PyTorch API 8 - 工具集、onnx、option、复数、DDP、量化、分布式 RPC、NeMo
文章目录
- torch.nn.init
- torch.nn.attention
- 工具集
- 子模块
- torch.onnx
- 概述
- 基于 TorchDynamo 的 ONNX 导出器
- 基于TorchScript的ONNX导出器
- 贡献与开发
- torch.optim
- 如何使用优化器
- 构建优化器
- 每个参数的选项
- 执行优化步骤
- `optimizer.step()`
- `optimizer.step(closure)`
- 基类
- 算法
- 如何调整学习率
- 如何利用命名参数加载优化器状态字典
- 权重平均法 (SWA 与 EMA)
- 构建平均模型
- 自定义平均策略
- SWA 学习率调度策略
- 批量归一化的处理
- 整合应用:SWA方法
- 整合实现:EMA模型
- 复数
- 创建复数张量
- 从旧表示法迁移
- 访问实部与虚部
- 角度与绝对值
- 线性代数
- 序列化
- 自动微分
- 优化器
- DDP 通信钩子
- 如何使用通信钩子?
- 通信钩子的作用对象是什么?
- 默认通信钩子
- PowerSGD 通信钩子
- PowerSGD 状态
- PowerSGD 钩子
- 调试通信钩子
- 通信钩子的检查点保存
- 致谢
- 量化
- 量化技术简介
- 量化API概览
- 即时模式量化
- 训练后动态量化
- 训练后静态量化
- 静态量化的量化感知训练
- 动态图模式静态量化的模型准备
- (原型 - 维护模式)FX 图模式量化
- (原型)PyTorch 2 导出量化
- 量化技术栈
- 量化模型
- 量化张量
- 量化与反量化
- 量化运算符/模块
- 量化引擎
- 量化流程
- Observer 与 FakeQuantize
- QConfig
- 通用量化流程
- 量化支持矩阵
- 量化模式支持
- 量化流程支持
- 后端/硬件支持
- 关于原生 CPU 后端的注意事项
- 算子支持情况
- 量化 API 参考
- 量化后端配置
- 量化精度调试
- 量化定制功能
- 量化自定义模块 API
- 最佳实践
- 常见问题解答
- 常见错误
- 将非量化张量传入量化内核
- 将量化张量传入非量化内核
- 保存与加载量化模型
- 使用FX图模式量化时出现符号追踪错误
- 分布式RPC框架
- 基础概念
- RPC 远程过程调用
- 后端实现
- TensorPipe 后端
- RRef 远程引用
- RemoteModule
- 分布式自动求导框架
- 分布式优化器
- 设计说明
- 教程
- 一、关于 NeMo
- 项目概览
- 相关链接资源
- NeMo 2.0 新特性
- NeMo 2.0 入门指南
- 开始使用 Cosmos
- LLM与多模态模型的训练、对齐与定制
- 大语言模型与多模态模型的部署与优化
- 语音 AI
- NeMo 框架启动器
- NeMo框架入门指南
- 二、安装 NeMo 框架
- 1、支持矩阵
- 2、Conda / Pip
- 选择正确版本
- 安装特定领域模块
- 3、NGC PyTorch 容器
- 三、NGC NeMo 容器
- 一、关于 NeMo
- 项目概览
- 相关链接资源
- NeMo 2.0 新特性
- NeMo 2.0 入门指南
- 开始使用 Cosmos
- LLM与多模态模型的训练、对齐与定制
- 大语言模型与多模态模型的部署与优化
- 语音 AI
- NeMo 框架启动器
- NeMo框架入门指南
- 二、安装 NeMo 框架
- 1、支持矩阵
- 2、Conda / Pip
- 选择正确版本
- 安装特定领域模块
- 3、NGC PyTorch 容器
- 三、NGC NeMo 容器
torch.nn.init
警告:本模块中的所有函数均用于初始化神经网络参数,因此它们都在 torch.no_grad() 模式下运行,且不会被自动求导机制追踪。
torch.nn.init.calculate_gain(nonlinearity, param=None)
返回给定非线性函数的推荐增益值。
具体数值如下:
| 非线性函数 | 增益值 |
|---|---|
| Linear / Identity | 111 |
| Conv{1,2,3}D | 111 |
| Sigmoid | 111 |
| Tanh | 5 3 \frac{5}{3} 35 |
| ReLU | 2 \sqrt{2} 2 |
| Leaky Relu | KaTeX parse error: Expected 'EOF', got '_' at position 34: … \text{negative_̲slope}^2}} |
| SELU | 3 4 \frac{3}{4} 43 |
警告:为了实现自归一化神经网络,应该使用nonlinearity='linear'而非nonlinearity='selu'。这样可以使初始权重具有1/N的方差,这对在前向传播中形成稳定不动点是必要的。
相比之下,SELU的默认增益值牺牲了归一化效果,以在矩形层中获得更稳定的梯度流。
参数说明
nonlinearity- 非线性函数(nn.functional名称)param- 非线性函数的可选参数
使用示例:
>>> gain = nn.init.calculate_gain('leaky_relu', 0.2) # leaky_relu with negative_slope=0.2
torch.nn.init.uniform_(tensor, a=0.0, b=1.0, generator=None)
使用均匀分布中的值填充输入张量。
U ( a , b ) {U}(a, b) U(a,b).
参数
tensor ( Tensor )– 一个n维的torch.Tensora (float)– 均匀分布的下界b (float)– 均匀分布的上界generator (Optional[ Generator ])– 用于采样的torch生成器(默认值:None)
返回类型:Tensor
示例
>>> w = torch.empty(3, 5)
>>> nn.init.uniform_(w)
torch.nn.init.normal_(tensor, mean=0.0, std=1.0, generator=None)
使用正态分布中的随机值填充输入张量。
N ( mean , std 2 ) \mathcal{N}(\text{mean}, \text{std}^2) N(mean,std2)
参数说明
tensor ( Tensor )– 一个n维的torch.Tensormean (float)– 正态分布的均值std (float)– 正态分布的标准差generator (Optional[ Generator ])– 用于采样的torch生成器对象(默认值为None)
返回值类型:Tensor
使用示例:
>>> w = torch.empty(3, 5)
>>> nn.init.normal_(w)
torch.nn.init.constant_(tensor, val)
将输入张量填充为值 val\text{val}val。
参数
tensor ( Tensor )– 一个 n 维的 torch.Tensorval (float)– 用于填充张量的值
返回类型 : Tensor
示例
>>> w = torch.empty(3, 5)
>>> nn.init.constant_(w, 0.3)
torch.nn.init.ones_(tensor)
填充输入张量(Tensor)为标量值1。
参数
tensor ( Tensor )– 一个n维的torch.Tensor
返回类型:Tensor
示例
>>> w = torch.empty(3, 5)
>>> nn.init.ones_(w)
torch.nn.init.zeros_(tensor)
将输入张量填充为标量值0。
参数
tensor ( Tensor )- 一个n维的torch.Tensor
返回类型: Tensor
示例
>>> w = torch.empty(3, 5)
>>> nn.init.zeros_(w)
torch.nn.init.eye_(tensor)
将二维输入张量填充为单位矩阵。
在Linear层中保留输入的恒等性,尽可能多地保留输入特征。
参数
tensor– 一个二维的torch.Tensor张量
示例
>>> w = torch.empty(3, 5)
>>> nn.init.eye_(w)
torch.nn.init.dirac_(tensor, groups=1)
用狄拉克δ函数填充{3, 4, 5}维输入张量。
在卷积层中保持输入数据的特性,尽可能多地保留输入通道。当组数大于1时,每组通道都会保持其特性。
参数
tensor– 一个{3, 4, 5}维的torch.Tensorgroups (int, 可选)– 卷积层中的组数(默认值:1)
示例
>>> w = torch.empty(3, 16, 5, 5)
>>> nn.init.dirac_(w)
>>> w = torch.empty(3, 24, 5, 5)
>>> nn.init.dirac_(w, 3)
torch.nn.init.xavier_uniform_(tensor, gain=1.0, generator=None)
使用Xavier均匀分布为输入张量填充数值。
该方法在论文《理解深度前馈神经网络训练难点》- Glorot, X. 和 Bengio, Y. (2010)中有详细描述。生成的张量将从U(−a,a)分布中采样,其中:
a = gain × √(6/(fan_in + fan_out))
该初始化方法也被称为Glorot初始化。
参数:
tensor (Tensor)- 一个n维的torch.Tensorgain (float)- 可选的缩放因子generator (Optional[Generator])- 用于采样的torch生成器(默认值:None)
返回类型:Tensor
示例:
>>> w = torch.empty(3, 5)
>>> nn.init.xavier_uniform_(w, gain=nn.init.calculate_gain('relu'))
注意:fan_in 和 fan_out 的计算基于权重矩阵以转置方式使用的假设(例如 Linear 层中的 x @ w.T,其中 w.shape = [fan_out, fan_in])。
这对正确初始化至关重要。
如果计划使用 x @ w(其中 w.shape = [fan_in, fan_out]),请传入转置后的权重矩阵,即 nn.init.xavier_uniform_(w.T, ...)。
torch.nn.init.xavier_normal_(tensor, gain=1.0, generator=None)
使用Xavier正态分布为输入张量填充数值。
该方法在论文《理解深度前馈神经网络训练的难点》- Glorot, X. 和 Bengio, Y. (2010) 中提出。生成的张量将从 U ( − a , a ) \mathcal{U}(-a, a) U(−a,a)分布中采样数值,其中
KaTeX parse error: Expected 'EOF', got '_' at position 48: …ac{6}{\text{fan_̲in} + \text{fan…
参数
tensor ( Tensor )– 一个n维的torch.Tensorgain (float)– 可选的缩放因子generator (Optional[ Generator ])– 用于采样的torch生成器(默认值:None)
返回类型:Tensor
示例
>>> w = torch.empty(3, 5)
>>> nn.init.xavier_normal_(w)
注意:fan_in 和 fan_out 的计算基于权重矩阵以转置方式使用的假设(例如 Linear 层中的 x @ w.T,其中 w.shape = [fan_out, fan_in])。
这一点对于正确初始化至关重要。
如果你计划使用 x @ w(其中 w.shape = [fan_in, fan_out]),请传入转置后的权重矩阵,即 nn.init.xavier_normal_(w.T, ...)。
torch.nn.init.kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu', generator=None)
使用Kaiming均匀分布为输入张量填充数值。
该方法出自论文《Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification》——何恺明等人(2015年)。生成的张量数值将采样自 U ( − b o u n d , b o u n d ) U(−bound,bound) U(−bound,bound)区间,其中边界值计算公式为:
KaTeX parse error: Expected 'EOF', got '_' at position 59: …ac{3}{\text{fan_̲mode}}}
该初始化方法也被称为He初始化。
参数说明
tensor ( Tensor )– 一个n维的torch.Tensora (float)– 该层后接整流器的负斜率(仅当使用'leaky_relu'时生效)mode (str)– 可选'fan_in'(默认)或'fan_out'。选择'fan_in'可保持前向传播中权重的方差量级,选择'fan_out'则保持反向传播中的量级nonlinearity (str)– 非线性函数名称(需对应nn.functional中的名称),建议仅使用'relu'或'leaky_relu'(默认值)generator (Optional[ Generator ])– 用于采样的torch生成器对象(默认值为None)
使用示例
>>> w = torch.empty(3, 5)
>>> nn.init.kaiming_uniform_(w, mode='fan_in', nonlinearity='relu')
注意:fan_in 和 fan_out 的计算基于权重矩阵以转置方式使用的假设(例如在 Linear 层中的 x @ w.T,其中 w.shape = [fan_out, fan_in])。
这一点对于正确的初始化非常重要。
如果你计划使用 x @ w(其中 w.shape = [fan_in, fan_out]),请传入转置后的权重矩阵,即 nn.init.kaiming_uniform_(w.T, ...)。
torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu', generator=None)
使用Kaiming正态分布为输入张量填充数值。
该方法在论文《深入研究整流器:超越ImageNet分类的人类水平性能》- He, K. 等人 (2015) 中有详细描述。生成的张量值将从 N ( 0 , s t d 2 ) N(0,std^2) N(0,std2) 分布中采样,其中
KaTeX parse error: Expected 'EOF', got '_' at position 48: …\sqrt{\text{fan_̲mode}}}
该方法也被称为He初始化。
参数
tensor ( Tensor )– 一个n维的torch.Tensora (float)– 该层之后使用的整流器的负斜率(仅与'leaky_relu'一起使用)mode (str)– 可选'fan_in'(默认)或'fan_out'。选择'fan_in'会保持前向传播中权重的方差大小,选择'fan_out'则会保持反向传播中的大小。nonlinearity (str)– 非线性函数(nn.functional名称),建议仅与'relu'或'leaky_relu'(默认)一起使用。generator (Optional[ Generator ])– 用于采样的torch生成器(默认:None)
示例
>>> w = torch.empty(3, 5)
>>> nn.init.kaiming_normal_(w, mode='fan_out', nonlinearity='relu')
注意:fan_in 和 fan_out 的计算基于权重矩阵以转置方式使用的假设(例如 Linear 层中的 x @ w.T,其中 w.shape = [fan_out, fan_in])。
这对正确初始化至关重要。
如果计划使用 x @ w(其中 w.shape = [fan_in, fan_out]),请传入转置后的权重矩阵,即 nn.init.kaiming_normal_(w.T, ...)。
torch.nn.init.trunc_normal_(tensor, mean=0.0, std=1.0, a=-2.0, b=2.0, generator=None)
使用截断正态分布生成的值填充输入张量。
这些值实际上是从正态分布 N ( m e a n , s t d 2 ) N(mean,std^2) N(mean,std2) 中抽取的,对于超出 [ a , b ] [a,b] [a,b] 范围的值会重新抽取,直到其落在边界内。当满足 a ≤ m e a n ≤ b a \leq mean \leq b a≤mean≤b 时,生成随机值的方法效果最佳。
参数
tensor ( Tensor )– 一个n维的torch.Tensormean (float)– 正态分布的均值std (float)– 正态分布的标准差a (float)– 最小截断值b (float)– 最大截断值generator (Optional[ Generator ])– 用于采样的torch生成器(默认值:None)
返回类型:Tensor
示例
>>> w = torch.empty(3, 5)
>>> nn.init.trunc_normal_(w)
torch.nn.init.orthogonal_(tensor, gain=1, generator=None)
用(半)正交矩阵填充输入张量。
该方法在《Exact solutions to the nonlinear dynamics of learning in deep linear neural networks》- Saxe, A. 等人 (2013) 的论文中有所描述。输入张量必须至少具有2个维度,对于超过2维的张量,其尾部维度会被展平。
参数
tensor– 一个n维的 torch.Tensor,其中 $n \geq 2 $gain– 可选缩放因子generator (Optional[ Generator ])– 用于采样的 torch Generator(默认值:None)
示例
>>> w = torch.empty(3, 5)
>>> nn.init.orthogonal_(w)
torch.nn.init.sparse_(tensor, sparsity, std=0.01, generator=None)
将二维输入张量填充为稀疏矩阵。
非零元素将从正态分布 N ( 0 , 0.01 ) N(0, 0.01) N(0,0.01) 中抽取,如《Deep learning via Hessian-free optimization》- Martens, J. (2010) 所述。
参数
tensor– 一个 n 维的 torch.Tensorsparsity– 每列中要置零的元素比例std– 用于生成非零值的正态分布的标准差generator (Optional[ Generator ])– 用于采样的 torch 生成器(默认值:None)
示例
>>> w = torch.empty(3, 5)
>>> nn.init.sparse_(w, sparsity=0.1)
torch.nn.attention
该模块包含用于改变 torch.nn.functional.scaled_dot_product_attention 行为的函数和类
工具集
sdpa_kernel | 用于选择缩放点积注意力计算后端的上下文管理器 |
|---|---|
SDPBackend | 枚举类,包含缩放点积注意力计算的不同后端实现 |
子模块
flex_attention | 该模块实现了PyTorch中flex_attention的用户接口API。 |
|---|---|
bias | 定义了与scaled_dot_product_attention配合使用的偏置子类 |
experimental |
torch.onnx
https://docs.pytorch.org/docs/stable/onnx.html
概述
开放神经网络交换格式(ONNX) 是一种用于表示机器学习模型的开放标准格式。torch.onnx 模块能够从原生 PyTorch torch.nn.Module 模型中捕获计算图,并将其转换为 ONNX 计算图。
导出的模型可以被众多支持 ONNX 的运行时使用,包括微软的 ONNX Runtime。
ONNX 导出器 API 提供两种使用方式,如下所列。
两者均可通过函数 torch.onnx.export() 调用。
接下来的示例展示了如何导出一个简单模型。
import torchclass MyModel(torch.nn.Module):def __init__(self):super(MyModel, self).__init__()self.conv1 = torch.nn.Conv2d(1, 128, 5)def forward(self, x):return torch.relu(self.conv1(x))input_tensor = torch.rand((1, 1, 128, 128), dtype=torch.float32)model = MyModel()torch.onnx.export(model, # model to export(input_tensor,), # inputs of the model, "my_model.onnx", # filename of the ONNX modelinput_names=["input"], # Rename inputs for the ONNX modeldynamo=True # True or False to select the exporter to use )
接下来的章节将介绍导出器的两个版本。
基于 TorchDynamo 的 ONNX 导出器
该基于 TorchDynamo 的 ONNX 导出器是 PyTorch 2.1 及更新版本中最新的(测试版)导出方案
TorchDynamo 引擎通过挂钩 Python 的帧评估 API,动态将其字节码重写为 FX 计算图。生成的 FX 计算图经过优化后,最终会被转换为 ONNX 计算图。
这种方法的主要优势在于:FX 计算图通过字节码分析捕获,保留了模型的动态特性,而非使用传统的静态追踪技术。
了解更多关于基于 TorchDynamo 的 ONNX 导出器
基于TorchScript的ONNX导出器
自PyTorch 1.2.0版本起提供基于TorchScript的ONNX导出功能
该导出器利用TorchScript(通过torch.jit.trace())对模型进行追踪,捕获静态计算图。
因此,生成的图存在以下限制:
- 无法记录任何控制流(如if语句或循环)
- 不区分
training和eval模式间的细微差异 - 无法真正处理动态输入
为弥补静态追踪的局限性,导出器还支持TorchScript脚本模式(通过torch.jit.script()),例如增加了对数据依赖控制流的支持。但TorchScript本身是Python语言的子集,因此不支持所有Python特性(如原地操作)。
了解更多关于基于TorchScript的ONNX导出器
贡献与开发
ONNX导出器是一个社区项目,我们欢迎各方贡献。我们遵循PyTorch贡献指南,同时建议您阅读我们的开发维基获取更多信息。
torch.optim
torch.optim 是一个实现了多种优化算法的包。
该包已经支持最常用的优化方法,其接口设计具有足够的通用性,未来也能方便地集成更复杂的优化算法。
如何使用优化器
要使用 torch.optim,你需要构造一个优化器对象,该对象将保持当前状态并根据计算的梯度更新参数。
构建优化器
要构建一个 Optimizer,需要向其提供一个包含待优化参数(所有参数都应为 Parameter 类型)或命名参数((str, Parameter) 元组)的可迭代对象。随后,可以指定优化器特有的选项,例如学习率、权重衰减等。
示例:
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001)
命名参数示例:
optimizer = optim.SGD(model.named_parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([('layer0', var1), ('layer1', var2)], lr=0.0001)
每个参数的选项
Optimizer 还支持为每个参数指定选项。要实现这一点,不是传入 Variable 的可迭代对象,而是传入 dict 的可迭代对象。每个字典将定义一个独立的参数组,其中必须包含一个 params 键,其值为属于该组的参数列表。其他键应与优化器接受的关键字参数匹配,并将作为该组的优化选项。
例如,这在需要为不同层指定不同学习率时非常有用:
optim.SGD([{'params': model.base.parameters(), 'lr': 1e-2}, {'params': model.classifier.parameters()}], lr=1e-3, momentum=0.9)optim.SGD([{'params': model.base.named_parameters(), 'lr': 1e-2}, {'params': model.classifier.named_parameters()}], lr=1e-3, momentum=0.9)
这意味着model.base的参数将使用1e-2的学习率,而model.classifier的参数将保持默认的1e-3学习率。
最后,所有参数都将使用0.9的动量值。
注意:您仍可以通过关键字参数传递选项。这些选项将作为未覆盖组的默认值,当您只想改变单个选项而保持其他所有参数组一致时,这非常有用。
另请考虑以下与参数差异化惩罚相关的示例。记住parameters()返回一个包含所有可学习参数的可迭代对象,包括偏置项和其他可能需要差异化惩罚的参数。为了解决这个问题,可以为每个参数组指定单独的惩罚权重:
bias_params = [p for name, p in self.named_parameters() if 'bias' in name]
others = [p for name, p in self.named_parameters() if 'bias' not in name]optim.SGD([{'params': others}, {'params': bias_params, 'weight_decay': 0}], weight_decay=1e-2, lr=1e-2)
通过这种方式,偏置项(bias terms)与非偏置项被区分开来,并专门为偏置项设置weight_decay为0,以避免对该组参数施加惩罚。
执行优化步骤
所有优化器都实现了 step() 方法,用于更新参数。该方法有两种使用方式:
optimizer.step()
这是大多数优化器支持的简化版本。在使用例如backward()计算完梯度后,可以调用该函数。
示例:
for input, target in dataset:optimizer.zero_grad()output = model(input)loss = loss_fn(output, target)loss.backward()optimizer.step()
optimizer.step(closure)
部分优化算法(如共轭梯度法和LBFGS)需要多次重新评估函数,因此必须传入一个闭包函数,使它们能够重新计算模型。该闭包应完成以下操作:清除梯度、计算损失值并返回结果。
示例:
for input, target in dataset:def closure():optimizer.zero_grad()output = model(input)loss = loss_fn(output, target)loss.backward()return lossoptimizer.step(closure)
基类
class torch.optim.Optimizer(params, defaults)
所有优化器的基类。
警告:参数必须指定为具有确定性顺序的集合,且该顺序在不同运行间保持一致。不满足此特性的对象包括集合(set)和字典值迭代器。
参数
params (iterable)- 一个包含torch.Tensor或dict的可迭代对象,指定需要优化的张量。defaults (dict[str, Any])- 包含优化选项默认值的字典(当参数组未指定这些选项时使用)。
Optimizer.add_param_group | 向优化器的 param_groups 添加参数组。 |
|---|---|
Optimizer.load_state_dict | 加载优化器状态。 |
Optimizer.register_load_state_dict_pre_hook | 注册一个在调用 load_state_dict() 前执行的前置钩子,其签名应为:: |
Optimizer.register_load_state_dict_post_hook | 注册一个在调用 load_state_dict() 后执行的后置钩子,其签名应为:: |
Optimizer.state_dict | 以 dict 形式返回优化器状态。 |
Optimizer.register_state_dict_pre_hook | 注册一个在调用 state_dict() 前执行的前置钩子。 |
Optimizer.register_state_dict_post_hook | 注册一个在调用 state_dict() 后执行的后置钩子。 |
Optimizer.step | 执行单次优化步骤以更新参数。 |
Optimizer.register_step_pre_hook | 注册一个在优化器步骤执行前调用的前置钩子。 |
Optimizer.register_step_post_hook | 注册一个在优化器步骤执行后调用的后置钩子。 |
Optimizer.zero_grad | 重置所有优化 torch.Tensor 的梯度。 |
算法
Adadelta | 实现Adadelta算法 |
|---|---|
Adafactor | 实现Adafactor算法 |
Adagrad | 实现Adagrad算法 |
Adam | 实现Adam算法 |
AdamW | 实现AdamW算法,其中权重衰减不会累积到动量或方差中 |
SparseAdam | 实现适用于稀疏梯度的Adam算法掩码版本 |
Adamax | 实现Adamax算法(基于无穷范数的Adam变体) |
ASGD | 实现平均随机梯度下降 |
LBFGS | 实现L-BFGS算法 |
NAdam | 实现NAdam算法 |
RAdam | 实现RAdam算法 |
RMSprop | 实现RMSprop算法 |
Rprop | 实现弹性反向传播算法 |
SGD | 实现随机梯度下降(可选带动量) |
我们的许多算法都有针对性能、可读性和/或通用性优化的不同实现,因此如果用户没有指定特定实现,我们会尝试默认为当前设备上通常最快的实现。
我们有三种主要的实现类别:for循环、foreach(多张量)和fused。最直接的实现是对参数进行for循环并执行大块计算。for循环通常比我们的foreach实现慢,后者将参数组合成多张量并一次性执行大块计算,从而节省了许多顺序内核调用。我们的一些优化器甚至有更快的fused实现,将大块计算融合到一个内核中。我们可以将foreach实现视为水平融合,而fused实现则在此基础上进行垂直融合。
一般来说,三种实现的性能排序是:fused > foreach > for循环。因此,在适用的情况下,我们默认使用foreach而非for循环。"适用"意味着foreach实现可用,用户没有指定任何特定于实现的kwargs(例如fused、foreach、differentiable),并且所有张量都是原生的。需要注意的是,虽然fused应该比foreach更快,但这些实现较新,我们希望在全面切换之前给予更多的测试时间。我们在下面的第二个表格中总结了每种实现的稳定性状态,欢迎您尝试!
