解密数据结构之位图和布隆过滤器
位图和布隆过滤器
- 前言:笔者在前面分享过哈希的知识,但是笔者在哈希那篇博客中并没有给出哈希的应用场景,今天笔者分享的知识是关于哈希的应用,也就是大名鼎鼎的位图和布隆过滤器。
- 1.位图的定义
- 位图解决
- 2.位图实现
- 1.先使用命名空间封装,防止和库里面的冲突
- 2.**我们需要先搞懂在位图中,需要有什么,我们是不是得有一个数组存放元素,还有一个统计总共存放了多少位的元素**
- 3.书写构造函数,在构造函数中,我们需要考虑开辟多大的内存合适
- 4.标记该位是否存在数据,如果该比特位存在数据,那么就置1,否则就置0.
- 5.将这个数从位图中删去
- 6.查找这个元素是否在位图中
- 3.位图优缺点
- 4.布隆过滤器定义
- 布隆过滤器是可以告诉你某样东西一定不存在或者可能存在,支持高效的插入和查询的数据结构。
- 5.布隆过滤器实现
- (1)由于布隆过滤器底层还是位图结构,那么我们还需要使用我们刚刚写的位图结构,那么我们就明白了,布隆过滤器里面需要有位图对象和表示布隆过滤器总的位置个数的变量
- (2)构造函数
- (3)实现仿函数
- (3)添加元素到布隆过滤器中
- (4)判断该元素是否在布隆过滤器中
- (5)布隆过滤器删除元素:布隆过滤器不支持删除操作,因为多个元素会映射到同一个位置,如果把位图中某一个位置由0置成1,那么会导致其他元素也会发生变化。
- (6)测试:老规矩,写完代码一定要测试!!!
- 海量数据处理
- 位图题目
- 题目1:给定100亿个整数,设计算法找到只出现一次的整数?
- 题目2:给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件的交集???
- 方案一:将文件一映射到位图1中,将文件二映射到位图二中,然后再将两个位图进行&操作,如果&的结果是1,那么就是交集!!!
- 方案二:我只存一个文件的数据,只需要500M,那绰绰有余,然后,我们再读取另一个文件,通过判断读取的文件在不在位图中,在就是交集!!!
- 题目三:1个文件有10亿个整形数据,我们有1G内存,设计算法找到出现次数不超过2次的所有整数.
- 布隆过滤器题目
- 题目一:给两个文件,分别有100亿个query(query一般是sql语句查询或者网络请求的url等,一般是一个字符串),我们只有1G内存,假设平均一个query占30-60byte,那么我们如何找到两个文件的交集???
- 方案一:我们分析一下100亿个查询,大概占300-600G左右,那么我们可以将query映射到布隆过滤器中,读取文件2的query,判断在不在布隆过滤器中,在就是交集!!!(**这里不能使用位图,位图只能处理整形**)
- 哈希切割
- 题目一:给一个超过100G大小的log file(日志文件)c存着IP地址,现在需要你设计算法找到出现次数最多的IP地址?
- 扩展
前言:笔者在前面分享过哈希的知识,但是笔者在哈希那篇博客中并没有给出哈希的应用场景,今天笔者分享的知识是关于哈希的应用,也就是大名鼎鼎的位图和布隆过滤器。
1.位图的定义
对于位图的定义,笔者先不讲,笔者先给各位老铁分享一个腾讯的面试题,看看各位老铁会不会这道面试题!

先审题,题目要求我们快速从40亿个数中判断一个数是否存在,很多老铁一下子就会想到哈希来做,本来哈希就是支持快速查找数据的。
但是各位老铁犯了一个致命的错误,没有看人家数据个数,40亿个数,每一个数都要使用4个字节映射key值,那么总的需要的内存就是16G左右了,那么你电脑内存还能放的下吗,就算放的下,一个程序就吃你电脑那么多内存了,你其他的程序不要跑了吗?
