MGP-STR:用于场景文本识别的多粒度预测
摘要
场景文本识别(Scene Text Recognition,简称STR)多年来一直是计算机视觉领域的研究热点。为了解决这一具有挑战性的问题,研究者们陆续提出了许多创新方法,近期将语言知识引入STR模型已成为一项重要趋势。在本研究中,我们首先从最近在Vision Transformer(ViT)上的进展中获得灵感,构建了一个概念上简单但性能强大的视觉STR模型,该模型基于ViT架构,在场景文本识别任务中优于以往的state-of-the-art模型,包括纯视觉模型和融合语言的模型。为整合语言知识,我们进一步提出了一种多粒度预测(Multi-Granularity Prediction)策略,以隐式方式将语言模态的信息注入模型中,即在输出空间中引入自然语言处理中广泛使用的子词表示(BPE和WordPiece),作为传统字符级别表示的补充,同时不采用独立的语言模型(Language Model,LM)。最终得到的算法被称为MGP-STR,其性能在STR任务上达到了新的高度,平均识别准确率达到了93.35%(在标准基准测试集上)。代码已开放获取:https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR。
关键词:场景文本识别、ViT、多粒度预测
1 引言
从自然场景中读取文本是构建具有高级智能的自动化机器所需的最基本能力之一。这正是计算机视觉社区的研究者们几十年来持续深入探索该复杂且具有挑战性任务的原因所在。场景文本识别(STR)任务的目标是从自然图像(通常是裁剪出的子图像)中解码出文本内容,它是文本读取流程中的关键环节。此前已有大量方法 [39,5,41,30] 被提出以应对STR问题。近年来,逐渐形成一种新趋势,即在文本识别过程中引入语言知识。SRN [53] 提出了一种全局语义推理模块(GSRM)来建模全局语义上下文;ABINet [9] 提出了双向完形填空网络(BCN)作为语言模型,用于学习双向特征表示。这些方法均采用了独立且分离的语言模型以获取丰富的语言先验。
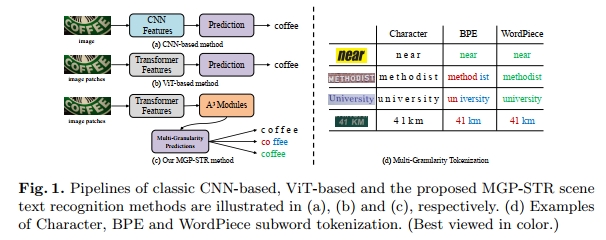
在本文中,我们提出了一种以隐式方式融合语言知识的方法用于场景文本识别。具体而言,我们首先基于ViT [8] 和一个定制的Adaptive Addressing and Aggregation(A3)模块(该模块灵感来源于TokenLearner [36])构建了一个纯视觉的STR模型。该模型作为一个强基线,在实验对比中已经取得了优于以往场景文本识别方法的性能。为了进一步利用语言知识增强视觉STR模型,我们探索了一种Multi-Granularity Prediction(MGP)策略来引入语言模态的信息。模型的输出空间被扩展,引入了subword表示(BPE和WordPiece),即该增强模型除了原始的字符级预测外,还会额外产生两个subword级的预测。值得注意的是,模型中并不包含独立的语言模型。在训练阶段,最终模型(命名为MGP-STR)在一个标准的多任务学习范式下进行优化(三种类型预测分别对应三个loss),语言知识自然地被融合进基于ViT的STR模型中。在推理阶段,三种类型的预测会被融合以给出最终的预测结果。在标准基准测试上的实验验证了所提出的MGP-STR算法能够达到state-of-the-art的性能。MGP-STR的另一个优势是它不涉及迭代式精炼,这种精炼在推理阶段可能会非常耗时。所提出的MGP-STR算法的整体流程以及以往基于CNN和ViT的方法流程如图1所示。简而言之,MGP-STR与其他方法的主要区别在于它生成三种类型的预测,分别代表不同粒度的文本信息:从单个字符到短字符组合,甚至完整单词。
本工作的贡献总结如下:
(1) 我们构建了一个纯视觉的STR模型,该模型将ViT与一个特别设计的A3模块结合,已经优于现有方法。
(2) 我们探索了一种隐式融合语言知识的方法,通过引入subword表示来实现多粒度预测,并证明独立语言模型(如SRN和ABINet中使用的)对于STR模型并非不可或缺。
(3) 所提出的MGP-STR算法达到了state-of-the-art的性能。
2 相关工作
场景文本识别(Scene Text Recognition,STR)长期以来一直是关注和研究的课题 [58,28,4]。随着深度学习方法的流行 [42,13,21],其在STR领域的有效性已被广泛验证。根据是否使用语言信息,我们大致将STR方法分为两类,即language-free方法与language-augmented方法。
2.1 语言无关的场景文本识别方法
STR方法中图像特征提取的主流方式是CNN [42,13]。例如,以往的STR方法 [39,40,21] 使用了VGG,而当前的STR方法 [3,26,2,48] 为了获得更好的性能采用了ResNet [13]。基于强大的CNN特征,提出了多种方法 [57,33,25] 来解决STR问题。基于CTC的方法 [39,46,26,15,14] 使用Connectionist Temporal Classification(CTC)[10] 来实现序列识别。基于分割的方法 [24,47,23,45] 则将STR看作一个语义分割问题。
受Transformer [44] 在自然语言处理(NLP)任务中巨大成功的启发,Transformer在STR中的应用也受到越来越多的关注。Vision Transformer(ViT)[8] 直接处理图像patch而不使用卷积操作,开启了使用Transformer block代替CNN来解决计算机视觉问题的探索 [27,52],并取得了显著成果。ViTSTR [1] 尝试直接利用ViT最后一层的特征表示进行并行的字符解码。总体来看,由于缺乏语言信息,language-free方法在识别低质量图像时常常表现不佳。
