图像来源:基于协同推理的双视角超声造影分类隐式数据增强方法|文献速递-深度学习医疗AI最新文献
Title
题目
Image by co-reasoning: A collaborative reasoning-based implicit data augmentation method for dual-view CEUS classification
图像来源:基于协同推理的双视角超声造影分类隐式数据增强方法
01
文献速递介绍
结合了B型超声(BUS)的双视角超声造影(CEUS),为多种临床任务提供了一种全面的成像方法,如疾病筛查、恶性肿瘤分级以及预后评估。如图1所示,B型超声能够捕捉病变的形态学特征,例如形状、大小、边缘以及回声模式。动态超声造影可对肿瘤的血供情况进行实时评估,其中不同的增强模式反映了增强程度、均匀性以及血流速度,这些都是肿瘤功能特征的体现,比如微血管分布、组织坏死情况以及肿瘤的侵袭范围(巴托洛塔等人,2019年;拉齐娜等人,2021年;南见和工藤,2011年)。最近,人们提出了各种机器学习算法,以使成像解读过程自动化,力求实现客观且高效的辅助诊断。 先前的研究通常将双视角超声造影分析构建为多视角学习问题(张等人,2023a;韩等人,2023年)或视频分类问题(梁等人,2016年;陈等人,2021年),强调多视角融合或动态特征提取方面。尽管这些方法在双视角超声造影分类中已取得了有前景的成果,但其有效性在很大程度上取决于大规模带注释数据集的可用性,而这些数据集能够保证捕捉到图像与标签之间稳定且可靠的相关性。然而,在实际应用中,收集足够的双视角超声造影数据尤其具有挑战性,这是因为数据采集既耗时又昂贵,而且还需要专家进行注释。一个常见的问题是,考虑到成像协议和患者状况的可变性,所收集的双视角超声造影数据会受到数据采集条件的干扰。 数据增强是一种丰富训练样本并降低过拟合风险的有效方法(王等人,2019年;洪等人,2022年;沃尔皮等人,2018年;李等人,2021年)。一种典型的解决方案是使用深度生成模型生成具有可控语义变化的人工样本(沙德贝克等人,2022年;弗里德 - 阿达等人,2018年;达尔马兹等人,2023年)。然而,这些生成模型本质上需要大量的训练数据,这与现实世界中数据稀缺的临床场景不符。另一种替代方法是隐式数据增强(王等人,2019年),它在潜在表示空间中对训练样本进行扰动。由于深度表示空间能够很好地线性化(厄普丘奇等人,2017年),沿着特定方向移动样本会引发相应的语义变化。 然而,现有的隐式数据增强方法通常是为单模态场景设计的,在这种场景中,语义扰动是针对每个模态独立推理的,而没有考虑模态间的语义一致性。我们认为,放射科医生可以根据他们的先验知识想象原始病例可能出现的变化,例如,“在给定肿瘤灌注模式的情况下,组织回声可能会如何变化,或者在给定肿瘤形态的情况下,可能会出现哪种类型的增强纹理”。也就是说,增强后的超声视角应该在特征空间中对齐,并一致地反映同一病变的形态学和功能特征。另一个局限性是,先前的研究通常从基于类别的增强分布中采样语义方向,忽略了同一类中的样本差异(陈等人,2022年)。考虑到同一类别的双视角超声造影通常表现出较大的成像变异性这一事实,我们认为最优的增强分布应该是“样本自适应的”,以便灵活地进行语义扰动。 受此启发,我们提出了一种基于协同推理的隐式数据增强(CRIDA)方法,用于双视角超声造影分类。CRIDA通过跨视角协同推理生成合理的增强数据,从而降低了在有限的双视角超声造影数据下过拟合的风险。该方法通过沿着某些语义方向平移训练样本的方式来增强训练样本,这些语义方向是从样本自适应增强分布中采样得到的,其协方差矩阵是根据训练数据的特征统计信息估计出来的。为了确保增强后的B型超声和超声造影视角在语义上对齐,我们的方法遵循一个两步流程。(1)我们首先使用可用的双视角超声造影数据训练网络,并将训练样本与类别标签一起,针对每个视角独立地聚类为K个组。然后,估计每个聚类的协方差矩阵,以捕捉该聚类内潜在的语义变化。(2)然后,我们通过协同推理的方式构建样本自适应增强分布(如图1所示)。例如,当解决“在给定肿瘤形态的情况下可能会出现哪种类型的增强纹理”这一问题时,我们从B型超声视角的相似聚类中搜索可转移的增强模式变化,借鉴具有相似肿瘤形态的实例的语义变化。同样,当考虑“在给定肿瘤灌注模式的情况下组织回声可能会如何变化”时,我们从超声造影视角的相似聚类中探索可转移的回声变化,从具有可比增强模式的实例中传播变换方向。我们的CRIDA方法的主要贡献可总结为以下三个方面。 - 我们提出了一种样本自适应的隐式数据增强方法,该方法为单个样本的每个超声视角构建特征增强分布。这种方法考虑了同一疾病类别的样本差异,为语义扰动提供了更大的灵活性。 - 我们引入了一种协同推理策略,以保持增强后的B型超声和超声造影视角之间的语义对齐。这种策略从另一个视角的相似实例中探索一个视角的可转移语义方向,从而一致地反映同一病变的形态学和功能特征。 - 我们在乳腺癌和肝癌的两个双视角超声造影数据集上评估了我们的CRIDA方法。我们的方法分别实现了89.25%和95.57%的卓越诊断准确率,证明了它在通过增加样本多样性来提高模型性能方面的有效性。
