transformers基础组件之pipeline
主要是参考教程:【手把手带你实战HuggingFace Transformers-入门篇】基础组件之Pipeline
1. 什么是pipeline
为了更加方便的使用预训练模型,Transformers提供了pipeline函数,该函数封装了模型及对应的数据前处理与后处理工工作,无需我们关注内部细节,只需要指定pipeline的任务类型并输入对应的文本,即可得到我们想要的答案,做到了真正的开箱即用。
将数据预处理、模型调用、结果后处理三部分组装成的流水线,使我们能够直接输入文本便获得最终的答案。主要是简化代码的作用。
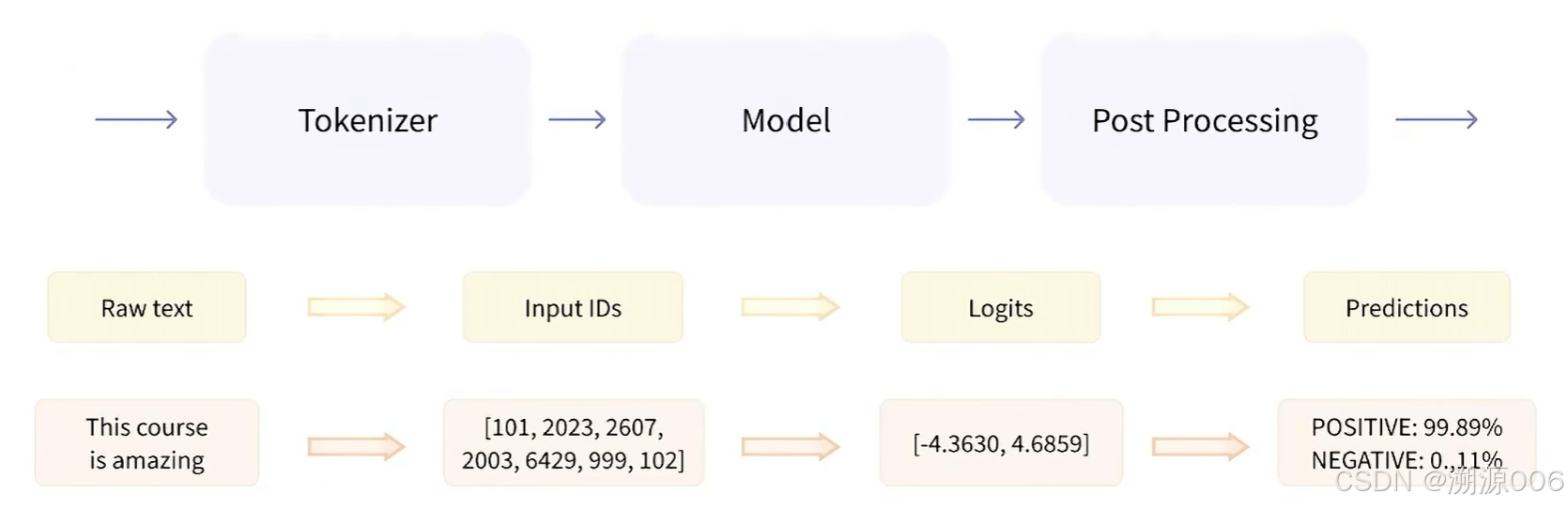
2. pipeline支持的任务类型
利用下面的代码打印pipeline支持的任务类型:
from transformers.pipelines import SUPPORTED_TASKS
for k, v in SUPPORTED_TASKS.items():print(k, v)
audio-classification {'impl': <class 'transformers.pipelines.audio_classification.AudioClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForAudioClassification'>,), 'default': {'model': {'pt': ('superb/wav2vec2-base-superb-ks', '372e048')}}, 'type': 'audio'}
automatic-speech-recognition {'impl': <class 'transformers.pipelines.automatic_speech_recognition.AutomaticSpeechRecognitionPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForCTC'>, <class 'transformers.models.auto.modeling_auto.AutoModelForSpeechSeq2Seq'>), 'default': {'model': {'pt': ('facebook/wav2vec2-base-960h', '22aad52')}}, 'type': 'multimodal'}
text-to-audio {'impl': <class 'transformers.pipelines.text_to_audio.TextToAudioPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForTextToWaveform'>, <class 'transformers.models.auto.modeling_auto.AutoModelForTextToSpectrogram'>), 'default': {'model': {'pt': ('suno/bark-small', '1dbd7a1')}}, 'type': 'text'}
feature-extraction {'impl': <class 'transformers.pipelines.feature_extraction.FeatureExtractionPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModel'>,), 'default': {'model': {'pt': ('distilbert/distilbert-base-cased', '6ea8117'), 'tf': ('distilbert/distilbert-base-cased', '6ea8117')}}, 'type': 'multimodal'}
text-classification {'impl': <class 'transformers.pipelines.text_classification.TextClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSequenceClassification'>,), 'default': {'model': {'pt': ('distilbert/distilbert-base-uncased-finetuned-sst-2-english', '714eb0f'), 'tf': ('distilbert/distilbert-base-uncased-finetuned-sst-2-english', '714eb0f')}}, 'type': 'text'}
token-classification {'impl': <class 'transformers.pipelines.token_classification.TokenClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForTokenClassification'>,), 'default': {'model': {'pt': ('dbmdz/bert-large-cased-finetuned-conll03-english', '4c53496'), 'tf': ('dbmdz/bert-large-cased-finetuned-conll03-english', '4c53496')}}, 'type': 'text'}
question-answering {'impl': <class 'transformers.pipelines.question_answering.QuestionAnsweringPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForQuestionAnswering'>,), 'default': {'model': {'pt': ('distilbert/distilbert-base-cased-distilled-squad', '564e9b5'), 'tf': ('distilbert/distilbert-base-cased-distilled-squad', '564e9b5')}}, 'type': 'text'}
table-question-answering {'impl': <class 'transformers.pipelines.table_question_answering.TableQuestionAnsweringPipeline'>, 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForTableQuestionAnswering'>,), 'tf': (), 'default': {'model': {'pt': ('google/tapas-base-finetuned-wtq', 'e3dde19'), 'tf': ('google/tapas-base-finetuned-wtq', 'e3dde19')}}, 'type': 'text'}