以下是显示每种算法的可用和默认实现的表格:
| 算法 | 默认 | 有foreach? | 有fused? |
|---|---|---|---|
Adadelta | foreach | 是 | 否 |
Adafactor | for-loop | 否 | 否 |
Adagrad | foreach | 是 | 是(仅CPU) |
Adam | foreach | 是 | 是 |
AdamW | foreach | 是 | 是 |
SparseAdam | for-loop | 否 | 否 |
Adamax | foreach | 是 | 否 |
ASGD | foreach | 是 | 否 |
LBFGS | for-loop | 否 | 否 |
NAdam | foreach | 是 | 否 |
RAdam | foreach | 是 | 否 |
RMSprop | foreach | 是 | 否 |
Rprop | foreach | 是 | 否 |
SGD | foreach | 是 | 是 |
下表显示了fused实现的稳定性状态:
| 算法 | CPU | CUDA | MPS |
|---|---|---|---|
Adadelta | 不支持 | 不支持 | 不支持 |
Adafactor | 不支持 | 不支持 | 不支持 |
Adagrad | beta | 不支持 | 不支持 |
Adam | beta | 稳定 | beta |
AdamW | beta | 稳定 | beta |
SparseAdam | 不支持 | 不支持 | 不支持 |
Adamax | 不支持 | 不支持 | 不支持 |
ASGD | 不支持 | 不支持 | 不支持 |
LBFGS | 不支持 | 不支持 | 不支持 |
NAdam | 不支持 | 不支持 | 不支持 |
RAdam | 不支持 | 不支持 | 不支持 |
RMSprop | 不支持 | 不支持 | 不支持 |
Rprop | 不支持 | 不支持 | 不支持 |
SGD | beta | beta | beta |
如何调整学习率
torch.optim.lr_scheduler.LRScheduler 提供了多种基于训练轮次调整学习率的方法。torch.optim.lr_scheduler.ReduceLROnPlateau 则支持根据验证指标动态降低学习率。
学习率调度应在优化器参数更新之后应用,具体代码写法如下:
示例:
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = ExponentialLR(optimizer, gamma=0.9)
for epoch in range(20):for input, target in dataset:optimizer.zero_grad()output = model(input)loss = loss_fn(output, target)loss.backward()optimizer.step()scheduler.step()
大多数学习率调度器可以连续调用(也称为链式调度器)。这样做的效果是,每个调度器会依次对前一个调度器输出的学习率进行调整。
示例:
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler1 = ExponentialLR(optimizer, gamma=0.9)
scheduler2 = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
for epoch in range(20):for input, target in dataset:optimizer.zero_grad()output = model(input)loss = loss_fn(output, target)loss.backward()optimizer.step()scheduler1.step()scheduler2.step()
在文档的许多地方,我们将使用以下模板来指代调度器算法。
>>> scheduler = ...
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
警告:在 PyTorch 1.1.0 版本之前,学习率调度器应在优化器更新之前调用;1.1.0 版本以不向后兼容的方式改变了这一行为。如果您在优化器更新(调用 optimizer.step())之前使用学习率调度器(调用 scheduler.step()),这将跳过学习率调度器的第一个值。
如果您在升级到 PyTorch 1.1.0 后无法复现结果,请检查是否在错误的时间调用了 scheduler.step()。
lr_scheduler.LRScheduler | 在优化过程中调整学习率。 |
|---|---|
lr_scheduler.LambdaLR | 设置初始学习率。 |
lr_scheduler.MultiplicativeLR | 将每个参数组的学习率乘以指定函数中给定的因子。 |
lr_scheduler.StepLR | 每隔 step_size 个 epoch,将每个参数组的学习率按 gamma 衰减。 |
lr_scheduler.MultiStepLR | 当 epoch 数达到某个里程碑时,将每个参数组的学习率按 gamma 衰减。 |
lr_scheduler.ConstantLR | 将每个参数组的学习率乘以一个小的常数因子。 |
lr_scheduler.LinearLR | 通过线性变化的小乘法因子衰减每个参数组的学习率。 |
lr_scheduler.ExponentialLR | 每个 epoch 将每个参数组的学习率按 gamma 衰减。 |
lr_scheduler.PolynomialLR | 在给定的 total_iters 中使用多项式函数衰减每个参数组的学习率。 |
lr_scheduler.CosineAnnealingLR | 使用余弦退火调度设置每个参数组的学习率。 |
lr_scheduler.ChainedScheduler | 将多个学习率调度器串联起来。 |
lr_scheduler.SequentialLR | 包含一组在优化过程中按顺序调用的调度器。 |
lr_scheduler.ReduceLROnPlateau | 当指标停止改善时降低学习率。 |
lr_scheduler.CyclicLR | 根据周期性学习率策略(CLR)设置每个参数组的学习率。 |
lr_scheduler.OneCycleLR | 根据 1cycle 学习率策略设置每个参数组的学习率。 |
lr_scheduler.CosineAnnealingWarmRestarts | 使用余弦退火调度设置每个参数组的学习率。 |
如何利用命名参数加载优化器状态字典
函数 load_state_dict() 会存储加载的状态字典中可选的 param_names 内容(如果存在)。不过加载优化器状态的过程不受影响,因为参数顺序对保持兼容性至关重要(以防参数顺序不同)。
要利用从加载的状态字典中获取的参数名称,需要根据需求自定义实现 register_load_state_dict_pre_hook。
这在某些场景下非常有用,例如当模型架构发生变化,但需要保持权重和优化器状态不变时。以下示例展示了如何实现这种定制化。
示例:
class OneLayerModel(nn.Module):def __init__(self):super().__init__()self.fc = nn.Linear(3, 4)def forward(self, x):return self.fc(x)model = OneLayerModel()
optimizer = optim.SGD(model.named_parameters(), lr=0.01, momentum=0.9)
# training..
torch.save(optimizer.state_dict(), PATH)
假设 model 实现了一个专家模型(MoE),现在我们需要复制它并继续训练两个专家模型,这两个专家模型的初始化方式都与 fc 层相同。对于接下来的 model2,我们创建两个与 fc 完全相同的层,并通过将 model 的模型权重和优化器状态加载到 model2 的 fc1 和 fc2 中(并相应调整它们)来恢复训练:
class TwoLayerModel(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(3, 4)self.fc2 = nn.Linear(3, 4)def forward(self, x):return (self.fc1(x) + self.fc2(x)) / 2model2 = TwoLayerModel()
# adapt and load model weights..
optimizer2 = optim.SGD(model2.named_parameters(), lr=0.01, momentum=0.9)
要为 optimizer2 加载前一个优化器的状态字典,使得 fc1 和 fc2 都能初始化获得 fc 优化器状态的副本(从而让每一层从 fc 的状态继续训练),可以使用以下钩子函数:
def adapt_state_dict_ids(optimizer, state_dict):adapted_state_dict = deepcopy(optimizer.state_dict())# Copy setup parameters (lr, weight_decay, etc.), in case they differ in the loaded state dict.for k, v in state_dict['param_groups'][0].items():if k not in ['params', 'param_names']:adapted_state_dict['param_groups'][0][k] = vlookup_dict = {'fc1.weight': 'fc.weight', 'fc1.bias': 'fc.bias', 'fc2.weight': 'fc.weight', 'fc2.bias': 'fc.bias'}clone_deepcopy = lambda d: {k: (v.clone() if isinstance(v, torch.Tensor) else deepcopy(v)) for k, v in d.items()}for param_id, param_name in zip(optimizer.state_dict()['param_groups'][0]['params'], optimizer.state_dict()['param_groups'][0]['param_names']):name_in_loaded = lookup_dict[param_name]index_in_loaded_list = state_dict['param_groups'][0]['param_names'].index(name_in_loaded)id_in_loaded = state_dict['param_groups'][0]['params'][index_in_loaded_list]# Copy the state of the corresponding parameterif id_in_loaded in state_dict['state']:adapted_state_dict['state'][param_id] = clone_deepcopy(state_dict['state'][id_in_loaded])return adapted_state_dictoptimizer2.register_load_state_dict_pre_hook(adapt_state_dict_ids)
optimizer2.load_state_dict(torch.load(PATH)) # The previous optimizer saved state_dict
这确保了在模型加载过程中,会使用针对model2各层状态调整后的state_dict。
请注意,这段代码专为本示例设计(例如假设只有一个参数组),其他情况可能需要不同的调整方法。
以下示例展示了当模型结构发生变化时,如何处理加载的state_dict中缺失的参数。
Model_bypass新增了一个原始Model1中不存在的bypass层。为了恢复训练,我们使用自定义的adapt_state_dict_missing_param钩子来调整优化器的state_dict:确保现有参数被正确映射,而缺失的参数(如bypass层)保持不变(在本示例中保持初始化状态)。
该方法使得即使模型发生变更,也能顺利加载并恢复优化器状态。新增的bypass层将从零开始训练:
class Model1(nn.Module):def __init__(self):super().__init__()self.fc = nn.Linear(5, 5)def forward(self, x):return self.fc(x) + xmodel = Model1()
optimizer = optim.SGD(model.named_parameters(), lr=0.01, momentum=0.9)
# training..
torch.save(optimizer.state_dict(), PATH)class Model_bypass(nn.Module):def __init__(self):super().__init__()self.fc = nn.Linear(5, 5)self.bypass = nn.Linear(5, 5, bias=False)torch.nn.init.eye_(self.bypass.weight)def forward(self, x):return self.fc(x) + self.bypass(x)model2 = Model_bypass()
optimizer2 = optim.SGD(model2.named_parameters(), lr=0.01, momentum=0.9)def adapt_state_dict_missing_param(optimizer, state_dict):adapted_state_dict = deepcopy(optimizer.state_dict())# Copy setup parameters (lr, weight_decay, etc.), in case they differ in the loaded state dict.for k, v in state_dict['param_groups'][0].items():if k not in ['params', 'param_names']:adapted_state_dict['param_groups'][0][k] = vlookup_dict = {'fc.weight': 'fc.weight', 'fc.bias': 'fc.bias', 'bypass.weight': None, }clone_deepcopy = lambda d: {k: (v.clone() if isinstance(v, torch.Tensor) else deepcopy(v)) for k, v in d.items()}for param_id, param_name in zip(optimizer.state_dict()['param_groups'][0]['params'], optimizer.state_dict()['param_groups'][0]['param_names']):name_in_loaded = lookup_dict[param_name]if name_in_loaded in state_dict['param_groups'][0]['param_names']:index_in_loaded_list = state_dict['param_groups'][0]['param_names'].index(name_in_loaded)id_in_loaded = state_dict['param_groups'][0]['params'][index_in_loaded_list]# Copy the state of the corresponding parameterif id_in_loaded in state_dict['state']:adapted_state_dict['state'][param_id] = clone_deepcopy(state_dict['state'][id_in_loaded])return adapted_state_dictoptimizer2.register_load_state_dict_pre_hook(adapt_state_dict_ids)
optimizer2.load_state_dict(torch.load(PATH)) # The previous optimizer saved state_dict
作为第三个示例,该钩子可用于根据参数名称(而非默认的参数顺序方式)加载状态。
def names_matching(optimizer, state_dict):assert len(state_dict['param_groups']) == len(optimizer.state_dict()['param_groups'])adapted_state_dict = deepcopy(optimizer.state_dict())for g_ind in range(len(state_dict['param_groups'])):assert len(state_dict['param_groups'][g_ind]['params']) == len(optimizer.state_dict()['param_groups'][g_ind]['params'])for k, v in state_dict['param_groups'][g_ind].items():if k not in ['params', 'param_names']:adapted_state_dict['param_groups'][g_ind][k] = vfor param_id, param_name in zip(optimizer.state_dict()['param_groups'][g_ind]['params'], optimizer.state_dict()['param_groups'][g_ind]['param_names']):index_in_loaded_list = state_dict['param_groups'][g_ind]['param_names'].index(param_name)id_in_loaded = state_dict['param_groups'][g_ind]['params'][index_in_loaded_list]# Copy the state of the corresponding parameterif id_in_loaded in state_dict['state']:adapted_state_dict['state'][param_id] = deepcopy(state_dict['state'][id_in_loaded])return adapted_state_dict
权重平均法 (SWA 与 EMA)
torch.optim.swa_utils.AveragedModel 实现了随机权重平均(SWA)和指数移动平均(EMA),torch.optim.swa_utils.SWALR 实现了SWA学习率调度器,而 torch.optim.swa_utils.update_bn() 是一个实用函数,用于在训练结束时更新SWA/EMA的批量归一化统计量。
SWA方法最初发表于论文《Averaging Weights Leads to Wider Optima and Better Generalization》。
EMA是一种广为人知的技术,通过减少权重更新次数来缩短训练时间。它是Polyak平均法的变体,但采用指数权重而非等权重进行迭代平均。
构建平均模型
AveragedModel 类用于计算 SWA 或 EMA 模型的权重。
可以通过以下命令创建 SWA 平均模型:
>>> averaged_model = AveragedModel(model)
EMA模型的构建通过如下方式指定multi_avg_fn参数实现:
>>> decay = 0.999
>>> averaged_model = AveragedModel(model, multi_avg_fn=get_ema_multi_avg_fn(decay))
衰减系数(Decay)是一个介于0和1之间的参数,用于控制平均参数的衰减速度。如果未传递给torch.optim.swa_utils.get_ema_multi_avg_fn(),默认值为0.999。衰减值应接近1.0,因为较小的值可能导致优化收敛问题。
torch.optim.swa_utils.get_ema_multi_avg_fn()会返回一个函数,该函数对权重应用以下指数移动平均(EMA)公式:
Wt+1EMA=αWtEMA+(1−α)WtmodelW^\textrm{EMA}{t+1} = \alpha W^\textrm{EMA}{t} + (1 - \alpha) W^\textrm{model}_t
Wt+1EMA=αWtEMA+(1−α)Wtmodel其中alpha为EMA衰减系数。
这里的模型model可以是任意torch.nn.Module对象。averaged_model会持续跟踪model参数的运行平均值。要更新这些平均值,应在optimizer.step()后使用update_parameters()函数。
>>> averaged_model.update_parameters(model)
对于SWA和EMA方法,这一调用通常在优化器执行step()后立即进行。在SWA的情况下,通常在训练初期会跳过若干步不执行此操作。
自定义平均策略
默认情况下,torch.optim.swa_utils.AveragedModel 会对提供的参数进行等权重滑动平均计算,但您也可以通过 avg_fn 或 multi_avg_fn 参数使用自定义平均函数:
avg_fn允许定义一个作用于每个参数元组(平均参数,模型参数)的函数,该函数应返回新的平均参数。multi_avg_fn允许定义更高效的操作,该操作同时作用于参数列表元组(平均参数列表,模型参数列表),例如使用torch._foreach*函数。此函数必须原地更新平均参数。
在以下示例中,ema_model 使用 avg_fn 参数计算指数移动平均:
>>> ema_avg = lambda averaged_model_parameter, model_parameter, num_averaged:\
>>> 0.9 * averaged_model_parameter + 0.1 * model_parameter
>>> ema_model = torch.optim.swa_utils.AveragedModel(model, avg_fn=ema_avg)
在以下示例中,ema_model 使用更高效的 multi_avg_fn 参数计算指数移动平均值:
>>> ema_model = AveragedModel(model, multi_avg_fn=get_ema_multi_avg_fn(0.9))
SWA 学习率调度策略
通常在使用随机权重平均(SWA)时,学习率会被设置为较高的恒定值。SWALR是一种学习率调度器,它会将学习率退火至固定值,然后保持恒定。例如,以下代码创建了一个调度器,该调度器会在每个参数组中将学习率从初始值线性退火至0.05,整个过程在5个epoch内完成:
>>> swa_scheduler = torch.optim.swa_utils.SWALR(optimizer, \
>>> anneal_strategy="linear", anneal_epochs=5, swa_lr=0.05)
您也可以通过设置 anneal_strategy="cos" 来使用余弦退火至固定值,而非线性退火。
批量归一化的处理
update_bn() 是一个实用函数,用于在训练结束时为 SWA 模型计算给定数据加载器 loader 上的批量归一化统计量。
>>> torch.optim.swa_utils.update_bn(loader, swa_model)
update_bn() 会对数据加载器中的每个元素应用 swa_model,并计算模型中每个批归一化层的激活统计量。
警告:update_bn() 假设数据加载器 loader 中的每个批次要么是张量,要么是张量列表(其中第一个元素是需要应用网络 swa_model 的张量)。
如果您的数据加载器结构不同,可以通过使用 swa_model 对数据集中的每个元素执行前向传递来更新 swa_model 的批归一化统计量。
整合应用:SWA方法
在以下示例中,swa_model是用于累积权重平均值的SWA模型。我们总共训练模型300个周期,并在第160个周期时切换至SWA学习率调度策略,同时开始收集参数的SWA平均值:
>>> loader, optimizer, model, loss_fn = ...
>>> swa_model = torch.optim.swa_utils.AveragedModel(model)
>>> scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=300)
>>> swa_start = 160
>>> swa_scheduler = SWALR(optimizer, swa_lr=0.05)
>>> >
>>> for epoch in range(300):
>>> for input, target in loader:
>>> optimizer.zero_grad()
>>> loss_fn(model(input), target).backward()
>>> optimizer.step()
>>> if epoch swa_start:
>>> swa_model.update_parameters(model)
>>> swa_scheduler.step()
>>> else:
>>> scheduler.step()
>>> >
>>> # Update bn statistics for the swa_model at the end
>>> torch.optim.swa_utils.update_bn(loader, swa_model)
>>> # Use swa_model to make predictions on test data
>>> preds = swa_model(test_input)
整合实现:EMA模型
在以下示例中,ema_model是指数移动平均(EMA)模型,它以0.999的衰减率累积权重值的指数衰减平均值。我们总共训练模型300个epoch,并立即开始收集EMA平均值。
>>> loader, optimizer, model, loss_fn = ...
