右值引用的剖析
引入:为什么要有右值引用?
右值引用的存在,就是为了解决左值引用解决不了的问题!
左值引用的问题:
我们知道,左值引用在做参数和做返回值都可以提高效率;但是有时候,我们无法用左值引用返回值,比如:当函数返回对象是一个局部变量,出了函数作用域就不存在了,就不能使用左值引用返回,只能传值返回,就导致无法提高效率;这时候就需要右值引用来提高效率了!
一:左值引用和右值引用
1:左值和右值的区别
①:左值
左值概念:
int main()
{// 以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;return 0;
}如何证明这些例子就是左值?规则说左值可以取地址,那就对上述例子取地址验证!
取地址验证:
int main()
{// 以下的p、b、c、*p都是左值int* p = new int(0);int b = 1;const int c = 2;//对上面左值取地址验证cout << &p << endl;cout << &(*p) << endl;cout << &b << endl;cout << &c << endl;return 0;
}运行结果:
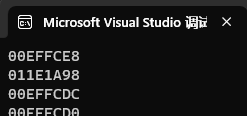
目前,取地址这个规则是通过了,继续进行规则中验证赋值:
在以下中验证赋值的时候,会知道为什么规则中会说左值一般可以赋值 因为有个例无法赋值
赋值验证:
int main()
{// 以下的p、b、c、*p都是左值int* p = new int(0);int b = 1;const int c = 2;cout << p << endl;cout << *p << endl;cout << b << endl;cout << c << endl;//对其赋值验证int k = 100;p = &k;*p = 1000;b = 30;//c = 10;cout << p << endl;cout << *p << endl;cout << b << endl;cout << c << endl;return 0;
}运行结果:
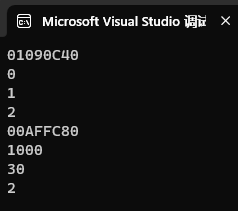
我们的确对这些左值做出了赋值,验证通过! 除了c这个左值无法赋值!
一般可以对左值进行赋值,这句话中的一般就是指的c这种static修饰的左值不可以修改(取消注释即报错),所以c我们无法赋值修改
证明了 例子中的左值的确是左值
注意: 左值也可以出现赋值符号的右边
例子:
int main()
{int b = 1;
int* p = &b;//赋值符号的左边p是左值,右边也b是左值return 0;
}②:右值
右值概念:
int main()
{
double x = 1.1, y = 2.2;// 以下几个都是常见的右值
10;
x + y;return 0;
}注意:x和y是左值,但是x+y这个表达式是右值
如何证明以上例子就是右值?规则说右值不可以取地址,那就对上述右值进行取地址验证!
int main()
{double x = 1.1, y = 2.2;10;x + y;&(10);//报错&(x + y);//报错return 0;
}报错:

目前,取地址这个规则的确报错,继续进行验证赋值查看是否报错:
int main()
{double x = 1.1, y = 2.2;10;x + y;10 = 20;//报错x + y = 20;//报错return 0;
}报错:
![]()
证明了 例子中的右值的确是右值
③:从函数返回值来看左值和右值
函数返回值也有左右值之分 之前不好一起举例子 现在单独拿出来举例子~
函数采取的是传值返回 ->则返回的是右值
函数采取的是引用返回->则返回的是左值
例子如下:
// 返回左值的函数
int& getLeftValue(int& x)
{return x; // 返回变量的引用
}// 返回右值的函数
int getRightValue(int a)
{return a; // 返回临时计算结果
}int main() {int num = 10;// 对返回左值函数进行赋值getLeftValue(num) = 20; // 返回值为左值,所以可以赋值,修改了返回的值cout << getLeftValue(num) << endl; // 输出20// 对返回左值函数进行取地址&(getLeftValue(num)); // 可以取地址cout << &(getLeftValue(num)) << endl; // 输出左值的地址// 使用右值返回函数//getRightValue(num) = 20; // 不可以赋值 报错!//&(getRightValue(num)); // 不可以取地址 报错!return 0;
}报错如下:
![]()
总结:
Q1:getRightValue函数返回的是右值,为什么?
A1:返回值是原始类型(int)的副本,是一个临时对象,取地址操作(&)需要一个持久的、可寻址的内存位置,而临时值不满足这个条件;而getLeftValue返回的是左值的引用,所以该返回值是左值,因为具有一个持久的、可寻址的内存位置
注意:getLeftValue函数的参数一定要加上引用符号,否则会返回了一个即将被销毁的局部变量的引用!这是典型的悬空引用!