visual-question-answering {'impl': <class 'transformers.pipelines.visual_question_answering.VisualQuestionAnsweringPipeline'>, 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForVisualQuestionAnswering'>,), 'tf': (), 'default': {'model': {'pt': ('dandelin/vilt-b32-finetuned-vqa', 'd0a1f6a')}}, 'type': 'multimodal'}
document-question-answering {'impl': <class 'transformers.pipelines.document_question_answering.DocumentQuestionAnsweringPipeline'>, 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForDocumentQuestionAnswering'>,), 'tf': (), 'default': {'model': {'pt': ('impira/layoutlm-document-qa', 'beed3c4')}}, 'type': 'multimodal'}
fill-mask {'impl': <class 'transformers.pipelines.fill_mask.FillMaskPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForMaskedLM'>,), 'default': {'model': {'pt': ('distilbert/distilroberta-base', 'fb53ab8'), 'tf': ('distilbert/distilroberta-base', 'fb53ab8')}}, 'type': 'text'}
summarization {'impl': <class 'transformers.pipelines.text2text_generation.SummarizationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM'>,), 'default': {'model': {'pt': ('sshleifer/distilbart-cnn-12-6', 'a4f8f3e'), 'tf': ('google-t5/t5-small', 'df1b051')}}, 'type': 'text'}
translation {'impl': <class 'transformers.pipelines.text2text_generation.TranslationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM'>,), 'default': {('en', 'fr'): {'model': {'pt': ('google-t5/t5-base', 'a9723ea'), 'tf': ('google-t5/t5-base', 'a9723ea')}}, ('en', 'de'): {'model': {'pt': ('google-t5/t5-base', 'a9723ea'), 'tf': ('google-t5/t5-base', 'a9723ea')}}, ('en', 'ro'): {'model': {'pt': ('google-t5/t5-base', 'a9723ea'), 'tf': ('google-t5/t5-base', 'a9723ea')}}}, 'type': 'text'}
text2text-generation {'impl': <class 'transformers.pipelines.text2text_generation.Text2TextGenerationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSeq2SeqLM'>,), 'default': {'model': {'pt': ('google-t5/t5-base', 'a9723ea'), 'tf': ('google-t5/t5-base', 'a9723ea')}}, 'type': 'text'}
text-generation {'impl': <class 'transformers.pipelines.text_generation.TextGenerationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForCausalLM'>,), 'default': {'model': {'pt': ('openai-community/gpt2', '607a30d'), 'tf': ('openai-community/gpt2', '607a30d')}}, 'type': 'text'}
zero-shot-classification {'impl': <class 'transformers.pipelines.zero_shot_classification.ZeroShotClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForSequenceClassification'>,), 'default': {'model': {'pt': ('facebook/bart-large-mnli', 'd7645e1'), 'tf': ('FacebookAI/roberta-large-mnli', '2a8f12d')}, 'config': {'pt': ('facebook/bart-large-mnli', 'd7645e1'), 'tf': ('FacebookAI/roberta-large-mnli', '2a8f12d')}}, 'type': 'text'}
zero-shot-image-classification {'impl': <class 'transformers.pipelines.zero_shot_image_classification.ZeroShotImageClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForZeroShotImageClassification'>,), 'default': {'model': {'pt': ('openai/clip-vit-base-patch32', '3d74acf'), 'tf': ('openai/clip-vit-base-patch32', '3d74acf')}}, 'type': 'multimodal'}
zero-shot-audio-classification {'impl': <class 'transformers.pipelines.zero_shot_audio_classification.ZeroShotAudioClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModel'>,), 'default': {'model': {'pt': ('laion/clap-htsat-fused', 'cca9e28')}}, 'type': 'multimodal'}
