精读计算机体系结构基础 第一章 引言
要研究如何制造计算机,我们需要从两个主要方面入手:硬件和软件。
在硬件方面,我们需要理解计算机组成原理和计算机体系结构。计算机组成原理主要讲述计算机的基本构成部分,比如CPU、内存和存储设备等。而计算机体系结构则更深入地研究如何设计和构建CPU,这是计算机的核心部分。
在软件方面,我们需要了解操作系统和编译原理。操作系统是管理计算机硬件和软件资源的程序,比如Windows和Linux。编译原理则涉及如何将程序代码转换为计算机可以理解的语言。
信息产业的主要技术平台都是围绕**中央处理器(CPU)和操作系统(OS)**构建的。例如:
- Wintel平台:由英特尔公司的X86架构CPU和微软公司的Windows操作系统组成。
- AA平台:由ARM公司的ARM架构CPU和谷歌公司的Android操作系统组成。
龙芯公司正在努力构建一个独立于Wintel和AA平台的第三套生态体系。这意味着他们希望开发出自己的CPU和操作系统,以减少对现有技术的依赖。
1.1 计算机体系结构的研究内容
计算机体系结构的研究内容非常广泛,涵盖了多个领域。
我们可以从两个主要方向来理解:纵向和横向。
在纵向上,计算机体系结构的研究主要围绕以下几个层次展开:
- 指令系统结构:这是计算机能够理解和执行的基本命令集,决定了CPU如何处理数据和指令。
- CPU的微结构:这涉及到CPU内部的具体设计和实现,包括数据通路、控制单元和缓存等。
- 电路结构:在更低的层次上,研究晶体管级的电路结构,了解如何通过电子元件构建出复杂的计算功能。
- 应用程序编程接口(API):在更高的层次上,API是程序与操作系统之间的接口,允许开发者利用计算机的功能来编写应用程序。
在横向上,计算机体系结构的研究主要集中在不同类型的计算机系统上:
- 个人计算机和服务器:这是最常见的计算机类型,研究它们的体系结构可以帮助我们理解日常使用的计算机如何工作。
- 手持移动终端和微控制器(MCU):这些是低端设备,通常用于特定的应用,如智能手机和嵌入式系统。
- 高性能计算机(HPC):这是高端计算机,专门用于处理复杂的计算任务,如科学计算和大数据分析。
1.1.1 WPS的输入到输出
为了说明计算机体系结构研究涉及的领域,我们看一个很简单平常的问题:为什么我按一下键盘,PPT会翻一页?这是一个什么样的过程?在这个过程中,应用程序(WPS)、操作系统(Windows或Linux)、硬件系统、CPU、晶体管是怎么协同工作的?
下面介绍用龙芯CPU构建的系统实现上述功能的原理性过程。
当你按下键盘上的一个键(例如字母“A”),键盘会生成一个电信号。这是一个简单的电流变化,表示你进行了一个输入操作。这个电信号会被发送到计算机主板上的南桥芯片。南桥芯片是负责管理输入设备(如键盘、鼠标等)与计算机其他部分之间通信的组件。南桥芯片接收到信号后,会将这个信号转换为一个特定的编码,这个编码代表你按下的键。然后,南桥芯片会把这个编码存储在它内部的一个寄存器中。寄存器可以看作是一个小的存储空间,用于临时保存信息。接下来,南桥芯片会向中央处理器(CPU)发出一个外部中断信号。这个信号的作用是通知CPU有新的输入需要处理。当外部中断信号到达CPU时,CPU会在其内部的一个控制寄存器中设置一个特定的位置为“1”。这个操作表示CPU已经收到了外部中断信号,知道有新的输入需要处理。CPU内部还有另一个控制寄存器,其中包含一个屏蔽位。
这个屏蔽位的作用是决定CPU是否处理这个外部中断信号:
- 如果屏蔽位是“打开”的(例如设置为“1”),那么CPU会处理这个外部中断信号。
- 如果屏蔽位是“关闭”的(例如设置为“0”),那么CPU会忽略这个信号,不进行处理。
当CPU接收到一个外部中断信号后,如果这个信号被允许处理(即屏蔽位是“打开”的),它会被附加到一条已经译码的指令上。这条指令随后会被送到重排序缓冲(Re-Order Buffer,简称ROB)。重排序缓冲是CPU内部的一个结构,用于管理指令的执行顺序。它允许CPU在执行指令时进行重排序,以提高性能,但同时也确保最终的执行结果是正确的。外部中断被视为一种例外(Exception)。当发生例外的指令被送到重排序缓冲时,这条指令不会被立即送到功能部件(如算术逻辑单元、内存访问单元等)执行。相反,CPU会等待这条指令成为重排序缓冲中的第一条指令。一旦这条例外指令成为重排序缓冲的第一条指令,CPU就会开始处理这个例外。在处理例外之前,重排序缓冲会确保以下两点:
- 执行完前面的指令:重排序缓冲会确保在这条例外指令之前的所有指令都已经执行完毕。这是为了保证系统状态的一致性。
- 取消后面的指令:对于在例外指令之后的所有指令,CPU会将它们取消掉。这是因为这些指令的执行可能会受到例外的影响,执行它们可能会导致不一致的状态。
通过这种方式,重排序缓冲为操作系统提供了一个精确的例外现场。这意味着操作系统可以准确地知道在发生例外时,CPU的状态是什么样的,包括寄存器的值和指令的执行状态。这对于调试和错误处理非常重要。
当重排序缓冲(Re-Order Buffer,简称ROB)检测到需要处理的例外指令时,它会向所有相关模块发出一个取消信号。这个信号的作用是取消该指令后面的所有指令的执行。这是为了确保在处理例外时,系统状态不会受到未执行指令的影响。接下来,CPU会修改控制寄存器,将系统状态设置为核心态(也称为特权态)。核心态是操作系统运行的状态,允许它访问所有硬件资源和执行特权指令。这一转换是必要的,因为处理异常需要更高的权限。在处理例外之前,CPU会保存一些关键信息到指定的控制寄存器中,包括:
- 例外原因:指明是什么原因导致了例外的发生(例如,非法操作、访问违规等)。
- 程序计数器(Program Counter,简称PC):保存发生例外时的程序计数器值。程序计数器指向下一条将要执行的指令,保存这个值是为了在处理完例外后能够恢复到正确的位置继续执行。
然后,CPU会将程序计数器的值置为相应的例外处理入口地址。这个地址是特定于体系结构的,指向处理该类型例外的代码位置。在LoongArch架构中,例外的入口地址计算规则可以在其体系结构手册中找到。这个入口地址通常是一个预定义的地址,指向处理例外的例程。
最后,CPU会开始从新的程序计数器地址取指,执行例外处理程序。这个处理程序会根据保存的例外原因进行相应的处理,比如记录错误、恢复状态或执行其他必要的操作。
当计算机遇到问题时,它会跳转到一个特定的地方来处理这个问题,这个地方叫做“异常处理器”。在这里,操作系统会首先保存当前的状态,就像把正在进行的工作记录下来,以便稍后继续。这个状态包括了处理器的寄存器内容等重要信息。
接下来,操作系统会查看发生了什么问题。它会从CPU的控制寄存器中读取异常的原因。如果发现是外部中断,比如说有人按下了空格键,操作系统就会去南桥的中断控制器那里确认具体的中断原因,并在读取的同时清除南桥的中断标志。最后,操作系统会发现,原来是因为有人敲了空格键导致了这个中断。
简单来说,这个过程就像是计算机在忙碌的时候被打断了,它需要先记录下当前的工作,然后找出打断它的原因,最后再决定如何继续工作。
接下来,操作系统需要确定刚刚读取到的空格键输入是要发送给哪个进程。它会检查是否有进程处于阻塞状态,等待键盘输入。大家都知道,进程通常有三种状态:运行态、阻塞态和睡眠态。当进程在等待输入/输出(IO)时,它会处于阻塞态。操作系统发现有一个名为WPS的进程正处于阻塞状态,而这个进程是可以响应空格键的。因此,操作系统决定唤醒WPS进程。一旦WPS被唤醒,它就进入了运行状态。此时,它发现操作系统传来的数据是一个空格键输入,这意味着用户想要翻页。于是,WPS开始准备下一页要显示的内容。它调用操作系统中的显示驱动程序,将要显示的内容发送到显存中。
接下来,图形处理器(GPU)会访问显存,刷新屏幕,最终实现翻页的效果。这样,用户就能看到新的内容了。整个过程就像是计算机在接收到用户的指令后,迅速而有序地完成了一项任务。如果在翻页过程中发现计算机的性能很低,翻页非常卡顿,可能有几个原因。首先,我们需要检查系统中是否有其他任务在运行。如果有很多任务同时进行,它们会占用CPU、内存带宽和输入/输出(IO)带宽等资源,这样WPS进程就得不到足够的资源,从而导致卡顿。如果系统中没有其他应用程序与WPS争夺资源,但翻页依然卡顿,那可能是什么原因呢?很多人可能会认为是CPU性能太低,需要升级。实际上,在WPS翻页时,CPU的工作量并不大。
一种可能性是,下一页的内容包含了大量的图形,尤其是矢量图,这些图形需要由图形处理器(GPU)来绘制。如果GPU的负担过重,就会导致翻页卡顿。另一种可能是要显示的数据量很大,WPS需要将大量数据从应用程序的内存空间传输到GPU专用的显存中。如果内存带宽不足,就会导致数据传输不及时,从而影响性能。在使用独立显存的情况下,数据从内存传输到显存有两种不同的方式:一种是由CPU从内存读取数据,然后再写入显存。这种方式需要CPU具备专门的IO加速功能,因为显存通常映射在CPU的IO空间。另一种方式是通过直接内存访问(Direct Memory Access,简称DMA),这种方式可以直接将数据从内存传输到显存,速度会快得多。
