kafka学习笔记(四、生产者、消费者(客户端)深入研究(三)——事务详解及代码实例)

1.事务简介
Kafka事务是Apache Kafka在流处理场景中实现Exactly-Once语义的核心机制。它允许生产者在跨多个分区和主题的操作中,以原子性(Atomicity)的方式提交或回滚消息,确保数据处理的最终一致性。例如,在流处理中,消费者读取消息后处理并生成新消息,若处理失败,事务可确保原始消息的消费偏移与新消息的发送同时回滚,避免数据不一致。
事务的核心作用:
原子性: 跨分区的写操作要么全部成功,要么全部失败。
隔离性: 事务未提交时,消息对消费者不可见(通过isolation.level=read_committed配置实现)。
持久性: 事务状态持久化至内部Topic __transaction_state,支持故障恢复。
2.事务实现的核心原理
2.1.幂等性
幂等性是事务的基础,确保单分区内消息不重复。
简单的说就是对接口的多次调用所产生的结果和调用一次是一致的。(生产者在进行重试的时候有可能会重复写入消息,kafka幂等性功能的使用就是为了避免这种情况的发生)
其实现依赖两个核心机制:
- Producer ID(PID):生产者初始化时由事务协调器(Transaction Coordinator)分配的唯一标识。
- 序列号(Sequence Number):每个消息携带的递增序号,Broker通过检查PID和序列号判断是否重复。
每个新的生产者实例在初始化的时候都会被分配一个
PID,这个PID对用户而言是完全透明的。对于每个PID,消息发送到的每一个分区都有对应的序列号,这些序列号从0开始单调递增。生产者没发送一条消息就会将 <PID,分区> 对应的序列号的值加1。broker端会在内存中为每一对 <PID,分区> 维护一个序列号。对于收到的额每一条消息,只有当他的序列号的值(
SN_new)比broker端维护的对应序列号的值(SN_old)大1(即SN_new = SN_old + 1)时,broker才会接收它。
配置要求:
enable.idempotence=truemax.in.flight.requests.per.connection≤5acks=allretries>0(需启用重试机制)。
局限性:幂等性仅保证单会话、单分区的
Exactly-Once语义,无法跨会话或多分区。
2.2.事务机制
事务通过事务协调器(TransactionCoordinator, TC)和事务日志(__transaction_state)扩展了幂等性,实现跨分区和会话的原子性。
- 事务协调器(
TransactionCoordinator)角色: 管理事务生命周期,持久化事务状态至
__transaction_state。
容错: TC故障时,新TC通过事务日志恢复状态。 - 事务日志(
__transaction_state)存储内容: 事务ID、PID、涉及的分区列表、事务状态(如Ongoing、PrepareCommit)。
分区策略: 按事务ID哈希分配到50个默认分区,确保负载均衡。
2.3.事务实现原理
事务实现的流程从事务的初始化到开启及发送消息再到提交或回滚事务主要分为以下五个阶段来讲解。
2.3.1.查找TransactionCoordinator
TransactionCoordinator负责分配PID和管理事务,所以生产者要做的第一件事就是找出对应的 TransactionCoordinator所在的broker节点。
步骤:
- 发送
FindCoordinatorRequest请求,FindCoordinatorRequest中的coordinator_type为1。 - kafka收到请求,根据
coordinator_key(transactionalId)查找对应的TransactionCoordinator节点,找到返回对应的node_id、host和 port信息。通过