2.2 语言增强的场景文本识别方法
显然,语言信息有助于识别低质量图像。基于RNN的方法 [39,21,48] 能有效捕捉字符之间的序列依赖性,可视作一种隐式语言模型。然而,它们在训练与推理过程中无法并行执行解码。近年来,Transformer block被引入到基于CNN的框架中,以促进语言内容的学习。SRN [53] 提出了一个Global Semantic Reasoning Module(GSRM),通过多路并行传输来捕捉全局语义上下文。ABINet [9] 提出了一个Bidirectional Cloze Network(BCN),用于显式建模语言信息,并进一步用于迭代纠错。VisionLAN [51] 提出了一个视觉推理模块,通过在特征层对输入图像进行遮蔽,来同时捕捉视觉与语言信息。上述方法均利用特定模块来融合语言信息。
与此同时,大多数工作 [16,9] 是基于字符级或词级捕捉语义信息。而在本文中,我们尝试基于BPE和WordPiece tokenizations,利用字符、subword乃至词级的multi-granularity语义信息。
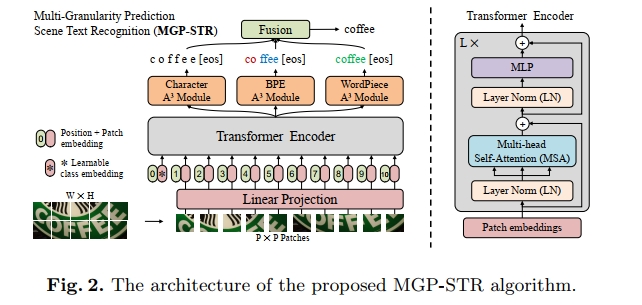
3 Methodology
所提出的MGP-STR方法的概述如图2所示,该方法主要基于原始的Vision Transformer(ViT)模型 [8]。我们提出了一个定制的Adaptive Addressing and Aggregation(A3)模块,用于从ViT中选择有意义的token组合,并将其整合为对应于特定字符的一个输出token,称为Character A3模块。此外,基于BPE A3模块和WordPiece A3模块设计了用于subword预测的分类头,以便隐式建模语言信息。最后,这些多粒度的预测通过一个简单而有效的融合策略进行合并。
3.1 视觉Transformer 骨干网络
MGP-STR的基本架构是Vision Transformer [8,43],其中原始图像patch通过线性投影直接用于图像特征提取。如图2所示,输入的RGB图像 x ∈ R H × W × C \mathbf { x } \in \mathbb { R } ^ { H \times W \times C } x∈RH×W×C被切割成不重叠的patches。具体而言,图像被重塑为一系列扁平化的2D patches x p ∈ R N × ( P 2 C ) \mathbf { x } _ { p } \in \mathbb { R } ^ { N \times ( P ^ { 2 } C ) } xp∈RN×(P2C),其中( P × P P × P P×P)是每个图像patch的分辨率,而( P 2 C P ^ { 2 } C P2C)是xp的特征通道数。通过这种方式,2D图像被表示为一个包含 N = H W / P 2 N = H W / P ^ { 2 } N=HW/P2个token的序列,这些token作为Transformer block的有效输入序列。然后, x p \mathbf { x } _ { p } xp的这些token通过线性变换为D维的patch嵌入。与原始的ViT [8]主干类似,引入了一个D维的可学习[class] token嵌入,作为patch嵌入的一部分。位置嵌入也添加到每个patch嵌入中,以保留位置信息,其中采用标准的可学习1D位置嵌入。因此,patch嵌入向量的生成公式如下:
z 0 = [ x c l a s s ; x p 1 E ; x p 2 E ; … ; x p N E ] + E p o s , ( 1 ) \begin{array} { r } { \mathbf { z } _ { 0 } = [ \mathbf { x } _ { c l a s s } ; \mathbf { x } _ { p } ^ { 1 } \mathbf { E } ; \mathbf { x } _ { p } ^ { 2 } \mathbf { E } ; \ldots ; \mathbf { x } _ { p } ^ { N } \mathbf { E } ] + \mathbf { E } _ { p o s } , } \end{array}\quad(1) z0=[xclass;xp1E;xp2E;…;xpNE]+Epos,(1)
其中, x c l a s s ∈ R 1 × D \mathbf { x } _ { c l a s s } \in \mathbb { R } ^ { 1 \times D } xclass∈R1×D 是[class]嵌入, E ∈ R ( P 2 C ) × D \mathbf { E } \in \mathbb { R } ^ { ( P ^ { 2 } C ) \times D } E∈R(P2C)×D 是线性投影矩阵, E p o s ∈ R ( N + 1 ) × D \mathbf { E } _ { p o s } \in \mathbb { R } ^ { ( N + 1 ) \times D } Epos∈R(N+1)×D 是位置嵌入。
最终得到的特征序列 z 0 ∈ R ( N + 1 ) × D \mathbf { z } _ { 0 } \in \mathbb { R } ^ { ( N + 1 ) \times D } z0∈R(N+1)×D 作为Transformer编码器块的输入,该编码器块主要由多头自注意力(MSA)、层归一化(LN)、多层感知机(MLP)和残差连接组成,如图2所示。Transformer编码器块的公式如下:
z l ′ = M S A ( L N ( z l − 1 ) ) + z l − 1 z l = M L P ( L N ( z l ′ ) ) + z l ′ . ( 2 ) \begin{array} { r l } & { \mathbf { z } _ { l } ^ { \prime } = \mathrm { M S A } ( L N ( \mathbf { z } _ { l - 1 } ) ) + \mathbf { z } _ { l - 1 } } \\ & { \mathbf { z } _ { l } = \mathrm { M L P } ( L N ( \mathbf { z } _ { l } ^ { \prime } ) ) + \mathbf { z } _ { l } ^ { \prime } . } \end{array}\quad(2) zl′=MSA(LN(zl−1))+zl−1zl=MLP(LN(zl′))+zl′.(2)
这里,L是Transformer块的深度, l = 1 … L l = 1 \ldots L l=1…L。MLP由两个线性层和GELU激活函数组成。最终,Transformer的输出嵌入 z L ∈ R ( N + 1 ) × D \mathbf { z } _ { L } \in \mathbb { R } ^ { ( N + 1 ) \times D } zL∈R(N+1)×D 被用于后续的文本识别。
3.2 自适应寻址与聚合 ( A 3 ) (A^3) (A3) 模块
传统的Vision Transformers [8,43] 通常将一个可学习的xclass token附加到patch嵌入序列前面,直接收集和聚合有意义的信息,并作为整个图像的表示用于分类。而场景文本识别任务的目标是生成一个字符预测序列,其中每个字符仅与图像的一个小patch相关。因此, z L 0 ∈ R D \mathbf { z } _ { L } ^ { 0 } \in \mathbb { R } ^ { D } zL0∈RD的全局图像表示不足以完成文本识别任务。ViTSTR [1]直接使用 z L \mathbf { z } _ { L } zL的前T个token进行文本识别,其中T是最大文本长度。不幸的是, z L \mathbf { z } _ { L } zL的其余token没有被充分利用。
为了充分利用 z L \mathbf { z } _ { L } zL序列中的丰富信息进行文本序列预测,我们提出了一个定制的Adaptive Addressing and Aggregation ( A 3 A^3 A3) 模块,用于选择 z L \mathbf { z } _ { L } zL中有意义的token组合,并将其整合为一个对应于特定字符的token。具体而言,我们从序列zL中学习T个token Y = [ y i ] i = 1 T \mathbf { Y } = [ \mathbf { y } _ { i } ] _ { i = 1 } ^ { T } Y=[yi]i=1T,以用于后续的文本识别任务。因此,聚合函数被定义为 y i = A i ( z L ) \mathbf { y } _ { i } = A _ { i } ( \mathbf { z } _ { L } ) yi=Ai(zL),它将输入 z L \mathbf { z } _ { L } zL转换为一个token向量 y i : R ( N + 1 ) × D ↦ R 1 × D \mathbf { y } _ { i } \, : \, \mathbb { R } ^ { ( N + 1 ) \times D } \, \mapsto \, \mathbb { R } ^ { 1 \times D } yi:R(N+1)×D↦R1×D。并且,为文本识别的顺序输出构建了这样的T个函数。
通常,聚合函数 A i ( z L ) A _ { i } ( \mathbf { z } _ { L } ) Ai(zL)是通过空间注意力机制[36]来实现的,以自适应地选择 z L \mathbf { z } _ { L } zL中对应于第i个字符的token。在这里,我们使用函数 α i ( z L ) \alpha _ { i } ( \mathbf { z } _ { L } ) αi(zL)和softmax函数来从 z L ∈ R ( N + 1 ) × D \mathbf { z } _ { L } \in \mathbb { R } ^ { ( N + 1 ) \times D } zL∈R(N+1)×D生成精确的空间注意力掩码 m i ∈ R ( N + 1 ) × 1 \mathbf { m } _ { i } \in \mathbb { R } ^ { ( N + 1 ) \times 1 } mi∈R(N+1)×1。因此,A3模块的每个输出token yi通过以下公式产生:
y i = A i ( z L ) = m i T z ~ L = s o f t m a x ( α i ( z L ) ) T ( z L U ) T ( 3 ) \mathbf { y } _ { i } = A _ { i } ( \mathbf { z } _ { L } ) = \mathbf { m } _ { i } ^ { T } \tilde { \mathbf { z } } _ { L } = \mathrm { s o f t m a x } ( \alpha _ { i } ( \mathbf { z } _ { L } ) ) ^ { T } ( \mathbf { z } _ { L } \mathbf { U } ) ^ { T }\quad(3) yi=Ai(zL)=miTz~L=softmax(αi(zL))T(zLU)T(3)
