解构语言模型推理过程,超越最终答案:通过分析子思考路径提升大语言模型推理准确性的方法研究
Beyond the Last Answer: Your Reasoning Trace Uncovers More Than You Think
链接:https://arxiv.org/abs/2504.20708
大型语言模型(LLM)在解决复杂的推理任务方面表现出了令人印象深刻的能力,特别是当被提示通过逐步推理来展示他们的工作时。评估 LLM 在此类任务上的主要方法通常侧重于推理轨迹末尾产生的最终答案。然而,这种方法忽略了嵌入在推理过程本身中的有价值的信息。
论文提出了两个核心问题:最终答案是否总是代表模型的最优结论?不同的推理路径是否会产生不同的结果?他们认为,模型在推理过程中可能会探索多个路径,而最终输出的答案只是其中一个可能的结果。

上图说明了该论文的一个关键见解:即使 LLM 产生了一个不正确的最终答案(50),它的大部分中间推理步骤都收敛到了正确的答案(96)。这种现象表明,分析完整的推理轨迹可以揭示比简单地信任最后一个答案更可靠的信息。
这篇由沙特阿拉伯国王科技大学(KAUST)的研究人员撰写的论文,通过提出以下问题挑战了传统的评估实践:如果我们超越最后一个答案并检查整个推理轨迹会怎样?作者提出了一种新颖的方法,该方法提取和分析来自中间推理步骤(子思考)的答案,以提高推理准确性并评估模型置信度,而无需任何模型参数更新。
该研究建立在 LLM 推理的几个关键领域之上:
思维链(CoT)提示:这种技术鼓励 LLM 在提供最终答案之前生成逐步推理,这已被证明对解决复杂问题有效。然而,标准评估实践通常只考虑最终输出。
测试时缩放:虽然许多方法侧重于通过监督微调或强化学习来提高训练期间的推理能力,但本文在 “测试时” 领域中运行——在不修改模型参数的情况下提高性能。
过度思考现象:先前的研究观察到,过度延长推理链有时会导致性能下降,这种现象通常被称为 “过度思考”。这项工作调查了推理过程中的替代路径是否可能产生更准确的结果。
LLM 中的错误检测:部署 LLM 的一个关键挑战是确定其输出何时不可靠。本文探讨了从不同子思考中得出的答案的一致性是否可以作为信心和正确性的指标。
-
要点:本文挑战了仅依赖大型语言模型最终答案的评估方法,提出通过分析推理过程中的子思考(subthoughts)来提高问题解决准确性的新策略。 -
方法:通过将推理轨迹分割为基于语言线索的连续子思考,并从每个子思考的末端提示模型生成延续,从而提取潜在答案,并使用众数(最频繁出现的答案)来聚合这些答案。 -
实验:在AIME2024和AIME2025数学推理数据集上,对多种大型语言模型进行实验,通过子思考方法,实现了准确性的一致提高,最高分别提升了13%和10%。
1.提出了一种通过分析和利用LLM推理过程中的中间“子思路”来获得更可靠答案的方法。
2.证明了通过聚合这些中间结论(尤其是取众数)可以显著提高模型在复杂推理任务上的表现。
3.揭示了答案在推理过程中的一致性(或熵)可以作为模型信心和答案可靠性的一个指标。
方法论
1. “子思路”(Subthought)分析方法:
-
生成初始推理轨迹: 首先,使用标准的贪婪解码(greedy decoding)让模型针对一个问题生成一个完整的、逐步的推理轨迹(reasoning trace)。 -
分割推理轨迹: 将这个完整的推理轨迹基于语言标记(如 “Wait,” “Alternatively,” “Hmm,” “So,” “Therefore” 等,具体见论文Page 4, “Subthought Transition Markers”)分割成一系列有序的“子思路”(subthoughts)。每个子思路代表推理过程中的一个中间步骤或状态。

-
从子思路生成完整答案: 对于每一个子思路的结束点,都将其作为新的起点,提示模型继续生成完整的解决方案。也就是说,模型会从推理过程中的不同中间点“重新思考”并完成推理。 -
提取答案: 从每个由子思路续写生成的完整方案中提取最终的数值答案。这样,对于一个问题,就能得到一个答案的集合 {A1, A2, …, An},其中 Ai 是从第 i 个子思路开始续写得到的答案。
论文的描述,用于从子思路生成完整答案的模型,与最初用于生成完整推理轨迹的模型是同一个模型。
论文中提到(Page 2, Section “Specifically, our methodology entails:”, 第3点): "Prompting the same model to generate a complete solution starting from an intermediate state (i.e., after each cumulative sequence of subthoughts)."以及在Page 5, Section 3.3 “Subthought Completion Generation” 中提到: “Each partial prompt Pi is then fed back into the same reasoning model M to generate a completion Ci.”