transactionalId的哈希值分配到__transaction_state的特定分区编号。
计算算法:
Utils.abs(transactionalId.hashCode) % transactionTopicPartitionCount1 - 最后根据找到的分区寻找此分区leader副本所在的broker节点,该broker几点即为这个
transactionalId对应的TransactionCoordinator节点。
2.3.2.获取PID
在找到TransactionCoordinator节点后,就需要为当前生产者分配一个PID了。生产者获取PID的操作是通过InitProducerIdRequest请求实现的。
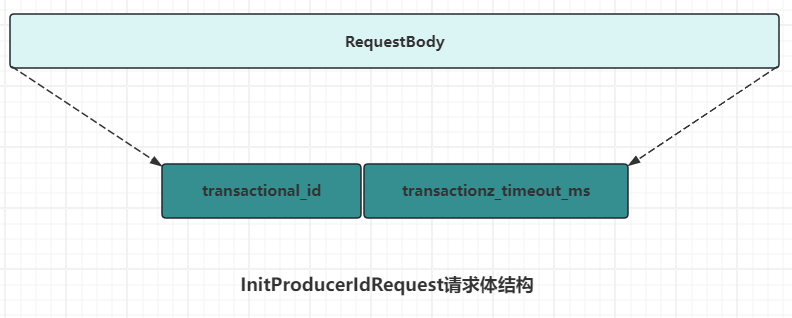
transactional_id: 表示事务transactionalId。transactional_timeout_ms: 表示TransactionCoordinator等待事务状态更新的超时时间,通过客户端参数transaction.timeout.ms配置,默认为60s。
步骤:
- 生产者发送
InitProducerIdRequest请求到TransactionCoordinator。如果未开启事务特性只开启幂等特性,则InitProducerIdRequest请求可以发送给任意的broker。
TransactionCoordinator将第一次收到包含transactionalId的InitProducerIdRequest请求的transactionalId和对应的PID以消息的形式保存到主题__transaction_state中(Conssume-transorm-produce流程图中2.1步骤)。- 增加该
PID对应的producer_epoch。具有相同
PID但producer_epoch小于该producer_epoch的其他生产者新开启的事务会被拒绝。 - 恢复(commit)或中止(Abort)之前的生产者未完成的事务。
- 响应InitProducerIdRequest请求。
返回类型为
InitProducerIdResponse,其主要包含PID和producer_epoch。
2.3.3.开启事务
通过KafkaProducer的beginTransaction()方法开启事务。
调用了此方法后,生产者本地会标记已经开启了一个新的事物,只有在生产者发送第一条消息之后TransactionCoordinator才会认为该事物已经开启。
2.3.4.Conssume-transorm-produce
这个阶段是kafka事务中最复杂的一个阶段,其包含了整个事务的数据处理流程,涉及多种请求。
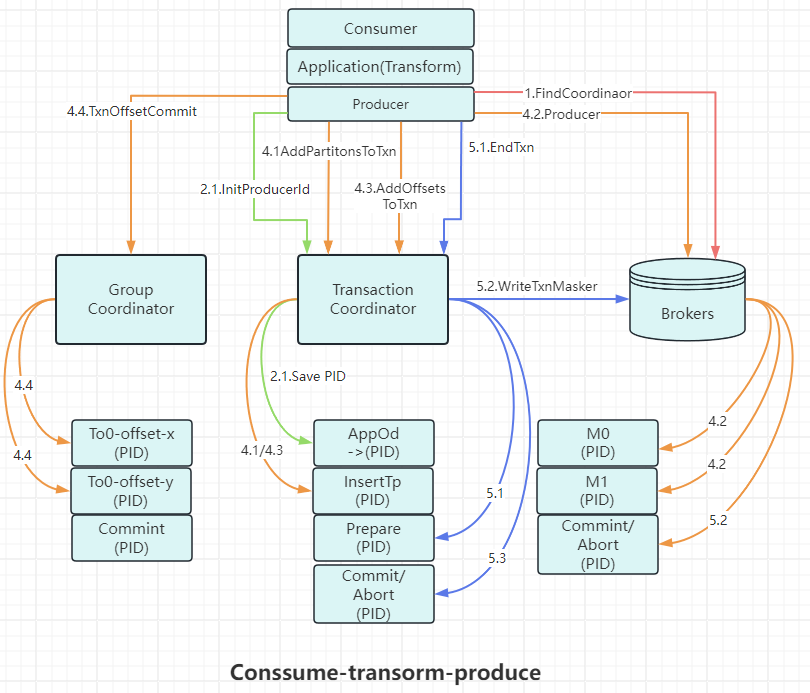
步骤:
-
AddpartitonsToTxnRequest
生产者给一个新的分区(TopicPartition)发送数据之前,就需要先向TransactionCoordinator发送AddpartitonsToTxnRequest。
这个请求会让TransactionCoordinator将<transactionId, TopicPartiton>的对应关系存储在主题_transaction_state中(上图中的4.1步骤)以此对照关系后续为每个分区设置COMMIT或ABORT标记。如果该分区是对应事务中的第一个分区,那么此时
TransactionCoordinator还会启动对该事务的计时。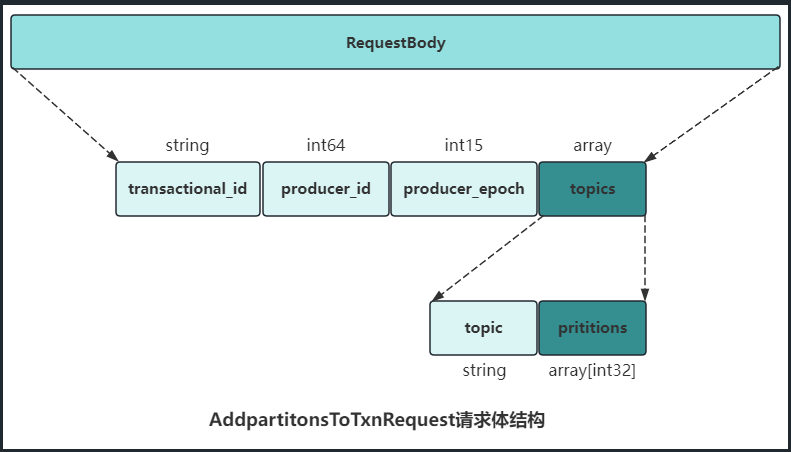
-
ProduceRequest
生产者通过ProduceRequest发送消息(ProducerBatch)到用户自定义主题中(与发送普通消息相同,如流程图4.2)。
与普通消息不同的是,ProducerBatch中包含实质的PID、producer_epoch和sequence number。 -
