Hadoop MapReduce 图文代码讲解
一、MapReduce原理
首先要了解一下MapReduce的几个过程,每个数据集中需要编写的逻辑会有所不同,但是大致是差不多的
1、MapReduce大致为这几个过程:
1、读取数据集并根据文件大小128MB拆分成多个map同时进行下面步骤
2、Map: 匹配和数据筛选: Map输入(MI)+ Map输出(MO)
3、Shuffle&Sort:洗牌排序阶段,Hadoop自带的方便后续合并
4、Reduce: 合并和数据处理: Reduce输入(RI)+ Reduce输出(RO)
在整个MapReduce过程中数据以键值对形式保存传输
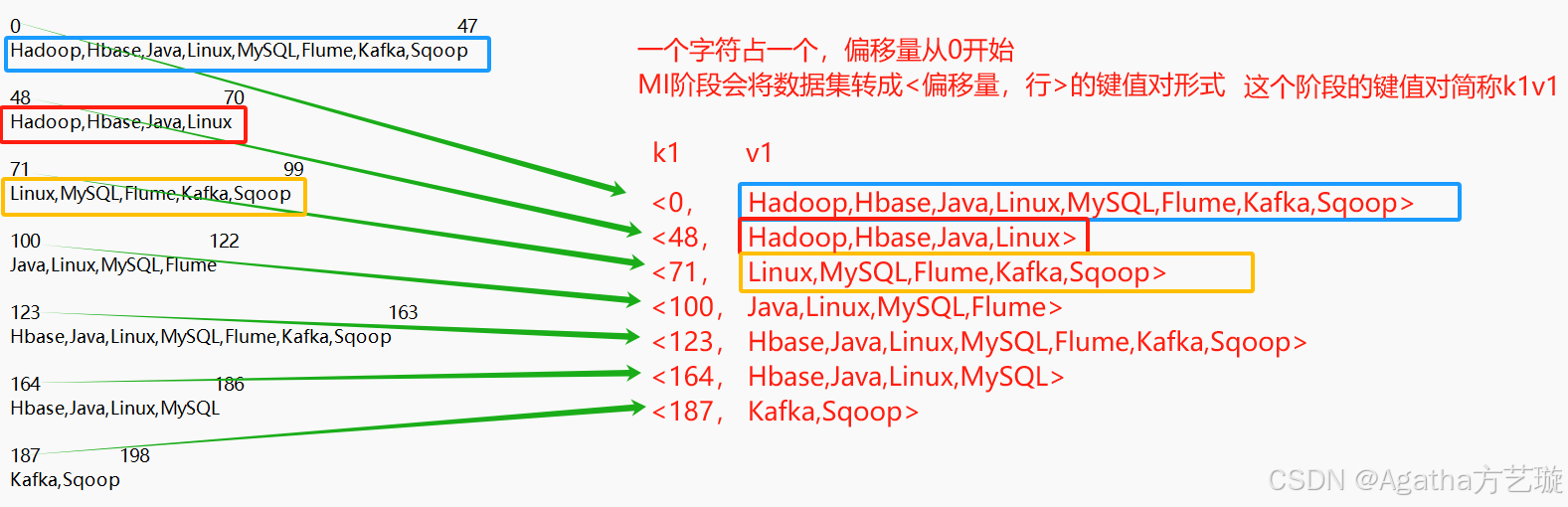
MI阶段:会将数据集输入并且转成偏移量和行的关系
MO阶段:会将MI的键值对里有用的数据转成键值对关系,这里是需要写代码写逻辑
RI阶段:会将MO的数据合并
RO阶段:会将RI阶段数据进行逻辑算法处理,这里是需要写代码写逻辑
二、MapReduce单词计数例子
1、图文解析
