机器学习 数据集
数据集
- 1. scikit-learn工具介绍
- 1.1 scikit-learn安装
- 1.2 Scikit-learn包含的内容
- 2 数据集
- 2.1 sklearn玩具数据集介绍
- 2.2 sklearn现实世界数据集介绍
- 2.3 sklearn加载玩具数据集
- 示例1:鸢尾花数据
- 示例2:分析糖尿病数据集
- 2.4 sklearn获取现实世界数据集
- 示例:获取20分类新闻数据
- 2.5数据集的划分
- (1) 函数
- (2)示例
- 列表数据集划分
- 二维数组数据集划分
- DataFrame数据集划分
- 字典数据集划分
- 鸢尾花数据集划分
- 现实世界数据集划分
1. scikit-learn工具介绍

- Python语言机器学习工具
- Scikit-learn包括许多智能的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API接口函数
- Scikit-learn官网:https://scikit-learn.org/stable/#
- Scikit-learn中文文档:https://scikitlearn.com.cn/
- scikit-learn中文社区
1.1 scikit-learn安装
参考以下安装教程:https://www.sklearncn.cn/62/
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn
1.2 Scikit-learn包含的内容
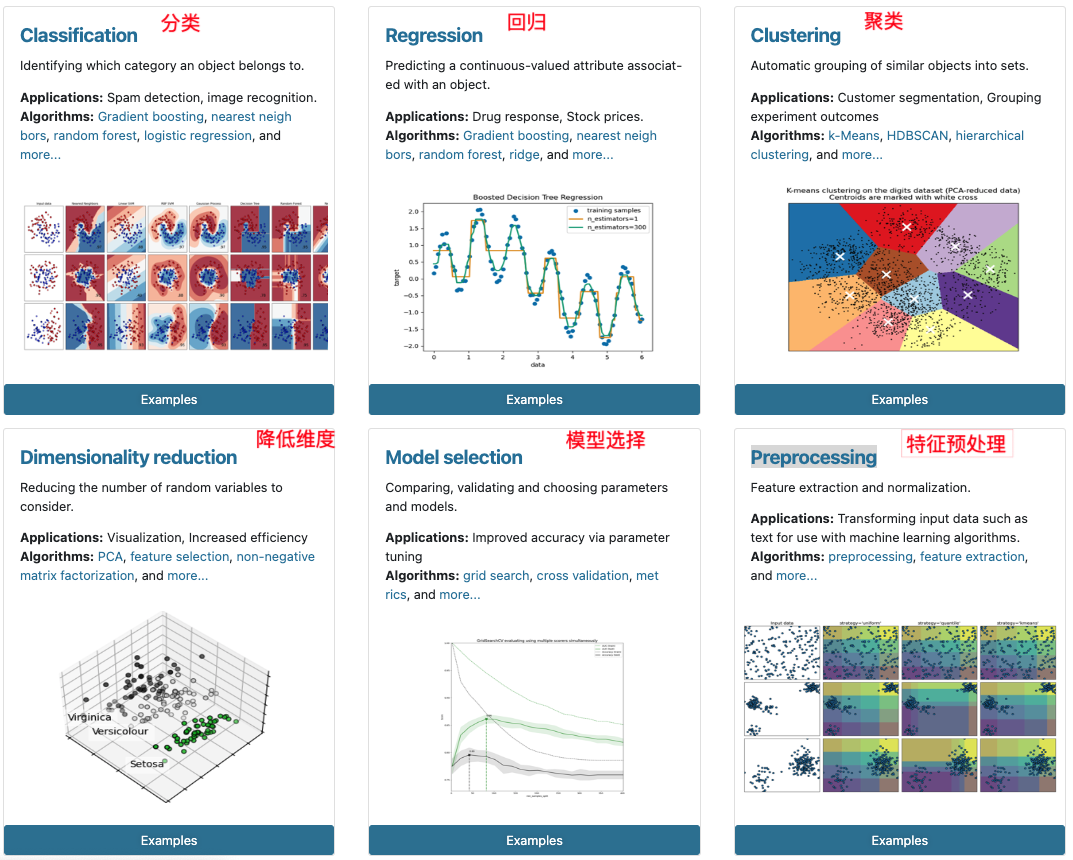
2 数据集
2.1 sklearn玩具数据集介绍
数据量小,数据在sklearn库的本地,只要安装了sklearn,不用上网就可以获取
2.2 sklearn现实世界数据集介绍
数据量大,数据只能通过网络获取

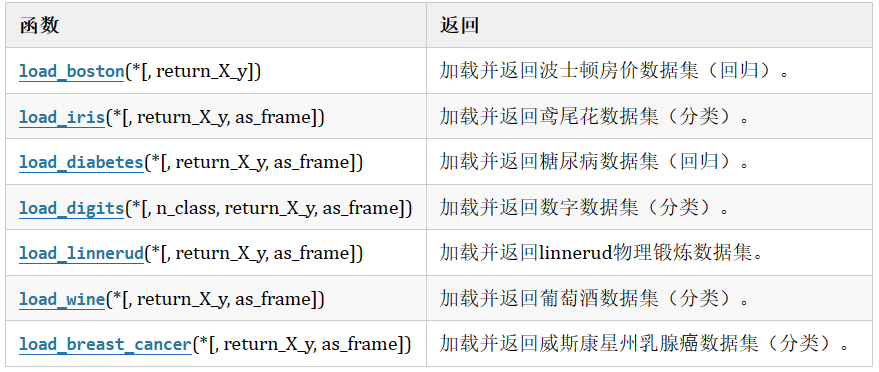
2.3 sklearn加载玩具数据集
示例1:鸢尾花数据
from sklearn.datasets import load_iris
iris = load_iris()#鸢尾花数据
鸢尾花数据集介绍
特征有:
花萼长 sepal length
花萼宽sepal width
花瓣长 petal length
花瓣宽 petal width
三分类:
0-Setosa山鸢尾
1-versicolor变色鸢尾
2-Virginica维吉尼亚鸢尾
- sklearn.datasets.load_iris():加载并返回鸢尾花数据集

sklearn数据集的使用
sklearn数据集返回值介绍
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是[n_samples * n_features]的二维numpy.ndarry数组
target:标签数组,是n_samples的一维numpy.ndarry数组
DESCR:数据描述
feature_names:特征名,新闻数据,手写数字、回归数据集没有
target_names:标签名
代码如下:
#获取鸢尾花数据集的库
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
# 获取鸢尾花数据集
iris=load_iris()
# iris字典中有几个重要属性:
# data 特征
data=iris.data