>>> ema_model = torch.optim.swa_utils.AveragedModel(model, \
>>> multi_avg_fn=torch.optim.swa_utils.get_ema_multi_avg_fn(0.999))
>>> >
>>> for epoch in range(300):
>>> for input, target in loader:
>>> optimizer.zero_grad()
>>> loss_fn(model(input), target).backward()
>>> optimizer.step()
>>> ema_model.update_parameters(model)
>>> >
>>> # Update bn statistics for the ema_model at the end
>>> torch.optim.swa_utils.update_bn(loader, ema_model)
>>> # Use ema_model to make predictions on test data
>>> preds = ema_model(test_input)
swa_utils.AveragedModel | 实现随机权重平均(SWA)和指数移动平均(EMA)的模型平均功能。 |
|---|---|
swa_utils.SWALR | 将每个参数组的学习率退火至固定值。 |
torch.optim.swa_utils.get_ema_multi_avg_fn(decay=0.999)
获取适用于多个参数的指数移动平均(EMA)函数。
torch.optim.swa_utils.update_bn(loader, model, device=None)
更新模型中 BatchNorm 的 running_mean 和 running_var 缓冲区。
该方法会对数据加载器中的数据进行一次遍历,以估算模型中 BatchNorm 层的激活统计量。
参数
loader ([torch.utils.data.DataLoader](data.html#torch.utils.data.DataLoader "torch.utils.data.DataLoader"))- 用于计算激活统计量的数据集加载器。每个数据批次应为一个张量,或是第一个元素为包含数据的张量的列表/元组。model ( torch.nn.Module )- 需要更新 BatchNorm 统计量的模型。device ( torch.device , 可选)- 若设置,数据在传入模型前会被转移到指定device。
示例
>>> loader, model = ...
>>> torch.optim.swa_utils.update_bn(loader, model)
注意:update_bn工具假设loader中的每个数据批次要么是张量,要么是张量的列表或元组;在后一种情况下,假设应对应数据批次的列表或元组的第一个元素调用model.forward()。
复数
复数是可以表示为a+bj形式的数,其中a和b是实数,j称为虚数单位,满足方程j² = -1。复数在数学和工程领域频繁出现,特别是在信号处理等主题中。传统上,许多用户和库(例如TorchAudio)通过使用形状为(…,2)的浮点张量来表示复数数据,其中最后一个维度包含实部和虚部值。
使用复数数据类型的张量能够为处理复数提供更自然的用户体验。对复数张量的操作(例如torch.mv()、torch.matmul())可能比模拟复数的浮点张量操作更快且内存效率更高。PyTorch中涉及复数的操作经过优化,可使用向量化汇编指令和专用内核(例如LAPACK、cuBlas)。
注意:torch.fft模块中的频谱操作支持原生复数张量。
警告:复数张量目前是测试版功能,可能会发生变化。
创建复数张量
我们支持两种复数数据类型:torch.cfloat 和 torch.cdouble
>>> x = torch.randn(2,2, dtype=torch.cfloat)
>>> x
tensor([[-0.4621-0.0303j, -0.2438-0.5874j], [0.7706+0.1421j, 1.2110+0.1918j]])
注意:复数张量的默认数据类型由默认浮点数据类型决定。
如果默认浮点数据类型是 torch.float64,则推断复数具有 torch.complex128 数据类型;否则假定为 torch.complex64。
除 torch.linspace()、torch.logspace() 和 torch.arange() 外,所有工厂函数都支持复数张量。
从旧表示法迁移
当前通过形状为 (…,2) 的实数张量来模拟复数张量的用户,可以轻松改用 torch.view_as_complex() 和 torch.view_as_real() 在代码中实现复数张量。请注意,这些函数不会执行任何复制操作,而是返回输入张量的视图。
>>> x = torch.randn(3, 2)
>>> x
tensor([[0.6125, -0.1681], [-0.3773, 1.3487], [-0.0861, -0.7981]])
>>> y = torch.view_as_complex(x)
>>> y
tensor([0.6125-0.1681j, -0.3773+1.3487j, -0.0861-0.7981j])
>>> torch.view_as_real(y)
tensor([[0.6125, -0.1681], [-0.3773, 1.3487], [-0.0861, -0.7981]])
访问实部与虚部
可以通过 real 和 imag 属性来访问复数张量的实部和虚部。
注意:访问实部(real)和虚部(imag)属性不会分配任何内存,对实部和虚部张量进行的就地更新会直接作用于原始复数张量。此外,返回的实部和虚部张量不是连续存储的。
>>> y.real
tensor([0.6125, -0.3773, -0.0861])
>>> y.imag
tensor([-0.1681, 1.3487, -0.7981])>>> y.real.mul_(2)
tensor([1.2250, -0.7546, -0.1722])
>>> y
tensor([1.2250-0.1681j, -0.7546+1.3487j, -0.1722-0.7981j])
>>> y.real.stride()
(2,)
角度与绝对值
可以使用 torch.angle() 和 torch.abs() 计算复数张量的角度和绝对值。
>>> x1=torch.tensor([3j, 4+4j])
>>> x1.abs()
tensor([3.0000, 5.6569])
>>> x1.angle()
tensor([1.5708, 0.7854])
线性代数
许多线性代数运算,如 torch.matmul()、torch.linalg.svd()、torch.linalg.solve() 等,都支持复数运算。
如果您需要的操作当前尚未支持,请先搜索是否已有相关议题,如果没有,欢迎新建一个。
序列化
复杂张量可以进行序列化操作,支持将数据保存为复数形式的值。
>>> torch.save(y, 'complex_tensor.pt')
>>> torch.load('complex_tensor.pt')
tensor([0.6125-0.1681j, -0.3773+1.3487j, -0.0861-0.7981j])
自动微分
PyTorch 支持复数张量的自动微分功能。计算得到的梯度是共轭Wirtinger导数,其负方向正是梯度下降算法中使用的最陡下降方向。因此,所有现有的优化器都可以直接用于复数参数。更多细节请参阅文档复数自动微分。
优化器
从语义上讲,我们定义通过PyTorch优化器对复数参数进行优化的过程,等同于在复数参数经过torch.view_as_real()转换后的等效实数参数上执行相同优化器的优化步骤。更具体地说:
>>> params = [torch.rand(2, 3, dtype=torch.complex64) for _ in range(5)]
>>> real_params = [torch.view_as_real(p) for p in params]>>> complex_optim = torch.optim.AdamW(params)
>>> real_optim = torch.optim.AdamW(real_params)
real_optim和complex_optim会对参数计算相同的更新,尽管这两个优化器之间可能存在细微的数值差异,类似于foreach与forloop优化器之间、capturable与默认优化器之间的数值差异。更多细节请参阅https://pytorch.org/docs/stable/notes/numerical_accuracy.html。
具体来说,虽然可以将优化器处理复数张量的方式视为分别优化其p.real和p.imag部分,但实现细节并非完全如此。请注意,torch.view_as_real()等效操作会将复数张量转换为形状为 ( . . . , 2 ) (...,2) (...,2)的实数张量,而将复数张量拆分为两个张量会得到两个尺寸为 ( . . . ) (...) (...)的张量。这种区别对逐点优化器(如AdamW)没有影响,但会导致执行全局归约的优化器(如LBFGS)出现轻微差异。
目前我们没有执行逐张量归约的优化器,因此尚未定义此行为。如果您有需要精确定义此行为的用例,请提交issue。
以下子系统尚未完全支持:
- 量化
- JIT
- 稀疏张量
- 分布式
如果其中任何功能对您的用例有帮助,请先搜索是否已有相关issue,如果没有,请提交新issue。
DDP 通信钩子
https://docs.pytorch.org/docs/stable/ddp_comm_hooks.html
DDP 通信钩子是一个通用接口,通过覆盖 DistributedDataParallel 中的原生 allreduce 操作,来控制梯度在 worker 之间的通信方式。PyTorch 提供了若干内置通信钩子,用户可以轻松应用这些钩子来优化通信。此外,该钩子接口还支持用户自定义通信策略,以满足更高级的使用场景。
如何使用通信钩子?
用户只需在训练循环开始前,让DDP模型注册通信钩子即可使用该功能。具体操作如下:
torch.nn.parallel.DistributedDataParallel.register_comm_hook()
通信钩子的作用对象是什么?
通信钩子提供了一种灵活的方式来对梯度进行AllReduce操作。因此,它主要作用于AllReduce之前每个副本上的梯度,这些梯度会被分桶处理以提高通信与计算的重叠度。具体来说,torch.distributed.GradBucket表示待AllReduce的梯度张量桶。
class torch.distributed.GradBucket
该类主要将一个扁平化的梯度张量(由 buffer() 返回)传递给 DDP 通信钩子。
该张量可进一步分解为此存储桶中按参数划分的张量列表(通过 get_per_parameter_tensors() 返回),以应用分层操作。
torch.distributed.GradBucket.index(self: torch._C._distributed_c10d.GradBucket) → int
警告:由于在第一次迭代后会重建存储桶,因此不应依赖训练初期的索引。
返回值
存储若干连续层梯度的存储桶索引。
所有梯度都已进行分桶处理。
torch.distributed.GradBucket.buffer(self: torch._C._distributed_c10d.GradBucket) → torch.Tensor
返回
一个展平的1D torch.Tensor缓冲区,可以进一步分解为此存储桶中每个参数张量的列表。
torch.distributed.GradBucket.gradients(self: torch._C._distributed_c10d.GradBucket) → list [torch.Tensor]
返回
一个包含 torch.Tensor 的列表。列表中的每个张量对应一个梯度。
torch.distributed.GradBucket.is_last(self: torch._C._distributed_c10d.GradBucket) → bool
返回
该桶是否为迭代中最后一个进行全局归约的桶。
这也意味着该桶对应前向传播中的前几层。
torch.distributed.GradBucket.set_buffer(self: torch._C._distributed_c10d.GradBucket, buffer: torch.Tensor) → None
将存储桶中的张量替换为输入张量缓冲区。
torch.distributed.GradBucket.parameters(self: torch._C._distributed_c10d.GradBucket) → list [torch.Tensor]
返回
一个包含 torch.Tensor 的列表。列表中的每个张量对应一个模型参数。
默认通信钩子
默认通信钩子是简单的无状态钩子,因此在register_comm_hook中的输入状态要么是一个进程组,要么是None。
输入参数bucket是一个torch.distributed.GradBucket对象。
torch.distributed.algorithms.ddp_comm_hooks.default_hooks.allreduce_hook(process_group, bucket)
使用 GradBucket 张量调用 allreduce。
当所有工作节点的梯度张量聚合完成后,其 then 回调会计算均值并返回结果。
如果用户注册了这个 DDP 通信钩子,DDP 的结果预期将与未注册钩子的情况相同。
因此,这不会改变 DDP 的行为,用户可以将此作为参考,或修改此钩子来记录有用信息或实现其他目的,同时不影响 DDP 的行为。
示例:
>>> ddp_model.register_comm_hook(process_group, allreduce_hook)
返回类型
Future [Tensor]
torch.distributed.algorithms.ddp_comm_hooks.default_hooks.fp16_compress_hook(process_group, bucket)
通过将 GradBucket 转换为 torch.float16 并除以进程组大小来实现压缩。
这个 DDP 通信钩子实现了一种简单的梯度压缩方法:先将 GradBucket 张量转换为半精度浮点格式(torch.float16),然后除以进程组大小。
随后对所有 float16 梯度张量执行 allreduce 操作。当压缩后的梯度张量完成 allreduce 后,链式回调函数 decompress 会将其转换回输入数据类型(例如 float32)。
示例:
>>> ddp_model.register_comm_hook(process_group, fp16_compress_hook)
返回类型
Future [Tensor ]
torch.distributed.algorithms.ddp_comm_hooks.default_hooks.bf16_compress_hook(process_group, bucket)
警告:此 API 为实验性功能,需要 NCCL 版本高于 2.9.6。
该 DDP 通信钩子实现了一种简单的梯度压缩方法,将 GradBucket 张量转换为半精度 Brain 浮点格式 (torch.bfloat16),然后除以进程组大小。
该方法会对这些 bfloat16 梯度张量执行全归约操作。压缩后的梯度张量完成全归约后,链式回调 decompress 会将其转换回输入数据类型(如 float32)。
示例:
>>> ddp_model.register_comm_hook(process_group, bf16_compress_hook)
返回类型
Future [Tensor ]
此外,还提供了一个通信钩子包装器,用于支持 fp16_compress_hook() 或 bf16_compress_hook() 作为包装器,该包装器可与其他通信钩子结合使用。
torch.distributed.algorithms.ddp_comm_hooks.default_hooks.fp16_compress_wrapper(hook)***
将输入张量转换为torch.float16,并将钩子函数的结果转换回输入数据类型。
该包装器将给定DDP通信钩子的输入梯度张量转换为半精度浮点格式(torch.float16),并将给定钩子的结果张量转换回输入数据类型(如float32)。
因此,fp16_compress_hook等价于fp16_compress_wrapper(allreduce_hook)。
示例:
>>> state = PowerSGDState(process_group=process_group, matrix_approximation_rank=1, start_powerSGD_iter=10)>>> ddp_model.register_comm_hook(state, fp16_compress_wrapper(powerSGD_hook))
返回类型
Callable [[Any , GradBucket ], Future [Tensor ]]
torch.distributed.algorithms.ddp_comm_hooks.default_hooks.bf16_compress_wrapper(hook) s
警告:此 API 为实验性功能,需要 NCCL 版本高于 2.9.6。
该包装器将给定 DDP 通信钩子的输入梯度张量转换为半精度脑浮点格式(参考 https://en.wikipedia.org/wiki/Bfloat16_floating-point_format torch.bfloat16),并将钩子返回的结果张量转换回输入数据类型(如 float32)。
因此,bf16_compress_hook 等效于 bf16_compress_wrapper(allreduce_hook)。
示例:
>>> state = PowerSGDState(process_group=process_group, matrix_approximation_rank=1, start_powerSGD_iter=10)>>> ddp_model.register_comm_hook(state, bf16_compress_wrapper(powerSGD_hook))
返回类型
可调用对象 [[Any, GradBucket], Future[Tensor]]
PowerSGD 通信钩子
PowerSGD(Vogels等人,NeurIPS 2019)是一种梯度压缩算法,能够提供极高的压缩率并加速带宽受限的分布式训练。该算法需要维护一些超参数和内部状态。因此,PowerSGD通信钩子是一个有状态的钩子,用户需要提供如下定义的状态对象。
PowerSGD 状态
class torch.distributed.algorithms.ddp_comm_hooks.powerSGD_hook.PowerSGDState(process_group, matrix_approximation_rank=1, start_powerSGD_iter=1000, min_compression_rate=2, use_error_feedback=True, warm_start=True, orthogonalization_epsilon=0, random_seed=0, compression_stats_logging_frequency=10000, batch_tensors_with_same_shape=False)
在训练过程中,同时存储算法的超参数和所有梯度的内部状态。
其中,matrix_approximation_rank 和 start_powerSGD_iter 是用户需要调优的主要超参数。
出于性能考虑,建议保持二进制超参数 use_error_feedback 和 warm_start 为开启状态。
1、matrix_approximation_rank 控制压缩低秩张量的大小,决定压缩率。秩越低,压缩效果越强。
1.1、如果 matrix_approximation_rank 设置过低,模型需要更多训练步数才能达到预期质量,甚至可能永远无法达到并导致精度损失。
1.2、增加 matrix_approximation_rank 会显著提升压缩计算成本,但超过特定阈值后精度可能不再继续提升。
调优建议:从1开始,按2的倍数递增(如指数网格搜索:1、2、4…),直至获得满意精度。通常只需使用1-4的小值。某些NLP任务(见原论文附录D)可能需要将该值提升至32。
2、start_powerSGD_iter 会延迟PowerSGD压缩至指定步数,此前使用普通allreduce。这种普通allreduce+PowerSGD的混合方案能有效提升精度,即使使用较小的matrix_approximation_rank。因为训练初期对梯度误差非常敏感,过早压缩可能导致训练陷入次优轨迹,造成不可逆的精度影响。
调优建议:从总训练步数的10%开始,逐步增加直至精度达标。若训练存在预热阶段,start_powerSGD_iter 通常不应小于预热步数。
3、min_compression_rate 是层压缩所需的最小压缩率。由于压缩会产生计算开销,仅当带宽节省足够时(满足 (num_rows + num_cols) * matrix_approximation_rank * min_compression_rate < num_rows * num_cols)才值得压缩。若不满足阈值,张量将直接进行非压缩allreduce。
PowerSGD压缩启动后,每 compression_stats_logging_frequency 次迭代记录一次压缩统计信息。
4、orthogonalization_epsilon 是在正交化步骤中添加到每个归一化矩阵列的极小值(如1e-8),防止全零列导致的除零错误。若已通过其他方式(如批归一化)预防,建议设为0以保证精度。
5、batch_tensors_with_same_shape 控制是否对同形状张量进行批量压缩/解压以提高并行度。注意:需同时增加桶大小(即DDP构造器的bucket_cap_mb参数)使同形状张量出现在同一桶中,但这可能降低计算与通信的重叠度,并因张量堆叠增加内存占用。当压缩/解压计算成为瓶颈时建议启用。
警告:若启用误差反馈或预热,DDP中 start_powerSGD_iter 的最小允许值为2。因为DDP在迭代1时会执行重建桶的内部优化,这与重建前记忆的任何张量都可能产生冲突。
PowerSGD 钩子
警告:PowerSGD 通常需要额外分配与模型梯度大小相同的内存空间来实现误差反馈机制,这可以补偿有偏压缩通信带来的误差并提高计算精度。
警告:PowerSGD 钩子可能与 Apex 自动混合精度包 产生冲突。建议改用 PyTorch 原生自动混合精度包。
torch.distributed.algorithms.ddp_comm_hooks.powerSGD_hook.powerSGD_hook(state, bucket)
实现PowerSGD算法。
该DDP通信钩子实现了论文中描述的PowerSGD梯度压缩算法。当所有工作节点的梯度张量聚合完成后,该钩子按以下步骤应用压缩:
1、将输入的一维扁平化梯度张量视为按参数分组的张量列表,并将所有张量分为两组:
1.1 应在allreduce前进行压缩的张量,因为压缩能显著节省带宽;
1.2 其余张量(包括所有向量张量如偏置)将直接进行非压缩的allreduce。
2、处理未压缩张量:
2.1 为这些张量分配连续内存空间,并作为批次整体执行非压缩的allreduce;
2.2 将单个未压缩张量从连续内存复制回输入张量。
3、处理需要PowerSGD压缩的张量:
3.1 对每个张量M,创建两个低秩张量P和Q用于分解M(满足M=PQ^T),其中Q初始化为标准正态分布并进行正交化;
3.2 计算Ps中的每个P,其值为MQ;
3.3 将Ps作为批次整体执行allreduce;
3.4 对Ps中的每个P进行正交化;
3.5 计算Qs中的每个Q,其近似等于M^TP;
3.6 将Qs作为批次整体执行allreduce;
3.7 计算所有压缩张量中的M,其近似等于PQ^T。
注意:该通信钩子在初始state.start_powerSGD_iter次迭代中强制使用标准allreduce。这不仅能更好地平衡加速与精度,也有助于为未来通信钩子开发者抽象DDP内部优化的复杂性。
参数说明
state (PowerSGDState)– 用于配置压缩率及支持误差反馈、热启动等的状态信息。主要需调优matrix_approximation_rank、start_powerSGD_iter和min_compression_rate参数。bucket (dist.GradBucket)– 存储批量处理的多变量一维扁平化梯度张量的桶。注意DDP通信钩子仅支持单进程单设备模式,故该桶中仅存储一个张量。
返回值
通信操作的Future句柄,该操作会原地更新梯度。
返回类型
Future[Tensor]
使用示例:
>>> state = PowerSGDState(process_group=process_group, matrix_approximation_rank=1, start_powerSGD_iter=10, min_compression_rate=0.5)>>> ddp_model.register_comm_hook(state, powerSGD_hook)
torch.distributed.algorithms.ddp_comm_hooks.powerSGD_hook.batched_powerSGD_hook(state, bucket)
实现简化的PowerSGD算法。
该DDP通信钩子实现了论文中描述的简化版PowerSGD梯度压缩算法。此变体不会逐层压缩梯度,而是压缩将所有梯度批量处理后的扁平化输入张量。因此,它比powerSGD_hook()更快,但通常会导致精度大幅下降,除非matrix_approximation_rank设为1。
警告:在此增加matrix_approximation_rank不一定能提高精度,因为未经行列对齐的批量参数张量处理可能会破坏低秩结构。因此,用户应优先考虑使用powerSGD_hook(),仅当matrix_approximation_rank为1时可获得满意精度时,才考虑此变体。
当所有工作节点的梯度张量聚合后,该钩子按以下步骤应用压缩:
1、将扁平化的1D梯度输入张量视为带0填充的方形张量M;
2、创建两个低秩张量P和Q用于分解M,满足M = PQ^T,其中Q从标准正态分布初始化并进行正交化;
3、计算P = MQ;
4、执行P的Allreduce操作;
5、对P进行正交化;
6、计算Q ≈ M^TP;
7、执行Q的Allreduce操作;
8、计算M ≈ PQ^T;
9、将输入张量截断至原始长度。
注意:该通信钩子在前state.start_powerSGD_iter次迭代中强制使用普通allreduce。这不仅让用户更好地权衡加速与精度,也有助于为未来通信钩子开发者抽象DDP内部优化的复杂性。
参数说明
state (PowerSGDState)– 用于配置压缩率及支持误差反馈、热启动等的状态信息。主要需调整matrix_approximation_rank和start_powerSGD_iter。bucket (dist.GradBucket)– 存储批量多变量张量的1D扁平梯度张量的桶。注意DDP通信钩子仅支持单进程单设备模式,故桶中仅存一个张量。
返回值
通信操作的Future处理器,该处理器会原地更新梯度。
返回类型
Future[Tensor]
示例:
>>> state = PowerSGDState(process_group=process_group, matrix_approximation_rank=1)>>> ddp_model.register_comm_hook(state, batched_powerSGD_hook)