其中, α i ( ⋅ ) \alpha _ { i } ( \cdot ) αi(⋅)通过使用一个1 × 1的卷积核实现。 U ∈ R D × D \mathbf { U } \in \mathbb { R } ^ { D \times D } U∈RD×D是用于学习特征 z ~ L \tilde { \mathbf { z } } _ { L } z~L的线性映射矩阵。因此,来自不同聚合函数的最终token将汇聚在一起,形成最终的输出张量,如下所示:
Y = [ y 1 y 2 ; … ; y T ] = [ A 1 ( z L ) ; A 2 ( z L ) ; … ; A T ( z L ) ] . ( 4 ) Y = [y_1 y_2; \dots; y_T] = [A_1(z_L); A_2(z_L); \dots; A_T(z_L)]. \quad(4) Y=[y1y2;…;yT]=[A1(zL);A2(zL);…;AT(zL)].(4)
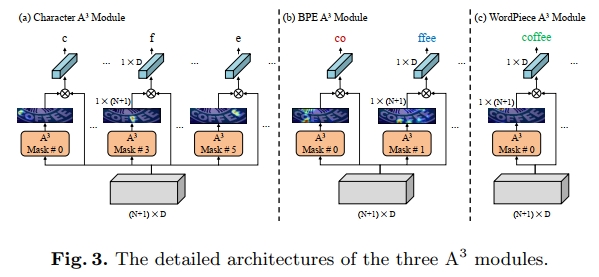
由于高效的 A 3 A^3 A3模块,文本序列的最终表示被表示为: Y ∈ R T × D Y ∈ R^{T×D} Y∈RT×D ,接着,构建一个字符分类头用于文本序列识别: G = Y W T ∈ R T × K , G = YW^T ∈ R^{T×K}, G=YWT∈RT×K, 其中, W ∈ R K × D \mathbf { W } \in \mathbb { R } ^ { K \times D } W∈RK×D是一个线性映射矩阵,K是类别数量,G是分类logits。我们将该模块称为Character A 3 A^3 A3,用于字符级别的预测,其详细结构如图3(a)所示。
Pytorch实现
import torch
import torch.nn as nn
import torch.nn.functional as Fclass AlphaNet(nn.Module):"""生成每个字符位置的注意力权重 α_i(z_L)"""def __init__(self, embed_dim, num_chars):super().__init__()self.num_chars = num_charsself.conv1x1 = nn.Conv1d(embed_dim, num_chars, kernel_size=1)def forward(self, z_L): # z_L: [B, N+1, D]z_L = z_L.transpose(1, 2) # [B, D, N+1]alpha = self.conv1x1(z_L) # [B, T, N+1]alpha = alpha.transpose(1, 2) # [B, N+1, T]return alpha # 每个token的注意力得分class CharacterA3(nn.Module):"""A^3 模块:从 z_L 中聚合得到 T 个字符级 token 表示"""def __init__(self, embed_dim, num_chars):super().__init__()self.alpha_net = AlphaNet(embed_dim, num_chars)self.U = nn.Linear(embed_dim, embed_dim, bias=False)def forward(self, z_L): # z_L: [B, N+1, D]B, N, D = z_L.size()alpha = self.alpha_net(z_L) # [B, N, T]attn_mask = F.softmax(alpha, dim=1) # softmax over N (token axis)z_proj = self.U(z_L) # [B, N, D]# 聚合: batch 矩阵乘法Y = torch.einsum('bnt,bnd->btd', attn_mask, z_proj) # [B, T, D]return Yclass ClassifierHead(nn.Module):"""字符分类头: Y @ W^T"""def __init__(self, embed_dim, num_classes):super().__init__()self.fc = nn.Linear(embed_dim, num_classes)def forward(self, Y): # Y: [B, T, D]return self.fc(Y) # [B, T, K]class CharacterA3Recognizer(nn.Module):"""整合 Character A^3 模块 + 分类头"""def __init__(self, embed_dim, num_chars, num_classes):super().__init__()self.a3 = CharacterA3(embed_dim, num_chars)self.classifier = ClassifierHead(embed_dim, num_classes)def forward(self, z_L): # z_L: [B, N+1, D]Y = self.a3(z_L) # [B, T, D]logits = self.classifier(Y) # [B, T, K]return logits| 维度 | 含义 | 示例值 |
|---|---|---|
B | Batch size(批大小) | 一个 batch 中的图像数量,例如 32 |
D | Embedding dim(特征维度) | 每个 token 的特征向量维度,例如 384 |
N | Token 数量(不含字符数) | patch 数 + 1(通常是 196 + 1 = 197) |
T | Max text length(最大字符数) | 模型最多预测的字符数,例如 25 个字符 |