# print('鸢尾花数据集的前5条数据',data[:5])
'''[[5.1 3.5 1.4 0.2][4.9 3. 1.4 0.2][4.7 3.2 1.3 0.2][4.6 3.1 1.5 0.2][5. 3.6 1.4 0.2]]'''# feature_names 特征描述
feature_names=iris.feature_names
print(feature_names)#['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
# target 目标
target=iris.target
# 获取前五条数据的目标值
print(target[:5])# [0 0 0 0 0]
# target_names 目标描述
target_names=iris.target_names
print(target_names) #['setosa(山鸢尾)' 'versicolor(变色鸢尾花)' 'virginica(维基利亚鸢尾)']
# DESCR 数据集的描述
res=iris.DESCR
print(res)
# filename 下后到本地保存后的文件名
iris_filename=iris.filename
print(iris_filename)#iris.csv示例2:分析糖尿病数据集
这是回归数据集,有442个样本,有可能就有442个目标值。
代码如下:
# 获取糖尿病数据集的库
from sklearn.datasets import load_diabetes
import numpy as np
import pandas as pd
dia=load_diabetes()
# print(dia)
data=dia.data
# print('糖尿病数据的特征的前五条',data[:5])
'''
糖尿病数据的特征的前五条 [[ 0.03807591 0.05068012 0.06169621 0.02187239 -0.0442235 -0.03482076-0.04340085 -0.00259226 0.01990749 -0.01764613][-0.00188202 -0.04464164 -0.05147406 -0.02632753 -0.00844872 -0.019163340.07441156 -0.03949338 -0.06833155 -0.09220405][ 0.08529891 0.05068012 0.04445121 -0.00567042 -0.04559945 -0.03419447-0.03235593 -0.00259226 0.00286131 -0.02593034][-0.08906294 -0.04464164 -0.01159501 -0.03665608 0.01219057 0.02499059-0.03603757 0.03430886 0.02268774 -0.00936191][ 0.00538306 -0.04464164 -0.03638469 0.02187239 0.00393485 0.015596140.00814208 -0.00259226 -0.03198764 -0.04664087]]
'''
#获取特征名
feature_names=dia.feature_names
print(feature_names) #['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
#获取目标值
target=dia.target
print(target[:5]) #[151. 75. 141. 206. 135.]