调试通信钩子
顾名思义,调试通信钩子仅用于调试和性能优化目的。
警告:调试通信钩子不一定能输出正确结果。
torch.distributed.algorithms.ddp_comm_hooks.debugging_hooks.noop_hook(_, bucket)
返回一个包装输入参数的 future 对象,使其成为无操作且不产生任何通信开销的调用。
该钩子仅应用于 allreduce 优化的性能余量分析,而非常规的梯度同步场景。
例如,若注册此钩子后观察到训练速度提升不足10%,通常表明 allreduce 并非当前场景的性能瓶颈。
当 GPU 跟踪数据难以获取或跟踪分析过于复杂时,此类检测手段尤为有用,特别是涉及以下因素时:
- allreduce 与计算的重叠情况
- 跨 rank 的异步问题
示例:
>>> ddp_model.register_comm_hook(None, noop_hook)
返回类型
Future [Tensor ]
通信钩子的检查点保存
状态型通信钩子可以作为模型检查点的一部分进行保存,以便支持训练器的重启。要使钩子可序列化,需要定义 __setstate__ 和 __getstate__ 方法。
警告:__getstate__ 方法应从返回的字典中排除不可序列化的属性。
警告:__setstate__ 方法应正确初始化从提供的 state 中排除的不可序列化属性。
PowerSGDState 已实现 __setstate__ 和 __getstate__ 方法,可作为参考使用。
class torch.distributed.algorithms.ddp_comm_hooks.powerSGD_hook.PowerSGDState
__getstate__()
返回一个将被序列化并保存的 Dict[str, Any] 字典。
process_group 不可序列化,因此会从返回的状态中排除。
__setstate__(state)
将提供的 state 设置到当前 PowerSGDState 实例中。
process_group 默认设置为缺省值。
以下是一个保存和重新加载 PowerSGD 状态及钩子的简单端到端示例。
import os
import sys
import tempfile
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mpfrom torch.nn.parallel import DistributedDataParallel
from torch.distributed.algorithms.ddp_comm_hooks import powerSGD_hook as powerSGDclass SimpleModel(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(24,24)self.relu = nn.ReLU()self.fc2 = nn.Linear(24,12)def forward(self, x):return self.fc2(self.relu(self.fc1(x)))def setup(rank, world_size):os.environ['MASTER_ADDR'] = 'localhost'os.environ['MASTER_PORT'] = '12355'# initialize the process groupdist.init_process_group("nccl", rank=rank, world_size=world_size)def cleanup():dist.destroy_process_group()def run_demo(demo_fn, world_size):mp.spawn(demo_fn,args=(world_size,),nprocs=world_size,join=True)def demo_serialization(rank, world_size):setup(rank, world_size)CHECKPOINT = tempfile.gettempdir() + "/checkpoint.pt"model = SimpleModel().to(rank)ddp_model = DistributedDataParallel(model, device_ids=[rank])powersgd_hook = powerSGD.powerSGD_hookpowersgd_state = powerSGD.PowerSGDState(process_group=None)optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)ddp_model.register_comm_hook(powersgd_state, powersgd_hook)state = {'state_dict': ddp_model.state_dict(),'comm_hook': powersgd_hook,'comm_hook_state': powersgd_state}if rank == 0:torch.save(state, CHECKPOINT)dist.barrier()map_location = {'cuda:%d' % 0: 'cuda:%d' % rank}checkpoint = torch.load(CHECKPOINT, map_location=map_location)new_ddp_model = DistributedDataParallel(SimpleModel().to(rank), device_ids=[rank])new_ddp_model.load_state_dict(checkpoint['state_dict'])powersgd_hook = checkpoint['comm_hook']powersgd_state = checkpoint['comm_hook_state']new_ddp_model.register_comm_hook(powersgd_state, powersgd_hook)if rank == 0:os.remove(CHECKPOINT)cleanup()if __name__ == "__main__":n_gpus = torch.cuda.device_count()assert n_gpus >= 2, f"Requires at least 2 GPUs to run, but got {n_gpus}"world_size = n_gpusrun_demo(demo_serialization, world_size)
致谢
特别感谢 PowerSGD 论文作者 Thijs Vogels 对 PowerSGD 通信钩子进行的代码审查,以及提供的对比实验。这些实验表明,PowerSGD 通信钩子的性能与原始论文中的实现相当。
量化
警告:量化功能目前处于测试阶段,可能会发生变化。
量化技术简介
量化是指以低于浮点精度的位宽执行计算并存储张量的技术。量化模型会以降低的精度(而非全精度浮点值)来执行部分或全部张量运算。这能实现更紧凑的模型表示,并可在多数硬件平台上使用高性能向量化运算。PyTorch支持INT8量化,相比典型的FP32模型,可使模型大小缩减4倍,内存带宽需求降低4倍。硬件对INT8运算的支持通常比FP32计算快2到4倍。量化本质上是一种加速推理的技术,目前仅支持量化算子的前向传播。
PyTorch支持多种深度学习模型量化方法。大多数情况下,模型会先以FP32格式训练,再转换为INT8格式。此外,PyTorch还支持量化感知训练,该方法通过伪量化模块在前向和反向传播中模拟量化误差(注意:所有计算仍以浮点形式进行)。在量化感知训练完成后,PyTorch会提供转换函数将训练好的模型转为低精度格式。
在底层实现上,PyTorch提供了量化张量的表示方法及其运算机制。开发者可直接用这些工具构建完全或部分采用低精度计算的模型。更高级的API则封装了将FP32模型转换为低精度模型的典型工作流,同时将精度损失降至最低。
量化API概览
PyTorch提供三种不同的量化模式:即时模式量化(Eager Mode Quantization)、FX图模式量化(维护状态)和PyTorch 2导出量化。
即时模式量化是测试版功能。用户需要手动进行算子融合并指定量化和反量化的位置,且仅支持模块而不支持函数式操作。
FX图模式量化是PyTorch中的自动化量化工作流,目前作为原型功能处于维护状态(因PyTorch 2导出量化的推出)。它在即时模式量化基础上增加了对函数式操作的支持并自动化了量化流程,但用户可能需要重构模型使其兼容FX图模式量化(需能被torch.fx符号追踪)。注意FX图模式量化不适用于任意模型,因为某些模型可能无法被符号追踪。我们将把它集成到torchvision等领域库中,用户可对类似领域库中的模型进行量化。对于任意模型,我们会提供通用指南,但实际使用时用户可能需要熟悉torch.fx,特别是如何使模型可被符号追踪。
PyTorch 2导出量化是全新的全图模式量化工作流,作为原型功能在PyTorch 2.1中发布。相比FX图模式量化使用的torch.fx.symbolic_trace(14K模型72.7%捕获率),新的程序捕获方案torch.export能达到更高覆盖率(14K模型88.8%)。虽然torch.export仍对某些Python结构有限制,且需要用户参与支持导出模型的动态特性,但整体优于之前的方案。PyTorch 2导出量化专为torch.export捕获的模型设计,兼顾建模用户和后端开发者的灵活性及生产力。主要特性包括:
1、可编程API用于配置模型量化方式,支持更多用例
2、简化用户体验,用户和开发者只需通过单一对象(Quantizer)表达量化意图和后端支持
3、可选参考量化模型表示法,能用整数运算表示量化计算,更接近硬件实际量化计算
新用户建议优先尝试PyTorch 2导出量化,若效果不佳可改用即时模式量化。
下表对比三种量化模式的差异:
| 即时模式量化 | FX图模式量化 | PyTorch 2导出量化 | |
|---|---|---|---|
| 发布状态 | 测试版 | 原型(维护中) | 原型 |
| 算子融合 | 手动 | 自动 | 自动 |
| 量化/反量化位置 | 手动 | 自动 | 自动 |
| 模块量化 | 支持 | 支持 | 支持 |
| 函数式/Torch运算量化 | 手动 | 自动 | 支持 |
| 自定义支持 | 有限支持 | 完全支持 | 完全支持 |
| 量化模式支持 | 训练后量化:静态、动态、仅权重量化感知训练:静态 | 训练后量化:静态、动态、仅权重量化感知训练:静态 | 由后端特定Quantizer定义 |
| 输入/输出模型类型 | torch.nn.Module | torch.nn.Module(可能需要重构以兼容) | torch.fx.GraphModule(由torch.export捕获) |
支持三种量化类型:
1、动态量化(权重量化,激活值以浮点存储但在计算时量化)
2、静态量化(权重量化,激活值量化,需训练后校准)
3、量化感知训练(权重量化,激活值量化,训练期间模拟量化数值)
详见我们关于PyTorch量化介绍的博客文章,了解这些量化类型的权衡分析。
静态与动态量化的算子覆盖范围如下表所示:
| 静态量化 | 动态量化 | |
|---|---|---|
| nn.Linear nn.Conv1d/2d/3d | 支持 支持 | 支持 不支持 |
| nn.LSTM nn.GRU | 支持(通过自定义模块) 不支持 | 支持 支持 |
| nn.RNNCell nn.GRUCell nn.LSTMCell | 不支持 不支持 不支持 | 支持 支持 支持 |
| nn.EmbeddingBag | 支持(激活值为fp32) | 支持 |
| nn.Embedding | 支持 | 支持 |
| nn.MultiheadAttention | 支持(通过自定义模块) | 不支持 |
| 激活值 | 广泛支持 | 保持不变,计算保持fp32 |
即时模式量化
如需了解量化流程的总体介绍(包括不同类型的量化技术),请参阅通用量化流程。
训练后动态量化
这是应用起来最简单的量化形式,其中权重会预先量化,而激活值在推理过程中动态量化。这种量化适用于模型执行时间主要消耗在从内存加载权重而非矩阵乘法计算的情况。对于小批量大小的LSTM和Transformer类型模型来说,这种情况尤为典型。
示意图:
# original model
# all tensors and computations are in floating point
previous_layer_fp32 -- linear_fp32 -- activation_fp32 -- next_layer_fp32/
linear_weight_fp32# dynamically quantized model
# linear and LSTM weights are in int8
previous_layer_fp32 -- linear_int8_w_fp32_inp -- activation_fp32 -- next_layer_fp32/linear_weight_int8
PTDQ API 示例:
import torch# define a floating point model
class M(torch.nn.Module):def __init__(self):super().__init__()self.fc = torch.nn.Linear(4, 4)def forward(self, x):x = self.fc(x)return x# create a model instance
model_fp32 = M()
# create a quantized model instance
model_int8 = torch.ao.quantization.quantize_dynamic(model_fp32, # the original model{torch.nn.Linear}, # a set of layers to dynamically quantizedtype=torch.qint8) # the target dtype for quantized weights# run the model
input_fp32 = torch.randn(4, 4, 4, 4)
res = model_int8(input_fp32)
要了解更多关于动态量化的信息,请参阅我们的动态量化教程。
训练后静态量化
训练后静态量化(PTQ static)会对模型的权重和激活值进行量化处理。它会尽可能将激活值融合到前驱层中。该方法需要通过代表性数据集进行校准,以确定激活值的最佳量化参数。训练后静态量化通常适用于需要同时节省内存带宽和计算资源的场景,CNN网络是典型用例。
在应用训练后静态量化前,我们可能需要修改模型结构。具体请参阅Eager模式静态量化的模型准备。
示意图:
# original model
# all tensors and computations are in floating point
previous_layer_fp32 -- linear_fp32 -- activation_fp32 -- next_layer_fp32/linear_weight_fp32# statically quantized model
# weights and activations are in int8
previous_layer_int8 -- linear_with_activation_int8 -- next_layer_int8/linear_weight_int8
PTSQ API 示例:
import torch# define a floating point model where some layers could be statically quantized
class M(torch.nn.Module):def __init__(self):super().__init__()# QuantStub converts tensors from floating point to quantizedself.quant = torch.ao.quantization.QuantStub()self.conv = torch.nn.Conv2d(1, 1, 1)self.relu = torch.nn.ReLU()# DeQuantStub converts tensors from quantized to floating pointself.dequant = torch.ao.quantization.DeQuantStub()def forward(self, x):# manually specify where tensors will be converted from floating# point to quantized in the quantized modelx = self.quant(x)x = self.conv(x)x = self.relu(x)# manually specify where tensors will be converted from quantized# to floating point in the quantized modelx = self.dequant(x)return x# create a model instance
model_fp32 = M()# model must be set to eval mode for static quantization logic to work
model_fp32.eval()# attach a global qconfig, which contains information about what kind
# of observers to attach. Use 'x86' for server inference and 'qnnpack'
# for mobile inference. Other quantization configurations such as selecting
# symmetric or asymmetric quantization and MinMax or L2Norm calibration techniques
# can be specified here.
# Note: the old 'fbgemm' is still available but 'x86' is the recommended default
# for server inference.
# model_fp32.qconfig = torch.ao.quantization.get_default_qconfig('fbgemm')
model_fp32.qconfig = torch.ao.quantization.get_default_qconfig('x86')# Fuse the activations to preceding layers, where applicable.
# This needs to be done manually depending on the model architecture.
# Common fusions include `conv + relu` and `conv + batchnorm + relu`
model_fp32_fused = torch.ao.quantization.fuse_modules(model_fp32, [['conv', 'relu']])# Prepare the model for static quantization. This inserts observers in # the model that will observe activation tensors during calibration.
model_fp32_prepared = torch.ao.quantization.prepare(model_fp32_fused)# calibrate the prepared model to determine quantization parameters for activations
# in a real world setting, the calibration would be done with a representative dataset
input_fp32 = torch.randn(4, 1, 4, 4)
model_fp32_prepared(input_fp32)# Convert the observed model to a quantized model. This does several things:
# quantizes the weights, computes and stores the scale and bias value to be # used with each activation tensor, and replaces key operators with quantized
# implementations.
model_int8 = torch.ao.quantization.convert(model_fp32_prepared)# run the model, relevant calculations will happen in int8
res = model_int8(input_fp32)
要了解更多关于静态量化的信息,请参阅静态量化教程。
静态量化的量化感知训练
量化感知训练(QAT)通过在训练过程中模拟量化效应,相比其他量化方法能实现更高精度。我们可以对静态量化、动态量化或仅权重量化实施QAT。训练期间,所有计算均以浮点数执行,fake_quant模块通过钳位和舍入操作模拟INT8量化效应。模型转换后,权重和激活值会被量化,且激活值会尽可能融合到前驱层中。该方法通常与CNN结合使用,相比静态量化能获得更高精度。
在应用训练后静态量化前,可能需要修改模型结构。详见Eager模式静态量化的模型准备。
示意图:
# original model
# all tensors and computations are in floating point
previous_layer_fp32 -- linear_fp32 -- activation_fp32 -- next_layer_fp32/linear_weight_fp32# model with fake_quants for modeling quantization numerics during training
previous_layer_fp32 -- fq -- linear_fp32 -- activation_fp32 -- fq -- next_layer_fp32/linear_weight_fp32 -- fq# quantized model
# weights and activations are in int8
previous_layer_int8 -- linear_with_activation_int8 -- next_layer_int8/linear_weight_int8
QAT API 示例:
import torch# define a floating point model where some layers could benefit from QAT
class M(torch.nn.Module):def __init__(self):super().__init__()# QuantStub converts tensors from floating point to quantizedself.quant = torch.ao.quantization.QuantStub()self.conv = torch.nn.Conv2d(1, 1, 1)self.bn = torch.nn.BatchNorm2d(1)self.relu = torch.nn.ReLU()# DeQuantStub converts tensors from quantized to floating pointself.dequant = torch.ao.quantization.DeQuantStub()def forward(self, x):x = self.quant(x)x = self.conv(x)x = self.bn(x)x = self.relu(x)x = self.dequant(x)return x# create a model instance
model_fp32 = M()# model must be set to eval for fusion to work
model_fp32.eval()# attach a global qconfig, which contains information about what kind
# of observers to attach. Use 'x86' for server inference and 'qnnpack'
# for mobile inference. Other quantization configurations such as selecting
# symmetric or asymmetric quantization and MinMax or L2Norm calibration techniques
# can be specified here.
# Note: the old 'fbgemm' is still available but 'x86' is the recommended default
# for server inference.
# model_fp32.qconfig = torch.ao.quantization.get_default_qconfig('fbgemm')
model_fp32.qconfig = torch.ao.quantization.get_default_qat_qconfig('x86')# fuse the activations to preceding layers, where applicable
# this needs to be done manually depending on the model architecture
model_fp32_fused = torch.ao.quantization.fuse_modules(model_fp32, [['conv', 'bn', 'relu']])# Prepare the model for QAT. This inserts observers and fake_quants in # the model needs to be set to train for QAT logic to work
# the model that will observe weight and activation tensors during calibration.
model_fp32_prepared = torch.ao.quantization.prepare_qat(model_fp32_fused.train())# run the training loop (not shown)
training_loop(model_fp32_prepared)# Convert the observed model to a quantized model. This does several things:
# quantizes the weights, computes and stores the scale and bias value to be # used with each activation tensor, fuses modules where appropriate, # and replaces key operators with quantized implementations.
