SGLang 实战介绍 (张量并行 / Qwen3 30B MoE 架构部署)
一、技术背景
随着大语言模型(LLM)的飞速发展,如何更高效、更灵活地驾驭这些强大的模型生成我们期望的内容,成为了开发者们面临的重要课题。传统的通过拼接字符串、管理复杂的状态和调用 API 的方式,在处理复杂任务时显得力不从心。正是在这样的背景下,SGlang (Structured Generation Language) 应运而生,它旨在成为连接用户意图与 LLM 生成能力之间的桥梁,提供一种更高效、更具控制力的 LLM 交互方式
二、SGlang 介绍
2.1 核心概念
SGLang 的核心概念围绕着如何将复杂的 LLM 生成任务分解和控制:
-
SGLang 程序 (SGLang Program): 这是 SGLang 的基本执行单元。一个 SGLang 程序定义了一系列与 LLM 交互的指令和逻辑。
-
生成原语 (Generation Primitives): SGLang 提供了一系列内置的指令,用于控制 LLM 的文本生成。这些原语包括:
gen:用于生成文本。select:用于从多个选项中选择一个。capture:用于捕获 LLM 生成的特定部分内容。 -
控制流 (Control Flow): SGLang 支持类似传统编程语言的控制流结构,如条件判断(
if/else)、循环(for)等。这使得开发者可以根据 LLM 的中间生成结果动态地调整后续的生成策略。 -
并行执行 (Parallel Execution): SGLang 允许并行执行多个生成任务或生成分支,从而提高效率。
-
状态管理 (State Management): SGLang 程序可以维护状态,并在不同的生成步骤之间传递信息。
-
模板化 (Templating): 支持灵活的文本模板,方便构建动态的提示。
2.2 组成部分
一个典型的 SGLang 系统通常包含以下几个关键组成部分:
-
SGLang 语言解释器/编译器 (SGLang Interpreter/Compiler): 负责解析和执行 SGLang 程序。它将 SGLang 代码转换为对底层 LLM 运行时的操作序列。
-
LLM 运行时 (LLM Runtime): 这是实际执行 LLM 推理的部分。SGLang 旨在与多种不同的 LLM 后端(如 vLLM、Hugging Face Transformers 等)集成。SGLang 的运行时优化是其核心优势之一,它通过将控制流直接卸载到 KV 缓存中,实现了高效的执行。
-
SGLang API/SDK: 提供给开发者的接口,用于编写、部署和管理 SGLang 程序。