a) 首先,在自己电脑D盘创一个文本文件WordCount.txt,内容为:
Hadoop,Hbase,Java,Linux,MySQL,Flume,Kafka,Sqoop
Hadoop,Hbase,Java,Linux
Linux,MySQL,Flume,Kafka,Sqoop
Java,Linux,MySQL,Flume
Hbase,Java,Linux,MySQL,Flume,Kafka,Sqoop
Hbase,Java,Linux,MySQL
Kafka,Sqoop
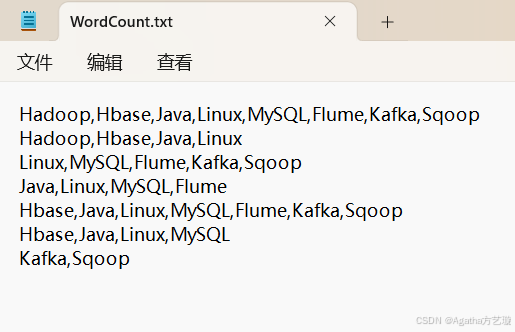
现在,要求实现计算不同的单词出现了几次
b) 实现过程
1、MI阶段:会将数据集输入并且转成偏移量和行的关系
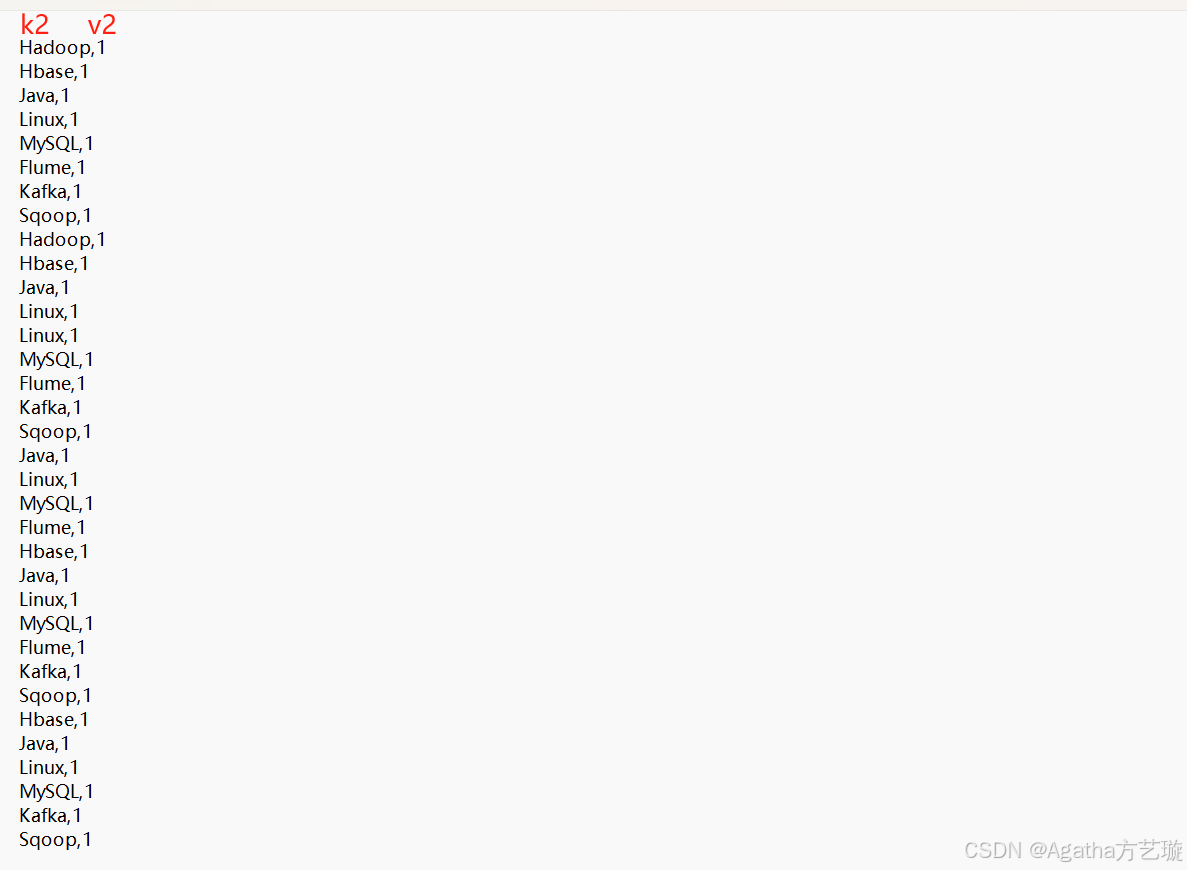
2、MO阶段:会将MI的键值对里有用的数据转成键值对关系,这里是需要写代码写逻辑,在这里我们要实现单词计数,有用的东西就是单词本身以及个数,k1是没用的,所以在这个阶段需要把v1的字符串按照分隔符拆成数组,把单词通过数组循环取出来当作k2,并且把每一个单词赋值数量为1当作v2