model_fp32_prepared.eval()
model_int8 = torch.ao.quantization.convert(model_fp32_prepared)# run the model, relevant calculations will happen in int8
res = model_int8(input_fp32)
要了解更多关于量化感知训练的内容,请参阅 QAT 教程。
动态图模式静态量化的模型准备
在实施动态图模式量化前,需要对模型定义进行一些修改。这是因为当前量化是按模块逐个进行的。具体而言,对于所有量化技术,用户需要:
1、将所有需要输出重量化(因此具有额外参数)的操作从函数形式转换为模块形式(例如使用 torch.nn.ReLU 替代 torch.nn.functional.relu)。
2、通过为子模块分配 .qconfig 属性或指定 qconfig_mapping 来确定模型的哪些部分需要量化。例如,设置 model.conv1.qconfig = None 表示 model.conv 层不会被量化,而设置 model.linear1.qconfig = custom_qconfig 表示 model.linear1 的量化设置将使用 custom_qconfig 而非全局配置。
对于需要量化激活值的静态量化技术,用户还需额外完成以下步骤:
1、使用 QuantStub 和 DeQuantStub 模块指定激活值的量化和反量化位置。
2、使用 FloatFunctional 封装需要特殊量化处理的张量操作(如 add 和 cat 等需要特殊处理以确定输出量化参数的操作)。
3、模块融合:将操作/模块合并为单一模块以获得更高的精度和性能。通过 fuse_modules() API 实现,该接口接收待融合模块列表。当前支持的融合组合包括:[Conv, Relu]、[Conv, BatchNorm]、[Conv, BatchNorm, Relu]、[Linear, Relu]。
(原型 - 维护模式)FX 图模式量化
训练后量化(Post Training Quantization)包含多种量化类型(仅权重量化、动态量化和静态量化),其配置通过 qconfig_mapping(prepare_fx 函数的一个参数)来完成。
FXPTQ API 示例:
import torch
from torch.ao.quantization import (get_default_qconfig_mapping, get_default_qat_qconfig_mapping, QConfigMapping, )
import torch.ao.quantization.quantize_fx as quantize_fx
import copymodel_fp = UserModel()#
# post training dynamic/weight_only quantization
## we need to deepcopy if we still want to keep model_fp unchanged after quantization since quantization apis change the input model
model_to_quantize = copy.deepcopy(model_fp)
model_to_quantize.eval()
qconfig_mapping = QConfigMapping().set_global(torch.ao.quantization.default_dynamic_qconfig)
# a tuple of one or more example inputs are needed to trace the model
example_inputs = (input_fp32)
# prepare
model_prepared = quantize_fx.prepare_fx(model_to_quantize, qconfig_mapping, example_inputs)
# no calibration needed when we only have dynamic/weight_only quantization
# quantize
model_quantized = quantize_fx.convert_fx(model_prepared)#
# post training static quantization
#model_to_quantize = copy.deepcopy(model_fp)
qconfig_mapping = get_default_qconfig_mapping("qnnpack")
model_to_quantize.eval()
# prepare
model_prepared = quantize_fx.prepare_fx(model_to_quantize, qconfig_mapping, example_inputs)
# calibrate (not shown)
# quantize
model_quantized = quantize_fx.convert_fx(model_prepared)#
# quantization aware training for static quantization
#model_to_quantize = copy.deepcopy(model_fp)
qconfig_mapping = get_default_qat_qconfig_mapping("qnnpack")
model_to_quantize.train()
# prepare
model_prepared = quantize_fx.prepare_qat_fx(model_to_quantize, qconfig_mapping, example_inputs)
# training loop (not shown)
# quantize
model_quantized = quantize_fx.convert_fx(model_prepared)#
# fusion
#
model_to_quantize = copy.deepcopy(model_fp)
model_fused = quantize_fx.fuse_fx(model_to_quantize)
请参考以下教程深入了解 FX 图模式量化:
- FX 图模式量化使用指南
- FX 图模式训练后静态量化
- FX 图模式训练后动态量化
(原型)PyTorch 2 导出量化
API 示例:
import torch
from torch.ao.quantization.quantize_pt2e import prepare_pt2e
from torch.export import export_for_training
from torch.ao.quantization.quantizer import (XNNPACKQuantizer, get_symmetric_quantization_config, )class M(torch.nn.Module):def __init__(self):super().__init__()self.linear = torch.nn.Linear(5, 10)def forward(self, x):return self.linear(x)# initialize a floating point model
float_model = M().eval()# define calibration function
def calibrate(model, data_loader):model.eval()with torch.no_grad():for image, target in data_loader:model(image)# Step 1、program capture
# NOTE: this API will be updated to torch.export API in the future, but the captured
# result should mostly stay the same m = export_for_training(m, example_inputs).module()
# we get a model with aten ops# Step 2、quantization
# backend developer will write their own Quantizer and expose methods to allow
# users to express how they
# want the model to be quantized
quantizer = XNNPACKQuantizer().set_global(get_symmetric_quantization_config())
# or prepare_qat_pt2e for Quantization Aware Training
m = prepare_pt2e(m, quantizer)# run calibration
# calibrate(m, sample_inference_data)
m = convert_pt2e(m)# Step 3、lowering
# lower to target backend
请按照以下教程开始使用 PyTorch 2 导出量化功能:
面向模型开发者:
- PyTorch 2 导出训练后量化
- 通过 Inductor 使用 X86 后端的 PyTorch 2 导出训练后量化
- PyTorch 2 导出量化感知训练
面向后端开发者(请同时查阅所有面向模型开发者的文档):
- 如何为 PyTorch 2 导出量化编写量化器
量化技术栈
量化是指将浮点模型转换为量化模型的过程。从高层次来看,量化技术栈可分为两个部分:
1、量化模型的构建模块或抽象层
2、将浮点模型转换为量化模型的量化流程构建模块或抽象层
量化模型
量化张量
为了在PyTorch中实现量化,我们需要能够用张量表示量化数据。量化张量允许存储量化数据(以int8/uint8/int32形式表示)以及量化参数(如scale和zero_point)。量化张量不仅支持量化格式数据的序列化,还能实现许多有用的操作,使量化运算变得简单。
PyTorch支持逐张量和逐通道的对称与非对称量化。逐张量量化意味着张量中的所有值都采用相同的量化参数进行量化。逐通道量化则是指对于每个维度(通常是张量的通道维度),张量中的值使用不同的量化参数进行量化。这种方式可以减少将张量转换为量化值时的误差,因为异常值只会影响其所在的通道,而不会波及整个张量。
映射过程通过以下公式将浮点张量转换实现:
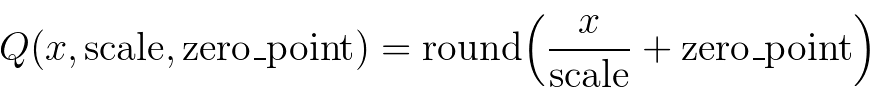
需注意,我们确保浮点数中的零值在量化后能无误差表示,从而保证像填充(padding)这类操作不会引入额外的量化误差。
以下是量化张量的几个关键属性:
- QScheme (torch.qscheme): 枚举类型,指定张量的量化方式
- torch.per_tensor_affine
- torch.per_tensor_symmetric
- torch.per_channel_affine
- torch.per_channel_symmetric
- dtype (torch.dtype): 量化张量的数据类型
- torch.quint8
- torch.qint8
- torch.qint32
- torch.float16
- 量化参数 (根据QScheme变化): 所选量化方式的参数
- torch.per_tensor_affine的量化参数包括:
- scale (浮点型)
- zero_point (整型)
- torch.per_channel_affine的量化参数包括:
- per_channel_scales (浮点型列表)
- per_channel_zero_points (整型列表)
- axis (整型)
- torch.per_tensor_affine的量化参数包括:
量化与反量化
模型的输入和输出是浮点张量,但量化模型中的激活值是量化后的,因此我们需要运算符来实现浮点张量与量化张量之间的转换。
- 量化(浮点 → 量化)
torch.quantize_per_tensor(x, scale, zero_point, dtype)torch.quantize_per_channel(x, scales, zero_points, axis, dtype)torch.quantize_per_tensor_dynamic(x, dtype, reduce_range)to(torch.float16)
- 反量化(量化 → 浮点)
quantized_tensor.dequantize()- 对torch.float16张量调用反量化会将其转换回torch.floattorch.dequantize(x)
量化运算符/模块
- 量化运算符是指以量化张量作为输入,并输出量化张量的运算符。
- 量化模块是执行量化操作的PyTorch模块,通常用于带权重的操作(如线性运算和卷积运算)。
量化引擎
当执行量化模型时,qengine(torch.backends.quantized.engine)用于指定执行时使用的后端。必须确保qengine与量化模型在量化激活值和权重的数值范围方面兼容。
量化流程
Observer 与 FakeQuantize
- Observer 是 PyTorch 模块,用于:
- 收集张量的统计信息(如通过 Observer 的张量的最小值和最大值)
- 根据收集的张量统计信息计算量化参数
- FakeQuantize 是 PyTorch 模块,用于:
- 模拟网络中对张量的量化操作(执行量化/反量化)
- 既可以根据 Observer 收集的统计信息计算量化参数,也可以学习量化参数
QConfig
- QConfig 是一个由 Observer 或 FakeQuantize 模块类组成的命名元组,可通过 qscheme、dtype 等进行配置,用于设定运算符的观测方式
- 为运算符/模块提供量化配置
- 支持不同类型的 Observer/FakeQuantize
- 数据类型 (dtype)
- 量化方案 (qscheme)
- quant_min/quant_max:可用于模拟低精度张量
- 当前支持对激活值和权重的配置
- 我们会根据为运算符或模块配置的 qconfig,插入输入/权重/输出观测器
- 为运算符/模块提供量化配置
通用量化流程
通常,流程如下:
- 准备阶段
- 根据用户指定的量化配置(qconfig)插入Observer/FakeQuantize模块
- 校准/训练阶段(取决于是训练后量化还是量化感知训练)
- 允许Observer收集统计信息,或让FakeQuantize模块学习量化参数
- 转换阶段
- 将校准/训练后的模型转换为量化模型
量化存在不同模式,可以从两个维度进行分类:
从应用量化流程的时机来看:
1、训练后量化(在训练完成后应用量化,量化参数基于校准样本数据计算得出)
2、量化感知训练(在训练过程中模拟量化,使量化参数能够与模型一起通过训练数据学习)
从算子量化的方式来看:
- 仅权重量化(仅对权重进行静态量化)
- 动态量化(权重静态量化,激活值动态量化)
- 静态量化(权重和激活值均静态量化)
在同一量化流程中可以混合使用不同的算子量化方式。例如,我们可以实现同时包含静态和动态量化算子的训练后量化方案。
量化支持矩阵
量化模式支持
| 量化模式 | 数据集要求 | 最佳适用场景 | 精度 | 备注 | ||
|---|---|---|---|---|---|---|
| 训练后量化 | 动态/仅权重量化 | 激活动态量化(fp16, int8)或不量化,权重静态量化(fp16, int8, int4) | 无 | LSTM、MLP、嵌入层、Transformer | 良好 | 易于使用,当性能受计算或内存限制时接近静态量化 |
| 静态量化 | 激活和权重静态量化(int8) | 校准数据集 | CNN | 良好 | 提供最佳性能,可能对精度有较大影响,适用于仅支持int8计算的硬件 | |
| 量化感知训练 | 动态量化 | 激活和权重伪量化 | 微调数据集 | MLP、嵌入层 | 最佳 | 目前支持有限 |
| 静态量化 | 激活和权重伪量化 | 微调数据集 | CNN、MLP、嵌入层 | 最佳 | 通常在静态量化导致精度不佳时使用,用于缩小精度差距 |
更多关于这些量化类型之间权衡的全面概述,请参阅我们的博客文章《PyTorch量化简介》。
量化流程支持
PyTorch 提供两种量化模式:Eager 模式量化和 FX 图模式量化。
Eager 模式量化是测试版功能。用户需要手动完成算子融合,并指定量化与反量化的发生位置,且该模式仅支持模块而不支持函数式操作。
FX 图模式量化是 PyTorch 的自动化量化框架,目前属于原型功能。它在 Eager 模式基础上增加了对函数式操作的支持,并自动化了量化流程,但用户可能需要重构模型以使其兼容 FX 图模式量化(需能通过 torch.fx 进行符号追踪)。需要注意的是,FX 图模式量化无法适用于所有模型,因为部分模型可能无法进行符号追踪。我们将把该功能集成到 torchvision 等领域库中,用户可对与受支持领域库相似的模型进行 FX 图模式量化。对于任意模型,我们会提供通用指南,但实际使用时用户可能需要熟悉 torch.fx,特别是如何使模型可符号化追踪。
建议量化新用户优先尝试 FX 图模式量化。若不可行,可参考 FX 图模式量化使用指南 或回退至 Eager 模式量化。
下表对比了两种量化模式的差异:
| Eager 模式量化 | FX 图模式量化 | |
|---|---|---|
| 发布状态 | 测试版 | 原型 |
| 算子融合 | 手动 | 自动 |
| 量化/反量化位置 | 手动 | 自动 |
| 模块量化 | 支持 | 支持 |
| 函数式/Torch 操作量化 | 手动 | 自动 |
| 自定义支持 | 有限支持 | 完全支持 |
| 支持的量化模式 | 训练后量化:静态、动态、仅权重量化感知训练:静态 | 训练后量化:静态、动态、仅权重量化感知训练:静态 |
| 输入/输出模型类型 | torch.nn.Module | torch.nn.Module(可能需要重构以兼容 FX 图模式量化) |
后端/硬件支持
| 硬件 | 内核库 | 即时模式量化 | FX图模式量化 | 量化模式支持 |
|---|---|---|---|---|
| 服务器CPU | fbgemm/onednn | 支持 | 全部支持 | |
| 移动端CPU | qnnpack/xnnpack | |||
| 服务器GPU | TensorRT (早期原型) | 不支持(需要依赖计算图) | 支持 | 静态量化 |
当前,PyTorch支持以下后端来高效运行量化算子:
- 支持AVX2或更高指令集的x86 CPU(若无AVX2,部分操作实现效率较低),通过fbgemm和onednn进行x86优化(详见RFC)
- ARM CPU(常见于移动/嵌入式设备),通过qnnpack实现
- (早期原型)通过fx2trt支持NVIDIA GPU的TensorRT加速(即将开源)
关于原生 CPU 后端的注意事项
我们通过相同的 PyTorch 量化运算符同时暴露 x86 和 qnnpack 后端,因此需要额外的标志来区分它们。x86 和 qnnpack 的具体实现会根据 PyTorch 构建模式自动选择,但用户也可以通过设置 torch.backends.quantization.engine 为 x86 或 qnnpack 来手动覆盖。
在准备量化模型时,必须确保 qconfig 和量化计算使用的引擎与模型运行时的后端相匹配。qconfig 用于控制在量化过程中使用的观察器类型,而 qengine 则决定在为线性函数和卷积函数/模块打包权重时,使用 x86 还是 qnnpack 特有的打包函数。例如:
x86 的默认设置:
# set the qconfig for PTQ
# Note: the old 'fbgemm' is still available but 'x86' is the recommended default on x86 CPUs
qconfig = torch.ao.quantization.get_default_qconfig('x86')
# or, set the qconfig for QAT
qconfig = torch.ao.quantization.get_default_qat_qconfig('x86')
# set the qengine to control weight packing
torch.backends.quantized.engine = 'x86'
qnnpack 的默认设置:
# set the qconfig for PTQ
qconfig = torch.ao.quantization.get_default_qconfig('qnnpack')
# or, set the qconfig for QAT
qconfig = torch.ao.quantization.get_default_qat_qconfig('qnnpack')
# set the qengine to control weight packing
torch.backends.quantized.engine = 'qnnpack'
算子支持情况
动态量化和静态量化所支持的算子范围有所不同,具体差异如下表所示。需要注意的是,对于FX图模式量化,相应的函数式操作也同样受支持。
| 静态量化 | 动态量化 | |
|---|---|---|
| nn.Linear nn.Conv1d/2d/3d | 支持 支持 | 支持 不支持 |
| nn.LSTM nn.GRU | 不支持 不支持 | 支持 支持 |
| nn.RNNCell nn.GRUCell nn.LSTMCell | 不支持 不支持 不支持 | 支持 支持 支持 |
| nn.EmbeddingBag | 支持(激活值保持fp32精度) | 支持 |
| nn.Embedding | 支持 | 支持 |
| nn.MultiheadAttention | 不支持 | 不支持 |
| 激活函数 | 广泛支持 | 保持不变,计算仍使用fp32精度 |
注:本表将很快根据原生backend_config_dict生成的信息进行更新。
量化 API 参考
量化 API 参考 文档包含了量化相关的 API 说明,例如量化处理流程、量化张量运算,以及支持的量化模块和函数。
量化后端配置
量化后端配置文档详细介绍了如何为不同后端配置量化工作流程。
量化精度调试
量化精度调试文档包含了如何调试量化精度的相关内容。
量化定制功能
虽然系统已默认提供基于观测张量数据自动选择比例因子和偏置的观测器实现,但开发者也可以自定义量化函数。量化操作可以有针对性地应用于模型的不同部分,或为模型的不同组件配置不同的量化方式。
我们还支持对 conv1d()、conv2d()、conv3d() 和 linear() 进行逐通道量化。
量化工作流的实现原理是通过在模型模块层级中新增子模块(例如添加.observer观测器子模块)或替换子模块(例如将nn.Conv2d转换为nn.quantized.Conv2d)。这意味着在整个过程中,模型始终保持基于nn.Module的标准实例形态,因此能与PyTorch其他API无缝协作。
量化自定义模块 API
Eager 模式和 FX 图模式量化 API 都提供了钩子,允许用户以自定义方式指定模块的量化逻辑,包括观测和量化的用户自定义逻辑。用户需要指定以下内容:
1、源 fp32 模块(模型中已存在)的 Python 类型
2、观测模块(由用户提供)的 Python 类型。该模块需要定义 from_float 函数,用于说明如何从原始 fp32 模块创建观测模块。
3、量化模块(由用户提供)的 Python 类型。该模块需要定义 from_observed 函数,用于说明如何从观测模块创建量化模块。
4、描述上述 (1)、(2)、(3) 的配置,传递给量化 API。
框架随后会执行以下操作:
1、在准备模块交换阶段,框架会使用 (2) 中类的 from_float 函数,将所有 (1) 指定类型的模块转换为 (2) 指定的类型。
2、在转换模块交换阶段,框架会使用 (3) 中类的 from_observed 函数,将所有 (2) 指定类型的模块转换为 (3) 指定的类型。
当前存在一个要求:ObservedCustomModule 必须具有单个 Tensor 输出,并且框架(而非用户)会在该输出上添加一个观测器。该观测器会作为自定义模块实例的属性,存储在 activation_post_process 键下。未来可能会放宽这些限制。
自定义 API 示例:
import torch
import torch.ao.nn.quantized as nnq
from torch.ao.quantization import QConfigMapping
import torch.ao.quantization.quantize_fx# original fp32 module to replace
class CustomModule(torch.nn.Module):def __init__(self):super().__init__()self.linear = torch.nn.Linear(3, 3)def forward(self, x):return self.linear(x)# custom observed module, provided by user
class ObservedCustomModule(torch.nn.Module):def __init__(self, linear):super().__init__()self.linear = lineardef forward(self, x):return self.linear(x)@classmethoddef from_float(cls, float_module):assert hasattr(float_module, 'qconfig')observed = cls(float_module.linear)observed.qconfig = float_module.qconfigreturn observed# custom quantized module, provided by user
class StaticQuantCustomModule(torch.nn.Module):def __init__(self, linear):super().__init__()self.linear = lineardef forward(self, x):return self.linear(x)@classmethoddef from_observed(cls, observed_module):assert hasattr(observed_module, 'qconfig')assert hasattr(observed_module, 'activation_post_process')observed_module.linear.activation_post_process = \observed_module.activation_post_processquantized = cls(nnq.Linear.from_float(observed_module.linear))return quantized#
# example API call (Eager mode quantization)
#m = torch.nn.Sequential(CustomModule()).eval()
prepare_custom_config_dict = {"float_to_observed_custom_module_class": {CustomModule: ObservedCustomModule}
}
convert_custom_config_dict = {"observed_to_quantized_custom_module_class": {ObservedCustomModule: StaticQuantCustomModule}
}
m.qconfig = torch.ao.quantization.default_qconfig
mp = torch.ao.quantization.prepare(m, prepare_custom_config_dict=prepare_custom_config_dict)
# calibration (not shown)
mq = torch.ao.quantization.convert(mp, convert_custom_config_dict=convert_custom_config_dict)
#
# example API call (FX graph mode quantization)
#
m = torch.nn.Sequential(CustomModule()).eval()
qconfig_mapping = QConfigMapping().set_global(torch.ao.quantization.default_qconfig)
prepare_custom_config_dict = {"float_to_observed_custom_module_class": {"static": {CustomModule: ObservedCustomModule, }}
}
convert_custom_config_dict = {"observed_to_quantized_custom_module_class": {"static": {ObservedCustomModule: StaticQuantCustomModule, }}
}
mp = torch.ao.quantization.quantize_fx.prepare_fx(m, qconfig_mapping, torch.randn(3,3), prepare_custom_config=prepare_custom_config_dict)
# calibration (not shown)
mq = torch.ao.quantization.quantize_fx.convert_fx(mp, convert_custom_config=convert_custom_config_dict)
最佳实践
1、如果使用 x86 后端,需要使用 7 位而非 8 位。请确保缩小 quant_min 和 quant_max 的范围。例如:
- 当
dtype为torch.quint8时,需将自定义quant_min设为0,quant_max设为127(即255/2) - 当
dtype为torch.qint8时,需将自定义quant_min设为-64(即-128/2),quant_max设为63(即127/2)
若通过调用torch.ao.quantization.get_default_qconfig(backend)或torch.ao.quantization.get_default_qat_qconfig(backend)函数获取x86或qnnpack后端的默认qconfig,系统已自动完成此设置。
2、若选择 onednn 后端,默认的量化配置映射 torch.ao.quantization.get_default_qconfig_mapping('onednn') 和默认配置 torch.ao.quantization.get_default_qconfig('onednn') 会为激活值使用 8 位量化。建议在支持向量神经网络指令集(VNNI)的 CPU 上使用该配置。对于不支持 VNNI 的 CPU,建议将激活值观察器的 reduce_range 参数设为 True 以获得更好的精度。
常见问题解答
1、如何在GPU上进行量化推理?
我们目前尚未正式支持GPU,但这是正在积极开发的领域。更多信息可参考此处。
2、如何获取量化模型的ONNX支持?
如果在导出模型时遇到错误(使用torch.onnx下的API),可以在PyTorch仓库提交问题。请在问题标题前添加[ONNX]前缀,并标记为module: onnx。
若遇到ONNX Runtime相关问题,请在GitHub - microsoft/onnxruntime提交问题。
3、如何在LSTM中使用量化?
LSTM通过我们的自定义模块API支持即时模式(eager mode)和FX图模式(fx graph mode)量化。
示例代码:
- 即时模式:pytorch/test_quantized_op.py TestQuantizedOps.test_custom_module_lstm
- FX图模式:pytorch/test_quantize_fx.py TestQuantizeFx.test_static_lstm
常见错误
将非量化张量传入量化内核
如果出现类似错误:
RuntimeError: Could not run 'quantized::some_operator' with arguments from the 'CPU' backend...
这意味着您正尝试将非量化张量传递给量化内核。常见的解决方法是使用 torch.ao.quantization.QuantStub 对张量进行量化。在 Eager 模式量化中,这需要手动完成。
端到端示例如下:
class M(torch.nn.Module):def __init__(self):super().__init__()self.quant = torch.ao.quantization.QuantStub()self.conv = torch.nn.Conv2d(1, 1, 1)def forward(self, x):# during the convert step, this will be replaced with a # `quantize_per_tensor` callx = self.quant(x)x = self.conv(x)return x
将量化张量传入非量化内核
如果遇到类似错误:
RuntimeError: Could not run 'aten::thnn_conv2d_forward' with arguments from the 'QuantizedCPU' backend.