总结来说,翻页卡顿的原因可能是资源竞争、GPU负担过重,或者内存带宽不足等问题,而不仅仅是CPU性能的问题。
想象一下,“计算机体系结构”这门课程就像是一门建筑课,教你如何设计和建造一座大楼,而不是教你如何在大楼里生活。学习这门课,就像是成为一名建筑师,而不是一名住户。在这个过程中,计算机体系结构设计师就像是一位建筑师,负责规划和设计大楼的每一个细节。他们需要掌握很多知识,就像建筑师需要了解建筑材料、结构安全和环境影响一样。如果建筑师只会在图纸上画画,而不懂实际的建筑技术,那他们的设计可能会出现问题,甚至导致大楼倒塌。对于计算机体系结构设计来说,“规划设计”就是设计计算机的结构;“了解环境”意味着要知道应用程序、操作系统和编译器是如何工作的;而“掌握材料”则是要明白逻辑电路和制造工艺的特点。总之,设计计算机体系结构时,不能只关注某一个方面,而是要把应用、系统、结构、逻辑、电路和器件的知识结合起来,形成一个完整的设计方案。就像一位成功的建筑师所说的:“我的设计理念是整体协调”,所有的知识都要紧密相连,才能建造出一座坚固而美观的大楼。
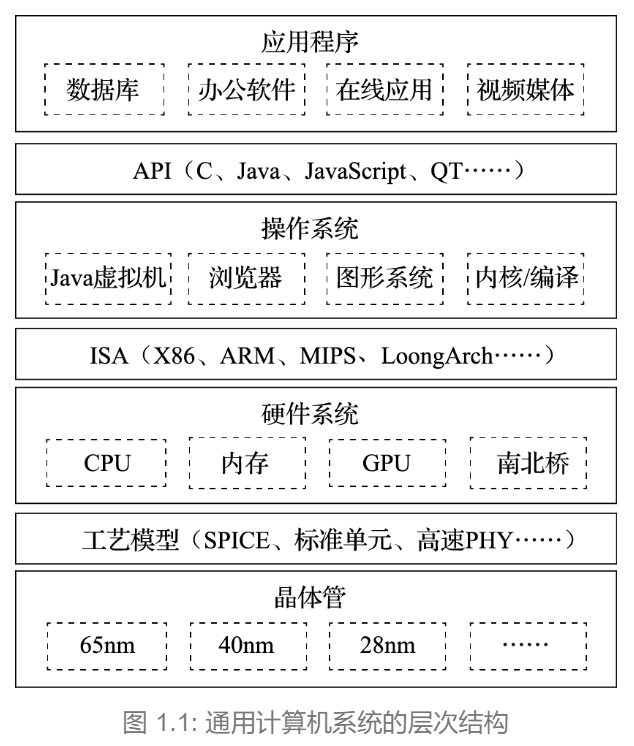
想象一下,计算机就像是一座复杂的城市,里面有不同的区域和功能。图1.1展示了这座城市的结构层次图,把计算机系统分成了四个主要的层次:应用程序、操作系统、硬件系统和晶体管。每个层次都有自己的角色,就像城市中的不同区域一样,具体情况如下所示。
-
应用程序:这是城市中的商店和娱乐场所,用户在这里进行各种活动,比如玩游戏、上网、写文档等。应用程序是我们直接使用的工具。
-
操作系统:可以把操作系统想象成城市的管理者,负责协调和管理所有的商店和娱乐场所。它确保每个应用程序能够顺利运行,并且与硬件进行沟通。
-
硬件系统:这是城市的基础设施,包括道路、建筑和电力系统等。硬件系统是计算机的物理部分,负责执行操作系统和应用程序的指令。
-
晶体管:这些就像是城市中的小工人,负责完成具体的任务。晶体管是构成硬件的基本单元,负责处理数据和执行指令。
在这四个层次之间,有三个重要的“界面”,它们帮助不同层次之间进行沟通。
-
应用程序编程接口(Application Programming Interface,API):想象API是商店和管理者之间的沟通桥梁。它就像是商店的营业手册,告诉商店如何与管理者(操作系统)互动。常见的API包括C语言、Java和JavaScript等。通过API编写的应用程序可以在不同的计算机上运行,就像商店可以在不同的城市开分店一样。API的好坏直接影响到应用程序的数量和质量,因此在IT行业中,谁控制了API,谁就能影响整个生态系统。
-
指令系统(Instruction Set Architecture,ISA):这是操作系统和硬件之间的另一座桥梁。指令系统就像是城市的交通规则,确保所有的车辆(指令)能够顺利通过。常见的指令系统有X86、ARM和RISC-V等。它们定义了计算机如何执行基本操作,比如加减乘除,以及如何管理内存和处理器的状态。指令系统是软件兼容的关键,确保不同的软件能够在同样的硬件上运行。
-
工艺模型:这是硬件系统和晶体管之间的接口。工艺模型就像是建筑蓝图,告诉芯片设计师如何制造晶体管和连接它们。它不仅包括晶体管的基本参数,还提供了各种功能模块(IP),比如实现高速数据传输的接口(如PCIE)。这些模块帮助设计师更高效地构建硬件。
在我们刚才讨论的计算机系统中,除了应用程序编程接口(API)和指令系统(ISA)之间的联系,还有一个非常重要的层次,叫做应用程序二进制接口(Application Binary Interface,ABI)。可以把ABI想象成一个专门的通道,帮助应用程序与计算机的硬件和操作系统进行沟通。ABI就像是一个翻译官,负责将应用程序的请求转换成计算机能够理解的语言。它由两部分组成:用户态指令和操作系统的系统调用。这里的“用户态”可以理解为普通市民的生活状态,而“核心态”则是城市的管理者或警察,负责维护城市的安全和秩序。
用户态:这是普通应用程序运行的状态,就像市民在日常生活中自由活动。用户程序在这个状态下执行,进行一些基本的操作,比如打开文件、显示信息等。
