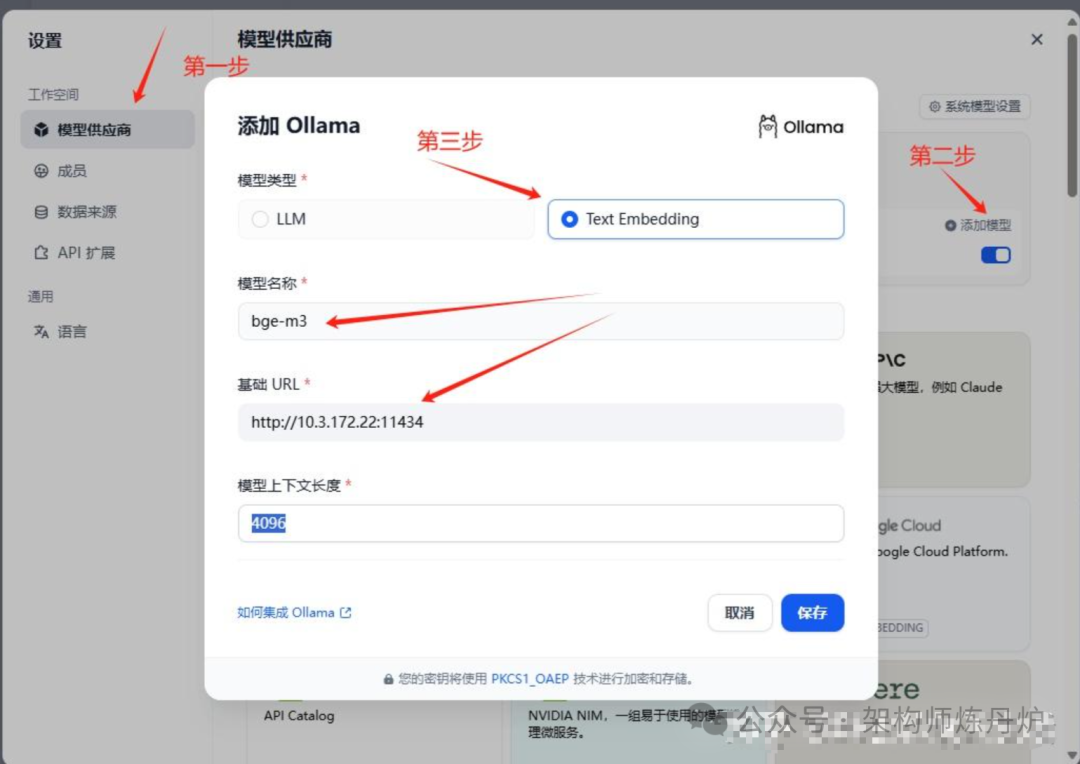
配置如上图,如果说连不上报错,要确认Ollama是否启动,就直接在浏览器里面输入URL看看是否有“Ollama is running”字样。点击保存按钮,就可以看到如下所示LLM用了deepseek-r1:14b而TEXT EMBEDDING用的是bge-m3。
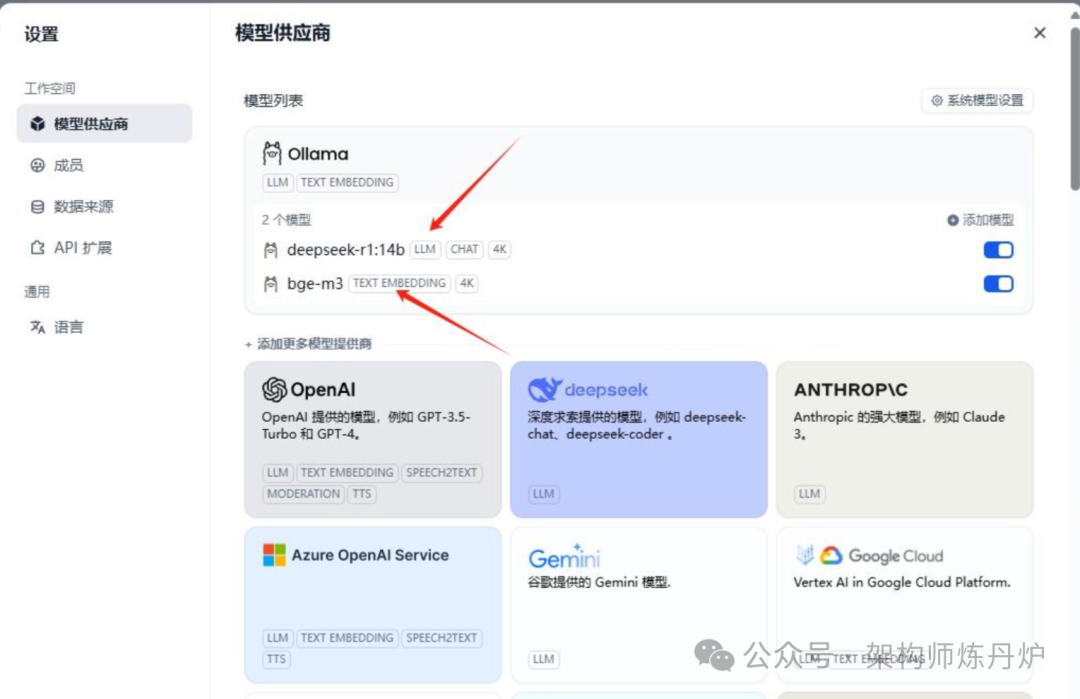
至此,两个模型配置完成。