//错误写法
int& getLeftValue(int x)
{ return x; // 会返回局部变量的引用!
}//正确写法
int& getLeftValue(int& x)
{ return x;
}
Q2:为什么参数不加& ,返回值也不能加&?
A2:函数参数x若只是传值接收,那其的作用域只在这个函数内,出了函数就会销毁,所以只能传值返回;与引入中的返回值即将销毁,函数只能传值返回是一样的道理 ;
而若是,引用接收,那代表其的作用域乃是整个main函数中(因为x本身就是main函数中的变量num),所以函数中的x不会出函数就销毁,所以可以引用返回!
2:左值引用和右值引用的区别
①:左值引用
左值引用很简单,我们之前学的引用全是左值引用,写法如下:
int main()
{
// 以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;// 以下几个是对上面左值的左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
return 0;
}②:右值引用
右值引用的写法,两个&即可
int main()
{
double x = 1.1, y = 2.2;
// 以下几个都是常见的右值
10;
x + y;
fmin(x, y);//一个返回右值的函数// 以下几个都是对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);return 0;
}③:二者的底层区别
先说结论:二者底层操作是几乎一致的
int main()
{int x = 10;int& a = x;//左值引用int&& b = 10;//右值引用return 0;
}查看两种引用的汇编:
//int & a = x;的汇编
007A2006 lea eax, [x] ; 将变量 x 的地址加载到 eax 寄存器
007A2009 mov dword ptr [a], eax ; 将 eax(x 的地址)存入 a(引用本质是指针)//int&& b = 10;的汇编
007A200C mov dword ptr [ebp-30h], 0Ah ; 将立即数 10 存入栈上的临时空间 [ebp-30h]
007A2013 lea eax, [ebp-30h] ; 获取临时空间的地址
007A2016 mov dword ptr [b], eax ; 将地址存入 b(引用本质仍是指针)Q:为什么说二者底层操作是几乎一致的?
A:因为区别仅在于:右值引用,是把这个数据先存储在栈上,再进行引用;而左值是直接引用本来就在栈上存储好的数据,所以说二者底层是几乎一致的
这里介绍二者的底层一致,是为后面作铺垫.....
3:互相引用
在某些写法下,左值引用能引用右值,右值引用也能引用左值~
①:左值引用去引用一个右值
int main()
{//左值引用去引用一个右值const int& r1 = 10;//int& r1 = 10;报错!return 0;
}![]()
解释:
Q1:为什么加了const的左值引用能去引用右值?
A1:我本人对于这个问题,从一开始的表面的理解,到后面深层次的理解,这里我都说一下吧
A:表面的理解:
10这个右值存放在了一个临时变量,而临时变量都具有常性(不可写),所以const让r1不可写,二者权限一致,所以加了const的左值引用能去引用右值。
B:深层次的理解:
为什么有深层次的理解,因为我觉得表面的理解,有一些漏洞:右值本身的生命周期是当前这一行代码,而左值是当前作用域,而你用左值引用去引用一个值,那这个值肯定在当前作用域都有可能被使用到,而右值又随时可能被销毁,这不是冲突了吗?所以表面的理解只能说明我理解了const让二者权限一致,但不理解为什么二者的生命周期不一致还能使用这个点!!
右值和左值的差别在于:
a:右值的生命周期只在这一行代码;而左值是当前作域
b:右值无法被修改;而左值一般可以修改(可以修改,也可能不可以修改)
所以要想用左值引用去引用一个右值,我们就要尽可能的把这个右值变成一个左值,那怎么变?
a:应该把右值的生命周期延长至和左值一致,为当前作用域
b:右值法修改不用管,因为左值也有不能修改的 也省事
如图: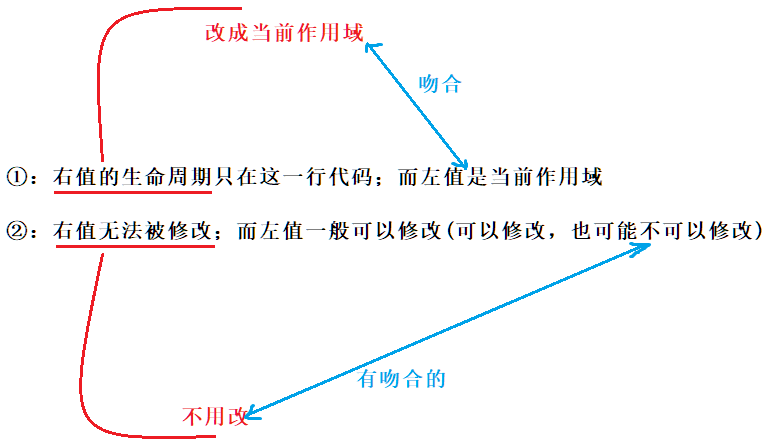
而const左值引用就可以达到要求:
a:const 左值引用绑定右值:C++ 会隐式延长右值的生命周期,使其和引用的作用域一致。
b:const本身就可以保证 r1 是无法修改的 与 右值10权限一致
所以const左值引用可以取引用一个右值了!
