贝叶斯定理
1. 背景与引入
历史与地位
贝叶斯定理(Bayes’ Theorem)由18世纪英国数学家托马斯·贝叶斯(Thomas Bayes)提出,后经拉普拉斯等人完善,是概率论中的核心工具之一。它解决了如何基于新证据动态修正概率估计的问题,为从经典统计学向贝叶斯统计学的范式转变奠定了基础。在机器学习中,贝叶斯方法被广泛应用于分类、推荐系统、概率图模型等领域,例如垃圾邮件过滤(通过关键词出现的概率推断邮件是否为垃圾邮件)、医学诊断(根据检测结果更新患病概率)等。
实际问题:垃圾邮件识别的直觉类比
假设你设计了一个垃圾邮件过滤器,已知以下数据:
- 任意一封邮件是垃圾邮件的概率为 10%(先验概率)。
- 若一封邮件是垃圾邮件,包含“免费”一词的概率为 60%;若不是垃圾邮件,包含“免费”的概率为 15%。
问题:当某封邮件包含“免费”时,它是垃圾邮件的概率是多少?
这个问题无法直接通过原始概率回答,但贝叶斯定理能结合先验知识与新证据(关键词“免费”),动态计算出后验概率(更新后的垃圾邮件概率),这正是贝叶斯的核心思想。
学习目标
学完本节后,你将能够:
- 理解贝叶斯定理的数学形式及其各部分含义(先验概率、似然、证据、后验概率)。
- 用贝叶斯定理解决实际问题,如医学检测准确性分析、垃圾邮件分类等。
- 掌握贝叶斯思维——如何在不确定条件下,通过新证据不断修正对事件的认知。
(注:本节仅聚焦背景与核心问题,公式推导与应用细节将在后续章节展开。)
2. 核心概念与定义
定义
贝叶斯定理(Bayes’ Theorem)是计算条件概率的数学工具,用于在已知新证据的条件下,修正事件发生的概率估计。其数学形式为:
P ( A ∣ B ) = P ( B ∣ A ) ⋅ P ( A ) P ( B ) P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)⋅P(A)
其中:
- P ( A ∣ B ) P(A|B) P(A∣B):后验概率(Posterior Probability),在观察到事件B后,事件A发生的概率。
- P ( B ∣ A ) P(B|A) P(B∣A):似然(Likelihood),在事件A发生的条件下,观察到事件B的概率。
- P ( A ) P(A) P(A):先验概率(Prior Probability),事件A发生的初始概率(未考虑B的证据)。
- P ( B ) P(B) P(B):证据(Evidence),所有可能情况下观察到事件B的总概率(常作为归一化因子)。
核心思想
贝叶斯定理的本质是利用新证据动态更新概率。
- 先验概率代表已有的知识或经验(如疾病的基础发病率)。
- 似然反映新证据(如医学检测结果)与事件之间的关联强度。
- 后验概率是结合先验与证据后,对事件概率的修正结果。
通俗类比:
想象你是一名侦探,调查一桩案件:
- 先验概率:根据历史数据,凶手是男性的概率为70%(已有经验)。
- 新证据:现场发现了一枚女性指纹(事件B)。
- 似然:若凶手是女性,留下指纹的概率更高。
- 后验概率:结合指纹证据,凶手是男性的概率会被大幅降低(更新后的判断)。
简单例子:医学检测的准确性
假设一种疾病的患病率为1%( P ( D ) = 0.01 P(D)=0.01 P(D)=0.01),检测的灵敏度(真阳性率)为95%( P ( T + ∣ D ) = 0.95 P(T^+|D)=0.95 P(T+∣D)=0.95),假阳性率为5%( P ( T + ∣ ¬ D ) = 0.05 P(T^+|\neg D)=0.05 P(T+∣¬D)=0.05)。
问题:若某人检测结果为阳性(T⁺),他实际患病的概率是多少?
贝叶斯计算:
- 先验 P ( D ) = 0.01 P(D)=0.01 P(D)=0.01,似然 P ( T + ∣ D ) = 0.95 P(T^+|D)=0.95 P(T+∣D)=0.95。
- 证据 P ( T + ) = P ( T + ∣ D ) P ( D ) + P ( T + ∣ ¬ D ) P ( ¬ D ) = 0.95 × 0.01 + 0.05 × 0.99 ≈ 0.059 P(T^+) = P(T^+|D)P(D) + P(T^+|\neg D)P(\neg D) = 0.95×0.01 + 0.05×0.99 ≈ 0.059 P(T+)=P(T+∣D)P(D)+P(T+∣¬D)P(¬D)=0.95×0.01+0.05×0.99≈0.059。
- 后验 P ( D ∣ T + ) = 0.95 × 0.01 0.059 ≈ 0.161 P(D|T^+) = \frac{0.95×0.01}{0.059} ≈ 0.161 P(D∣T+)=0.0590.95×0.01≈0.161。
结论:即使检测阳性,实际患病的概率仅约16.1%。这揭示了先验概率对结果的强烈影响,也体现了贝叶斯定理对直觉的修正作用。
直观形象:概率的“动态天平”
贝叶斯定理可视为一个天平:
- 左侧托盘是先验概率(已有信念)。
- 右侧托盘是似然(新证据的支持程度)。
- 支撑天平的基座是证据(所有可能性的归一化)。
当新证据(如阳性检测结果)加入时,天平会从先验向后验倾斜,体现概率的动态更新过程。
(注:本节聚焦定义与直观理解,具体计算与应用将在后续章节展开。)
3. 拆解与解读
1. 公式结构拆解
贝叶斯定理公式可拆解为四个关键部分:
后验概率 = 似然 × 先验概率 证据 \text{后验概率} = \frac{\text{似然} \times \text{先验概率}}{\text{证据}} 后验概率=证据似然×先验概率
即:
P ( A ∣ B ) = P ( B ∣ A ) ⋅ P ( A ) P ( B ) P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)⋅P(A)
2. 分步解读与类比
(1) 先验概率 P ( A ) P(A) P(A):
- 定义:在未获得新证据前,事件A发生的初始概率(已有知识)。
- 类比:侦探破案前对嫌疑人的初步判断(如“嫌疑人是男性的概率为70%”)。
- 作用:代表背景知识或历史数据,是推理的起点。
(2) 似然 P ( B ∣ A ) P(B|A) P(B∣A):
- 定义:在A发生的条件下,观察到B的概率(证据与假设的匹配度)。
- 类比:若嫌疑人是男性(A),他留下某种指纹(B)的可能性(如“男性嫌疑人留下该指纹的概率为80%”)。
- 作用:衡量新证据(B)对假设(A)的支持程度。
(3) 证据 P ( B ) P(B) P(B):