2.3 关键技术
SGLang 的实现依赖于以下一些关键技术:
-
基于提示的执行 (Prompt-based Execution with Advanced Control): 虽然仍然以提示为基础,但 SGLang 通过其语言结构提供了更高级别的控制。
-
KV 缓存优化 (KV Cache Optimization): 这是 SGLang 实现高性能的关键。传统的 LLM 调用在每次生成时都需要重新计算和填充 KV 缓存(键值缓存,用于存储注意力机制的中间结果)。SGLang 通过将控制逻辑(如
if/else,for循环,select)直接在 KV 缓存层面进行管理和复用,显著减少了冗余计算和数据传输,从而大幅提升了执行速度,特别是在需要复杂控制流和多轮交互的场景下。 -
Radix Tree (基数树) 和 Token Healing: 用于高效地管理和重用提示(prompts)以及修复因 tokenization 边界问题导致的生成不连贯的情况。Radix Tree 允许多个并发请求共享和重用共同的前缀提示,从而节省了重复处理的时间和内存。Token Healing 则用于确保在
select或其他需要精确匹配的场景下,即使 LLM 的生成结果在 token 边界上与预期不完全一致,也能进行有效的校正。 -
与后端 LLM 推理引擎的紧密集成: SGLang 不是一个独立的 LLM,而是一个运行在现有 LLM 推理引擎之上的控制层。它通过与 vLLM 等高性能推理后端的深度集成,充分利用这些后端的优化能力。
-
声明式与命令式编程的结合: SGLang 允许开发者以声明式的方式定义生成目标(例如,生成一个 JSON 对象),同时也提供了命令式的控制流结构来指导生成过程。
2.4 优势与价值
SGLang 为开发者和应用带来了显著的优势和价值:
-
显著的性能提升 (Significant Performance Improvement): 通过 KV 缓存优化、Radix Tree 和并行执行等技术,SGLang 可以大幅度提高 LLM 应用的吞吐量并降低延迟,尤其是在需要复杂交互和控制流的任务中(例如,多轮对话、结构化数据生成、Agent 模拟等)。有报告称其速度比传统方法快几倍甚至几十倍。
-
增强的可控性 (Enhanced Controllability): 开发者可以更精确地控制 LLM 的生成过程,包括强制输出格式、实现条件逻辑、从多个选项中进行选择等。这使得构建更可靠、更符合预期的 LLM 应用成为可能。
-
