C++修炼:stack和queue
Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路!
我的博客:<但凡.
我的专栏:《编程之路》、《数据结构与算法之美》、《题海拾贝》、《C++修炼之路》
欢迎点赞,关注!

目录
1、stack和queue的使用
1.1、stack
1.2、queue
2、stack和queue的模拟实现
2.1、容器适配器
2.2、模拟实现
3、list,vector,deque的对比
3.1、list和vector对比
3.2、缓存命中率
3.3、deque
1、stack和queue的使用
1.1、stack
栈这个数据结构相信大家都不陌生了,在这我就不过多介绍了,我们直接使用stl中的栈进行一些基础操作。
#include<iostream>
#include<stack>
using namespace std;
int main()
{stack<int> st;st.push(1);//插入操作st.push(2);st.push(3);st.push(4);st.push(5);st.push(6);st.push(7);while (st.size()){cout << st.top() <<" ";//取栈顶操作st.pop();}
}stack的接口很少,并且stack不支持迭代器。以上操作输出结果为7 6 5 4 3 2 1。
1.2、queue
队列这个结构我们也很熟悉了,这里的queue和stack一样也不支持迭代器访问,并且接口也很少。我们拿和上面一样的方法来使用一下。
#include<iostream>
#include<queue>
using namespace std;
int main()
{queue<int> q;q.push(1);//插入操作q.push(2);q.push(3);q.push(4);q.push(5);q.push(6);q.push(7);while (q.size()){cout << q.front() << " ";//输出队头q.pop();}cout << endl;q.push(1);cout << q.back() << endl;//支持输出队尾
}输出结果:

2、stack和queue的模拟实现
2.1、容器适配器
现在我们进入第二个阶段模拟实现。我们前两篇list和vector都用了很大的篇幅去模拟实现,但是stack和queue就很简单了。因为我们可以用到一个叫 容器适配器 的东西来帮助我们。