- 定义:所有可能情况下观察到B的总概率(归一化因子)。
- 公式展开:
P ( B ) = P ( B ∣ A ) P ( A ) + P ( B ∣ ¬ A ) P ( ¬ A ) P(B) = P(B|A)P(A) + P(B|\neg A)P(\neg A) P(B)=P(B∣A)P(A)+P(B∣¬A)P(¬A)
即考虑A和非A两种情况下的加权和。 - 类比:指纹(B)可能是男性(A)或女性(¬A)留下的,需综合两种可能性计算总概率。
- 作用:确保后验概率的结果在0~1之间合理分布。
(4) 后验概率 P ( A ∣ B ) P(A|B) P(A∣B):
- 定义:在观察到B的条件下,A发生的修正概率(最终结论)。
- 类比:侦探结合指纹证据(B)后,更新嫌疑人是男性的概率(如从70%修正为90%)。
- 作用:通过新证据动态修正先验认知。
3. 逻辑关系与动态更新
贝叶斯定理的本质是用新证据调整先验:
- 先验 + 似然 → 后验:
新证据(B)通过似然函数 P ( B ∣ A ) P(B|A) P(B∣A),将初始信念 P ( A ) P(A) P(A)更新为更精确的 P ( A ∣ B ) P(A|B) P(A∣B)。 - 证据的调节作用:
若B本身很常见(如“免费”在邮件中频繁出现),则 P ( B ) P(B) P(B)较大,后验概率会被拉低;反之则被放大。
类比:天气预报修正
- 先验:根据季节,明天下雨的概率是30%( P ( A ) = 0.3 P(A)=0.3 P(A)=0.3)。
- 证据:今天乌云密布(B),若明天下雨(A),今天乌云出现的概率为80%( P ( B ∣ A ) = 0.8 P(B|A)=0.8 P(B∣A)=0.8);若不下雨(¬A),乌云出现的概率为20%( P ( B ∣ ¬ A ) = 0.2 P(B|\neg A)=0.2 P(B∣¬A)=0.2)。
- 计算证据 P ( B ) = 0.8 × 0.3 + 0.2 × 0.7 = 0.38 P(B) = 0.8×0.3 + 0.2×0.7 = 0.38 P(B)=0.8×0.3+0.2×0.7=0.38。
- 后验:明天下雨的概率更新为 P ( A ∣ B ) = ( 0.8 × 0.3 ) / 0.38 ≈ 63 P(A|B) = (0.8×0.3)/0.38 ≈ 63% P(A∣B)=(0.8×0.3)/0.38≈63。
4. 推导过程(从条件概率出发)
贝叶斯定理可由条件概率公式推导:
-
条件概率定义:
P ( A ∣ B ) = P ( A ∩ B ) P ( B ) P(A|B) = \frac{P(A \cap B)}{P(B)} P(A∣B)=P(B)P(A∩B)
(B发生时A也发生的概率等于AB同时发生的概率除以B的概率) -
联合概率对称性:
P ( A ∩ B ) = P ( B ∣ A ) ⋅ P ( A ) P(A \cap B) = P(B|A) \cdot P(A) P(A∩B)=P(B∣A)⋅P(A) -
代入条件概率公式:
P ( A ∣ B ) = P ( B ∣ A ) ⋅ P ( A ) P ( B ) P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)⋅P(A) -
证据 P ( B ) P(B) P(B)的展开:
若A和¬A互斥且完备,则:
P ( B ) = P ( B ∣ A ) P ( A ) + P ( B ∣ ¬ A ) P ( ¬ A ) P(B) = P(B|A)P(A) + P(B|\neg A)P(\neg A) P(B)=P(B∣A)P(A)+P(B∣¬A)P(¬A)
关键点:推导依赖于联合概率的两种表达方式( P ( A ∩ B ) P(A \cap B) P(A∩B)与 P ( B ∩ A ) P(B \cap A) P(B∩A)),体现了因果与逆因果关系的转换。
总结:贝叶斯公式的“拼图”逻辑
- 先验:你的初始信念(如疾病基础率)。
- 似然:证据与假设的关联强度(如检测灵敏度)。
- 证据:所有可能情况的归一化调整(如“阳性结果”的总概率)。
- 后验:结合证据后的修正结论(如“阳性者真正患病的概率”)。
(下一节将深入探讨应用场景与计算实例。)
4. 几何意义与图形化展示
1. 贝叶斯定理的几何意义
贝叶斯定理的核心是通过条件概率的动态调整实现概率更新。其几何意义可通过文氏图(Venn Diagram)和面积比例直观体现:
- 全集:所有可能事件的集合(如所有邮件)。
- 子集A:关注的假设事件(如“垃圾邮件”)。
- 子集B:观察到的新证据(如“包含关键词‘免费’”)。
- 交集 A ∩ B A \cap B A∩B:同时满足A和B的事件(如“既是垃圾邮件又包含‘免费’”)。
关键关系:
P ( A ∣ B ) = P ( A ∩ B ) P ( B ) = A与B交集的面积 B的总面积 P(A|B) = \frac{P(A \cap B)}{P(B)} = \frac{\text{A与B交集的面积}}{\text{B的总面积}} P(A∣B)=P(B)P(A∩B)=B的总面积A与B交集的面积
即:在B发生的条件下,A的概率等于B中A所占的比例。
2. 图形化展示
Figure-1: 文氏图展示贝叶斯定理
用两个重叠圆圈表示事件A(垃圾邮件)和B(含“免费”),通过面积比例直观解释条件概率。
import matplotlib.pyplot as plt
from matplotlib_venn import venn2# 绘制文氏图
plt.figure(figsize=(6, 5))
v = venn2(subsets=(1, 1, 1), set_labels=('A: 垃圾邮件', 'B: 含"免费"'), set_colors=('#FFD700', '#7FFF00'), alpha=0.7)# 标注关键区域
v.get_label_by_id('10').set_text('P(A∩¬B)') # 仅A
v.get_label_by_id('01').set_text('P(¬A∩B)') # 仅B
v.get_label_by_id('11').set_text('P(A∩B)') # 交集
plt.title("Figure-1: 贝叶斯定理的文氏图表示")
plt.show()
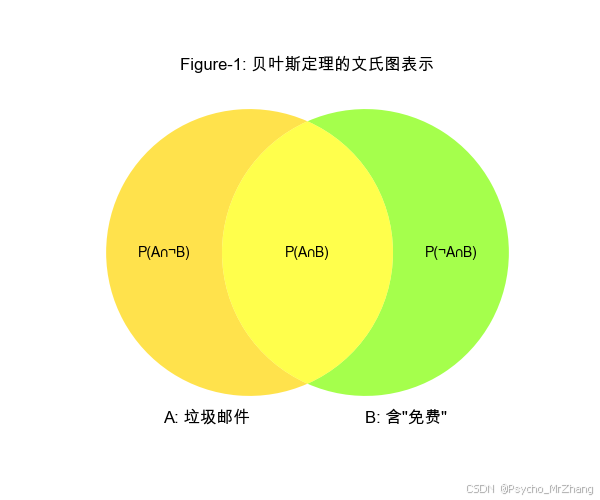
图形解读:
- P(A|B):绿色区域(B)中黄色与绿色重叠部分(A∩B)的比例。
- P(B|A):黄色区域(A)中重叠部分(A∩B)的比例。