基于以上的问题,引出了我们今天的嘉宾,位图,先给各位老铁来一段位图的字面定义:位图就是每一位存放某种状态.
位图解决
对于位图通俗点讲,就是在每一个比特位中是不是可以存储两种状态,1表示存在,0表示不存在,那么我们就可以使用位图来解决上面的面试题了,我们可以算算内存的花费,直接用40亿➗8,再换算单位,那么我们得到需要的内存就是500M,一下子内存减少了多少,所以从这个例子中,我们就可以感受到位图对于在海量数据判断某个数是否存在,优势是多么大了。
2.位图实现
在上面,我们已经懂得了位图的定义和优势,那么我们该如何来实现位图呢?
1.先使用命名空间封装,防止和库里面的冲突
#include <iostream>
using namespace std;namespace ljy
{}
2.我们需要先搞懂在位图中,需要有什么,我们是不是得有一个数组存放元素,还有一个统计总共存放了多少位的元素
#include <iostream>
#include <vector>
using namespace std;namespace ljy
{class bitset{private:vector<int> _bits;size_t _num;};}
3.书写构造函数,在构造函数中,我们需要考虑开辟多大的内存合适
#include <iostream>
#include <vector>
using namespace std;namespace ljy
{class bitset{public://N表示总的元素个数bitset(size_t N){//为什么需要除以32位呢?//答:整形占四个字节,32个比特位_bits.resize(N / 32, 0);_num = 0;}private:vector<int> _bits;size_t _num;};}
各位老铁看看这个写法有没有什么问题?
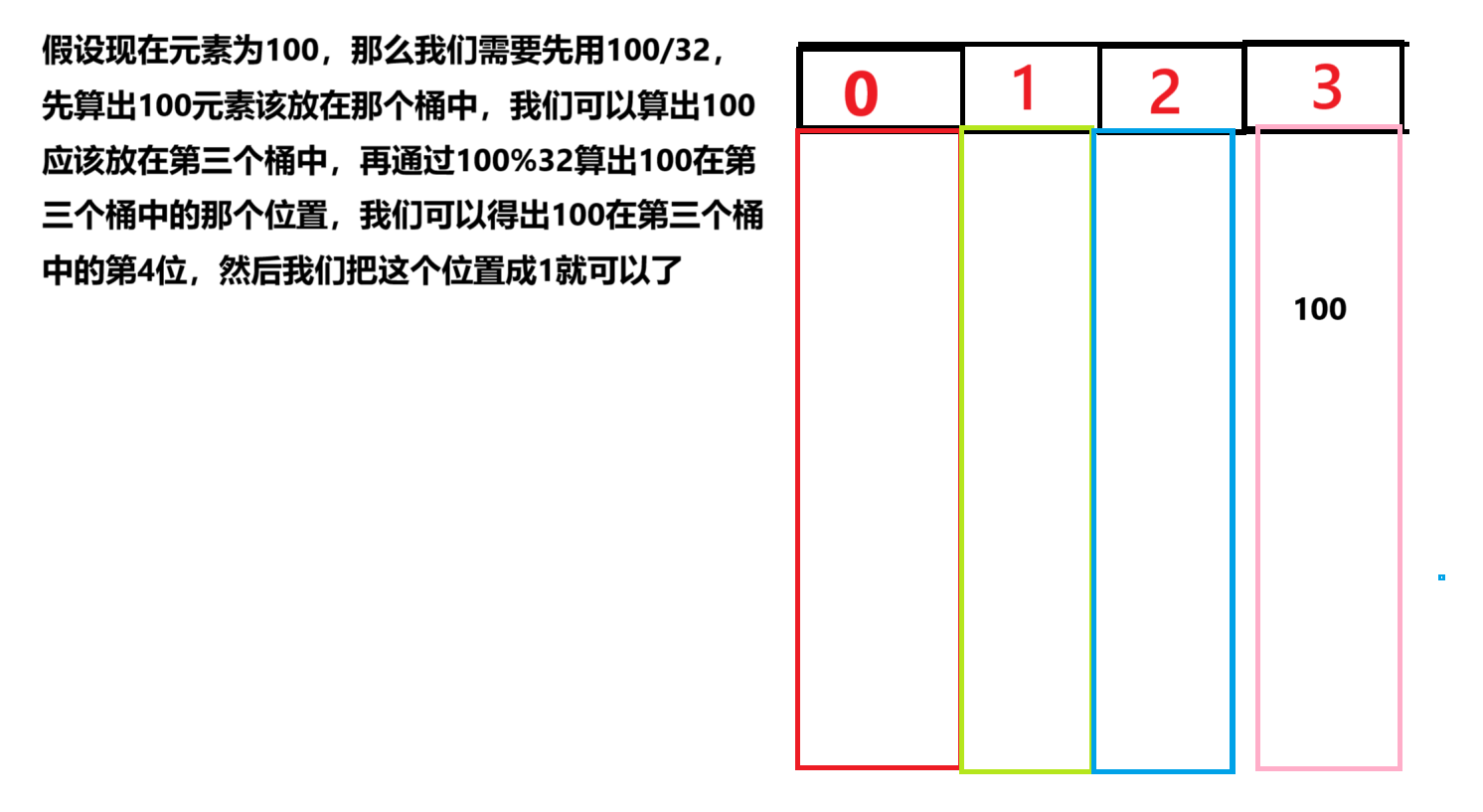
假设N/32不是整除,还有余数呢?那不是炸了吗,我的数据还有N%32位难道不要了吗,所以我们需要多开32位。
#include <iostream>
#include <vector>
