[白话文] 从百草园RLHF到三味书屋DPO
原创不易,特别是手打Latex简直要了命了,转载请注明出处。-- 鲁迅说的
周五看到学城有部门同事分享DPO实践,写的非常好,但总感觉有点太“学术”了,知识分享更应该考虑如何让观众接受(毕竟不是发论文),特别是DPO公式推导部分简单的一笔带过很不过瘾,所以想尝试用比较通俗易懂的白话、偏感性的描述一下我的理解。
RLHF
RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习) 是通过标准化的3个阶段,将LLM和人类偏好进行结合,其中每个阶段都建立在前一个阶段的基础上,进一步完善模型。
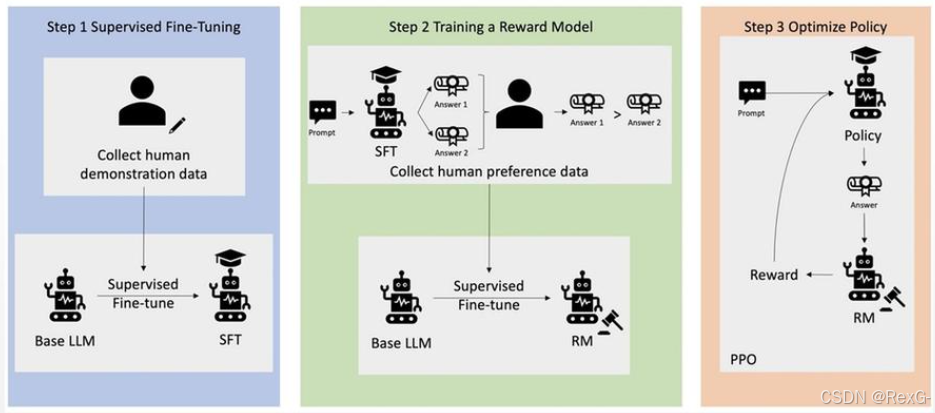
step 1:SFT
SFT(supervised fine-tuning,监督微调) 是在预训练的基座LLM模型的基础上,根据特定领域场景、使用高质量数据进行微调, 此阶段后的模型 π S F T ( y ∣ x ) \pi_{SFT(y|x)} πSFT(y∣x)已经可以很好的完成一般的任务了,只不过需要进一步改进,以更符合人类偏好。
这里有几个小点可以更好的帮助理解:
- π S F T ( y ∣ x ) \pi_{SFT(y|x)} πSFT(y∣x):指的是策略模型
policy model也就是我们目标要train的model,在输入x下生成回答y的概率,例如x是“美团的吉祥物是”, π S F T ( y ∣ x ) \pi_{SFT(y|x)} πSFT(y∣x)则是模型生成“袋鼠”的概率 - 什么是人类偏好:
human preference指的是人类对模型生成结果的主观价值判断,也就是说你行你就行,说你不行就不行,你打我撒。其实就是人为的判断回答是否有用、无害、逻辑连贯… 这是SFT无法完全覆盖的部分,也是由于SFT的局限性导致的,例如:SFT的数据肯定是有限的,无法覆盖所有场景(长尾问题比较严重),同时人类偏好通常都非常隐式、难以量化(很多都在酒里说不出来的东西)
step 2:Train RM
使用 π S F T ( y ∣ x ) \pi_{SFT(y|x)} πSFT(y∣x)模型针对每一个input生成一对儿输出 ( y 1 , y 2 ) (y_1,y_2) (y1,y2),通过人工比较这俩输出,选出觉得不错的 y w y_w yw以及拒绝的 y l y_l yl,然后用这三元组 ( x , y w , y l ) (x,y_w,y_l) (x,yw,yl)去训练一个reward model奖励模型 r ( x , y ) r(x,y) r(x,y),目的是让这个RM更符合人类偏好。
RM的loss函数可以表示为: L ( θ ) = − E ( x , y w , y l ) ∼ D [ log σ ( r θ ( x , y w ) − r θ ( x , y l ) ) ] \mathcal{L}(\theta) = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma \left( r_\theta(x, y_w) - r_\theta(x, y_l) \right) \right] L(θ)=−E(x,yw,yl)∼D[logσ(rθ(x,yw)−rθ(x,yl))]
- σ ( ⋅ ) \sigma(·) σ(⋅) :是
sigmoid函数,将数值映射到 [ 0 , 1 ] [0,1] [0,1]区间 - D \mathcal{D} D:是上面说的偏好数据集
- E \mathbb{E} E:表示对某个随机变量分布的期望值,也就是概率加权平均值
- E ( x , y w , y l ) ∼ D \mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} E(x,yw,yl)∼D:则表示对数据集 D \mathcal{D} D内的所有可能三元组 ( x , y w , y l ) (x,y_w,y_l) (x,yw,yl)计算方括号内的平均值
step 3:PPO
有了RM就可以结合RL算法,如PPO进行强化学习,对 π S F T ( y ∣ x ) \pi_{SFT(y|x)} πSFT(y∣x)进一步微调优化。
但如果只考虑最大化奖励肯定不行,模型会trick的过分偏离原模型,所以这里要加一个惩罚策略也就是KL散度,使其优化目标变成: max π θ E x ∼ D , y ∼ π θ ( y ∣ x ) [ r ϕ ( x , y ) − β D KL ( π θ ( y ∣ x ) ∥ π ref ( y ∣ x ) ) ] \max_{\pi\theta} \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_\theta(y|x)} \left[ r_{\phi}(x, y) - \beta \, \mathcal{D}_\text{KL}\left( \pi_\theta(y|x) \parallel \pi_{\text{ref}}(y|x) \right) \right] maxπθEx∼D,y∼πθ(y∣x)[rϕ(x,y)−βDKL(πθ(y∣x)∥πref(y∣x))]
其中的KL散度指的是:对偏离参考策略 π R e f \pi_{Ref} πRef(通常是 π S F T \pi_{SFT} πSFT)过远的当前策略 π θ \pi_{\theta} πθ进行惩罚,并通过超参 β \beta β控制权重。
DPO