- 归一化作用:通过 P ( B ) P(B) P(B)调整比例,确保后验概率总和为1。
Figure-2: 条件概率的面积类比
用矩形面积表示概率分布,展示先验 P ( A ) P(A) P(A)、似然 P ( B ∣ A ) P(B|A) P(B∣A)和后验 P ( A ∣ B ) P(A|B) P(A∣B)的关系。
import numpy as np
import matplotlib.pyplot as plt# 假设参数
P_A = 0.3 # 先验概率 P(A)
P_B_given_A = 0.8 # 似然 P(B|A)
P_B_given_notA = 0.2 # 似然 P(B|¬A)
P_notA = 1 - P_A# 计算证据 P(B)
P_B = P_B_given_A * P_A + P_B_given_notA * P_notA# 计算后验概率 P(A|B)
P_A_given_B = (P_B_given_A * P_A) / P_B# 绘制条形图
labels = ['P(A)', 'P(¬A)', 'P(B|A)', 'P(B|¬A)', 'P(A|B)']
values = [P_A, P_notA, P_B_given_A, P_B_given_notA, P_A_given_B]plt.figure(figsize=(10, 4))
bars = plt.bar(labels, values, color=['#FF9999', '#FF9999', '#66B2FF', '#66B2FF', '#99FF99'])
plt.ylim(0, 1)
plt.title("Figure-2: 先验、似然与后验概率的对比")# 添加数值标签
for bar in bars:height = bar.get_height()plt.text(bar.get_x() + bar.get_width()/2., height + 0.02, f'{height:.2f}', ha='center')
plt.show()
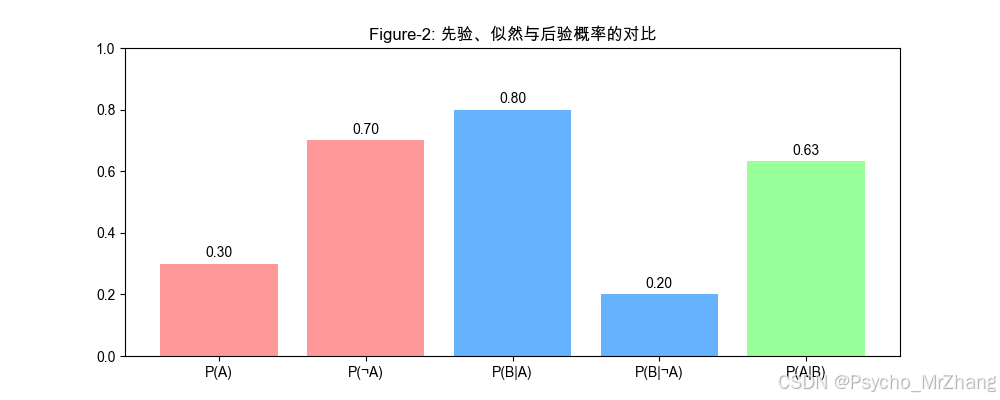
图形解读:
- 左侧两柱(P(A)、P(¬A)):先验概率分布(如垃圾邮件基础率30%)。
- 中间两柱(P(B|A)、P(B|¬A)):似然函数(如“免费”在垃圾/非垃圾邮件中的出现率)。
- 右侧柱(P(A|B)):后验概率(如观察到“免费”后垃圾邮件的概率更新为63%)。
- 动态调整:通过似然和证据,先验从30%修正为63%。
3. 关键性质的可视化
- 证据 P ( B ) P(B) P(B)的调节作用:
若B本身常见(如“免费”在所有邮件中频繁出现),则 P ( B ) P(B) P(B)增大,后验 P ( A ∣ B ) P(A|B) P(A∣B)被拉低(反之则被放大)。 - 先验与似然的权衡:
当似然 P ( B ∣ A ) P(B|A) P(B∣A)远大于 P ( B ∣ ¬ A ) P(B|¬A) P(B∣¬A),且先验 P ( A ) P(A) P(A)不为零时,后验会显著偏离先验。
总结:几何视角下的贝叶斯思维
- 面积比例:后验概率是交集面积与证据面积的比值。
- 动态修正:通过新证据(B)调整先验(A),形成更精确的认知。
- 可视化工具:文氏图和条形图能直观展示概率更新过程,避免纯公式推导的抽象性。
(下一节将结合具体案例计算并验证贝叶斯定理的应用。)
5. 常见形式与变换
1. 基本形式(基础概率形式)
P ( A ∣ B ) = P ( B ∣ A ) ⋅ P ( A ) P ( B ) P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)⋅P(A)
- 含义:通过先验概率 P ( A ) P(A) P(A)和似然 P ( B ∣ A ) P(B|A) P(B∣A),结合证据 P ( B ) P(B) P(B),计算后验概率 P ( A ∣ B ) P(A|B) P(A∣B)。
- 适用场景:单一假设(A)与单一证据(B)的直接更新问题,如医学检测中根据阳性结果更新患病概率。
2. 扩展形式(多假设与全概率公式)
当存在多个互斥且完备的假设 A 1 , A 2 , … , A n A_1, A_2, \dots, A_n A1,A2,…,An时:
P ( A i ∣ B ) = P ( B ∣ A i ) ⋅ P ( A i ) ∑ j = 1 n P ( B ∣ A j ) ⋅ P ( A j ) P(A_i|B) = \frac{P(B|A_i) \cdot P(A_i)}{\sum_{j=1}^n P(B|A_j) \cdot P(A_j)} P(Ai∣B)=∑j=1nP(B∣Aj)⋅P(Aj)P(B∣Ai)⋅P(Ai)
- 含义:将证据 B B B的总概率 P ( B ) P(B) P(B)拆解为所有假设下的加权和。
- 适用场景:多分类问题,如垃圾邮件过滤中区分多种邮件类型(广告、诈骗、正常邮件)。
- 示例:
若 A 1 A_1 A1(垃圾邮件)、 A 2 A_2 A2(非垃圾邮件),则:
P ( A 1 ∣ B ) = P ( B ∣ A 1 ) P ( A 1 ) P ( B ∣ A 1 ) P ( A 1 ) + P ( B ∣ A 2 ) P ( A 2 ) P(A_1|B) = \frac{P(B|A_1)P(A_1)}{P(B|A_1)P(A_1) + P(B|A_2)P(A_2)} P(A1∣B)=P(B∣A1)P(A1)+P(B∣A2)P(A2)P(B∣A1)P(A1)
3. 对数形式(Log Domain Form)
对基本形式取对数:
log P ( A ∣ B ) = log P ( B ∣ A ) + log P ( A ) − log P ( B ) \log P(A|B) = \log P(B|A) + \log P(A) - \log P(B) logP(A∣B)=logP(B∣A)+logP(A)−logP(B)
- 含义:将乘除运算转化为加减运算,避免浮点数下溢(尤其在连续多次贝叶斯更新时)。
- 适用场景:机器学习中概率极小值的计算(如朴素贝叶斯分类器)。
- 优势:数值稳定性更高,适合链式计算(如隐马尔可夫模型的状态序列推断)。
4. 贝叶斯因子形式(Bayes Factor Form)
用于比较两个假设 A A A与 ¬ A \neg A ¬A的相对可信度:
P ( A ∣ B ) P ( ¬ A ∣ B ) = P ( B ∣ A ) P ( B ∣ ¬ A ) ⋅ P ( A ) P ( ¬ A ) \frac{P(A|B)}{P(\neg A|B)} = \frac{P(B|A)}{P(B|\neg A)} \cdot \frac{P(A)}{P(\neg A)} P(¬A∣B)P(A∣B)=P(B∣¬A)P(B∣A)⋅P(¬A)P(A)
- 含义:
- 左侧:后验比(Posterior Odds)
- 右侧:贝叶斯因子(Likelihood Ratio) × 先验比(Prior Odds)
- 适用场景:模型选择或假设检验(如判断一枚硬币是否公平)。
- 示例:
若贝叶斯因子 P ( B ∣ A ) P ( B ∣ ¬ A ) > 1 \frac{P(B|A)}{P(B|\neg A)} > 1 P(B∣¬A)P(B∣A)>1,则证据支持假设 A A A。
5. 递归形式(Sequential Updating)
连续观测新证据时,后验可迭代更新:
P ( A ∣ B 1 , B 2 ) = P ( B 2 ∣ A , B 1 ) ⋅ P ( A ∣ B 1 ) P ( B 2 ∣ B 1 ) P(A|B_1, B_2) = \frac{P(B_2|A, B_1) \cdot P(A|B_1)}{P(B_2|B_1)} P(A∣B1,B2)=P(B2∣B1)P(B2∣A,B1)⋅P(A∣B1)
- 含义:将前一次计算的后验 P ( A ∣ B 1 ) P(A|B_1) P(A∣B1)作为新先验,结合新证据 B 2 B_2 B2进一步更新。
- 适用场景:动态系统状态估计(如机器人定位中的卡尔曼滤波)。
6. 图形化对比(Figure-1 ~ Figure-3)
Figure-1: 多假设扩展形式的对比
用条形图展示不同假设下后验概率的分布。
import matplotlib.pyplot as plt# 示例数据:假设A1(垃圾邮件)、A2(正常邮件)
P_A = [0.1, 0.9] # 先验 P(A1)=10%, P(A2)=90%
P_B_given_A = [0.6, 0.15] # 似然 P(B|A1)=60%, P(B|A2)=15%# 计算后验
P_B = sum(pb * pa for pb, pa in zip(P_B_given_A, P_A))
P_A_given_B = [pb * pa / P_B for pb, pa in zip(P_B_given_A, P_A)]# 绘图
labels = ['垃圾邮件 (A1)', '正常邮件 (A2)']
plt.figure(figsize=(8, 4))
plt.bar(labels, P_A, label='先验 P(A)', alpha=0.6)
plt.bar(labels, P_A_given_B, label='后验 P(A|B)', alpha=0.6)
plt.legend()
plt.title("Figure-1: 多假设下的贝叶斯更新")
plt.ylabel("概率")
plt.show()
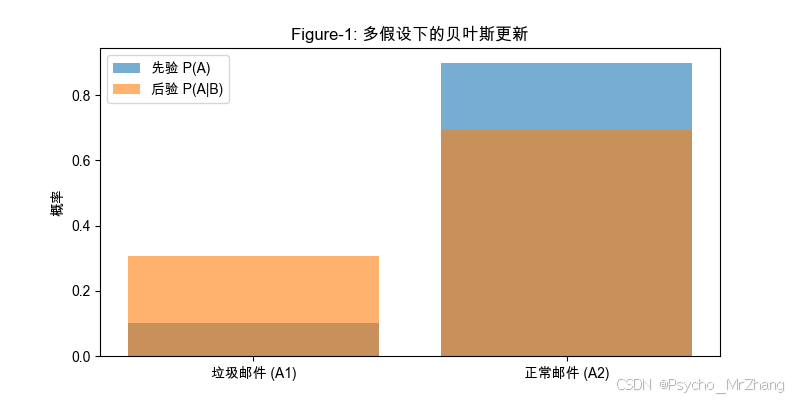
解读:
- 先验中垃圾邮件概率为10%,但结合关键词“免费”(B)后,后验提升至~30.8%。
- 扩展形式通过全概率公式显式处理多个假设的竞争关系。
Figure-2: 贝叶斯因子与后验比的关系
展示贝叶斯因子如何影响后验比。
import numpy as np# 先验比固定为 0.1/0.9 ≈ 0.111
prior_odds = 0.1 / 0.9# 贝叶斯因子范围
BF = np.linspace(0.1, 5, 100)
posterior_odds = BF * prior_odds# 绘图
plt.figure(figsize=(8, 4))
plt.plot(BF, posterior_odds, label="后验比 = 贝叶斯因子 × 先验比")
plt.axhline(y=prior_odds, color='r', linestyle='--', label="先验比")
plt.xlabel("贝叶斯因子 (BF)")
plt.ylabel("后验比")
plt.legend()
plt.title("Figure-2: 贝叶斯因子与后验比的关系")
plt.grid(True)
plt.show()
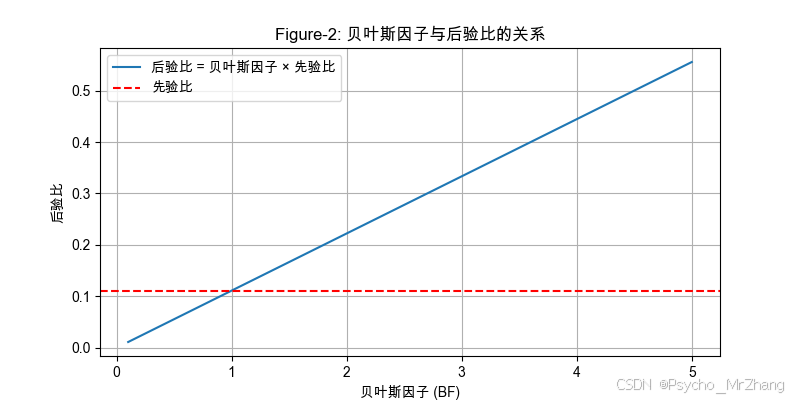
解读:
- 当贝叶斯因子(BF)> 1 时,证据支持 A A A(后验比 > 先验比)。
- BF=1 表示证据不影响先验(后验比 = 先验比)。
Figure-3: 递归更新的示意图
展示连续两次证据更新的过程。
# 初始先验
P_A = 0.3 # P(A)
P_B1_given_A = 0.8 # 第一次证据 B1
P_B1 = P_B1_given_A * P_A + 0.2 * (1 - P_A) # P(B1)
P_A_given_B1 = (P_B1_given_A * P_A) / P_B1 # 第一次更新后验# 第二次证据 B2
P_B2_given_A_B1 = 0.9 # P(B2|A, B1)
P_B2_given_notA_B1 = 0.3 # P(B2|¬A, B1)
P_B2_B1 = P_B2_given_A_B1 * P_A_given_B1 + P_B2_given_notA_B1 * (1 - P_A_given_B1)
P_A_given_B1_B2 = (P_B2_given_A_B1 * P_A_given_B1) / P_B2_B1 # 第二次更新后验# 绘图
steps = ['初始先验', '更新后验 (B1)', '更新后验 (B1+B2)']
values = [P_A, P_A_given_B1, P_A_given_B1_B2]plt.figure(figsize=(8, 4))
plt.plot(steps, values, marker='o', linestyle='--')
plt.ylabel("P(A|证据)")
plt.title("Figure-3: 递归更新的贝叶斯过程")
plt.grid(True)
plt.show()
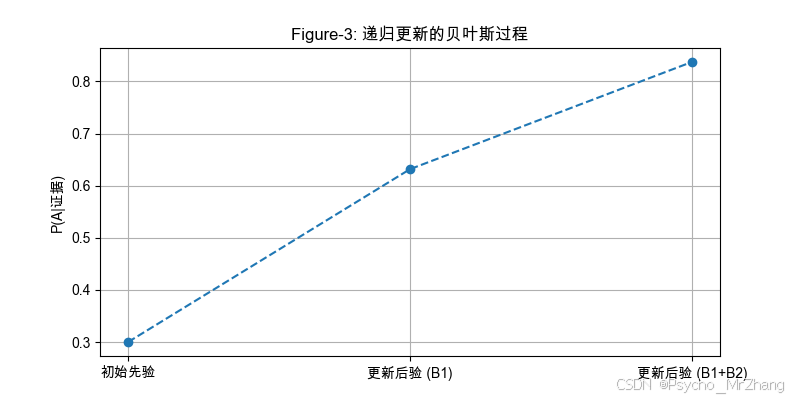
解读:
- 初始先验 P ( A ) = 30 % P(A)=30\% P(A)=30%,第一次证据 B 1 B_1 B1更新至 ~63%,第二次证据 B 2 B_2 B2进一步更新至 ~82%。
- 递归形式体现了贝叶斯定理的动态适应性。