第三步 知识库操作
3.1 创建知识库
如下图操作
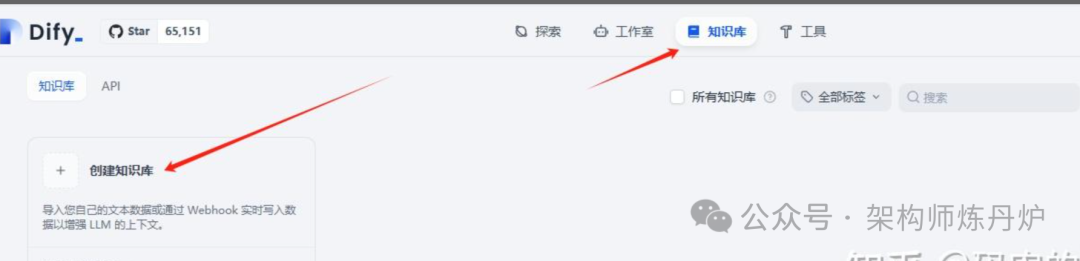
3.2 上传RAG资料
可以看到有三步,即选择数据源,文本分段与清洗,处理并完成。资料可以是本地的文本文件,或者直接同步网络资料等等。
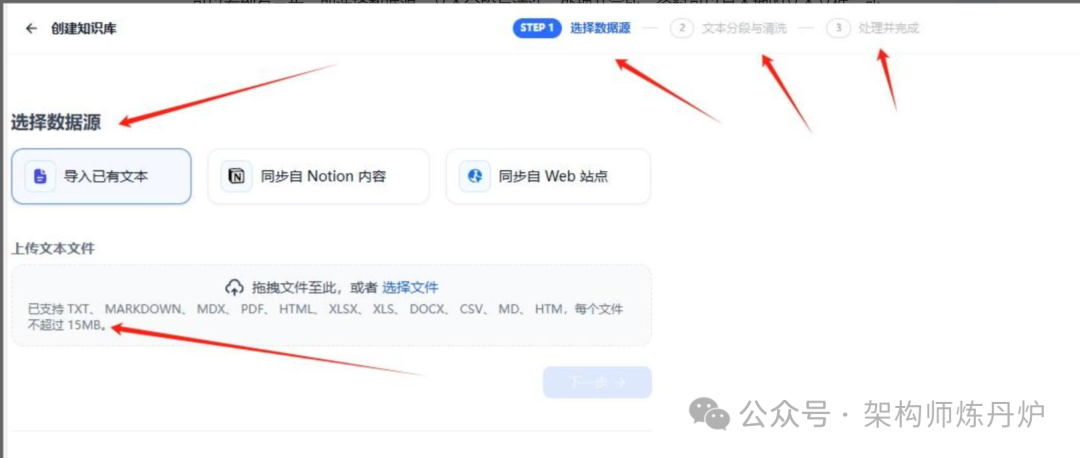
支持的文本文件类型也很多,不过要注意单个文件不能超过15M。如果文件大了怎么办,拆呗。