image-classification {'impl': <class 'transformers.pipelines.image_classification.ImageClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForImageClassification'>,), 'default': {'model': {'pt': ('google/vit-base-patch16-224', '3f49326'), 'tf': ('google/vit-base-patch16-224', '3f49326')}}, 'type': 'image'}
image-feature-extraction {'impl': <class 'transformers.pipelines.image_feature_extraction.ImageFeatureExtractionPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModel'>,), 'default': {'model': {'pt': ('google/vit-base-patch16-224', '3f49326'), 'tf': ('google/vit-base-patch16-224', '3f49326')}}, 'type': 'image'}
image-segmentation {'impl': <class 'transformers.pipelines.image_segmentation.ImageSegmentationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForImageSegmentation'>, <class 'transformers.models.auto.modeling_auto.AutoModelForSemanticSegmentation'>), 'default': {'model': {'pt': ('facebook/detr-resnet-50-panoptic', 'd53b52a')}}, 'type': 'multimodal'}
image-to-text {'impl': <class 'transformers.pipelines.image_to_text.ImageToTextPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForVision2Seq'>,), 'default': {'model': {'pt': ('ydshieh/vit-gpt2-coco-en', '5bebf1e'), 'tf': ('ydshieh/vit-gpt2-coco-en', '5bebf1e')}}, 'type': 'multimodal'}
image-text-to-text {'impl': <class 'transformers.pipelines.image_text_to_text.ImageTextToTextPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForImageTextToText'>,), 'default': {'model': {'pt': ('llava-hf/llava-onevision-qwen2-0.5b-ov-hf', '2c9ba3b')}}, 'type': 'multimodal'}
object-detection {'impl': <class 'transformers.pipelines.object_detection.ObjectDetectionPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForObjectDetection'>,), 'default': {'model': {'pt': ('facebook/detr-resnet-50', '1d5f47b')}}, 'type': 'multimodal'}
zero-shot-object-detection {'impl': <class 'transformers.pipelines.zero_shot_object_detection.ZeroShotObjectDetectionPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForZeroShotObjectDetection'>,), 'default': {'model': {'pt': ('google/owlvit-base-patch32', 'cbc355f')}}, 'type': 'multimodal'}
depth-estimation {'impl': <class 'transformers.pipelines.depth_estimation.DepthEstimationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForDepthEstimation'>,), 'default': {'model': {'pt': ('Intel/dpt-large', 'bc15f29')}}, 'type': 'image'}
video-classification {'impl': <class 'transformers.pipelines.video_classification.VideoClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForVideoClassification'>,), 'default': {'model': {'pt': ('MCG-NJU/videomae-base-finetuned-kinetics', '488eb9a')}}, 'type': 'video'}
mask-generation {'impl': <class 'transformers.pipelines.mask_generation.MaskGenerationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForMaskGeneration'>,), 'default': {'model': {'pt': ('facebook/sam-vit-huge', '87aecf0')}}, 'type': 'multimodal'}
image-to-image {'impl': <class 'transformers.pipelines.image_to_image.ImageToImagePipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForImageToImage'>,), 'default': {'model': {'pt': ('caidas/swin2SR-classical-sr-x2-64', 'cee1c92')}}, 'type': 'image'}
3. Pipeline的创建与使用
3.1 根据任务类型直接创建Pipeline
from transformers import pipeline# 注意:需要魔法流量才能下载相关模型
pipe = pipeline("text-classification")
pipe("very good!")