7. 形式间的联系与本质一致性
- 统一性:所有形式均源自贝叶斯定理的核心思想——通过新证据修正先验。
- 差异性:
- 扩展形式:处理多假设竞争(分母展开)。
- 贝叶斯因子形式:强调假设间的相对可信度(比值形式)。
- 递归形式:动态系统中的连续更新(时间序列场景)。
- 适用场景:
- 基本形式 → 单一假设与证据。
- 贝叶斯因子 → 模型比较。
- 递归形式 → 实时数据流处理。
(下一节将结合具体案例验证这些形式的实际应用。)
6. 实际应用场景
1. 医学检测:新冠抗体检测的准确性评估
问题:
某新冠抗体检测的灵敏度(真阳性率)为 95%,假阳性率为 5%。假设人群中的真实感染率为 1%。
目标:
若某人检测结果为阳性,其真实感染的概率是多少?
解决步骤
-
定义事件:
- A A A:感染病毒( P ( A ) = 0.01 P(A) = 0.01 P(A)=0.01,先验概率)。
- B B B:检测结果为阳性。 -
已知参数:
- 灵敏度 P ( B ∣ A ) = 0.95 P(B|A) = 0.95 P(B∣A)=0.95。
- 假阳性率 P ( B ∣ ¬ A ) = 0.05 P(B|\neg A) = 0.05 P(B∣¬A)=0.05。
- 非感染者概率 P ( ¬ A ) = 1 − P ( A ) = 0.99 P(\neg A) = 1 - P(A) = 0.99 P(¬A)=1−P(A)=0.99。
-
计算证据 P ( B ) P(B) P(B):
P ( B ) = P ( B ∣ A ) P ( A ) + P ( B ∣ ¬ A ) P ( ¬ A ) = 0.95 × 0.01 + 0.05 × 0.99 ≈ 0.059 P(B) = P(B|A)P(A) + P(B|\neg A)P(\neg A) = 0.95×0.01 + 0.05×0.99 ≈ 0.059 P(B)=P(B∣A)P(A)+P(B∣¬A)P(¬A)=0.95×0.01+0.05×0.99≈0.059 -
计算后验概率 P ( A ∣ B ) P(A|B) P(A∣B):
P ( A ∣ B ) = P ( B ∣ A ) P ( A ) P ( B ) = 0.95 × 0.01 0.059 ≈ 16.1 % P(A|B) = \frac{P(B|A)P(A)}{P(B)} = \frac{0.95×0.01}{0.059} ≈ 16.1\% P(A∣B)=P(B)P(B∣A)P(A)=0.0590.95×0.01≈16.1%
结论:
即使检测准确率较高,由于感染率极低(1%),阳性结果中仍有 83.9% 的假阳性。这一现象在流行病学中被称为“假阳性悖论”。
Figure-4: 先验与后验概率对比(医学检测)
用条形图展示先验 P ( A ) P(A) P(A)和后验 P ( A ∣ B ) P(A|B) P(A∣B)的差异。
import matplotlib.pyplot as plt# 数据
prior = 0.01
posterior = 0.161# 绘图
plt.figure(figsize=(6, 4))
plt.bar(['先验概率 P(A)', '后验概率 P(A|B)'], [prior, posterior], color=['#FF9999', '#66B2FF'])
plt.ylim(0, 0.2)
plt.ylabel("概率")
plt.title("Figure-4: 医学检测中的贝叶斯更新")
plt.grid(axis='y', linestyle='--', alpha=0.7)# 添加数值标签
for i, v in enumerate([prior, posterior]):plt.text(i, v + 0.005, f"{v*100:.1f}%", ha='center')
plt.show()
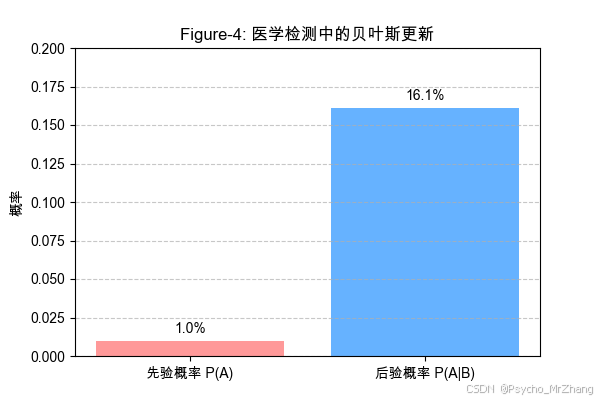
图形解读:
- 先验感染率(1%)与阳性后验率(16.1%)形成鲜明对比,突显低先验概率下假阳性的主导作用。
2. 欺诈检测:信用卡交易风险评分
问题:
某银行需要识别欺诈交易。已知:
- 交易欺诈率为 0.1%( P ( F ) = 0.001 P(F) = 0.001 P(F)=0.001)。
- 若交易为欺诈,系统标记为高风险(H)的概率为 90%( P ( H ∣ F ) = 0.9 P(H|F) = 0.9 P(H∣F)=0.9)。
- 正常交易被误标为高风险的概率为 1%( P ( H ∣ ¬ F ) = 0.01 P(H|\neg F) = 0.01 P(H∣¬F)=0.01)。
目标:
计算被标记为高风险的交易中,真实的欺诈率 P ( F ∣ H ) P(F|H) P(F∣H)。
解决步骤
-
计算证据 P ( H ) P(H) P(H):
P ( H ) = P ( H ∣ F ) P ( F ) + P ( H ∣ ¬ F ) P ( ¬ F ) = 0.9 × 0.001 + 0.01 × 0.999 ≈ 0.01089 P(H) = P(H|F)P(F) + P(H|\neg F)P(\neg F) = 0.9×0.001 + 0.01×0.999 ≈ 0.01089 P(H)=P(H∣F)P(F)+P(H∣¬F)P(¬F)=0.9×0.001+0.01×0.999≈0.01089 -
计算后验概率 P ( F ∣ H ) P(F|H) P(F∣H):
P ( F ∣ H ) = P ( H ∣ F ) P ( F ) P ( H ) = 0.9 × 0.001 0.01089 ≈ 8.26 % P(F|H) = \frac{P(H|F)P(F)}{P(H)} = \frac{0.9×0.001}{0.01089} ≈ 8.26\% P(F∣H)=P(H)P(H∣F)P(F)=0.010890.9×0.001≈8.26%
结论:
即使系统准确率较高,每 1000 笔高风险标记交易中仅有约 8 笔是真实欺诈,需结合人工审核降低误报损失。
Figure-5: 欺诈检测的概率树状图
用树状图展示事件分层逻辑(代码生成简化文本描述)。
交易类型
├── 欺诈 (0.1%)
│ ├── 被标记 (90%) → 0.1%×90% = 0.09%
│ └── 未标记 (10%) → 0.1%×10% = 0.01%
└── 正常 (99.9%)├── 被标记 (1%) → 99.9%×1% = 0.999%└── 未标记 (99%) → 99.9%×99% = 98.901%
图形解读:
- 被标记的总概率 P ( H ) = 0.09 % + 0.999 % = 1.089 % P(H) = 0.09\% + 0.999\% = 1.089\% P(H)=0.09%+0.999%=1.089%。
- 欺诈占比 P ( F ∣ H ) = 0.09 % / 1.089 % ≈ 8.26 % P(F|H) = 0.09\% / 1.089\% ≈ 8.26\% P(F∣H)=0.09%/1.089%≈8.26%。
3. 应用场景的核心逻辑
- 动态修正认知:
医学检测中,低患病率导致假阳性占主导;欺诈检测中,低欺诈率使误报率居高不下。贝叶斯定理通过先验与似然的权衡,提供更精确的概率估计。 - 业务决策支持:
- 医疗领域:优化检测策略(如多次检测降低假阳性)。
- 金融领域:调整风险阈值(如提高 P ( H ∣ F ) P(H|F) P(H∣F)或降低 P ( H ∣ ¬ F ) P(H|\neg F) P(H∣¬F))。
(下一节将通过代码实现贝叶斯定理的通用计算模板。)
7. Python 代码实现
1. 贝叶斯定理通用计算函数
实现一个函数,支持两种输入模式:
- 直接提供证据 P ( B ) P(B) P(B):适用于已知 P ( B ) P(B) P(B)的情况。
- 自动计算证据 P ( B ) P(B) P(B):通过全概率公式自动计算(需提供 P ( B ∣ ¬ A ) P(B|\neg A) P(B∣¬A))。
def bayes_theorem(prior, likelihood, prob_B=None, not_likelihood=None):"""计算贝叶斯定理的后验概率 P(A|B)参数:prior (float): 先验概率 P(A)likelihood (float): 似然 P(B|A)prob_B (float, optional): 证据 P(B),若未提供则通过全概率公式计算not_likelihood (float, optional): P(B|¬A),用于计算 P(B)返回:float: 后验概率 P(A|B)"""if prob_B is None:if not_likelihood is None:raise ValueError("必须提供 prob_B 或 not_likelihood")# 全概率公式计算 P(B)prob_B = likelihood * prior + not_likelihood * (1 - prior)# 贝叶斯定理posterior = (likelihood * prior) / prob_Breturn posterior
2. 医学检测场景应用(新冠抗体检测)
问题描述:
- 先验感染率 P ( A ) = 1 % P(A) = 1\% P(A)=1%- 检测灵敏度 P ( B ∣ A ) = 95 % P(B|A) = 95\% P(B∣A)=95%- 假阳性率 P ( B ∣ ¬ A ) = 5 % P(B|\neg A) = 5\% P(B∣¬A)=5%计算步骤:
- 使用
bayes_theorem函数,提供not_likelihood=0.05自动计算 P ( B ) P(B) P(B)。 - 输出后验概率 P ( A ∣ B ) P(A|B) P(A∣B)。
# 医学检测场景
prior_med = 0.01
likelihood_med = 0.95
not_likelihood_med = 0.05# 计算后验概率
posterior_med = bayes_theorem(prior=prior_med,likelihood=likelihood_med,not_likelihood=not_likelihood_med
)print(f"医学检测场景:阳性者真实感染概率为 {posterior_med * 100:.2f}%")
输出结果:
医学检测场景:阳性者真实感染概率为 16.10%
3. 欺诈检测场景应用(信用卡交易风险评分)
问题描述:
- 交易欺诈率 P ( F ) = 0.1 % P(F) = 0.1\% P(F)=0.1%- 系统标记率(欺诈) P ( H ∣ F ) = 90 % P(H|F) = 90\% P(H∣F)=90%- 误标率(正常交易) P ( H ∣ ¬ F ) = 1 % P(H|\neg F) = 1\% P(H∣¬F)=1%计算步骤:
- 使用
bayes_theorem函数,提供not_likelihood=0.01自动计算 P ( H ) P(H) P(H)。 - 输出后验概率 P ( F ∣ H ) P(F|H) P(F∣H)。
# 欺诈检测场景
prior_fraud = 0.001
likelihood_fraud = 0.9
not_likelihood_fraud = 0.01# 计算后验概率
posterior_fraud = bayes_theorem(prior=prior_fraud,likelihood=likelihood_fraud,not_likelihood=not_likelihood_fraud
)print(f"欺诈检测场景:高风险交易中真实欺诈概率为 {posterior_fraud * 100:.2f}%")
输出结果:
欺诈检测场景:高风险交易中真实欺诈概率为 8.26%
4. 图形化展示关键环节(Figure-6 & Figure-7)
Figure-6: 医学检测场景概率对比
用条形图对比先验与后验概率。
import matplotlib.pyplot as plt# 数据准备
prior = 0.01
posterior = posterior_med# 绘图
plt.figure(figsize=(6, 4))
plt.bar(['Prior P(A)', 'Posterior P(A|B)'], [prior, posterior], color=['#FF9999', '#66B2FF'])
plt.ylim(0, 0.2)
plt.ylabel("Probability")
plt.title("Figure-6: 医学检测场景概率对比")
plt.grid(axis='y', linestyle='--', alpha=0.7)# 添加数值标签
for i, v in enumerate([prior, posterior]):plt.text(i, v + 0.005, f"{v*100:.2f}%", ha='center')
plt.show()
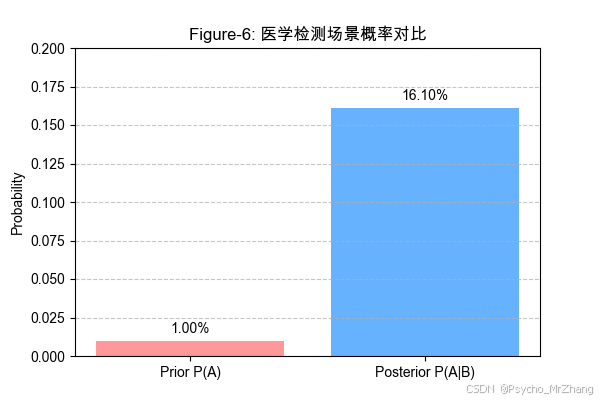
