【RAG官方大神笔记】检索增强生成 (RAG):Python AI 教程的详细介绍
从零开始学习检索增强生成 (RAG):Python AI 教程的详细介绍
-
引言:检索增强生成 (RAG) 概述
- 检索增强生成 (RAG) 是一种先进的人工智能框架,它巧妙地融合了传统信息检索系统的强大功能与生成式大型语言模型 (LLM) 的卓越能力 1。其核心思想在于,通过从广泛的外部知识库中动态检索相关的事实和信息,来增强 LLM 的知识储备,使其在生成文本响应时能够依据最新、最准确的数据,并为用户提供 LLM 生成过程的透明度 1。RAG 的重要性在于它能够克服传统 LLM 依赖于静态训练数据的固有局限性,使得 AI 模型能够处理需要特定领域知识或实时信息的复杂查询。通过在生成答案之前检索并整合外部知识,RAG 显著提升了 LLM 的实用性和可靠性,尤其是在需要高度准确性和最新信息的应用场景中 1。这种机制不仅提高了 LLM 的性能,还增强了用户对模型输出的信任感,因为用户可以追溯并验证答案的来源 3。根据 Ars Technica 的精辟见解,RAG 的本质在于将 LLM 的强大生成能力与网络搜索或文档查找等信息检索过程相结合,从而有效地帮助 LLM 坚持事实,最终提高其整体性能 3。IBM 的专家 Marina Danilevsky 将 RAG 比作 LLM 的“开放书籍”考试,强调了模型在回答问题时可以查阅外部知识,而不是仅仅依赖记忆中的信息,这进一步凸显了 RAG 在提升 LLM 知识水平和响应质量方面的重要性 2。
- RAG 的出现并非偶然,而是为了解决大型语言模型在实际应用中面临的一系列核心问题。其中一个主要问题是 LLM 固有的知识局限性。由于 LLM 是基于大量的公开数据进行训练的,因此它们无法直接访问用户的私有数据或特定领域的数据 4。此外,LLM 的知识还存在一个“截止日期”,即它们无法了解其训练数据截止日期之后发生的事件或产生的新信息 1。为了使 AI 应用程序真正有效,它们需要能够利用这些自定义数据,理解特定领域的知识,并提供相关且具体的响应,而不是泛泛而谈 4。检索增强生成技术正是为了解决这些问题而诞生的。它通过在用户查询时检索相关的外部数据,并将其作为增强的上下文提供给 LLM,从而弥合了模型知识的不足 4。这种方法不仅将静态的 LLM 与实时的数据检索能力连接起来,还使得组织能够利用自己的数据来增强 LLM 的性能,而无需进行耗时且昂贵的模型重新训练 4。此外,RAG 还有助于减少 LLM 产生不准确甚至虚假信息的风险,因为它引导 LLM 从预先确定的权威知识来源检索信息 7。最终,RAG 的目标是显著提高 LLM 在知识密集型任务中的表现,通过减少模型对内部参数的过度依赖,降低生成过时或不准确信息的可能性,并提升生成内容整体的可信度 8。
- 检索增强生成 (RAG) 的基本工作流程可以概括为三个关键步骤:检索、增强和生成 1。首先,当用户提出一个问题或查询时,RAG 系统会接收这个输入 1。然后,系统会利用强大的检索机制,例如高效的搜索算法,从预先构建的外部知识库中搜索与用户查询最相关的信息 1。这个知识库可以包含各种各样的数据,包括网页、庞大的知识图谱、结构化的数据库等等 1。一旦检索到相关的信息片段,RAG 系统会对这些信息进行预处理,例如进行分词、词干提取、去除停用词等操作,以便更好地融入到后续的生成过程中 1。接下来,预处理后的检索信息会与用户的原始查询一起,被无缝地整合到发送给预训练的 LLM 的提示 (prompt) 中 1。通过提供这个经过增强的上下文,LLM 能够更全面地理解用户的意图和查询的主题,从而超越其自身训练数据所包含的知识范围 1。最后,LLM 会利用这个融合了检索信息的提示,生成一个更精确、信息更丰富、并且更具吸引力的文本响应,直接回答用户的查询,并遵循系统的指令和安全约束 1。在一些更高级的 RAG 系统中,可能还包括对检索到的文档进行评估和重新排序的步骤,以进一步提高检索质量,确保 LLM 能够获得最相关的上下文信息 1。
-
RAG 的关键组成部分
- 大型语言模型 (LLM) 是 RAG 系统的智能核心,它承担着理解用户查询和生成最终文本响应的关键职责 7。LLM 拥有理解人类语言的强大能力,并且能够根据其庞大的训练数据以及接收到的上下文信息,生成连贯且类似人类的文本 4。在 RAG 框架下,LLM 的作用是至关重要的,因为它不仅需要理解用户的原始查询,还要能够有效地利用检索系统提供的外部知识,将两者融合起来,最终生成既准确又具有上下文相关性的答案 7。值得一提的是,RAG 具有高度的灵活性,可以与各种不同的 LLM 配合使用,包括但不限于 OpenAI 的 GPT 系列模型、Google 的 Gemini 模型以及 Meta 的 Llama 模型等等 7。不同的 LLM 在理解上下文、生成文本的流畅性以及创造性方面可能存在差异,因此,在实际应用中,选择最适合特定场景需求的 LLM 对于 RAG 系统的整体性能至关重要。LLM 的强大能力与 RAG 框架的外部知识增强机制相结合,使得 AI 系统能够处理更加复杂和知识密集型的任务,为用户提供更优质的体验。
- 外部知识库是 RAG 系统中至关重要的信息来源,它为 LLM 提供了超出其自身训练数据范围的丰富知识 1。这个知识库可以包含各种各样的数据格式,例如大量的文档集合、结构化的数据库、广阔的网页资源等等 1。为了确保 RAG 系统能够提供高质量的响应,知识库的内容需要与具体的应用场景高度相关,并且必须是权威可靠且及时更新的最新信息 7。RAG 系统具备连接到多种不同类型知识库的能力,这使得它能够灵活地适应各种数据存储和管理需求,例如,它可以连接到专门用于存储向量嵌入的向量数据库,也可以连接到存储传统数据的关系型数据库,甚至可以访问文件系统或通过 API 接口获取外部信息 7。外部知识库的质量和相关性直接决定了 RAG 系统能够检索到的信息的质量,因此,构建一个高质量的、与应用场景紧密相关的知识库是 RAG 系统成功的关键步骤。只有当知识库中存储了丰富、准确且最新的信息,RAG 系统才能够有效地增强 LLM 的知识,并为用户提供满意的答案。
- 在将外部数据整合到 RAG 系统的知识库中之前,通常需要进行一系列的加载和处理步骤 9。这个过程的首要环节是从各种不同的数据来源加载文档,这些来源可能包括本地的 PDF 文件、远程的网站内容、结构化的数据库记录等等 9。为了方便后续的处理和利用,加载的文档通常需要被转换为 LLM 可以有效理解的文本格式 9。在 LangChain 等先进的框架中,提供了专门的文档加载器 (Document Loaders) 工具,这些工具能够处理来自各种数据源的数据,并将其转化为统一的文档对象列表,为后续的处理步骤奠定基础 13。数据加载完成之后,通常还需要对数据进行进一步的处理,例如提取出文档中的文本内容,去除可能存在的格式信息干扰,对文本数据进行必要的清洗等等 1。这些预处理步骤的目的是确保原始数据能够被有效地转化为 RAG 系统可用的格式,从而提高后续检索和生成过程的效率和准确性。不同的数据来源可能需要不同的加载方法和处理技术,因此,根据实际情况选择合适的数据加载和处理流程对于构建一个高效的 RAG 系统至关重要。
- 为了进一步提升检索的效率,并适应大型语言模型 (LLM) 在处理文本长度上的上下文窗口限制,通常需要将加载的文档分割成更小的、更易于管理的文本块,这些文本块通常被称为“chunks” 9。文本分割的过程通常由专门的文本分割器 (Text Splitters) 来完成,这些工具能够根据预设的规则,例如按照句子、段落或者固定的字符大小,将原本较大的文档分割成若干个更小的文本片段 9。在进行文本分割时,一个非常重要的考虑因素是需要尽可能地保持分割后的文本块的语义完整性,避免将原本密切相关的上下文信息人为地分割到不同的文本块中,从而影响后续的检索效果 9。选择合适的文本分割策略对于 RAG 系统的整体性能具有显著的影响。一个好的分割策略能够在保证检索到足够相关信息的同时,有效地避免信息冗余,并且确保分割后的文本块不会超出 LLM 的上下文窗口限制,从而为后续的增强和生成步骤提供最佳的输入 9。
- 嵌入模型在 RAG 系统中扮演着至关重要的角色,它们的主要功能是将分割后的文本块以及用户的查询语句转换成高维向量空间中的数值表示,这些数值表示被称为“embeddings” 7。这些向量之所以重要,是因为它们能够有效地捕捉到文本的语义信息,使得计算机能够理解不同文本之间的语义关联性 1。目前,有许多成熟且被广泛使用的嵌入模型可供选择,例如 OpenAI 提供的 OpenAI Embeddings 模型,Google 提供的 Google PaLM Embeddings 模型,以及 Hugging Face Transformers 库中提供的各种预训练模型等等 13。在 RAG 系统中,通过计算用户查询的嵌入向量与知识库中各个文本块的嵌入向量之间的相似度,通常使用的方法是计算向量之间的余弦相似度,系统就能够有效地衡量用户查询与知识库中不同文本块之间的语义相关性,从而找到最相关的文本块用于后续的增强和生成步骤 9。因此,选择一个能够准确捕捉文本语义信息的嵌入模型,对于 RAG 系统实现高效且准确的语义检索至关重要。
- 向量存储是 RAG 系统中用于高效存储和索引文本块的嵌入向量的关键组件,它的主要目的是为了能够快速地进行相似性搜索 7。在 RAG 系统中,知识库中所有文本块的嵌入向量都需要被存储在一个专门的数据库中,这个数据库就是向量存储 7。目前,市面上存在多种功能强大且被广泛应用的向量存储解决方案,例如 Chroma、FAISS、Pinecone 和 Milvus 等等 13。向量存储的核心功能在于能够提供高效的相似性搜索能力,这意味着当 RAG 系统接收到用户查询并将其转换为嵌入向量后,向量存储能够快速地在海量的已存储向量中找到与查询向量最相似的那些向量,从而定位到知识库中最相关的文本块 1。向量存储的选择直接关系到 RAG 系统的检索效率和整体的可扩展性。不同的向量存储在性能特点、功能特性以及成本方面可能存在显著的差异,因此,在构建 RAG 系统时,需要根据具体的应用需求和场景,仔细选择最合适的向量存储解决方案。
- 检索器在 RAG 系统中扮演着信息“雷达”的角色,其核心功能是根据用户提出的查询,从向量存储中高效地检索出那些最相关的文本块 。检索器的工作流程通常是这样的:首先,它会接收到用户的查询,然后将这个查询通过之前提到的嵌入模型转换为一个查询向量 9。接下来,检索器会在向量存储中执行相似性搜索操作,基于查询向量与存储的所有文本块向量之间的相似度进行比较,最终返回与查询最相似的前 K 个文本块,这里的 K 值是一个可以根据具体需求进行调整的参数 9。值得注意的是,LangChain 这样的框架提供了多种内置的检索技术,例如多查询检索器 (MultiQueryRetriever) 和多向量检索器 (MultiVectorRetriever),以及基于最大边际相关性 (Max marginal relevance) 的检索方法等等,这些高级技术旨在进一步提高检索的效果和准确性 14。检索器的设计和选择对于 RAG 系统能否找到高质量的相关信息至关重要,不同的检索策略适用于不同的应用场景和数据特点,因此,根据实际情况选择合适的检索器是构建高性能 RAG 系统的关键环节。
- 提示工程 (Prompt Engineering) 在 RAG 系统中扮演着至关重要的“指挥官”的角色,它指的是设计和优化发送给 LLM 的提示 (prompt),目的是精确地指导 LLM 如何有效地利用检索到的外部知识,并最终生成用户所期望的答案 7。在 RAG 的应用场景中,提示通常会包含两个关键部分:用户的原始查询以及检索系统找到的相关文本块 9。通过精心构建这样的提示,我们可以指示 LLM 基于这些被检索到的信息来回答用户的问题,从而确保答案的准确性和相关性都得到显著提高 9。一个有效的提示能够帮助 LLM 更好地理解用户的真实意图,并且能够引导 LLM 从检索到的信息中提取关键要点,最终生成更符合用户期望的高质量答案。因此,投入时间和精力进行提示工程,根据具体的应用场景和 LLM 的特性,设计出清晰、明确、有效的提示,是构建一个成功的 RAG 系统的关键环节之一。