#获取目标名
# target_names=dia.target_names
# print(target_names[:5]) 因为糖尿病数据集是回归的,所以它的目标值是线上的点没有对应的名称
#获取糖尿病的描述
res=dia.DESCR
# print(res)注意:
- 因为糖尿病数据集是回归的,所以它的目标值是线上的点没有对应的名称
2.4 sklearn获取现实世界数据集
(1)所有现实世界数据,通过网络才能下载后,默认保存的目录可以使用下面api获取。实际上就是保存到home目录
from sklearn import datasets
datasets.get_data_home() #查看数据集默认存放的位置
(2)下载时,有可能回为网络问题而出问题,要“小心”的解决网络问题,不可言……
(3)第一次下载会保存的硬盘中,如果第二次下载,因为硬盘中已经保存有了,所以不会再次下载就直接加载成功了。
示例:获取20分类新闻数据
(1)使用函数: sklearn.datasets.fetch_20newsgroups(data_home,subset)
(2)函数参数说明:
(2.1) data_home
None这是默认值,下载的文件路径为 “C:/Users/ADMIN/scikit_learn_data/20news-bydate_py3.pkz”
自定义路径例如 “./src”, 下载的文件路径为“./20news-bydate_py3.pkz”
(2.2) subset
“train”,只下载训练集
“test”,只下载测试集
“all”, 下载的数据包含了训练集和测试集
(2.3) return_X_y,决定着返回值的情况
False,这是默认值
True,
(3) 函数返值说明:
当参数return_X_y值为False时, 函数返回Bunch对象,Bunch对象中有以下属性*data:特征数据集, 长度为18846的列表list, 每一个元素就是一篇新闻内容, 共有18846篇*target:目标数据集,长度为18846的数组ndarray, 第一个元素是一个整数,整数值为[0,20)*target_names:目标描述,长度为20的list*filenames:长度为18846的ndarray, 元素为字符串,代表新闻的数据位置的路径当参数return_X_y值为True时,函数返回值为元组,元组长度为2, 第一个元素值为特征数据集,第二个元素值为目标数据集
代码
import sklearn.datasets as datasets
from sklearn.datasets import fetch_20newsgroups
import numpy as np
import pandas as pd
path=datasets.get_data_home()
news=fetch_20newsgroups(data_home='./src',subset='all')
# print(news.data[0])
# print(news.target_names[:5])data,target=fetch_20newsgroups(data_home='./src',subset='all',return_X_y=True)
2.5数据集的划分
"""
1. 复习不定长参数
一个"*" 把多个参数转为元组
两个"*" 把多个关键字参数转为字典
"""
def m(*a, **b):print(a) #('hello', 123)print(b) #{'name': '小王', 'age': 30, 'sex': '男'}
m("hello", 123, name="小王", age=30, sex="男")2. 复习列表值的解析
list = [11,22,33]
a, b, c = list # a=11 b=22 c=33
a, b = ["小王", 30] #a="小王" b=30
(1) 函数
sklearn.model_selection.train_test_split(*arrays,**options)
参数
(1) *array 这里用于接收1到多个"列表、numpy数组、稀疏矩阵或padas中的DataFrame"。
(2) **options, 重要的关键字参数有:test_size 值为0.0到1.0的小数,表示划分后测试集占的比例random_state 值为任意整数,表示随机种子,使用相同的随机种子对相同的数据集多次划分结果是相同的。否则多半不同strxxxx 分层划分,填y
2 返回值说明返回值为列表list, 列表长度与形参array接收到的参数数量相关联, 形参array接收到的是什么类型,list中对应被划分出来的两部分就是什么类型
(2)示例
列表数据集划分
因为随机种子都使用了相同的整数(22),所以划分的划分的情况是相同的。
代码如下:
# 导入数据集划分的库
from sklearn.model_selection import train_test_split
# 1.列表数据集的划分
x=[1,2,3,4,5,6,7,8,9]#作为特征值
y=['1a','2a','3a','4a','5a','6a','7a','8a','9a']#作为目标值
# x,y的长度要一致
# 直接对特征值进行划分为训练集0.8和测试集0.2
x_train,x_test=train_test_split(x,test_size=0.2,shuffle=True,random_state=5)
# shuffle:表示是否打乱,random_state:设置随机种子
# print(x_train,x_test)#[9, 5, 8, 2, 1, 3, 6] [7, 4]顺序是随机的
# 对特征值和目标值进行划分为训练集0.8和测试集0.2
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,shuffle=True,random_state=5)
print(x_train,x_test)#[9, 8, 2, 1, 6, 7, 4] [3, 5]
print(y_train,y_test)#['9a', '8a', '2a', '1a', '6a', '7a', '4a'] ['3a', '5a']
# 划分时特征值和目标值划分的位置是一一对应的
注意:
- 1.x(特征值),y(目标值)的长度要一致
- 2.划分时特征值和目标值划分的位置是一一对应的
二维数组数据集划分
# 2.二维数组数据集划分
x=np.arange(16).reshape(4,4)
y=np.arange(0,160,10).reshape(4,4)
# print(x)
# print(y)
# x,y的长度要一致
# 直接对特征值进行划分为训练集0.8和测试集0.2
x_train,x_test=train_test_split(x,test_size=0.2,shuffle=True,random_state=5)
# shuffle:表示是否打乱,random_state:设置随机种子
# print(x_train,x_test)#[9, 5, 8, 2, 1, 3, 6] [7, 4]顺序是随机的
# 对特征值和目标值进行划分为训练集0.8和测试集0.2
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,shuffle=True,random_state=5)