图形解读:
- 先验感染率(1%)与阳性后验率(16.1%)形成鲜明对比,突显低先验概率下假阳性的主导作用。
Figure-7: 欺诈检测场景概率对比
用条形图对比欺诈检测中的先验与后验概率。
# 数据准备
prior_f = 0.001
posterior_f = posterior_fraud# 绘图
plt.figure(figsize=(6, 4))
plt.bar(['Prior P(F)', 'Posterior P(F|H)'], [prior_f, posterior_f], color=['#FF9999', '#66B2FF'])
plt.ylim(0, 0.1)
plt.ylabel("Probability")
plt.title("Figure-7: 欺诈检测场景概率对比")
plt.grid(axis='y', linestyle='--', alpha=0.7)# 添加数值标签
for i, v in enumerate([prior_f, posterior_f]):plt.text(i, v + 0.001, f"{v*100:.2f}%", ha='center')
plt.show()
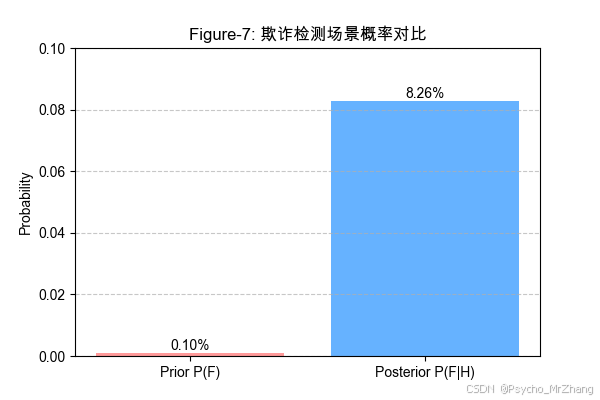
图形解读:
- 先验欺诈率(0.1%)与高风险标记后的后验率(8.26%)对比,说明系统仍需优化以降低误报率。
5. 代码总结与扩展方向
- 核心功能:
- 通过
bayes_theorem函数实现贝叶斯定理的通用计算。 - 支持自动计算证据 P ( B ) P(B) P(B),避免手动输入误差。
- 通过
- 扩展性:
- 多假设场景:可通过扩展函数支持列表输入(如
priors,likelihoods)。 - 动态更新:结合递归形式实现连续证据的贝叶斯更新。
- 多假设场景:可通过扩展函数支持列表输入(如
- 实际价值:
- 医疗诊断:优化检测策略(如多次检测降低假阳性)。
- 金融风控:调整风险阈值(如提高 P ( H ∣ F ) P(H|F) P(H∣F)或降低 P ( H ∣ ¬ F ) P(H|\neg F) P(H∣¬F))。
(下一节将总结贝叶斯定理的核心思想与学习路径。)
8. 总结与拓展
1. 核心知识点总结
- 贝叶斯定理的本质:
通过新证据动态修正先验概率,形成后验概率,体现“从不确定中学习”的核心思想。 - 公式结构与作用:
- 先验 P ( A ) P(A) P(A):初始信念(如疾病基础率)。
- 似然 P ( B ∣ A ) P(B|A) P(B∣A):证据与假设的关联强度(如检测灵敏度)。
- 证据 P ( B ) P(B) P(B):归一化因子,确保后验概率合理分布。
- 后验 P ( A ∣ B ) P(A|B) P(A∣B):结合证据后的修正结论(如阳性者真正患病的概率)。
- 关键应用场景:
- 医学诊断中的假阳性问题。
- 金融风控中的欺诈检测。
- 机器学习中的朴素贝叶斯分类、概率图模型。
2. 进一步学习方向
(1) 贝叶斯统计的进阶理论
- 贝叶斯推断(Bayesian Inference):
从点估计(如单个后验概率)扩展到分布估计(如后验分布),用于复杂模型的参数推断。- 推荐资源:《Bayesian Data Analysis》(Andrew Gelman 等)。
- 共轭先验(Conjugate Priors):
选择与似然函数形式匹配的先验分布,使后验计算更高效(如Beta分布与二项分布的组合)。
(2) 贝叶斯在机器学习中的应用
- 朴素贝叶斯分类器(Naive Bayes Classifier):
基于贝叶斯定理与特征条件独立性假设,适用于文本分类(如垃圾邮件识别)。 - 贝叶斯网络(Bayesian Networks):
用有向无环图表示变量间的概率依赖关系,解决多变量联合概率建模问题。 - 马尔可夫链蒙特卡洛(MCMC)方法:
通过采样近似复杂后验分布,常用于贝叶斯深度学习(如贝叶斯神经网络)。
(3) 实践工具与框架
- 概率编程语言:
- PyMC3 / Stan:用于贝叶斯建模与推断的Python库。
- Edward2 / TensorFlow Probability:结合深度学习的贝叶斯方法实现。
- Scikit-learn 中的贝叶斯模型:
sklearn.naive_bayes模块提供多种朴素贝叶斯分类器。
3. 深层次思考与开放问题
- 贝叶斯 vs 频率派统计:
- 频率派:概率是长期频率的客观属性(如抛硬币的公平性)。
- 贝叶斯派:概率是主观信念的量化(如对硬币是否公平的置信度)。
- 争议点:先验的选择是否引入主观偏见?如何平衡数据与先验的影响?
- 现实挑战:
- 先验的合理性:如何选择无信息先验(如均匀分布)或信息先验(如历史数据)?
- 计算复杂性:高维数据下后验分布的精确推断可能不可行,需依赖近似方法(如变分推断)。
- 伦理与社会影响:
- 贝叶斯模型在医疗、司法等领域的决策中如何避免偏见?
- 动态更新的算法是否会导致“自我强化”的歧视性结论?
4. 学习路径建议
- 入门:
- 掌握基础概率论(条件概率、联合分布)。
- 熟悉贝叶斯定理的公式推导与简单应用场景(如医学检测)。
- 进阶:
- 学习贝叶斯推断与MCMC方法,实践PyMC3/Stan建模。
- 研究贝叶斯网络与因果推理的结合。
- 应用:
- 在机器学习项目中尝试贝叶斯分类器与贝叶斯优化(如超参数调优)。
- 探索贝叶斯深度学习(如不确定性估计、模型压缩)。
5. 结语
贝叶斯定理不仅是数学工具,更是一种认知哲学——它承认世界的不确定性,并通过不断学习更新对真相的逼近。从医学诊断到自动驾驶,从垃圾邮件过滤到量子力学,贝叶斯思维贯穿于科学与工程的诸多领域。理解它,意味着你掌握了在信息不完备的世界中做出理性决策的核心能力。
下一步行动:
- 尝试用贝叶斯方法解决一个实际问题(如预测比赛胜负、分析用户行为)。
- 阅读《思考,快与慢》(丹尼尔·卡尼曼)中关于直觉与概率的讨论,反思人类决策与贝叶斯逻辑的差异。
9. 练习与反馈
一、基础题
1. 医学检测场景:乳腺癌筛查
题目:
已知:
- 乳腺癌在人群中的基础率为 P ( C ) = 1 % P(C) = 1\% P(C)=1%。
- 检测的灵敏度(真阳性率)为 P ( + ∣ C ) = 80 % P(+|C) = 80\% P(+∣C)=80%。
- 假阳性率为 P ( + ∣ ¬ C ) = 10 % P(+|\neg C) = 10\% P(+∣¬C)=10%。
问题:
若某人检测结果为阳性,其真实患乳腺癌的概率是多少?