Abatract
摘要
Dual-view contrast-enhanced ultrasound (CEUS) data are often insufficient to train reliable machine learningmodels in typical clinical scenarios. A key issue is that limited clinical CEUS data fail to cover the underlyingtexture variations for specific diseases. Implicit data augmentation offers a flexible way to enrich samplediversity, however, inter-view semantic consistency has not been considered in previous studies. To addressthis issue, we propose a novel implicit data augmentation method for dual-view CEUS classification, whichperforms a sample-adaptive data augmentation with collaborative semantic reasoning across views. Specifically,the method constructs a feature augmentation distribution for each ultrasound view of an individual sample,accounting for intra-class variance. To maintain semantic consistency between the augmented views, plausiblesemantic changes in one view are transferred from similar instances in the other view. In this retrospectivestudy, we validate the proposed method on the dual-view CEUS datasets of breast cancer and liver cancer,obtaining the superior mean diagnostic accuracy of 89.25% and 95.57%, respectively. Experimental resultsdemonstrate its effectiveness in improving model performance with limited clinical CEUS data.
在典型临床场景中,双视角超声造影(CEUS)数据往往不足以训练出可靠的机器学习模型。一个关键问题在于,有限的临床CEUS数据无法涵盖特定疾病潜在的纹理变化。隐式数据增强为丰富样本多样性提供了一种灵活的方式,然而,以往研究未考虑视角间语义一致性。 为解决这一问题,我们提出一种用于双视角CEUS分类的新型隐式数据增强方法,该方法通过跨视角协同语义推理进行样本自适应的数据增强。具体而言,该方法针对单个样本的每个超声视角构建特征增强分布,以考虑类内差异。为保持增强视角间的语义一致性,一个视角中合理的语义变化是从另一视角的相似实例中迁移而来。 在这项回顾性研究中,我们在乳腺癌和肝癌的双视角CEUS数据集上对所提方法进行了验证,分别获得了89.25%和95.57%的卓越平均诊断准确率。实验结果证明了该方法在临床CEUS数据有限的情况下,对提升模型性能的有效性。
Method
方法
In this part, we introduce in detail our proposed CRIDA method,including the architecture of our network (Section 4.1), dual-viewCEUS representation (Section 4.2), the collaborative semantics reasoning strategy (Section 4.3), a modified cross-entropy loss for modeltraining (Section 4.4), and the implementation details (Section 4.5).