print(x_train)
print("="*20)
print(x_test)
print("="*20)
print(y_train)
print("="*20)
print(y_test)
'''
[[ 4 5 6 7][ 8 9 10 11][12 13 14 15]]
====================
[[0 1 2 3]]
====================
[[ 40 50 60 70][ 80 90 100 110][120 130 140 150]]
====================
[[ 0 10 20 30]]
'''
DataFrame数据集划分
可以划分DataFrame, 划分后的两部分还是DataFrame
x= np.arange(1, 16, 1)
x.shape=(5,3)
df = pd.DataFrame(x, index=[1,2,3,4,5], columns=["one","two","three"])
# print(df)x_train,x_test = train_test_split(df, test_size=0.4, random_state=22)
print("\n", x_train)
print("\n", x_test)
'''one two three
4 10 11 12
1 1 2 3
5 13 14 15one two three
2 4 5 6
3 7 8 9
'''
字典数据集划分
可以划分非稀疏矩阵
用于将字典列表转换为特征向量。这个转换器主要用于处理类别数据和数值数据的混合型数据集
1.对于类别特征DictVectorizer 会为每个不同的类别创建一个新的二进制特征,如果原始数据中的某个样本具有该类别,则对应的二进制特征值为1,否则为0。
2.对于数值特征保持不变,直接作为特征的一部分
这样,整个数据集就被转换成了一个适合机器学习算法使用的特征向量形式
代码如下:
# 字典数据集的划分
# 引入字典向量化的模块
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
# 创建一个字典
data = [{'city':'成都', 'age':30, 'temperature':20}, {'city':'重庆','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80},{'city':'上海', 'age':22, 'temperature':70},{'city':'成都', 'age':72, 'temperature':40},]
# 将字典进行向量化并转换为稀疏矩阵
transfer=DictVectorizer(sparse=True)
# 将data进行向量化
data_new=transfer.fit_transform(data)
# print("data_new\n",data_new)
'''
<Compressed Sparse Row sparse matrix of dtype 'float64'with 15 stored elements and shape (5, 6)>Coords Values(0, 0) 30.0(0, 3) 1.0(0, 5) 20.0(1, 0) 33.0(1, 4) 1.0(1, 5) 60.0(2, 0) 42.0(2, 2) 1.0(2, 5) 80.0(3, 0) 22.0(3, 1) 1.0(3, 5) 70.0(4, 0) 72.0(4, 3) 1.0(4, 5) 40.0
'''
data=data_new.toarray()
# print(x,type(x))
'''
[[30. 0. 0. 1. 0. 20.][33. 0. 0. 0. 1. 60.][42. 0. 1. 0. 0. 80.][22. 1. 0. 0. 0. 70.][72. 0. 0. 1. 0. 40.]] <class 'numpy.ndarray'>'''
x=data[:,:5]
y=data[:,5]
# print(x)
# print(y)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,shuffle=True,random_state=42)
print(x_train.shape,x_test.shape)
print(y_train.shape,y_test.shape)
print(y_train)
'''
(4, 5) (1, 5)
(4,) (1,)
[40. 80. 20. 70.]
'''
注意:
- 因为机器学习时只能对数字进行处理字典中不是数字的键不能直接处理,需要进行特征处理(向量化就是把他转化为数字)
鸢尾花数据集划分
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
x,y=load_iris(return_X_y=True)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,shuffle=True,random_state=42)
print(x_train.shape,x_test.shape)
print(y_train.shape,y_test.shape)
print(y_train)
'''
(120, 4) (30, 4)
(120,) (30,)
[0 0 1 0 0 2 1 0 0 0 2 1 1 0 0 1 2 2 1 2 1 2 1 0 2 1 0 0 0 1 2 0 0 0 1 0 12 0 1 2 0 2 2 1 1 2 1 0 1 2 0 0 1 1 0 2 0 0 1 1 2 1 2 2 1 0 0 2 2 0 0 0 12 0 2 2 0 1 1 2 1 2 0 2 1 2 1 1 1 0 1 1 0 1 2 2 0 1 2 2 0 2 0 1 2 2 1 2 11 2 2 0 1 2 0 1 2]'''
现实世界数据集划分
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
import numpy as np
news = fetch_20newsgroups(data_home=None, subset='all')
list = train_test_split(news.data, news.target,test_size=0.2, random_state=22)
# """
# 返回值是一个list:其中有4个值,分别为训练集特征、测试集特征、训练集目标、测试集目标
# 与iris相同点在于x_train和x_test是列表,而iris是
# """
x_train, x_test, y_train, y_test = list
#打印结果为: 15076 3770 (15076,) (3770,)
print(len(x_train), len(x_test), y_train.shape, y_test.shape)