核心态:这是计算机的核心部分,只有经过特别授权的程序才能进入这个状态。就像警察在执行任务时,能够进入特定区域,处理一些重要的事情。核心态可以访问计算机的硬件资源,比如输入输出设备(IO设备)和修改处理器的状态。
当用户程序需要访问一些只有核心态才能使用的资源时,它会通过系统调用来请求帮助。这个过程就像市民向警察求助:
- 用户程序发出请求,调用系统调用函数。
- 处理器会切换到核心态,执行一些特殊的指令,比如访问硬件设备或修改系统状态。
- 完成任务后,处理器再返回到用户态,继续执行用户程序的代码。
最重要的是,相同的应用程序二进制代码可以在不同的计算机上运行,只要它们使用相同的ABI。这就像是一个城市的市民,无论在哪个城市,只要遵循相同的法律和规则,就能顺利生活。
学习计算机体系结构就像是学习如何设计和建造一座复杂的建筑。想象一下,图1.1就像是这座建筑的蓝图,帮助我们理解计算机的各个组成部分。计算机体系结构的研究内容主要包括三个方面:指令系统结构、硬件系统结构和CPU内部的微结构。要做好这些设计,就必须对应用程序和操作系统有深入的了解,同时也要懂得晶体管的基本行为。就像一位建筑师,如果不懂建筑材料和结构原理,就无法设计出安全和美观的建筑。首先,指令系统就像是从建筑设计中提取出来的“功能需求”。想象你是一位建筑师,准备设计一座大楼。你需要了解这座大楼的用途(应用程序),才能决定哪些功能(指令)需要直接在建筑中实现,哪些功能可以通过后期的装修和设施(软件)来完成。比如,如果这座大楼是办公楼,你可能需要设计电梯、会议室等功能,而这些功能的实现就需要相应的指令系统。接下来,硬件系统和CPU的微结构就像是建筑的结构和材料选择。为了确保建筑的安全和美观,建筑师需要根据建筑的用途进行优化设计。例如,如果这座建筑是一个博物馆,可能需要特别设计的展览空间和照明系统,以提升观众的体验。CPU的高速缓存就像是建筑中的储物间,存放常用的工具和材料,确保工人在需要时能够快速获取。此外,CPU还使用转移猜测算法,就像建筑师在设计时预测未来的使用需求,确保建筑能够灵活应对不同的使用场景。设计CPU的内存带宽时,就像考虑建筑的供水和电力系统,既要满足建筑内部的需求,也要考虑外部的供给。然后,指令系统和CPU微结构的设计还需要充分考虑操作系统的管理需求。想象一下,操作系统就像是建筑的物业管理,负责协调建筑内的各种活动。为了确保每个租户都能顺利使用设施,物业管理需要制定相应的管理规则。这就需要CPU实现TLB(Translation Lookaside Buffer),就像是物业管理的记录系统,帮助管理人员快速找到每个租户的需求。此外,CPU还需要实现多组通用寄存器的快速切换机制,以加速多线程的切换。这就像建筑内有多个租户同时使用不同的设施,能够快速切换使用权,确保每个租户都能及时满足需求。最后,计算机中的主要硬件组件,如CPU、GPU、南北桥和内存,都是通过晶体管来实现的。了解晶体管的行为就像了解建筑材料的特性,能够帮助我们在设计阶段评估建筑的安全性、成本和耐用性。例如,高速缓存的容量就像是建筑的储物空间,影响到你能存放多少设备,而多发射结构的发射电路则决定了建筑的承重能力。在微结构设计时,我们需要在这些因素之间进行权衡和取舍。
1.1.2 什么是计算机
什么是计算机?大多数人认为计算机就是我们桌面的电脑,实际上计算机已经深入到我们信息化生活的方方面面。除了大家熟知的个人电脑、服务器和工作站等通用计算机外,像手机、数码相机、数字电视、游戏机、打印机、路由器等设备的核心部件都是计算机,都是计算机体系结构研究的范围。也许此刻你的身上就有好几台计算机。计算机的另外一个极端应用就是手机,手机也是计算机的一种。现在的手机里至少有一个CPU,有的甚至有几个。希望大家建立一个概念,计算机不光是桌面上摆的个人计算机,它可以大到一个厅都放不下,需要专门为它建一个电站来供电,也可以小到揣在我们的兜里,充电两个小时就能用一整天。不管这个计算机的规模有多大,都是计算机体系结构的研究对象。计算机是为了满足人们各种不同的计算需求设计的自动化计算设备。随着人类科技的进步和新需求的提出,最快的计算机会越来越大,最小的计算机会越来越小。
1.1.3 计算机的基本组成