4.1. Architecture
The overall architecture of the proposed Collaborative Reasoningbased Implicit Data Augmentation (CRIDA) method is depicted in Fig.It consists of two sequential components, i.e., (1) raw dual-viewCEUS representation learning and (2) collaborative reasoning-basedsemantic augmentation.Our CRIDA method first extracts BUS view representation 𝑓𝑖 𝑢𝑠 andsequential CEUS view representation 𝐅 𝑐𝑒𝑢𝑠 𝑖 through the backbone network 𝑢𝑠𝜃and 𝑐𝑒𝑢𝑠𝜃, respectively. Then, dynamic enhancement pattern𝛾𝑖 is obtained by temporal ranking pooling 𝛾 = ( 𝐅 𝑐𝑒𝑢𝑠 𝑖 ) , concatenated with the peaking enhancement pattern 𝑓𝑖,𝑝 𝑐𝑒𝑢𝑠 to represent thedynamic blood perfusion process. After that, dual-view CEUS features𝐟𝑖 = [ 𝑓𝑖 𝑢𝑠; 𝑓𝑖 𝑐𝑒𝑢𝑠] are augmented by the module of collaborative semantic reasoning (⋅), which transfers relevant semantics via cross-viewcollaborative reasoning. Finally, augmented dual-view CEUS features̃𝐟 𝑖 = [ 𝑓̃𝑢𝑠𝑖; 𝑓̃𝑐𝑒𝑢𝑠𝑖] are concatenated for lesion classification.
在这一部分,我们将详细介绍我们提出的基于协同推理的隐式数据增强(CRIDA)方法,包括我们网络的架构(4.1节)、双视角超声造影(CEUS)表示(4.2节)、协同语义推理策略(4.3节)、用于模型训练的改进交叉熵损失函数(4.4节)以及实现细节(4.5节)。 4.1 架构 所提出的基于协同推理的隐式数据增强(CRIDA)方法的总体架构如图所示。它由两个顺序的组件组成,即:(1)原始双视角超声造影表示学习;(2)基于协同推理的语义增强。 我们的CRIDA方法首先分别通过主干网络(\mathcal{F}{us}^{\theta})和(\mathcal{F}{ceus}^{\theta})提取B型超声(BUS)视角表示(f{i}^{us})和连续的超声造影视角表示(\mathbf{F}{ceus}^{i})。然后,通过时间排序池化(\gamma = \mathcal{R}(\mathbf{F}{ceus}^{i}))得到动态增强模式(\gamma^{i}),并将其与峰值增强模式(f{i,p}^{ceus})连接起来,以表示动态的血液灌注过程。在此之后,双视角超声造影特征(\mathbf{f}^{i} = [f{i}^{us}; f{i}^{ceus}])由协同语义推理模块(\mathcal{C}(\cdot))进行增强,该模块通过跨视角协同推理来传递相关语义。最后,增强后的双视角超声造影特征(\tilde{\mathbf{f}}^{i} = [\tilde{f}{us}^{i}; \tilde{f}{ceus}^{i}])被连接起来用于病变分类。
Conclusion
结论
In this study, a Collaborative Reasoning-based Implicit Data Augmentation (CRIDA) method is proposed to improve diagnostic performance of dual-view CEUS imaging. To encode dynamic enhancement characteristics of CEUS view, we incorporate temporal rankpooling to disentangle temporal evolution direction of wash-in andwash-out stages, respectively. To boost multi-modality classificationperformance, we propose to augment dual-view CEUS at the featurelevel while keep inter-modality consistency. On the collected dual-viewCEUS dataset, the proposed method has demonstrated better or at leastcomparable classification performance.
在本研究中,我们提出了一种基于协同推理的隐式数据增强(CRIDA)方法,以提高双视角超声造影(CEUS)成像的诊断性能。为了对超声造影视角的动态增强特征进行编码,我们引入了时间排序池化方法,分别梳理出造影剂注入期和廓清期的时间演变方向。为了提升多模态分类性能,我们提议在保持模态间一致性的同时,在特征层面上对双视角超声造影数据进行增强。在收集到的双视角超声造影数据集上,所提出的方法已展现出更优或者至少相当的分类性能。
Results
结果
In this section, we first compare our CRIDA method with severalstate-of-the-art methods. Then, we validate the effectiveness of dynamicenhancement pattern representation and collaborative semantics reasoning of this method. After that, we perform ablation experimentsby removing the core components. Finally, we analyze the sensitivityof key model hyper-parameters and provide visualization results ofaugmented samples.
