Dify使用总结
最近完成了一个Dify的项目简单进行总结下搭建服务按照官方文档操作就行就不写了。
进入首页之后由以下组成:
探索、工作室、知识库、工具
探索:
可以展示自己创建的所有应用,一个应用就是一个APP,可以进行测试使用

工作室包含如下:
创建应用
点击创建应用可以创建不同种类的助手,可以根据自己的需要选择不同类型:
Dify支持DSL文件导入创建应用(将流程图导出为文件然后导入),但是这个和其他的平台不相同,百炼的导出之后是一个zip包里面包含yaml流程图定义文件和一个加密字符串用于防止用户修改,Dify的只是一个yaml文件,但是百炼平台的yaml文件不能导入Dify,文件格式不太一样。
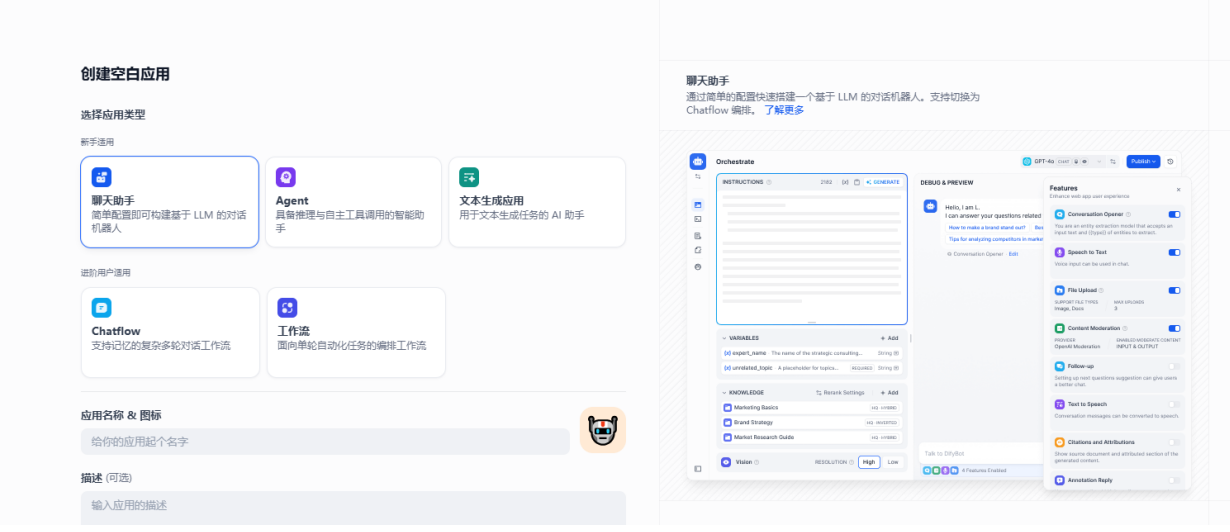
聊天助手:一个简单的基于LLM的搜索工具可以快速创建
Agent:类似于一个MCP的工具,可以在其他应用流程中进行调用
文本生成:用于生成简单文本
Chatflow:多轮对话,相比与聊天助手支持记忆功能有复杂的工作流
工作流:完成复杂的工作例如发邮件或者其他任务型的。
知识库:
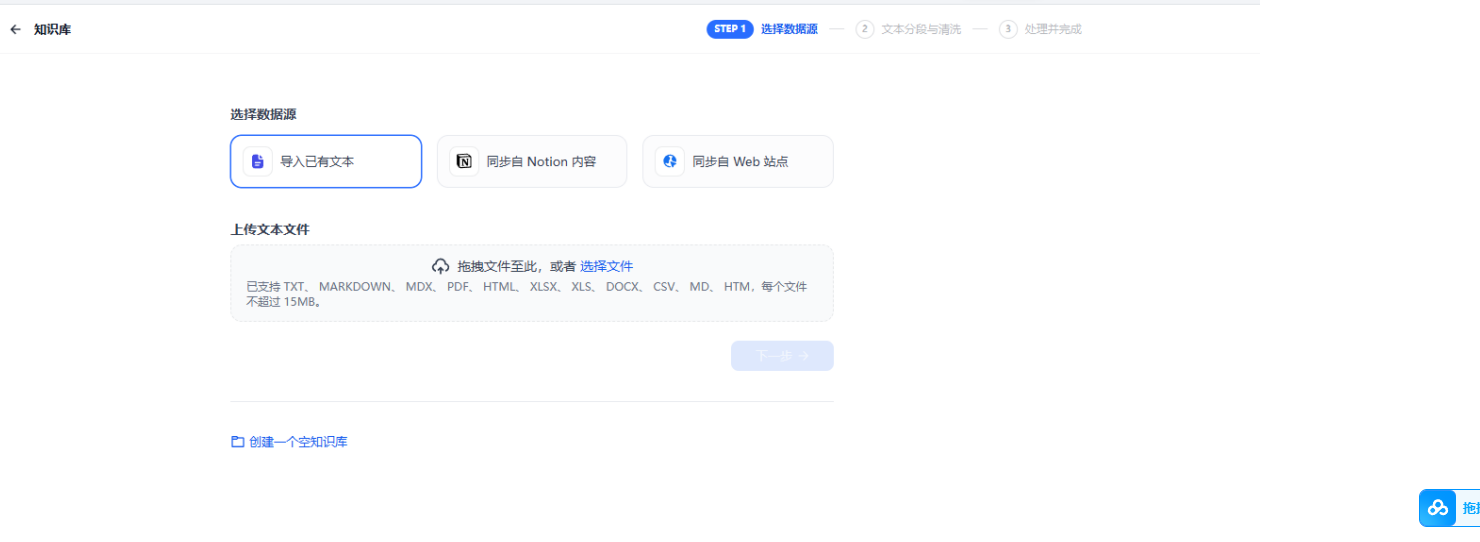
知识库是用于RAG生成时给LLM作为Prompt提示语用,相当于一个内部搜索系统。
知识库大部分是导入已有文件,也可以通过API导入,另外还可以同步Notion和web网站的内容,我以导入已有文件介绍下:
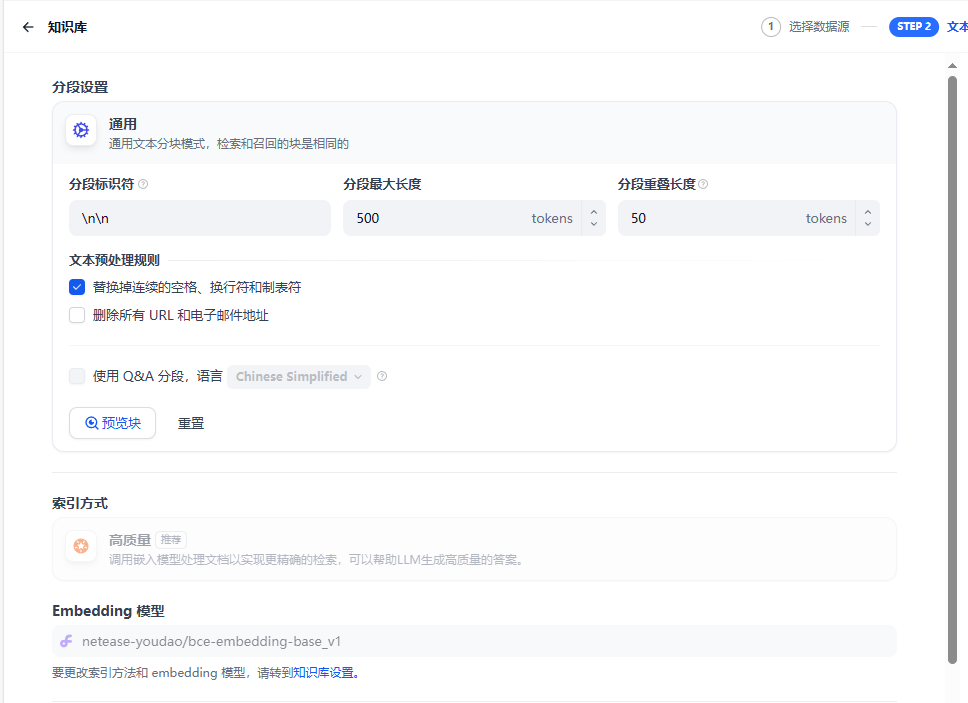
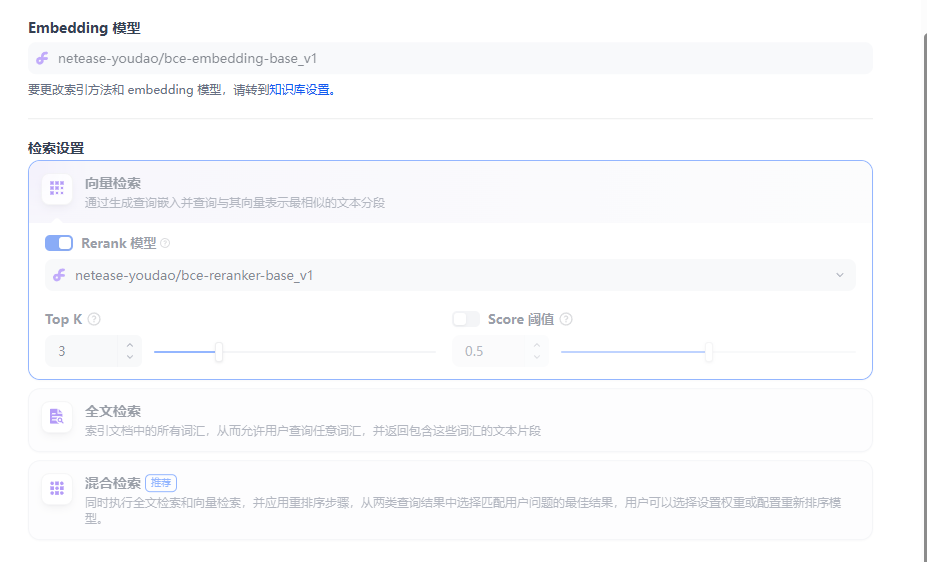
首先是知识库的分段,因为会将上传的内容切割为多个分段去处理,每个分段里面会有搜索关键字和内容,支持手动改动。分段标识符代表按照什么分段,分段最大长度代表每个分段的最大,如果超出会强制分断,分段重叠代表每个分段之间的重叠度是多少,这个字段防止分段的时候丢失掉内容,避免查询出来只有一部分,但是个人在使用中仍然有丢失的感觉还是没有百炼的按照段落和一级标题分段好点。
分割方式分为父子和普通:
普通的会将文本按照定义的分割符进行分割,查询出来的只有当前分割匹配到的。