对不用改,右吻合这个点的理解:
之前的省事原则,是帮助理解,实则是理解不够到位的
其实这里的保持引用右值的r1无法被修改有更深层次的原因:(也就是表面理解中的权限问题)
右值10本身就是可读不可写的,根据权限原则,你用r1引用右值10,r1不可能变成可读可写,这属于权限的扩大,是非法的,会报错;所以const加上保持r1的权限和10一致,是必要的!
总结:const在左值引用中除了起到了自身的的作用(让r1不可写),还起到了延长声明周期的效果!
Q2:为什么int& r1 = 10;是非法的?
A2:理解了Q1,Q1就很好理解了!
a:你这直接引用,右值的生命周期依旧是处于当前这一行代码,可能很快被销毁
b:你没const,你让r1的权限(可读可写)相对于10的权限(可读不可写)扩大了,是错的
思考:为什么要用一个左值引用去引用右值?
其实const左值引用去引用一个右值的写法为什么会产生,本质就是当时没有右值引用,所以赋予了const左值引用能够引用右值的功能,说白了就是一种语法规则,上面剖析这么多,完全是让大家理解这种强势的语法规则的内部原理,理解语法规则的益处远大于仅仅记得语法规则!
②:右值引用去引用一个左值
例子:
int main()
{//x是左值int x = 0;//右值引用引用左值 对左值move一下即可int&& rr1 = move(x);return 0;
}![]()
解释:因为对一个左值进行了move操作后,就会变成右值,对于右值,当然可以右值引用了
二:右值引用的意义
引入中说了,有时候,我们无法用左值引用返回,比如:当函数返回对象是一个局部变量,出了函数作用域就不存在了,就不能使用左值引用返回,只能传值返回,而这种传值返回的效率不高,这就是左值返回的不足之处,当然寥寥数语,无法感受到这种不足
1:左值引用的不足
例子:(函数值返回string类的场景)
自己模拟实现一个string类,因为这样构造相关的函数被调用时会打印信息 如下:
namespace bit
{class string{public://构造函数string(const char* str = ""):_size(strlen(str)), _capacity(_size){//cout << "string(char* str)" << endl;//注释掉 是因为我们传值返回场景只看拷贝构造更好理解_str = new char[_capacity + 1];strcpy(_str, str);}// 拷贝构造string(const string& s):_str(nullptr){cout << "拷贝构造 -- 深拷贝" << endl;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}//赋值重载//s1 = s3 string& operator=(const string& s) {if (this != &s) {char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[] _str;_str = tmp;// 把容量和大小赋过去_size = s._size;_capacity = s._capacity;}cout << "赋值重载----深拷贝" << endl;return *this; // 结果返回*this}//析构~string(){delete[] _str;_str = nullptr;}private:char* _str;size_t _size;size_t _capacity; // 不包含最后做标识的\0};
}解释:我实现的构造相关的函数中,都不会牵扯到其他的函数,这样对于后面的讲解不易混淆!