- 生成模型在 RAG 系统中承担着“最终决策者”的角色,它通常就是我们所选择的大型语言模型 (LLM) 本身 7。生成模型接收到的是经过精心构建的提示,这个提示中包含了用户的原始查询以及检索系统提供的相关上下文信息 7。然后,生成模型会利用其自身强大的语言理解和生成能力,结合提示中提供的检索信息,最终生成自然流畅且易于理解的文本答案,直接回应用户的提问 7。为了确保最终呈现给用户的答案符合预期,生成模型的输出可能还需要经过进一步的格式化和后处理,以满足用户在格式、风格等方面的特定需求 9。因此,选择一个合适的、具有强大生成能力的 LLM 作为 RAG 系统中的生成模型至关重要,因为生成模型的质量直接决定了 RAG 系统最终输出的质量和用户体验。
-
RAG 的优势与益处
- RAG 技术最显著的优势之一在于其能够显著提升知识的时效性 1。众所周知,大型语言模型 (LLM) 的知识水平受到其训练数据的限制,这意味着它们可能无法提供关于最新事件或新近出现信息的准确回答。然而,RAG 通过引入外部知识库,使得 LLM 能够在生成响应时动态地检索最新的信息,从而有效地克服了这一局限性 1。更重要的是,RAG 系统甚至可以被配置为连接到实时更新的信息源,例如实时新闻网站或社交媒体平台,这确保了 LLM 能够随时获取最新的数据,并将其融入到生成的答案中 5。相较于传统的模型微调方法,RAG 提供了一种更为便捷和高效的知识更新方式,因为它无需对整个模型进行重新训练,只需保持外部知识库的更新即可 7。这对于那些需要处理快速变化信息或对实时数据有高度依赖的应用场景来说,RAG 无疑是一个极具价值的解决方案。
- RAG 技术的另一个核心优势是其能够显著增强生成文本的事实依据,并有效地减少 LLM 产生“幻觉”的可能性 1。所谓的“幻觉”指的是 LLM 在没有真实信息支持的情况下,生成看似合理但实际上并不存在的或不正确的信息。RAG 通过在生成答案的过程中,要求 LLM 必须基于从外部知识库检索到的事实和证据,从而极大地降低了这种风险 1。更重要的是,许多 RAG 系统还能够提供模型生成答案所依据的原始来源信息,这使得用户可以方便地验证答案的准确性,并对模型产生更高的信任感 2。通过这种方式,RAG 不仅提高了 LLM 生成内容的可靠性,还增强了其透明度,使得用户能够更好地理解模型是如何得出答案的,从而建立起更强的信任关系。
- RAG 技术通过整合来自特定且相关的外部知识来源的信息,能够显著提高 LLM 生成答案的准确性和相关性 1。与传统的 LLM 相比,RAG 不仅依赖于其自身训练数据中包含的知识,还能够访问并利用更广泛的信息,例如组织内部特定的知识库 7。这种能力使得 LLM 能够生成更具针对性的输出,更好地满足用户的具体需求。此外,RAG 模型还能够理解用户查询的上下文,并在此基础上生成全新的、更贴近人类语言习惯的回复,从而提供更加准确和相关的答案 11。通过这种方式,RAG 使得 LLM 在回答问题时能够考虑到更全面的信息,从而避免了仅仅基于有限的训练数据而产生的泛化或不准确的回答,最终提升了用户体验。
- 相较于传统的模型微调方法,RAG 技术提供了一种更经济高效的方式来扩展 LLM 的知识 1。模型微调通常需要大量的标注数据和昂贵的计算资源,尤其是在需要频繁更新模型知识的情况下,重新训练整个模型的成本是非常高昂的。然而,RAG 通过在用户查询时动态地从外部知识库检索相关信息,并将其作为上下文提供给 LLM,从而避免了重新训练整个模型的需要,大大降低了成本 5。这种经济高效的特性使得 RAG 技术能够被更广泛地应用,并使得更多的企业能够利用现有的 LLM 模型,通过有针对性的知识库来增强其能力,而无需承担高昂的重新训练费用 5。因此,RAG 技术使得生成式 AI 能够更广泛地被采用和使用,为各种应用场景提供了更具成本效益的解决方案 7。
- RAG 技术通过允许 LLM 在生成答案时提供准确的信息并标注其来源,从而显著增强了用户的信任感 2。具体来说,RAG 系统的输出可以包含对检索到的原始信息来源的引用或参考链接,这使得用户可以方便地追溯信息的出处,并自行查找源文档以获取更深入的理解或进一步的澄清 2。这种透明的机制使得用户能够验证 LLM 所提供信息的准确性,从而在很大程度上建立了用户对生成式 AI 解决方案的信任和信心 2。通过这种方式,RAG 不仅提高了 LLM 的可靠性,还增强了其透明度,使得用户能够更好地理解模型是如何得出答案的,从而建立起更强的信任关系。
- RAG 技术为开发者提供了更强大的控制能力,使得他们能够更有效地测试和改进他们的聊天应用程序 7。开发者可以根据实际需求,灵活地控制和更改 LLM 的信息来源,以便适应不断变化的应用场景或跨职能的使用需求 7。此外,RAG 还允许开发者对不同授权级别的用户进行敏感信息检索的限制,确保 LLM 生成的响应是适当且安全的 7。更重要的是,如果开发者发现 LLM 在回答特定问题时引用了不正确的信息来源,他们还可以通过 RAG 提供的机制进行故障排除和修复,从而不断提高系统的准确性和可靠性 7。这种更强的开发者控制能力使得组织能够更自信地将生成式 AI 技术应用于更广泛的领域,并根据实际反馈进行持续的优化和改进。
- RAG 技术通过为大型语言模型 (LLM) 提供超出其初始训练范围的外部数据,极大地扩展了 LLM 的应用场景 44。借助 RAG,用户实际上可以与各种数据存储库进行对话,这为开发全新的用户体验和应用模式开辟了广阔的空间 19。这意味着,RAG 的潜在应用数量可能远远超过现有可用数据集的数量,因为它使得 LLM 能够处理更加多样化和专业的任务。例如,一个经过医疗索引数据增强的 LLM 可以成为医生或护士的得力助手,而一个与市场数据相连接的 LLM 则可以为金融分析师提供强大的支持 19。更重要的是,RAG 技术扩展了 LLM 的应用领域,允许它们有效地利用特定领域或组织的内部知识库,而无需进行耗时且昂贵的模型重新训练 50。这种能力使得 LLM 能够应用于更广泛的实际场景中,为各行各业带来创新性的解决方案。
-
RAG 的挑战与局限性
- 尽管 RAG 技术带来了诸多优势,但在实际应用中仍然面临着一些挑战和局限性。其中一个主要的挑战在于如何保证检索到的信息的质量 51。RAG 模型的有效性在很大程度上取决于其检索机制的性能。如果检索到的文档或段落与用户的查询不相关、不准确,或者过于肤浅,那么最终生成的响应也很可能无法满足用户的需求 32。尤其是在处理复杂或需要深入理解的查询时,简单的关键词匹配技术可能无法准确地捕捉到用户的意图,从而导致检索到不相关或仅仅是表面上的信息 53。此外,RAG 系统在处理同义词、多义词以及查询中的细微差别时,也可能面临困难,从而导致检索到错误或不适用的信息 53。因此,如何设计出更智能、更精准的检索算法,确保 RAG 系统能够检索到最符合用户查询意图的高质量信息,仍然是该领域需要持续研究和改进的关键问题。
- 另一个重要的挑战涉及到上下文的理解与管理 32。RAG 模型不仅需要检索到与用户查询相关的信息,还需要能够有效地将这些检索到的信息整合到最终的文本生成过程中,以确保输出的连贯性和流畅性。然而,在实践中,如何才能实现这种无缝的整合仍然是一个复杂的问题。如果上下文管理不当,RAG 模型可能会难以将检索到的段落与自身生成的文本自然地融合,导致输出出现不连贯或脱节的情况 51。此外,大型语言模型 (LLM) 本身在处理文本长度上存在上下文窗口的限制。当检索到大量的相关文档时,如果直接将所有信息都提供给 LLM,可能会超出其处理能力,导致重要信息的截断或丢失,最终影响生成答案的质量 32。更进一步地,RAG 系统有时可能难以捕捉到用户查询中更细微、更深层次的上下文含义,而仅仅关注于表面的关键词匹配,这也会导致检索和生成的结果无法完全满足用户的需求 33。
- RAG 系统在处理复杂或非结构化数据时也可能遇到显著的挑战 32。例如,从包含嵌入式表格、图表等复杂元素的 PDF 文档中准确地提取数据,通常需要非常精细和复杂的解析逻辑,因为这些文档的布局和格式往往不尽相同 32。此外,处理完全非结构化的数据,例如自由流动的文本或者自然语言形式的对话记录,也可能给 RAG 系统带来困难 32。更重要的是,并非所有潜在的外部数据源都能够轻易地被 RAG 系统访问,或者其访问成本对于一些小型组织来说可能过高,这在一定程度上限制了 RAG 技术的应用范围 52。因此,如何提升 RAG 系统处理各种复杂格式文档和非结构化数据的能力,以及如何降低数据获取的门槛,是未来需要重点关注和解决的问题。
- 数据质量与偏差问题是 RAG 系统面临的另一个重要挑战 18。RAG 系统的性能高度依赖于其所连接的外部知识库中数据的质量。如果知识库中存储的信息本身就不准确、已经过时,或者带有某种潜在的偏见,那么 RAG 系统最终生成的输出也很可能会受到这些问题的影响,从而产生误导用户或者不公正的答案 18。因此,仅仅依靠 RAG 技术来增强 LLM 的知识是不够的,更重要的是要确保外部知识库中数据的可靠性和公正性。建立一套完善的数据质量控制和管理机制,定期审查和更新知识库中的信息,并且努力识别和消除潜在的偏差,是保证 RAG 系统能够提供高质量、可信赖答案的关键环节。
- 系统性能与延迟是 RAG 系统在实际应用中需要考虑的重要因素 22。与直接使用独立的 LLM 相比,RAG 系统在生成答案之前需要先进行信息检索的步骤,这无疑会增加系统的整体处理时间,导致更高的延迟 34。尤其是在处理大规模的知识库或者需要实时响应的应用场景下,例如在线客服聊天机器人,用户对于响应速度的要求往往很高。如果 RAG 系统的检索过程过于耗时,或者生成答案的速度较慢,那么就会严重影响用户的使用体验 22。此外,构建和运行 RAG 系统通常需要大量的计算资源,尤其是在处理大规模知识库和复杂查询时,这也会对系统的性能和可扩展性提出更高的要求 19。因此,在设计和部署 RAG 系统时,需要在保证答案准确性的前提下,努力优化系统的性能,降低响应延迟,以提供更好的用户体验。
- 知识库的维护与更新是 RAG 系统持续有效运行的关键 1。外部知识库中的信息并非一成不变,它可能会随着时间的推移而变得过时或不准确。为了确保 RAG 系统能够检索到最新和最相关的信息,需要建立一套完善的机制来定期地维护和更新知识库的内容 1。这可能涉及到自动化的更新流程,例如定期从原始数据源同步信息,或者人工的审查和编辑过程,以确保知识库中的信息始终保持高质量和高时效性。缺乏有效的知识库维护和更新机制会导致 RAG 系统检索到过时的或不准确的信息,从而严重影响其性能和用户体验。
- 评估 RAG 系统的有效性是一个复杂且持续性的挑战 22。与传统的自然语言处理任务不同,RAG 系统的性能受到多个因素的影响,包括检索的准确性、检索到的信息与用户查询的相关性、LLM 如何有效地利用检索到的信息生成答案,以及最终答案的流畅性和准确性等等。传统的评估指标可能无法全面地捕捉到这些细微差别,因此,需要开发专门的评估方法和指标来更准确地衡量 RAG 系统的性能 22。这可能涉及到人工的评估、基于 LLM 的自动评估,以及利用用户反馈等多种方式。此外,由于 RAG 系统的性能在很大程度上取决于其所连接的知识库的质量,因此,对知识库本身的质量进行评估也是至关重要的。建立一套完善的评估体系,能够对 RAG 系统的各个方面进行有效的衡量,是持续改进和优化 RAG 系统性能的关键步骤。
-
RAG 的不同架构与高级技术
- 基本 RAG 架构是最直接和最简单的实现方式 23。在这种架构中,当用户提出查询时,语言模型会直接从一个预先存在的静态数据库中检索出相关的文档,然后仅仅基于这些检索到的信息来生成最终的输出 23。这种基本架构通常适用于那些拥有小型且相对固定的数据库的场景,例如常见的问答系统或者知识范围比较有限的客户支持机器人 23。
- 为了处理更复杂的交互场景,例如需要保持对话上下文的连续对话,或者需要跨越多个查询的任务,一种更高级的架构是在基本 RAG 的基础上引入记忆功能 23。在这种架构中,系统会增加一个存储组件,用于记录和保留先前交互的信息。这样,模型在处理新的查询时,不仅可以检索外部知识,还可以回顾之前的对话历史,从而更好地理解用户的意图,并生成更具上下文相关性的回复 23。实现这种记忆功能的一种常见方法是使用提示缓存技术 23。