输出结果如下:
[{'label': 'POSITIVE', 'score': 0.9998525381088257}]
3.2 指定任务类型,再指定模型,创建基于指定模型的Pipeline
上面的模型采用的是默认的模型,如果想自己指定模型怎么办呢?(比如默认的都是英文的模型,但是我们想处理中文的模型,这个时候肯定需要自己去指定模型)
3.2.1 到哪里找模型
这里就会牵扯到一个问题就是到哪里去找模型。到huggingface的官网去找就可以:
https://huggingface.co/models
找到自己想要做的任务类型,然后就可以找想要的模型了。
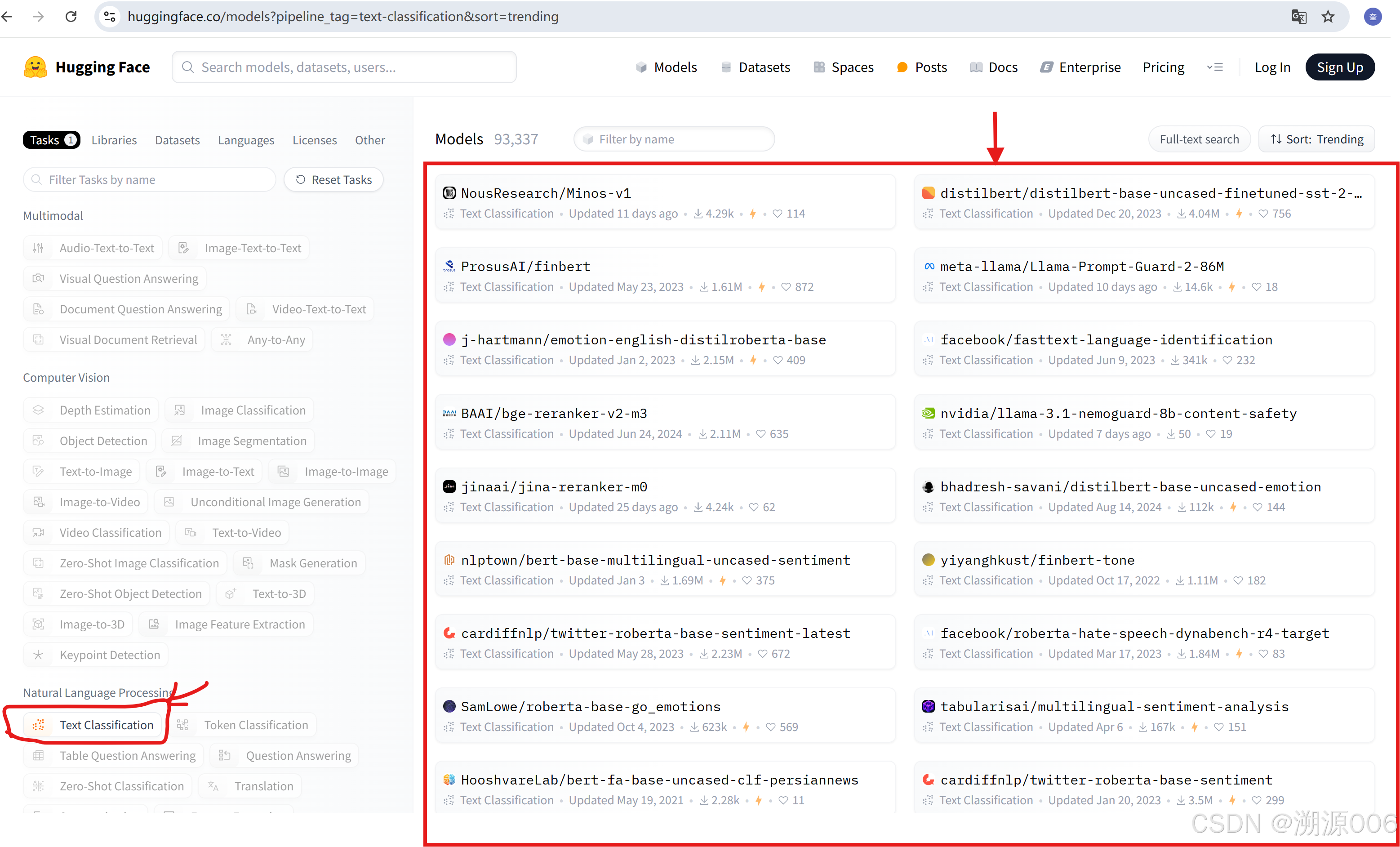
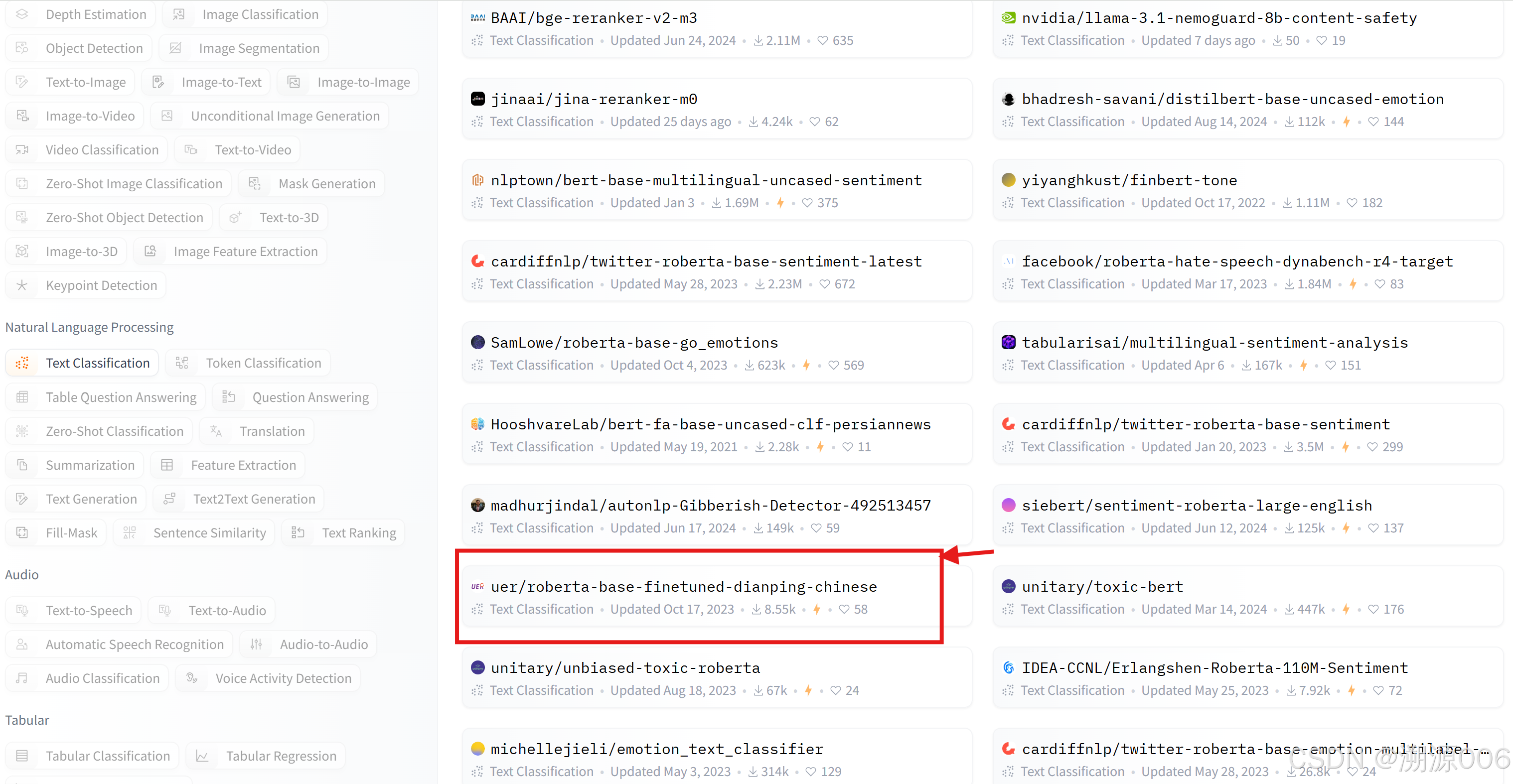
可以直接复制模型名称,赋值给pipeline的model参数,如下:
pipe = pipeline("text-classification", model="uer/roberta-base-finetuned-dianping-chinese")
如果网络和相关配置正确,就会下载模型,如果不行可以先离线下载模型到本地,然后指定本地的模型地址
# 这里因为网络问题,先离线下载【pytorch_model.bin、vocab.txt等文件】,然后加载pipe = pipeline("text-classification", model="../models/roberta-base-finetuned-dianping-chinese")pipe("我觉得不太行!") # [{'label': 'negative (stars 1, 2 and 3)', 'score': 0.9735506772994995}]
3.3 预先加载模型,再创建Pipeline
这个时候必须同时指定model和tokenizer
# 这种方式,必须同时指定model和tokenizer
from transformers import AutoModelForSequenceClassification
from transformers import AutoTokenizermodel = AutoModelForSequenceClassification.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer)pipe("我觉得不太行!")