更高的开发效率和可维护性 (Improved Developer Productivity and Maintainability): SGLang 提供了更接近传统编程的体验,使得编写、调试和维护复杂的 LLM 应用更加容易。将控制逻辑从冗长的提示中分离出来,使得代码更清晰、更模块化。
-
降低成本 (Reduced Cost): 通过提高推理效率,可以减少对计算资源的需求,从而降低运行 LLM 应用的成本。
-
促进复杂 LLM 应用的开发 (Facilitates Development of Complex LLM Applications): 使得构建需要精细控制和高效执行的复杂应用(如多步骤推理、模拟、内容生成流水线、以及各种 Agent 应用)变得更加可行。
-
后端无关性 (Backend Agnostic - to some extent): 虽然与特定后端(如 vLLM)集成可以获得最佳性能,但其设计理念是希望能够支持多种 LLM 推理后端。
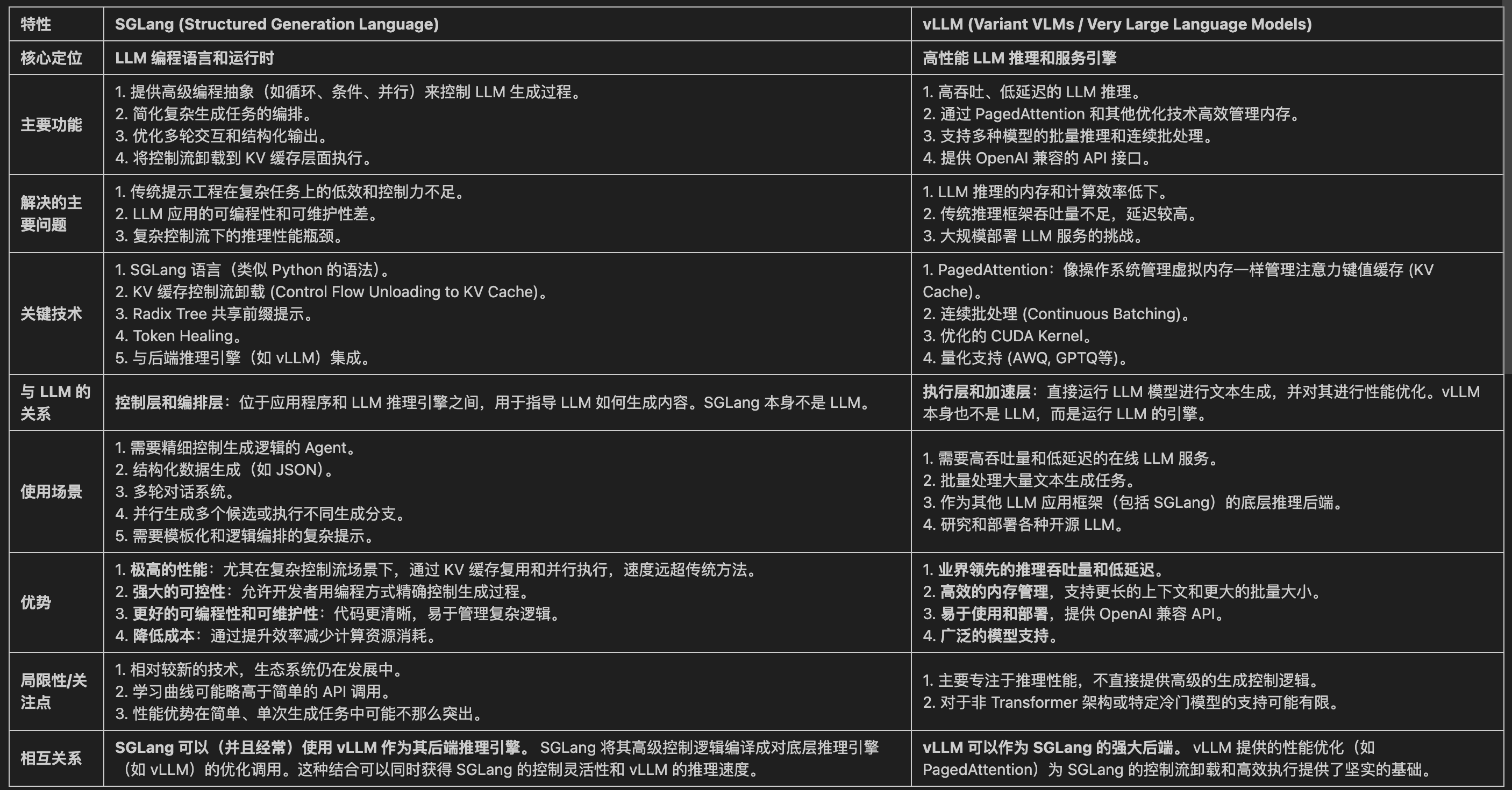
2.5 SGLang vs vLLM
三、SGlang 实战
3.1 基础环境配置
服务器资源申请请参考:
Qwen2.5 7B 极简微调训练_qwen-7b训练-CSDN博客文章浏览阅读310次,点赞4次,收藏6次。实现 qwen 2.5 7b 模型微调实验,并打包好模型最后发布到 huggingface_qwen-7b训练https://blog.csdn.net/weixin_39403185/article/details/147115232?spm=1001.2014.3001.5501
sudo apt update && upgrade -y
sudo apt install build-essential cmake -y# 安装 conda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O /data/Miniconda3.sh
bash /data/Miniconda3.sh -b -p /data/miniconda3echo 'export PATH="/data/miniconda3/bin:$PATH"' >> ~/.bashrc
source /data/miniconda3/bin/activate
source ~/.bashrc# 安装 conda 训练环境
conda create -n llm python=3.10 -y
conda activate llm
echo 'conda activate llm' >> ~/.bashrc
source ~/.bashrcpip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install "sglang[all]"3.2 SGlang 单机部署测试