在本节中,我们首先将我们的CRIDA方法与几种最先进的方法进行比较。然后,我们验证该方法中动态增强模式表示以及协同语义推理的有效性。在此之后,我们通过去除核心组件来进行消融实验。最后,我们分析关键模型超参数的敏感性,并给出增强样本的可视化结果。
Figure
图
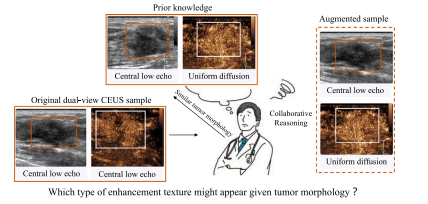
Fig. 1. An illustration of collaborative semantic reasoning for implicit data augmentation. We could reason the possible enhancement pattern (i.e., uniform diffusion) ofCEUS view by the same echo pattern (i.e., central low echo) of BUS view.
图1:用于隐式数据增强的协同语义推理示意图。我们可以通过B型超声(BUS)视角中相同的回声模式(即中心低回声),来推断超声造影(CEUS)视角中可能的增强模式(即均匀扩散) 。
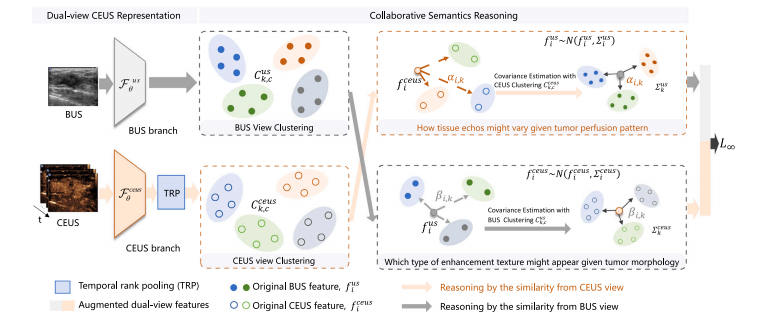
Fig. 2. The framework of the proposed Collaborative Reasoning-based Implicit Data Augmentation (CRIDA) method. It consists of Dual-view CEUS representation and Collaborativesemantics reasoning. To ensure augmented BUS and CEUS features to be aligned semantically, this method augments dual-view samples through cross-view collaborative reasoning,addressing the question how tissue echos might vary given tumor perfusion pattern and *which type of enhancement texture might appear given tumor morphology
图2:所提出的基于协同推理的隐式数据增强(CRIDA)方法的框架。它由双视角超声造影(CEUS)表示和协同语义推理两部分组成。为确保增强后的B型超声(BUS)和超声造影(CEUS)特征在语义上保持一致,该方法通过跨视角协同推理对双视角样本进行增强,从而解决“在给定肿瘤灌注模式的情况下,组织回声可能会如何变化”以及“在给定肿瘤形态的情况下,可能会出现哪种类型的增强纹理”这样的问题。
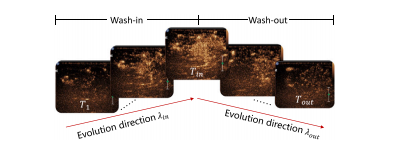
Fig. 3. Dynamic enhancement pattern representation. There exists a temporal evolutiondirection within wash-in ( 𝑇1 → 𝑇𝑖𝑛) or wash-out ( 𝑇𝑖𝑛 → 𝑇𝑜𝑢𝑡) stage, 𝛾𝑖𝑛 and 𝛾𝑜𝑢𝑡, outliningenhancement texture changes along time
图3:动态增强模式表示。在造影剂注入期((T_1)→(T{in}))或廓清期((T{in})→(T{out}))阶段内存在一个时间演变方向,(\gamma{in})和(\gamma_{out})描绘了随时间变化的增强纹理变化情况。
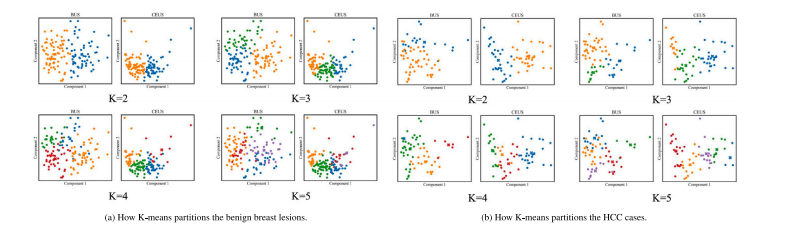
Fig. 4. 2-dim distribution maps of the 𝐾-means clustering with various 𝐾 settings from 2 to 5. Note that, clustering are performed within certain class in our method.
