YOLOv1模型架构、损失值、NMS极大值抑制
文章目录
- 前言
- 一、YOLO系列v1
- 1、核心思想
- 2、流程解析
- 二、损失函数
- 1、位置误差
- 2、置信度误差
- 3、类别概率损失
- 三、NMS(非极大值抑制)
- 总结YOLOv1的优缺点
前言
YOLOv1(You Only Look Once: Unified, Real-Time Object Detection)由Joseph Redmon等人在2016年提出,是YOLO系列的第一代模型,首次将目标检测任务转化为单阶段端到端的回归问题,实现了实时检测的突破性进展。
一、YOLO系列v1
1、核心思想
将一副图像分成SxS个网格(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。
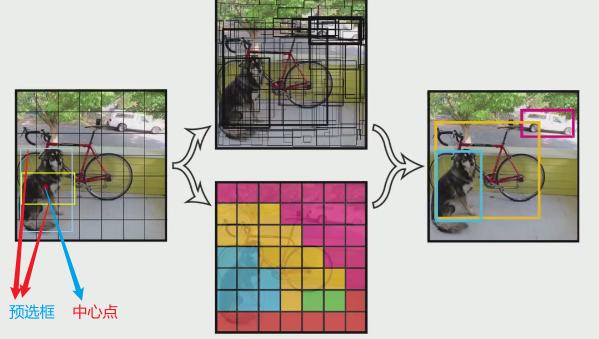
上图把图片划分成7x7的网格,每个网格只用两个预选框,这些边框大小可以超出当前网格的范围,对于每个边框,v1模型分别预测出5个参数:中心坐标(x, y)、宽度w、高度h以及置信度confidence。置信度反映了模型对边框内包含物体的信心程度以及边框的准确度。(置信度(confidence)=类概率*IoU)