这意味着,如果他们用一个特定的LLM(比如DeepSeek-R1-Distill-Qwen-14B)来生成初始的思考链,那么当他们从这个思考链的某个“子思路”出发继续生成答案时,他们仍然使用的是同一个DeepSeek-R1-Distill-Qwen-14B模型。
论文在 4.1 Experimental Setup 部分的 Models 小节(Page 6)列出了他们实验中评估过的七个开源模型:
- DeepScaleR-1.5B-Preview
- DeepSeek-R1-Distill-Qwen-1.5B
- DeepSeek-R1-Distill-Qwen-14B
- EXAONE-Deep-7.8B
- Light-R1-7B-DS
- QwQ-32B
- Skywork-OR1-Math-7B
因此,对于这七个模型中的任何一个,当研究人员应用他们提出的方法时,该模型既是初始完整推理的生成者,也是从其中间“子思路”出发进行补全并生成新答案的执行者。
论文还提到,在答案提取(Mextract)阶段,他们一致使用了 Qwen/Qwen2.5-14B-Instruct 模型来从生成的文本中解析出最终的数值答案。但这是答案提取模型,而不是用于生成推理过程或从子思路续写的模型。
2. 答案聚合与评估:
众数答案 (Amode): 作者发现,在这个答案集合中,出现频率最高的答案(即众数)往往比原始完整推理轨迹给出的最终答案 (Alast) 更准确。如论文图1所示,即使原始的 Alast 是错误的(50),但从中间步骤生成的答案中,96 是出现次数最多的 (Amode),并且是正确答案。准确性提升: 实验表明,使用 Amode 作为最终答案,在多个LLM和数学推理数据集(AIME2024, AIME2025)上,准确率显著高于仅使用 Alast 的传统方法,提升最高可达13%和10%。
3.答案一致性作为可靠性信号:
熵分析: 通过分析从不同子思路得到的答案分布(例如计算香农熵),可以揭示模型对问题理解的稳定性和信心。
低熵对应高正确率: 如果从各个子思路生成的答案高度一致(低熵),那么模型给出的答案(无论是 Alast 还是 Amode)正确的可能性更高。
高熵对应高错误率: 如果答案分布非常发散(高熵),则表明模型可能在推理过程中遇到了困难,答案的可靠性较低。这可以作为一个潜在的错误检测信号(见论文Page 8, Figure 3)。
分析揭示了答案在推理过程中演变的几个一致模式:
一致正确性:当 LLM 正确解决问题时,从子思考中得出的一系列答案往往会迅速收敛到正确答案并保持稳定。
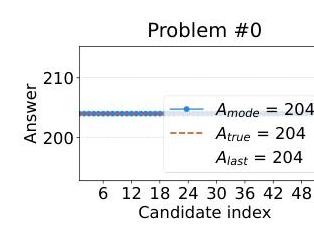
在此示例(问题 #0)中,模型在不同的子思考中始终产生正确的答案 (204),表明高度的信心和可靠性。
波动不正确性:当模型产生不正确的最终答案时,答案序列通常表现出高度波动,表明推理过程存在不确定性。
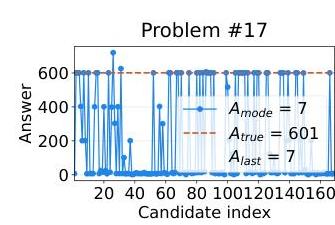
该图显示了问题 #17,其中答案在不同的子思考中差异很大,尽管众数 (7) 与最终答案匹配并且恰好是正确的。
众数纠正最后答案的错误:在许多情况下,即使初始追踪中的最终答案不正确,子思考中最常见的答案(众数)也是正确的。
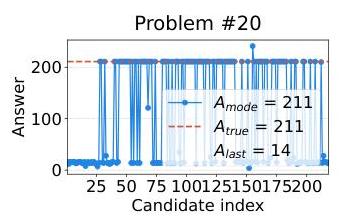
在问题 #20 中,最终答案 (14) 不正确,但众数 (211) 与真实答案匹配,这表明聚合子思考答案如何克服最终结论中的错误。