图4:在不同(K)值(从(2)到(5))设置下的(K)均值聚类的二维分布图。请注意,在我们的方法中,聚类是在特定类别内进行的。
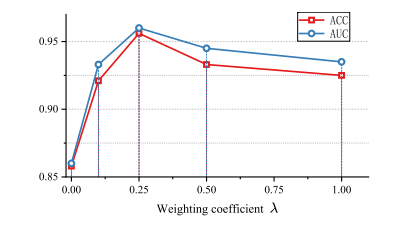
Fig. 5. Results of liver cancer differentiation obtained by our CRIDA method based ondifferent values of the weighting coefficient 𝜆.
图5:我们的基于协同推理的隐式数据增强(CRIDA)方法在不同加权系数(\lambda)取值情况下,所得到的肝癌鉴别结果。
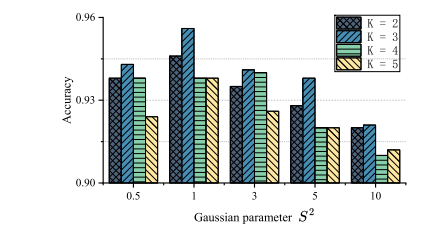
Fig. 6. Results of liver cancer differentiation obtained by our CRIDA method based ondifferent combinations of 𝐾 and 𝑠 2 .
图6:我们的CRIDA方法基于(K)和(s_2)的不同组合所得到的肝癌鉴别结果。
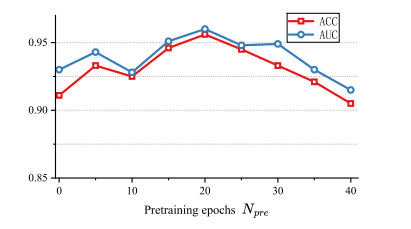
Fig. 7. Results of liver cancer differentiation obtained by our CRIDA method based on different numbers of pretraining epochs𝑁𝑝𝑟𝑒 .
图7:我们的CRIDA方法基于不同的预训练轮数(N_{pre})所得到的肝癌鉴别结果。
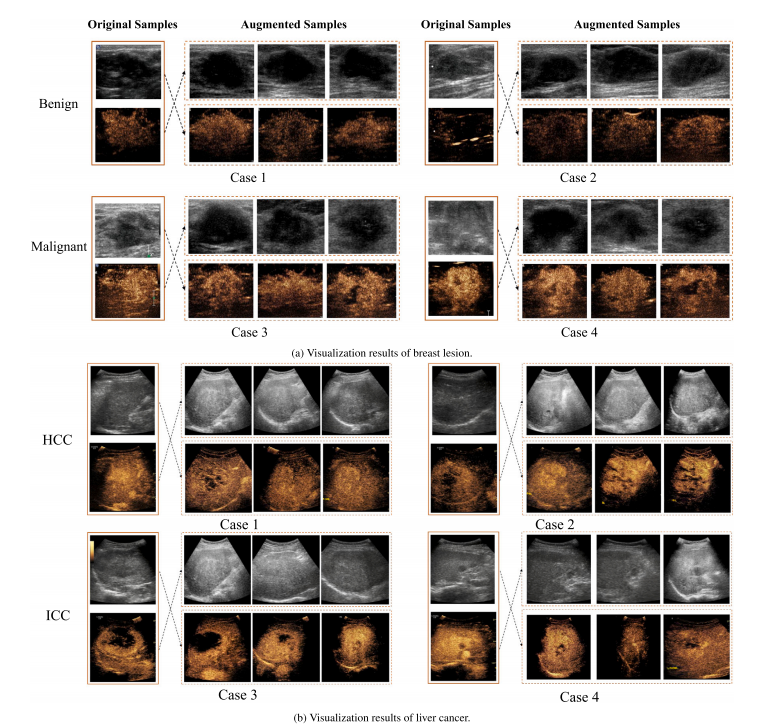
Fig. 8. Visualization of original samples and augmented samples for breast lesion and liver cancer. The dotted line points to the cross-view collaborative reasoning with the givenBUS or CEUS view images. For each image, three corresponding augmented images are displayed.