2、流程解析
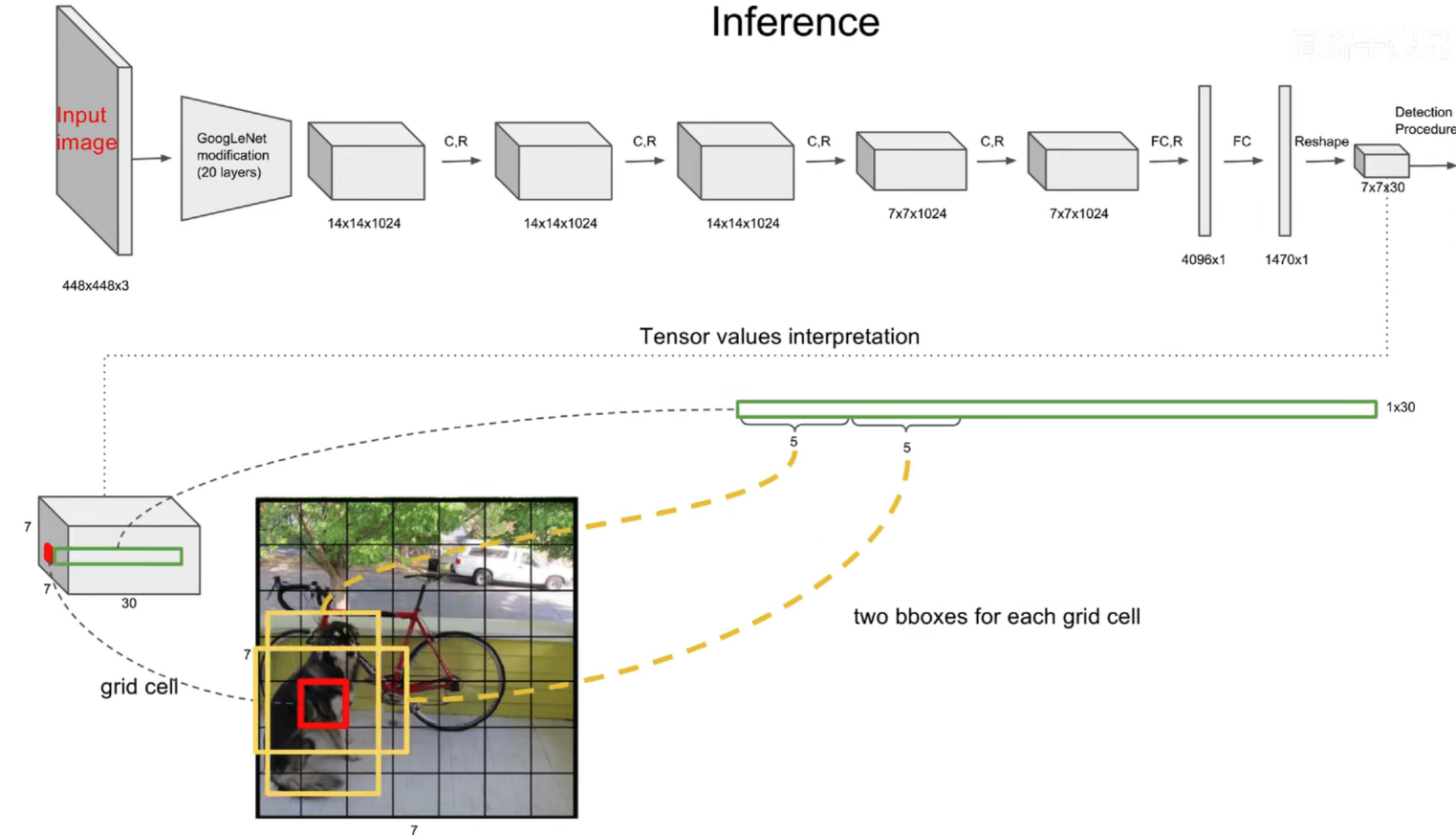

网络架构借鉴了GoogleNet。24个卷积层,2个全连接层
(用1×1 reduction layers 紧跟 3×3 convolutional layers 取代Goolenet的 inception modules )
7×7意味着7×7个grid cell,30表示每个grid cell包含30个信息,其中2个预测框,每个预测框包含5个信息(x y w h c),分别为中心点位置坐标,宽高以及置信度,剩下20个是针对数据集的20个种类的预测概率(即假设该grid cell负责预测物体,那么它是某个类别的概率)。
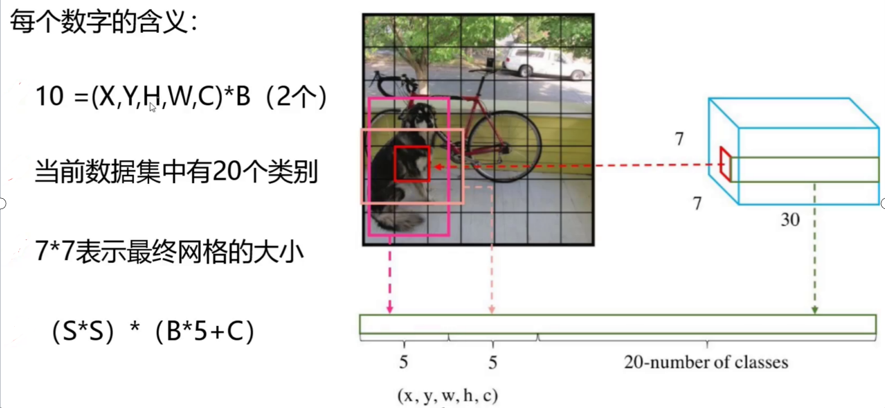
每个grid有30维,这30维中,8维是回归box的坐标,2个B是box的confidence,还有20维是类别。 其中坐标的x,y(相对于网格单元格边界的框的中心)用对应网格的归一化到0-1之间,w,h用图像的width和height归一化到0-1之间。
二、损失函数
YOLO-V1算法最后输出的检测结果为7x7x30的形式,其中30个值分别包括两个候选框的位置和有无包含物体的置信度以及网格中包含20个物体类别的概率。那么YOLO的损失就包括三部分:位置误差,confidence误差,分类误差。