在某些更优的写法中,比如赋值重载函数就会调用拷贝构造函数,这样写虽然简单好用,但是在这里相看运行结果的打印消息时容易混淆,所以要看的去这个博客的现代写法中板块中看: string类的模拟实现_string类模拟实现-CSDN博客
此时在类中进行如下测试:
//bit类中:
string test1()
{string s1;return s1;}//main中:
int main()
{bit::string s = bit::test1();return 0;
}
前提:我们屏蔽掉了普通构造函数的打印信息的语句 避免混淆
分析:
第一步:return s1,s1会拷贝构造一个临时对象(第一次调用拷贝构造函数)
第二步:bit::string s = bit::test1(); 临时对象拷贝构造给s(第二次调用拷贝构造函数)
如图:
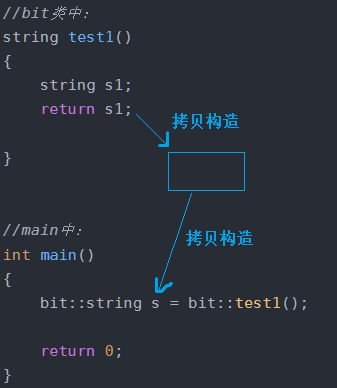
本来应该是两次拷贝构造,但是新一点的编译器(比如我用的vs19)一般都会优化,优化后变成了一次拷贝构造。
如图:
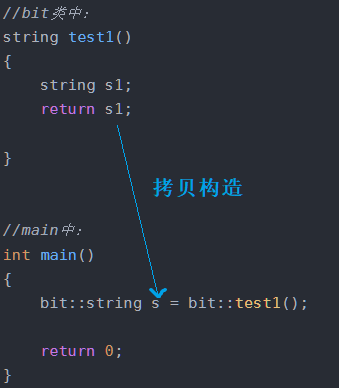
所以运行结果如下图所示:
总结:
这种场景说明了左值引用的不足,导致只能采取值返回,最终要调用两次拷贝构造,我们知道,类似string这种类的拷贝啊,赋值啊,都是深拷贝的,成本很高,所以两次的拷贝构造带来的两次深拷贝,成本极高;但是在右值引用产生之前,C++官方也做出了相应的努力:直接将连续两次的拷贝构造,优化成了一次拷贝构造,直接用s1拷贝构造出了s,但是不管怎么优化,至少都是一次深拷贝,所以C++官方决心用新的语法来彻底解决这种消耗,那就是右值拷贝
2:右值引用的意义->移动构造
既然你函数中的s1即将被销毁,而我们又想要s1中的资源,所以我们能不能不要在拷贝出一份一样的资源了,能不能直接搬运s1中的资源,反正你马上就要被销毁了
就好比,这有一份已经写完了的作业,你打算马上要烧毁了,而我又刚好需要这一份作业,你能不能别让我用一个新的本子再抄你的作业了,你直接给我呗,反正你也马上烧毁不要了
这种行为叫移动构造!
所以右值引用的思想就是,将s1的资源拷贝构造到到临时变量中(这一步没变),再把临时变量中的资源移动构造到s中(这一步变了),所以就是拷贝构造+移动构造,而后面C++官方直接优化成了移动构造!
所以现在我们要在bit::string中增加移动构造,移动构造本质是将参数右值的资源窃取过来,占位已有,那么就不用做深拷贝了,所以它叫做移动构造,就是窃取别人的资源来构造自己。
另外还要写一个交换函数,因为移动构造本身就是交换资源
代码如下:
namespace bit
{class string{public://构造函数string(const char* str = ""):_size(strlen(str)), _capacity(_size){//cout << "string(char* str)" << endl;//注释掉 是因为我们传值返回场景只看拷贝构造更好理解_str = new char[_capacity + 1];strcpy(_str, str);}// 交换函数void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 拷贝构造string(const string& s):_str(nullptr){cout << "拷贝构造 -- 深拷贝" << endl;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}//移动构造string(string&& s):_str(nullptr), _size(0), _capacity(0){cout << "移动构造" << endl;swap(s);}//赋值重载//s1 = s3 string& operator=(const string& s) {if (this != &s) {char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[] _str;_str = tmp;// 把容量和大小赋过去_size = s._size;_capacity = s._capacity;}cout << "赋值重载----深拷贝" << endl;return *this; // 结果返回*this}//析构~string(){delete[] _str;_str = nullptr;}private:char* _str;size_t _size;size_t _capacity; // 不包含最后做标识的\0};string test1(){string s1;return s1;}
}int main()
{bit::string s;s = bit::test1();return 0;
}
运行结果:

解释:符合预期,本来是要拷贝构造+移动构造,这里优化成了单独的移动构造
分析:
Q1:为什么移动构造的消耗小?
Q2:在需要构造的时候,是如何匹配到移动构造的?