从小我们就学习十进制的运算,使用0到9这十个数字,逢十进一。比如,当我们数到10时,就会进位到下一个数字。而计算机则使用二进制,只有0和1两个数字,逢二进一。你可能会问,为什么计算机要用二进制,而不是我们熟悉的十进制呢?答案很简单:二进制最容易实现。在自然界中,有很多现象可以用二值系统来表示,比如电压的高低(高电压代表1,低电压代表0)、水位的高低(满水代表1,空水代表0)、门的开关(开门代表1,关门代表0)以及电流的有无(有电流代表1,没电流代表0)。这些都可以用来构建计算机的基础。二进制的概念最早是由德国哲学家莱布尼茨发明的,而著名的计算机科学家冯·诺依曼则是最早将二进制应用于计算机的。他的工作奠定了现代计算机的基础,计算机中的程序和数据都是用二进制表示的。实际上,从某种意义上说,中国古人的八卦也是一种二进制,因为它通过阴阳两种状态来表达事物的变化。
虽然计算机的组成非常复杂,但它的基本单元却非常简单。想象一下,当你打开一台PC的机箱时,你会看到电路板上有许多芯片。每个芯片就像一个小型的系统,里面包含了很多模块,比如加法器和乘法器等。这些模块又由许多逻辑门组成,比如与门、或门和非门等。而这些逻辑门则是由晶体管构成的,像PMOS管和NMOS管等。可以把计算机想象成一座宏伟的建筑。无论这座建筑多么高大,最终都是由基本的砖瓦、钢筋和水泥等材料搭建而成。计算机也是如此,它是一个复杂的系统,由许多可以存储和处理二进制运算的基本元件组成。在CPU芯片内部,细小的导线可以并排放下上千根,想象一下,一根头发的宽度就能容纳这么多导线。而且,用一粒大米的钱,你就可以购买上千个晶体管!这说明了计算机内部的微小和复杂。
计算机结构的基本思想是由匈牙利数学家冯·诺依曼在1945年提出的,这种结构被称为冯·诺依曼结构。它为现代计算机的设计奠定了基础。为了更好地理解冯·诺依曼结构,我们可以通过一个简单的例子来说明。假设我们要计算表达式(3×4 + 5×7)的值。
人类是如何进行这个计算的呢?首先,我们计算3×4,得到12。我们把这个结果记在脑子里。接着,我们计算5×7,得到35。然后,我们再把这两个结果相加,12 + 35,最终得到47。在这个过程中,我们的计算和记忆都是在同一个脑袋里进行的(当然,如果式子很长,我们可能需要把临时结果写在纸上)。与人类不同,计算机的计算和记忆是分开的。计算机的计算部分由运算器和控制器组成,这个组合被称为中央处理器(CPU);而负责记忆的部分则称为存储器。
存储器的内容:
- 数据:这包括我们要计算的数字,比如3、4、5、7,以及计算过程中的临时结果12、35和最终结果47。
- 指令:这些是告诉计算机如何进行计算的步骤,也就是程序。
换句话说,计算机把操作对象(数据)和操作序列(指令)都保存在存储器里。
现在,让我们看看计算机在逻辑上是如何完成(3×4 + 5×7)这个计算的:
- 计算机首先把数字3、4、5、7存储在内存中。
- 在计算过程中,临时结果(12、35)和最终结果(47)也会存储在内存中。
- 此外,计算机还会把描述计算过程的程序存储在内存中,这个程序由许多指令组成。
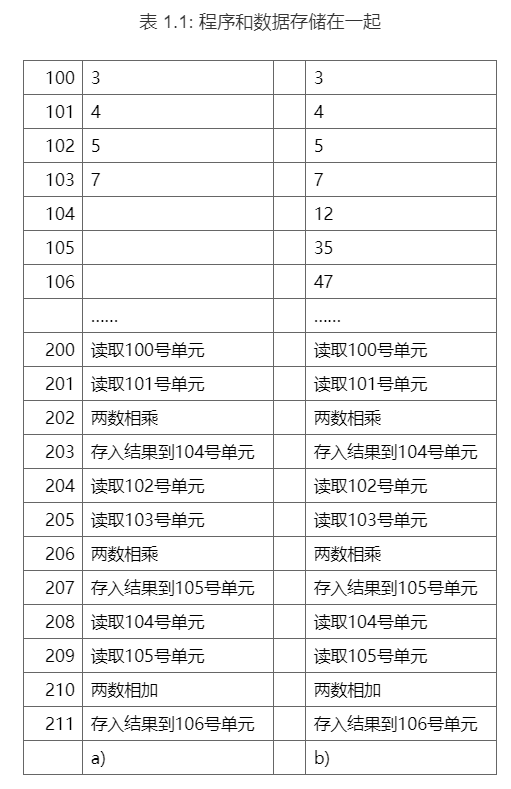
假设数据存储在内存的100号单元开始的区域,而程序则存储在200号单元开始的区域。让我们来看看计算机是如何进行运算的。假设我们要计算表达式(3×4 + 5×7),计算机的具体执行过程是这样的:
-
取指令:首先,CPU从内存的200号单元取回第一条指令,这条指令是“读取100号单元”。根据这条指令,CPU从内存中读取数字“3”。
-
继续取指令:接着,CPU从201号单元取下一条指令“读取101号单元”,然后从内存中读取数字“4”。
-
执行运算:然后,CPU从202号单元取出指令“两数相乘”,计算出结果为“12”。
-
存储结果:最后,CPU从203号单元取出指令“存入结果到104号单元”,把结果“12”存入104号单元。
这个过程会不断重复,直到程序结束。表1.1b展示了程序执行结束时内存中的内容。大家可以看到,这个过程比我们大脑运算要复杂得多。我们在脑海中只需三步就能完成计算,而计算机却需要这么多步骤来取指令和数据,确实显得有些麻烦。这就是冯·诺依曼结构的基本思想:数据和程序都存储在内存中,CPU从内存中取出指令和数据进行运算,并把结果也放回内存。将指令和数据都存放在内存中,使得计算机能够按照预先设定的程序自动完成运算。这是一种实现图灵机的简单方法。冯·诺依曼结构很好地解决了自动化的问题:程序被放在内存中,计算机可以一条条地取出指令,自己完成计算,而不需要人来干预。如果没有这种自动执行的机制,计算机就像算盘一样,需要人手动控制每一步。想象一下,如果程序没有保存在内存中,而是保存在人脑中,那就变得非常不方便了。尽管计算机技术在不断发展,70多年过去了,冯·诺依曼结构依然是现代计算机的主流结构。虽然它有一些缺点,比如将所有数据和指令都保存在内存中会导致访问速度成为性能瓶颈,但我们仍然无法摆脱它。