父子分割会将文档按照父子级别存取,查询出来之后会显示父子关系更利于大模型分析,如果是pdf的文档还是建议用这个比较好,如果只是一条一条的内容还是建议普通较好。
Embedding 模型选择:
根据自己的文档选择不同的模型,作为文档切割分词用。
检索设置:
有向量检索和全文检索两种:向量检索会将分词按照向量搜索去匹配。泛华性更高搜索较强但是准确性没有全文检索好。全文检索是分割之后按照关键字去匹配。泛华较差但是匹配结果度较高,可以根据自己的需要选择不同的方式。
工具页面:主要提供一些根据类似于MCP的工具,结合大模型分析会去选择不同的工具调用。自己开发的agent也算是一个工具。
流程图:
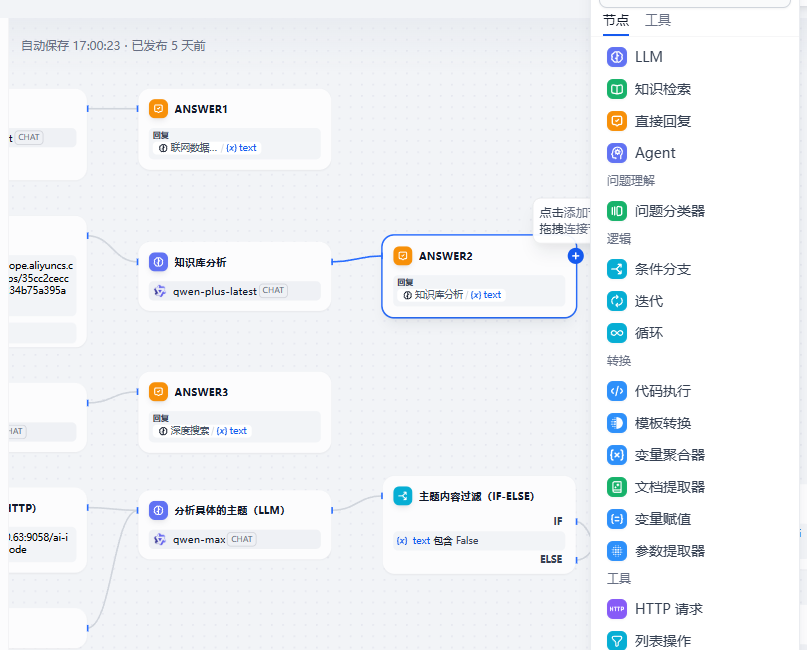
可以选择不同的节点,流程触发之后会根据条件选择不同的节点进行流转处理。
需要注意在大模型的提示词上非常关键,直接影响大模型的回答。
以上只是手动配置,在项目中都是通过API去操作,流程是一样的。
服务搭建可以参考:【2025年看这一篇就够了】Dify从入门到精通_dify教程-CSDN博客
详细参考中文官方文档: 产品简介 - Dify Docs