- 为了提高检索的覆盖率和召回率,一种名为多查询 RAG (Multi-Query RAG) 的技术被提出 14。该技术的核心思想是将用户最初提出的查询重写成多个不同的、但语义上相关的查询,然后分别使用这些查询去检索信息。通过这种方式,可以从更广泛的角度探索知识库,从而有可能检索到更多与用户需求相关的文档,即使这些文档与原始查询的字面匹配度不高 14。
- RAG 融合 (RAG Fusion) 是另一种用于改进检索效果的查询重写方法 64。它不仅像多查询 RAG 那样生成多个查询,还包含了对检索到的文档进行排序的步骤。具体来说,系统会首先使用初始查询检索到一个初步的文档集合,然后利用多个重写后的查询对这些文档进行重新评估和排序。通过这种方式,RAG 融合能够更有效地识别出那些真正与用户需求最相关的文档,从而提高提供给 LLM 的上下文质量 64。
- 对于一些复杂的输入问题,用户可能希望系统能够将其分解为几个更小的、更易于处理的子问题。查询分解 (Query Decomposition) 技术正是为了满足这种需求而设计的 64。该技术的核心思想是将一个复杂的查询拆分成多个语义上独立的子查询,然后分别针对每个子查询进行信息检索。通过单独解决这些子问题,检索过程可以更加有针对性,从而更有效地收集到回答原始复杂问题所需的全部信息 64。
- 查询翻译 (Query Translation) 涉及到将用户提出的查询转换成更适合进行信息检索的形式或语言 64。例如,一种被称为“逐步回溯提示” (Stepback Prompting) 的技术,会先询问与原始查询相关的更抽象或更一般的问题,目的是生成更广泛的响应,这些响应可以为后续更精确的文档检索提供更好的基础 64。LangChain 工程师的系列教程中就深入探讨了查询翻译的各种技巧和方法 64。
- 自适应 RAG (Adaptive RAG) 是一种更为动态的 RAG 实现方式 23。与基本 RAG 模型无论查询的复杂性如何都遵循单一的检索路径不同,自适应 RAG 能够根据用户查询的实际情况,实时地调整其检索策略 23。例如,对于简单的查询,系统可能只需要查询一个特定的数据源;而对于复杂的查询,系统可能会选择访问多个数据源,或者采用更高级的检索技术。这种灵活性使得自适应 RAG 能够更有效地处理各种不同类型的查询,从而提高整体的检索性能。
- 纠正性 RAG (Corrective RAG) 在传统的 RAG 流程中加入了对检索到的文档进行自我反思或自我评分的机制 23。与传统的 RAG 模型不同,纠正性 RAG 在将检索到的信息用于生成答案之前,会对这些信息的质量进行关键性的评估 23。具体来说,系统会将检索到的文档分解成更小的“知识条”,并对每个知识条与原始查询的相关性进行评分。如果初始检索的结果未能达到预设的相关性阈值,CRAG 还会启动额外的检索步骤,例如执行网络搜索,以确保最终用于生成答案的信息是尽可能最准确和最相关的 23。
- 自检索 RAG (Self-Retrieval RAG) 引入了一种模型自主进行检索的机制 23。与传统的 RAG 模型中检索过程完全依赖于用户的初始输入不同,自检索 RAG 允许模型在生成内容的过程中,根据自身的需要自主地生成新的检索查询 23。这意味着,模型可以迭代地优化其检索查询,以便在生成最终答案的过程中,能够发现和利用更多相关的外部数据。这种机制赋予了模型更强的探索能力,尤其是在处理需要深入研究或逐步细化的复杂问题时,能够显著提高答案的质量和全面性。
- 代理 RAG (Agentic RAG) 代表了 RAG 技术的一个更高级的阶段,它在检索和生成过程中引入了更自主的、类似代理的行为 23。在这种架构中,模型不再仅仅是被动地响应用户的查询,而是像一个智能代理一样,能够主动执行复杂的、多步骤的任务,例如主动与多个不同的数据源或 API 接口进行交互,以便更全面地收集所需的信息 23。这种系统具备更复杂的决策能力,能够根据用户查询的复杂程度,自主地决定应该采用哪种检索策略,或者应该与哪些外部系统进行交互。代理 RAG 特别适用于需要自动化研究、聚合来自多个来源的数据,或者为高层决策提供支持等场景,在这些场景中,模型需要具备高度的自主性,能够整合来自各种系统的信息,并生成综合性的响应 23。
-
RAG 在实际应用中的案例
- 检索增强生成 (RAG) 技术在智能客服与聊天机器人领域展现出巨大的应用潜力 1。通过 RAG,企业可以构建出能够为客户查询提供更个性化和准确响应的高级聊天机器人或虚拟助手,从而显著加快响应速度,提高运营效率,并最终提升客户满意度 1。例如,DoorDash、LinkedIn 和 Bell 等知名公司已经成功地采用了 RAG 技术,以增强其客户支持和内部知识管理流程 39。RAG 技术使得聊天机器人能够实时访问最新的产品详细信息或客户特定的信息,从而为用户提供更有效、更精准的帮助 68。
- RAG 技术在内容创作与辅助写作领域也展现出强大的潜力 2。企业可以利用 RAG 从各种来源检索相关信息,从而更高效地生成高质量的博客文章、文章、产品描述等内容,显著简化内容创作的过程 2。RAG 模型不仅能够检索信息,还能根据特定的提示或主题生成连贯的文本,极大地提高了内容创作的效率和质量 30。此外,RAG 技术还能增强文本摘要的能力,确保生成的摘要既准确又具有高度的上下文相关性 81。
- 企业知识管理与内部问答系统是 RAG 技术另一个重要的应用领域 4。许多组织正在利用 RAG 来革新其内部知识管理流程,通过简化员工从海量数据中查找所需信息的过程,从而提高工作效率 4。员工可以使用 RAG 驱动的系统快速找到关于内部政策、程序或过往项目信息的答案 40。例如,加拿大皇家银行 (RBC) 构建了一个名为 Arcane 的 RAG 系统,旨在帮助银行专家快速找到散布在其内部网络平台上的最相关的政策文件 39。
- RAG 技术在教育与研究领域也展现出巨大的潜力 5。通过提供关于各种主题的最新信息,RAG 模型可以增强学习工具和研究资源,从而简化学生和研究人员的知识发现过程 5。例如,哈佛商学院就创建了一个名为 ChatLTV 的基于 RAG 的 AI 教师聊天机器人,用于辅助其创业课程 39。RAG 模型甚至可以根据不同的学习风格个性化教育内容,并使复杂的科学概念更容易被大众理解 68。
- 在法律与金融领域,RAG 技术同样具有广阔的应用前景 5。通过检索相关的法律信息,RAG 模型可以帮助法律专业人士更高效、更准确地起草法律文件、分析案例和制定辩论策略,从而简化法律研究的过程 5。在金融领域,RAG 可以通过动态整合最新的金融法规、行业洞察和市场分析,来解决金融咨询中可能出现的知识截止和“幻觉”问题 69。
- 医疗健康领域是 RAG 技术另一个极具潜力的应用方向 5。在这个对信息准确性要求极高的领域,RAG 通过检索和整合来自外部来源的相关医学知识,可以在医疗保健应用中提供更准确、更具有上下文意识的响应 5。例如,可以利用 RAG 技术构建能够从医学文献中检索信息并生成精确答案的系统,从而为医生和患者提供及时的医疗信息支持 30。
- RAG 技术还可以应用于代码生成与辅助开发领域 5。在这种应用场景下,检索模型可以检索到相关的代码片段,而生成模型则可以根据具体的项目需求对这些代码片段进行调整和扩展 5。RAG 技术甚至可以从现有的代码仓库中获取相关信息,并利用这些信息来开发出更准确的代码和文档,甚至能够帮助开发者修复代码中存在的错误 69。
-
基于 LangChain 的 RAG 实现
- LangChain 作为一个开源的框架和开发者工具包,旨在帮助开发者能够更便捷地将大型语言模型 (LLM) 应用从最初的原型阶段推向最终的生产环境 10。在检索增强生成 (RAG) 技术的实现过程中,LangChain 扮演着至关重要的角色,它提供了一整套全面且直观的工具和框架,使得开发者能够轻松地将企业或用户的私有数据与 LLM 的强大功能连接起来 42。LangChain 框架内置了数据摄取和检索的方法,这使得开发者能够利用公司或用户的特定数据来增强 LLM 的知识 42。为了方便开发者构建各种 RAG 应用,LangChain 提供了极其丰富的组件库,包括超过 150 种不同的文档加载器 (Document Loaders),60 多种向量存储 (Vector Stores),50 多种嵌入模型 (Embedding Models),以及 40 多种检索器 (Retrievers) 42。此外,LangChain 还提供了一种名为 LangChain 表达式语言 (LCEL) 的声明式方式,用于创建 LangChain 链,这极大地简化了 RAG 流程的构建过程,使得开发者可以更加专注于业务逻辑的实现 14。总而言之,LangChain 作为一个功能强大的框架,极大地简化了 RAG 应用程序的开发过程,为开发者提供了构建功能完善的 RAG 系统所需的各种模块化组件,涵盖了从数据加载、分割、嵌入、存储到检索和生成的各个环节。
- 在使用 LangChain 框架构建 RAG 应用程序时,有几个关键的模块是开发者需要重点关注和使用的 14。首先是 文档加载器 (Document Loaders),它们负责从各种不同的数据来源加载数据,例如常见的 WebBaseLoader 用于加载网页内容,PDFLoader 用于加载 PDF 文件等等 12。接下来是 文本分割器 (Text Splitters),当加载的文档过大时,需要使用文本分割器将其分割成更小的文本块,以便更好地进行后续处理,例如 RecursiveCharacterTextSplitter 就是一个常用的递归字符文本分割器 9。然后是 嵌入模型 (Embeddings),它们用于将文本块和用户的查询语句转换成向量表示,以便进行语义相似性搜索,例如 OpenAIEmbeddings 可以使用 OpenAI 的模型生成文本嵌入向量 13。向量存储 (Vector Stores) 则用于存储和索引这些嵌入向量,常见的向量存储包括 Chroma、FAISS、Pinecone 等 1。检索器 (Retrievers) 负责根据用户的查询,从向量存储中检索出相关的文档或文本块,例如 VectorStoreRetriever 和 MultiQueryRetriever 等 10。语言模型 (Language Models) / 聊天模型 (Chat Models) 则是最终生成答案的关键,例如可以使用 ChatOpenAI 来与 OpenAI 的聊天模型进行交互 10。为了指导 LLM 生成期望的输出,开发者需要使用 提示 (Prompts) 来构建发送给 LLM 的指令,这些指令通常会包含用户的查询以及检索到的相关上下文信息 7。最后,输出解析器 (Output Parsers) 可以用于对 LLM 生成的输出进行结构化或从中提取特定的信息,例如 StrOutputParser 可以将 LLM 的输出解析为字符串 14。此外,LangChain 还提供了一种名为 LangChain 表达式语言 (LCEL) 的工具,它允许开发者以一种声明式的方式将这些不同的组件组合和链接起来,构建成一个可运行的 RAG 流程 25。通过灵活地选择和组合这些模块,开发者可以快速地搭建出满足特定需求的 RAG 应用程序。
- LangChain 工程师 Lance Martin 的 RAG 教程系列全面地讨论了检索增强生成 (RAG) 技术的重要性 66。他详细解释了 RAG 在将私有数据与大型语言模型 (LLM) 集成时所发挥的关键作用,并对 RAG 的核心过程进行了概述,包括数据的索引 (indexing)、信息的检索 (retrieval) 以及最终答案的生成 (generation) 66。该教程系列不仅涵盖了 RAG 的基本概念和工作流程,还深入探讨了诸如查询翻译 (query translation)、路由 (routing) 等高级技术,并强调了上下文 (context) 在 LLM 中的重要性 66。通过这个教程系列,学习者可以深入了解 RAG 的关键步骤,包括如何从外部文档中索引数据、如何检索相关信息以及如何基于检索到的信息生成答案 65。此外,Martin 还演示了多种用于改进检索效果和增强 RAG 工作流程的技术,例如查询重写 (query rewriting)、查询分解 (query decomposition) 以及如何利用先前的问答对来优化检索过程 65。该视频教程还探讨了一些更高级的方法,例如用于语义相似性搜索的 Co-BEAR 方法、用于控制 RAG 工作流程的状态机实现,以及如何集成查询分析以实现长上下文模型中的高效路由和以文档为中心的索引 65。教程的早期部分介绍了 RAG 的基本概念,并通过一个最小化的实现案例进行了演示,帮助初学者快速入门 13。随后,教程的第二部分进一步扩展了这个基本的实现,以适应更复杂的场景,例如对话式的交互以及涉及多个步骤的检索过程 13。此外,教程中还涉及了逐步回溯提示 (step back prompting) 等查询翻译技术,以进一步提升检索的准确性和相关性 64。总而言之,Lance Martin 的 RAG 教程系列全面地介绍了 RAG 的基础知识和高级技巧,并结合了在 LangChain 框架下的实际代码示例,为开发者提供了一个从零开始学习和实现 RAG 技术的实用指南。
