【图像大模型】Stable Diffusion Web UI:深度解析与实战指南
Stable Diffusion Web UI:深度解析与实战指南
- 一、项目概述
- 核心功能
- 二、项目运行方式与执行步骤
- 1. 环境准备
- 2. 安装步骤
- 在Windows上安装
- 在Linux上安装
- 3. 使用Web UI
- 三、执行报错及问题解决方法
- 1. Python版本不兼容
- 2. CUDA未正确安装
- 3. 依赖库安装失败
- 4. 内存不足
- 5. 扩展功能无法加载
- 四、 相关论文信息
- 五、总结
在人工智能和计算机视觉领域,Stable Diffusion作为一种强大的生成式模型,已经吸引了众多研究者和开发者的关注。而 Stable Diffusion Web UI项目则为这一技术提供了一个直观、易用且功能强大的交互界面,极大地降低了使用门槛,使其能够被更广泛地应用于图像生成任务中。本文将深入解析该项目,从技术原理、运行方式、执行步骤到常见问题及解决方法,全方位展示其魅力和实用性。
一、项目概述
Stable Diffusion Web UI是由AUTOMATIC1111开发的一个基于Web的用户界面,旨在为Stable Diffusion模型提供一个简单易用的操作平台。该项目基于Gradio库实现,支持多种图像生成模式,包括文本到图像(txt2img)和图像到图像(img2img)等。它不仅提供了丰富的功能,还通过扩展和自定义脚本支持了更多高级特性。
核心功能
- 文本到图像(txt2img):根据用户输入的文本描述生成图像。
- 图像到图像(img2img):基于输入图像进行风格转换或内容修改。
- 扩展功能:支持多种扩展,如GFPGAN(修复人脸)、CodeFormer(人脸修复)、RealESRGAN(图像超分辨率)等。
- 高级特性:包括文本反转(Textual Inversion)、注意力权重调整、批处理、图像拼接等。
- 模型支持:支持多种Stable Diffusion模型版本,包括Stable Diffusion 2.0和Alt-Diffusion。
二、项目运行方式与执行步骤
1. 环境准备
在运行Stable Diffusion Web UI之前,需要确保系统满足以下依赖条件:
- Python:建议使用Python 3.10.6,更高版本可能不兼容。
- Git:用于克隆项目代码。
- CUDA(可选):如果使用NVIDIA GPU加速,需要安装CUDA和相应的驱动程序。
- 其他依赖:根据操作系统不同,可能需要安装额外的库或工具。
2. 安装步骤
在Windows上安装
-
安装Python和Git:
- 下载并安装Python 3.10.6,确保勾选“Add Python to PATH”选项。
- 下载并安装Git。
-
克隆项目代码:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git cd stable-diffusion-webui -
运行安装脚本:
- 如果使用NVIDIA GPU,运行
webui-user.bat。 - 如果使用CPU,运行
webui-user-cpu.bat。
- 如果使用NVIDIA GPU,运行
-
启动Web UI:
- 运行
webui.bat或webui-cpu.bat,根据提示访问本地服务器(通常是http://127.0.0.1:7860)。
- 运行
在Linux上安装
-
安装依赖:
# Debian-based sudo apt install wget git python3 python3-venv libgl1 libglib2.0-0# Red Hat-based sudo dnf install wget git python3 gperftools-libs libglvnd-glx# openSUSE-based sudo zypper install wget git python3 libtcmalloc4 libglvnd# Arch-based sudo pacman -S wget git python3 -
克隆项目代码:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git cd stable-diffusion-webui -