下面开始依据我的认知,简单描述下从如何从RLHF推导到DPO(直接偏好优化,Direct Preference Optimization)的,又是如何省掉RM的
- 从
RLHF的目标函数入手: max θ E x ∼ D , y ∼ π θ ( y ∣ x ) [ r ϕ ( x , y ) − β D KL ( π θ ( y ∣ x ) ∥ π ref ( y ∣ x ) ) ] \max_{\theta} \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_\theta(y|x)} \left[ r_{\phi}(x, y) - \beta \, \mathcal{D}_\text{KL}\left( \pi_\theta(y|x) \parallel \pi_{\text{ref}}(y|x) \right) \right] maxθEx∼D,y∼πθ(y∣x)[rϕ(x,y)−βDKL(πθ(y∣x)∥πref(y∣x))] - 先看
KL散度部分,也就是: D KL ( π θ ( y ∣ x ) ∥ π ref ( y ∣ x ) ) ] \mathcal{D}_\text{KL}\left( \pi_\theta(y|x) \parallel \pi_{\text{ref}}(y|x) \right)] DKL(πθ(y∣x)∥πref(y∣x))] - 拆开
KL散度表达式: D KL ( π θ ( y ∣ x ) ∥ π ref ( y ∣ x ) ) ] = E x ∼ D , y ∼ π θ ( y ∣ x ) [ l o g π θ ( y ∣ x ) π r e f ( y ∣ x ) ] \mathcal{D}_\text{KL}\left( \pi_\theta(y|x) \parallel \pi_{\text{ref}}(y|x) \right)]= \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_\theta(y|x)} \left[ log \frac{\pi_{\theta(y|x)}}{\pi_{ref}(y|x)} \right] DKL(πθ(y∣x)∥πref(y∣x))]=Ex∼D,y∼πθ(y∣x)[logπref(y∣x)πθ(y∣x)] - 根据对数的运算性质: l o g ( P ( x ) Q ( x ) = l o g P ( x ) − l o g Q ( x ) ) log \left(\frac{P(x)}{Q(x)} = logP(x) - logQ(x) \right) log(Q(x)P(x)=logP(x)−logQ(x))得到展开的
KL散度: D KL ( π θ ( y ∣ x ) ∥ π ref ( y ∣ x ) ) ] = E x ∼ D , y ∼ π θ ( y ∣ x ) [ l o g π θ ( y ∣ x ) − l o g r e f ( y ∣ x ) ] \mathcal{D}_\text{KL}\left( \pi_\theta(y|x) \parallel \pi_{\text{ref}}(y|x) \right)]= \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_\theta(y|x)} \left[ log\pi_{\theta}(y|x) - log_{ref}(y|x) \right] DKL(πθ(y∣x)∥πref(y∣x))]=Ex∼D,y∼πθ(y∣x)[logπθ(y∣x)−logref(y∣x)] - 带入
PPO的优化目标: max π θ E x ∼ D , y ∼ π θ ( y ∣ x ) [ r ϕ ( x , y ) − β D KL ( π θ ( y ∣ x ) ∥ π ref ( y ∣ x ) ) ] \max_{\pi\theta} \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_\theta(y|x)} \left[ r_{\phi}(x, y) - \beta \, \mathcal{D}_\text{KL}\left( \pi_\theta(y|x) \parallel \pi_{\text{ref}}(y|x) \right) \right] maxπθEx∼D,y∼πθ(y∣x)[rϕ(x,y)−βDKL(πθ(y∣x)∥πref(y∣x))] - 得到: max π θ E x ∼ D , y ∼ π θ ( y ∣ x ) [ r ϕ ( x , y ) − β ( l o g π θ ( y ∣ x ) − l o g r e f ( y ∣ x ) ) ] \max_{\pi\theta} \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_\theta(y|x)} \left[ r_{\phi}(x, y) - \beta (log\pi_{\theta}(y|x) - log_{ref}(y|x) ) \right] maxπθEx∼D,y∼πθ(y∣x)[rϕ(x,y)−β(logπθ(y∣x)−logref(y∣x))]
- 将最大化优化目标,转化为最小化: min π θ E x ∼ D , y ∼ π θ ( y ∣ x ) [ l o g π θ ( y ∣ x ) − l o g π r e f ( y ∣ x ) − r ( x , y ) β ] \min_{\pi_\theta} \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_\theta(y|x)} \left[ log\pi_{\theta}(y|x) - log\pi_{ref}(y|x) - \frac{r(x,y)}{\beta} \right] minπθEx∼D,y∼πθ(y∣x)[logπθ(y∣x)−logπref(y∣x)−βr(x,y)]
