高精度之加减乘除之多解总结(加与减篇)
开篇总述:精度计算的教学比较杂乱,无系统的学习,且存在同法多线的方式进行同一种运算,所以我写此篇的目的只是为了直指本质,不走教科书方式,步骤冗杂。
一,加法
我在此讲两种方法:
1,首先科普常识:

length()和size()函数不可统计字符型数组大小;sizeof返回的是总数组
2,为什么字符型数组可以直接接收输入而不用索引接收
原因:数组名的隐式转换规则 和 输入函数的设计机制
(1)数组名的隐式转化:
在代码中直接使用字符型数组组名,它会 自动退化为指向数组首元素的指针。

s1 作为指针传递了数组的起始内存地址,输入函数(如 scanf)会从该地址开始 连续写入字符,直到遇到终止符(如空格、换行或字符串结束符 \0)
(2)输入函数工作机制:
以 scanf("%s", s1) 为例:
- 按格式读取:
%s表示按字符串格式读取输入。 - 连续内存写入:
- 从
s1的起始地址开始,逐个写入字符到s1[0],s1[1],s1[2]... - 自动在末尾添加
\0终止符(因此数组长度需足够大)
- 从
3,为什么其他数组不能一次输入连续读入
- 字符数组的特殊性:
- 字符串本质是 连续的字符序列,天然适合用指针连续操作。
- 输入函数(如
scanf)专门为字符串设计了%s格式符。
- 其他类型数组:
- 例如
int a[505],每个元素可能需不同格式(如%d),无法统一连续处理。 - 必须显式指定索引或指针偏移
- 例如
好了,基础知识已经掌握了,让我们直接看代码吧。
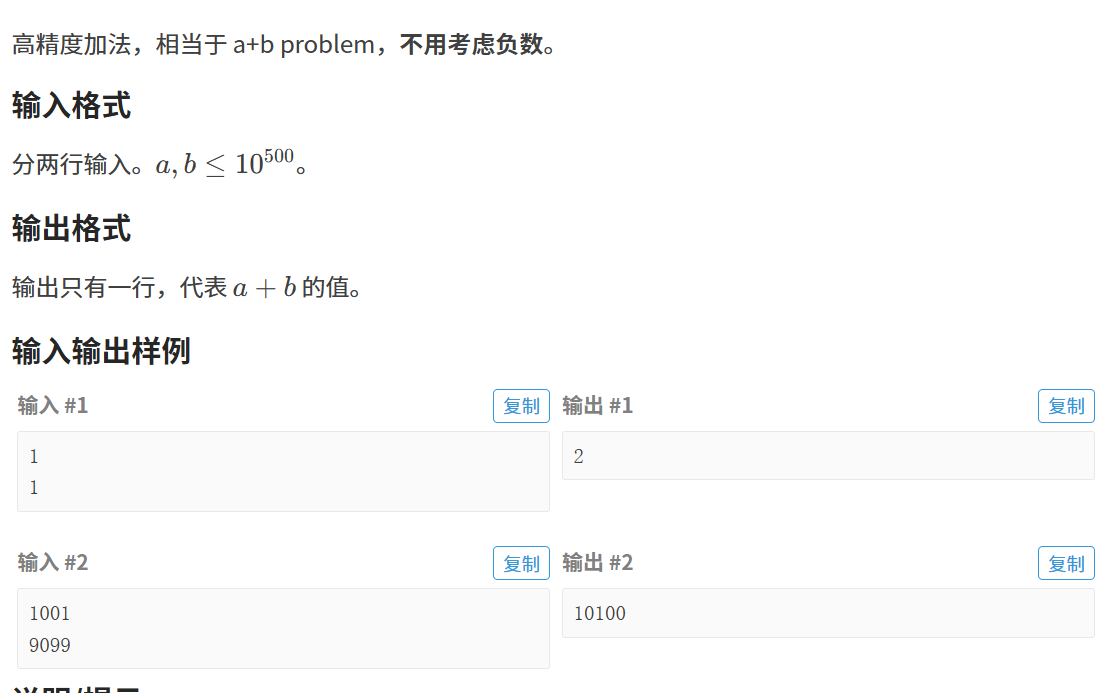
法一:
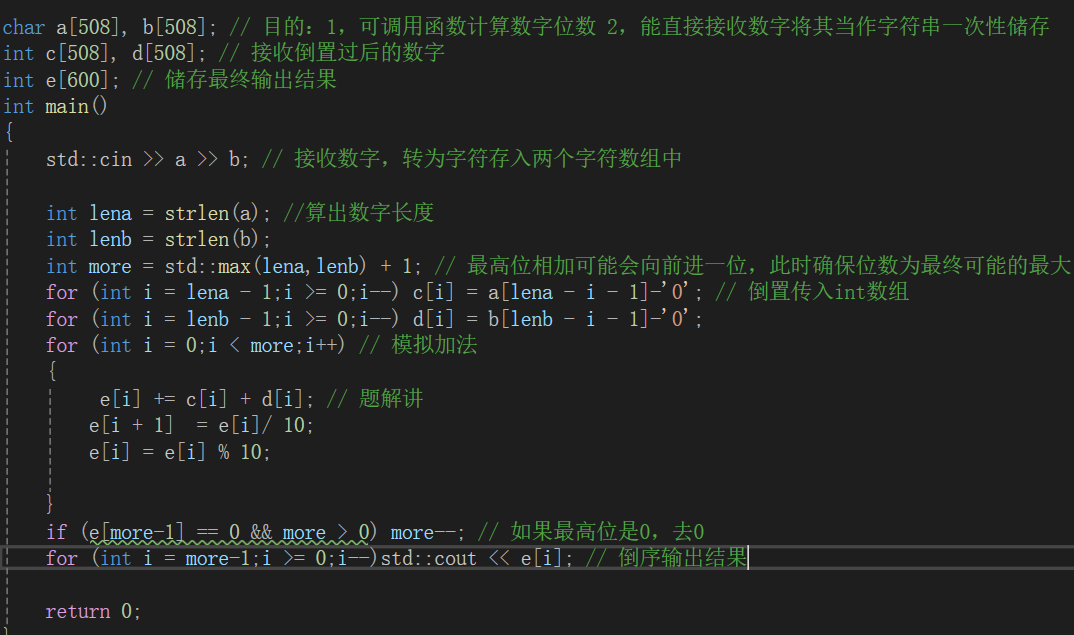
倒置是因为加法是从后往前加的,所以倒置过来在代码里从前往后加模拟,只是换了方向。
此时里面的加法模拟, 我们先不看加号就是这样,e[i] = c[i] + d[i],e数组统计数字总和,每个位数上的数字相加,此时会出现加后为两位数,此时要往后进一位 ,所以有 e[i + 1] = e[i]/ 10;
