学习pytorch的第二日
一、现有网络模型的使用与修改(以vgg16为例)
1、导入(pretrained为True则代表参数已经训练过了)

2、修改

二、网络模型的保存与读取(模型保存,保存的是实例)
1、保存 (两种方式)
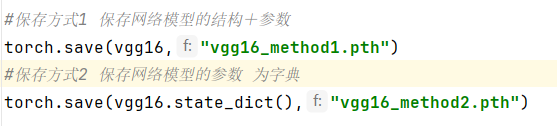
2、读取加载

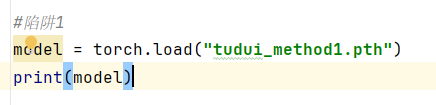
3、保存方式1的陷阱(自己写出的模型, 在加载时必须要有该模型类)

三、完整的模型训练套路(技巧)
1、.item()函数 可以将tensor数据
将单元素张量转换为Python标量(例如,float、int等)。
如果张量有多个元素,使用
.item()会抛出错误。
2、测试时(不需要反向传播)可以使用 with torch.no_grad():
已知在PyTorch中,默认情况下,前向传播时会构建计算图,以便于反向传播时计算梯度。
但是,如果我们在测试阶段不需要计算梯度,那么使用torch.no_grad()可以避免构建计算图,从而节省内存和计算资源。
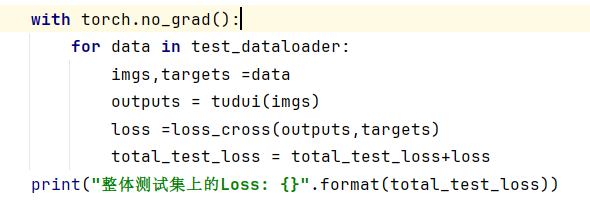
3、求得测试集的正确率
argmax的作用

在测试集中的应用

4、模型的模式
train() 和 eval() 主要影响 Dropout 和 BatchNorm 层的行为。


1. model.train()
Dropout层:启用,随机"关闭"一部分神经元
BatchNorm层:使用当前batch的统计量(均值和方差),并更新运行统计量
其他层:不受影响
2. model.eval()
Dropout层:禁用,所有神经元都参与计算
BatchNorm层:使用训练阶段积累的运行统计量,不更新统计量
其他层:不受影响
5、模型的训练套路
数据集dataset ——》加载数据集dataloader——》调用模型、设置损失函数、设置优化器、设置参数——》开始训练 模型.train() 输入、输出、计算损失、梯度清零、计算梯度(损失.backward)、根据梯度更新——》测试 模型.eval()、with torch.no_grad():无梯度模式、计算损失、正确率
四、利用gpu进行训练
第一种使用gpu的方式
1、网络模型的cuda()
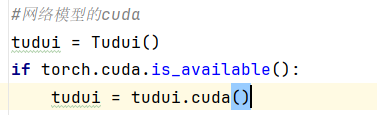
2、损失函数的cuda()
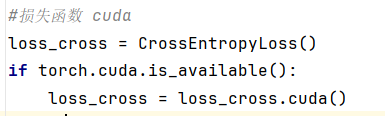
3、数据(输入、标注)的cuda()(需要重新赋值)

第二种使用gpu的方式
1、定义device

2、网络模型的cuda()

3、损失函数的cuda()

4、数据(输入、标注)的cuda()(需要重新赋值)

五、time
import time
start_time = time.time()
{ 代码块 }
end_time = time.time()