移动构造代码如下:
//移动构造string(string&& s):_str(nullptr), _size(0), _capacity(0){cout << "移动构造" << endl;swap(s);}A1:从代码可知:移动构造函数中只需要调用swap函数进行资源的转移,因此调用移动构造的代价比调用拷贝构造的代价远远小的多
A2:首先是将s1的资源拷贝构造到到临时变量中,而这个临时变量就是一个右值,所以当这个临时变量想要拷贝构造出一个新的对象的时候,就会匹配到移动构造这个函数,因为移动构造的参数是右值引用,而临时变量也是一个右值,刚好参数匹配,所以调用到了移动构造
Q3:那C++官方直接优化成了一个移动构造,直接从s1移动构造到了s,但是s1不是左值吗,怎么能直接调用移动构造函数构造出s呢?左值怎么匹配到移动构造函数里面的右值类型的参数?
A3: 编译器会承受这一切!它会先把s1隐藏的move一下变成右值,然后就可以移动构造,所以我们不用手动写move了;这样做的目的是,我们不用修改原本的代码(手动move),确保了向前兼容!
总结:
移动构造就是将参数右值的资源窃取过来,占位已有,那么就不用做深拷贝了,所以它叫做移动构造,就是窃取别人的资源来构造自己。
当一个类是浅拷贝的类的时候,就没必要写移动构造了
3:右值引用的意义->移动赋值
右值引用的好处不仅仅是移动构造,在下面这种场景,右值引用也会有相应的措施进行效率提高
这种行为叫作移动赋值
namespace bit
{class string{public://构造函数string(const char* str = ""):_size(strlen(str)), _capacity(_size){//cout << "string(char* str)" << endl;//注释掉 是因为我们传值返回场景只看拷贝构造更好理解_str = new char[_capacity + 1];strcpy(_str, str);}// 交换函数void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 拷贝构造string(const string& s):_str(nullptr){cout << "拷贝构造 -- 深拷贝" << endl;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}移动构造//string(string&& s)// :_str(nullptr)// , _size(0)// , _capacity(0)//{// cout << "移动构造" << endl;// swap(s);//}//赋值重载//s1 = s3 string& operator=(const string& s) {if (this != &s) {char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[] _str;_str = tmp;// 把容量和大小赋过去_size = s._size;_capacity = s._capacity;}cout << "赋值重载----深拷贝" << endl;return *this; // 结果返回*this}//析构~string(){delete[] _str;_str = nullptr;}private:char* _str;size_t _size;size_t _capacity; // 不包含最后做标识的\0};string test1(){string s1;return s1;}
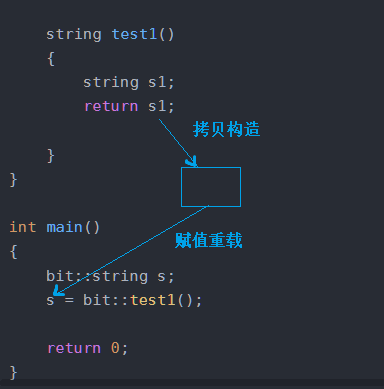
}int main()
{bit::string s;s = bit::test1();return 0;
}运行结果:(因为注释掉了移动构造)

解释如图:
而当我们把代码里面的移动构造注释放开的时候,会变成:
解释如图:(因为有了移动构造,所以第一次变成了移动构造)
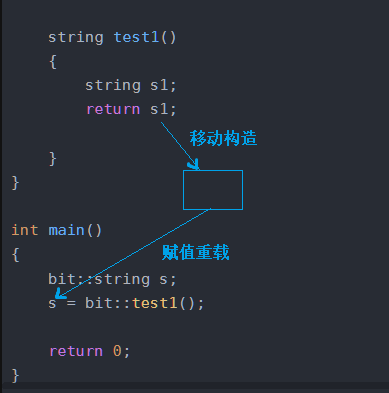
但是,尽管有了移动构造,我们的两次深拷贝(拷贝构造+赋值重载) 变成了一次深拷贝(移动构造+赋值重载),但是无论如何,都会有一次深拷贝,所以右值引用还有一个意义,那就是实现一个参数为右值的赋值重载->叫作 移动赋值
代码如下:(在string类中增加了移动赋值)
namespace bit
{class string{public://构造函数string(const char* str = ""):_size(strlen(str)), _capacity(_size){//cout << "string(char* str)" << endl;//注释掉 是因为我们传值返回场景只看拷贝构造更好理解_str = new char[_capacity + 1];strcpy(_str, str);}// 交换函数void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 拷贝构造string(const string& s):_str(nullptr){cout << "拷贝构造 -- 深拷贝" << endl;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}//移动构造string(string&& s):_str(nullptr), _size(0), _capacity(0){cout << "移动构造" << endl;swap(s);}//赋值重载//s1 = s3 string& operator=(const string& s) {if (this != &s) {char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[] _str;_str = tmp;// 把容量和大小赋过去_size = s._size;_capacity = s._capacity;}cout << "赋值重载----深拷贝" << endl;return *this; // 结果返回*this}// 移动赋值string& operator=(string&& s){cout << "移动赋值" << endl;swap(s);return *this;}//析构~string(){delete[] _str;_str = nullptr;}private:char* _str;size_t _size;size_t _capacity; // 不包含最后做标识的\0};string test1(){string s1;return s1;}
}int main()
{bit::string s;s = bit::test1();return 0;
}运行结果:
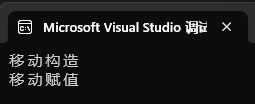
不要疑问为什么没有优化,因为像这种分开写的代码,往往都无法优化
//分开写
int main()
{bit::string s;s = bit::test1();return 0;
}//而不是
int main()
{bit::string s = bit::test1();return 0;
}关于这种优化的一些规律,我写过一篇博客,建议看看:编译器对连续构造的优化-CSDN博客
总结:
移动赋值是一个赋值运算符重载函数,该函数的参数是右值引用类型的,移动赋值也是将传入右值的资源窃取过来,占为己有,这样就避免了深拷贝,所以它叫移动赋值,就是窃取别人的资源来赋值给自己的意思。
当一个类是浅拷贝的类的时候,就也没必要写移动赋值了
4:右值引用的意义->容器的插入接口
所以当右值引用出来之后,STL中的容器除开增加了移动构造和移动赋值之外,容器的接口还都增加了右值版本
下面是几个例子:
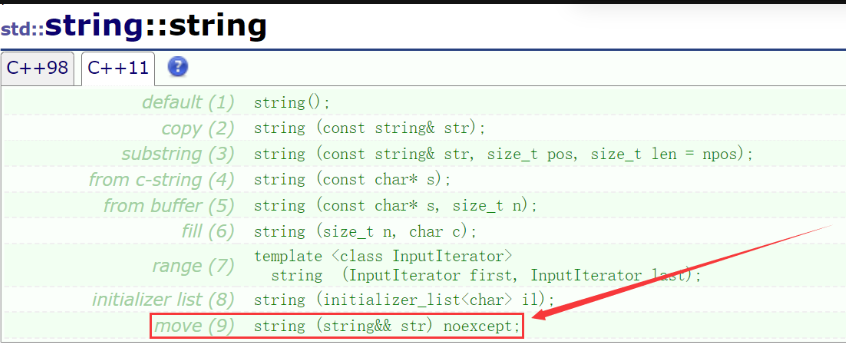
a:string类增加的移动构造:
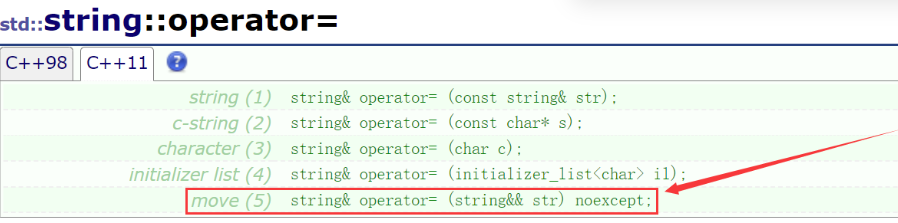
b:string类增加的移动赋值:
c:list容器的push_back接口增加了右值版本:
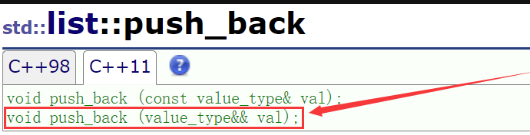
三:完美转发 forward
那现在我们想对一个模拟实现的没有右值函数接口的list,进行改造,让其也拥有右值的接口。改造如下:
1:改造list,完善右值函数接口
namespace bit
{template<class T>struct ListNode{T _data;ListNode* _next = nullptr;ListNode* _prev = nullptr;};template<class T>class list{typedef ListNode<T> node;public://构造函数list(){_head = new node;_head->_next = _head;_head->_prev = _head;}//左值引用版本的push_backvoid push_back(const T& x){insert(_head, x);}//右值引用版本的push_backvoid push_back(T&& x){insert(_head, x); //完美转发}//左值引用版本的insertvoid insert(node* pos, const T& x){node* prev = pos->_prev;node* newnode = new node;newnode->_data = x;prev->_next = newnode;newnode->_prev = prev;newnode->_next = pos;pos->_prev = newnode;}//右值引用版本的insertvoid insert(node* pos, T&& x){node* prev = pos->_prev;node* newnode = new node;newnode->_data = x; //完美转发prev->_next = newnode;newnode->_prev = prev;newnode->_next = pos;pos->_prev = newnode;}private:node* _head; //指向链表头结点的指针};
}此时在main中:
int main()
{bit::list<bit::string> lt;bit::string s("1111");lt.push_back(s); //期望在监视窗口下的调用逻辑://左值版本的push_back ----> 左值版本的insertlt.push_back("2222"); //期望在监视窗口下的调用逻辑://右值版本的push_back ----> 右值版本的insertreturn 0;
}
解释:按照我们的期望如注释所言,那真的会这样吗?