# [{'label': 'negative (stars 1, 2 and 3)', 'score': 0.9735506772994995}]
3.4 使用GPU加速推理
刚才没有指定模型在cpu还是gpu上运行,模型会在cpu上运行。如果要指定gpu需要设置参数device=0期中0是第几个显卡(从0开始)。
# 使用GPU进行推理
pipe = pipeline("text-classification", model=model_path, device=0)print(pipe.model.device) # device(type='cuda', index=0)
##下面的代码是测试推理使用的时间
import torch
import time
times = []
for i in range(100):torch.cuda.synchronize()start = time.time()pipe("我觉得不太行!")torch.cuda.synchronize()end = time.time()times.append(end - start)
print(sum(times) / 100)
3.5 确定Pipeline的参数
不同类型的pipline可能需要输入不同的参数。到底需要哪些参数呢?比如我们现在要使用question-answering类型的pipline,首先查看他属于哪个类(QuestionAnsweringPipeline)
question-answering {'impl': <class 'transformers.pipelines.question_answering.QuestionAnsweringPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForQuestionAnswering'>,), 'default': {'model': {'pt': ('distilbert/distilbert-base-cased-distilled-squad', '564e9b5'), 'tf': ('distilbert/distilbert-base-cased-distilled-squad', '564e9b5')}}, 'type': 'text'}
然后直接进入这个类(QuestionAnsweringPipeline)的代码,可以看到该pipline的简单的使用样例。
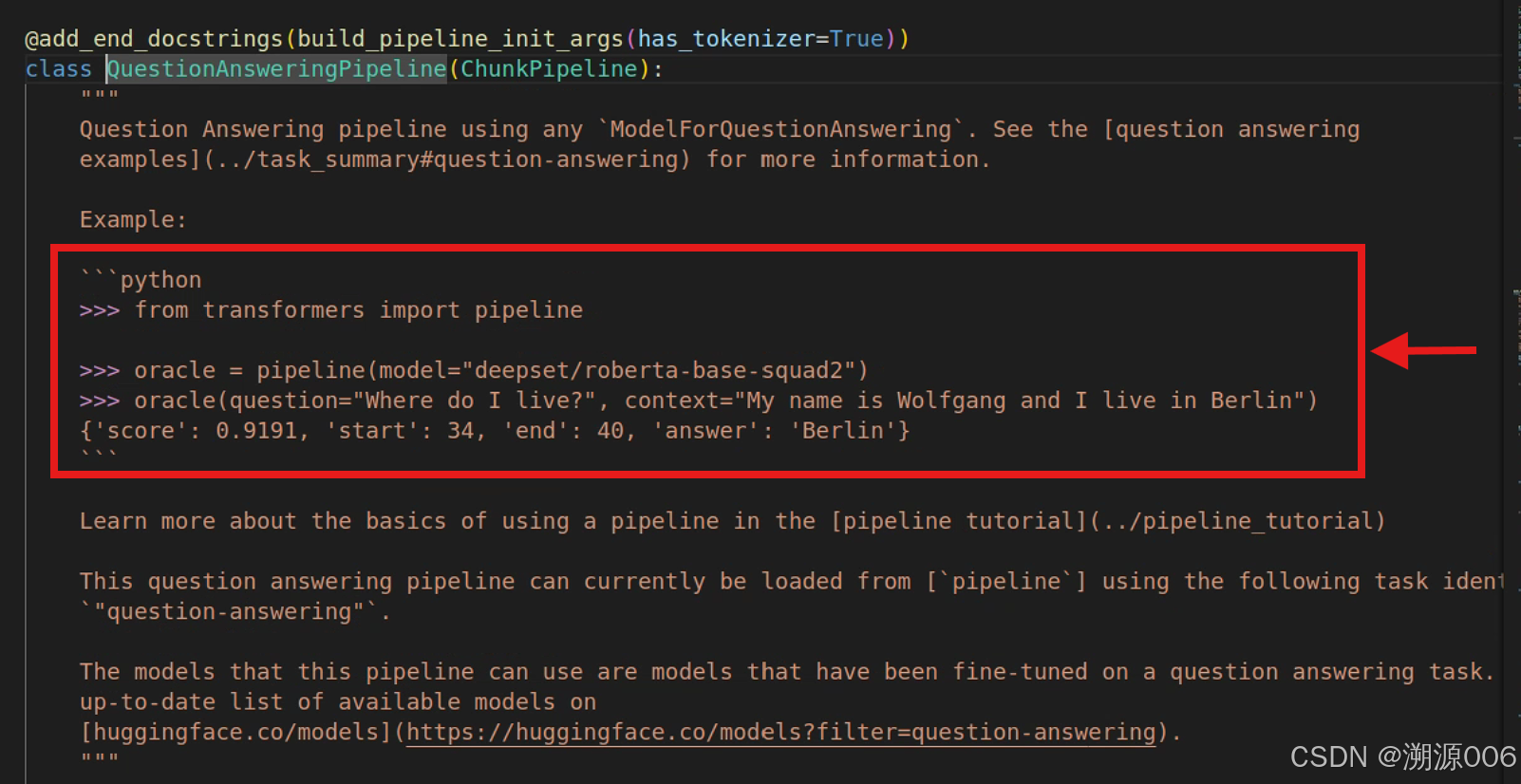
完整的参数列表需要查看 __call__方法的注解:
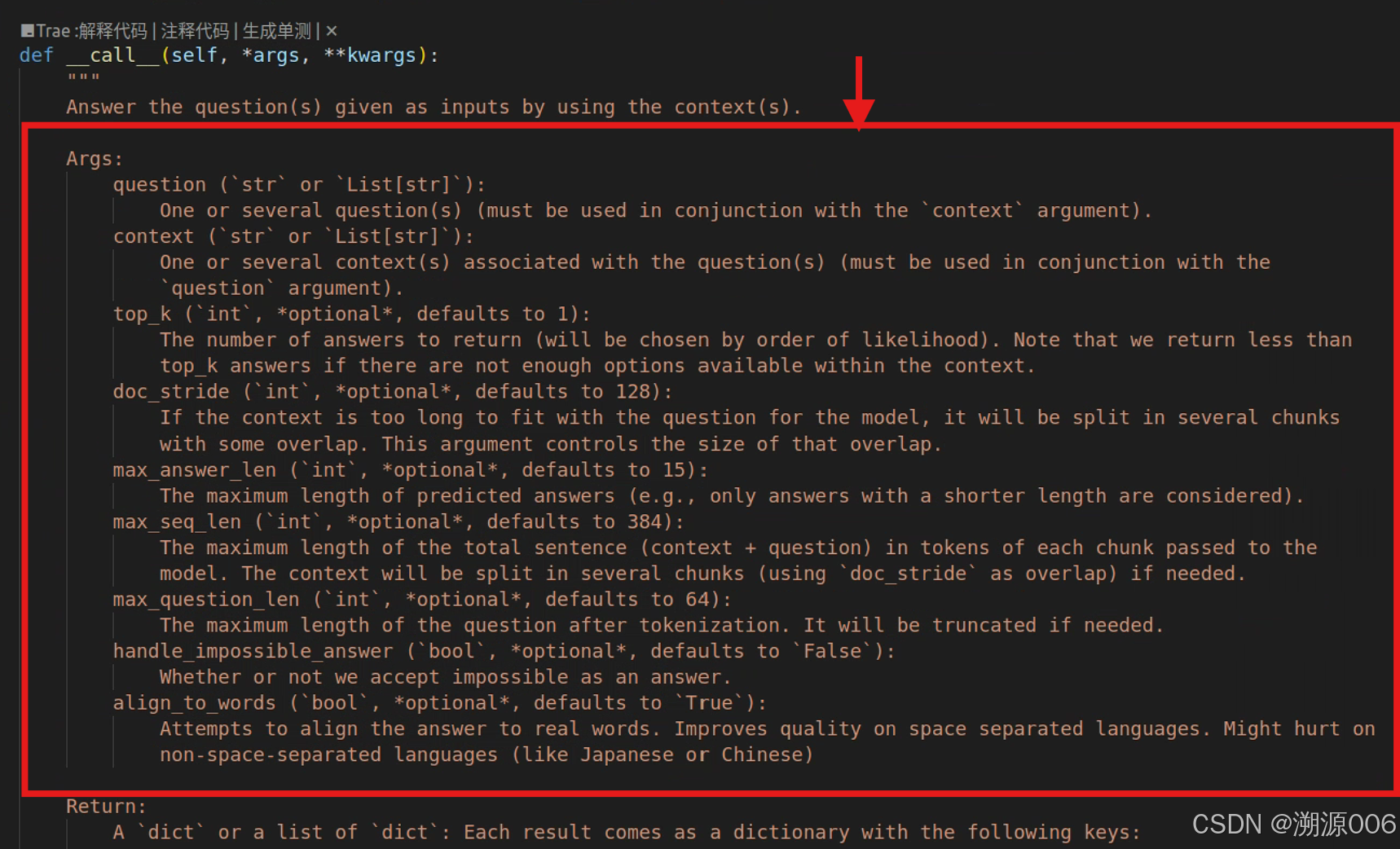
qa_pipe = pipeline("question-answering", model="uer/roberta-base-chinese-extractive-qa")
qa_pipe(question="中国的首都是哪里?", context="中国的首都是北京", max_answer_len=1)
# {'score': 0.00228740437887609, 'start': 6, 'end': 7, 'answer': '北'}
3.6 一个视觉目标检测的例子
(1)首先查看哪个任务类型可用于视觉的目标检测:zero-shot-object-detection,对应的类是:transformers.pipelines.zero_shot_object_detection.ZeroShotObjectDetectionPipeline
(2)查看使用样例和参数
def __call__(self,image: Union[str, "Image.Image", List[Dict[str, Any]]],candidate_labels: Union[str, List[str]] = None,**kwargs,):"""Detect objects (bounding boxes & classes) in the image(s) passed as inputs.Args:image (`str`, `PIL.Image` or `List[Dict[str, Any]]`):The pipeline handles three types of images:- A string containing an http url pointing to an image- A string containing a local path to an image- An image loaded in PIL directlyYou can use this parameter to send directly a list of images, or a dataset or a generator like so:```python>>> from transformers import pipeline>>> detector = pipeline(model="google/owlvit-base-patch32", task="zero-shot-object-detection")>>> detector(... [... {... "image": "http://images.cocodataset.org/val2017/000000039769.jpg",... "candidate_labels": ["cat", "couch"],... },... {... "image": "http://images.cocodataset.org/val2017/000000039769.jpg",... "candidate_labels": ["cat", "couch"],... },... ]... )[[{'score': 0.287, 'label': 'cat', 'box': {'xmin': 324, 'ymin': 20, 'xmax': 640, 'ymax': 373}}, {'score': 0.25, 'label': 'cat', 'box': {'xmin': 1, 'ymin': 55, 'xmax': 315, 'ymax': 472}}, {'score': 0.121, 'label': 'couch', 'box': {'xmin': 4, 'ymin': 0, 'xmax': 642, 'ymax': 476}}], [{'score': 0.287, 'label': 'cat', 'box': {'xmin': 324, 'ymin': 20, 'xmax': 640, 'ymax': 373}}, {'score': 0.254, 'label': 'cat', 'box': {'xmin': 1, 'ymin': 55, 'xmax': 315, 'ymax': 472}}, {'score': 0.121, 'label': 'couch', 'box': {'xmin': 4, 'ymin': 0, 'xmax': 642, 'ymax': 476}}]]```candidate_labels (`str` or `List[str]` or `List[List[str]]`):What the model should recognize in the image.threshold (`float`, *optional*, defaults to 0.1):The probability necessary to make a prediction.top_k (`int`, *optional*, defaults to None):The number of top predictions that will be returned by the pipeline. If the provided number is `None`or higher than the number of predictions available, it will default to the number of predictions.timeout (`float`, *optional*, defaults to None):The maximum time in seconds to wait for fetching images from the web. If None, no timeout is set andthe call may block forever.Return:A list of lists containing prediction results, one list per input image. Each list contains dictionarieswith the following keys:- **label** (`str`) -- Text query corresponding to the found object.- **score** (`float`) -- Score corresponding to the object (between 0 and 1).- **box** (`Dict[str,int]`) -- Bounding box of the detected object in image's original size. It is adictionary with `x_min`, `x_max`, `y_min`, `y_max` keys."""if "text_queries" in kwargs:candidate_labels = kwargs.pop("text_queries")if isinstance(image, (str, Image.Image)):inputs = {"image": image, "candidate_labels": candidate_labels}elif isinstance(image, (list, tuple)) and valid_images(image):return list(super().