using namespace std;namespace ljy
{class bitset{public://N表示总的元素个数bitset(size_t N){//为什么需要除以32位呢?//答:整形占四个字节,32个比特位_bits.resize(N / 32+1, 0);//这里开辟是按整形进行开辟的_num = 0;}private:vector<int> _bits;size_t _num;};}
4.标记该位是否存在数据,如果该比特位存在数据,那么就置1,否则就置0.

void set(size_t x)
{//先算出在那个桶size_t idx = x / 32;//每个桶占32个位size_t pos = x % 32;//再算出在桶中的那个位置//在对应位由0置1_bits[idx] |= (1 << pos);//位运算优先级低于或运算++_num;//位图中元素个数++
}
5.将这个数从位图中删去
取消该位的标记,如果该位是1,需要变成0,其余位是0就标记0,1还是标记1
将一个数从位图中删去,和插入差不多,我们需要先找到这个数在几号数组中,然后再到对应的数组中,找到对应的下标,最后将1先左移pos位,再取反,最后再进行与操作,那么原来在位图中的是1的,还是1,0的还是0,只有目标位置会从1变成0.,最后再减减位图中元素的总的个数
void reset(size_t x){size_t idx = x / 32;//先求出在几号桶中size_t pos = x % 32;//在桶中的下标//再进行由1变0操作_bits[idx] &= ~(1 << pos);--_num;}
6.查找这个元素是否在位图中
判断一个元素是否在位图中,也是得先找到这个元素在位图中得位置,那么也得先找到这个元素在几号桶中,然后再找到在桶中的下标,最后在将1左移pos位,然后再进行与操作,在就返回true
bool test(size_t x){size_t idx = x / 32;size_t pos = x % 32;return _bits[idx] & (1 << pos);}
到这里,位图就实现完了,笔者附上完整的代码和对代码进行测试,写完不测试,出问题都没地方哭!!!