服务器申请: 一台 A10 先显卡的服务器即可
a) 基础环境配置
参考 3.1
b) 模型准备
mkdir -p /data/models
huggingface-cli download Qwen/Qwen3-8B --resume-download --local-dir /data/models/qwen3-8b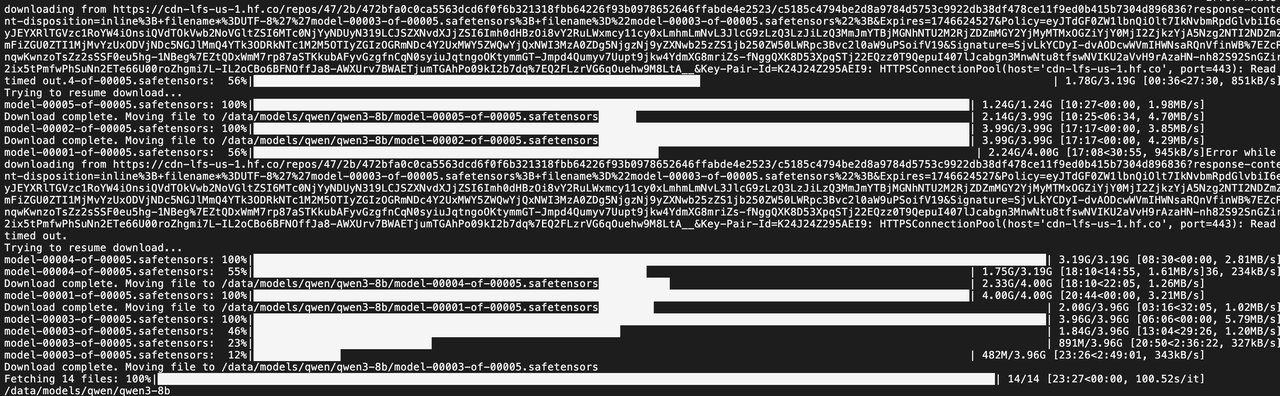
c) 单机部署
python -m sglang.launch_server \
--model-path /data/models/qwen3-8b \
--port 8000 --host 0.0.0.0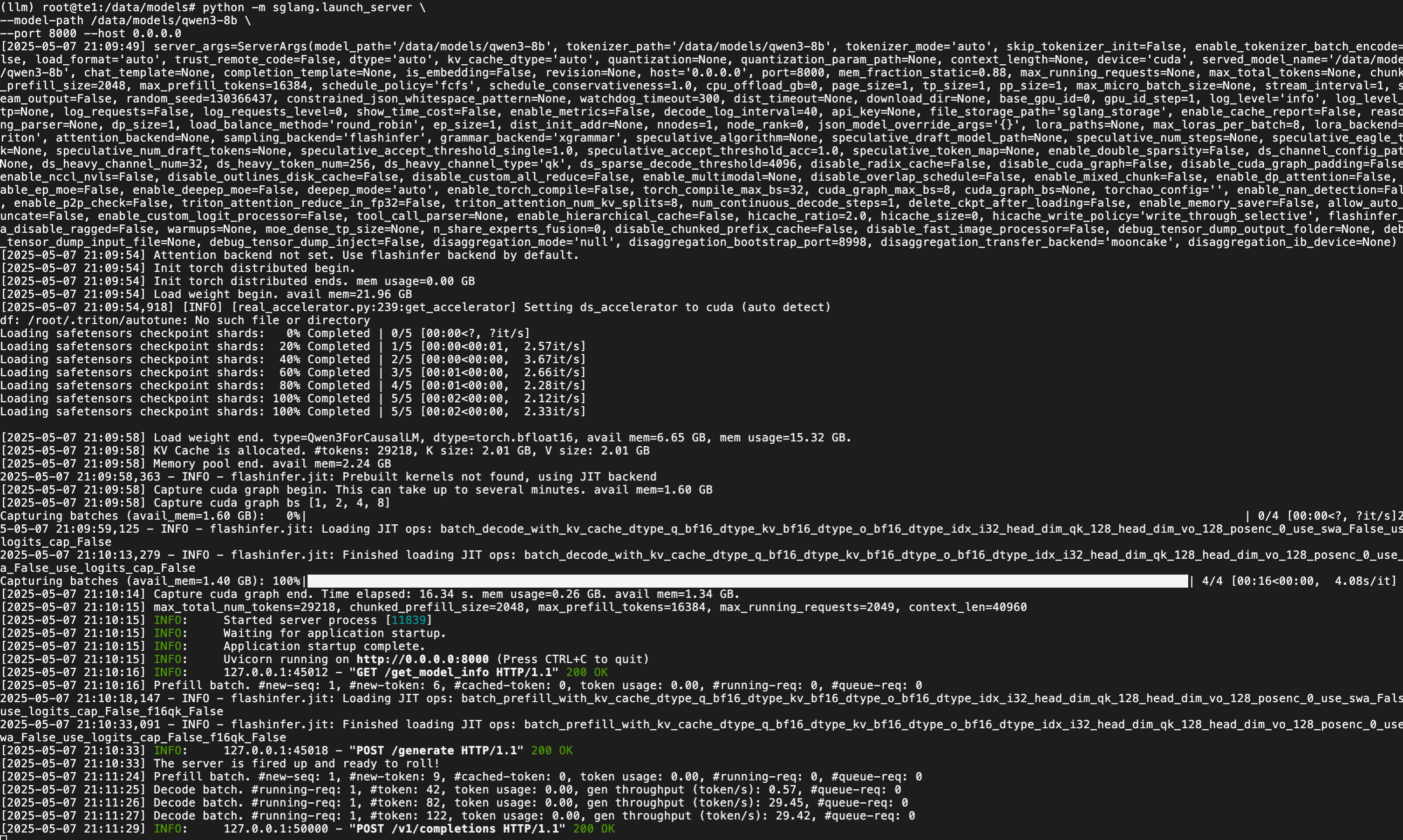
d) 测试推理模型
curl http://localhost:8000/v1/completions \-H "Content-Type: application/json" \-d '{"model": "Qwen/Qwen2-7B-Instruct","prompt": "你好,请介绍一下你自己以及 SGLang。","max_tokens": 150,"temperature": 0.7}' | jq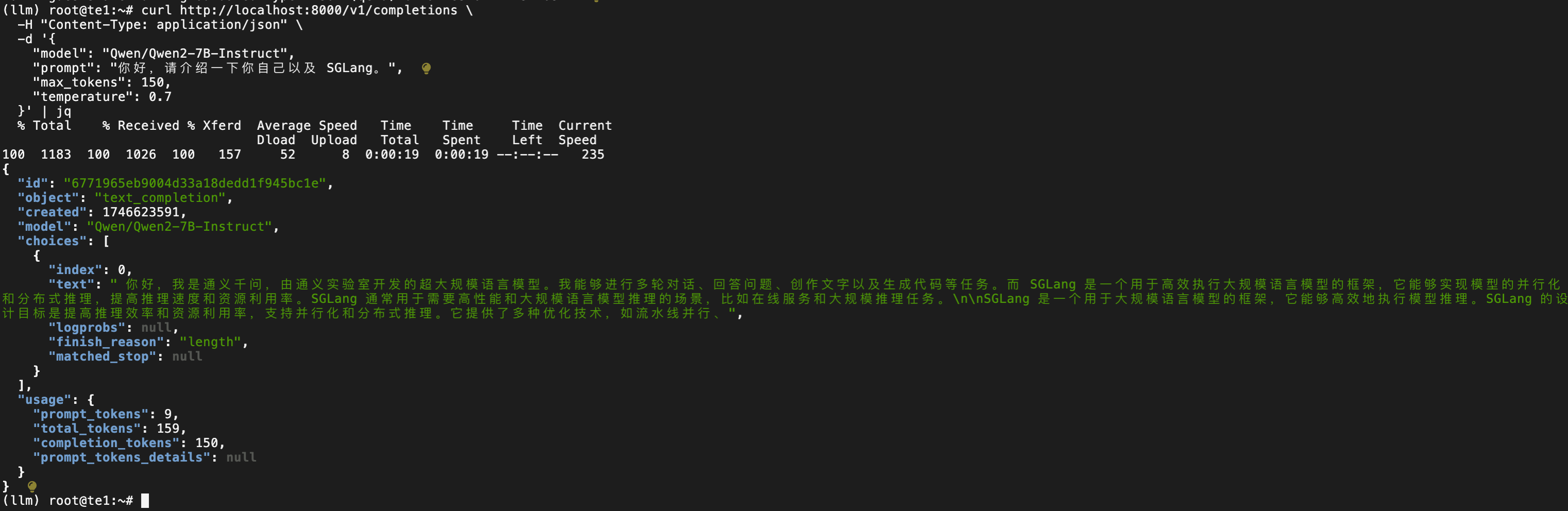
watch -n 0.5 nvidia-smi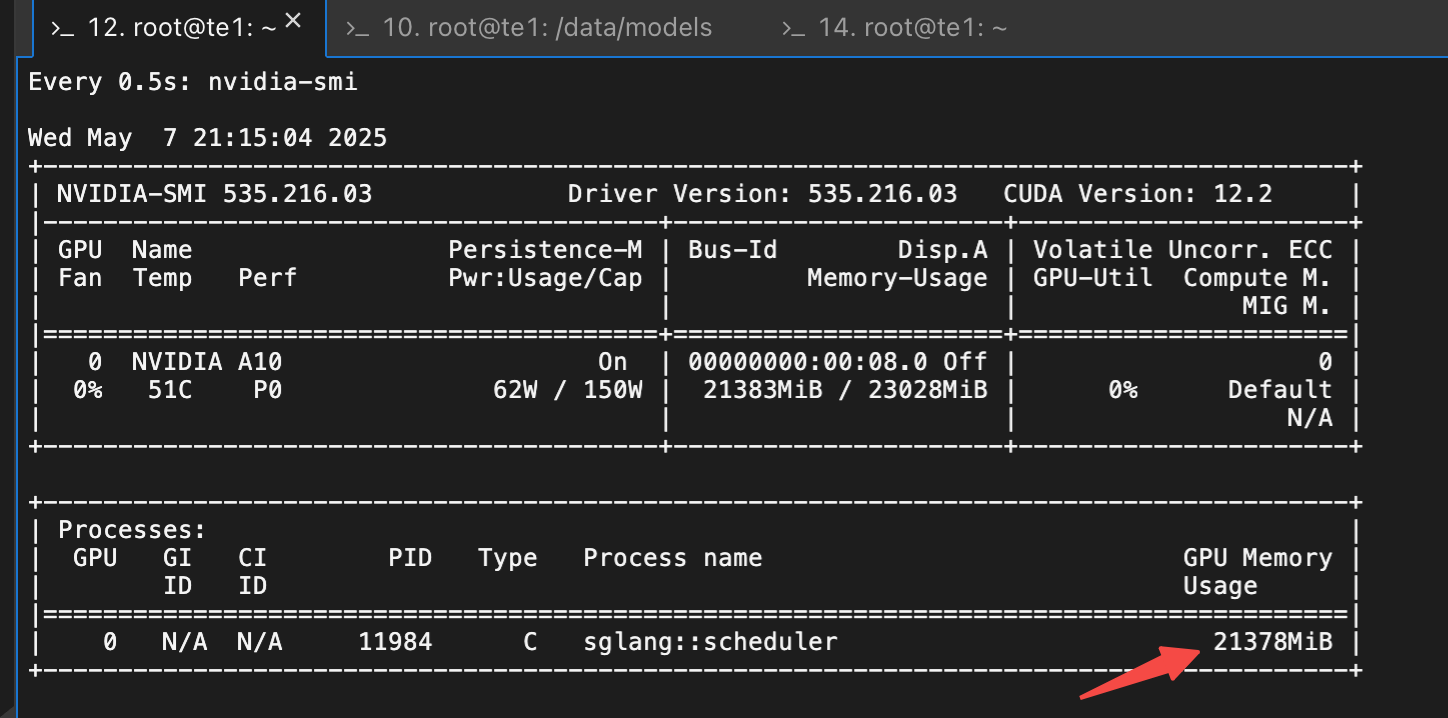
3.3 SGlang 推理模型张量并行
服务器申请: 2台 A10 先显卡的服务器即可
详情可以参考:
a) 基础环境配置
参考 3.1
b) 模型准备
参考 3.4 模型准备
c) 张量并行部署
# te1 节点执行
python -m sglang.launch_server \--model-path /data/models/qwen3-8b \--host 0.0.0.0 \--port 8000 \--log-level info \--trust-remote-code \--dtype auto \--mem-fraction-static 0.85 \--tensor-parallel-size 2 \--nnodes 2 \--node-rank 0 \--dist-init-addr "te1:29500" \--dist-timeout 600# te2 节点执行
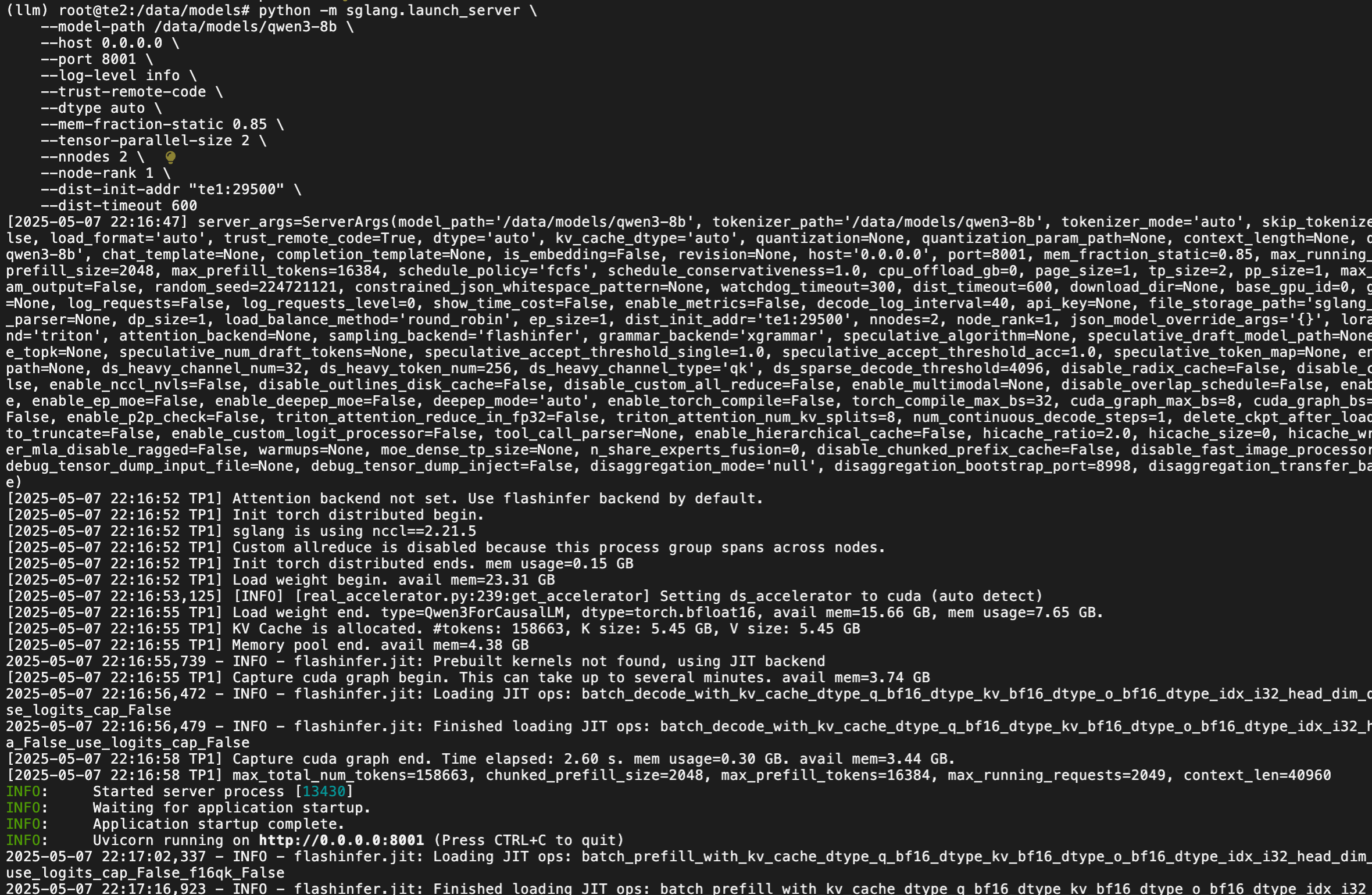