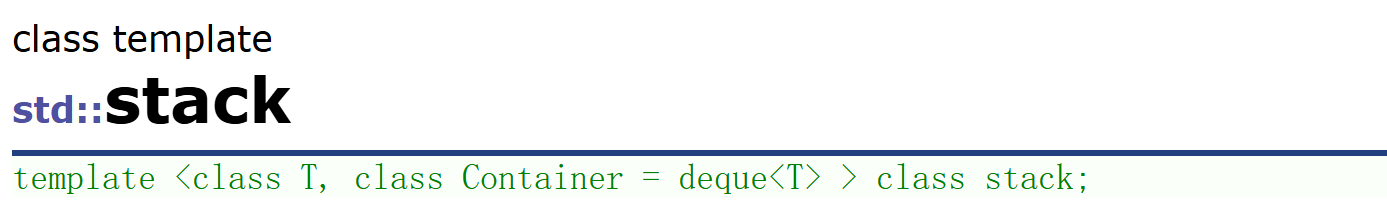
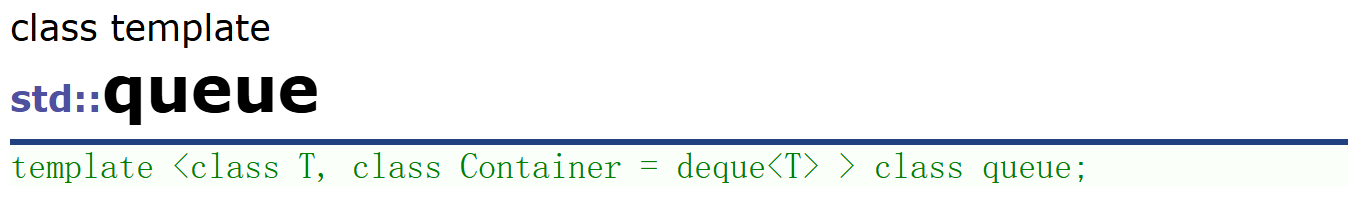
我们注意到STL底层在实现这两个数据结构的时候用了一个叫Container(容器适配器)的东西。
在 C++ 标准模板库(STL)中,容器适配器(Container Adaptor) 是一种特殊的容器,它们基于现有的 STL 容器(如 std::deque、std::list 或 std::vector)进行封装,所以本质上是一种复用,就像我们之前在模拟实现string里面部分接口是复用了memcpy,memset这种库里已经写好的函数。只不过这回我们复用的不是函数了而是一个容器,一个写好的数据结构。
使用容器适配器的结构不能通过迭代器访问,因为这样可能会破坏这个容器的使用规则,比如栈要求后进先出,而queue要求先进先出。虽然不能用迭代器但是我们可以更换底层容器(deque,vector,list等)。
现在我们来模拟实现以下stack和queue。
2.2、模拟实现
模拟实现stack:
template<class T,class con=deque<T>>
class stack
{
public:stack(){}void push(const T& x){_c.push_back(x);}void pop(){_c.pop_back();}T& top(){return _c.back();}const T& top() const{return _c.back();}size_t size() const{return _c.size();}bool empty() const{return _c.empty();}
private:con _c;//默认调用deque的构造
};模拟实现queue:
template<class T,class con=deque<T>>
class queue
{
public:queue(){}void push(const T& x) {_c.push_back(x);}void pop() {_c.pop_front();}T& back() { return _c.back(); }const T& back() const { return _c.back(); }T& front() { return _c.front(); }const T& front() const { return _c.front(); }size_t size() {return _c.size();}bool empty() const{return _c.empty;}