完整代码
#include <iostream>
#include <vector>
using namespace std;namespace ljy
{class bitset{public://N表示总的元素个数bitset(size_t N){//为什么需要除以32位呢?//答:整形占四个字节,32个比特位_bits.resize(N / 32+1, 0);//这里开辟是按整形进行开辟的_num = 0;}void set(size_t x){//先算出在那个桶size_t idx = x / 32;//每个桶占32个位size_t pos = x % 32;//再算出在桶中的那个位置//在对应位由0置1_bits[idx] |= (1 << pos);//位运算优先级低于或运算++_num;//位图中元素个数++}void reset(size_t x){size_t idx = x / 32;//先求出在几号桶中size_t pos = x % 32;//在桶中的下标//再进行由1变0操作_bits[idx] &= ~(1 << pos);--_num;}bool test(size_t x){size_t idx = x / 32;size_t pos = x % 32;return _bits[idx] & (1 << pos);}private:vector<int> _bits;size_t _num;};}
测试代码
void test_bitset()
{bitset bit(10);//现在有100个位置//设置bit.set(1);bit.set(2);bit.set(3);bit.set(4);bit.set(5);//打印for (int i = 0; i < 10; i++){printf("[%d]:%d\n", i, bit.test(i));//如果在就会返回true,true转化为整形数值为1}
}
输出结果
daoz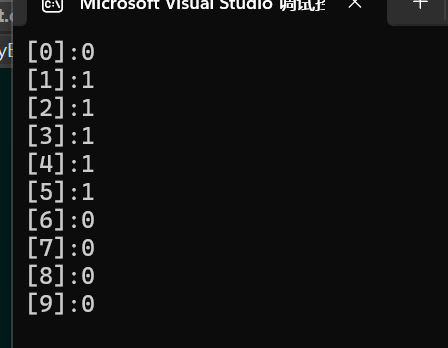
到这里为止,我们就讲完了位图的实现,那么接下来我们就需要讲讲位图的使用了。
3.位图优缺点
1.位图可以支持我们快速查找一个整形是否在集合中
2.位图也可以讲数据进行排序和去重
3.求两个集合的交集和并集
4.操作系统中磁盘块的标记
我们知道问题的优点是节省空间和效率高,但是各位老铁有没有发现,如果元素是字符串类型,位图还能处理吗,是不是位图只能处理整形。
4.布隆过滤器定义
现在问老铁们一个问题,现在假设我使用头条客户端看新闻,头条会不断的给我推荐新的内容,它每次给我推荐的内容是不是都要和上一次不一样,那么它就要对数据进行去重,那么头条的服务端是如何实现去重的呢???
它是不是会从我的浏览记录里面查,过滤掉我浏览记录里面已经存在的记录,那么我们的浏览记录那么多,它是如何快速查找的呢???
有老铁会立马想到了哈希,但是我的数据那么多,哈希消耗的内存是很大的!!!
那么还有老铁说使用刚刚学的位图,刚刚笔者说过了,位图只能处理整形,不能处理字符串类型!!!
那么就需要引出我们的嘉宾了,布隆过滤器
布隆过滤器是可以告诉你某样东西一定不存在或者可能存在,支持高效的插入和查询的数据结构。
回到上面的例子,这里的哈希冲突是不是指的是多个字符串映射到同一个位置,那么会导致后台认为这个内容已经推送过了,不会推送给我了,但实际上这个内容没有推送过给我,那么如何解决呢???