损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification这个三个方面达到很好的平衡。
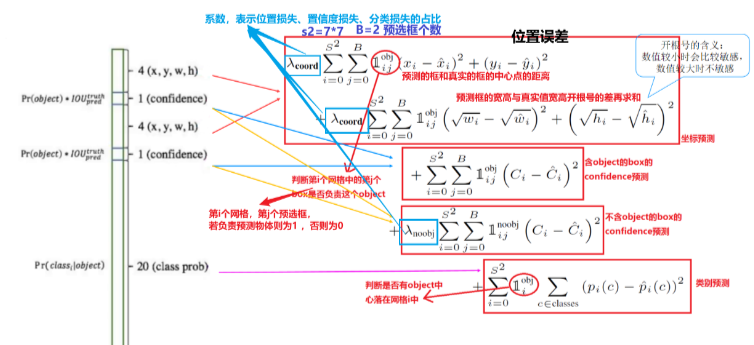
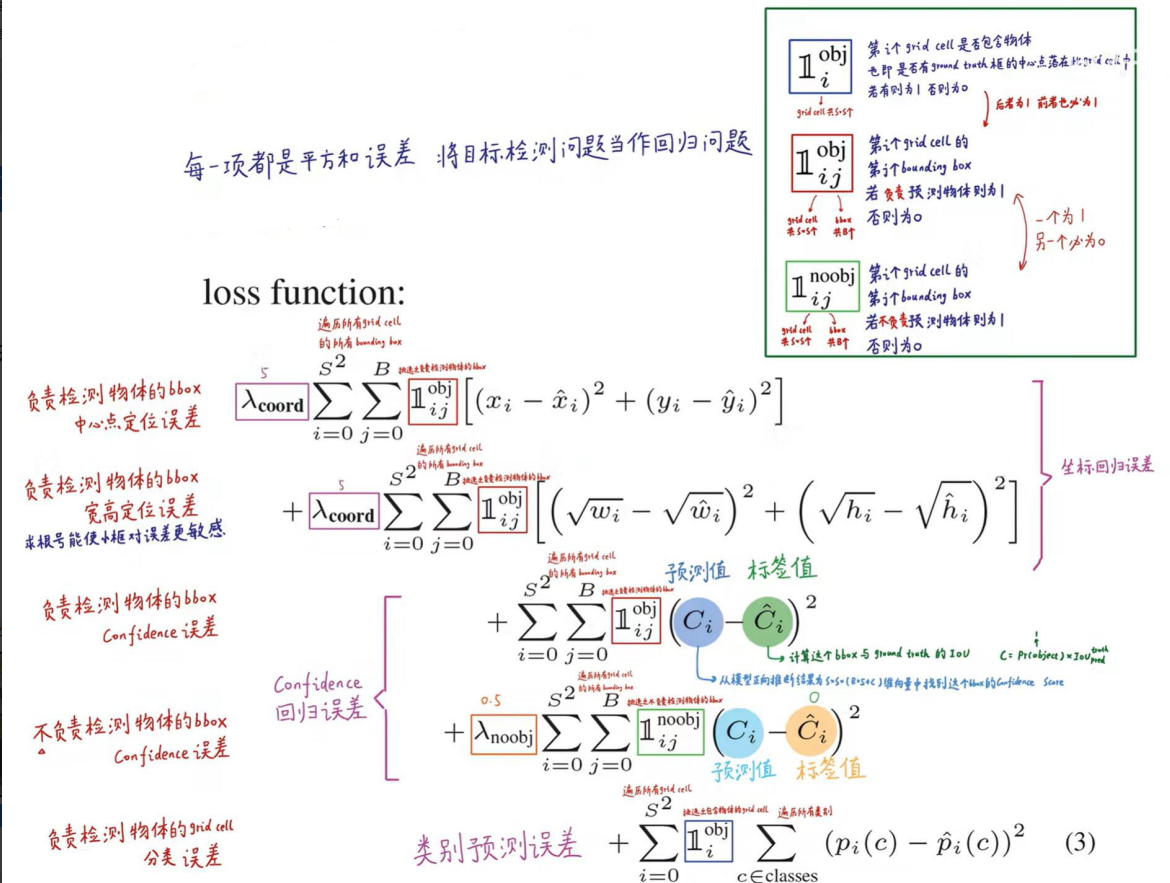
1、位置误差
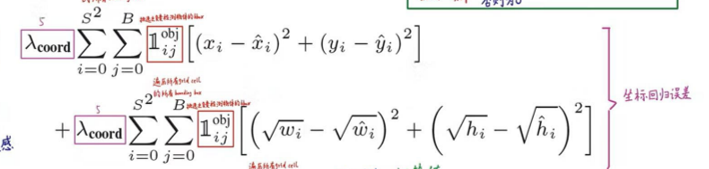
如上图所示,其为位置误差的计算公式,其中对应的值为一个系数,表示如果你觉得位置误差更重要,那么就设置大一点,置信度误差与分类误差也是同样的意思
第二个红框内的符号表示第i个网格的第j个预选框,如果负责预测物体,那么整体的值为1,反之为0
前面的求和符号s平方表示网格的格式,例如YOLO v1中的网格个数为7*7,然后B表示预选框的个数,此处数值为2,后面的x表示预选框的中心点的坐标x,y,以及预选框的宽w、高h。
2、置信度误差

λ的值所表示的意思和上述一致,但是第二个像阿拉伯数字1noobj的符号,其所表示的值和上述位置误差中的相反,此处表示第i个网格,第j个预选框,如果不负责预测物体,那么他的值为1,否则为0,