3.3 多粒度预测
字符标记化方法简单地将文本分割为字符,这在场景文本识别方法中是常见的。然而,这种简单而标准的方法忽视了文本的语言信息。为了有效地利用语言信息进行场景文本识别,我们将子词[20]标记化机制引入到文本识别方法中。子词标记化算法旨在将稀有单词分解为有意义的子词,并保留常用单词,这样单词的语法信息就已经在子词中得到了捕捉。同时,由于A3模块独立于Transformer编码器骨干网,我们可以直接添加额外的并行子词A3模块来进行子词预测。这样,语言信息可以隐式地注入到模型学习中,从而提高性能。值得注意的是,先前的方法,如SRN[53]和ABINet[9],为语言建模设计了显式的Transformer模块,而我们将语言信息编码问题作为字符和子词预测任务来处理,且没有显式的语言模型。具体而言,我们使用两种子词标记化算法——字节对编码(BPE)[38]和WordPiece[37]——来生成如图1(b)©所示的多种组合。因此,提出了BPE A3模块和WordPiece A3模块用于子词注意力。同时,使用两个子词级别的分类头进行子词预测。由于子词可能是整个单词(例如,WordPiece中的“coffee”),因此BPE和WordPiece分类头可以生成子词级甚至单词级的预测。与原始的字符级预测一起,我们将这些不同的输出称为用于文本识别的多粒度预测。通过这种方式,字符级预测保证了基本的识别准确性,而子词级或单词级预测可以通过语言信息为噪声图像提供补充结果。
从技术上讲,BPE或WordPiece A3模块的架构与字符A3模块相同。它们是相互独立的,并具有不同的参数。不同的分类头有不同的类别数量,这取决于每个标记化方法的词汇大小。分类使用交叉熵损失。此外,掩码mi精确指示了字符A3模块中第i个字符的注意力位置,而在子词A3模块中,它大致显示了图像中第i个子词区域,因为子词分割的学习具有更高的复杂性和不确定性。
3.4 多粒度结果的融合策略
多粒度预测(字符、BPE和WordPiece)由不同的A3模块和分类头生成。因此,需要一种融合策略来合并这些结果。一开始,我们尝试通过在特征层级上聚合来自不同A3模块的文本特征Y来融合多粒度信息。然而,由于这些特征来自不同的粒度,字符级的第i个token y i c h a r \mathbf { y } _ { i } ^ { c h a r } yichar 与BPE级别的第i个token y i b p e \mathbf { y } _ { i } ^ { b p e } yibpe(或WordPiece级别的 y i w p \mathbf { y } _ { i } ^ { w p } yiwp)并不对齐,因此这些特征不能直接加起来进行融合。同时,即使我们通过 [ Y i c h a r , Y i b p e , Y i w p ] [ \mathbf { Y } _ { i } ^ { c h a r } , \mathbf { Y } _ { i } ^ { b p e } , \mathbf { Y } _ { i } ^ { w p } ] [Yichar,Yibpe,Yiwp]连接特征,也只能使用一个字符级头进行最终的预测。这样,子词信息将大大受到损害,导致效果提升有限。因此,我们的方法采用了决策层融合策略。然而,完美地融合这些预测是一个具有挑战性的问题[11]。因此,我们提出了一种基于预测置信度的折中但高效的融合策略。具体而言,每个字符或子词的识别置信度可以通过相应的分类头获得。然后,我们提出了两个融合函数f(·)来基于原子置信度生成最终的识别分数:
f M e a n ( [ c 1 , c 2 , … , c e o s ] ) = 1 n ∑ i = 1 e o s c i ( 5 ) f _ { M e a n } ( [ c _ { 1 } , c _ { 2 } , \dots , c _ { e o s } ] ) = \frac { 1 } { n } \sum _ { i = 1 } ^ { e o s } c _ { i } \quad(5) fMean([c1,c2,…,ceos])=n1i=1∑eosci(5) f C u m p r o d ( [ c 1 , c 2 , . … , c e o s ] ) = ∏ i = 1 e o s c i ( 6 ) f _ { C u m p r o d } ( [ c _ { 1 } , c _ { 2 } , . \ldots , c _ { e o s } ] ) = \prod _ { i = 1 } ^ { e o s } \; c _ { i }\quad(6) fCumprod([c1,c2,.…,ceos])=i=1∏eosci(6)
我们仅考虑有效字符或子词以及结束符号 eos 的置信度,忽略填充符号 pad。通过如公式 (5) 所示的均值函数生成“Mean”识别分数。而“Cumprod”表示由累积乘积函数生成的识别分数。接着,可以通过函数 f(·) 为同一张图像的三个分类头分别计算出三个识别分数。我们仅简单地选取识别分数最高的那个,作为最终预测结果。
我们通过一个具体例子来解释这段“多粒度结果融合策略”的过程和意义。
背景简述:
在场景文本识别中,我们使用多个不同的粒度来识别图像中的文字:
| 粒度类型 | 输出单位 | 示例 |
|---|---|---|
| 字符级(char) | 单个字符 | T, e, x, t |
| BPE | 子词(比如 ##ext) | T, ##ext |
| WordPiece | 更粗的子词结构 | Text |
每个粒度都有自己的 A³ 模块和分类头,分别独立地预测识别结果(和置信度)。
Step 1 假设:
假设你现在识别一张图像,三个粒度给出了如下预测(及其每个 token 的置信度):
字符级预测(char):
- 预测:
["T", "e", "x", "t"] - 置信度:
[0.9, 0.8, 0.85, 0.95]
BPE预测:
- 预测:
["T", "##ext"] - 置信度:
[0.88, 0.91]
WordPiece预测:
- 预测:
["Text"] - 置信度:
[0.86]
Step 2: 计算三个识别分数
我们使用两种方式来为每个粒度生成识别分数:
方法一:Mean(平均值)
f Mean ( c 1 , c 2 , . . . , c e o s ) = 1 n ∑ i = 1 e o s c i f_{\text{Mean}}(c_1, c_2, ..., c_{eos}) = \frac{1}{n} \sum_{i=1}^{eos} c_i fMean(c1,c2,...,ceos)=n1i=1∑eosci
- char: ( 0.9 + 0.8 + 0.85 + 0.95 ) / 4 = 0.875 (0.9 + 0.8 + 0.85 + 0.95)/4 = 0.875 (0.9+0.8+0.85+0.95)/4=0.875
- BPE: ( 0.88 + 0.91 ) / 2 = 0.895 (0.88 + 0.91)/2 = 0.895 (0.88+0.91)/2=0.895
- WP : 0.86 0.86 0.86(只有一个 token)
方法二:Cumprod(累积乘积)
f Cumprod ( c 1 , c 2 , . . . , c e o s ) = ∏ i = 1 e o s c i f_{\text{Cumprod}}(c_1, c_2, ..., c_{eos}) = \prod_{i=1}^{eos} c_i fCumprod(c1,c2,...,ceos)=i=1∏eosci
- char: 0.9 × 0.8 × 0.85 × 0.95 ≈ 0.5805 0.9 × 0.8 × 0.85 × 0.95 ≈ 0.5805 0.9×0.8×0.85×0.95≈0.5805
- BPE: 0.88 × 0.91 ≈ 0.8008 0.88 × 0.91 ≈ 0.8008 0.88×0.91≈0.8008
- WP : 0.86 0.86 0.86
Step 3 最后一步:选择哪个预测?
无论你用 Mean 还是 Cumprod,你都得到了每个粒度对应的“整体置信分数”。最终只需要选择置信分数最大的那个预测结果即可作为最终输出。
用 Mean 策略:
- BPE 的 0.895 最高 → 最终识别为:
["T", "##ext"]→ 解码为"Text"
用 Cumprod 策略:
- BPE 的 0.8008 最高 → 同样选择
"Text"
4 实验
4.1 数据集
为了公平对比,我们使用 MJSynth [16,17] 和 SynthText [12] 作为训练数据。MJSynth 包含 900 万张真实文本图像,SynthText 包含 700 万张合成文本图像。测试数据集包含“规则”和“不规则”两类。“规则”数据集主要由水平对齐的文本图像组成。IIIT 5K-Words (IIIT) [31] 包含 3,000 张从网页上收集的图像。Street View Text (SVT) [49] 包含 647 张测试图像。ICDAR 2013 (IC13) [19] 包含 1,095 张从商场图片中裁剪出的图像,但最终我们在 857 张图像上进行评估,去除了包含非字母数字字符或少于三个字符的图像。
“不规则”数据集中的文本实例大多是弯曲或扭曲的。ICDAR 2015 (IC15) [18] 包含 2,077 张从 Google Eyes 收集的图像,但我们使用其中 1,811 张图像,去除了一些极度扭曲的图像。Street View Text-Perspective (SVTP) [32] 包含 639 张从 Google 街景中收集的图像。CUTE80 (CUTE) [35] 包含 288 张弯曲文本图像。
4.2 实现细节
**模型配置。**MGP-STR 构建于 DeiT-Base 模型 [43] 之上,该模型由 12 个堆叠的 transformer block 构成。每层中,注意力头数量为 12,嵌入维度 D 为 768。更重要的是,我们的方法并未采用常见的 224×224 方形图像输入 [8,43,1]。输入图像的高度 H 和宽度 W 设置为 32 和 128。Patch 大小 P 设置为 4,因此可以产生 N = 8 × 32 = 256 N = 8 × 32 = 256 N=8×32=256 个 patch,加上一个 [class] token,即最终的 z L ∈ R 257 × 768 \mathbf { z } _ { L } \in \mathbb { R } ^ { 2 5 7 \times 7 6 8 } zL∈R257×768。A3 模块的输出序列 Y 的最大长度 T 设置为 27。Character 分类头的词表大小 K 设置为 38,包括 0 − 9 、 a − z 0 − 9、a − z 0−9、a−z、pad(填充符号)和 eos(结束符号)。BPE 和 WordPiece 分类头的词表大小分别为 50,257 和 30,522。
模型训练。 除了 patch embedding 模块(由于 patch 尺寸不一致),我们加载 DeiT-base [43] 的预训练权重作为初始参数。采用常见的文本图像数据增强方法 [6],如透视变换、仿射变换、模糊、噪声和旋转。我们使用两张 NVIDIA Tesla V100 GPU 训练模型,批大小为 100。优化器使用 Adadelta [55],初始学习率设为 1。学习率衰减策略为 Cosine Annealing LR [29],训练共进行 10 个 epoch。
4.3 关于 Vision Transformer 和 A3 模块的讨论