3、Shuffle&Sort阶段:洗牌排序

4、RI阶段:会将MO的数据合并

5、RO阶段:会将RI阶段数据进行逻辑算法处理,这里是需要写代码写逻辑,此例子需要计数,所以把v3数据相加,k3直接转k4

2、代码解析
现在图文理解了来看看代码的过程
一共要写三坨代码,Map的,Reduce的以及Driver提交程序

在写代码之前要了解Hadoop代码中数据类型有变化,,String对应Text,其他类型全部加上后缀Writeable,例如java中如果是int类型,MapReduce中写代码对应就是IntWriteable,为啥不一样呢,因为hadoop分布式中数据会跨电脑传输处理,会涉及到互联网带宽之类的,普通java没发传,不安全,而hadoop类型传输时可以序列化反序列化(加密解密)
a、Map部分:
1)首先先了解下别人写的代码的规则使用方式:
Map代码中:
1、要继承Mapper
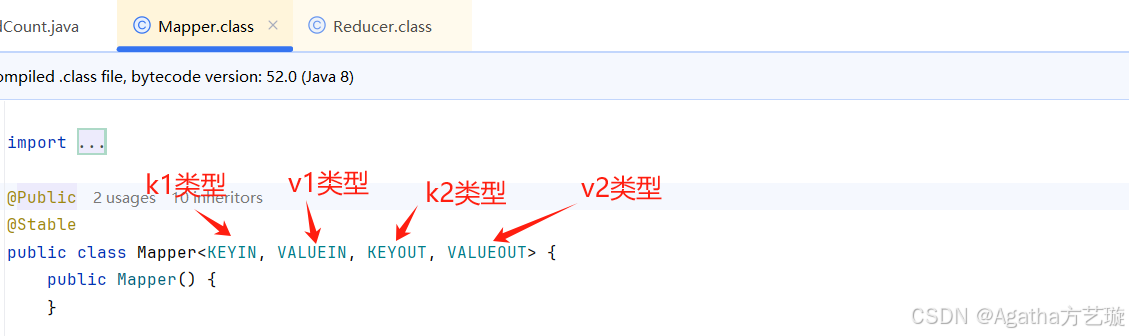
2、要重写map方法实现k2,v2的逻辑