AddOffsetsToTxnRequest
此请求来自KafkaProducer中的sendOffsetsToTranscation()方法,此方法可以在一个事物批次里处理消息的消费和发送。此方法会向TransactionCoordinator节点发送AddOffsetsToTxnRequest请求,TransactionCoordinator收到后会通过groupId来推导出在_consumer_offsets中的分区,之后将这个分区保存在_consumer_offsets中(如流程图4.3)。方法有两次参数
Map<TopicPartition, OffsetAndMetadata> offsets和groupId。
-
TxnOffsetCommitRequest
此请求也来自sendOffsetsToTranscation(),在处理完AddOffsetsToTxnRequest之后,生产者还会发送TxnOffsetCommitRequest请求给GroupCoordinator,从而将本次事务中包含的消费位移信息offsets存储到主题_consumer_offsets中(如流程图4.4)。
2.3.5.提交或中止事务
数据写入成功就可以调用kafkaProducer中的commitTransaction()方法或abortTransaction()方法来结束当前事务。其步骤如下:
-
EndTxnrequest
此请求用来提交或中止事务。无论调用
commitTransaction()方法或abortTransaction()方法,生产者都会向TransactionCoordinator发送EndTxnRequest请求。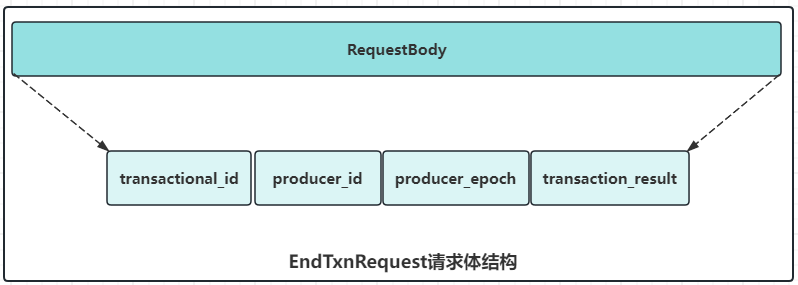
TransactionCoordinator收到EndTxnRquest的执行流程:
- 将
PREPARE_COMMIT或PREPARE_ABORT消息写入主题__transaction_state(流程图5.1)。 - 通过
WriteTxnMarkersRequest请求将COMMIT或ABORT信息写入用户所使用的普通主题和__consumer_offsets(流程图5.2)。 - 将
COMPLETE_COMMIT或COMPLETE_ABORT信息写入内部主题__transaction_state(流程图5.3)
- 将
-
WriteTxnMarkersRequest
此请求的由TransactionCoordinator发向事务中各个分区的leader节点,当节点收到请求后会在对应的分区中写入控制消息(ControlBatch)。控制消息用来标识事务的终结,和普通消息一样存储到日志文件中。
-
写入最终的
COMPLETE_COMMIT或COMPLETE_ABORT
TransactionCoordinator将最终的COMPLETE_COMMIT或COMPLETE_ABORT信息写入主题__transaction_state以表明当前事务已经结束,此时可以删除主题__transaction_state中所有关于该事务的消息。
由于主题
__transaction_state采用的日志清理策略为日志压缩,所以这里的删除只需将相应的消息设置为墓碑消息2即可。
transactionTopicPartitionCount为主题__transaction_state中分区个数,这个可以通过broker端参数transaction.state.log.num.partitions类配置,默认为50。 ↩︎
墓碑消息:不直接删除数据,而是通过在数据记录中插入一个特殊的标记(即墓碑消息),来指示这些数据已被删除或不再有效。墓碑消息本身不占用存储空间,它只是标记了数据的删除状态,实际的物理删除是由日志压缩(Compact)或日志删除(Delete)策略来完成的。 ↩︎