3.3 保存资料并处理
我上传了一个自己写的用户手册,pdf格式,12.86M,可以处理。点击下一步,如下图。
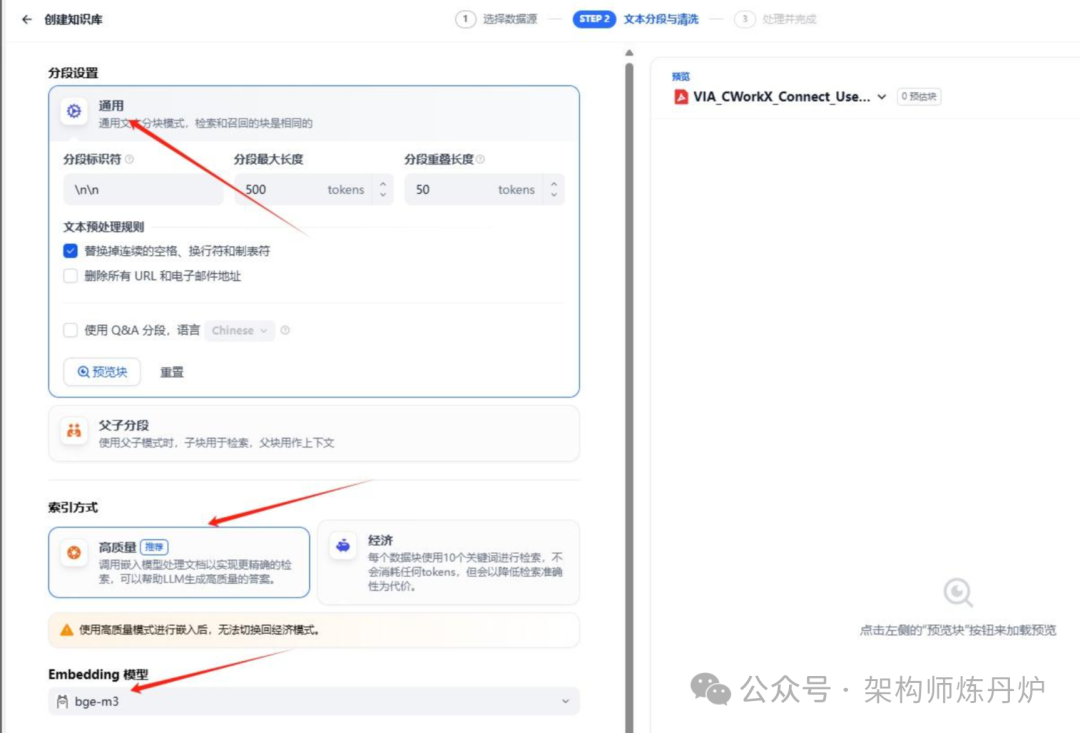
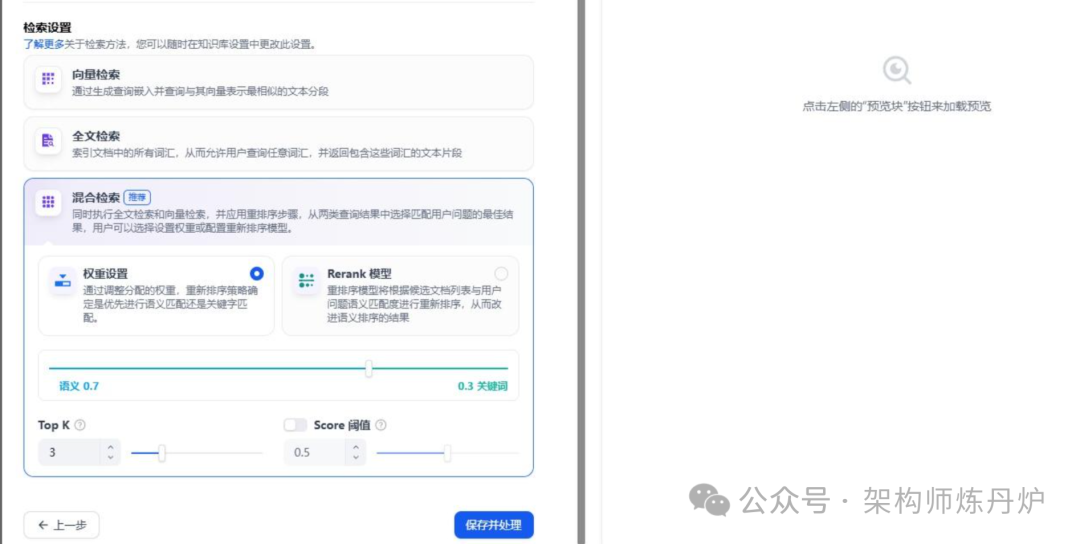
分段设置直接用了通用的,索引方式用高质量,Embedding模型用bge-m3,检索设置用混合检索。点击保存并处理,等待处理完成。