这意味着您正尝试将量化张量传递给非量化内核。常见的解决方法是使用 torch.ao.quantization.DeQuantStub 对张量进行反量化。在 Eager 模式量化中,需要手动完成此操作。
端到端示例:
class M(torch.nn.Module):def __init__(self):super().__init__()self.quant = torch.ao.quantization.QuantStub()self.conv1 = torch.nn.Conv2d(1, 1, 1)# this module will not be quantized (see `qconfig = None` logic below)self.conv2 = torch.nn.Conv2d(1, 1, 1)self.dequant = torch.ao.quantization.DeQuantStub()def forward(self, x):# during the convert step, this will be replaced with a # `quantize_per_tensor` callx = self.quant(x)x = self.conv1(x)# during the convert step, this will be replaced with a # `dequantize` callx = self.dequant(x)x = self.conv2(x)return xm = M()
m.qconfig = some_qconfig
# turn off quantization for conv2
m.conv2.qconfig = None
保存与加载量化模型
当对量化模型调用 torch.load 时,如果出现类似以下错误:
***
AttributeError: 'LinearPackedParams' object has no attribute '_modules'
这是因为直接使用torch.save和torch.load保存和加载量化模型是不被支持的。要保存/加载量化模型,可以采用以下方式:
1、保存/加载量化模型的state_dict
示例如下:
class M(torch.nn.Module):def __init__(self):super().__init__()self.linear = nn.Linear(5, 5)self.relu = nn.ReLU()def forward(self, x):x = self.linear(x)x = self.relu(x)return xm = M().eval()
prepare_orig = prepare_fx(m, {'' : default_qconfig})
prepare_orig(torch.rand(5, 5))
quantized_orig = convert_fx(prepare_orig)# Save/load using state_dict
b = io.BytesIO()
torch.save(quantized_orig.state_dict(), b)m2 = M().eval()
prepared = prepare_fx(m2, {'' : default_qconfig})
quantized = convert_fx(prepared)
b.seek(0)
quantized.load_state_dict(torch.load(b))
2、使用 torch.jit.save 和 torch.jit.load 保存/加载脚本化量化模型
示例:
# Note: using the same model M from previous example
m = M().eval()
prepare_orig = prepare_fx(m, {'' : default_qconfig})
prepare_orig(torch.rand(5, 5))
quantized_orig = convert_fx(prepare_orig)# save/load using scripted model
scripted = torch.jit.script(quantized_orig)
b = io.BytesIO()
torch.jit.save(scripted, b)
b.seek(0)
scripted_quantized = torch.jit.load(b)
使用FX图模式量化时出现符号追踪错误
符号可追踪性是(原型-维护模式)FX图模式量化的必要条件。因此,如果您向torch.ao.quantization.prepare_fx或torch.ao.quantization.prepare_qat_fx传递一个无法进行符号追踪的PyTorch模型,可能会遇到如下错误:
torch.fx.proxy.TraceError: symbolically traced variables cannot be used as inputs to control flow
请参考符号追踪的限制,并使用FX图模式量化的用户指南来解决该问题。
分布式RPC框架
该分布式RPC框架通过一组基础原语实现多机模型训练,支持远程通信,并提供高级API来自动处理跨多台机器分割的模型微分。
警告:RPC包中的API目前处于稳定状态。我们正在进行多项改进性能和错误处理的工作,这些改进将在未来版本中发布。
警告:PyTorch 1.9引入了CUDA支持,但目前仍属于测试版功能。并非所有RPC包功能都与CUDA支持兼容,因此不建议使用这些功能。这些不受支持的功能包括:RRefs、JIT兼容性、分布式自动微分和分布式优化器以及性能分析。这些不足将在未来版本中解决。
注意:有关分布式训练相关功能的简要介绍,请参阅PyTorch分布式概述。
基础概念
分布式RPC框架能够轻松实现远程函数调用,支持在不复制实际数据的情况下引用远程对象,并提供自动求导和优化器API,从而透明地跨RPC边界执行反向传播和参数更新。这些功能可分为四组API:
1、远程过程调用(RPC) 支持在指定工作节点上运行带参数的函数,并获取返回值或创建对返回值的引用。主要提供三个RPC API:rpc_sync()(同步)、rpc_async()(异步)和remote()(异步且返回远程值的引用)。当用户代码必须获得返回值才能继续执行时,应使用同步API;否则可使用异步API获取future对象,待需要返回值时再等待future完成。remote()API适用于需要在远程创建对象但调用方自身无需获取该对象的场景。例如驱动进程设置参数服务器和训练器时,可以在参数服务器上创建嵌入表后,仅将引用分享给训练器,而驱动进程自身不会本地使用该嵌入表。此时rpc_sync()和rpc_async()不再适用,因为它们始终意味着返回值会立即或将来返回给调用方。
2、远程引用(RRef) 作为指向本地或远程对象的分布式共享指针,可被其他工作节点共享,并透明处理引用计数。每个RRef只有一个所有者,对象仅存在于所有者节点。持有RRef的非所有者节点可通过显式请求从所有者处获取对象副本。当工作节点需要访问某个数据对象,但自身既非创建者(即remote()调用方)也非对象所有者时,这个机制非常有用。后文将讨论的分布式优化器就是典型用例。
3、分布式自动求导 将参与前向传播的所有工作节点的本地求导引擎连接起来,在反向传播期间自动协调这些节点计算梯度。当进行分布式模型并行训练、参数服务器训练等需要跨多台机器执行前向传播的场景时,这个特性尤为重要。有了该功能,用户代码不再需要操心如何跨RPC边界传递梯度,以及以何种顺序启动本地求导引擎——当前向传播中存在嵌套且相互依赖的RPC调用时,这些操作会变得异常复杂。
4、分布式优化器 的构造函数接收一个Optimizer()(如SGD()、Adagrad()等)和参数RRef列表,在每个不同的RRef所有者节点上创建Optimizer()实例,执行step()时相应更新参数。当采用分布式前向传播和反向传播时,参数和梯度会分散在多个工作节点上,因此每个相关节点都需要优化器。分布式优化器将所有本地优化器封装成统一接口,提供简洁的构造函数和step()API。
RPC 远程过程调用
在使用 RPC 和分布式自动微分原语之前,必须进行初始化。要初始化 RPC 框架,我们需要使用 init_rpc() 函数,该函数会同时初始化 RPC 框架、RRef 框架以及分布式自动微分系统。
torch.distributed.rpc.init_rpc(name, backend=None, rank=-1, world_size=None, rpc_backend_options=None)
初始化RPC基础组件,包括本地RPC代理和分布式自动梯度计算,使当前进程立即具备发送和接收RPC的能力。
参数
name (str)- 节点的全局唯一名称(例如Trainer3、ParameterServer2、Master、Worker1)。名称只能包含数字、字母、下划线、冒号和/或短横线,且长度必须小于128个字符。backend (BackendType , Optional)- RPC后端实现类型。支持的值为BackendType.TENSORPIPE(默认值)。详见后端获取更多信息。rank (int)- 节点的全局唯一ID/排名。world_size (int)- 工作组中的工作节点数量。rpc_backend_options (RpcBackendOptions , Optional)- 传递给RpcAgent构造函数的选项。必须是RpcBackendOptions的代理特定子类,包含代理特定的初始化配置。默认情况下,对所有代理设置60秒超时,并使用init_method = "env://"初始化底层进程组进行会合,这意味着需要正确设置环境变量MASTER_ADDR和MASTER_PORT。详见后端获取可用选项。
以下API允许用户远程执行函数,并创建对远程数据对象的引用(RRefs)。在这些API中,当传递Tensor作为参数或返回值时,目标工作节点会尝试创建具有相同元数据(如形状、步幅等)的Tensor。我们明确禁止传输CUDA张量,因为如果源工作节点和目标工作节点的设备列表不匹配,可能会导致崩溃。在这种情况下,应用程序可以始终在调用方将输入张量显式移动到CPU,并在必要时在被调用方将其移动到所需设备。
警告:RPC中的TorchScript支持是原型功能,可能会发生变化。自v1.5.0起,torch.distributed.rpc支持将TorchScript函数作为RPC目标函数调用,这将有助于提高被调用方的并行性,因为执行TorchScript函数不需要GIL。
torch.distributed.rpc.rpc_sync(to, func, args=None, kwargs=None, timeout=-1.0)
向工作节点 to 发起阻塞式 RPC 调用以执行函数 func。RPC 消息的发送和接收与 Python 代码的执行是并行进行的。该方法是线程安全的。
参数
to (str 或 WorkerInfo 或 int)– 目标工作节点的名称/排名/WorkerInfofunc (Callable)– 可调用对象,例如 Python 可调用对象、内置运算符(如add())以及带注解的 TorchScript 函数args (tuple)– 调用func时的参数元组kwargs (dict)– 调用func时的关键字参数字典timeout (float, Optional)– RPC 超时时间(秒)。若在此时间内未完成 RPC 调用,将抛出超时异常。值为 0 表示无限超时(永不抛出超时错误)。若未指定,则使用初始化时或通过_set_rpc_timeout设置的默认值
返回值
返回 func 以 args 和 kwargs 为参数执行的结果。
示例
确保两个工作节点上都正确设置了 MASTER_ADDR 和 MASTER_PORT 环境变量。详情请参考 init_process_group() API。例如:
export MASTER_ADDR=localhost
export MASTER_PORT=5678
然后在两个不同进程中运行以下代码:
>>> # On worker 0:
>>> import torch
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker0", rank=0, world_size=2)
>>> ret = rpc.rpc_sync("worker1", torch.add, args=(torch.ones(2), 3))
>>> rpc.shutdown()>>> # On worker 1:
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker1", rank=1, world_size=2)
>>> rpc.shutdown()
以下是通过RPC运行TorchScript函数的示例。
>>> # On both workers:
>>> @torch.jit.script
>>> def my_script_add(tensor: torch.Tensor, scalar: int):
>>> return torch.add(tensor, scalar)>>> # On worker 0:
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker0", rank=0, world_size=2)
>>> ret = rpc.rpc_sync("worker1", my_script_add, args=(torch.ones(2), 3))
>>> rpc.shutdown()>>> # On worker 1:
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker1", rank=1, world_size=2)
>>> rpc.shutdown()torch.distributed.rpc.rpc_async(to, func, args=None, kwargs=None, timeout=-1.0)
向工作节点to发起非阻塞的RPC调用以运行函数func。RPC消息的发送和接收与Python代码的执行是并行进行的。该方法是线程安全的,会立即返回一个可等待的Future对象。
参数
to (str 或 [WorkerInfo](https://pytorch.org/docs/stable/data.html#torch.distributed.rpc.WorkerInfo "torch.distributed.rpc.WorkerInfo") 或 int)– 目标工作节点的名称/排名/WorkerInfo标识func (Callable)– 可调用对象,包括Python函数、内置运算符(如add())及带有注解的TorchScript函数args (tuple)– 传递给func的位置参数元组kwargs (dict)– 传递给func的关键字参数字典timeout (float, Optional)– RPC超时时间(秒)。若未在指定时间内完成,将抛出超时异常。值为0表示无限等待(永不超时)。未提供时默认使用初始化或_set_rpc_timeout设置的值
返回值
返回可等待的Future对象。完成后可通过该对象获取func在args和kwargs上的返回值。
警告
1、不支持将GPU张量作为func的参数或返回值,因为当前不支持通过网络传输GPU张量。使用前需显式将GPU张量复制到CPU。
2、rpc_async API在通过网络发送参数张量前不会复制其存储空间(具体由RPC后端类型的线程处理)。调用者必须确保这些张量的内容在Future完成前保持不变。
示例
需确保两个工作节点都正确设置了MASTER_ADDR和MASTER_PORT环境变量(参考init_process_group() API)。例如:
export MASTER_ADDR=localhost
export MASTER_PORT=5678
然后在两个不同进程中运行以下代码:
>>> # On worker 0:
>>> import torch
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker0", rank=0, world_size=2)
>>> fut1 = rpc.rpc_async("worker1", torch.add, args=(torch.ones(2), 3))
>>> fut2 = rpc.rpc_async("worker1", min, args=(1, 2))
>>> result = fut1.wait() + fut2.wait()
>>> rpc.shutdown()>>> # On worker 1:
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker1", rank=1, world_size=2)
>>> rpc.shutdown()
以下是通过RPC运行TorchScript函数的示例。
>>> # On both workers:
>>> @torch.jit.script
>>> def my_script_add(tensor: torch.Tensor, scalar: int):
>>> return torch.add(tensor, scalar)>>> # On worker 0:
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker0", rank=0, world_size=2)
>>> fut = rpc.rpc_async("worker1", my_script_add, args=(torch.ones(2), 3))
>>> ret = fut.wait()
>>> rpc.shutdown()>>> # On worker 1:
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker1", rank=1, world_size=2)
>>> rpc.shutdown()torch.distributed.rpc.remote(to, func, args=None, kwargs=None, timeout=-1.0)
远程调用在工作者 to 上运行 func 并立即返回结果值的 RRef 引用。
工作者 to 将成为返回 RRef 的所有者,而调用 remote 的工作者是使用者。所有者负责管理其 RRef 的全局引用计数,只有当全局范围内不存在对该 RRef 的活动引用时,所有者才会销毁该引用。
参数
to (str 或 [WorkerInfo](https://pytorch.org/docs/stable/data.html#torch.distributed.rpc.WorkerInfo "torch.distributed.rpc.WorkerInfo") 或 int)– 目标工作者的名称/排名/WorkerInfo信息func (Callable)– 可调用对象,例如 Python 可调用对象、内置运算符(如add())以及带注解的 TorchScript 函数args (tuple)– 调用func时的参数元组kwargs (dict)– 调用func时的关键字参数字典timeout (float, Optional)– 远程调用的超时时间(秒)。如果在此超时时间内未能在工作者to上成功创建该RRef,则下次尝试使用该 RRef(例如调用to_here())时将触发超时错误。值为 0 表示无限超时,即永远不会触发超时错误。若未指定,则使用初始化时或通过_set_rpc_timeout设置的默认值。
返回
指向结果值的使用者端 RRef 实例。可通过阻塞式 API torch.distributed.rpc.RRef.to_here() 在本地获取结果值。
警告
remote API 在通过网络发送参数张量之前不会复制其存储空间,具体复制操作可能由不同线程执行(取决于 RPC 后端类型)。调用方必须确保这些张量的内容在所有者确认返回的 RRef 之前保持不变,可通过 torch.distributed.rpc.RRef.confirmed_by_owner() API 进行验证。
警告
remote API 的超时等错误采用尽力而为的处理机制。这意味着当 remote 发起的远程调用失败(例如发生超时错误)时,我们采取尽力而为的方式处理错误。错误处理将以异步方式设置到结果 RRef 上。如果在错误处理完成前(例如调用 to_here 或 fork 操作前)应用程序尚未使用该 RRef,则后续使用该 RRef 时会正确抛出错误。但若用户应用程序在错误处理完成前就使用了 RRef,则可能不会抛出尚未处理的错误。
示例
Make sure that MASTER_ADDR and MASTER_PORT are set properly on both workers. Refer to :meth:~torch.distributed.init_process_group
API for more details. For example,
export MASTER_ADDR=localhost
export MASTER_PORT=5678
Then run the following code in two different processes:
>>> # On worker 0:
>>> import torch
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker0", rank=0, world_size=2)
>>> rref1 = rpc.remote("worker1", torch.add, args=(torch.ones(2), 3))
>>> rref2 = rpc.remote("worker1", torch.add, args=(torch.ones(2), 1))
>>> x = rref1.to_here() + rref2.to_here()
>>> rpc.shutdown()>>> # On worker 1:
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker1", rank=1, world_size=2)
>>> rpc.shutdown()Below is an example of running a TorchScript function using RPC.>>> # On both workers:
>>> @torch.jit.script
>>> def my_script_add(tensor: torch.Tensor, scalar: int):
>>> return torch.add(tensor, scalar)>>> # On worker 0:
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker0", rank=0, world_size=2)
>>> rref = rpc.remote("worker1", my_script_add, args=(torch.ones(2), 3))
>>> rref.to_here()
>>> rpc.shutdown()>>> # On worker 1:
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker1", rank=1, world_size=2)
>>> rpc.shutdown()torch.distributed.rpc.get_worker_info(worker_name=None)
获取指定工作节点名称的 WorkerInfo。
使用此 WorkerInfo 可避免每次调用时传递开销较大的字符串。
参数
worker_name (str)– 工作节点的字符串名称。若为None,则返回当前工作节点的 ID。(默认值None)
返回值:返回给定 worker_name 对应的 WorkerInfo 实例;若 worker_name 为 None,则返回当前工作节点的 WorkerInfo。
torch.distributed.rpc.shutdown(graceful=True, timeout=0)
执行 RPC 代理的关闭操作,随后销毁该 RPC 代理。此操作将:
1、阻止本地代理接收未完成请求
2、通过终止所有 RPC 线程来关闭 RPC 框架
当参数 graceful=True 时,该方法会阻塞直至满足以下条件:
- 所有本地和远程 RPC 进程都执行到本方法
- 所有未完成的工作均执行完毕
若参数 graceful=False,则仅执行本地关闭,不会等待其他 RPC 进程执行本方法。
警告:对于通过 rpc_async() 返回的 Future 对象,在调用 shutdown() 后不应再执行 future.wait()。
参数说明
graceful ([bool])- 是否执行优雅关闭。当设为 True 时,将:- 等待直至没有针对
UserRRefs的待处理系统消息并删除它们 - 阻塞直至所有本地和远程 RPC 进程都执行到本方法,并等待所有未完成工作执行完毕
- 等待直至没有针对
使用示例
确保在两个工作节点上正确设置 MASTER_ADDR 和 MASTER_PORT 环境变量,具体可参考 init_process_group() API 文档。例如:
export MASTER_ADDR=localhost
export MASTER_PORT=5678
然后在两个不同进程中运行以下代码:
>>> # On worker 0:
>>> import torch
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker0", rank=0, world_size=2)
>>> # do some work
>>> result = rpc.rpc_sync("worker1", torch.add, args=(torch.ones(1), 1))
>>> # ready to shutdown
>>> rpc.shutdown()>>> # On worker 1:
>>> import torch.distributed.rpc as rpc
>>> rpc.init_rpc("worker1", rank=1, world_size=2)
>>> # wait for worker 0 to finish work, and then shutdown.
>>> rpc.shutdown()class torch.distributed.rpc.WorkerInfo
一个用于封装系统中工作节点信息的数据结构。
该结构包含工作节点的名称和ID。不建议直接构造此类的实例,而是应通过 get_worker_info() 方法获取实例,获取的结果可传递给 rpc_sync()、rpc_async() 和 remote() 等方法,以避免每次调用时复制字符串。
property id
用于标识工作节点的全局唯一ID。
property name
工作线程的名称。
RPC 包还提供了装饰器,允许应用程序指定被调用方应如何处理特定函数。
torch.distributed.rpc.functions.async_execution(fn)
这是一个函数装饰器,用于表明该函数的返回值保证是一个Future对象,且该函数可以在RPC被调用方异步执行。具体来说,被调用方会提取被装饰函数返回的Future,并将后续处理步骤作为回调函数安装到该Future上。安装的回调函数会在Future完成时读取其值,并将该值作为RPC响应发送回去。这也意味着返回的Future仅存在于被调用方,永远不会通过RPC传输。
当被装饰函数(fn)的执行需要暂停和恢复时(例如包含rpc_async()或等待其他信号),这个装饰器特别有用。
注意:要启用异步执行,应用程序必须将此装饰器返回的函数对象传递给RPC API。如果RPC检测到此装饰器安装的属性,就会知道该函数返回一个Future对象并相应地进行处理。
但这并不意味着在定义函数时此装饰器必须是最外层的。例如,当与@staticmethod或@classmethod结合使用时,@rpc.functions.async_execution需要作为内层装饰器,以使目标函数被识别为静态方法或类方法。该目标函数仍可异步执行,因为当访问时,静态方法或类方法会保留@rpc.functions.async_execution安装的属性。
示例:返回的Future对象可以来自rpc_async()、then()或Future构造函数。下面的示例展示了直接使用then()返回的Future。
>>> from torch.distributed import rpc
>>> >
>>> # omitting setup and shutdown RPC
>>> >
>>> # On all workers
>>> @rpc.functions.async_execution
>>> def async_add_chained(to, x, y, z):
>>> # This function runs on "worker1" and returns immediately when
>>> # the callback is installed through the `then(cb)` API. In the >> # mean time, the `rpc_async` to "worker2" can run concurrently.
>>> # When the return value of that `rpc_async` arrives at >> # "worker1", "worker1" will run the lambda function accordingly
>>> # and set the value for the previously returned `Future`, which >> # will then trigger RPC to send the result back to "worker0".
>>> return rpc.rpc_async(to, torch.add, args=(x, y)).then(
>>> lambda fut: fut.wait() + z
>>> )
>>> >
>>> # On worker0
>>> ret = rpc.rpc_sync(
>>> "worker1", >> async_add_chained, >> args=("worker2", torch.ones(2), 1, 1)
>>> )
>>> print(ret) # prints tensor([3., 3.])当与TorchScript装饰器结合使用时,此装饰器必须位于最外层。
>>> from torch import Tensor
>>> from torch.futures import Future
>>> from torch.distributed import rpc
>>> >
>>> # omitting setup and shutdown RPC
>>> >
>>> # On all workers
>>> @torch.jit.script
>>> def script_add(x: Tensor, y: Tensor) -Tensor:
>>> return x + y
>>> >
>>> @rpc.functions.async_execution
>>> @torch.jit.script
>>> def async_add(to: str, x: Tensor, y: Tensor) -Future[Tensor]:
>>> return rpc.rpc_async(to, script_add, (x, y))
>>> >
>>> # On worker0
>>> ret = rpc.rpc_sync(
>>> "worker1", >> async_add, >> args=("worker2", torch.ones(2), 1)
>>> )
>>> print(ret) # prints tensor([2., 2.])当与静态方法或类方法结合使用时,此装饰器必须作为最内层的装饰器。
>>> from torch.distributed import rpc
>>> >
>>> # omitting setup and shutdown RPC
>>> >
>>> # On all workers
>>> class AsyncExecutionClass:
>>> >
>>> @staticmethod
>>> @rpc.functions.async_execution
>>> def static_async_add(to, x, y, z):
>>> return rpc.rpc_async(to, torch.add, args=(x, y)).then(
>>> lambda fut: fut.wait() + z
>>> )
>>> >
>>> @classmethod
>>> @rpc.functions.async_execution
>>> def class_async_add(cls, to, x, y, z):
>>> ret_fut = torch.futures.Future()
>>> rpc.rpc_async(to, torch.add, args=(x, y)).then(
>>> lambda fut: ret_fut.set_result(fut.wait() + z)
>>> )
>>> return ret_fut
>>> >
>>> @rpc.functions.async_execution
>>> def bound_async_add(self, to, x, y, z):
>>> return rpc.rpc_async(to, torch.add, args=(x, y)).then(
>>> lambda fut: fut.wait() + z
>>> )
>>> >
>>> # On worker0
>>> ret = rpc.rpc_sync(
>>> "worker1", >> AsyncExecutionClass.static_async_add, >> args=("worker2", torch.ones(2), 1, 2)
>>> )
>>> print(ret) # prints tensor([4., 4.])
>>> >
>>> ret = rpc.rpc_sync(
>>> "worker1", >> AsyncExecutionClass.class_async_add, >> args=("worker2", torch.ones(2), 1, 2)
>>> )
>>> print(ret) # prints tensor([4., 4.])该装饰器同样适用于 RRef 辅助方法,例如:
torch.distributed.rpc.RRef.rpc_sync()、torch.distributed.rpc.RRef.rpc_async() 和 torch.distributed.rpc.RRef.remote()。
>>> from torch.distributed import rpc
>>> >
>>> # reuse the AsyncExecutionClass class above
>>> rref = rpc.remote("worker1", AsyncExecutionClass)
>>> ret = rref.rpc_sync().static_async_add("worker2", torch.ones(2), 1, 2)
>>> print(ret) # prints tensor([4., 4.])
>>> >
>>> rref = rpc.remote("worker1", AsyncExecutionClass)
>>> ret = rref.rpc_async().static_async_add("worker2", torch.ones(2), 1, 2).wait()
>>> print(ret) # prints tensor([4., 4.])