python -m sglang.launch_server \--model-path /data/models/qwen3-8b \--host 0.0.0.0 \--port 8001 \--log-level info \--trust-remote-code \--dtype auto \--mem-fraction-static 0.85 \--tensor-parallel-size 2 \--nnodes 2 \--node-rank 1 \--dist-init-addr "te1:29500" \--dist-timeout 600te1 日志
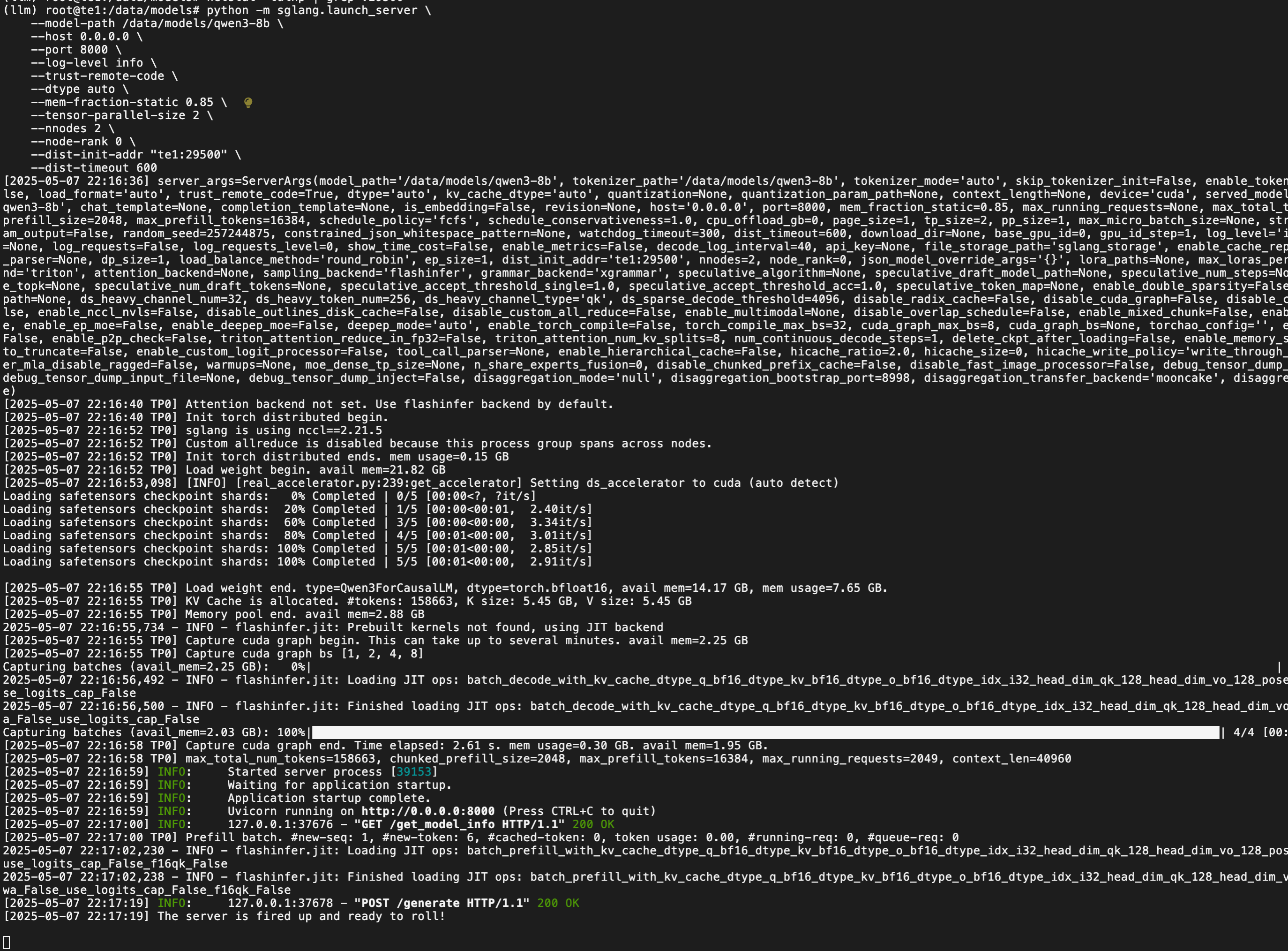
te2 日志
d) 测试推理模型
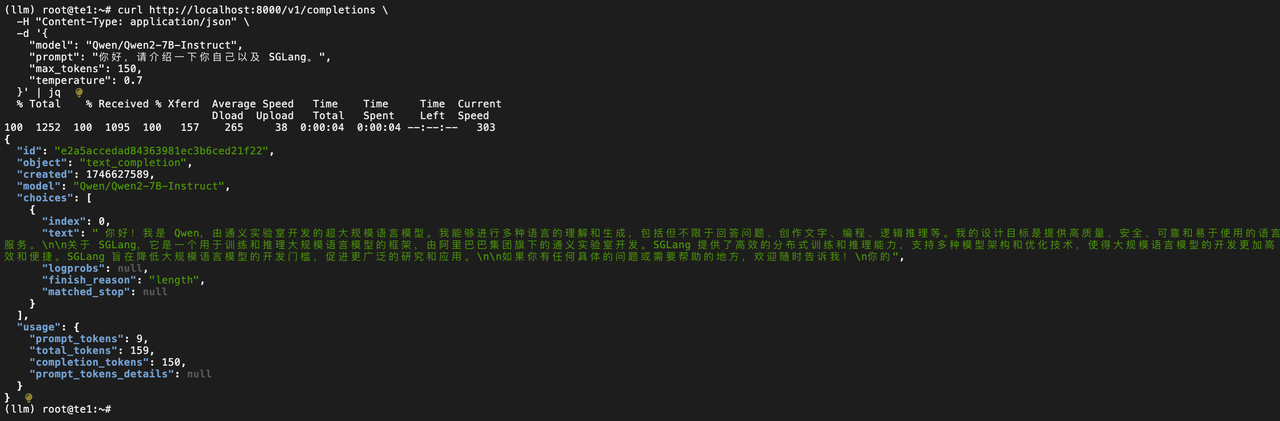
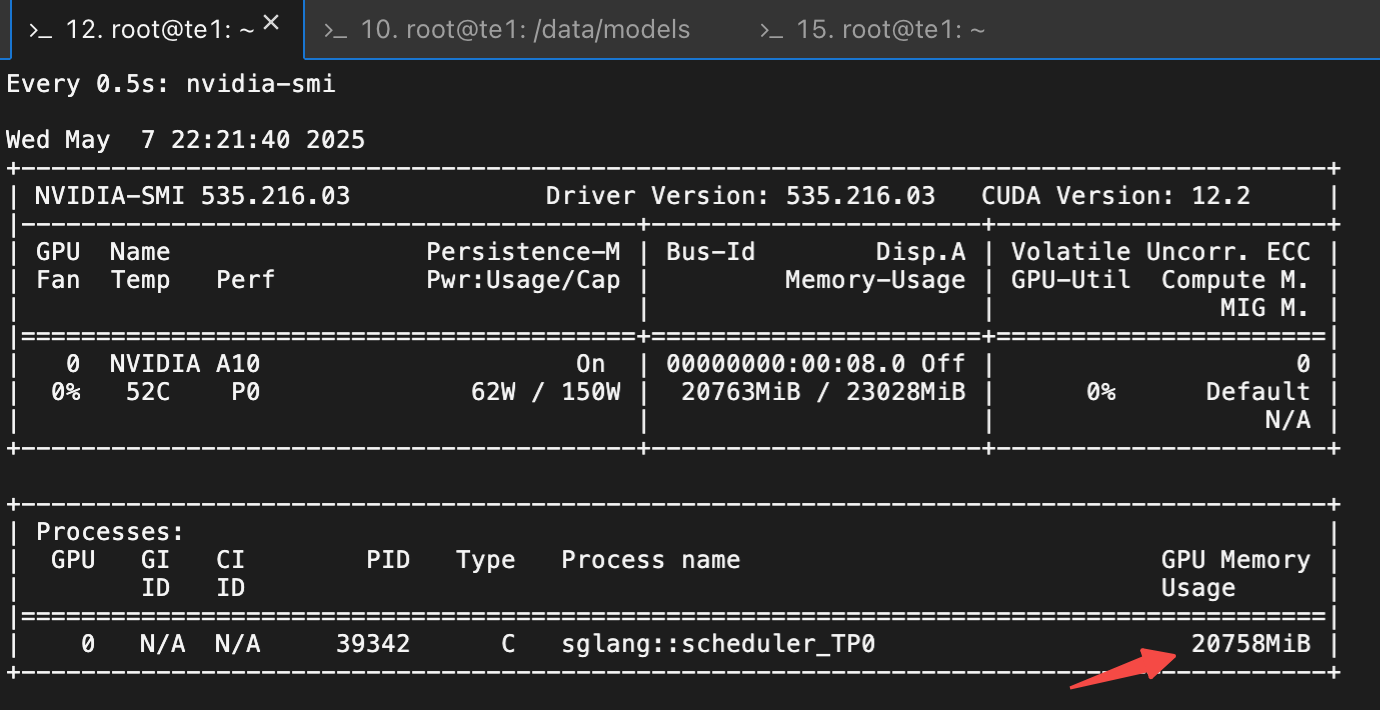
3.4 SGlang MoE 推理模型
服务器申请: 4台 A10 先显卡的服务器即可
a) 基础环境准备
参考 3.1
b) 模型准备 (MoE 架构的 Qwen3 -30B)
Qwen/Qwen3-30B-A3B 模型准备:
模型很大约 60Gi 要下载很久很久。
mkdir -p /data/models
huggingface-cli download Qwen/Qwen3-30B-A3B --resume-download --local-dir /data/models/Qwen3-30B-A3B
c) SGLang 部署 MoE Qwen3 30B
# te1 节点执行
python -m sglang.launch_server \--model-path /data/models/Qwen3-30B-A3B \--host 0.0.0.0 \--port 8000 \--log-level info \--trust-remote-code \--dtype auto \--mem-fraction-static 0.85 \--attention-backend flashinfer \--tensor-parallel-size 4 \--nnodes 4 \--node-rank 0 \--dist-init-addr "te1:29500" \--dist-timeout 600 \--enable-ep-moe \--ep-size 4# te2 节点执行