另一个重要的发现是,答案分布的熵与正确性密切相关。当模型的推理正确时,子思考中答案的熵远低于推理不正确时。
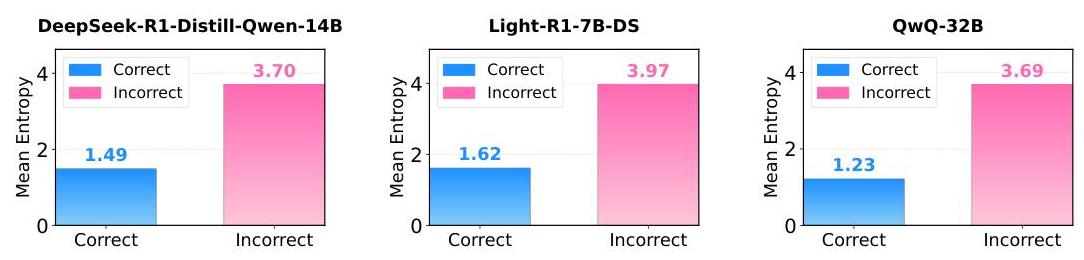
该图显示了不同模型中正确与不正确情况下的平均熵值。例如,对于 DeepSeek-R1-Distill-Qwen-14B 模型,正确答案的平均熵为 1.49,而不正确答案的平均熵为 3.70——这是一个明显的信号,可用于评估置信度。
这种模式在所有测试模型中都是一致的:
QwQ-32B 模型的平均熵:
- 正确答案:1.23
- 不正确答案:3.69EXAONE-Deep-7.8B 模型的平均熵:
- 正确答案:1.03
- 不正确答案:3.42这种显著的差异表明,熵分析可以作为一种有效的工具,用于识别 LLM 中不可靠的输出,而无需验证的真实数据。
4.不同补全策略的比较:
论文比较了两种从子思路生成补全答案的策略:
贪婪补全 (Greedy Subthought Completion): 确定性的,总是选择最高概率的路径。
非贪婪补全 (Non-Greedy Subthought Completion): 引入随机性(如设置temperature > 0, top-p < 1),允许模型探索更多样的推理路径。
非贪婪策略效果更佳: 实验表明,非贪婪补全策略通常能带来更大或更频繁的准确性提升,因为它能更好地探索初始推理路径周围的推理空间(见论文Page 9的结论部分)。
贪婪采样策略: 使用温度参数为0.0和top-p参数为1.0的采样策略,生成确定性最高的推理路径。
非贪婪采样策略: 使用温度参数为1.0和top-p参数为0.95的采样策略,鼓励模型探索不同的推理路径,从而提高答案的多样性。
该方法一致地提高了多个 LLM 和基准数据集的推理准确性:
使用 A_mode 与 A_last 时的性能提升:
- 使用非贪婪采样的 AIME2024:+13.0% 的提升
- 使用非贪婪采样的 AIME2025:+10.0% 的提升
- 多个 LLM 在基准测试中表现出一致的收益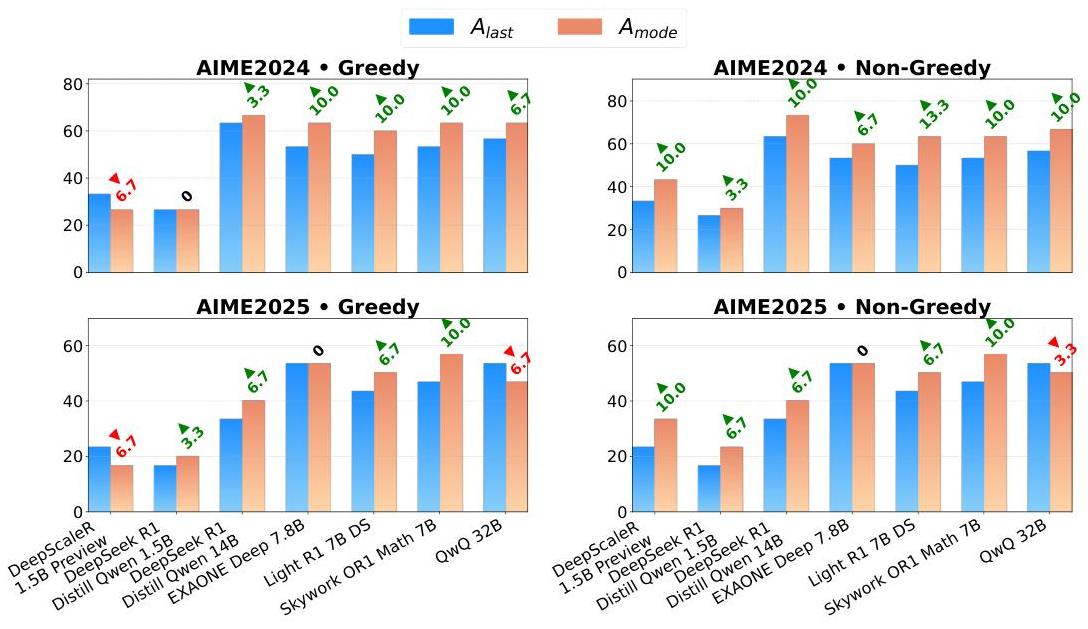
上图比较了不同模型和基准测试中,最后答案 (Alast) 与众数答案 (Amode) 的准确率。绿色三角形表示性能提升,而红色三角形表示性能下降。一致的绿色三角形表明,众数答案方法可靠地提高了各种模型和数据集的性能。
主要观察结果包括:
- 非贪婪采样策略通常比贪婪策略产生更大的改进。
- 改进在不同的模型架构中是一致的。
- 一些模型显示出显着改进(在具有挑战性的数学推理基准测试中高达 13%)。
影响和应用
该发现对 LLM 的部署和研究有几个重要的意义:
改进的评估:本文通过分析整个推理过程而不仅仅是最终答案,提供了一种更细致的评估 LLM 的方法。
增强的可靠性:通过聚合来自多个子思考的答案,用户可以在不修改模型参数或使用集成方法的情况下获得更可靠的结果。
置信度估计:答案分布的熵提供了模型置信度的自然度量,这对于高风险应用至关重要,在这些应用中,知道何时信任模型输出至关重要。
实际实施:该方法可以在不需要模型重新训练或参数更新的情况下实施,使其适用于各种现有模型。
熵计算的数学公式为:
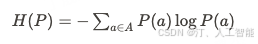
其中 P(a) 是答案 a 在从子思考得出的答案集合中出现的概率。