我们分析了 Vision Transformer 的 patch 大小对模型的影响,以及 A 3 A^3 A3 模块在所提出的 MGP-STR 方法中的有效性(如表 1 所示)。 M G P − S T R P = 16 \mathrm { M G P - S T R } _ { P = 1 6 } MGP−STRP=16 表示该模型直接使用 z L \mathbf { z } _ { L } zL的前 T 个 token 进行文本识别,与 ViTSTR [1] 中的方法相同,此时输入图像被重新调整为 224 × 224,patch 大小设置为 16 × 16。为了保留原始文本图像的重要信息,MGP-STRP=4 中使用了 32 × 128 图像以及 4 × 4 的 patch。 M G P − S T R P = 4 \mathrm { M G P - S T R } _ { P = 4 } MGP−STRP=4 的性能优于 M G P − S T R P = 16 \mathrm { M G P - S T R } _ { P = 16 } MGP−STRP=16,这表明 ViT [8,43] 的标准图像尺寸不适用于文本识别。因此,MGP-STR 中采用了 32 × 128 的图像与 4 × 4 的 patch。
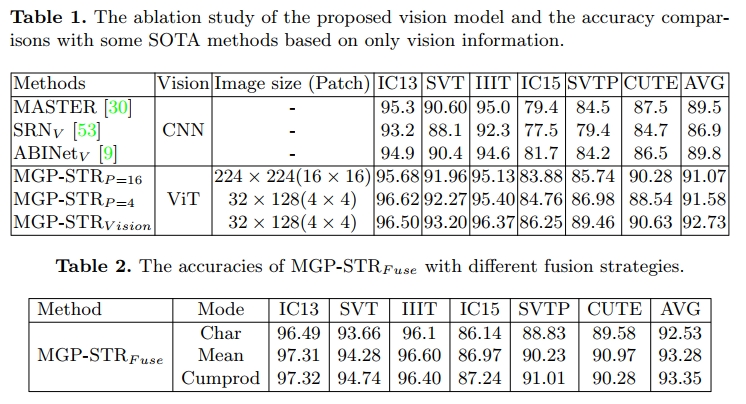
当将 Character A 3 A^3 A3 模块引入 MGP-STR 中(记作 MGP-STRVision)时,识别性能将进一步提升。 M G P − S T R P = 16 \mathrm { M G P - S T R } _ { P = 1 6 } MGP−STRP=16和 M G P − S T R P = 4 \mathrm { M G P { - } S T R } _ { P = 4 } MGP−STRP=4 无法充分学习和利用所有 token,而 Character A3 模块可以自适应地聚合最后一层的特征,从而实现更充分的学习和更高的准确率。同时,与使用 CNN 特征提取器的 SOTA 文本识别方法相比,所提出的 M G P − S T R V i s i o n \mathrm { M G P - S T R } _ { V i s i o n } MGP−STRVision 方法在性能上实现了显著提升。
4.4 多粒度预测的讨论
融合策略的影响。由于 subword 分词方法生成的 subword 单元包含语法信息,我们直接将 subword 作为目标,以隐式捕获语言信息。如第 3.2 节所述,我们采用了两种不同的 subword 分词方法(BPE 和 WordPiece),用于互补的多粒度预测。除了字符预测之外,我们还提出了两种融合策略,用于进一步融合这三类结果,分别记作第 3.4 节中提到的 “Mean” 与 “Cumprod”。我们将融合三类预测结果的方法记作 MGP-STRFuse,其在不同融合策略下的准确率结果列于表 2 中。此外,表 2 的第一行 “Char” 记录了 MGP-STRFuse 中字符分类头的单独结果。可以明显看出,无论是 “Mean” 还是 “Cumprod” 融合策略,都能显著提升相较于单一字符级别结果的识别准确率。由于 “Cumprod” 策略表现更优,我们在后续实验中采用该策略作为默认融合方法。
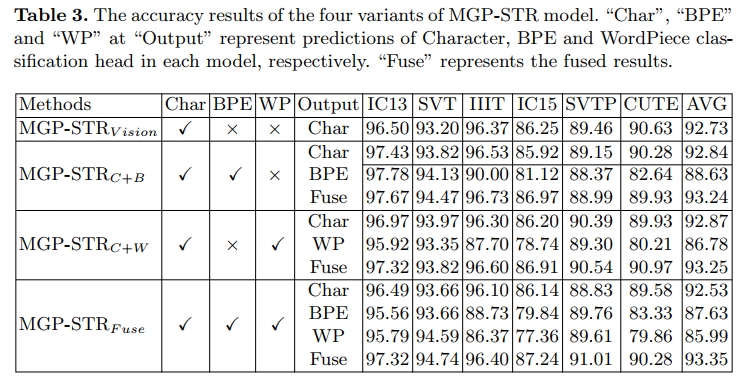
子词表示的影响 。 我们评估了 MGP-STR 模型的四种变体,其性能如表 3 所详尽列出,包括融合结果与各个单独分类器的结果。具体而言,仅使用 Character A 3 A^3 A3 模块的 MGP-STRVision 就已经获得了有希望的结果。MGP-STRC+B 和 MGP-STRC+W 分别将 Character A 3 A^3 A3 模块与 BPE A3 模块、WordPiece A3 模块结合在一起。无论单独使用哪种 subword 分词方法,在 MGP-STRC+B 和 MGP-STRC+W 两种方法中,“Fuse” 的准确率都能超过 “Char”。尤其值得注意的是,在相同模型中,“BPE” 或 “WP” 的分类性能在 SVP 和 SVTP 数据集上甚至优于 “Char”。这些结果表明,subword 预测通过隐式引入语言信息,能够提升文本识别性能。因此,配备三种 A 3 A^3 A3 模块的 MGP-STRFuse 能够实现字符、subword,甚至 word 级别的互补多粒度预测,通过融合这些多粒度结果,MGP-STRFuse 达到了最佳性能。
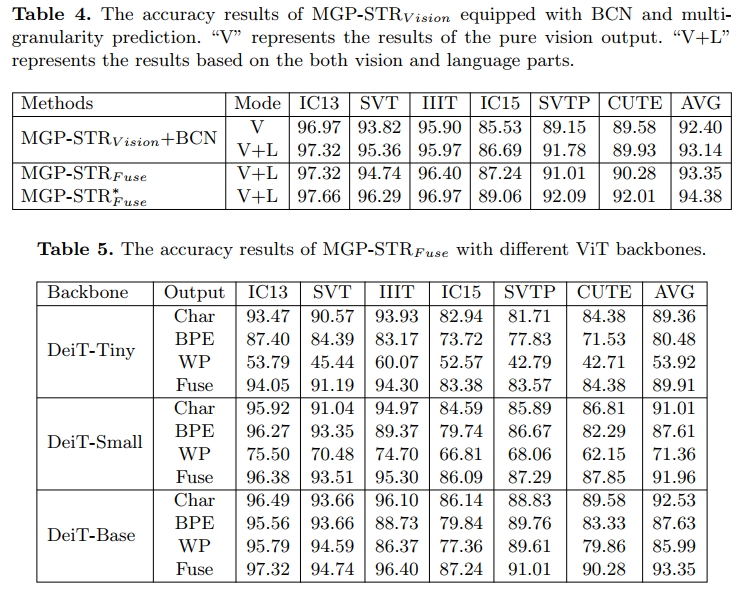
与 BCN 的对比 。ABINet [9] 中提出的双向 cloze 网络(BCN)是一种用于显式语言建模的方法,它能显著提升纯视觉模型的性能。我们将 BCN 加入 MGP-STRVision 中,与 MGP-STRFuse 进行对比,以验证多粒度预测的优势。具体而言,我们首先将表示特征 Y 的维度从 768 降到 512,以便与 BCN 的输出进行特征融合。按照 [9] 中的训练设定,模型结果列于表 4。MGP-STRVision+BCN 中的 “V+L” 在纯视觉预测 “V” 的基础上进一步提升,并超过了原始的 ABINet [9],但其性能略逊于 MGP-STRFuse。
此外,我们在表 4 中给出了 MGP-STRFuse 性能的上限,记作 MGP-STRFuse。如果三类预测中的任意一个(“Char”、“BPE” 或 “WP”)是正确的,则认为最终预测是正确的。MGP-STRFuse 的最高得分展示了多粒度预测的巨大潜力。更重要的是,MGP-STRFuse 只需引入两个新的 subword 预测头,而不需要像 [9, 53] 中那样设计一个特定的显式语言模型。