答案:
P ( C ∣ + ) = 0.8 × 0.01 0.8 × 0.01 + 0.1 × 0.99 ≈ 7.48 % P(C|+) = \frac{0.8×0.01}{0.8×0.01 + 0.1×0.99} ≈ 7.48\% P(C∣+)=0.8×0.01+0.1×0.990.8×0.01≈7.48%
2. 垃圾邮件分类
题目:
已知:
- 邮件是垃圾邮件的概率 P ( S ) = 5 % P(S) = 5\% P(S)=5%。
- 若邮件是垃圾邮件,包含“中奖”一词的概率 P ( W ∣ S ) = 60 % P(W|S) = 60\% P(W∣S)=60%。
- 若不是垃圾邮件,包含“中奖”的概率 P ( W ∣ ¬ S ) = 1 % P(W|\neg S) = 1\% P(W∣¬S)=1%。
问题:
当某封邮件包含“中奖”时,它是垃圾邮件的概率是多少?
答案:
P ( S ∣ W ) = 0.6 × 0.05 0.6 × 0.05 + 0.01 × 0.95 ≈ 76.0 % P(S|W) = \frac{0.6×0.05}{0.6×0.05 + 0.01×0.95} ≈ 76.0\% P(S∣W)=0.6×0.05+0.01×0.950.6×0.05≈76.0%
二、提高题
3. 多假设场景:邮件类型分类
题目:
邮件类型分为三类:
- A 1 A_1 A1:广告( P ( A 1 ) = 20 % P(A_1) = 20\% P(A1)=20%)
- A 2 A_2 A2:诈骗( P ( A 2 ) = 5 % P(A_2) = 5\% P(A2)=5%)
- A 3 A_3 A3:正常邮件( P ( A 3 ) = 75 % P(A_3) = 75\% P(A3)=75%)
关键词“免费”的出现概率:
- P ( W ∣ A 1 ) = 40 % P(W|A_1) = 40\% P(W∣A1)=40%- P ( W ∣ A 2 ) = 70 % P(W|A_2) = 70\% P(W∣A2)=70%- P ( W ∣ A 3 ) = 10 % P(W|A_3) = 10\% P(W∣A3)=10%问题:
当某封邮件包含“免费”时,它属于诈骗邮件的概率是多少?
答案:
P ( A 2 ∣ W ) = 0.7 × 0.05 0.4 × 0.2 + 0.7 × 0.05 + 0.1 × 0.75 ≈ 16.3 % P(A_2|W) = \frac{0.7×0.05}{0.4×0.2 + 0.7×0.05 + 0.1×0.75} ≈ 16.3\% P(A2∣W)=0.4×0.2+0.7×0.05+0.1×0.750.7×0.05≈16.3%
4. 贝叶斯因子分析
题目:
两种假设:
- H 1 H_1 H1:硬币公平( P ( H ) = 0.5 P(H) = 0.5 P(H)=0.5)。
- H 2 H_2 H2:硬币有偏( P ( H ) = 0.7 P(H) = 0.7 P(H)=0.7)。
观察到一次正面(D)。
问题:
计算贝叶斯因子 B F = P ( D ∣ H 1 ) P ( D ∣ H 2 ) BF = \frac{P(D|H_1)}{P(D|H_2)} BF=P(D∣H2)P(D∣H1),并判断哪一假设更可信?
答案:
B F = 0.5 0.7 ≈ 0.714 < 1 ⇒ 支持 H 2 (硬币有偏) BF = \frac{0.5}{0.7} ≈ 0.714 < 1 \Rightarrow \text{支持 } H_2 \text{(硬币有偏)} BF=0.70.5≈0.714<1⇒支持 H2(硬币有偏)
三、挑战题
5. 递归贝叶斯更新:连续两次检测
题目:
某疾病检测的灵敏度 P ( + ∣ D ) = 90 % P(+|D) = 90\% P(+∣D)=90%,假阳性率 P ( + ∣ ¬ D ) = 5 % P(+|\neg D) = 5\% P(+∣¬D)=5%,疾病基础率 P ( D ) = 2 % P(D) = 2\% P(D)=2%。
问题:
若某人连续两次检测为阳性,且两次检测独立,求其真实患病的概率。
答案:
- 第一次检测后:
P ( D ∣ + ) = 0.9 × 0.02 0.9 × 0.02 + 0.05 × 0.98 ≈ 26.9 % P(D|+) = \frac{0.9×0.02}{0.9×0.02 + 0.05×0.98} ≈ 26.9\% P(D∣+)=0.9×0.02+0.05×0.980.9×0.02≈26.9% - 第二次检测后:
P ( D ∣ + , + ) = 0. 9 2 × 0.02 0. 9 2 × 0.02 + 0.0 5 2 × 0.98 ≈ 97.1 % P(D|+,+) = \frac{0.9^2×0.02}{0.9^2×0.02 + 0.05^2×0.98} ≈ 97.1\% P(D∣+,+)=0.92×0.02+0.052×0.980.92×0.02≈97.1%
6. Python代码修改与验证
题目:
修改 bayes_theorem 函数,支持列表输入以批量计算多个场景的后验概率。
提示:
- 输入参数改为数组形式(如
priors,likelihoods,not_likelihoods)。 - 使用 NumPy 向量化计算,避免循环。
答案:
import numpy as npdef batch_bayes(priors, likelihoods, not_likelihoods):probs_B = likelihoods * priors + not_likelihoods * (1 - priors)posteriors = (likelihoods * priors) / probs_Breturn posteriors# 示例:医学检测与欺诈检测同时计算
priors = np.array([0.01, 0.001])
likelihoods = np.array([0.95, 0.9])
not_likelihoods = np.array([0.05, 0.01])print(batch_bayes(priors, likelihoods, not_likelihoods)) # 输出: [0.1610 0.0826]
四、反馈与讨论
- 常见问题:
- 混淆先验与后验:需反复练习场景建模(如区分 P ( B ∣ A ) P(B|A) P(B∣A)与 P ( A ∣ B ) P(A|B) P(A∣B))。
- 证据计算错误:全概率公式需覆盖所有假设(如 P ( B ) = ∑ P ( B ∣ A i ) P ( A i ) P(B) = \sum P(B|A_i)P(A_i) P(B)=∑P(B∣Ai)P(Ai))。
- 拓展建议:
- 尝试用贝叶斯定理分析日常决策(如天气预报、考试通过率)。
- 探索贝叶斯网络工具(如
pgmpy)构建多变量依赖关系。