python -m sglang.launch_server \--model-path /data/models/Qwen3-30B-A3B \--host 0.0.0.0 \--port 8000 \--log-level info \--trust-remote-code \--dtype auto \--mem-fraction-static 0.85 \--attention-backend flashinfer \--tensor-parallel-size 4 \--nnodes 4 \--node-rank 1 \--dist-init-addr "te1:29500" \--dist-timeout 600--enable-ep-moe \--ep-size 4# te3 节点执行
python -m sglang.launch_server \--model-path /data/models/Qwen3-30B-A3B \--host 0.0.0.0 \--port 8000 \--log-level info \--trust-remote-code \--dtype auto \--mem-fraction-static 0.85 \--attention-backend flashinfer \--tensor-parallel-size 4 \--nnodes 4 \--node-rank 2 \--dist-init-addr "te1:29500" \--dist-timeout 600--enable-ep-moe \--ep-size 4# te4 节点执行
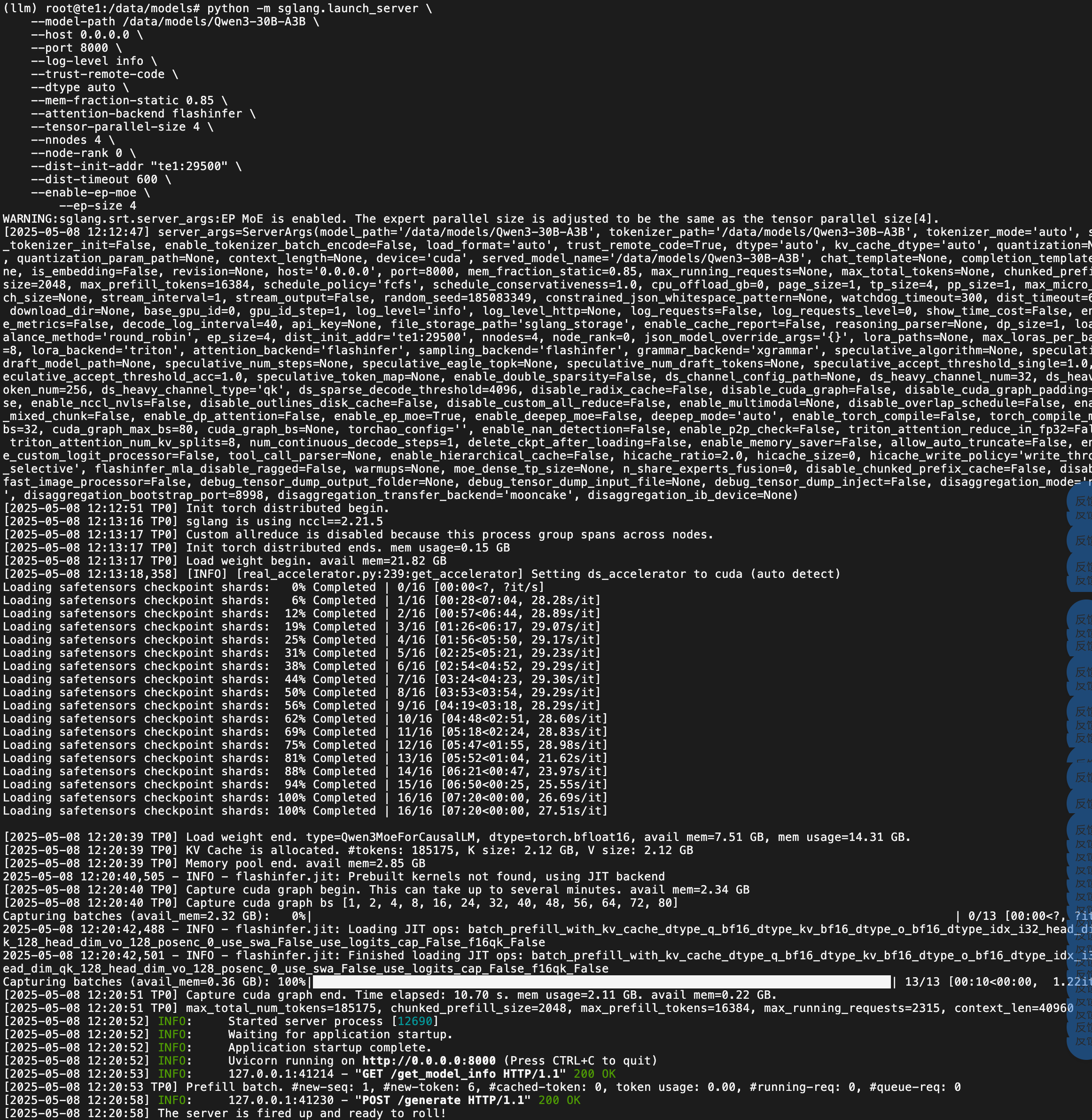
python -m sglang.launch_server \--model-path /data/models/Qwen3-30B-A3B \--host 0.0.0.0 \--port 8000 \--log-level info \--trust-remote-code \--dtype auto \--mem-fraction-static 0.85 \--attention-backend flashinfer \--tensor-parallel-size 4 \--nnodes 4 \--node-rank 3 \--dist-init-addr "te1:29500" \--dist-timeout 600--enable-ep-moe \--ep-size 4te1 节点上运行日志
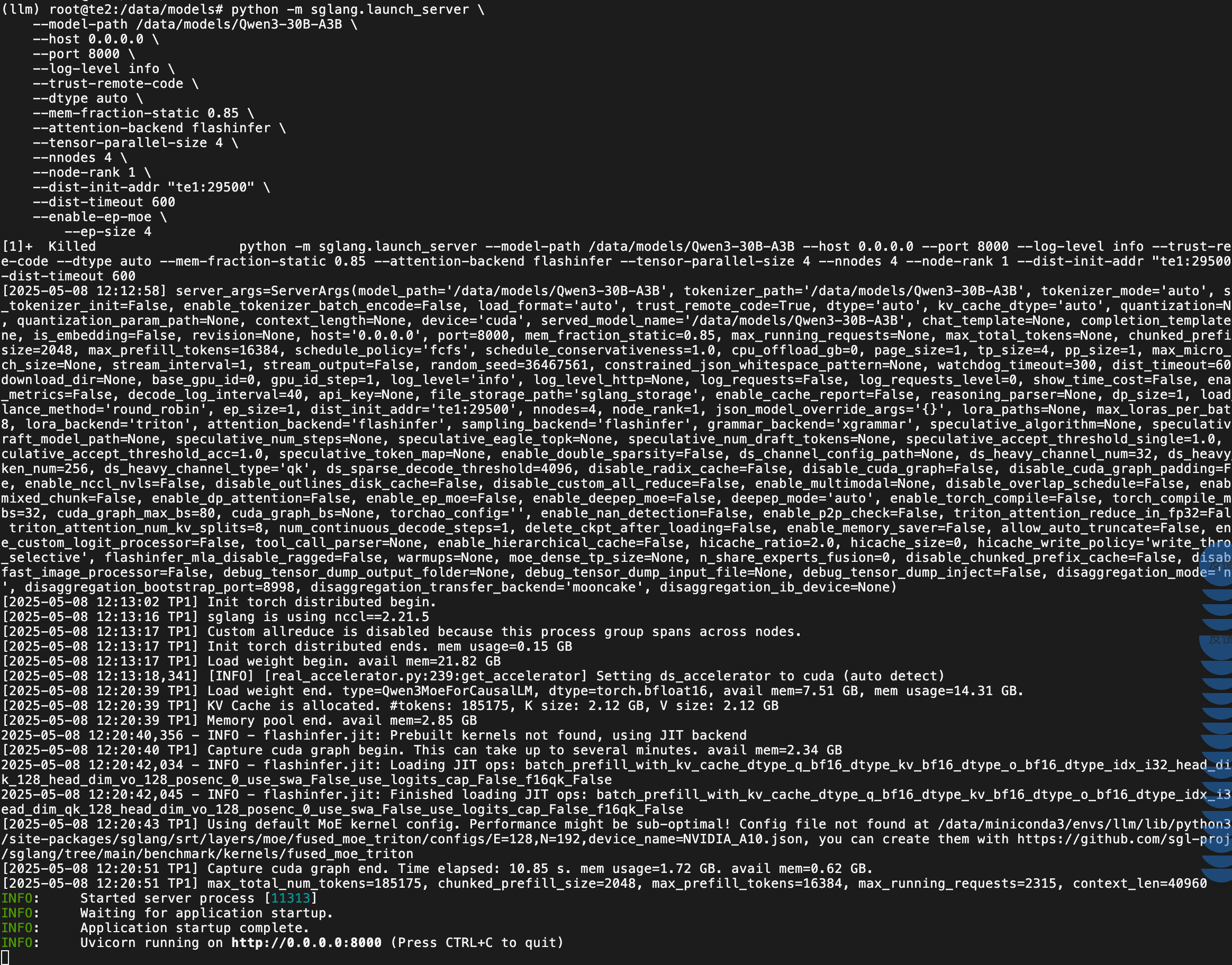
te2,te3,te4节点上日志都差不多 我就保留了 te2 的运行情况
d) 测试推理模型