对lt.push_back(s); 进行调试监视,调用逻辑如下:
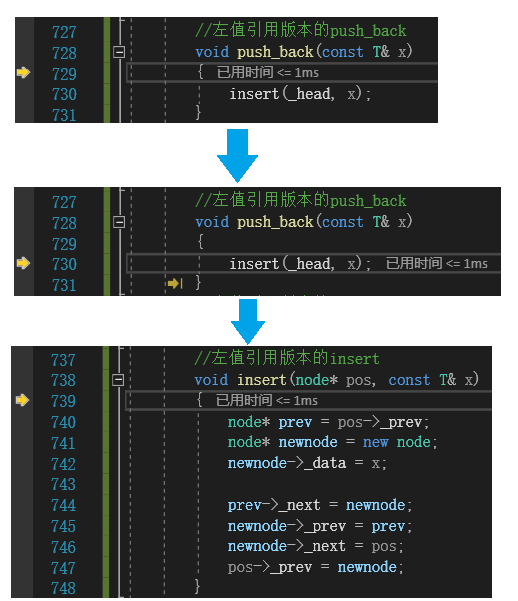
符合我们的预期,因为s是左值,所以去调用左值版本的push_back,然后在push_back的内部调用左值版本的inset,和我们预期一致
对lt.push_back("2222");的调试监视,调用逻辑如下:
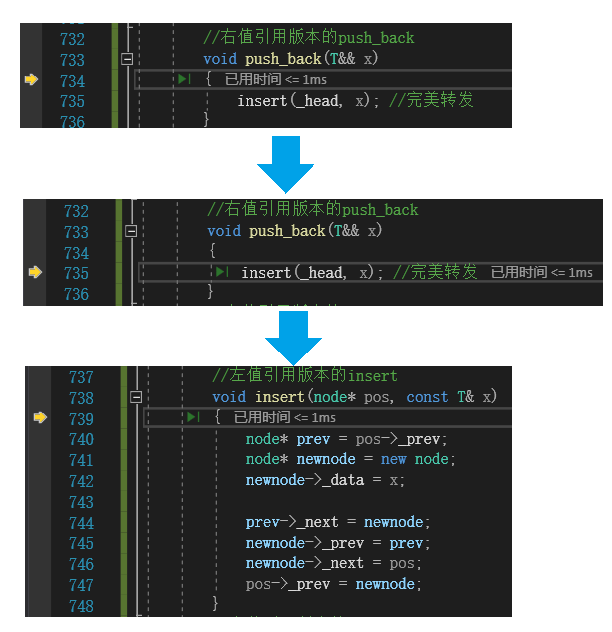
不符合预期!!因为"2222"是一个右值,应该去调用右值版本的push_back,然后在push_back的内部调用右值版本的inset,但是调试监视下来发现在进入了右值版本的 push_back后,却进入了左值版本的inset,这是为什么??
结论:右值被右值引用后,会变成左值
2:右值被右值引用后,会变成左值
其实这个疑问的点,在之前的移动构造和移动赋值中也有体现:
右值不可赋值,这是我们在前面就知道的,但是移动构造中调用swap函数的时候,你给swap函数传参数s过去,这个s是右值,而swap里面却能成功得对这个右值s和this指针指向的对象进行交换赋值?!
为什么说交换就是一种赋值,代码如下:
int main()
{int x = 1;int y = 2;//交换二者的值//交换本身就是一种赋值x = 2;y = 1;return 0;
}那请问,这为什么会被允许呢?右值不是不可以赋值吗?