4.5 不同 ViT 主干结构下的结果
上述所有提出的 MGP-STR 模型均基于 DeiT-Base [43] 构建。为了进一步评估 MGP-STRFuse 方法的有效性,我们还引入了两个更小的模型,即 DeiT-Small 和 DeiT-Tiny,如 [43] 所述。具体来说,DeiT-Small 和 DeiT-Tiny 的嵌入维度分别被减少至 384 和 192。表 5 记录了在不同 ViT 主干下,MGP-STRFuse 方法中各个预测头的结果。
显然,在每一个主干结构中,融合多粒度预测都可以提升纯字符级预测的性能。而且,在相同的预测头下,较大的模型能取得更好的表现。更重要的是,即使是 DeiT-Small 甚至 DeiT-Tiny 中的 “Char” 预测结果,也已经超过了基于纯 CNN 的 SOTA 视觉模型(可参考表 1)。因此,使用小型或轻量 ViT 主干的 MGP-STRVision 依然是一种具有竞争力的视觉模型,而多粒度预测策略在不同 ViT 主干中同样有效。
4.6 与现有最先进方法的对比
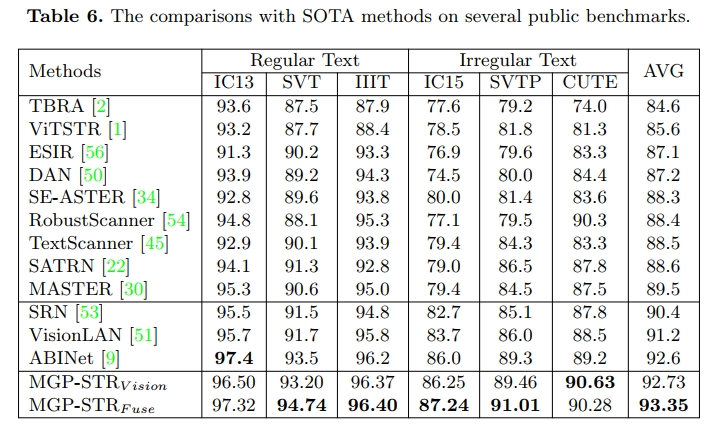
我们将所提出的 MGP-STRVision 和 MGP-STRFuse 方法与现有最先进的场景文字识别方法进行了对比,并在 6 个标准基准数据集上的结果汇总于表 6。为公平评估,所有对比方法及我们的方法均在合成数据集 MJ 和 ST 上进行训练,且结果均未采用词典基础的后处理策略。
总体来看,包含语言建模的语言感知方法(如 SRN [53]、VisionLAN [51]、ABINet [9] 和 MGP-STRFuse)普遍优于不依赖语言的纯视觉方法,说明语言信息的重要性。值得注意的是,即使不引入任何语言信息,MGP-STRVision 也已超过具备显式语言模型的 SOTA 方法 ABINet。而由于采用了多粒度预测策略,MGP-STRFuse 进一步取得了更优异的表现,平均准确率较 ABINet 提高了 0.7%。
4.7 多粒度预测的细节
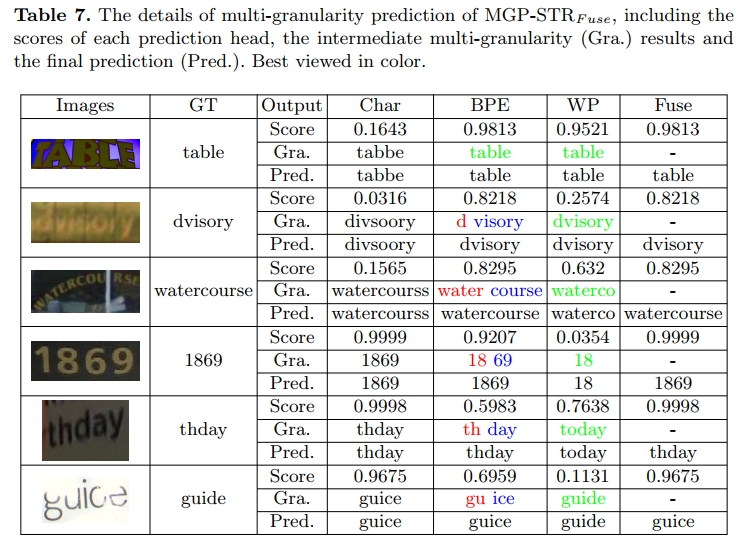
我们展示了 MGP-STRFuse 方法在 6 张标准数据集测试图像上的详细预测过程。在前三张图像中,由于不规则字体、运动模糊和文字弯曲等因素,字符级预测结果均为错误。这些图像的字符预测得分非常低,因为每张图像都有一个字符被错误识别。然而,“BPE” 和 “WP” 预测头却可以较高置信度识别出“table”图像,而在“dvisory”与“watercourse”图像中,“BPE” 可以使用两个 subword 做出正确预测,尽管“WP” 在“watercourse”中预测错误。在融合之后,这些错误被成功纠正。
从后面三张图像中还可观察到有趣的现象:“Char” 与 “BPE” 的预测与图像内容一致,而 “WP” 的预测则倾向于生成具有更强语言语义的词语,例如“today”和“guide”。一般来说,“Char” 逐字符预测;“BPE” 倾向于生成与图像对应的 n-gram 片段;而“WP” 更倾向于直接预测有语言意义的完整词汇。这说明不同粒度的预测从不同角度传达文本信息,确实具有互补性。
4.8 A3 模块空间注意力图的可视化
图 4 展示了 Character、BPE 和 WordPiece 三个 A3 模块的示例注意力图 m i m_i mi。Character 的 A3 模块在多种文本图像上表现出极为精确的定位能力。具体而言,对于仅包含一个字符的 “7” 图像,其注意力掩码呈现出类似“7”字形的结构;而对于包含三个字符的 “day” 和 “bar” 图像,中间字符 “a” 的注意力图则完全不同,这验证了 A3 模块具备良好的适应性。
如图 1(d) 和表 7 所示,BPE 更倾向于生成较短的片段,因此其注意力图往往分裂为 2 到 3 个区域,如 “leaves” 和 “academy” 图像中所示。这可能是由于在视觉任务中同时进行 subword 切分和字符定位具有挑战性所致。
此外,WordPiece 通常生成整个词汇,其对应的注意力图往往覆盖整个特征图。由于 softmax 生成的注意力图通常是稀疏的,WordPiece 的注意力图不如 Character A3 模块直观可读。
这些观察结果与表 3 中的准确率结果是一致的,即 “BPE” 和 “WP” 的准确率相对低于 “Char”,这源于精确 subword 预测的难度更高。

4.9 推理时间与模型规模的对比
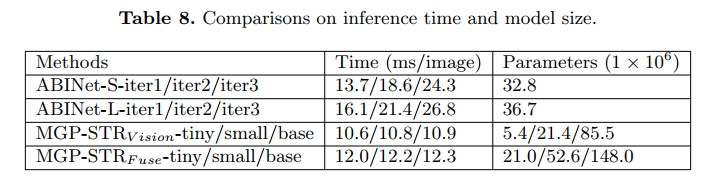
表 8 显示了所提出的 MGP-STR 在不同设置下的模型规模和推理延迟,以及 ABINet 的对比结果。由于 MGP-STR 配备了常规的 Vision Transformer(ViT),并且不涉及迭代细化,其推理速度非常快:使用 ViT-Base 主干时为 12.3 毫秒。与 ABINet 相比,MGP-STR 的推理速度更快(12.3 毫秒对比 26.8 毫秒),同时性能也更高。MGP-STR 的模型规模相对较大,但大部分参数来自于 BPE 和 WordPiece 分支。对于对模型规模敏感或内存有限的场景,MGP-STRV ision 是一个很好的选择。
5 结论
我们提出了一种基于 ViT 的纯视觉模型用于场景文本识别(STR),该模型在识别准确性方面表现出优越性。为了进一步提升该基线模型的识别准确性,我们提出了多粒度预测策略,充分利用语言知识。最终模型在广泛使用的数据集上实现了最先进的性能。未来,我们将把多粒度预测的思想扩展到更广泛的领域。
论文名称:
Multi-Granularity Prediction for Scene Text Recognition
论文地址:
https://arxiv.org/pdf/2209.03592