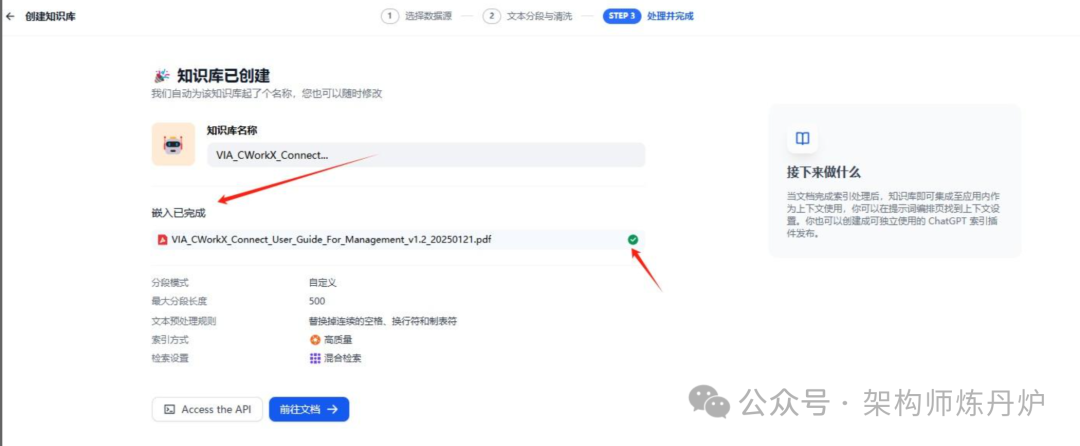
完成前往文档,知识库里面就有一个文档知识库内容了。
第四步 测试结果
点击工作室,并打开已经创建完成的智能体(Agent)
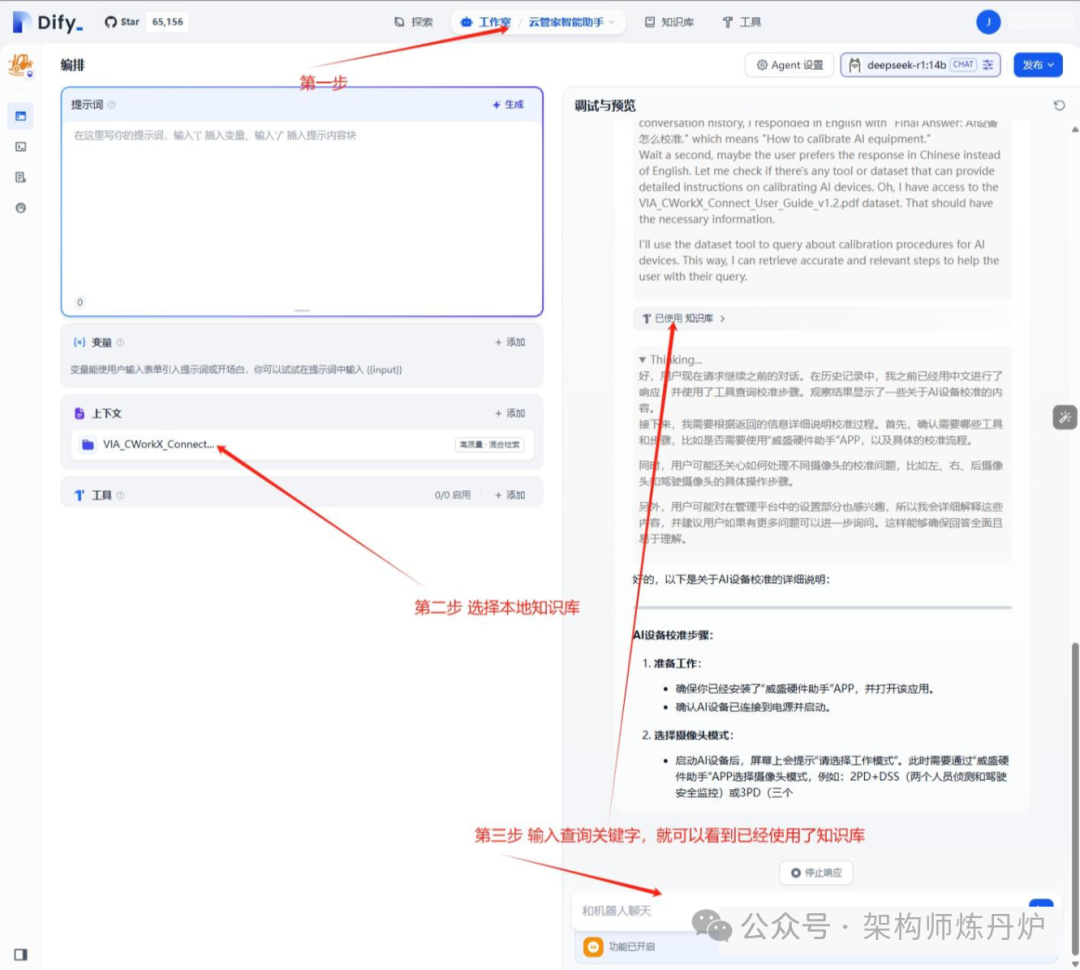
不错,AI能够自己检索并拼出结果给用户。接下来要研究怎么改进RAG,并嵌入到自己写的系统中。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!