curl http://localhost:8000/v1/completions \-H "Content-Type: application/json" \-d '{"model": "Qwen/Qwen2-7B-Instruct","prompt": "请介绍一下自己","max_tokens": 150,"temperature": 0.7}' | jq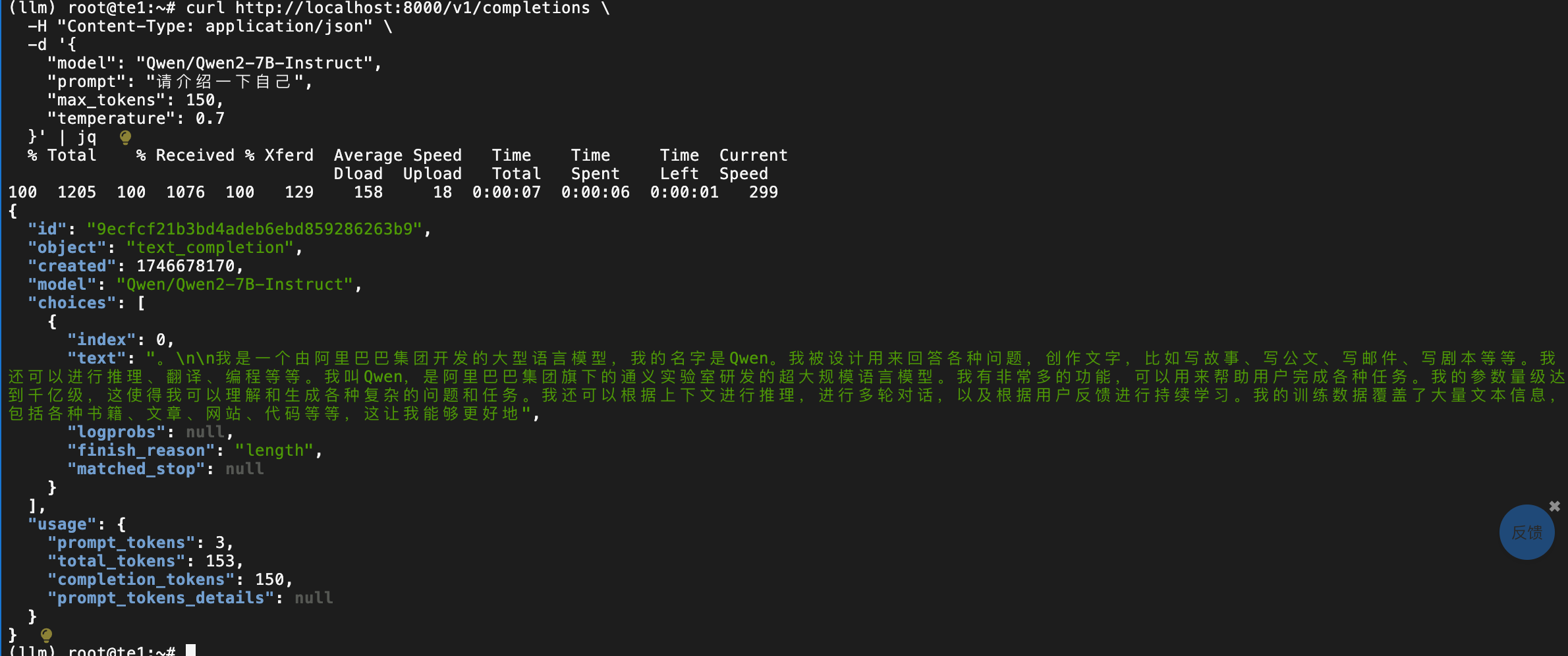
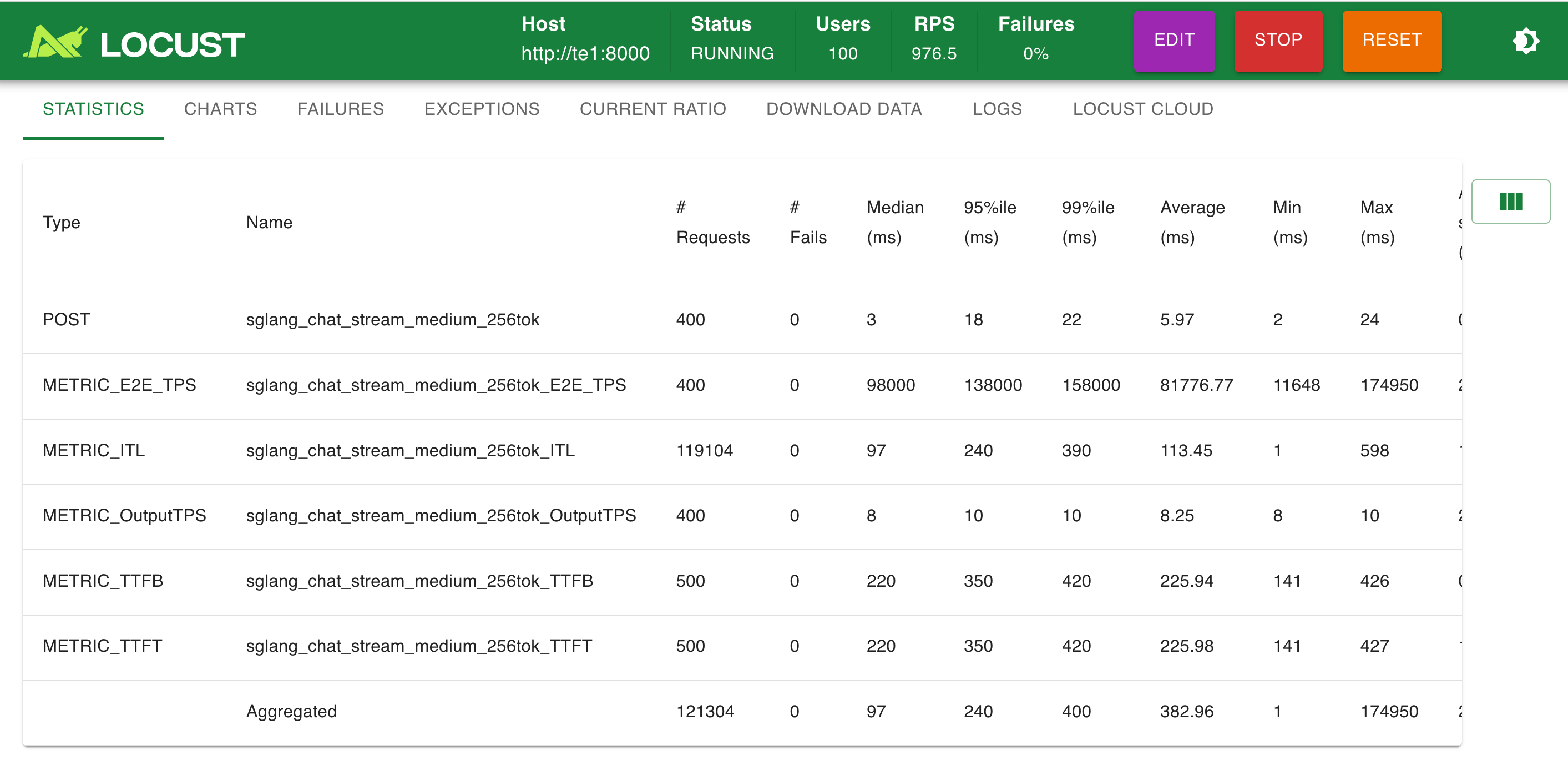
e) locust 性能测试
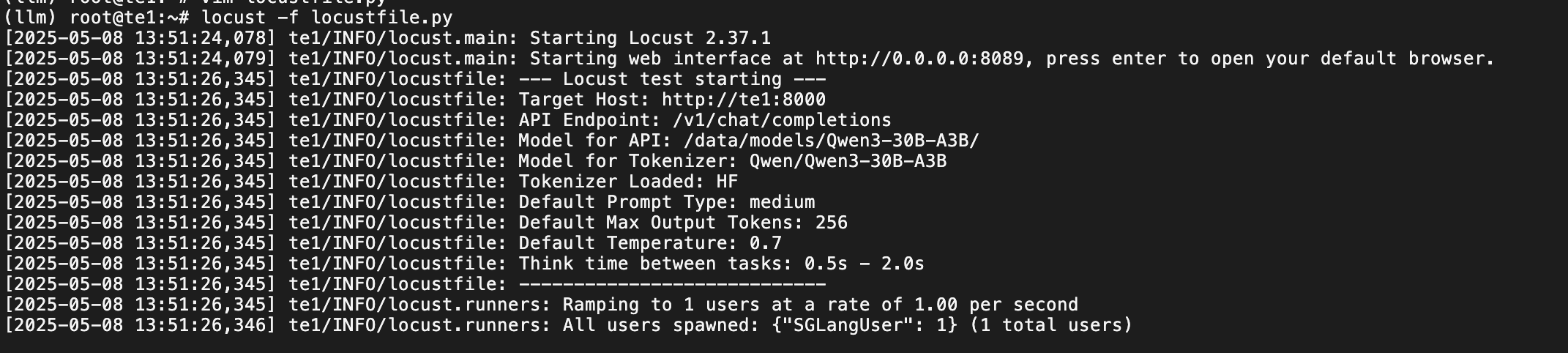
模拟 30 并发:
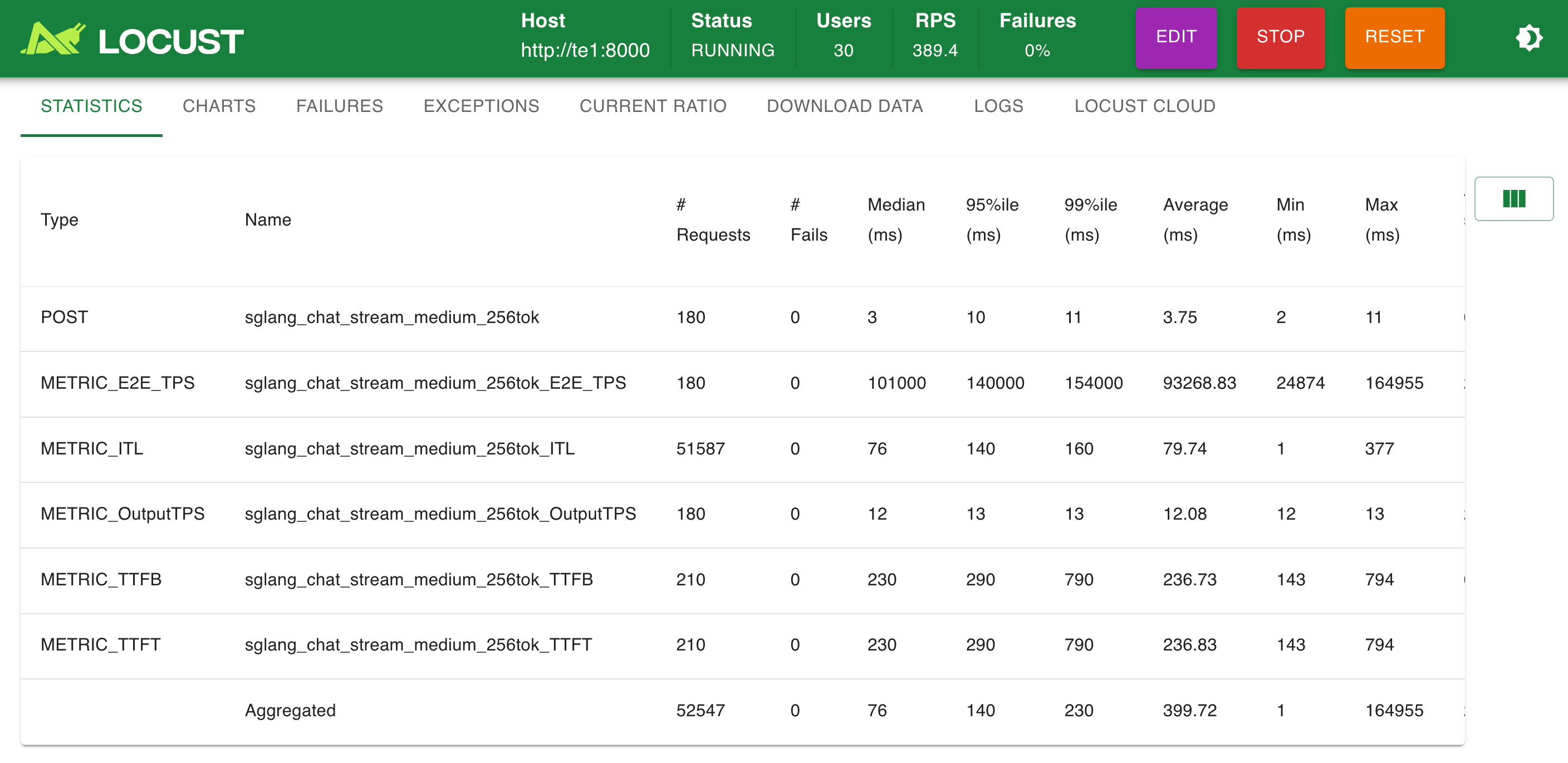
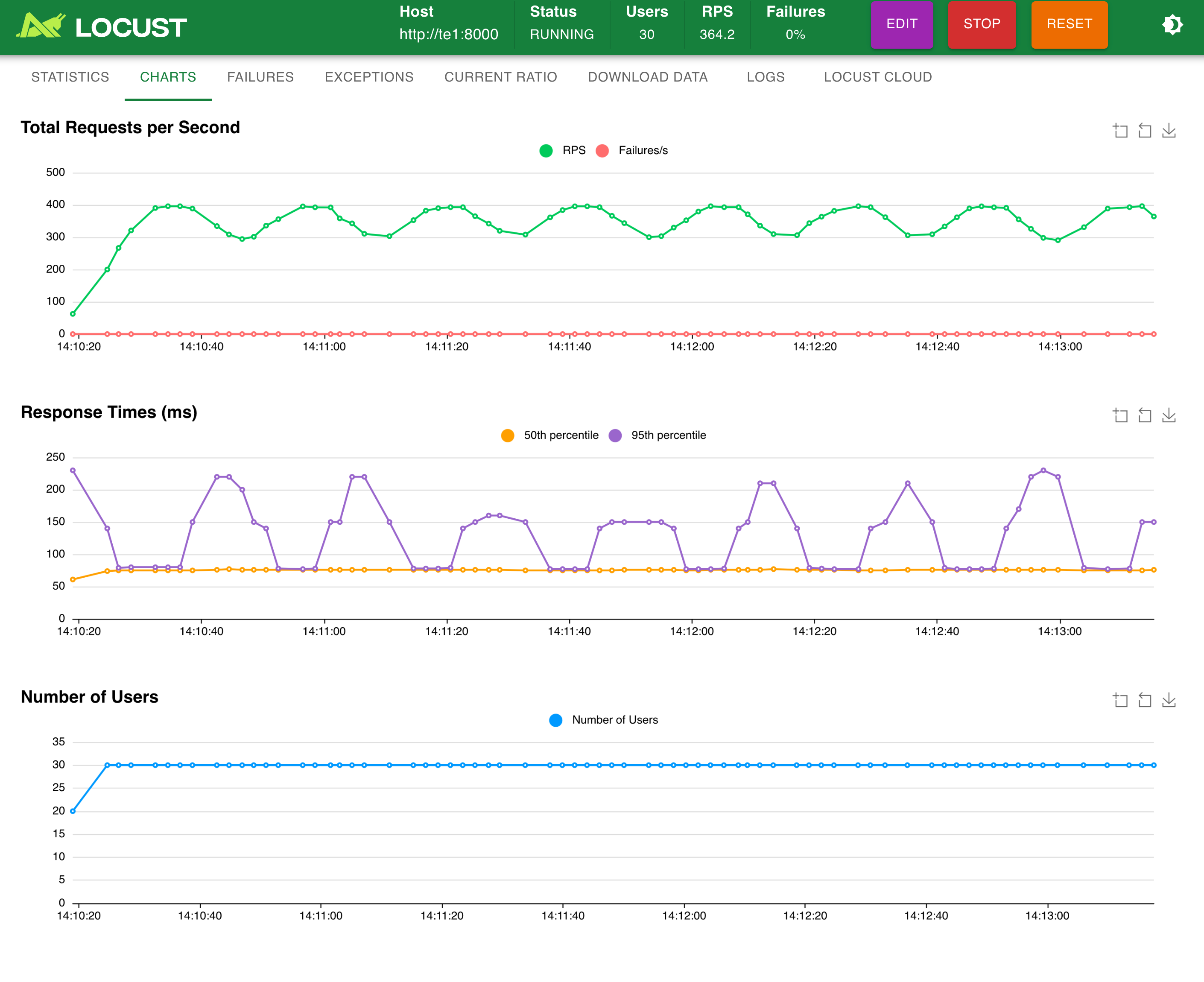
模拟 100 并发:
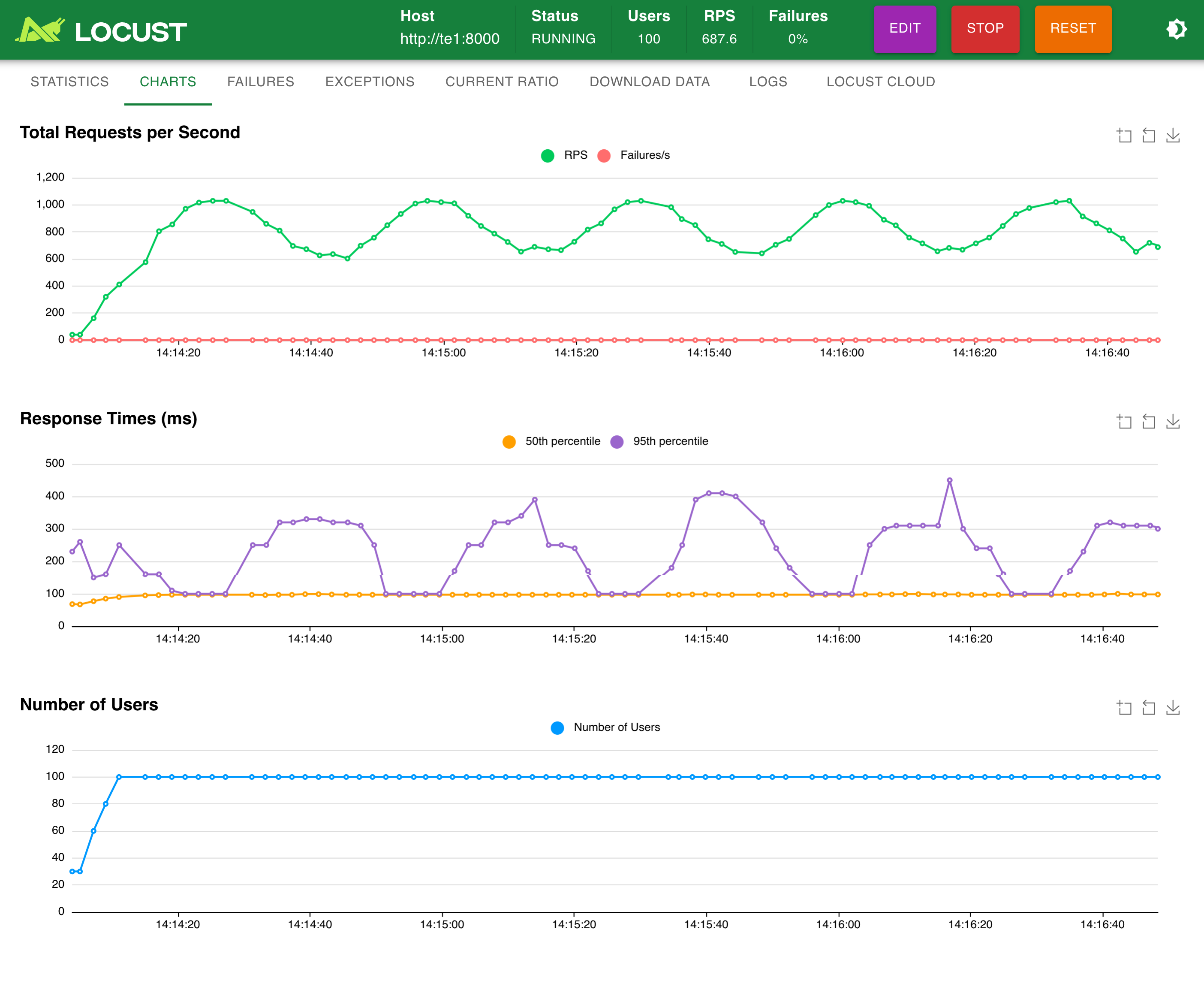
补充代码:
## 调试专用
## te1
watch nvidia-smi
kill -9 pid
netstat -tulnp | grep :8000
netstat -tulnp | grep :29500## te2
nvidia-smi
kill -9 pid
netstat -tulnp | grep :8001四、小结
SGlang技术还是相当成熟的,使用下来基本上没有什么 bug 或者莫名的报错,显存管理控制也是非常好。测试调试最顺畅的一次。针对SGlang部署推理模型 单机版,张量并行和 MoE 形式的都提供了完整的示例。最后也提供了性能测试的相关内容。
参考:
Server Arguments — SGLang![]() https://docs.sglang.ai/backend/server_arguments.htmlGitHub - sgl-project/sglang: SGLang is a fast serving framework for large language models and vision language models.SGLang is a fast serving framework for large language models and vision language models. - sgl-project/sglang