冯·诺依曼结构的核心思想就是:数据和程序都存储在内存中,CPU从内存中取出指令和数据进行运算,并将结果也放回内存。简单来说,就是存储程序和指令驱动执行。
衡量计算机的指标
在了解了计算机的基本组成部分之后,我们自然会想,那如何来衡量一台计算机的好坏呢?计算机的衡量指标有很多,其中性能、价格和功耗是三个主要指标。
1.2.1 计算机的性能
在计算机的世界里,第一个也是最重要的指标就是性能。那么,性能到底是什么呢?简单来说,性能的本质定义就是“完成一个任务所需要的时间”。对于中央气象台的台长来说,性能就是计算明天的天气预报需要多长时间。举个例子,如果计算机甲需要两个小时才能完成24小时的天气预报,而计算机乙只需要一个小时就能完成,那么显然,计算机乙的性能要比计算机甲好得多。
T = I × C × P T = I \times C \times P T=I×C×P
其中:
- T 表示完成一个任务所需的时间。
- I 表示完成任务需要的指令数,这与所使用的算法、编译器和指令的功能有关。
- C 表示每条指令需要的拍数,这与编译器、指令功能和微结构设计相关。
- P 表示每拍需要的时间,也就是时钟周期,这与计算机的结构、电路设计和制造工艺等因素有关。
完成一个任务所需的指令数首先取决于算法。在20世纪六七十年代,美国的计算机每秒可以进行一亿次计算,而苏联的计算机每秒只能进行一百万次计算。然而,当两台计算机计算同一个问题时,苏联的计算机却先算完了。这是因为苏联使用了更优秀的算法。以对N个数进行排序为例,冒泡排序算法的运算复杂度是 O(N^2),而快速排序算法的运算复杂度是 O(N * log2(N))。如果我们设定 N = 1024,那么这两种算法在执行指令数上就会相差100倍!这说明选择合适的算法是多么重要。
接下来,我们来谈谈编译器。编译器的工作是将用户用高级语言(比如C、Java、JavaScript等)编写的代码转换成计算机能够理解的二进制指令。编译器生成的目标代码质量直接影响完成任务所需的指令数。在同一台计算机上运行同一个应用程序,如果使用不同的编译器或不同的编译选项,运行时间可能会有几倍的差距。
指令系统的设计也会显著影响完成任务的指令数。例如,我们可以选择设计一条指令来直接完成快速傅里叶变换(FFT),或者让用户通过软件来实现这个功能。这种设计选择直接影响到完成任务所需的指令数。在计算机体系结构中,有一个常用的指标叫做MIPS(每秒百万条指令),它表示计算机每秒能执行多少百万条指令。虽然这个指标看起来很合理,但关键在于一条指令能完成多少工作。如果计算机A的一条指令就能完成一个1024点的FFT,而计算机B的一条指令只能进行一个加法运算,那么比较它们的MIPS值就没有意义了。因此,有人把MIPS戏称为“Meaningless Indication of Processor Speed”(毫无意义的处理器速度指示)。现在,我们更常用的性能指标是MFLOPS(每秒百万浮点运算),它表示计算机每秒能进行多少百万次浮点运算。但这个指标也有类似的问题:如果数据供不上,再强的运算能力也没有用。在确定了指令系统后,结构设计需要重点考虑如何降低每条指令的平均执行周期(Cycles Per Instruction,简称CPI),或者提高每个时钟周期平均执行的指令数(Instructions Per Cycle,简称IPC)。这正是处理器微结构研究的主要内容。
- CPI 是一个程序执行所需的总时钟周期数除以它所执行的总指令数。
- IPC 则是反过来的计算。
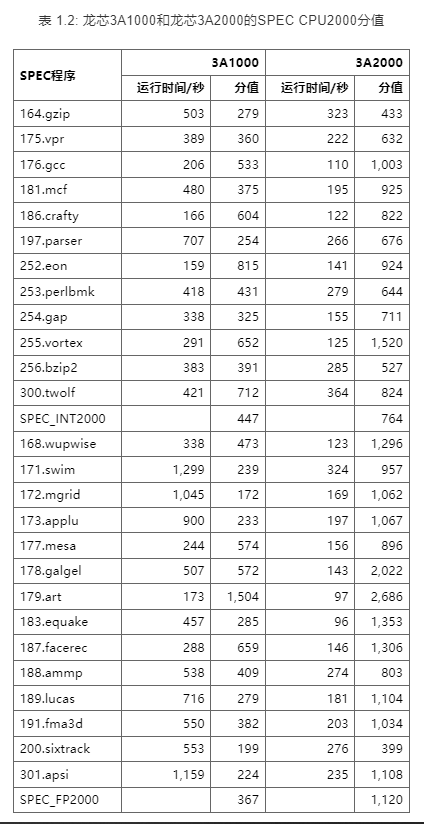
处理器的微结构设计对IPC的影响非常大,比如采用单发射还是多发射结构、使用何种转移猜测策略以及设计什么样的存储层次,都会直接影响IPC的值。举个例子,表1.2展示了龙芯3A1000和龙芯3A2000处理器在运行SPEC CPU2000基准程序时的分值。虽然这两个CPU都是64位四发射结构,主频均为1GHz,并且运行相同的二进制代码,但由于微结构的不同,它们的IPC差异很大。总体来说,3A2000的IPC是3A1000的2到3倍,这说明微结构设计对性能的影响是多么显著。