图8:乳腺病变和肝癌的原始样本与增强样本的可视化展示。虚线指向与给定的B型超声(BUS)或超声造影(CEUS)视图图像进行的跨视图协同推理。对于每一幅图像,都展示了三张相应的增强图像。
Table
表
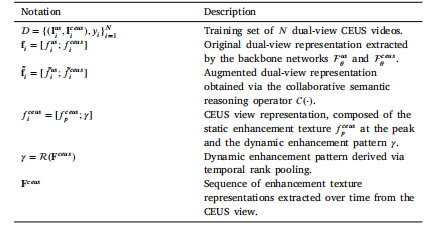
Table 1Notations and descriptions
表1 符号及说明

Table 2Parameters of the collected dual-view CEUS datasets. Dataset I and II are breast andliver dual-view CEUS dataset, respectively. 1 denotes malignant lesion or ICC. FPS arethe abbreviations for frames per second.
表2 所收集的双视角超声造影(CEUS)数据集的参数。数据集I和数据集II分别为乳腺和肝脏的双视角超声造影数据集。“1”表示恶性病变或肝内胆管细胞癌(ICC)。FPS是“每秒帧数(frames per second)”的缩写。

Table 3Hyperparameters for 𝑓𝜃 ℎ𝑦𝑝
表3 (f_{\theta}^{hyp})的超参数
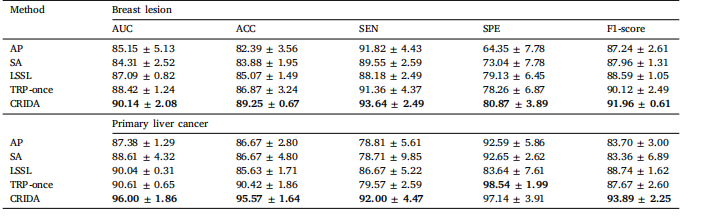
Table 4Comparison of different temporal dynamics learning methods.
表4 不同时间动态学习方法的比较。
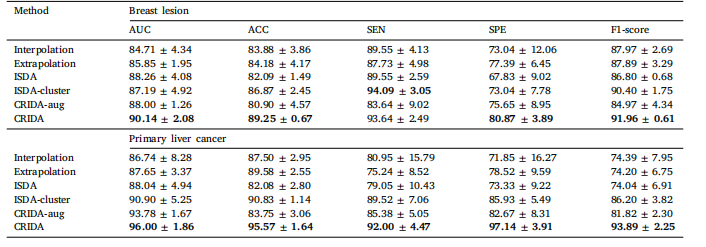
Table 5Comparison of different feature augmentation strategies
表5 不同特征增强策略的比较
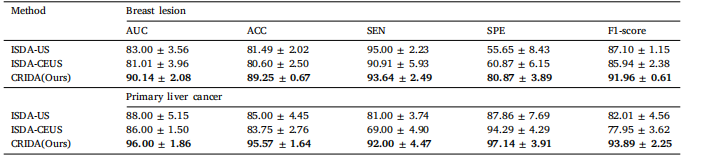
Table 6Comparison with single-modality data augmentation classification.
表6 与单模态数据增强分类的比较

Table 7Results of ablation experiments under different component combinations
表7 不同组件组合下的消融实验结果