https://docs.sglang.ai/backend/server_arguments.htmlGitHub - sgl-project/sglang: SGLang is a fast serving framework for large language models and vision language models.SGLang is a fast serving framework for large language models and vision language models. - sgl-project/sglang![]() https://github.com/sgl-project/sglangLarge Language Models — SGLang
https://github.com/sgl-project/sglangLarge Language Models — SGLang![]() https://docs.sglang.ai/supported_models/generative_models.htmlhttps://huggingface.co/Qwen/Qwen3-30B-A3B
https://docs.sglang.ai/supported_models/generative_models.htmlhttps://huggingface.co/Qwen/Qwen3-30B-A3B![]() https://huggingface.co/Qwen/Qwen3-30B-A3B大语言模型中的MoE - 哥不是小萝莉 - 博客园1.概述 MoE代表“混合专家模型”(Mixture of Experts),这是一种架构设计,通过将不同的子模型(即专家)结合起来进行任务处理。与传统的模型相比,MoE结构能够动态地选择并激活其中一部分专家,从而显著提升模型的效率和性能。尤其在计算和参数规模上,MoE架构能够在保持较低计算开销的同
https://huggingface.co/Qwen/Qwen3-30B-A3B大语言模型中的MoE - 哥不是小萝莉 - 博客园1.概述 MoE代表“混合专家模型”(Mixture of Experts),这是一种架构设计,通过将不同的子模型(即专家)结合起来进行任务处理。与传统的模型相比,MoE结构能够动态地选择并激活其中一部分专家,从而显著提升模型的效率和性能。尤其在计算和参数规模上,MoE架构能够在保持较低计算开销的同![]() https://www.cnblogs.com/smartloli/p/18577833
https://www.cnblogs.com/smartloli/p/18577833
https://huggingface.co/blog/zh/moe![]() https://huggingface.co/blog/zh/moe
https://huggingface.co/blog/zh/moe