private:con _c;
};我们可以用刚开始写的代码测试一下他们的逻辑发现没有问题,符合栈和队列的使用规范。
我们同样可以把适配器换成vector和list,其他不用改变。在这里我就不再演示了。
那现在就有一个问题,list,deque,vector这三种容器作为适配器有什么区别呢?到底哪个更好呢?
3、list,vector,deque的对比
3.1、list和vector对比
我们先来看list和vector,这两个容器的特点可以说是两个极端或者说是两个对立。
list的优点是插入,删除效率高,任意位置插入删除时间复杂度都是O(1)级别。
并且空间利用率高,节点都是按需申请,按需释放的。
而vector的与list相比在这两方面都是劣势,缺点。vector头插和头删需要挪动数据,效率低下。并且存在扩容浪费空间的问题。比如说我们申请二十个空间,但实际上我们只插入一个元素。
那vector有什么优点呢?首先它支持迭代器随机访问,而list是不支持迭代器随机访问的。当然了这一点也不是那么重要因为做适配器根本就不能用迭代器访问。
第二点非常重要也是大家以前可能从来没听说过的,vector的cpu高速缓冲命中率高,而list的cpu高速缓存命中率低。
什么是cpu高速缓存命中率呢?我们展开解释一下。
3.2、缓存命中率
我们先来补充一点作为程序员,应该知道的有关cpu的“常识”。
我们的cpu现在基本都有三级缓存(L3,L2,L1),当然较老的cpu只有两级缓存(L2,L1),他们的访问速度L3>L2>L1,在这之后还有内存,硬盘。当然了硬盘的访问速度就很慢了。我们的数据从内存,先到L3,再到L2,再到L1,然后到寄存器中进行cpu计算。
数据的距离cpu核心越来越近、因为L1,L2分布在cpu的每一个核中,而L3是所有cpu核共有的内存。
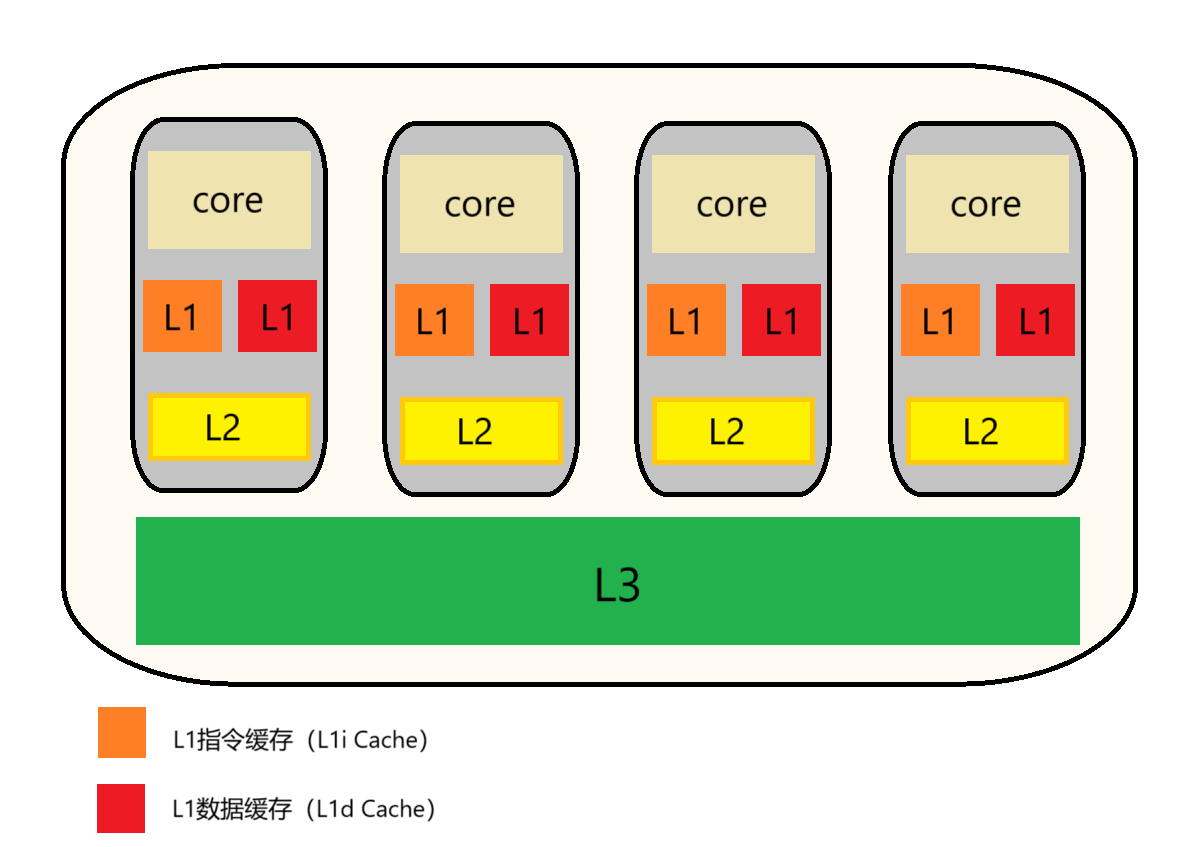
注:上图展示的是一个4核CPU的缓存结构示例,而现代主流CPU通常配备6-16个物理核心,服务器级CPU甚至可达128核。随着核心数量增加,实际缓存架构会存在些许差异。