>>> >
>>> rref = rpc.remote("worker1", AsyncExecutionClass)
>>> ret = rref.remote().static_async_add("worker2", torch.ones(2), 1, 2).to_here()
>>> print(ret) # prints tensor([4., 4.])后端实现
RPC模块可以利用不同的后端实现来执行节点间的通信。通过在init_rpc()函数中传入BackendType枚举的特定值,可以指定要使用的后端。无论使用哪种后端,RPC API的其他部分都保持不变。每个后端还会定义自己的RpcBackendOptions类子类,其实例也可以传递给init_rpc()来配置后端的行为。
class torch.distributed.rpc.BackendType(value)
可用后端的枚举类。
PyTorch 内置提供了 BackendType.TENSORPIPE 后端。
可以通过 register_backend() 函数注册其他后端。
class torch.distributed.rpc.RpcBackendOptions
一个抽象结构,用于封装传递给 RPC 后端的选项。可以将该类的实例传入 init_rpc() 方法,以便使用特定配置初始化 RPC,例如 RPC 超时设置和要使用的 init_method。
property init_method
指定如何初始化进程组的URL。
默认为 env://
property rpc_timeout
一个浮点数,表示所有RPC调用的超时时间。如果RPC在此时间范围内未完成,将以抛出超时异常的方式结束。
TensorPipe 后端
TensorPipe 代理作为默认选项,利用了 TensorPipe 库。该库专门为机器学习提供了一种原生点对点通信原语,从根本上解决了 Gloo 的某些局限性。与 Gloo 相比,它具有异步优势,允许大量传输同时进行,各自以不同速度运行而不会相互阻塞。它仅在需要时按需在节点对之间建立管道,当某个节点故障时,仅关闭与其相关的管道,而其他所有管道仍能正常工作。此外,它支持多种传输方式(包括 TCP、共享内存、NVLink、InfiniBand 等),并能自动检测可用性,为每条管道协商最佳传输方案。
TensorPipe 后端自 PyTorch v1.6 引入并持续积极开发。目前仅支持 CPU 张量,GPU 支持即将推出。与 Gloo 类似,它提供了基于 TCP 的传输方式,还能自动将大张量分块并通过多套接字和多线程进行复用,从而实现超高带宽。代理能够自主选择最佳传输方式,无需人工干预。
示例:
>>> import os
>>> from torch.distributed import rpc
>>> os.environ['MASTER_ADDR'] = 'localhost'
>>> os.environ['MASTER_PORT'] = '29500'
>>> >
>>> rpc.init_rpc(
>>> "worker1", >> rank=0, >> world_size=2, >> rpc_backend_options=rpc.TensorPipeRpcBackendOptions(
>>> num_worker_threads=8, >> rpc_timeout=20 # 20 second timeout
>>> )
>>> )
>>> >
>>> # omitting init_rpc invocation on worker2class torch.distributed.rpc.TensorPipeRpcBackendOptions(*, num_worker_threads=16, rpc_timeout=60.0, init_method='env://', device_maps=None, devices=None, _transports=None, _channels=None)
TensorPipeAgent的后端选项,继承自RpcBackendOptions。
参数
num_worker_threads (int, Optional)–TensorPipeAgent用于执行请求的线程池中的线程数(默认值:16)。rpc_timeout (float, Optional)– RPC请求的默认超时时间,单位为秒(默认值:60秒)。如果RPC在此时间内未完成,将抛出异常提示超时。调用者可以在必要时通过rpc_sync()和rpc_async()为单个RPC覆盖此超时设置。init_method (str, Optional)– 用于初始化分布式存储的URL,该存储用于集合点。它接受与init_process_group()相同参数的任何值(默认值:env://)。device_maps (Dict[str, Dict], Optional)– 从此工作者到被调用者的设备放置映射。键是被调用者工作者的名称,值是将此工作者的设备映射到被调用者工作者设备的字典(int、str或torch.device的Dict)(默认值:None)。devices (List[int, str, 或torch.device], Optional)– RPC代理使用的所有本地CUDA设备。默认情况下,它将初始化为来自自身device_maps的所有本地设备以及来自其对等方device_maps的相应设备。在处理CUDA RPC请求时,代理将为此List中的所有设备正确同步CUDA流。
property device_maps
设备映射位置。
property devices
本地代理使用的所有设备。
property init_method
URL 指定如何初始化进程组。
默认值为 env://
property num_worker_threads
TensorPipeAgent 用于执行请求的线程池中的线程数量。
property rpc_timeout
一个浮点数,表示所有RPC调用的超时时间。如果RPC在此时间内未完成,将以抛出超时异常的方式结束。
set_device_map(to, device_map)
为每个RPC调用方与被调用方对设置设备映射关系。该函数可被多次调用,以逐步添加设备放置配置。
参数
to (str)– 被调用方名称。device_map (Dict* *of* int ,* str, or* torch.device )– 从当前工作节点到被调用方的设备放置映射。该映射必须是可逆的。
示例
>>> # both workers
>>> def add(x, y):
>>> print(x) # tensor([1., 1.], device='cuda:1')
>>> return x + y, (x + y).to(2)
>>> >
>>> # on worker 0
>>> options = TensorPipeRpcBackendOptions(
>>> num_worker_threads=8, >> device_maps={"worker1": {0: 1}}
>>> # maps worker0's cuda:0 to worker1's cuda:1
>>> )
>>> options.set_device_map("worker1", {1: 2})
>>> # maps worker0's cuda:1 to worker1's cuda:2
>>> >
>>> rpc.init_rpc(
>>> "worker0", >> rank=0, >> world_size=2, >> backend=rpc.BackendType.TENSORPIPE, >> rpc_backend_options=options
>>> )
>>> >
>>> x = torch.ones(2)
>>> rets = rpc.rpc_sync("worker1", add, args=(x.to(0), 1))
>>> # The first argument will be moved to cuda:1 on worker1、When
>>> # sending the return value back, it will follow the invert of >># the device map, and hence will be moved back to cuda:0 and >># cuda:1 on worker0
>>> print(rets[0]) # tensor([2., 2.], device='cuda:0')
>>> print(rets[1]) # tensor([2., 2.], device='cuda:1')set_devices(devices)
设置 TensorPipe RPC 代理使用的本地设备。当处理 CUDA RPC 请求时,TensorPipe RPC 代理会正确同步此 List 中所有设备的 CUDA 流。
参数
devices (List[int, str, 或 torch.device])– TensorPipe RPC 代理使用的本地设备。
注意:RPC 框架不会自动重试任何 rpc_sync()、rpc_async() 或 remote() 调用。原因是 RPC 框架无法判断操作是否是幂等的,以及重试是否安全。因此,应用程序需要自行处理失败并在必要时重试。RPC 通信基于 TCP,因此可能因网络故障或间歇性连接问题导致失败。在这种情况下,应用程序应合理设置退避时间进行重试,以避免因频繁重试导致网络过载。
RRef 远程引用
警告:当前不支持在 CUDA 张量上使用 RRef
RRef(Remote REFerence,远程引用)是对某个远程工作节点上类型为 T(例如 Tensor)的值的引用。该句柄会确保被引用的远程值在其所有者节点上保持存活状态,但并不暗示该值未来会被传输到本地工作节点。在分布式机器训练中,RRef 可用于持有存在于其他工作节点上的 nn.Module 引用,并通过调用相应函数在训练过程中获取或修改其参数。更多细节请参阅 远程引用协议。
class torch.distributed.rpc.PyRRef(RRef)
一个封装了对远程工作节点上某类型值引用的类。该句柄会保持被引用的远程值在工作节点上存活。UserRRef会在以下情况被删除:1) 应用代码和本地RRef上下文中都不再持有其引用;2) 应用程序调用了优雅关闭。对已删除的RRef调用方法会导致未定义行为。RRef实现仅提供尽力而为的错误检测,应用在rpc.shutdown()后不应继续使用UserRRefs。
警告:RRef只能通过RPC模块进行序列化和反序列化。若脱离RPC进行序列化/反序列化(例如使用Python pickle、torch的save()/load()、JIT的save()/load()等)将引发错误。
参数
value ( object )– 要被RRef包装的值对象type_hint (Type, Optional)– 应作为value的类型提示传递给TorchScript编译器的Python类型
示例:为简化说明,以下示例跳过RPC初始化和关闭代码,具体细节请参阅RPC文档。
1、使用rpc.remote创建RRef
>>> import torch
>>> import torch.distributed.rpc as rpc
>>> rref = rpc.remote("worker1", torch.add, args=(torch.ones(2), 3))
>>> # get a copy of value from the RRef
>>> x = rref.to_here()2、从本地对象创建 RRef
>>> import torch
>>> from torch.distributed.rpc import RRef
>>> x = torch.zeros(2, 2)
>>> rref = RRef(x)3、与其他工作节点共享RRef
>>> # On both worker0 and worker1:
>>> def f(rref):
>>> return rref.to_here() + 1>>> # On worker0:
>>> import torch
>>> import torch.distributed.rpc as rpc
>>> from torch.distributed.rpc import RRef
>>> rref = RRef(torch.zeros(2, 2))
>>> # the following RPC shares the rref with worker1, reference
>>> # count is automatically updated.
>>> rpc.rpc_sync("worker1", f, args=(rref,))backward(self: torch._C._distributed_rpc.PyRRef, dist_autograd_ctx_id: int = -1, retain_graph: bool = False) → None
使用 RRef 作为反向传播的根节点执行反向传播。如果提供了 dist_autograd_ctx_id,我们将从 RRef 的所有者开始,使用给定的 ctx_id 执行分布式反向传播。在这种情况下,应使用 get_gradients() 来检索梯度。如果 dist_autograd_ctx_id 为 None,则假定这是一个本地自动微分图,我们仅执行本地反向传播。在本地情况下,调用此 API 的节点必须是 RRef 的所有者。
RRef 的值应为标量张量。
参数
dist_autograd_ctx_id (int, Optional)– 用于检索梯度的分布式自动微分上下文 ID(默认值:-1)。retain_graph ([bool], Optional)– 如果为False,用于计算梯度的图将被释放。请注意,在几乎所有情况下都不需要将此选项设置为True,通常可以通过更高效的方式解决。通常,只有在需要多次运行反向传播时才需要将此设置为True(默认值:False)。
示例:
>>> import torch.distributed.autograd as dist_autograd
>>> with dist_autograd.context() as context_id:
>>> rref.backward(context_id)confirmed_by_owner(self: torch._C._distributed_rpc.PyRRef) → bool
返回该RRef是否已被所有者确认。
OwnerRRef始终返回true,而UserRRef仅当所有者知晓该UserRRef时才返回true。
is_owner(self: torch._C._distributed_rpc.PyRRef) → bool
返回当前节点是否为此RRef的所有者。
local_value(self: torch._C._distributed_rpc.PyRRef) → object
如果当前节点是所有者,则返回对本地值的引用。否则抛出异常。
owner(self: torch._C._distributed_rpc.PyRRef) → torch._C._distributed_rpc.WorkerInfo
返回拥有此RRef的节点的工作者信息。
owner_name(self: torch._C._distributed_rpc.PyRRef) → str
返回拥有该RRef的节点的工作线程名称。
remote(self: torch._C._distributed_rpc.PyRRef, timeout: float = -1.0) → object
创建一个辅助代理,用于轻松发起remote调用,该调用会以RRef的持有者作为目标节点,在RRef引用的对象上执行函数。更具体地说,rref.remote().func_name(args, *kwargs)等同于以下操作:
>>> def run(rref, func_name, args, kwargs):
>>> return getattr(rref.local_value(), func_name)(args, *kwargs)
>>> >
>>> rpc.remote(rref.owner(), run, args=(rref, func_name, args, kwargs))参数
timeout (float, Optional)–rref.remote()的超时时间。如果在此超时时间内未能成功创建该RRef,则下次尝试使用该 RRef(例如to_here操作)时会触发超时错误。若未指定该参数,将使用默认的 RPC 超时设置。具体关于RRef的超时语义,请参阅rpc.remote()的说明。
示例:
>>> from torch.distributed import rpc
>>> rref = rpc.remote("worker1", torch.add, args=(torch.zeros(2, 2), 1))
>>> rref.remote().size().to_here() # returns torch.Size([2, 2])
>>> rref.remote().view(1, 4).to_here() # returns tensor([[1., 1., 1., 1.]])rpc_async(self: torch._C._distributed_rpc.PyRRef, timeout: float = -1.0) → object
创建一个辅助代理,用于轻松发起rpc_async调用,该调用会以RRef的所有者作为目标节点,在RRef引用的对象上运行函数。具体来说,rref.rpc_async().func_name(args, *kwargs)等价于以下操作:
>>> def run(rref, func_name, args, kwargs):
>>> return getattr(rref.local_value(), func_name)(args, *kwargs)
>>> >
>>> rpc.rpc_async(rref.owner(), run, args=(rref, func_name, args, kwargs))参数
timeout (float, Optional)–rref.rpc_async()的超时时间。
如果调用未在此时间范围内完成,将抛出超时异常。如果未提供此参数,则使用默认的 RPC 超时设置。
示例:
>>> from torch.distributed import rpc
>>> rref = rpc.remote("worker1", torch.add, args=(torch.zeros(2, 2), 1))
>>> rref.rpc_async().size().wait() # returns torch.Size([2, 2])
>>> rref.rpc_async().view(1, 4).wait() # returns tensor([[1., 1., 1., 1.]])rpc_sync(self: torch._C._distributed_rpc.PyRRef, timeout: float = -1.0) → object
创建一个辅助代理,方便通过rpc_sync调用RRef所有者作为目标节点,在该RRef引用的对象上执行函数。具体来说,rref.rpc_sync().func_name(args, *kwargs)等同于以下操作:
>>> def run(rref, func_name, args, kwargs):
>>> return getattr(rref.local_value(), func_name)(args, *kwargs)
>>> >
>>> rpc.rpc_sync(rref.owner(), run, args=(rref, func_name, args, kwargs))参数
timeout (float, Optional)-rref.rpc_sync()的超时时间。
如果调用在此时间内未完成,将抛出超时异常。若未提供此参数,则使用默认的 RPC 超时设置。
示例:
>>> from torch.distributed import rpc
>>> rref = rpc.remote("worker1", torch.add, args=(torch.zeros(2, 2), 1))
>>> rref.rpc_sync().size() # returns torch.Size([2, 2])
>>> rref.rpc_sync().view(1, 4) # returns tensor([[1., 1., 1., 1.]])to_here(self: torch._C._distributed_rpc.PyRRef, timeout: float = -1.0) → object
阻塞式调用,将RRef的值从所有者节点复制到本地节点并返回。如果当前节点就是所有者,则直接返回本地值的引用。
参数
timeout (float, Optional)–to_here操作的超时时间。若调用未在规定时间内完成,将抛出超时异常。若不提供此参数,则默认采用RPC超时设置(60秒)。
关于RRef的更多信息
- 远程引用协议
-
背景知识
-
基本假设
-
RRef生命周期
- 设计原理
- 实现细节
- 协议场景
- 用户以返回值形式与所有者共享RRef
- 用户以参数形式与所有者共享RRef
- 所有者与用户共享RRef
- 用户间共享RRef
RemoteModule
警告:当前不支持在使用CUDA张量时使用RemoteModule
RemoteModule提供了一种简便方式,可以在不同进程上远程创建nn.Module。实际模块运行在远程主机上,但本地主机持有该模块的句柄,并能像调用常规nn.Module一样调用它。不过这种调用会触发对远程端的RPC请求,必要时可通过RemoteModule支持的额外API实现异步调用。
class torch.distributed.nn.api.remote_module.RemoteModule(*args, **kwargs)
RemoteModule 实例只能在 RPC 初始化完成后创建。
它会在指定的远程节点上创建一个用户自定义模块。其行为与常规 nn.Module 类似,区别在于 forward 方法会在远程节点上执行。
该模块会处理自动梯度记录,确保反向传播能将梯度回传到对应的远程模块。
它会根据 module_cls 的 forward 方法签名生成两个方法:forward_async 和 forward。其中 forward_async 以异步方式运行并返回一个 Future 对象。这两个方法的参数与 module_cls 返回模块的 forward 方法完全一致。
例如,若 module_cls 返回的 nn.Linear 实例具有如下方法签名:def forward(input: Tensor) -> Tensor:,那么生成的 RemoteModule 将包含两个对应方法:
def forward(input: Tensor) -> Tensor:
def forward_async(input: Tensor) -> Future[Tensor]:
参数说明
remote_device (str)– 目标工作节点上放置该模块的设备位置。格式应为"<工作节点名>/<设备>“,其中设备字段可解析为 torch.device 类型。例如:“trainer0/cpu”、“trainer0”、“ps0/cuda:0”。设备字段可省略,默认值为"cpu”。module_cls (nn.Module)– 需要在远程创建的模块类。例如,
>>> class MyModule(nn.Module):
>>> def forward(input):
>>> return input + 1
>>> >
>>> module_cls = MyModuleargs (Sequence, Optional)– 传递给module_cls的参数序列。kwargs (Dict, Optional)– 传递给module_cls的关键字参数字典。
返回值:一个远程模块实例,该实例封装了由用户提供的 module_cls 创建的 Module。它具有阻塞式的 forward 方法以及一个异步的 forward_async 方法,后者会返回远程端用户模块上 forward 调用的 Future 对象。
示例:在以下两个不同进程中运行代码:
>>> # On worker 0:
>>> import torch
>>> import torch.distributed.rpc as rpc
>>> from torch import nn, Tensor
>>> from torch.distributed.nn.api.remote_module import RemoteModule
>>> >
>>> rpc.init_rpc("worker0", rank=0, world_size=2)
>>> remote_linear_module = RemoteModule(
>>> "worker1/cpu", nn.Linear, args=(20, 30), >>)
>>> input = torch.randn(128, 20)
>>> ret_fut = remote_linear_module.forward_async(input)
>>> ret = ret_fut.wait()
>>> rpc.shutdown()>>> # On worker 1:
>>> import torch
>>> import torch.distributed.rpc as rpc
>>> >
>>> rpc.init_rpc("worker1", rank=1, world_size=2)
>>> rpc.shutdown()此外,一个结合了DistributedDataParallel(DDP)的更实用示例可以在本教程中找到。
get_module_rref()
返回一个指向远程模块的 RRef(RRef[nn.Module])。
返回类型:RRef[Module]
remote_parameters(recurse=True)
返回一个指向远程模块参数的RRef列表。
该方法通常可与DistributedOptimizer配合使用。
参数
recurse ([bool])- 若为True,则返回远程模块及其所有子模块的参数;否则仅返回直接属于远程模块的参数。
返回值:远程模块参数的RRef列表(List[RRef[nn.Parameter]])。
返回类型 : list [torch.distributed.rpc.api.RRef[[torch.nn.parameter.Parameter ]]
分布式自动求导框架
警告:当前不支持使用CUDA张量时的分布式自动求导功能
本模块提供基于RPC的分布式自动求导框架,适用于模型并行训练等场景。简而言之,应用程序可以通过RPC发送和接收梯度记录张量。在前向传播过程中,我们会记录通过RPC发送的梯度记录张量;在反向传播阶段,则利用这些信息通过RPC执行分布式反向传播。更多细节请参阅分布式自动求导设计。
torch.distributed.autograd.backward(context_id: int , roots: List[Tensor ], retain_graph=False) → None
使用提供的根节点启动分布式反向传播过程。当前实现的是FAST模式算法,该算法假设所有在同一分布式自动求导上下文中跨工作节点发送的RPC消息,都会成为反向传播期间计算图的一部分。
系统会利用提供的根节点来发现自动求导计算图并建立正确的依赖关系。该方法会阻塞,直到整个自动求导计算完成。
梯度会被累积到各个节点对应的torch.distributed.autograd.context中。具体的自动求导上下文是通过调用torch.distributed.autograd.backward()时传入的context_id来查找的。如果找不到对应ID的有效上下文,系统会抛出错误。可以通过get_gradients()API来获取累积的梯度。
参数说明:
context_id (int)- 需要获取梯度的自动求导上下文IDroots (list)- 表示自动求导计算根节点的张量列表,所有张量必须是标量retain_graph ([bool], Optional)- 若设为False,用于计算梯度的计算图会被释放。注意在绝大多数情况下不需要将此参数设为True,通常可以通过更高效的方式实现多次反向传播。只有在需要多次运行反向传播时,才需要将此参数设为True。
示例:
>>> import torch.distributed.autograd as dist_autograd
>>> with dist_autograd.context() as context_id:
>>> pred = model.forward()
>>> loss = loss_func(pred, loss)
>>> dist_autograd.backward(context_id, loss)class torch.distributed.autograd.context