举个例子,你想买彩票中奖,那么如何能提高中奖率,那肯定是多买几张咯,这里也一样,如果我们让一个值映射到多个位置,那么是不是冲突的概率就降低了
那么接下来,我们就开始实现布隆过滤器了
5.布隆过滤器实现
(1)由于布隆过滤器底层还是位图结构,那么我们还需要使用我们刚刚写的位图结构,那么我们就明白了,布隆过滤器里面需要有位图对象和表示布隆过滤器总的位置个数的变量
#include <iostream>
#include "bitset.h"
using namespace std;namespace BoolmFilter
{//布隆过滤器中元素可能是字符串,也能是整形,也能是结构体等等//所以需要使用模板template<class K>class boolmfilter{private:ljy::bitset _bs;size_t _N;};
}
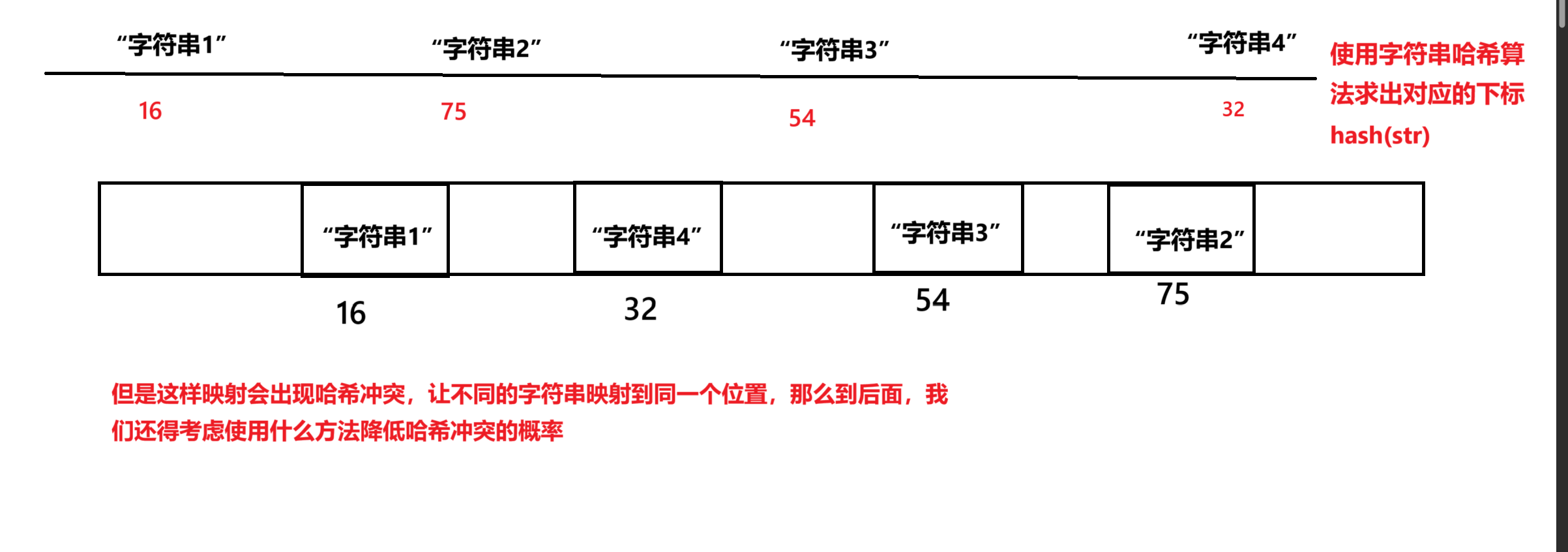
上面的代码还是有缺陷,在上面我们讲过,为了防止误判的概率增加,我们需要一个元素映射多个位置,但是我们不知道这个元素是什么类型,所以我们还需要加对应的仿函数,这里我们一个元素映射三个位置
#include <iostream>
#include "bitset.h"
using namespace std;namespace BoolmFilter
{//布隆过滤器中元素可能是字符串,也能是整形,也能是结构体等等//所以需要使用模板//由于常见的元素是字符串,那么就给缺省值是字符串template<class K,class Hash1=HashStr1,class Hash2=HashStr2,class Hash3=HashStr3>class boolmfilter{private:ljy::bitset _bs;size_t _N;};
}
(2)构造函数
bloomfilter(size_t num):_bs(5*num),_N(5*num)
{}
(3)实现仿函数
那么如何实现仿函数呢???