__call__(({"image": img, "candidate_labels": labels} for img, labels in zip(image, candidate_labels)),**kwargs,))else:"""Supports the following format- {"image": image, "candidate_labels": candidate_labels}- [{"image": image, "candidate_labels": candidate_labels}]- Generator and datasetsThis is a common pattern in other multimodal pipelines, so we support it here as well."""inputs = imageresults = super().__call__(inputs, **kwargs)return results
import requests
from PIL import Image
from PIL import ImageDrawcheckpoint = "google/owlvit-base-patch32"
detector = pipeline(model=checkpoint, task="zero-shot-object-detection")url = "https://unsplash.com/photos/oj0zeY2Ltk4/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8MTR8fHBpY25pY3xlbnwwfHx8fDE2Nzc0OTE1NDk&force=true&w=640"
im = Image.open(requests.get(url, stream=True).raw)predictions = detector(im,candidate_labels=["hat", "sunglasses", "book"])draw = ImageDraw.Draw(im)for prediction in predictions:box = prediction["box"]label = prediction["label"]score = prediction["score"]xmin, ymin, xmax, ymax = box.values()draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)draw.text((xmin, ymin), f"{label}: {round(score,2)}", fill="red")
4. pipline的背后实现

from transformers import AutoTokenizer,AutoModelForSequenceClassification
import torch# 1、词元化
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForSequenceClassification.from_pretrained(model_path)input_text = "我觉得不太行!"
inputs = tokenizer(input_text, return_tensors="pt")#{'input_ids': tensor([[ 101, 2769, 6230, 2533, 679, 1922, 6121, 8013, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1]])}# 2、加载模型,进行预测
res = model(**inputs)
#SequenceClassifierOutput(loss=None, logits=tensor([[ 1.7376, -1.8681]], grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None)
logits = res.logits
logits = torch.softmax(logits, dim=-1)
#tensor([[0.9736, 0.0264]], grad_fn=<SoftmaxBackward0>)# 3、标签映射
pred = torch.argmax(logits).item()
result = model.config.id2label.get(pred)
#'negative (stars 1, 2 and 3)'
参考:
【1】【手把手带你实战HuggingFace Transformers-入门篇】基础组件之Pipeline_哔哩哔哩_bilibili
【2】Transformers基本组件(一)快速入门Pipeline、Tokenizer、Model_transformers.pipeline-CSDN博客