-
结论与展望
- 检索增强生成 (RAG) 技术作为一种强大的工具,为解决大型语言模型 (LLM) 在知识时效性、事实准确性以及特定领域知识整合方面面临的挑战提供了有效的解决方案。其主要优势包括能够显著提升 LLM 的知识更新速度,通过引用外部知识来源减少“幻觉”现象,提高答案的准确性和与用户查询的相关性,降低模型微调的成本,增强用户对 AI 系统输出的信任感,为开发者提供更强的控制能力,以及极大地扩展了 LLM 的应用场景。然而,RAG 技术在实际应用中也面临着一些重要的挑战,例如如何保证检索到的信息的质量,如何有效地管理和利用检索到的上下文信息,如何处理复杂或非结构化的数据,如何解决知识库中可能存在的数据质量和偏差问题,如何优化系统的性能和降低延迟,以及如何持续地维护和更新知识库,并最终如何有效地评估 RAG 系统的整体性能。
- 展望未来,检索增强生成 (RAG) 技术在自然语言处理领域将继续蓬勃发展并不断创新。随着研究的深入,我们可以期待更先进、更智能的检索技术出现,例如能够更好地理解用户查询意图的多模态检索,以及能够更有效地处理长上下文和复杂数据结构的检索方法。在上下文管理方面,未来的 RAG 系统可能会采用更智能的策略,例如动态地选择和组合检索到的信息,以最大化其对生成过程的贡献。对于多模态数据的支持也将得到进一步加强,使得 RAG 系统能够处理包括图像、音频和视频在内的更广泛类型的信息。此外,随着对 RAG 系统评估方法的研究不断深入,我们将能够更全面地衡量其性能,并进行更有针对性的优化。在应用潜力方面,RAG 技术有望在各个领域发挥越来越重要的作用,例如构建更智能的个人助手,提供更个性化的推荐系统,以及开发更强大的企业知识管理工具等等。总而言之,RAG 技术作为连接 LLM 和外部知识的关键桥梁,其未来的发展前景十分广阔,将在人工智能领域持续释放其巨大的潜力。
| 组件名称 (Component Name) | 描述 (Description) | 关键功能 (Key Functions) |
| 大型语言模型 (LLM) | RAG 系统的核心,负责生成最终文本响应。 | 理解用户查询,结合检索到的上下文生成连贯的文本。 |
| 外部知识库 | RAG 系统检索信息的来源,包含各种格式的数据。 | 存储与应用场景相关的、权威的和最新的信息。 |
| 文档加载与处理 | 从不同来源加载文档并转换为 LLM 可理解的文本格式。 | 提取文本内容,去除格式信息,清理数据。 |
| 文本分割 | 将加载的文档分割成更小的文本块(chunks)。 | 提高检索效率,适应 LLM 的上下文窗口限制,保持语义完整性。 |
| 嵌入模型 | 将文本块和用户查询转换为高维向量空间中的数值表示。 | 捕捉文本的语义信息,用于语义相似性搜索。 |
| 向量存储 | 存储和索引文本块的嵌入向量,以便高效地进行相似性搜索。 | 快速找到与给定查询向量最相似的文本块向量。 |
| 检索器 | 根据用户查询从向量存储中检索相关的文本块。 | 基于相似性搜索或其他策略,返回最相关的文本块。 |
| 提示工程 | 设计和优化发送给 LLM 的提示,以指导其生成期望的答案。 | 指导 LLM 有效利用检索到的外部知识,生成准确相关的答案。 |
| 生成模型 | 通常是 LLM 本身,接收包含用户查询和检索到的上下文的提示,并生成最终的答案。 | 利用语言理解和生成能力,结合检索到的信息,生成自然流畅的文本答案。 |
总体框架图
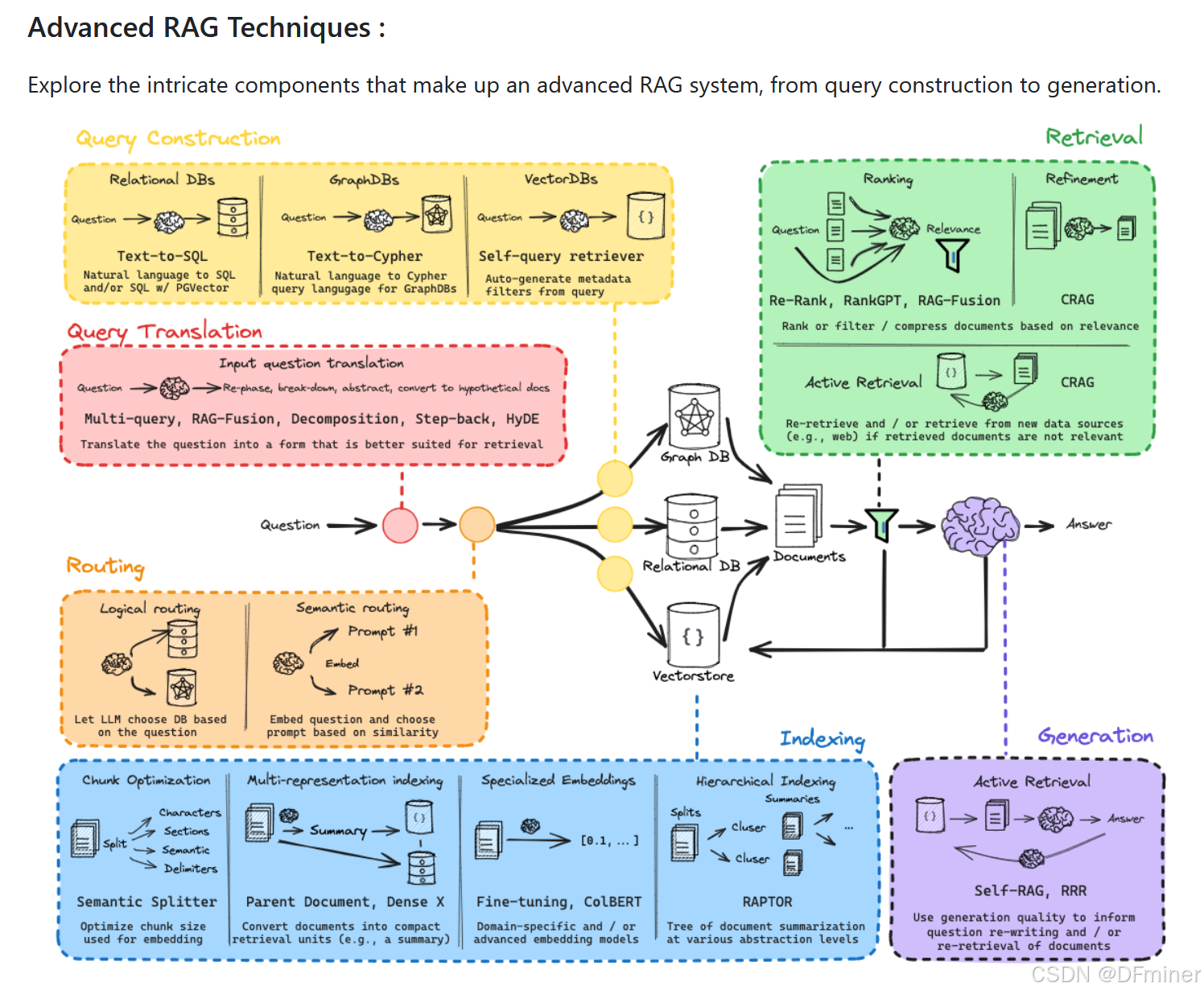
摘要:
这份文档详细介绍了检索增强生成 (RAG) 流程中的各个关键模块,包括查询转换 (Query Translation)、路由 (Routing)、查询构建 (Query Construction)、索引 (Indexing)、检索 (Retrieval) 和生成 (Generation)。
查询转换 (Query Translation) 模块负责将用户原始问题改写、分解、抽象或转换为假设文档,以便更有效地从知识库中检索信息。文中列举了 Multi-query、RAG-Fusion、Decomposition、Step-back 和 HyDE 等具体技术。
路由 (Routing) 模块则根据用户查询的逻辑或语义,将查询导向到最合适的知识库或处理流程,包括基于 LLM 分析的逻辑路由和基于问题与预定义提示词语义相似性的语义路由。
查询构建 (Query Construction) 模块的任务是将转换后的自然语言问题转化为目标数据源(关系型数据库、图数据库、向量数据库)能够理解和执行的查询语句,例如 Text-to-SQL、Text-to-Cypher 和 Self-query retriever。
索引 (Indexing) 模块关注如何高效地组织和存储从原始数据中提取的信息,以提升检索效率。讨论了分块优化 (Chunk Optimization)、多重表示索引 (Multi-representation Indexing)、专用嵌入 (Specialized Embeddings) 和分层索引 (Hierarchical Indexing) 等策略。
检索 (Retrieval) 模块的任务是根据用户查询从索引中找到最相关的信息片段。介绍了排序 (Ranking) 技术如 Re-Rank、RankGPT 和 RAG-Fusion,以及精炼 (Refinement) 和主动检索 (Active Retrieval) 的概念,特别是 CRAG 框架。
生成 (Generation) 模块利用检索到的信息和用户问题生成最终答案,并探讨了在生成过程中进行主动检索 (Active Retrieval) 的策略,如 Self-RAG 和 RRR,以提高答案质量。
提示词:详细介绍一下xx模块,尤其是涉及到的关键词是什么意思。还有涉及到的技术的讲解,怎么实现的,可以举例子,不用写代码。
查询转换 (Query Translation)”模块

这个模块在检索增强生成 (RAG) 流程中扮演着至关重要的角色,其核心目标是将用户提出的原始问题转换成一种更适合从知识库中检索相关信息的形式。
模块概述
这个模块的输入是用户提出的原始“Question”。经过“Input question translation”这个过程(图中用一个大脑的图标表示,象征着智能处理),原始问题会被“Re-phase, break-down, abstract, convert to hypothetical docs”。最终,原始问题会被“Translate the question into a form that is better suited for retrieval”。
下方列举了几种实现查询转换的技术:Multi-query, RAG-Fusion, Decomposition, Step-back, HyDE。
关键词和技术详解
让我们逐个解释一下这些关键词和相关的技术:
-
Re-phrase (改述):
- 意思:用不同的词语或句式重新表达原始问题,但保持其核心含义不变。
- 实现:可以利用语言模型自身的生成能力,给定原始问题,让模型生成多个语义上相似但表达方式不同的问题。
- 例子:
- 原始问题:“最新款的iPhone有哪些颜色?”
- 改述后的问题可以包括:“iPhone最新型号的配色方案是什么?”,“新款iPhone都提供哪些颜色选择?”,“最近发布的iPhone的颜色有哪些?”
-
Break-down (分解/拆解):
- 意思:将一个复杂的多方面问题拆分成几个更简单、更集中的子问题。
- 实现:通常需要模型理解原始问题的结构和包含的不同信息需求,然后将其分解为独立的、可以单独检索的子问题。
- 例子:
- 原始问题:“介绍一下RAG的工作原理和它的主要优点。”
- 分解后的子问题可以是:“RAG是如何工作的?”,“RAG的主要优势有哪些?”
-
Abstract (抽象):
- 意思:将原始问题中的具体细节或实体进行泛化或抽象,以便检索更广泛的相关信息。
- 实现:模型需要识别问题中的关键实体,并将其替换为更通用的概念。
- 例子:
- 原始问题:“比较一下iPhone 15 Pro和三星Galaxy S23 Ultra的相机性能。”
- 抽象后的问题可以是:“比较一下高端智能手机的相机性能。” 这样可以检索到更广泛的关于高端手机相机技术的讨论和评测,而不仅仅局限于具体的型号。
-
Convert to hypothetical docs (转换为假设文档),通常与 HyDE (Hypothetical Document Embeddings) 技术相关:
- 意思:不是直接使用原始问题进行检索,而是先让语言模型基于原始问题生成一个或多个假设性的“文档”或“答案”,然后使用这些假设文档的嵌入向量进行检索。
- 实现:模型接收到问题后,会尝试想象一个可能包含答案的文档会是什么样的,并生成这个假设文档的文本。然后,将这个假设文档通过嵌入模型转换成向量,并用这个向量去知识库中寻找相似的真实文档。
- 例子:
- 原始问题:“什么是光合作用?”
- 模型生成的假设文档可能包含:“光合作用是一种生物化学过程,通常发生在植物、藻类和一些细菌中。它利用光能将二氧化碳和水转化为葡萄糖(一种糖)和氧气。这个过程对于地球上的生命至关重要,因为它是许多食物链的基础,并且释放氧气到大气中。”
- 然后,使用这个假设文档的嵌入向量去知识库中检索包含关于光合作用解释的真实文档。HyDE 的思想是,模型生成的假设答案可能在语义空间上更接近真实答案所在的文档,即使它们在字面上不完全匹配。
-
Multi-query (多查询):
- 意思:针对同一个原始问题,生成多个不同的、但语义上相关的查询,然后使用这些查询并行地从知识库中检索信息,最后将检索到的结果合并。
- 实现:可以结合使用“Re-phrase”、“Break-down”等策略来生成不同的查询。
- 例子:
- 原始问题:“介绍一下北京的著名景点和美食。”
- 生成多个查询:“北京有哪些值得参观的景点?”,“北京有什么特色美食?”,“去北京旅游应该去哪些地方?”,“北京的当地小吃有哪些?”
-
RAG-Fusion (RAG 融合):
- 意思:这是一种更复杂的查询重写和结果融合策略。它不仅生成多个不同的查询,还可能对检索到的文档进行评分和排序,以更有效地找到最相关的上下文。
- 实现:可能涉及使用多个不同的检索器或不同的查询策略检索文档,然后使用某种机制(例如交叉注意力或重新排序模型)来融合这些检索结果,突出显示最关键的信息。
-
Decomposition (分解):
- 意思:与上面提到的 “Break-down” 类似,但在这里更强调将一个复杂的问题分解成一系列顺序的子问题,可能需要逐步解决这些子问题才能得到最终答案。
- 实现:模型需要理解问题之间的依赖关系,并规划出解决问题的步骤,为每个步骤生成相应的查询。
- 例子:
- 原始问题:“如果我想在北京买一套三居室的房子,需要考虑哪些因素?房价大概是多少?”
- 分解后的子问题可能是:“北京有哪些主要的住宅区域?”,“在这些区域购买三居室需要考虑哪些因素?”,“目前北京三居室的平均房价是多少?”,“不同区域的三居室房价差异如何?”
-
Step-back (逐步回溯):
- 意思:首先提出一个与原始问题相关的更抽象或更一般性的“回溯”问题,检索到更广泛的背景信息,然后再用原始问题进行更具体的检索。
- 实现:模型需要识别原始问题所处的更广泛的知识领域,并生成一个更上层的相关问题。
- 例子:
- 原始问题:“牛顿第一定律是什么?”