那我们数据是通过什么一层一层的往上走的呢?首先明确一点他不是一个字节一个字节加载向上走的,而是一块一块的向上走的。什么意思?我们打个比方。我们在写文章的时候,如果想引用什么名人名言可以去百度上搜索,比如我搜索出了一段鲁迅说过的话,想把他复制到我的文章中,我肯定不是一个字一个字的复制的吧?那样也太累了。我们肯定是把一段话都复制下来然后放到文章中。
cpu也是,如果傻傻的一个字节一个字节的挪动数据那也太慢了,他是一块一块的挪动,那么这一块数据单位就叫一个“Cache Line”。
那为什么vector缓存命中率高呢?比方说我们就挪动64字节(目前主流cpu的Cache Line是64字节),恰巧我们64个字节是存储的连续的16个int类型数据,那好了我一次性都加载走了。
但如果是list呢?他的内存分布是不连续的,是这一块内存一个数据,那一块内存一个数据,倘若我对于某一块内存扫描64字节的话,可能只能挪走一个数据,甚至一个也挪不到。那命中率就低了。进而效率也就低了。
介绍完vector和list以及缓存命中率,我们再来看一下deque。
3.3、deque
deque(双端队列)是一种支持高效头尾插入/删除的序列容器,它结合了vector和list的优缺点,既支持随机访问,又能高效的插入和删除。
deque可以说是把两者融合了一下,但是由于他的底层逻辑设计起来比较复杂,他的头插尾插效率高,但是高不过list,他的cpu缓存命中率比list优秀,但是也优秀不过vector。我们在这里不模拟实现他,但是我们说一下他的底层是什么样子的。
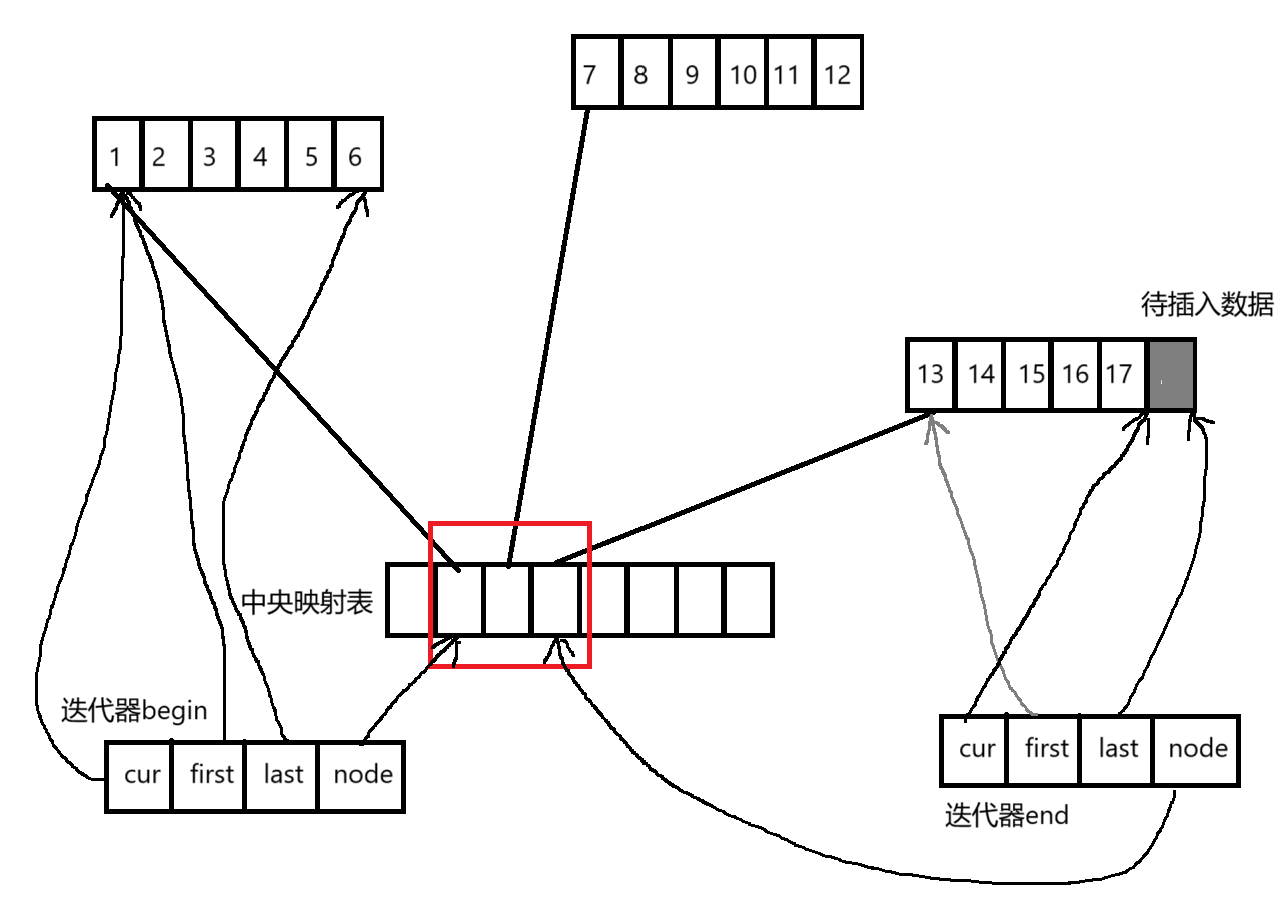
deque通常由多个固定大小的连续内存块(分块数组)通过中央控制器(如指针数组)链接而成,具体结构如下:
(1)分块储存
每个内存块存储若干元素,独立分配,插入新元素无需整体挪动,只需要分配新的内存块
(2)中央映射表
通过一个存储着每块内存地址的数组来快速找到这块内存。
STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
1. stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
2. 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。 结合了deque的优点,而完美的避开了其缺陷。
好了,今天的内容就分享到这,我们下期再见!