上下文对象,用于在使用分布式自动微分时封装前向和反向传播过程。在with语句中生成的context_id用于在所有工作节点上唯一标识一个分布式反向传播过程。每个工作节点存储与该context_id关联的元数据,这些元数据是正确执行分布式自动微分过程所必需的。
示例:
>>> import torch.distributed.autograd as dist_autograd
>>> with dist_autograd.context() as context_id:
>>> t1 = torch.rand((3, 3), requires_grad=True)
>>> t2 = torch.rand((3, 3), requires_grad=True)
>>> loss = rpc.rpc_sync("worker1", torch.add, args=(t1, t2)).sum()
>>> dist_autograd.backward(context_id, [loss])torch.distributed.autograd.get_gradients(context_id: int ) → Dict[Tensor , Tensor ]
获取从 Tensor 到对应梯度的映射关系
在分布式自动求导的反向传播过程中,该方法会检索与给定 context_id 对应的上下文内累积的梯度。
参数
context_id ( int )– 需要获取梯度的自动求导上下文 ID。
返回值:返回一个映射关系,其中键为 Tensor,值为该 Tensor 关联的梯度。
示例:
>>> import torch.distributed.autograd as dist_autograd
>>> with dist_autograd.context() as context_id:
>>> t1 = torch.rand((3, 3), requires_grad=True)
>>> t2 = torch.rand((3, 3), requires_grad=True)
>>> loss = t1 + t2
>>> dist_autograd.backward(context_id, [loss.sum()])
>>> grads = dist_autograd.get_gradients(context_id)
>>> print(grads[t1])
>>> print(grads[t2])关于RPC Autograd的更多信息
- 分布式Autograd设计
-
背景介绍
-
前向传播中的Autograd记录
-
分布式Autograd上下文
-
分布式反向传播
- 计算依赖关系
- FAST模式算法
- SMART模式算法
-
分布式优化器
-
简单端到端示例
分布式优化器
有关分布式优化器的文档,请参阅 torch.distributed.optim 页面。
设计说明
分布式自动求导设计说明涵盖了基于RPC的分布式自动求导框架设计,该框架适用于模型并行训练等应用场景。
- 分布式自动求导设计
RRef设计说明阐述了RRef(远程引用)协议的设计,该协议用于框架中引用远程工作节点上的值。
- 远程引用协议
教程
RPC 教程向用户介绍 RPC 框架,提供多个使用 torch.distributed.rpc API 的示例应用,并演示如何使用 性能分析器 来分析基于 RPC 的工作负载。
- 分布式 RPC 框架入门
- 使用分布式 RPC 框架实现参数服务器
- 将分布式数据并行 (Distributed DataParallel) 与分布式 RPC 框架结合使用(涵盖 RemoteModule)
- 分析基于 RPC 的工作负载
- 实现批量 RPC 处理
- 分布式流水线并行
一、关于 NeMo
项目概览
NVIDIA NeMo 是一个可扩展的云原生生成式AI框架,专为研究大型语言模型(LLM)、多模态模型(MM)、自动语音识别(ASR)、文本转语音(TTS)和计算机视觉(CV)领域的研究人员和PyTorch开发者设计。
相关链接资源
- Github:https://github.com/NVIDIA/NeMo
- 官方文档:https://docs.nvidia.com/nemo-framework/user-guide/latest/playbooks/index.html
- Hugging Face:https://huggingface.co/models?library=nemo&sort=downloads&search=nvidia
- NVIDIA NGC:https://catalog.ngc.nvidia.com/models?query=nemo&orderBy=weightPopularDESC
- 演示视频:https://developer.nvidia.com/nemo-microservices-early-access
- 社区支持:Discussions Board
- License:Apache 2.0
NeMo 2.0 新特性
NVIDIA NeMo 2.0 相比前代 NeMo 1.0 进行了多项重大改进,显著提升了灵活性、性能和可扩展性。
- 基于 Python 的配置 - NeMo 2.0 从 YAML 文件转向基于 Python 的配置方案,提供更高的灵活性和控制力。这一转变使得通过编程方式扩展和自定义配置变得更加便捷。
- 模块化抽象 - 通过采用 PyTorch Lightning 的模块化抽象,NeMo 2.0 简化了模型适配和实验流程。这种模块化方法让开发者能更轻松地修改模型组件并进行实验。
- 可扩展性 - NeMo 2.0 借助 NeMo-Run 工具无缝扩展至数千块 GPU 的大规模实验。该工具专为简化跨计算环境的机器学习实验配置、执行和管理而设计。
总体而言,这些改进使 NeMo 2.0 成为功能强大、可扩展且用户友好的 AI 模型开发框架。
重要提示:NeMo 2.0 目前支持 LLM(大语言模型)和 VLM(视觉语言模型)系列模型。
NeMo 2.0 入门指南
- 参考快速入门,了解如何使用 NeMo-Run 在本地和 slurm 集群上启动 NeMo 2.0 实验的示例。
- 有关 NeMo 2.0 的更多信息,请参阅 NeMo 框架用户指南。
- NeMo 2.0 配方库提供了使用 NeMo 2.0 和 NeMo-Run 启动大规模运行的额外示例。
- 要深入了解 NeMo 2.0 的主要功能,请查看功能指南。
- 如需从 NeMo 1.0 迁移到 2.0 版本,请按照迁移指南中的分步说明操作。
开始使用 Cosmos
NeMo Curator 和 NeMo Framework 支持对 Cosmos 世界基础模型进行视频数据整理和训练后处理。
这些模型已开源,并可在 NGC 和 Hugging Face 上获取。
如需了解视频数据集的更多信息,请参阅 NeMo Curator。
若想使用 NeMo Framework 针对自定义物理 AI 任务对世界基础模型进行训练后处理,请查看 Cosmos Diffusion 模型 和 Cosmos Autoregressive 模型。
LLM与多模态模型的训练、对齐与定制
所有NeMo模型均采用Lightning框架进行训练,可自动扩展至数千块GPU。
最新NeMo框架容器的性能基准测试结果可参阅此处。
NeMo模型在适用场景下会运用前沿的分布式训练技术,通过整合并行策略实现超大规模模型的高效训练。这些技术包括:张量并行(TP)、流水线并行(PP)、全分片数据并行(FSDP)、专家混合(MoE)、以及采用BFloat16和FP8的混合精度训练等。
基于Transformer架构的NeMo大语言模型和多模态模型采用NVIDIA Transformer Engine在NVIDIA Hopper GPU上实现FP8训练,同时利用NVIDIA Megatron Core扩展Transformer模型的训练规模。
NeMo大语言模型支持与前沿对齐方法结合,包括SteerLM、直接偏好优化(DPO)以及基于人类反馈的强化学习(RLHF)。更多详情请参见NVIDIA NeMo Aligner。
除监督微调(SFT)外,NeMo还支持最新的参数高效微调(PEFT)技术,例如LoRA、P-Tuning、适配器和IA3。完整支持的模型与技术列表请参考NeMo框架用户指南。
大语言模型与多模态模型的部署与优化
NVIDIA NeMo 微服务可用于部署和优化 NeMo 大语言模型及多模态模型。
语音 AI
NeMo 的自动语音识别(ASR)和文本转语音(TTS)模型可通过 NVIDIA Riva 进行推理优化并部署到生产环境中使用。
NeMo 框架启动器
重要提示:
NeMo 框架启动器仅兼容 NeMo 1.0 版本。如需使用 NeMo 2.0 启动实验,推荐使用 NeMo-Run。
NeMo 框架启动器 是一款云原生工具,旨在简化 NeMo 框架的使用体验。它用于在 CSP(云服务提供商)和 Slurm 集群上启动端到端的 NeMo 框架训练任务。
NeMo 框架启动器包含丰富的训练 NeMo 大语言模型(LLM)的配方、脚本、工具和文档。它还集成了 NeMo 框架的 自动配置器,该功能专为在特定集群上寻找最优模型并行配置而设计。
要快速上手 NeMo 框架启动器,请参阅 NeMo 框架操作手册。目前 NeMo 框架启动器暂不支持 ASR(自动语音识别)和 TTS(文本转语音)训练,但相关功能即将推出。
NeMo框架入门指南
开始使用NeMo框架非常简单。最先进的预训练NeMo模型可在Hugging Face Hub和NVIDIA NGC免费获取。只需几行代码,这些模型就能用于生成文本或图像、转录音频以及合成语音。
我们提供了丰富的教程,可在Google Colab或我们的NGC NeMo框架容器中运行。对于希望使用NeMo Framework Launcher训练NeMo模型的用户,我们还准备了详细的操作手册。
针对需要从头训练NeMo模型或微调现有模型的高级用户,我们提供了一套完整的示例脚本,支持多GPU/多节点训练。
二、安装 NeMo 框架
NeMo 框架提供多种安装方式,您可以根据实际需求选择最适合的方法。不同领域可能适用不同的安装方案:
- Conda/Pip:通过原生 Pip 将 NeMo-Framework 安装到虚拟环境中
- 适用于在任何支持平台上探索 NeMo
- 这是语音识别(ASR)和文本转语音(TTS)领域的推荐安装方式
- 其他领域的功能完整性可能受限
- NGC PyTorch 容器:在高度优化的容器中从源码安装功能完整的 NeMo-Framework
- 适合需要在优化容器中进行源码安装的用户
- NGC NeMo 容器:即用型 NeMo-Framework 解决方案
- 为追求最高性能的用户设计
- 包含所有经过性能与收敛性测试的预装依赖项
1、支持矩阵
NeMo-Framework 根据操作系统/平台和安装方式提供不同级别的支持。以下是各支持级别的概述:
- 完全支持:最佳性能和功能完整性
- 有限支持:用于探索 NeMo
- 暂不支持:正在开发中
- 已弃用:支持已终止
当前支持级别请参考下表:
| 操作系统/平台 | 通过PyPi安装 | 通过NGC容器源码安装 |
|---|---|---|
linux - amd64/x84_64 | 有限支持 | 完全支持 |
linux - arm64 | 有限支持 | 有限支持 |
darwin - amd64/x64_64 | 已弃用 | 已弃用 |
darwin - arm64 | 有限支持 | 有限支持 |
windows - amd64/x64_64 | 暂不支持 | 暂不支持 |
windows - arm64 | 暂不支持 | 暂不支持 |
2、Conda / Pip
在新创建的 Conda 环境中安装 NeMo:
conda create --name nemo python==3.10.12
conda activate nemo
选择正确版本
NeMo-Framework 会为每个版本发布预构建的 wheel 包。若要通过此类 wheel 安装 nemo_toolkit,请使用以下安装方法:
pip install "nemo_toolkit[all]"
如果需要更具体的版本,我们推荐使用 Pip-VCS 安装方式。从 NVIDIA/NeMo 仓库获取您希望安装的提交记录、分支或标签。
要基于 Git 引用 $REF 安装 nemo_toolkit,请使用以下安装方法:
git clone https://github.com/NVIDIA/NeMo
cd NeMo
git checkout @${REF:-'main'}
pip install '.[all]'
安装特定领域模块
要安装NeMo的特定领域模块,首先需要按照上述说明安装nemo_toolkit。然后运行以下针对特定领域的命令:
pip install nemo_toolkit['all'] # or pip install "nemo_toolkit['all']@git+https://github.com/NVIDIA/NeMo@${REF:-'main'}"
pip install nemo_toolkit['asr'] # or pip install "nemo_toolkit['asr']@git+https://github.com/NVIDIA/NeMo@$REF:-'main'}"
pip install nemo_toolkit['nlp'] # or pip install "nemo_toolkit['nlp']@git+https://github.com/NVIDIA/NeMo@${REF:-'main'}"
pip install nemo_toolkit['tts'] # or pip install "nemo_toolkit['tts']@git+https://github.com/NVIDIA/NeMo@${REF:-'main'}"
pip install nemo_toolkit['vision'] # or pip install "nemo_toolkit['vision']@git+https://github.com/NVIDIA/NeMo@${REF:-'main'}"
pip install nemo_toolkit['multimodal'] # or pip install "nemo_toolkit['multimodal']@git+https://github.com/NVIDIA/NeMo@${REF:-'main'}"
3、NGC PyTorch 容器
注意:以下步骤从 24.04 版本(NeMo-Toolkit 2.3.0)开始支持
我们建议您从基础 NVIDIA PyTorch 容器开始:nvcr.io/nvidia/pytorch:25.01-py3。
如果从基础 NVIDIA PyTorch 容器开始,您需要首先启动该容器:
docker run \--gpus all \-it \--rm \--shm-size=16g \--ulimit memlock=-1 \--ulimit stack=67108864 \nvcr.io/nvidia/pytorch:${NV_PYTORCH_TAG:-'nvcr.io/nvidia/pytorch:25.01-py3'}
从 NVIDIA/NeMo 获取您想要安装的提交记录/分支/标签。
要从此 Git 引用 $REF 安装 nemo_toolkit 及其所有依赖项,请使用以下安装方法:
cd /opt
git clone https://github.com/NVIDIA/NeMo
cd NeMo
git checkout ${REF:-'main'}
bash reinstall.sh --library all
三、NGC NeMo 容器
NeMo 容器会随着 NeMo 版本更新同步发布。现在 NeMo 框架已支持将大语言模型(LLMs)、多模态模型(MMs)、自动语音识别(ASR)和文本转语音(TTS)整合到单个 Docker 容器中。您可以在 NeMo 版本发布页 查看已发布容器的更多信息。
要使用预构建的容器,请运行以下代码:
docker run \--gpus all \-it \--rm \--shm-size=16g \--ulimit memlock=-1 \--ulimit stack=67108864 \nvcr.io/nvidia/pytorch:${NV_PYTORCH_TAG:-'nvcr.io/nvidia/nemo:25.02'}
一、关于 NeMo
项目概览
NVIDIA NeMo 是一个可扩展的云原生生成式AI框架,专为研究大型语言模型(LLM)、多模态模型(MM)、自动语音识别(ASR)、文本转语音(TTS)和计算机视觉(CV)领域的研究人员和PyTorch开发者设计。
相关链接资源
- Github:https://github.com/NVIDIA/NeMo
- 官方文档:https://docs.nvidia.com/nemo-framework/user-guide/latest/playbooks/index.html
- Hugging Face:https://huggingface.co/models?library=nemo&sort=downloads&search=nvidia
- NVIDIA NGC:https://catalog.ngc.nvidia.com/models?query=nemo&orderBy=weightPopularDESC
- 演示视频:https://developer.nvidia.com/nemo-microservices-early-access
- 社区支持:Discussions Board
- License:Apache 2.0
NeMo 2.0 新特性
NVIDIA NeMo 2.0 相比前代 NeMo 1.0 进行了多项重大改进,显著提升了灵活性、性能和可扩展性。
- 基于 Python 的配置 - NeMo 2.0 从 YAML 文件转向基于 Python 的配置方案,提供更高的灵活性和控制力。这一转变使得通过编程方式扩展和自定义配置变得更加便捷。
- 模块化抽象 - 通过采用 PyTorch Lightning 的模块化抽象,NeMo 2.0 简化了模型适配和实验流程。这种模块化方法让开发者能更轻松地修改模型组件并进行实验。
- 可扩展性 - NeMo 2.0 借助 NeMo-Run 工具无缝扩展至数千块 GPU 的大规模实验。该工具专为简化跨计算环境的机器学习实验配置、执行和管理而设计。
总体而言,这些改进使 NeMo 2.0 成为功能强大、可扩展且用户友好的 AI 模型开发框架。
重要提示:NeMo 2.0 目前支持 LLM(大语言模型)和 VLM(视觉语言模型)系列模型。
NeMo 2.0 入门指南
- 参考快速入门,了解如何使用 NeMo-Run 在本地和 slurm 集群上启动 NeMo 2.0 实验的示例。
- 有关 NeMo 2.0 的更多信息,请参阅 NeMo 框架用户指南。
- NeMo 2.0 配方库提供了使用 NeMo 2.0 和 NeMo-Run 启动大规模运行的额外示例。
- 要深入了解 NeMo 2.0 的主要功能,请查看功能指南。
- 如需从 NeMo 1.0 迁移到 2.0 版本,请按照迁移指南中的分步说明操作。
开始使用 Cosmos
NeMo Curator 和 NeMo Framework 支持对 Cosmos 世界基础模型进行视频数据整理和训练后处理。
这些模型已开源,并可在 NGC 和 Hugging Face 上获取。
如需了解视频数据集的更多信息,请参阅 NeMo Curator。
若想使用 NeMo Framework 针对自定义物理 AI 任务对世界基础模型进行训练后处理,请查看 Cosmos Diffusion 模型 和 Cosmos Autoregressive 模型。
LLM与多模态模型的训练、对齐与定制
所有NeMo模型均采用Lightning框架进行训练,可自动扩展至数千块GPU。
最新NeMo框架容器的性能基准测试结果可参阅此处。
NeMo模型在适用场景下会运用前沿的分布式训练技术,通过整合并行策略实现超大规模模型的高效训练。这些技术包括:张量并行(TP)、流水线并行(PP)、全分片数据并行(FSDP)、专家混合(MoE)、以及采用BFloat16和FP8的混合精度训练等。
基于Transformer架构的NeMo大语言模型和多模态模型采用NVIDIA Transformer Engine在NVIDIA Hopper GPU上实现FP8训练,同时利用NVIDIA Megatron Core扩展Transformer模型的训练规模。
NeMo大语言模型支持与前沿对齐方法结合,包括SteerLM、直接偏好优化(DPO)以及基于人类反馈的强化学习(RLHF)。更多详情请参见NVIDIA NeMo Aligner。
除监督微调(SFT)外,NeMo还支持最新的参数高效微调(PEFT)技术,例如LoRA、P-Tuning、适配器和IA3。完整支持的模型与技术列表请参考NeMo框架用户指南。
大语言模型与多模态模型的部署与优化
NVIDIA NeMo 微服务可用于部署和优化 NeMo 大语言模型及多模态模型。
语音 AI
NeMo 的自动语音识别(ASR)和文本转语音(TTS)模型可通过 NVIDIA Riva 进行推理优化并部署到生产环境中使用。
NeMo 框架启动器
重要提示:
NeMo 框架启动器仅兼容 NeMo 1.0 版本。如需使用 NeMo 2.0 启动实验,推荐使用 NeMo-Run。
NeMo 框架启动器 是一款云原生工具,旨在简化 NeMo 框架的使用体验。它用于在 CSP(云服务提供商)和 Slurm 集群上启动端到端的 NeMo 框架训练任务。
NeMo 框架启动器包含丰富的训练 NeMo 大语言模型(LLM)的配方、脚本、工具和文档。它还集成了 NeMo 框架的 自动配置器,该功能专为在特定集群上寻找最优模型并行配置而设计。
要快速上手 NeMo 框架启动器,请参阅 NeMo 框架操作手册。目前 NeMo 框架启动器暂不支持 ASR(自动语音识别)和 TTS(文本转语音)训练,但相关功能即将推出。
NeMo框架入门指南
开始使用NeMo框架非常简单。最先进的预训练NeMo模型可在Hugging Face Hub和NVIDIA NGC免费获取。只需几行代码,这些模型就能用于生成文本或图像、转录音频以及合成语音。
我们提供了丰富的教程,可在Google Colab或我们的NGC NeMo框架容器中运行。对于希望使用NeMo Framework Launcher训练NeMo模型的用户,我们还准备了详细的操作手册。
针对需要从头训练NeMo模型或微调现有模型的高级用户,我们提供了一套完整的示例脚本,支持多GPU/多节点训练。
二、安装 NeMo 框架
NeMo 框架提供多种安装方式,您可以根据实际需求选择最适合的方法。不同领域可能适用不同的安装方案:
- Conda/Pip:通过原生 Pip 将 NeMo-Framework 安装到虚拟环境中
- 适用于在任何支持平台上探索 NeMo
- 这是语音识别(ASR)和文本转语音(TTS)领域的推荐安装方式
- 其他领域的功能完整性可能受限
- NGC PyTorch 容器:在高度优化的容器中从源码安装功能完整的 NeMo-Framework
- 适合需要在优化容器中进行源码安装的用户
- NGC NeMo 容器:即用型 NeMo-Framework 解决方案
- 为追求最高性能的用户设计
- 包含所有经过性能与收敛性测试的预装依赖项
1、支持矩阵
NeMo-Framework 根据操作系统/平台和安装方式提供不同级别的支持。以下是各支持级别的概述:
- 完全支持:最佳性能和功能完整性
- 有限支持:用于探索 NeMo
- 暂不支持:正在开发中
- 已弃用:支持已终止
当前支持级别请参考下表:
| 操作系统/平台 | 通过PyPi安装 | 通过NGC容器源码安装 |
|---|---|---|
linux - amd64/x84_64 | 有限支持 | 完全支持 |
linux - arm64 | 有限支持 | 有限支持 |
darwin - amd64/x64_64 | 已弃用 | 已弃用 |
darwin - arm64 | 有限支持 | 有限支持 |
windows - amd64/x64_64 | 暂不支持 | 暂不支持 |
windows - arm64 | 暂不支持 | 暂不支持 |
2、Conda / Pip
在新创建的 Conda 环境中安装 NeMo:
conda create --name nemo python==3.10.12
conda activate nemo
选择正确版本
NeMo-Framework 会为每个版本发布预构建的 wheel 包。若要通过此类 wheel 安装 nemo_toolkit,请使用以下安装方法:
pip install "nemo_toolkit[all]"
如果需要更具体的版本,我们推荐使用 Pip-VCS 安装方式。从 NVIDIA/NeMo 仓库获取您希望安装的提交记录、分支或标签。
要基于 Git 引用 $REF 安装 nemo_toolkit,请使用以下安装方法:
git clone https://github.com/NVIDIA/NeMo
cd NeMo
git checkout @${REF:-'main'}
pip install '.[all]'
安装特定领域模块
要安装NeMo的特定领域模块,首先需要按照上述说明安装nemo_toolkit。然后运行以下针对特定领域的命令:
pip install nemo_toolkit['all'] # or pip install "nemo_toolkit['all']@git+https://github.com/NVIDIA/NeMo@${REF:-'main'}"
pip install nemo_toolkit['asr'] # or pip install "nemo_toolkit['asr']@git+https://github.com/NVIDIA/NeMo@$REF:-'main'}"
pip install nemo_toolkit['nlp'] # or pip install "nemo_toolkit['nlp']@git+https://github.com/NVIDIA/NeMo@${REF:-'main'}"
pip install nemo_toolkit['tts'] # or pip install "nemo_toolkit['tts']@git+https://github.com/NVIDIA/NeMo@${REF:-'main'}"
pip install nemo_toolkit['vision'] # or pip install "nemo_toolkit['vision']@git+https://github.com/NVIDIA/NeMo@${REF:-'main'}"
pip install nemo_toolkit['multimodal'] # or pip install "nemo_toolkit['multimodal']@git+https://github.com/NVIDIA/NeMo@${REF:-'main'}"
3、NGC PyTorch 容器
注意:以下步骤从 24.04 版本(NeMo-Toolkit 2.3.0)开始支持
我们建议您从基础 NVIDIA PyTorch 容器开始:nvcr.io/nvidia/pytorch:25.01-py3。
如果从基础 NVIDIA PyTorch 容器开始,您需要首先启动该容器:
docker run \--gpus all \-it \--rm \--shm-size=16g \--ulimit memlock=-1 \--ulimit stack=67108864 \nvcr.io/nvidia/pytorch:${NV_PYTORCH_TAG:-'nvcr.io/nvidia/pytorch:25.01-py3'}
从 NVIDIA/NeMo 获取您想要安装的提交记录/分支/标签。
要从此 Git 引用 $REF 安装 nemo_toolkit 及其所有依赖项,请使用以下安装方法:
cd /opt
git clone https://github.com/NVIDIA/NeMo
cd NeMo
git checkout ${REF:-'main'}
bash reinstall.sh --library all
三、NGC NeMo 容器
NeMo 容器会随着 NeMo 版本更新同步发布。现在 NeMo 框架已支持将大语言模型(LLMs)、多模态模型(MMs)、自动语音识别(ASR)和文本转语音(TTS)整合到单个 Docker 容器中。您可以在 NeMo 版本发布页 查看已发布容器的更多信息。
要使用预构建的容器,请运行以下代码:
docker run \--gpus all \-it \--rm \--shm-size=16g \--ulimit memlock=-1 \--ulimit stack=67108864 \nvcr.io/nvidia/pytorch:${NV_PYTORCH_TAG:-'nvcr.io/nvidia/nemo:25.02'}
2025-05-10(六)