- 通过
拉格朗日函数并令导数为0,可以得到 π θ ( y ∣ x ) \pi_{\theta}(y|x) πθ(y∣x)的最优解: π r e f ( y ∣ x ) e x p ( r ( x . y ) β ) \pi_{ref}(y|x)exp \left( \frac{r(x.y)}{\beta} \right) πref(y∣x)exp(βr(x.y)) 这一步就不展开了,拉格朗日这玩意不学也罢 - 然后通过
归一化确保概率在[0,1]之间,将上式除以归一化因子Z ( x ) Z(x) Z(x),得到: π θ ( y ∣ x ) = 1 Z ( x ) π r e f ( y ∣ x ) e x p ( r ( x . y ) β ) \pi_{\theta}(y|x) = \frac{1}{Z(x)} \pi_{ref}(y|x)exp \left( \frac{r(x.y)}{\beta} \right) πθ(y∣x)=Z(x)1πref(y∣x)exp(βr(x.y)) - 通过上式反解,得到奖励函数
RM为: r ( x , y ) = β l o g π θ ( y ∣ x ) π r e f ( y ∣ x ) + β l o g Z ( x ) r(x,y)=\beta log \frac{\pi_{\theta}(y|x)}{\pi_{ref}(y|x)} +\beta logZ(x) r(x,y)=βlogπref(y∣x)πθ(y∣x)+βlogZ(x) - 关键的来了,
DPO的核心思想就是通过成对儿的偏好数据来进行优化,它采用了Bradley_Treey模型为偏好分配概率 - 根据
Bradley_Treey模型,对于接受的输出 y w y_w yw和拒绝的输出 y l y_l yl的概率是: P ( y w ≻ y l ∣ x ) = P ( y w 击败 y l ) = σ ( r ( x , y w ) − r ( x , y l ) ) P(y_w \succ y_l \mid x) = P(y_w击败y_l)= \sigma(r(x,y_w) - r(x,y_l)) P(yw≻yl∣x)=P(yw击败yl)=σ(r(x,yw)−r(x,yl)) - 注意:从第10步得到的
RM得知,此时两个RM相减就会约掉 Z ( x ) Z(x) Z(x) - 此时再把
RM带入偏好概率以及sigmoid函数,得到 P ( y w ≻ y l ∣ x ) = P ( y w 击败 y l ) = 1 1 + e x p ( β l o g π θ ( y r ∣ x ) π r e f ( y r ∣ x ) − β l o g π θ ( y w ∣ x ) π r e f ( y w ∣ x ) ) P(y_w \succ y_l \mid x) = P(y_w击败y_l)=\frac{1}{1 + exp\left( \beta log\frac{\pi_{\theta}(y_r|x)}{\pi_{ref}(y_r|x)} - \beta log \frac{\pi_{\theta}(y_w|x)}{\pi_{ref}(y_w|x)} \right)} P(yw≻yl∣x)=P(yw击败yl)=1+exp(βlogπref(yr∣x)πθ(yr∣x)−βlogπref(yw∣x)πθ(yw∣x))1 - 此时再回到目标,对于偏好数据集 D = ( x , y w , y l ) \mathcal{D}={(x,y_w,y_l)} D=(x,yw,yl),目标是最大化所有偏好对儿的联合概率,也就是最大化上面值的sum ∑ \sum ∑
- 有了最大化目标,就可以通过
对数似然估计得到DPO的最终loss函数: L DPO ( θ ) = − E ( x , y win , y lose ) ∼ D [ log σ ( β ( log π θ ( y win ∣ x ) π ref ( y win ∣ x ) − log π θ ( y lose ∣ x ) π ref ( y lose ∣ x ) ) ) ] \mathcal{L}_{\text{DPO}}(\theta) = -\mathbb{E}_{(x,y_{\text{win}},y_{\text{lose}})\sim\mathcal{D}} \left[ \log \sigma \left( \beta \left( \log\frac{\pi_\theta(y_{\text{win}}|x)}{\pi_{\text{ref}}(y_{\text{win}}|x)} - \log\frac{\pi_\theta(y_{\text{lose}}|x)}{\pi_{\text{ref}}(y_{\text{lose}}|x)} \right) \right) \right] LDPO(θ)=−E(x,ywin,ylose)∼D[logσ(β(logπref(ywin∣x)πθ(ywin∣x)−logπref(ylose∣x)πθ(ylose∣x)))] - 有了
loss函数,就可以训练模型,生成更符合 y w y_w yw的结果了
所以,通过数学推导转换,将RLHF转化成DPO,避免了训练奖励模型的开销,既简化了训练流程,降低了训练的复杂度,又实现了模型输出符合人类偏好的目的。