而原来的位数上保留个位上的数字 所以有 e[i] = e[i] % 10; 但之后进入下一次循环,开始加下一个位数,此时会出现一种情况,在前一位的加法里面,如果有进位发生到此处怎么把进位的数加上,所以此时有了 e[i] += c[i] + d[i] 将之前的进位的情况数字加上。
法二:

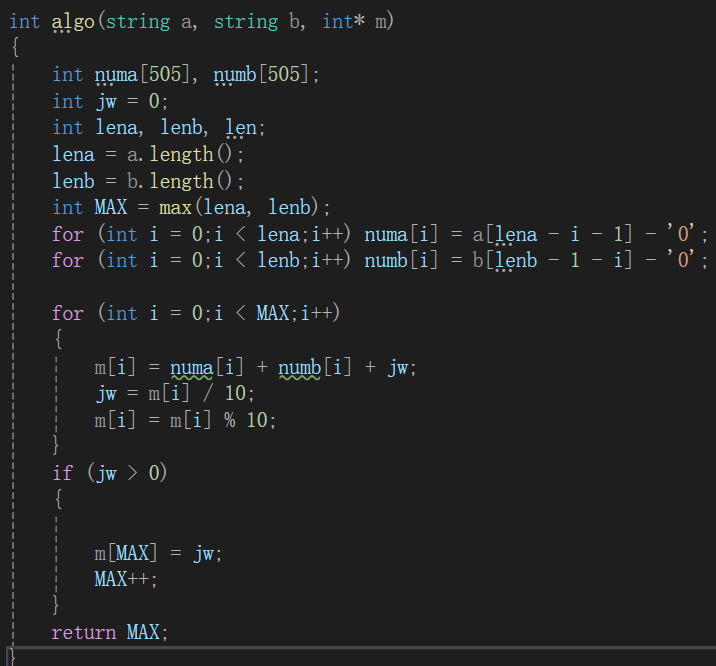
只是进位的方式发生改变,此时jw单独设成一个变量,如果前面有jw,在下一次循环加上。
之后循环完毕,看是否还有进位,若还有则总位数加1,将jw变量设在开头代表进位的数字,m数组在函数里面就已经将结果输入完毕,最后只需要传入位数。
最后返回的是运算完成后数字的位数
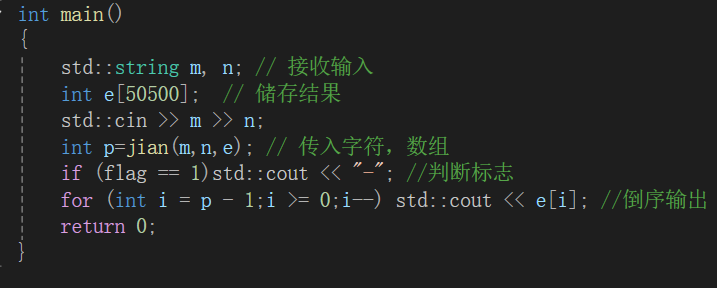
二,减法
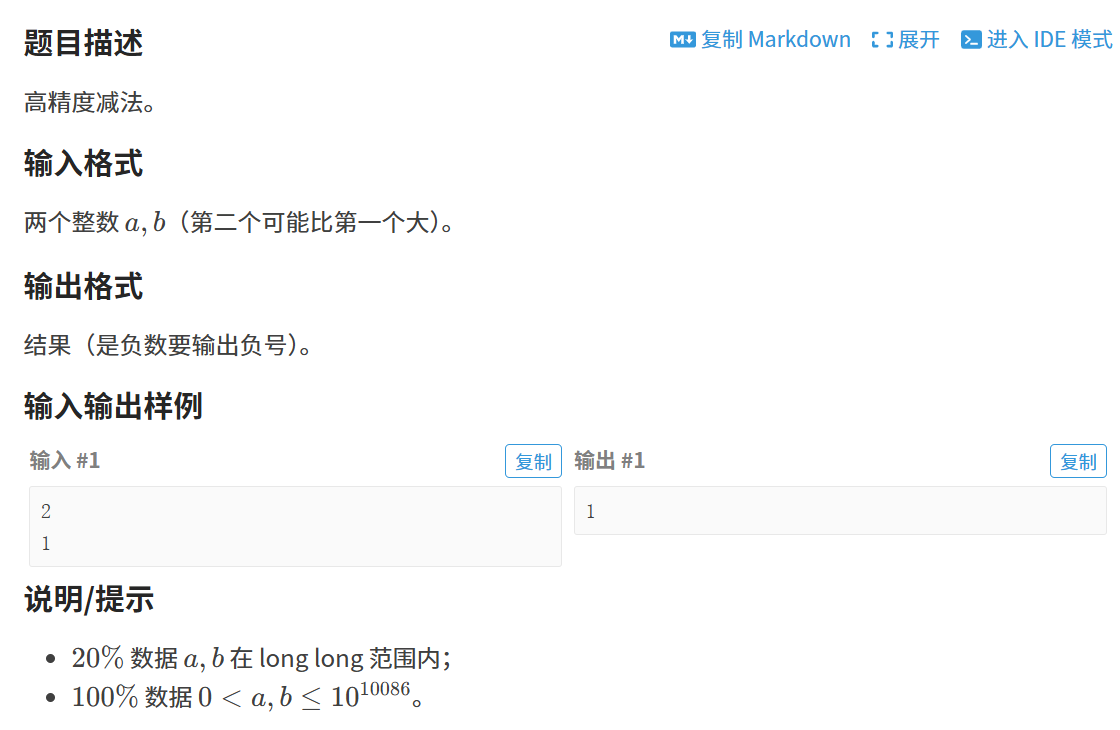
注意:此题重在分析:
1,减是两个数字相减,此时如果第一个数比第二个大,则可以安全相减,若比第二个小,则需要添负号,再把两数反过来相减,这就涉及到数学知识,两个数若相减,前一个数比后一个数小,则它们最后的结果相当于后面大的数减前面小的数,再在前面添负号。