- 回溯问题:“关于物体运动的基本规律有哪些?” 先检索到关于运动基本定律的更广泛的解释,然后再用原始问题检索牛顿第一定律的具体内容。
总结
查询转换模块的目标是通过智能地处理用户的原始问题,使其更适合用于信息检索。不同的转换技术侧重于不同的方面,例如改变问题的表达方式、分解复杂问题、抽象问题以扩大搜索范围,或者甚至先生成假设答案再进行搜索。这些技术可以单独使用,也可以组合使用,以提高 RAG 系统检索到相关且高质量信息的能力,从而最终提升生成答案的质量。
核心概念:Routing(路由)
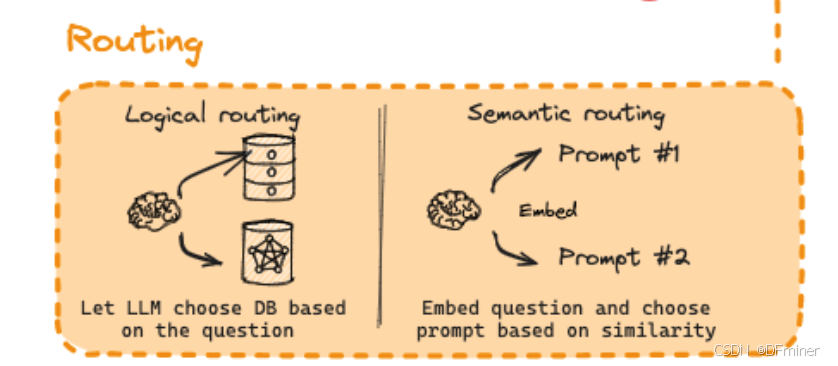
正如其字面意思,Routing 在这个语境下指的是将用户的查询或处理后的信息导向到最合适的资源或处理流程的过程。它的目标是确保后续的步骤能够高效且准确地获取所需的信息,从而提升整个生成过程的质量。
Routing 的两种主要类型(根据图片):
图片中展示了两种主要的 Routing 方式:Logical Routing(逻辑路由) 和 Semantic Routing(语义路由)。
1. Logical Routing(逻辑路由)
关键词解析:
- LLM (Large Language Model, 大型语言模型): 这是指像我这样的强大的 AI 模型,经过海量文本数据的训练,具备理解和生成自然语言的能力。在 Logical Routing 中,LLM 扮演着决策者的角色。
- DB (Database, 数据库): 数据库是存储和管理数据的结构化集合。图片中展示了两个不同的数据库,它们可能包含不同类型或来源的信息。
- Choose DB based on the question (基于问题选择数据库): 这是 Logical Routing 的核心思想。LLM 会分析用户的查询,理解其意图和涉及的领域,然后判断哪个或哪些数据库最有可能包含回答该问题所需的信息,并将查询导向到这些选定的数据库。
技术讲解与实现方式:
Logical Routing 的实现通常依赖于 LLM 的文本理解和分类能力。具体来说,可以采用以下方式:
- 查询理解 (Query Understanding): LLM 首先需要深入理解用户提出的问题,识别出问题中的关键实体、概念、意图和主题。
- 知识库索引 (Knowledge Base Indexing): 不同的数据库或知识库需要被适当地索引和描述,以便 LLM 能够了解它们所包含的信息类型和范围。例如,一个数据库可能专注于产品信息,另一个可能包含客户服务记录。
- 分类或决策模型 (Classification or Decision Model): 基于对查询的理解和对知识库的索引,LLM 内部或外部的分类模型会判断哪个知识库与查询的相关性最高。这可以基于规则、机器学习分类器或者直接利用 LLM 的上下文学习能力。
- 路由执行 (Route Execution): 一旦确定了目标数据库,用户的查询(或其转换后的形式)就会被发送到该数据库进行信息检索。
举例说明:
假设用户提出了以下问题:
- 问题 1: “索尼 WH-1000XM5 耳机的价格是多少?”
- 问题 2: “我昨天购买的电视遇到了问题,应该联系谁?”
对于 问题 1,LLM 分析后可能会判断这个问题涉及到产品信息和价格。因此,Logical Routing 可能会将这个查询导向到存储产品目录和价格信息的数据库。
对于 问题 2,LLM 可能会识别出这个问题与售后服务和联系方式相关。因此,Logical Routing 可能会将这个查询导向到存储客户服务联系信息和常见问题解答的数据库。
在以上两个例子中,LLM 并没有直接去所有的数据库中搜索,而是根据问题的性质“逻辑地”选择了最相关的数据库,从而提高了效率和准确性。
2. Semantic Routing(语义路由)
关键词解析:
- Embed (嵌入): 嵌入是一种将文本(例如问题或提示词)转换为低维、稠密的向量表示的技术。这些向量能够捕捉到文本的语义信息,即文本的含义和上下文。语义上相似的文本在向量空间中会更加接近。
- Prompt #1, Prompt #2: 这里指的是预先定义好的不同的提示词或指令。这些提示词可能针对不同的任务、领域或者期望的生成风格。
- Embed question and choose prompt based on similarity (嵌入问题并基于相似性选择提示词): 这是 Semantic Routing 的核心思想。首先,用户的问题会被嵌入成一个向量。然后,每一个预定义的提示词也会被嵌入成向量。通过计算问题向量和各个提示词向量之间的相似度(例如,使用余弦相似度),选择与问题在语义上最相似的提示词,并将其用于后续的生成过程。
技术讲解与实现方式:
Semantic Routing 的实现依赖于文本嵌入模型和相似度计算方法:
- 文本嵌入模型 (Text Embedding Model): 这些模型(例如,Word2Vec、GloVe、Sentence-BERT、OpenAI Embeddings 等)经过训练,能够将文本转换为捕捉其语义信息的向量。不同的模型在性能和适用场景上有所不同。
- 提示词库 (Prompt Library): 需要预先构建一个包含多个不同提示词的库,每个提示词都代表着一种特定的处理方式或目标。
- 嵌入生成 (Embedding Generation): 当用户提出问题时,以及在系统初始化时,问题和库中的所有提示词都会被文本嵌入模型转换为向量。
- 相似度计算 (Similarity Calculation): 使用某种距离或相似度度量方法(如余弦相似度)计算问题向量与每个提示词向量之间的相似度得分。
- 提示词选择 (Prompt Selection): 选择与问题向量相似度最高的提示词。这个最相似的提示词被认为最能指导 LLM 生成符合用户意图的回答。
举例说明:
假设我们有以下几个预定义的提示词:
- Prompt #1 (摘要提示): “请用简洁的语言总结一下这段文本的主要内容。”
- Prompt #2 (详细解释提示): “请详细解释一下这个概念,并提供相关的例子。”
- Prompt #3 (情感分析提示): “分析这段文本的情感是积极的、消极的还是中性的。”
现在,用户提出了以下问题:
- 问题 A: “这篇文章主要讲了什么?”
- 问题 B: “什么是量子力学?”
- 问题 C: “用户对这款产品的评价如何?”
当系统接收到 问题 A 时,它会被嵌入成一个向量。这个向量很可能会与 Prompt #1 (摘要提示) 的向量在语义空间中更接近,因为两者都涉及到文本的主要内容。因此,系统会选择 Prompt #1 来指导 LLM 处理后续的文本。
对于 问题 B,其嵌入向量会更接近 Prompt #2 (详细解释提示) 的向量,因为两者都涉及到概念的解释。
对于 问题 C,其嵌入向量会更接近 Prompt #3 (情感分析提示) 的向量,因为两者都涉及到情感的判断。
通过这种方式,Semantic Routing 能够根据问题的语义含义,动态地选择最合适的处理方式(通过选择最相关的提示词),从而更灵活地应对用户的不同需求。
总结:
Routing 模块在整个信息检索和生成流程中扮演着至关重要的角色。Logical Routing 侧重于基于对问题的逻辑理解来选择合适的数据源,而 Semantic Routing 则侧重于基于问题的语义相似性来选择合适的处理方式或指令。这两种方法可以单独使用,也可以结合使用,以实现更智能和高效的信息处理。
希望这个详细的解释能够帮助你更好地理解 Routing 模块及其相关的关键概念和技术。如果你还有其他问题,欢迎随时提出!
为了更好地理解 Semantic Routing,我们再来一个更具体的例子,并探讨一下它适用的场景。
更具体的例子:智能客服场景
假设我们正在构建一个智能客服系统,这个系统需要能够回答用户关于产品、订单、售后等各种问题。为了更好地处理不同类型的问题,我们预先定义了几个不同的“处理流程”或者说“意图模板”,每个模板都对应一个特定的提示词(Prompt)。
我们的提示词库可能包含以下内容(简化版):
- Prompt #1 (产品咨询): “请根据以下信息,详细介绍一下 {产品名称} 的特点、优势和使用方法。”
- Prompt #2 (订单查询): “请查询订单号为 {订单号} 的订单状态和物流信息。”
- Prompt #3 (售后服务咨询): “用户遇到了关于 {产品名称} 的 {问题描述},请提供解决方案或联系售后部门。”
- Prompt #4 (通用问候): “请用礼貌友好的方式回复用户的问候。”
现在,假设用户提出了以下几个问题:
- 用户问题 A: “你们的最新款智能手表有哪些新功能?”
- 用户问题 B: “我的订单 20250508-12345 的包裹现在到哪里了?”
- 用户问题 C: “我买的咖啡机坏了,怎么办?”
- 用户问题 D: “你好!”
Semantic Routing 的处理过程:
-
嵌入问题: 用户的每一个问题都会被一个预先训练好的文本嵌入模型转换成一个向量。例如:
- “你们的最新款智能手表有哪些新功能?” -> 向量 VA
- “我的订单 20250508-12345 的包裹现在到哪里了?” -> 向量 VB
- “我买的咖啡机坏了,怎么办?” -> 向量 VC
- “你好!” -> 向量 VD
-
嵌入提示词: 我们预先将提示词库中的每一个提示词也转换成向量:
- “请根据以下信息,详细介绍一下 {产品名称} 的特点、优势和使用方法。” -> 向量 P1
- “请查询订单号为 {订单号} 的订单状态和物流信息。” -> 向量 P2
- “用户遇到了关于 {产品名称} 的 {问题描述},请提供解决方案或联系售后部门。” -> 向量 P3
- “请用礼貌友好的方式回复用户的问候。” -> 向量 P4
-
计算相似度: 系统会计算用户问题向量和每一个提示词向量之间的相似度。例如,使用余弦相似度:
- 计算 VA 和 P1, P2, P3, P4 的相似度。
- 计算 VB 和 P1, P2, P3, P4 的相似度。
- 计算 VC 和 P1, P2, P3, P4 的相似度。
- 计算 VD 和 P1, P2, P3, P4 的相似度。
-
选择最相关的提示词: 对于每一个用户问题,系统会选择与其向量最相似的提示词向量所对应的提示词。例如,很可能出现以下结果:
- VA 与 P1 的相似度最高(因为都与产品信息相关)。
- VB 与 P2 的相似度最高(因为都与订单查询相关)。
- VC 与 P3 的相似度最高(因为都与售后服务和问题描述相关)。
- VD 与 P4 的相似度最高(因为都是简单的问候)。
-
应用选定的提示词: 选定最相关的提示词后,系统会将其作为指导 LLM 生成回复的指令。当然,用户问题中提取的关键信息(例如,产品名称、订单号、问题描述)会被填充到提示词的占位符中。
- 对于问题 A,LLM 会根据 P1 的指示,结合产品知识库,生成关于最新款智能手表功能的介绍。
- 对于问题 B,LLM 会根据 P2 的指示,查询订单系统并回复订单状态和物流信息。
- 对于问题 C,LLM 会根据 P3 的指示,尝试提供解决方案或引导用户联系售后部门。
- 对于问题 D,LLM 会根据 P4 的指示,回复一个友好的问候。
Semantic Routing 的适用场景:
在以下场景中,使用 Semantic Routing 通常会比较合适:
-
需要根据用户意图选择不同的处理流程或策略的场景: 就像上面的智能客服例子,不同的用户问题需要不同的处理方式(查询订单、产品介绍、售后服务等)。Semantic Routing 可以根据问题的语义自动识别用户意图,并选择相应的处理流程。
-
存在多个预定义的任务或目标,但用户的表达方式多种多样的场景: 即使用户的表达方式不同,但如果其潜在的意图是相似的,Semantic Routing 可以通过捕捉语义上的相似性,将它们映射到同一个预定义的任务或目标上。例如,“我想知道XX手机的性能怎么样?”和“XX手机好用吗?”虽然表达不同,但都指向了解产品的性能,Semantic Routing 可以将它们都路由到“产品性能介绍”相关的提示词。
-
希望提高系统的灵活性和鲁棒性,使其能够处理更自然、更开放式的用户输入: 相比于依赖精确的关键词匹配或复杂的规则,Semantic Routing 能够理解更深层次的语义,从而更好地处理用户的自然语言输入,即使这些输入没有严格遵循预设的格式。
-
需要根据用户输入动态调整生成内容的风格、详细程度或侧重点的场景: 通过选择不同的提示词,我们可以引导 LLM 生成不同风格或侧重点的内容。例如,一个提示词可能要求简洁的回答,另一个可能要求详细的解释。
-
当难以通过明确的逻辑规则或关键词匹配来准确判断用户意图时: 有些用户问题可能比较模糊或复杂,难以用简单的规则进行分类。Semantic Routing 通过语义相似性计算,能够更好地捕捉这些隐含的意图。
总结来说,Semantic Routing 的核心优势在于其能够理解用户输入的深层含义,并基于这种理解动态地选择最合适的处理方式。它在需要灵活应对用户多样化输入和根据意图选择不同处理流程的场景中非常有用。
Query Construction(查询构建)
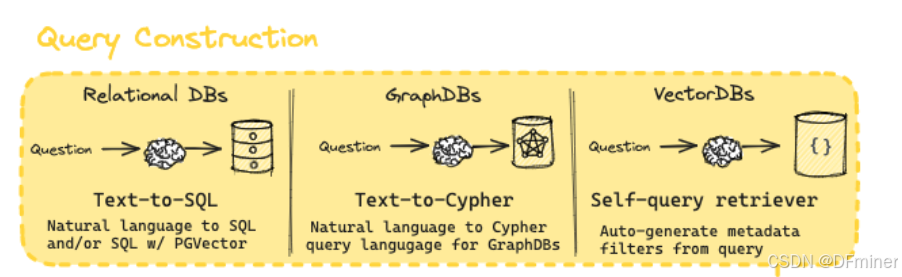
在 Routing 模块确定了要查询的资源(例如,特定的数据库)之后,Query Construction 模块的任务就是将用户的自然语言问题转换成目标数据源能够理解和执行的查询语句。
图片中展示了针对不同类型数据库的 Query Construction 方法:
1. Relational Databases(关系型数据库)
关键词解析:
- Relational DBs (关系型数据库): 这类数据库以表格的形式存储数据,表格之间通过关系(例如,主键和外键)相互关联。常见的关系型数据库包括 MySQL、PostgreSQL、SQL Server 等。
- Question (问题): 这是指用户输入的自然语言查询。
- Text-to-SQL: 这是一种将自然语言文本转换为 SQL(Structured Query Language,结构化查询语言)的技术。SQL 是用于管理和查询关系型数据库的标准语言。
- Natural language to SQL and/or SQL w/ PGVector: 这说明 Text-to-SQL 的目标是将自然语言问题转换为标准的 SQL 查询语句。
w/ PGVector指的是在 PostgreSQL 数据库中,可能还会结合使用PGVector扩展来处理向量嵌入,以便进行基于语义的相似性搜索,但这仍然是在 SQL 的框架下进行的。
技术讲解与实现方式:
Text-to-SQL 的实现是一个复杂但重要的任务,常见的方法包括:
-
基于规则的方法: 这种方法依赖于预先定义好的语法规则和模式,将自然语言中的关键词和结构映射到 SQL 的语法元素。这种方法对于结构简单、领域明确的查询可能有效,但难以处理复杂的或超出规则范围的自然语言表达。
-
基于机器学习的方法:
- 序列到序列模型 (Sequence-to-Sequence Models): 这类模型(例如,使用 Transformer 架构)将自然语言问题作为输入序列,并生成 SQL 查询作为输出序列。模型需要在大规模的自然语言-SQL 对的数据集上进行训练。
- 语法增强的方法: 这些方法在生成 SQL 的过程中会考虑 SQL 的语法规则,以确保生成的查询是合法的。
- 基于中间表示的方法: 一些方法会先将自然语言问题转换成一个中间的语义表示(例如,逻辑形式),然后再将这个中间表示转换成 SQL。
-
结合知识图谱的方法: 利用知识图谱中实体和关系的信息,帮助理解自然语言问题中的指代和语义关系,从而更准确地生成 SQL 查询。
举例说明:
假设我们有一个名为 Customers 的关系型数据库表,包含 CustomerID, Name, City, OrderCount 等列。用户提出了以下问题:
- 问题: “住在东京并且订单数量超过 5 的客户的名字是什么?”