仿函数是伪装成函数的类,实际上是类,然后实现operator[]重载
//BKDRHash算法
struct HashStr1
{size_t operator()(const std::string& str){size_t hash = 0;for (size_t i = 0; i < str.size(); i++){hash *= 131;//魔数hash += str[i];}return hash;}
};//RSHash算法
struct HashStr2
{size_t operator()(const std::string& str){size_t hash = 0;size_t magic = 63689;//魔数for (size_t i = 0; i < str.size(); i++){hash *= magic;//魔数hash += str[i];magic *= 378551;}return hash;}
};//BKDRHash算法
struct HashStr3
{size_t operator()(const std::string& str){size_t hash = 0;for (size_t i = 0; i < str.size(); i++){hash *= 65599;//魔数hash += str[i];}return hash;}
};
(3)添加元素到布隆过滤器中
通过字符串哈希算法求出在布隆过滤器中的下标,然后借助位图在对应的下标进行标记。
//添加元素
void set(const K& key)
{//分别求出元素在布隆过滤器中的三个位置//size_t idx1 = Hash1()(key)%_N;//这个是仿函数size_t idx2 = Hash2()(key)%_N;//这个是仿函数size_t idx3 = Hash3()(key)%_N;//这个是仿函数//将key值映射到对应位置_bs.set(idx1);_bs.set(idx2);_bs.set(idx3);
}
(4)判断该元素是否在布隆过滤器中
其实底层就算判断这个元素在不在位图中的对应三个位置
bool test(const K& key)
{size_t idx1 = Hash1()(key) % _N;//如果不在返回falseif (!_bs.test(idx1)) return false;size_t idx2 = Hash2()(key) % _N;//如果不在返回falseif (!_bs.test(idx2)) return false;size_t idx3 = Hash3()(key) % _N;//如果不在返回falseif (!_bs.test(idx3)) return false;return true;
}
(5)布隆过滤器删除元素:布隆过滤器不支持删除操作,因为多个元素会映射到同一个位置,如果把位图中某一个位置由0置成1,那么会导致其他元素也会发生变化。
(6)测试:老规矩,写完代码一定要测试!!!
测试代码
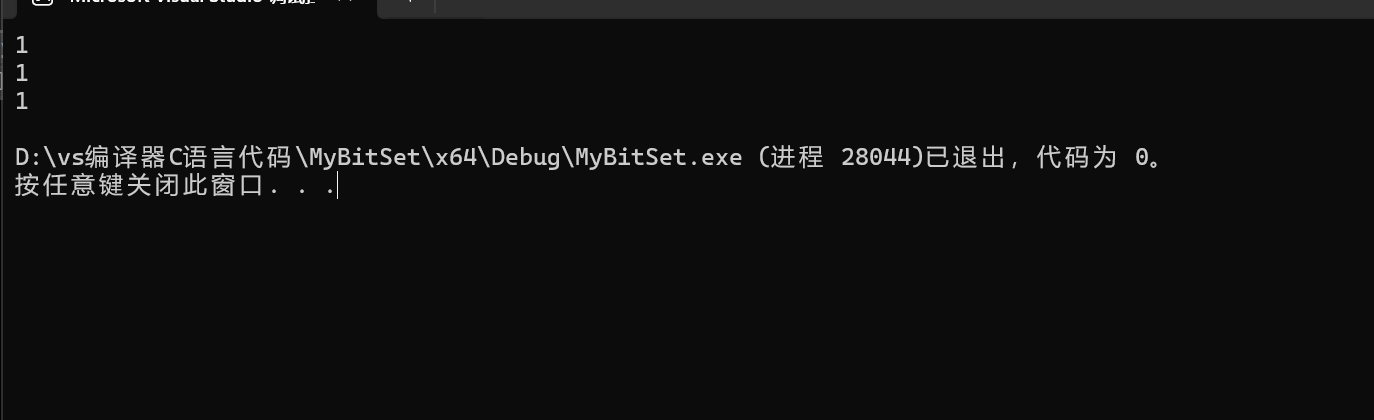
void bloomfilter_test()
{bloomfilter<std::string> bf(100);bf.set("abcd");bf.set("aadd");bf.set("bcad");cout << bf.test("abcd") << endl;cout << bf.test("aadd") << endl;cout << bf.test("bcad") << endl;}
输出结果
海量数据处理
我们已经学习完了哈希和位图和布隆过滤器,那么我们就需要趁热打铁,学了就要用,才会让我们印象深刻,那么接下来笔者会通过几道面试题来给各位老铁分享如何应用哈希和位图和布隆过滤器,解决实际问题!!!