正如结论所言:右值被右值引用会变成左值
例子如下:
int main()
{int&& a = 10;//10是一个右值 被右值引用之后变成了左值 所以可以赋值和取地址a = 20;int* p = &a;cout << a << endl;cout << p << endl;return 0;
}
运行结果:
并且在前文的一中的2中的③:二者的底层区别中,汇编也向我们展示了,右值引用和左值引用并未区别,右值引用的步骤:
a:只把这个右值数据先存储在栈上
因为右值一开始无地址,也就是无对应的空间去存储,所以想要引用,只能先存储在栈上
b:再对该空间进行引用
现在看来,b这一步不就是引用一个左值吗
所以这就是为什么右值被右值引用后就变成了左值!
疑问:为什么要这么设计,为什么右值被右值引用后就变成了左值
不这样设计,请问你的移动构造和移动赋值中的交换资源,如何才能进行?你是右值,永远无法完成赋值,而你变成左值后,就能完成交换资源这一步!
所以我们想要将list改造,之前的改造是不彻底的,我们还需要一个东西--->完美转发 forward
3:forward 的作用
namespace cl
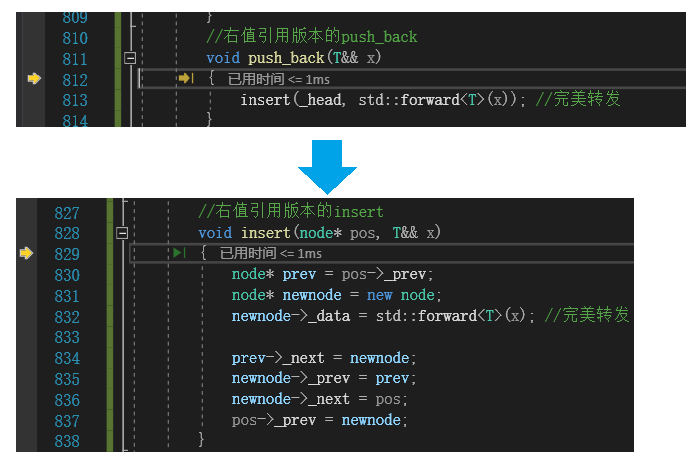
{template<class T>struct ListNode{T _data;ListNode* _next = nullptr;ListNode* _prev = nullptr;};template<class T>class list{typedef ListNode<T> node;public://构造函数list(){_head = new node;_head->_next = _head;_head->_prev = _head;}//左值引用版本的push_backvoid push_back(const T& x){insert(_head, x);}//右值引用版本的push_backvoid push_back(T&& x){insert(_head, std::forward<T>(x)); //完美转发}//左值引用版本的insertvoid insert(node* pos, const T& x){node* prev = pos->_prev;node* newnode = new node;newnode->_data = x;prev->_next = newnode;newnode->_prev = prev;newnode->_next = pos;pos->_prev = newnode;}//右值引用版本的insertvoid insert(node* pos, T&& x){node* prev = pos->_prev;node* newnode = new node;newnode->_data = std::forward<T>(x); //完美转发prev->_next = newnode;newnode->_prev = prev;newnode->_next = pos;pos->_prev = newnode;}private:node* _head; //指向链表头结点的指针};
}int main()
{cl::list<cl::string> lt;cl::string s("1111"); lt.push_back(s); //调用左值引用版本的push_backlt.push_back("2222"); //调用右值引用版本的push_backreturn 0;
}加入了forward 后的调试监视的调用逻辑:
四:默认成员函数的增加
Q:如何理解写了析构函数 、拷贝构造、拷贝赋值重载中的任何一个,就不会生成移动构造?
A:初看的确觉得这个规则很奇怪,竟然存在没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个的这种奇怪要求,但其实其中是有道理的
一般显式写了析构或拷贝构造或复制重载的,基本都是需要深拷贝的类,所以析构函数 、拷贝构造、拷贝赋值重载这三者是一体化的,一般你需要写其中一个,那么另外两个都得写 ;所以此时移动构造也是需要手动去写成深拷贝的,这就是为什么你但凡写了那三个中的其中的一个,编译器就不会生成默认的移动构造了,而是需要自己手写移动构造了!
所以根本不奇怪,因为当一个类需要写析构函数 、拷贝构造、拷贝赋值重载,这时候默认生成的移动构造是没作用的,所以C++干脆不生成了!
理解成:移动构造社恐,不敢见到析构函数 、拷贝构造、拷贝赋值重载
移动赋值类似道理不再赘述~