一个 Text-to-SQL 模型可能会将这个自然语言问题转换为以下的 SQL 查询语句:
SQL
SELECT Name
FROM Customers
WHERE City = 'Tokyo' AND OrderCount > 5;
在这个过程中,Text-to-SQL 模型需要理解 “住在东京” 对应于 WHERE City = 'Tokyo',“订单数量超过 5” 对应于 AND OrderCount > 5,“客户的名字” 对应于 SELECT Name 以及它们之间的逻辑关系。
2. Graph Databases(图数据库)
关键词解析:
- GraphDBs (图数据库): 这类数据库使用图结构(节点和边)来存储数据,节点代表实体,边代表实体之间的关系。常见的图数据库包括 Neo4j、Amazon Neptune 等。
- Text-to-Cypher: 这是一种将自然语言文本转换为 Cypher 查询语言的技术。Cypher 是 Neo4j 图数据库的查询语言,用于在图结构中查找和操作数据。对于其他图数据库,可能存在类似的 Text-to-Graph Query Language 的技术。
- Natural language to Cypher query language for GraphDBs: 这明确了 Text-to-Cypher 的目标是将自然语言问题转换为图数据库特定的查询语言(这里是 Cypher)。
技术讲解与实现方式:
Text-to-Cypher 的实现与 Text-to-SQL 类似,但也面临一些图数据库特有的挑战,例如理解自然语言中隐含的图结构和关系。常见的方法包括:
- 基于模式匹配的方法: 识别自然语言问题中的实体和关系,并将其映射到图数据库的模式(节点标签和关系类型)。
- 基于语义解析的方法: 将自然语言问题解析成一个语义图,然后将这个语义图映射到图数据库的查询结构。
- 基于机器学习的方法: 训练模型将自然语言问题直接翻译成 Cypher 查询。这通常需要标注了自然语言问题和对应 Cypher 查询的数据集。
举例说明:
假设我们有一个图数据库,其中包含代表“人”的节点和代表“居住在”关系的边。用户提出了以下问题:
- 问题: “住在东京的人叫什么名字?”
一个 Text-to-Cypher 模型可能会将这个自然语言问题转换为以下的 Cypher 查询语句(假设“人”节点的标签是 Person,表示名字的属性是 name,“居住在”关系的类型是 LIVES_IN,“城市”节点的标签是 City,表示城市名字的属性是 name):
Cypher
MATCH (p:Person)-[:LIVES_IN]->(c:City)
WHERE c.name = 'Tokyo'
RETURN p.name;
在这个过程中,Text-to-Cypher 模型需要理解 “住在” 对应于 LIVES_IN 关系,“东京” 对应于 City 节点且 name 属性为 'Tokyo',“人” 对应于 Person 节点,“名字” 对应于 p.name。
3. Vector Databases(向量数据库)
关键词解析:
- VectorDBs (向量数据库): 这类数据库专门用于存储和高效检索向量嵌入。向量嵌入是通过机器学习模型将文本、图像、音频等数据转换成的低维稠密向量,能够捕捉数据的语义信息。常见的向量数据库包括 Pinecone、Faiss、Milvus 等。
- Self-query retriever: 这是一种针对向量数据库的查询构建方法。与前两种方法不同,它不是将自然语言直接翻译成特定的查询语言,而是从自然语言问题中自动生成用于过滤向量数据库元数据的条件,然后结合问题的向量嵌入进行相似性搜索。
- Auto-generate metadata filters from query: 这是 Self-query retriever 的核心思想。向量数据库通常会为存储的向量关联一些元数据(例如,文档的来源、创建时间、作者等)。Self-query retriever 会分析用户的自然语言问题,识别出与这些元数据相关的约束条件,并将其转换为过滤条件。
技术讲解与实现方式:
Self-query retriever 的实现通常涉及以下步骤:
- 元数据定义: 需要明确向量数据库中存储的向量都关联了哪些元数据字段以及它们的含义。
- 问题分析: LLM 或专门的自然语言处理模型分析用户的自然语言问题,识别出可能与元数据相关的关键词或短语。
- 过滤器生成: 基于识别出的关键词和元数据定义,自动生成用于过滤向量数据库的条件表达式。
- 向量嵌入: 同时,用户的自然语言问题也会被转换为向量嵌入。
- 相似性搜索与过滤: 使用问题的向量嵌入在向量数据库中进行相似性搜索,并结合生成的元数据过滤器,只返回满足过滤条件的相似向量。
举例说明:
假设我们有一个向量数据库,存储了大量文档的向量嵌入,每个文档都关联了以下元数据:source(文档来源,例如“公司官网”、“产品手册”)和 category(文档类别,例如“技术规格”、“用户指南”、“FAQ”)。用户提出了以下问题:
- 问题: “公司官网上关于最新产品技术规格的文档有哪些?”
一个 Self-query retriever 可能会进行以下操作:
- 分析问题: 分析问题,识别出 “公司官网” 可能对应于元数据字段
source的值为 “公司官网”,“技术规格” 可能对应于元数据字段category的值为 “技术规格”,“最新产品” 虽然没有直接对应元数据,但可以用于生成问题的向量嵌入。 - 生成过滤器: 生成元数据过滤器:
source = '公司官网' AND category = '技术规格'。 - 嵌入问题: 将问题 “公司官网上关于最新产品技术规格的文档有哪些?” 转换为一个向量嵌入。
- 搜索与过滤: 在向量数据库中搜索与该问题嵌入最相似的向量,并且只返回那些
source为 “公司官网” 且category为 “技术规格” 的文档对应的向量。
总结:
Query Construction 模块是 RAG 流程中连接用户的自然语言问题和后端数据源的关键桥梁。针对不同类型的数据库,需要采用不同的技术将自然语言转换为相应的查询语言或过滤条件。Text-to-SQL 和 Text-to-Cypher 致力于生成目标数据库可以直接执行的查询语句,而 Self-query retriever 则专注于为向量数据库生成元数据过滤器,以便在进行语义搜索时缩小范围,提高检索的准确性。理解这些不同的方法及其背后的原理,对于构建高效和准确的 RAG 系统至关重要。
Query Construction(查询构建)中的三种数据库分别一般用在哪些应用场景?在什么场景下使用什么Query Construction(查询构建)比较合适?
好的,我们来分别看一下关系型数据库、图数据库和向量数据库通常的应用场景,以及在什么情况下选择对应的 Query Construction 方法会比较合适。
1. Relational Databases (关系型数据库)
常见应用场景:
- 事务处理和数据管理: 适用于需要高度一致性和事务性操作的场景,例如:
- 金融系统: 银行账户、交易记录等。
- 电商平台: 订单管理、库存管理、用户信息等。
- 客户关系管理 (CRM): 客户信息、销售活动、服务记录等。
- 企业资源规划 (ERP): 财务、人力资源、供应链管理等。
- 结构化数据存储和查询: 适用于数据结构清晰、关系明确的场景,例如:
- 报表和分析: 基于结构化数据生成各种报表和进行数据分析。
- 传统 Web 应用: 存储和检索用户信息、产品信息等。
何时使用 Text-to-SQL:
- 用户需要基于结构化数据进行灵活查询,但又不熟悉 SQL 语言: Text-to-SQL 可以让用户用自然语言提问,系统将其转换为 SQL 查询,从而降低了用户的使用门槛。例如,在一个电商平台的分析系统中,业务人员可以用自然语言查询“上个月北京地区销量最好的前十名商品是什么”。
- 存在清晰定义的关系型数据库 Schema (表结构和关系): Text-to-SQL 的效果很大程度上依赖于数据库 Schema 的清晰度和质量。如果 Schema 设计良好,模型更容易理解自然语言中的指代并映射到相应的表、列和关系。
- 查询逻辑相对复杂,涉及多个表之间的连接和聚合操作: 对于需要组合多个条件、进行排序、分组和聚合的查询,Text-to-SQL 可以生成相应的复杂 SQL 语句。
2. Graph Databases (图数据库)
常见应用场景:
- 知识图谱: 存储和查询实体之间的复杂关系,例如:
- 语义搜索: 理解用户查询的深层含义,基于实体和关系进行搜索。
- 智能推荐: 基于用户兴趣、商品属性和用户之间的关联进行推荐。
- 问答系统: 从知识图谱中提取事实并回答用户问题。
- 社交网络分析: 分析用户之间的连接、社区发现、影响力传播等。
- 欺诈检测: 识别异常的连接模式和行为。
- 供应链管理: 跟踪产品和供应商之间的关系。
- 生物信息学: 分析基因、蛋白质和其他生物实体之间的相互作用。
何时使用 Text-to-Cypher (或其他图查询语言):
- 用户需要查询数据之间的复杂关系和路径: 当问题的核心在于实体之间的连接方式、距离或模式时,图数据库和相应的查询语言非常适合。Text-to-Cypher 可以将自然语言中对关系的描述转换为图查询语句,例如,“找到与我朋友的朋友都居住在上海的人”。
- 数据以高度关联的方式组织,且关系本身包含重要信息: 在图数据库中,关系通常带有属性,Text-to-Cypher 需要能够理解自然语言中对这些关系属性的约束。
- 需要进行图遍历和模式匹配: Cypher 等图查询语言擅长执行复杂的图遍历操作,例如查找特定模式的子图。Text-to-Cypher 需要能够将自然语言中对模式的描述转换为相应的图查询结构。
3. Vector Databases (向量数据库)
常见应用场景:
- 语义搜索和文档检索: 基于文本的语义相似性进行搜索,超越关键词匹配。例如,搜索“如何治疗感冒”可以找到包含“缓解流感症状”的文档。
- 推荐系统: 基于用户的行为和物品的向量表示,找到相似的物品进行推荐。
- 文本相似性比较: 比较两段文本的语义相似度。
- 图像、音频、视频等非结构化数据的相似性搜索: 将这些数据编码成向量后进行相似性检索。
- 问答系统中的段落检索: 找到与用户问题语义最相关的文档段落作为上下文。
何时使用 Self-query retriever:
- 向量数据库中的文档或数据条目包含丰富的元数据信息,并且用户查询中可能包含对这些元数据的过滤条件: Self-query retriever 能够从自然语言问题中提取出与元数据相关的约束,并在进行语义搜索的同时应用这些过滤条件,从而提高检索的精确度。例如,用户查询“2023年关于人工智能在医疗领域应用的综述文章有哪些?” 既包含语义搜索的需求(“人工智能在医疗领域应用”),也包含对年份(元数据)的过滤。
- 需要在语义相似性搜索的基础上进行精确的元数据匹配: 仅仅依靠语义相似性可能返回一些不符合特定元数据要求的文档。Self-query retriever 结合了语义搜索和元数据过滤,可以更准确地找到用户需要的信息。
- 用户可能在查询中同时表达了语义上的需求和属性上的限制: Self-query retriever 可以同时处理这两种类型的信息,先通过语义理解生成查询向量,再通过分析问题提取元数据过滤条件。
总结:
选择哪种 Query Construction 方法以及使用哪种类型的数据库,应该基于数据的特性、查询的需求以及用户的交互方式来决定:
- 如果数据是高度结构化的,关系清晰,且用户可能需要复杂的逻辑查询,那么关系型数据库和 Text-to-SQL 是一个不错的选择。
- 如果数据主要由实体和它们之间的复杂关系构成,并且查询的重点在于这些连接和模式,那么图数据库和 Text-to-Cypher (或其他图查询语言) 更为合适。
- 如果数据是非结构化的,并且查询的重点在于语义上的相似性,同时可能需要基于元数据进行过滤,那么向量数据库和 Self-query retriever 能够提供强大的能力。
在实际应用中,也可能出现多种数据库和查询方法结合使用的情况,以满足更复杂的需求。例如,可以使用关系型数据库存储结构化信息,同时使用向量数据库存储文档的嵌入,并结合 Text-to-SQL 和语义搜索来进行更全面的信息检索。
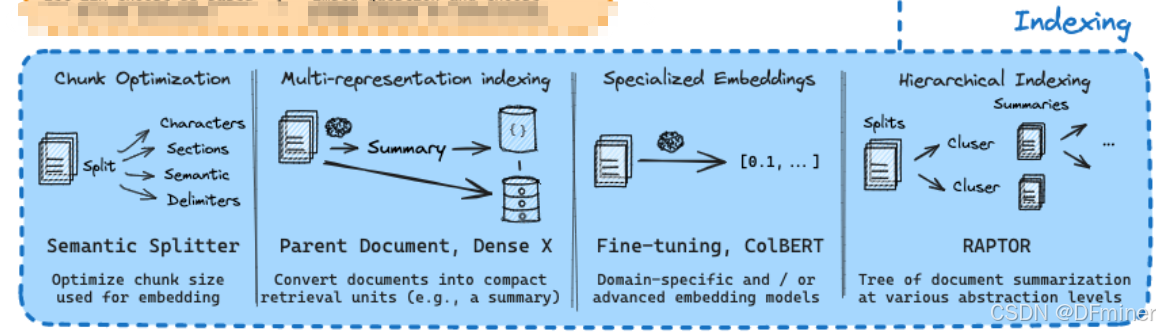
Indexing(索引)
在 Query Construction 模块生成了针对特定数据源的查询之后,Indexing 模块的任务是高效地组织和存储从原始数据中提取的信息,以便能够快速地响应后续的查询。一个好的索引策略能够显著提升检索效率和相关性。
图片中展示了 Indexing 模块中涉及的几种关键技术和策略:
1. Chunk Optimization(分块优化)
关键词解析:
- Chunk (块): 指的是将原始文档分割成的一小段文本。这是进行后续嵌入和索引的基础单元。
- Split (分割): 将原始文档分割成多个块的过程。
- Characters (字符): 最简单的分割方式,按照固定的字符数量进行分割。
- Sections (章节): 按照文档的逻辑结构(例如,标题、子标题)进行分割。
- Semantic Delimiters (语义分隔符): 基于文本的语义含义进行分割,例如,句子、段落或自定义的语义边界。