位图题目
题目1:给定100亿个整数,设计算法找到只出现一次的整数?
分析:1G=2^30byte,一个整数占4个字节,那么100亿个整数占40G左右,内存肯定放不下了。那么自然而言我们就会想到今天学习到的位图来解决,但是上面我们讲的位图是只有两种状态的,
但是这里状态却是三种,一种是只出现0次,一种是只出现一次,还有一种是出现两次或两次以上!!!那么我们就需要改进位图来解决,通过使用两个bite位来进行标记,两个bite位是不是可以标记4种状态。,那么00可以表示只出现0次,01表示只出现一次,10表示出现两次或两次以上。
但是这种写法有点小复杂,如果是笔者,笔者不会使用这种写法,笔者会换种写法。
class solve{public:void set(size_t x){//00->01if (_bs1.test(x) == false && _bs2.test(x) == false){_bs2.set(x);}//01->10else if (_bs1.test(x) == false && _bs2.test(x) == true){_bs1.set(x);_bs1.reset(x);}//10就不需要处理了,最后再找出值为01映射的整数}private:bitset _bs1;bitset _bs2;};
题目2:给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件的交集???
在上面我们讲过,我们存储100亿个整数l,借助位图存储只需要500M左右。
方案一:将文件一映射到位图1中,将文件二映射到位图二中,然后再将两个位图进行&操作,如果&的结果是1,那么就是交集!!!
方案二:我只存一个文件的数据,只需要500M,那绰绰有余,然后,我们再读取另一个文件,通过判断读取的文件在不在位图中,在就是交集!!!
题目三:1个文件有10亿个整形数据,我们有1G内存,设计算法找到出现次数不超过2次的所有整数.
这道题,相信各位老铁会了,笔者就不讲了。
布隆过滤器题目
题目一:给两个文件,分别有100亿个query(query一般是sql语句查询或者网络请求的url等,一般是一个字符串),我们只有1G内存,假设平均一个query占30-60byte,那么我们如何找到两个文件的交集???
方案一:我们分析一下100亿个查询,大概占300-600G左右,那么我们可以将query映射到布隆过滤器中,读取文件2的query,判断在不在布隆过滤器中,在就是交集!!!(这里不能使用位图,位图只能处理整形)
但是方案一是有缺陷的,在上面我们讲过布隆过滤器是存在误判的,那么布隆过滤器是判断不在一定是准确的,判断在可能存在误判,然后,在布隆过滤器中不可能有交集数据漏掉,只会出现交集中有些数据不准确,因为我这个元素本来没有的,但是由于其它元素映射了我这个元素对应的比特位,导致我这个元素也出现在交集中。
那么为了解决以上的缺陷,我们就还需要有一个方案二
哈希切割
方案二:等分切分和哈希切分

题目一:给一个超过100G大小的log file(日志文件)c存着IP地址,现在需要你设计算法找到出现次数最多的IP地址?
这道题我们首先想到KV模型的map,但是数据量太大了,内存存不下,那么我们可以使用前面讲的哈希切割,先创建出1000个100M的小文件,再读取IP,计算出i=hashstr(IP)%1000,然后让该ip到i下标得小文件中,那么我们就可以保证相同得ip一定会进入到同一个文件中,最后再使用map来读取每一个Ai小文件出现得ip的次数,一个读完了,清理掉再读下一个,最后再使用一个pair类型的变量记录出现次数最多的ip
扩展
感兴趣的老铁可以去研究一下一致性哈希