在计算机的世界里,主频是一个非常重要的指标,它决定了计算机的运算速度。主频的高低,宏观上取决于微结构设计,而微观上又与工艺和电路设计密切相关。举个例子,Pentium III处理器的流水线有10级,而Pentium IV为了提高主频,猛然将流水线增加到了20级,甚至想要做到40级!这就像是在高速公路上增加车道,理论上可以让更多的车同时行驶,从而提高整体的通行能力。Intel的研究发现,如果我们把Cache(缓存)和转移猜测表的容量增加一倍,就能抵消流水线增加一倍所导致的效率降低。这就像是增加了更多的停车位,虽然车道变多了,但如果停车位不够,车流也会受到影响。从电路的角度来看,假设甲设计的64位加法器只需要1纳秒(ns),而乙设计的加法器需要2纳秒,那么甲的设计主频就比乙高一倍。这说明,电路设计的效率直接影响到主频的高低。同样,相同的电路设计,如果采用不同的工艺,主频也会有所不同。比如,使用先进工艺制造的晶体管速度更快,因此主频也会更高。
流水线(Pipelining)是一种提高计算机处理器性能的技术,它通过将指令的执行过程分解为多个阶段,使得多个指令可以同时在不同的阶段进行处理。可以把流水线想象成一个生产线,每个工人负责生产过程中的一个特定步骤。在流水线中,级(Stage)是指指令执行过程中的每一个独立阶段。每个级代表了流水线中的一个处理步骤。在计算机中,指令的执行通常可以分为五级,例如:
- 取指令(Fetch):从内存中获取指令。
- 译码(Decode):解析指令,确定要执行的操作和操作数。
- 执行(Execute):执行指令所指定的操作。
- 访存(Memory Access):如果指令需要访问内存,进行读写操作。
- 写回(Write Back):将结果写回寄存器或内存。
通过将这些阶段分开,流水线允许在一个时钟周期内同时处理多个指令。例如,当第一条指令在执行阶段时,第二条指令可以在译码阶段,第三条指令可以在取指令阶段。这样,处理器的整体吞吐量就得到了显著提高。流水线的级数并不是越多越好。设计者需要在级数、性能、复杂性和延迟之间找到一个平衡点。理想的流水线设计应该根据具体的应用需求和目标性能来决定级数,以实现最佳的性能和效率。
通过这些例子,我们可以看到,在一个系统中,不同层次有不同的性能标准。因此,很难用单一的指标来全面刻画计算机性能的高低。大家可能会说,从应用的角度来看,性能是最合理的衡量标准。比如,计算机甲需要两个小时才能完成明天的天气预报,而计算机乙只需要一个小时。那么,乙的性能肯定比甲好,对吧?这看似没错,但实际上,这种说法也有其局限性。我们只能说,针对“计算明天的天气预报”这个特定应用,乙计算机的性能确实比甲的好。然而,对于其他应用,甲的性能可能反而比乙的好。比如在某些特定的计算任务中,甲可能使用了更高效的算法或设计,导致它在这些任务上表现更佳。
1.2.2 计算机价格
三个字讲完,性价比
计算机的功耗
在计算机的世界里,功耗是一个非常重要的指标,尤其是在移动设备如手机中,因为它们需要依靠电池供电。为了让电池使用得更久,降低功耗就显得尤为重要。即使是高性能计算机,也需要关注功耗,它们的功耗通常以**兆瓦(MW)**来计量。那么,兆瓦到底是什么概念呢?想象一下,我们在大学宿舍里用的电热棒,功率大约是1000瓦(W)。如果几个电热棒同时使用,宿舍就可能会停电。1兆瓦等于1000个电热棒的功率!这意味着,如果一台高性能计算机的功耗达到1兆瓦,它的电力消耗就相当于1000个电热棒同时在工作。举个例子,曙光5000高性能计算机在中科院计算所的地下室组装调试时,运行一天的电费就超过了一万块钱,甚至比整栋楼的电费还要高。这让我们意识到,计算机的功耗是多么庞大。
计算机内部产生功耗的地方非常多。比如:
- CPU(中央处理器)会消耗电力。
- 内存条也需要电力来存储数据。
- 硬盘在读写数据时也会消耗电力。
- 最后,为了将这些产生的热量散发出去,制冷系统也需要消耗电力。
因此,近年来,性能功耗比(Performance per Watt)成为了评估计算机性能的重要指标。这个指标帮助我们理解在消耗一定电力的情况下,计算机能完成多少工作。
在计算机功耗中,芯片功耗是一个重要的组成部分。芯片的功耗主要是由晶体管的工作产生的。让我们先来看看晶体管的功耗组成。
以反相器为例,它由一个PMOS管和一个NMOS管组成。反相器的功耗主要可以分为三类:
-
开关功耗:这是由于电容的充放电造成的。当输出端从0变为1时,负载电容需要充电;当输出端从1变为0时,电容又需要放电。在这个充电和放电的过程中,就会产生功耗。开关功耗与充放电的电压、电容值以及反相器的开关频率都有关系。
-
短路功耗:这是在开关过程中,电流短暂地流过PMOS和NMOS管时产生的功耗。