- Semantic Splitter (语义分割器): 一种能够理解文本语义并据此进行分割的工具或算法。
- Optimize chunk size used for embedding (优化用于嵌入的块大小): 指选择最合适的块大小,以在保留足够上下文信息和控制嵌入维度之间取得平衡,从而提升检索效果。
技术讲解与实现方式:
Chunk Optimization 的目标是找到一个最佳的块大小和分割策略,以便生成的文本嵌入能够最好地捕捉文档的语义信息,并提高后续检索的相关性。不同的分割策略有其优缺点:
- 按字符分割: 简单快速,但可能破坏语义单元,导致上下文信息不完整。
- 按章节分割: 保留了文档的逻辑结构,但章节长度可能差异很大,不利于统一处理。
- 按语义分隔符分割: 能够更好地保留语义完整性,但需要更复杂的分割算法。
实现方式通常包括:
- 选择合适的分割策略: 根据文档的特性和下游任务的需求选择合适的分割方式。
- 确定最佳块大小: 这通常需要实验和评估不同大小的块在嵌入质量和检索效果上的表现。较小的块可能丢失上下文,较大的块可能包含无关信息并增加计算成本。
- 使用专门的分割工具: 例如,LangChain 等框架提供了多种文本分割器,可以根据字符、分隔符、甚至利用语言模型进行语义分割。
举例说明:
假设我们有一篇关于“量子力学”的长篇文章。
- 按字符分割: 如果我们设置块大小为 500 个字符,一个包含完整句子的段落可能会被分割到两个不同的块中,导致每个块的语义不完整。
- 按章节分割: 文章的不同章节(例如,“量子叠加”、“量子纠缠”)会被分割成独立的块,这保留了每个主题的完整性,但章节的长度可能相差很大。
- 按语义分隔符分割: 语义分割器可能会识别出段落之间的空行或者表示主题转换的句子作为分割点,从而生成更符合语义单元的文本块。例如,“量子叠加是指一个量子系统可以同时处于多个状态的线性组合。” 这句话很可能会被完整地保留在一个块中。
2. Multi-representation Indexing(多重表示索引)
关键词解析:
- Parent Document (父文档): 原始的完整文档。
- Dense X: 指的是对父文档或其摘要进行稠密向量嵌入 (Dense Embedding)。这里的 "X" 可以代表不同的嵌入方式或模型。
- Summary (摘要): 原始文档的简短概括。
- Convert documents into compact retrieval units (e.g., a summary) (将文档转换为紧凑的检索单元,例如摘要): 指的是除了对文档的原始块进行嵌入外,还可能对文档的摘要进行嵌入,作为一种更高级别的表示。
技术讲解与实现方式:
Multi-representation Indexing 的核心思想是为同一个文档创建不同粒度和不同类型的表示,并将其存储在索引中。这样可以在检索时根据查询的特点选择最合适的表示进行匹配,从而提高检索的灵活性和效果。
实现方式通常包括:
- 生成文档摘要: 可以使用各种文本摘要技术(例如,抽取式摘要、生成式摘要、基于 Transformer 的模型)从原始文档生成简洁的摘要。
- 对原始块进行嵌入: 按照 Chunk Optimization 策略分割文档并生成每个块的向量嵌入。
- 对父文档或摘要进行嵌入: 使用不同的嵌入模型或策略对整个父文档或其摘要生成一个或多个全局的向量嵌入。例如,可以使用一个擅长捕捉文档整体主题的嵌入模型。
- 存储多重表示: 将原始块的嵌入、父文档或摘要的嵌入以及它们之间的对应关系存储在向量数据库中。
举例说明:
对于一篇关于“全球气候变化的影响”的长报告:
- 我们可能会将报告分割成段落,并为每个段落生成嵌入。
- 同时,我们可能会生成该报告的摘要,例如:“本报告总结了全球气候变化对地球生态系统、人类社会和经济的广泛影响,并提出了可能的应对措施。” 然后,我们也会为这个摘要生成一个全局的嵌入。
当用户查询一个非常宽泛的问题,例如“气候变化的主要影响有哪些?”,系统可能会首先匹配到报告摘要的嵌入,从而快速定位到这份相关的报告。然后,如果用户提出更具体的问题,例如“气候变化如何影响农业生产?”,系统可能会在报告的各个段落的嵌入中进行更细粒度的搜索。
3. Specialized Embeddings(专用嵌入)
关键词解析:
- Fine-tuning (微调): 在预训练的语言模型的基础上,使用特定领域或任务的数据进行额外的训练,使其更擅长处理该领域或任务的文本。
- ColBERT: 一种上下文化后期交互 (Contextualized Late Interaction) 的高效检索模型。与传统的先独立嵌入再计算相似度的方法不同,ColBERT 为文档的每个 token 生成上下文嵌入,并在检索时进行更细粒度的交互和匹配。
- Domain-specific and / or advanced embedding models (领域特定和/或高级嵌入模型): 指的是针对特定领域(例如,医学、法律、金融)训练或微调的嵌入模型,或者采用更先进架构(例如,Transformer 的变体)的嵌入模型,这些模型通常能更好地捕捉领域内的专业知识和细微差别。
- [0.1, ...]: 表示生成的向量嵌入。
技术讲解与实现方式:
Specialized Embeddings 的核心思想是利用更适合特定数据或任务的嵌入模型,以提高检索的质量和相关性。
实现方式通常包括:
- 选择或训练合适的嵌入模型:
- 使用领域特定的预训练模型: 例如,BioBERT(生物医学)、SciBERT(科学)、FinBERT(金融)等。
- 对通用预训练模型进行微调: 使用目标领域的数据对通用模型(例如,BERT、RoBERTa)进行微调,使其更好地理解和表示该领域的文本。
- 使用高级检索模型: 例如,采用 ColBERT 架构的模型,可以在检索时进行更精细的匹配。
- 生成嵌入: 使用选定的专用嵌入模型将文档块转换为向量表示。
- 存储嵌入: 将生成的专用嵌入存储到向量数据库中。
举例说明:
假设我们正在构建一个医学知识库的检索系统。
- 我们可以使用通用的句子嵌入模型(例如,Sentence-BERT)来嵌入医学文献的段落。
- 或者,我们可以选择使用在大量医学文献上预训练的 BioBERT 模型来生成嵌入,这样生成的嵌入可能更能捕捉医学术语和概念之间的细微差别。
- 更进一步,我们可以对 BioBERT 模型在我们特定的医学知识库上进行微调,使其更了解我们数据的特点。
- 此外,我们还可以尝试使用 ColBERT 模型,它在检索时会考虑查询和文档块中每个 token 的上下文嵌入,从而可能更准确地找到相关的段落。
4. Hierarchical Indexing(分层索引)
关键词解析:
- Splits (分割): 原始文档被分割成较小的块。
- Cluster (聚类): 将语义上相似的文档块分组在一起。
- Summaries (摘要): 为每个聚类或更高层次的节点生成摘要。
- RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval): 一种构建文档摘要树的框架,通过递归地对文档块进行聚类和摘要,形成一个多层次的索引结构。
- Tree of document summarization at various abstraction levels (在不同抽象级别的文档摘要树): 指的是通过分层聚类和摘要构建的索引结构,顶层是整个文档的粗略摘要,底层是更细粒度的文档块。
技术讲解与实现方式:
Hierarchical Indexing 的核心思想是通过构建一个多层次的索引结构,实现从粗到细的检索。当用户查询时,可以先在高层级的摘要上进行快速匹配,缩小搜索范围,然后再在低层级的更细粒度的块中进行精确匹配,从而提高检索效率和准确性。
实现方式通常包括:
- 文档分割: 将原始文档分割成较小的块。
- 聚类: 使用聚类算法(例如,k-means、层次聚类)将语义上相似的文档块分组在一起。可以使用块的向量嵌入作为聚类的依据。
- 摘要生成: 为每个聚类生成一个或多个摘要,概括该聚类中包含的主要信息。
- 构建层次结构: 可以递归地对聚类进行聚类和摘要,形成一个树状结构,其中每个节点都包含其子节点的摘要。
- 检索: 在检索时,首先在顶层的摘要上进行匹配。如果匹配到相关的节点,则可以向下探索其子节点,直到找到最相关的文档块。
举例说明:
对于一本关于“人工智能”的教科书:
- 我们首先将其分割成段落。
- 然后,我们将语义上相关的段落聚类在一起,例如,关于“机器学习基础”的段落会形成一个聚类,关于“深度学习”的段落会形成另一个聚类。
- 为每个聚类生成一个摘要,例如,“机器学习基础聚类包含监督学习、无监督学习和强化学习的基本概念和算法。”
- 我们可以继续对这些聚类进行更高层次的聚类和摘要,例如,将“机器学习基础”和“深度学习”聚类合并为“人工智能的核心技术”聚类,并生成相应的摘要。
当用户查询“什么是卷积神经网络?”时,系统可能会先在顶层的摘要中找到“人工智能的核心技术”相关的节点,然后向下探索到“深度学习”聚类,最终在“深度学习”聚类下的具体段落中找到关于卷积神经网络的详细解释。
总结:
Indexing 模块是 RAG 流程中至关重要的一步,它决定了我们如何组织和存储信息,从而影响到后续检索的效率和质量。Chunk Optimization 关注如何将文档分割成最适合嵌入的单元;Multi-representation Indexing 通过存储不同粒度的文档表示来提高检索的灵活性;Specialized Embeddings 利用更先进或领域特定的模型来提升嵌入的语义表达能力;而 Hierarchical Indexing 则通过构建多层次的索引结构来实现高效的从粗到细的检索。选择合适的索引策略和技术取决于数据的特性、查询的类型以及对检索效率和准确性的要求。
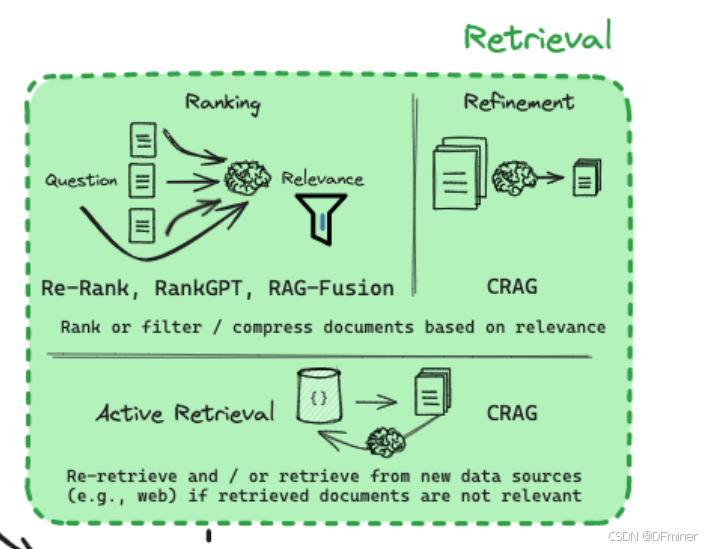
Retrieval(检索)
在 Indexing 模块构建好索引之后,Retrieval 模块的任务就是根据用户的查询,从索引中找到最相关的信息片段(文档块),以便后续的生成模型可以利用这些信息来生成最终的答案。一个好的检索策略能够确保提供给生成模型的信息既相关又充足。
图片中展示了 Retrieval 模块中涉及的几种关键策略和技术:
1. Ranking(排序)
关键词解析:
- Question (问题): 用户输入的自然语言查询。
- Documents (文档): 从索引中检索到的候选文档块。
- Ranking (排序): 根据文档与查询的相关性对检索到的文档进行排序的过程。
- Relevance (相关性): 指文档与用户查询的匹配程度。
- Re-Rank, RankGPT, RAG-Fusion: 这些是用于提升检索结果排序质量的技术或模型。
- Re-Rank (重排序): 指的是在初步检索得到一批文档后,使用更复杂的模型对这些文档进行重新排序,以提高相关性。
- RankGPT: 一种利用生成式语言模型(如 GPT)进行文档排序的方法。它通常会将查询和文档拼接起来,然后让模型预测它们的相关性得分。
- RAG-Fusion: 一种通过生成多个不同的查询,检索多个结果集,然后将这些结果集融合(例如,通过交叉注意力机制)来提高检索质量的方法。
- Rank or filter / compress documents based on relevance (基于相关性对文档进行排序、过滤或压缩): 这是 Ranking 阶段的目标。不仅要排序,还可以根据相关性阈值过滤掉不相关的文档,或者对相关文档进行压缩以减少后续处理的负担。
技术讲解与实现方式:
Ranking 的目标是提高检索结果的质量,确保最相关的文档排在前面。常见的实现方式包括:
-
基于相似度评分的初始检索: 在向量数据库中,通常使用查询的嵌入向量与索引中所有文档块的嵌入向量计算相似度(例如,余弦相似度),并返回相似度最高的 top-k 个文档作为初始检索结果。
-
重排序 (Re-Ranking):
- 使用更复杂的模型: 初始的基于向量相似度的检索可能只考虑了语义相似性,而忽略了更细致的词汇匹配或上下文关系。Re-ranking 阶段可以使用更强大的模型(例如,基于 Transformer 的交叉编码器)来重新评估候选文档与查询的相关性。这些模型通常会将查询和每个文档拼接在一起,然后输出一个相关性得分。
- RankGPT: 可以将查询和每个候选文档作为输入,让 GPT 模型生成一个表示相关性的文本片段或直接预测一个相关性得分。由于 GPT 具有强大的语言理解和生成能力,它可以捕捉到更复杂的语义关系。
-
RAG-Fusion:
- 生成多个查询: 基于原始查询,利用 LLM 生成多个语义上相关但表达方式不同的变体查询。
- 执行多次检索: 使用每个生成的查询分别从索引中检索相关的文档。
- 融合检索结果: 将多个检索结果集进行融合。一种常见的方法是使用交叉注意力机制,让模型学习不同查询检索到的文档之间的关系,并根据综合的相关性对文档进行排序。
-
过滤和压缩:
- 基于阈值过滤: 设定一个相关性得分的阈值,只保留得分高于该阈值的文档。
- 文档压缩: 对于特别长的相关文档,可以利用摘要模型或信息抽取技术进行压缩,提取关键信息,减少后续传递给生成模型的文本长度。
举例说明:
假设用户查询是:“治疗高血压的最新指南是什么?”