运行安装脚本:
- 运行
webui.sh。 - 如果需要自定义配置,可以编辑
webui-user.sh。
- 运行
-
启动Web UI:
- 运行
webui.sh,根据提示访问本地服务器。
- 运行
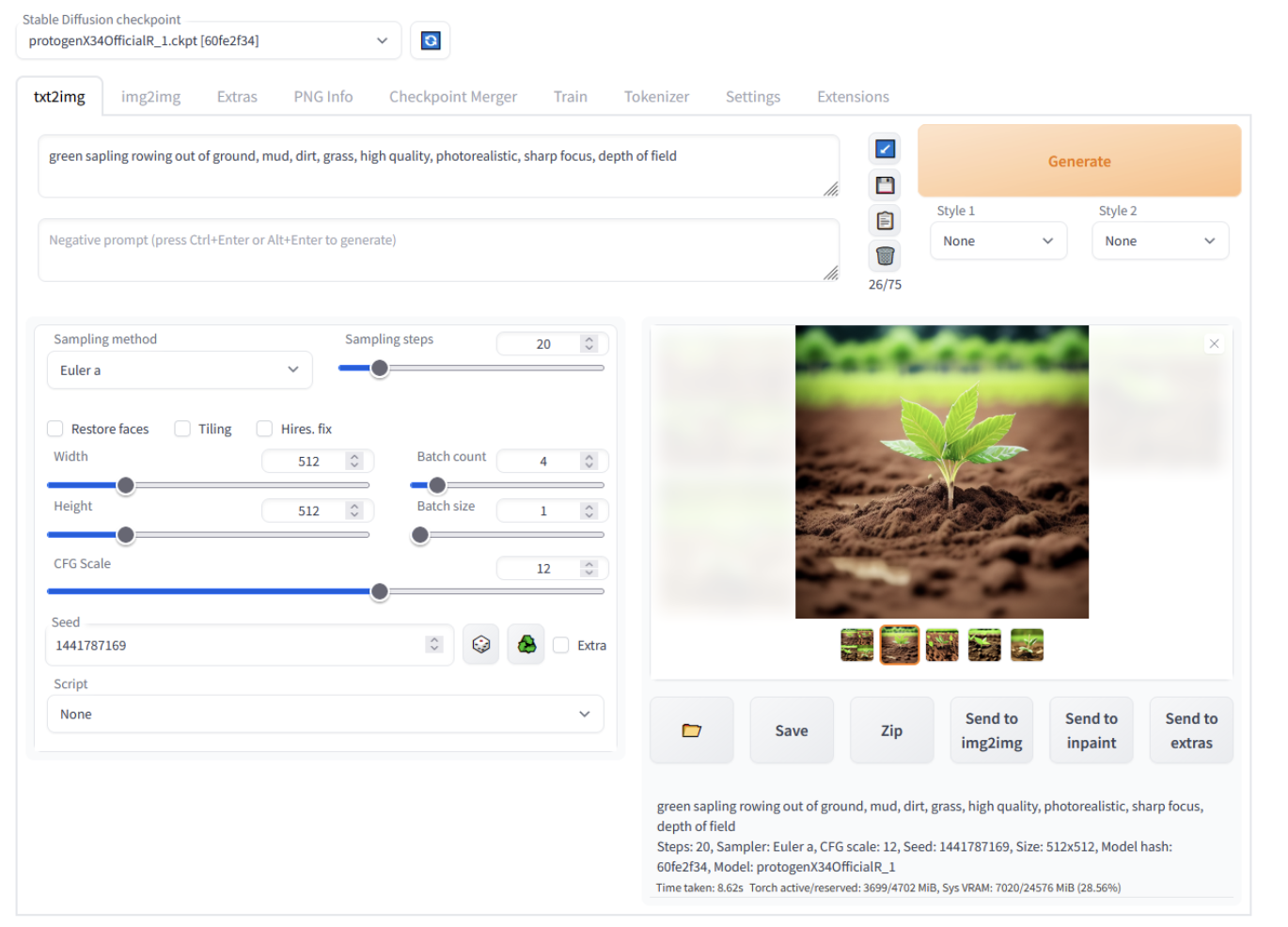
3. 使用Web UI
启动Web UI后,可以通过浏览器访问本地服务器地址(通常是http://127.0.0.1:7860)。界面分为多个模块,包括:
- txt2img:输入文本描述生成图像。
- img2img:上传图像并进行风格转换或内容修改。
- 扩展功能:如GFPGAN、CodeFormer等。
- 高级设置:调整模型参数、采样方法等。
三、执行报错及问题解决方法
1. Python版本不兼容
问题描述:运行时提示Python版本不兼容,例如需要Python 3.10.6,但系统安装了更高版本。
解决方法:
- 卸载当前Python版本,重新安装Python 3.10.6。
- 或者使用虚拟环境管理工具(如
conda或virtualenv)创建一个Python 3.10.6的虚拟环境。
2. CUDA未正确安装
问题描述:使用NVIDIA GPU时,提示CUDA未正确安装或版本不匹配。
解决方法:
- 确保安装了正确版本的CUDA(与PyTorch版本匹配)。
- 更新NVIDIA驱动程序到最新版本。
- 如果问题仍然存在,尝试手动安装CUDA工具包。
3. 依赖库安装失败
问题描述:运行安装脚本时,某些依赖库安装失败。
解决方法:
- 手动安装失败的库,例如:
pip install torch torchvision torchaudio - 如果使用Linux系统,确保安装了必要的系统依赖库。
4. 内存不足
问题描述:在生成高分辨率图像时,提示内存不足。
解决方法:
- 降低生成图像的分辨率。
- 使用低精度模式(如
--precision fp16)。 - 如果使用GPU,尝试减少批处理大小。
5. 扩展功能无法加载
问题描述:某些扩展功能(如GFPGAN)无法加载。
解决方法:
- 确保扩展功能的依赖库已正确安装。
- 检查扩展功能的模型文件是否完整,必要时重新下载。
四、 相关论文信息
Stable Diffusion Web UI项目基于Stable Diffusion模型,其核心论文为:
Stable Diffusion: A Latent Diffusion Model for High-Fidelity Image Generation
论文链接
作者:Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
该论文提出了一种基于扩散模型的图像生成方法,通过在潜在空间中进行扩散过程,实现了高质量的图像生成。
此外,项目还集成了多种扩展功能,其相关论文包括:
-
GFPGAN: Towards Real-World Blind Face Restoration with Generative Facial Prior
论文链接
作者:Xintao Wang, Yu Li, Honglun Zhang, Ying Shan, Chao Dong, Chen Change Loy
该论文提出了一种用于人脸修复的生成对抗网络,能够有效修复低质量人脸图像。 -
CodeFormer: Robust Facial Code Manipulation for High-Fidelity Face Editing
论文链接
作者:Zhou et al.
该论文提出了一种基于编码器-解码器结构的面部编辑方法,能够实现高质量的人脸修复和编辑。
五、总结
Stable Diffusion Web UI项目为Stable Diffusion模型提供了一个功能强大且易于使用的交互界面。通过丰富的功能和灵活的配置选项,用户可以轻松实现各种图像生成任务。本文详细介绍了项目的运行方式、执行步骤以及常见问题的解决方法,希望能够帮助读者更好地理解和应用这一工具。无论是在艺术创作、图像编辑还是研究领域,Stable Diffusion Web UI都展现了其强大的潜力和实用性。