2,而此时,就需要设置一个布尔类型判断两数谁小了。
原题解如下:
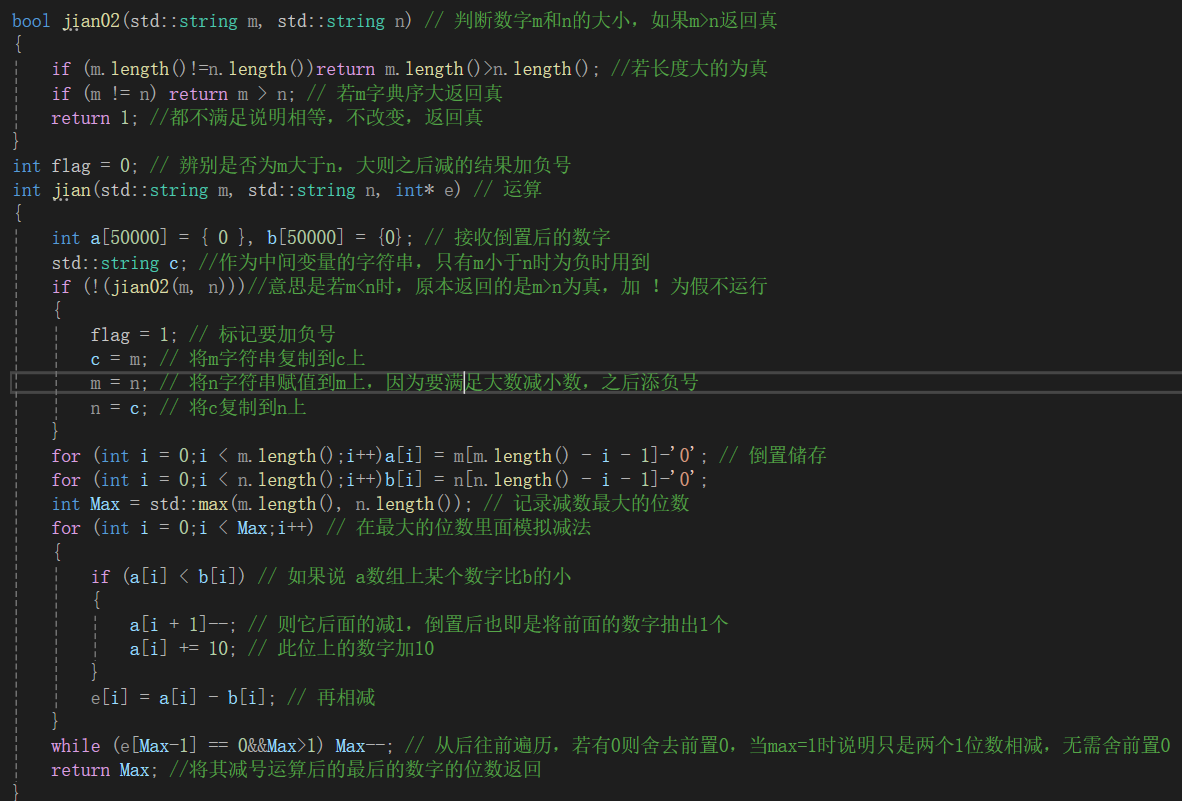
此时涉及到字符串的知识
字典序:
字符串比较规则。
字典序的核心规则(以 m > n 为例):
m 和 n 都是字符串,但怎么比较大小
-
从左到右逐字符比较
比较m和n的第一个字符:- 如果
m[0]的ASCII码 大于n[0]→ 直接判定m > n为true。 - 如果 小于 → 判定为
false。 - 如果 相等 → 继续比较下一个字符。
- 如果
-
若所有字符均相同
- 较长的字符串更大(例如
"hello" > "hell")。 - 长度和内容完全相同时 →
m > n为false。
- 较长的字符串更大(例如
比较的是字符串里面每个字符的ASCLL编码。
m > n ,此为逐个逐个比较字符串里面逐个的字符编码,看谁先出现大的数,
但是思考 "100"和"99"这类情况,则反而判断出后面比前面大,那该怎么克服呢,只需要按我题解一样先判断长短就行。
ok,结束,下期的事我们下期再聊。