-
初始检索: 向量数据库可能会基于查询的嵌入,返回一些包含“高血压”、“治疗”等关键词的医学指南文档片段。
-
Re-Ranking:
- 交叉编码器: 一个重排序模型可能会分析查询和每个返回的文档片段的上下文,判断哪些片段更精确地回答了“最新指南”这个问题,从而将包含最新发布日期或明确提及“最新指南”的文档排在前面。
- RankGPT: RankGPT 可能会阅读查询和每个文档片段,然后生成类似“这份指南明确提到了 2023 年发布的最新治疗建议,因此非常相关”的文本,或者直接给出一个高相关性评分。
-
RAG-Fusion:
- 生成多个查询: LLM 可能会基于原始查询生成:“高血压最新治疗建议”、“高血压管理新进展”、“高血压用药最新指导”等变体查询。
- 执行多次检索: 使用这些变体查询分别检索文档。
- 融合检索结果: 系统可能会发现多个查询都检索到了同一份最新的指南文档,并通过融合机制提高这份文档的最终排名。
2. Refinement(精炼)
关键词解析:
- Documents (文档): 初始检索到的文档块。
- Relevance (相关性): 文档与查询的匹配程度。
- CRAG (Corrective Retrieval augmented Generation): 一种在生成答案的过程中,如果发现检索到的信息不足或不准确,会主动进行修正或补充检索的框架。在 Refinement 阶段,CRAG 可能用于判断检索到的文档是否足够好,如果不够好,可能会触发 Active Retrieval。
- Refinement (精炼): 在检索到初步结果后,对其进行评估和改进的过程。这可能包括重新排序、过滤,或者在更复杂的框架下,判断是否需要进行额外的检索。
技术讲解与实现方式:
Refinement 的目标是确保提供给生成模型的信息是高质量的。这通常涉及到对初步检索结果的评估和可能的改进。
-
相关性评估: 使用模型(可以是简单的相似度评分,也可以是更复杂的判别模型)评估检索到的文档与查询的相关性。
-
冗余信息处理: 如果检索到多个包含重复信息的文档,可以进行去重或只保留最全面的版本。
-
上下文充足性判断: 在 CRAG 等框架下,模型可能会判断检索到的文档是否足以回答用户的问题。如果信息不足,可能会触发 Active Retrieval。
举例说明:
假设用户查询是:“巴黎有哪些著名的博物馆?”
-
初始检索: 系统可能会返回一些包含“巴黎”和“博物馆”的文档片段。
-
Refinement (CRAG 的一部分): 系统可能会分析这些文档,发现它们只列举了少数几个博物馆,并没有覆盖“著名”的范围。CRAG 可能会判断这些信息不足以生成全面的答案,从而触发 Active Retrieval,例如,主动搜索“巴黎著名博物馆列表”等更精确的查询。
3. Active Retrieval(主动检索)
关键词解析:
- {} (空集或低质量结果): 表示初始检索没有返回相关结果或返回的结果质量不高。
- Re-retrieve and / or retrieve from new data sources (e.g., web) if retrieved documents are not relevant (如果检索到的文档不相关,则重新检索和/或从新的数据源(例如,网络)检索): 这是 Active Retrieval 的核心思想。当系统判断当前的检索结果不满意时,会采取主动措施来获取更好的信息。
- CRAG (Corrective Retrieval augmented Generation): 在 Active Retrieval 的上下文中,CRAG 框架会根据生成过程中的需要,动态地决定是否需要重新检索或从新的来源检索信息。
技术讲解与实现方式:
Active Retrieval 的核心是让系统具备判断检索质量的能力,并在必要时采取行动来改进检索结果。
-
检索质量评估: 使用模型判断当前检索到的文档是否能够充分回答用户的问题。这可以基于相关性得分、信息覆盖度、答案的潜在质量等指标。
-
重新查询 (Re-querying): 如果检索结果不佳,系统可以尝试修改原始查询,例如:
- 添加关键词: 基于对初始检索结果的分析,添加更具体的关键词。
- 改变查询的表达方式: 使用同义词或不同的句式重新表达查询。
- 分解复杂查询: 将一个复杂的问题分解成多个更小的子问题进行检索。
-
跨数据源检索: 如果初始检索的数据源没有提供足够的信息,系统可以尝试从其他数据源进行检索,例如:
- Web 搜索: 对于需要最新信息或更广泛知识的问题,可以集成 Web 搜索功能。
- 访问其他内部知识库: 如果组织有多个知识库,可以尝试查询其他相关的知识库。
举例说明:
假设用户查询是:“最新的 iPhone 型号有哪些新功能?”
-
初始检索: 系统可能只检索到一些关于 iPhone 的基本介绍文档,没有详细列出最新型号的新功能。
-
Active Retrieval (CRAG 的一部分): 系统判断这些信息不足以回答问题。
-
重新查询: 系统可能会尝试重新构造查询,例如:“iPhone 15 新功能”、“最新 iPhone 型号特性”。
-
跨数据源检索: 如果内部知识库没有最新信息,系统可能会发起 Web 搜索,查询最新的 iPhone 发布信息和评测文章,并将搜索结果也纳入考虑。
总结:
Retrieval 模块在 RAG 流程中扮演着至关重要的角色,它直接影响着提供给生成模型的信息质量。Ranking 通过对检索结果进行排序和过滤来提高相关性;Refinement 则关注对检索结果的评估和改进;而 Active Retrieval 则使系统具备了根据检索质量动态调整检索策略甚至扩展检索范围的能力。这些策略和技术的结合,旨在确保 RAG 系统能够检索到最准确、最全面的信息,从而生成高质量的答案。
Generation(生成)
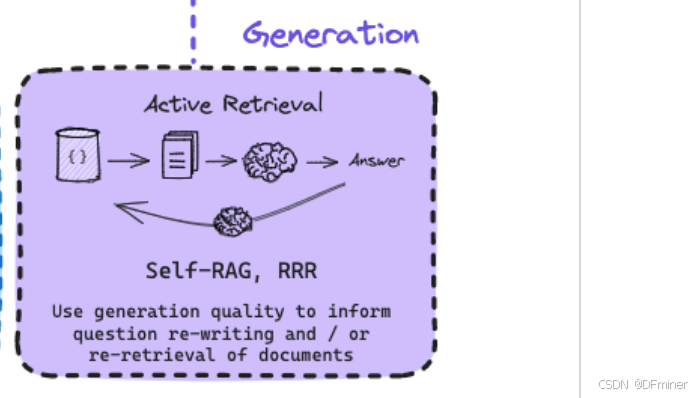
在 Retrieval 模块检索到相关的信息片段之后,Generation 模块的任务就是利用这些检索到的信息和用户的原始问题,生成最终的自然语言答案。一个好的生成策略能够确保答案的准确性、流畅性和相关性。
图片中展示了 Generation 模块中涉及的一种关键策略:
Active Retrieval (in the context of Generation)
关键词解析:
- {} (可能是指质量不高的检索结果): 在 Generation 的语境下,这可能表示 Retrieval 模块提供的信息不足以生成高质量的答案,或者检索到的信息与用户的真实意图存在偏差。
- Documents (文档): Retrieval 模块检索到的相关文档块。
- LLM (Large Language Model, 大型语言模型): 指的是用于生成最终答案的 AI 模型,例如 GPT-3、GPT-4、LLaMA 等。
- Answer (答案): Generation 模块最终生成的自然语言回复。
- Self-RAG (Self-Reflective Retrieval-Augmented Generation): 一种让生成模型能够自我评估生成内容的质量,并在必要时主动进行反思和重新检索的框架。
- RRR (Retrieve-Read-Rerank): 虽然图片中将其放在 Generation 模块,但 RRR 更像是一个完整的 RAG 流程的迭代策略。它强调在检索 (Retrieve) 之后,模型阅读 (Read) 检索到的文档,然后可能基于理解重新评估 (Rerank) 文档的相关性,这可以影响最终的生成。
- Use generation quality to inform question re-writing and / or re-retrieval of documents (使用生成质量来指导问题重写和/或文档的重新检索): 这是 Generation 阶段中 Active Retrieval 的核心思想。生成模型在生成答案的过程中,如果判断当前的信息不足或质量不高,可以主动要求系统进行更精确的检索。
技术讲解与实现方式:
在 Generation 阶段融入 Active Retrieval 的目标是提高生成答案的质量和可靠性。这通常涉及到生成模型与检索模块的反馈循环:
-
初始生成: LLM 基于检索模块提供的文档和用户的问题,开始生成答案。
-
自我评估 (Self-RAG): 在生成过程中或生成结束后,Self-RAG 框架会让 LLM 对其生成的内容进行自我评估,判断答案的质量、是否充分回答了问题、是否与检索到的证据一致等。评估可以基于模型自身的置信度、生成文本的流畅度和连贯性,或者通过专门的评估模块。
-
触发重新检索: 如果 LLM 的自我评估结果表明答案质量不高或信息不足,它可以触发重新检索。这可以基于以下策略:
- 问题重写 (Question Re-writing): LLM 可以根据当前生成过程中的理解或遇到的信息缺失,对原始问题进行细化、扩展或调整,以便进行更精确的检索。
- 指定新的检索需求: LLM 可以明确指出需要检索哪些特定类型的信息或来自哪些来源的信息。
-
重新检索: 经过问题重写或新的检索需求指定后,系统会再次调用 Retrieval 模块,从索引中检索更相关或更全面的信息。
-
基于新信息的重新生成: LLM 接收到重新检索到的信息后,会将其融入到答案生成过程中,生成最终的回复。
RRR (Retrieve-Read-Rerank) 在 Generation 上下文中的理解:
虽然 RRR 通常被视为一个更广义的 RAG 策略,但其“Read”阶段发生在检索之后,并在生成之前对检索到的文档进行更深入的理解。如果模型在“Read”阶段发现检索到的文档不够相关或全面,它可以触发“Rerank”甚至“Re-retrieve”,从而影响最终用于生成答案的信息基础。
举例说明 (Self-RAG):
假设用户查询是:“如何用 Python 编写一个 Web 服务器?”
-
初始检索: 系统检索到了一些关于 Python 网络编程的基本教程和代码示例。
-
初始生成: LLM 基于这些信息开始生成答案,但可能只涵盖了简单的单线程服务器,没有涉及更高级的功能(例如,处理并发请求、框架的使用)。
-
自我评估: Self-RAG 框架让 LLM 评估其生成的答案,模型可能会判断答案不够全面,没有涵盖实际应用中更重要的方面。
-
触发重新检索 (问题重写): LLM 可能会将原始问题重写为更具体的查询,例如:“Python 高性能 Web 服务器框架”、“Python 异步 Web 服务器示例”。
-
重新检索: 系统使用重写后的查询重新检索,可能会找到关于 Flask、Django、asyncio 等框架的更深入的文档。
-
基于新信息的重新生成: LLM 利用这些新的信息,生成一个更全面、更实用的答案,包括使用框架和处理并发的示例。
总结:
在 Generation 模块中融入 Active Retrieval 机制,特别是像 Self-RAG 这样的框架,使得 RAG 系统不再是单向的信息检索和生成流程,而是具备了自我反思和迭代改进的能力。通过让生成模型参与到检索质量的评估和检索策略的调整中,可以显著提高最终生成答案的准确性、完整性和实用性。这代表了 RAG 技术向更智能、更自主的方向发展。