C的表示置信度的值,置信度C的值 = Pr类别概率 * IOU
类别概率表示边界框(预选框)内存在对象的概率,若存在对象则为1,不存在则为0,IOU为预测的位置框和真实值的框相交集的值除以并集的值的大小。
Ci表示模型预测出来的置信度的值,C^i的值表示实际计算得到的置信度的值
3、类别概率损失

这里第一个求和符号后面的小符号,表示第i个网格是否包含物体,如果包含,那么其值为1,否则为0
pi©-p^i©表示预测的类别的概率减去真实标签的概率,例如模型输出20类别的结果,即有20个数据,其中有预测到狗的概率,加入标签打的是狗,只需要将20个数据中预测狗额概率的值取出来,然后减去1,在对结果平方即可
三、NMS(非极大值抑制)
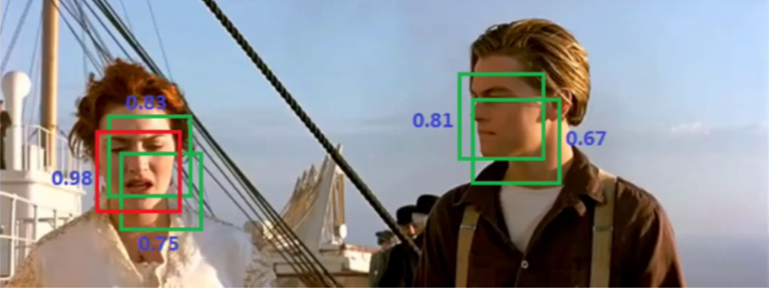
同一个人脸被多个预选框预测出来,导致了预选框的重叠,此时可以将置信度低的抑制了,只保留最大的那个。
对每个类别,按置信度排序,剔除与最高分框IoU超过阈值(如0.5)的预测框。
总结YOLOv1的优缺点
YOLO V1存在的优缺点:
优点:速度快,简单
缺点1:每个cell只预测1个类别,如果重叠无法解决
缺点2:小物体检测效果一般,长宽比可选,但单一。