-
漏电功耗:即使在静止状态下,晶体管也可能会有少量电流流过,这种功耗称为漏电功耗。
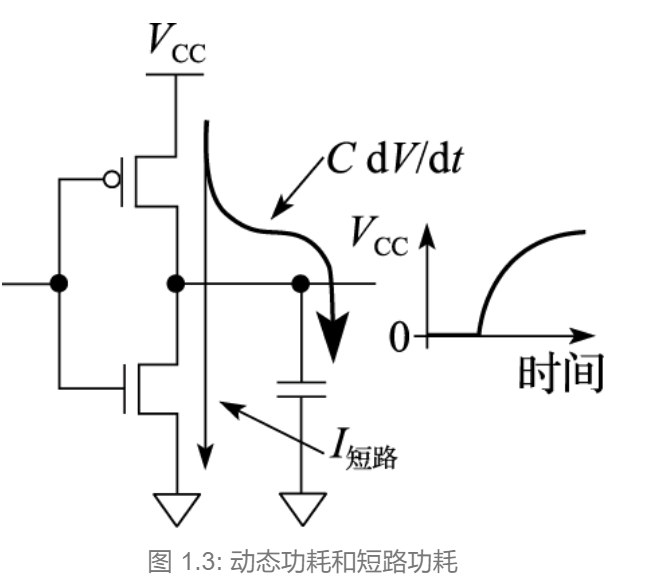
在计算机中,功耗是一个非常重要的概念,尤其是在芯片设计中。我们来看看芯片功耗的三种主要类型:短路功耗、漏电功耗和动态功耗。
短路功耗是指在反相器的工作过程中,当P管(PMOS管)和N管(NMOS管)同时部分导通时产生的功耗。想象一下,当反相器的输出为1时,P管打开,N管关闭;而当输出为0时,N管打开,P管关闭。在这个开关的过程中,电流的变化并不是瞬间的,而是有一个渐变的过程。这意味着在某些时刻,P管和N管可能会同时部分打开,导致电流短路,从而产生短路功耗。
接下来是漏电功耗。这是指当MOS管不能完全关闭时,仍然会有电流流过,造成的功耗。以NMOS管为例,当栅极有电时,N管导通;如果栅极没有电,N管应该关闭。然而,在纳米级工艺下,MOS管的沟道非常窄,即使栅极不加电压,源极和漏极之间仍然会有电流流动。此外,栅极下的绝缘层非常薄,只有几个原子的厚度,这也会导致漏电流的产生。漏电流的大小会随着温度的升高而指数增加,因此温度被认为是集成电路的“第一杀手”。
为了降低芯片的功耗,设计师通常会从两个方面入手:动态功耗优化和静态功耗优化。
-
动态功耗优化:通过升级工艺来降低动态功耗是一个有效的方法。工艺升级可以减少电容和电压,从而显著降低动态功耗。芯片的工作频率与电压成正比,因此在一定范围内(例如5%到10%)降低频率可以相应降低电压。举个例子,如果频率降低10%,动态功耗可以降低约30%(因为功耗与电压的平方成正比)。
-
静态功耗优化:选择低功耗工艺可以有效降低静态功耗。集成电路生产厂家通常会提供高性能工艺和低功耗工艺。低功耗工艺的速度稍慢,但漏电功耗可以降低几个数量级。在设计时,避免不必要的逻辑翻转也能有效降低功耗。例如,在某一流水级没有有效工作时,保持该流水级的状态不翻转。
在物理设计中,可以通过门控时钟来降低时钟树的翻转功耗。在电路设计中,采用低摆幅电路也能降低功耗。例如,当工作电压为1V时,可以用0.4V表示逻辑0,用0.6V表示逻辑1,这样摆幅只有0.2V,从而大大降低了动态功耗。芯片的功耗是一个全局量,涉及到每一个设计阶段。功耗优化的层次包括系统级、算法级、逻辑级、电路级,直到版图和工艺级。这是一个全系统的工程。近年来,降低功耗的研究越来越多,设计师们已经意识到,降低功耗已成为芯片设计中最重要的任务之一。信息产业是一个高能耗的行业,信息设备的耗电量逐年增加。根据冯·诺依曼的公式,现在每翻转一个比特所耗的电能是理论值的10^10倍以上。整个信息运算过程是一个从无序到有序的过程,这个过程中熵变小,吸收能量。但实际上,所需的能量并不多,因为我们目前的运算手段还不够先进,造成了如此高的能耗。因此,我们还有很大的优化空间,这需要在材料和设计上进行革命性的创新。
除了功耗,计算机的设计还需要考虑其他指标,例如使用寿命、安全性和可靠性。以可靠性为例,计算机中的CPU可以分为商用级、工业级、军品级和宇航级等。例如,北斗卫星上的计算机,虽然价格贵一点、速度慢一点也没关系,但最重要的是要可靠。因为在特定领域,可靠性要求非常高。再比如,银行的核心业务计算机也非常重视可靠性,只要一年死机一次,价格贵一千万元也没关系,因为一旦核心计算机死机,所有储户就无法取钱,损失将是巨大的。
1.3 计算机体系结构的发展
只需要了解摩尔定律。
摩尔定律(Moore’s Law)是由英特尔公司的创始人之一戈登·摩尔(Gordon Moore)在1965年提出的一个观察和预测。摩尔定律主要描述了集成电路上可容纳的晶体管数量随着时间的推移而呈指数增长的趋势。具体来说,摩尔在其论文中指出,集成电路上的晶体管数量大约每两年就会翻一番,这意味着计算机的性能将以相似的速度提高,同时成本也会降低。
尽管摩尔定律在过去几十年中得到了广泛的验证,但随着技术的进步,许多专家开始担心摩尔定律可能会面临一些挑战:
-
物理极限:随着晶体管尺寸的不断缩小,接近物理极限,制造更小的晶体管变得越来越困难,可能会导致成本上升。
-
热管理问题:晶体管数量的增加会导致芯片发热量增加,如何有效管理热量成为一个重要挑战。
-
经济因素:随着制造工艺的复杂性增加,研发和生产新一代芯片的成本也在上升,这可能影响到摩尔定律的持续性。
摩尔定律的终结仅仅指的是晶体管尺寸难以进一步缩小,并不是硅平台的终结。
1.4 体系结构设计的基本原则
没必要了解,不可能做设计