Reduce代码中:
3、要继承Reducer
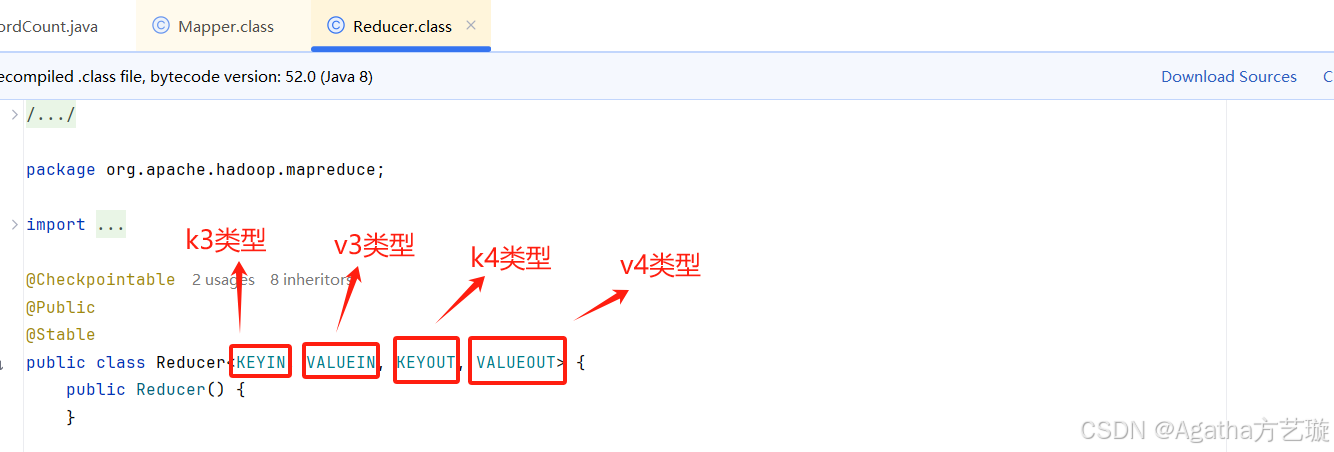
4、要重写reduce方法实现k4,v4的逻辑

2)可以开始写自己的代码啦:
1、创一个maven项目,把pom依赖弄好
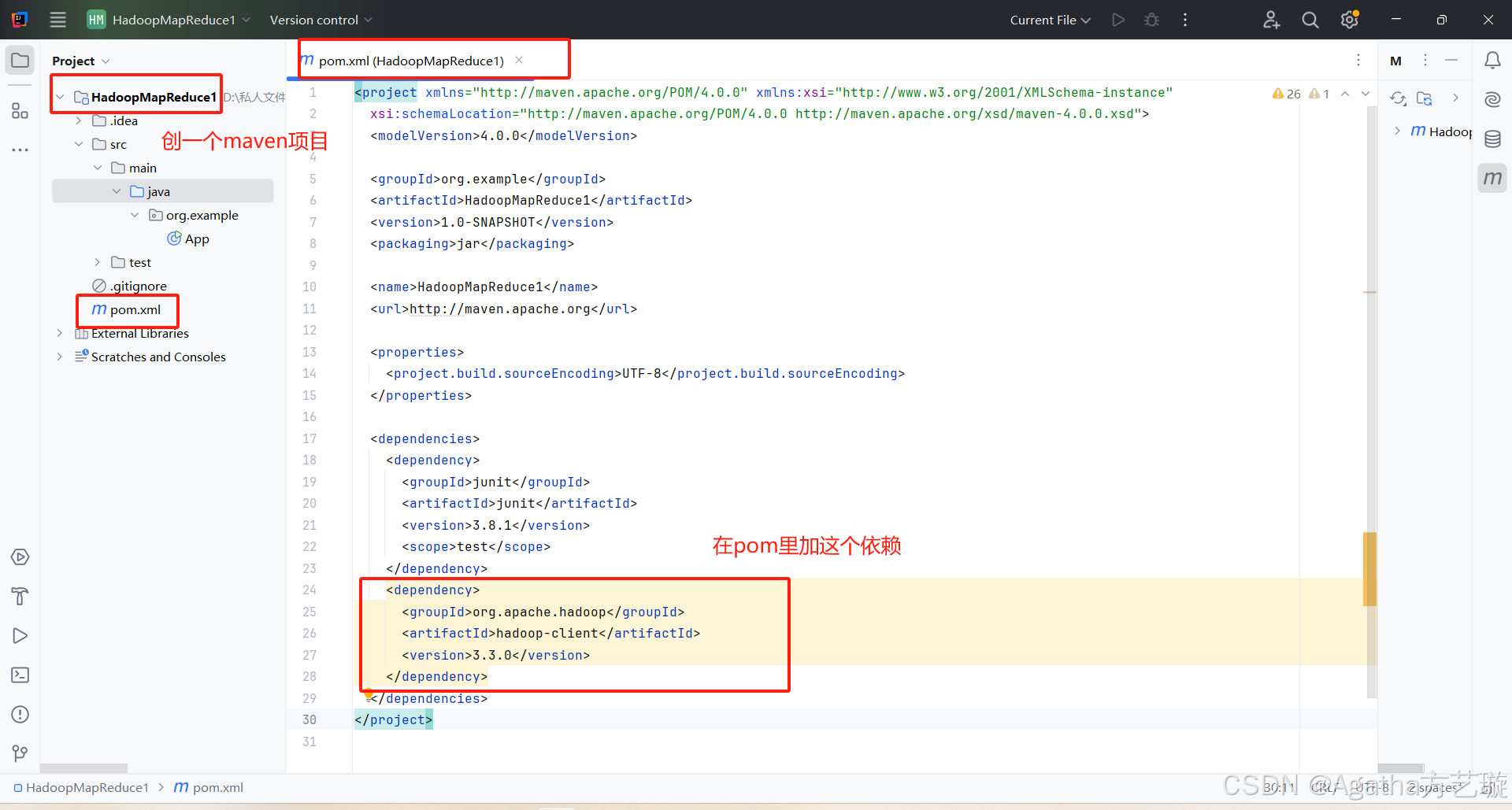
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.3.0</version></dependency>
2、新建一个类,我这取名WordCount
3、引入的依赖包内容为
import java.io.File;
import java.io.IOException;
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
4、Map部分,结合上面的图片解析模块和代码编写规则理解
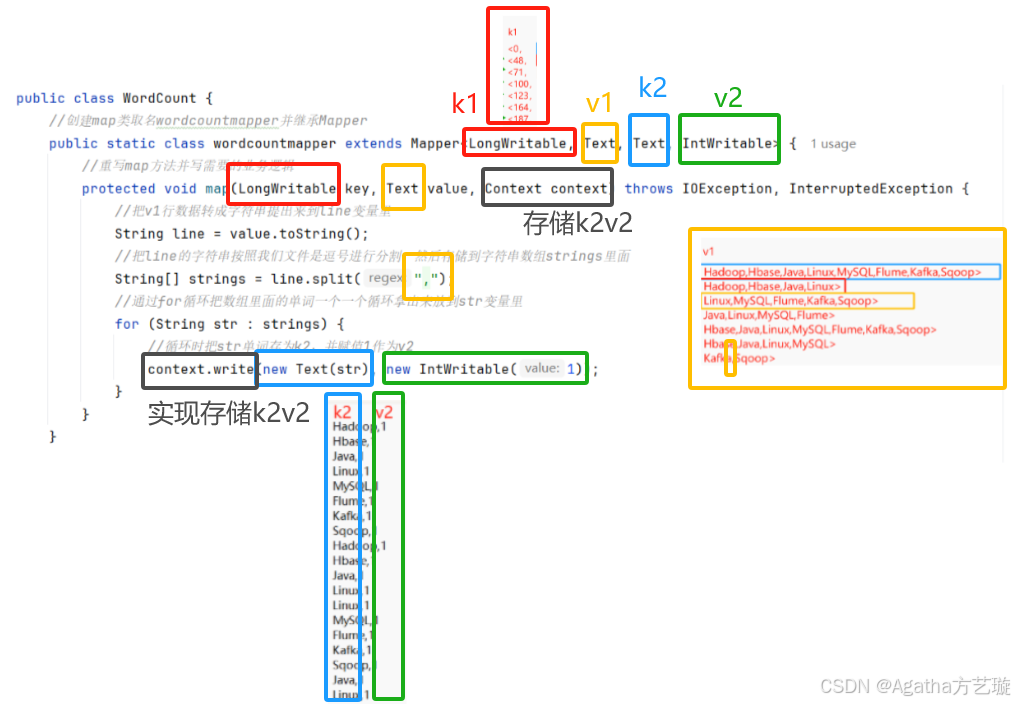
//创建map类取名wordcountmapper并继承Mapperpublic static class wordcountmapper extends Mapper<LongWritable, Text, Text, IntWritable> {//重写map方法并写需要的业务逻辑protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//把v1行数据转成字符串提出来到line变量里String line = value.toString();//把line的字符串按照我们文件是逗号进行分割,然后存储到字符串数组strings里面String[] strings = line.split(",");//通过for循环把数组里面的单词一个一个循环拿出来放到str变量里for (String str : strings) {//循环时把str单词存为k2,并赋值1作为v2context.write(new Text(str), new IntWritable(1));}}
5、Reduce部分,结合上面的图片解析模块和代码编写规则理解
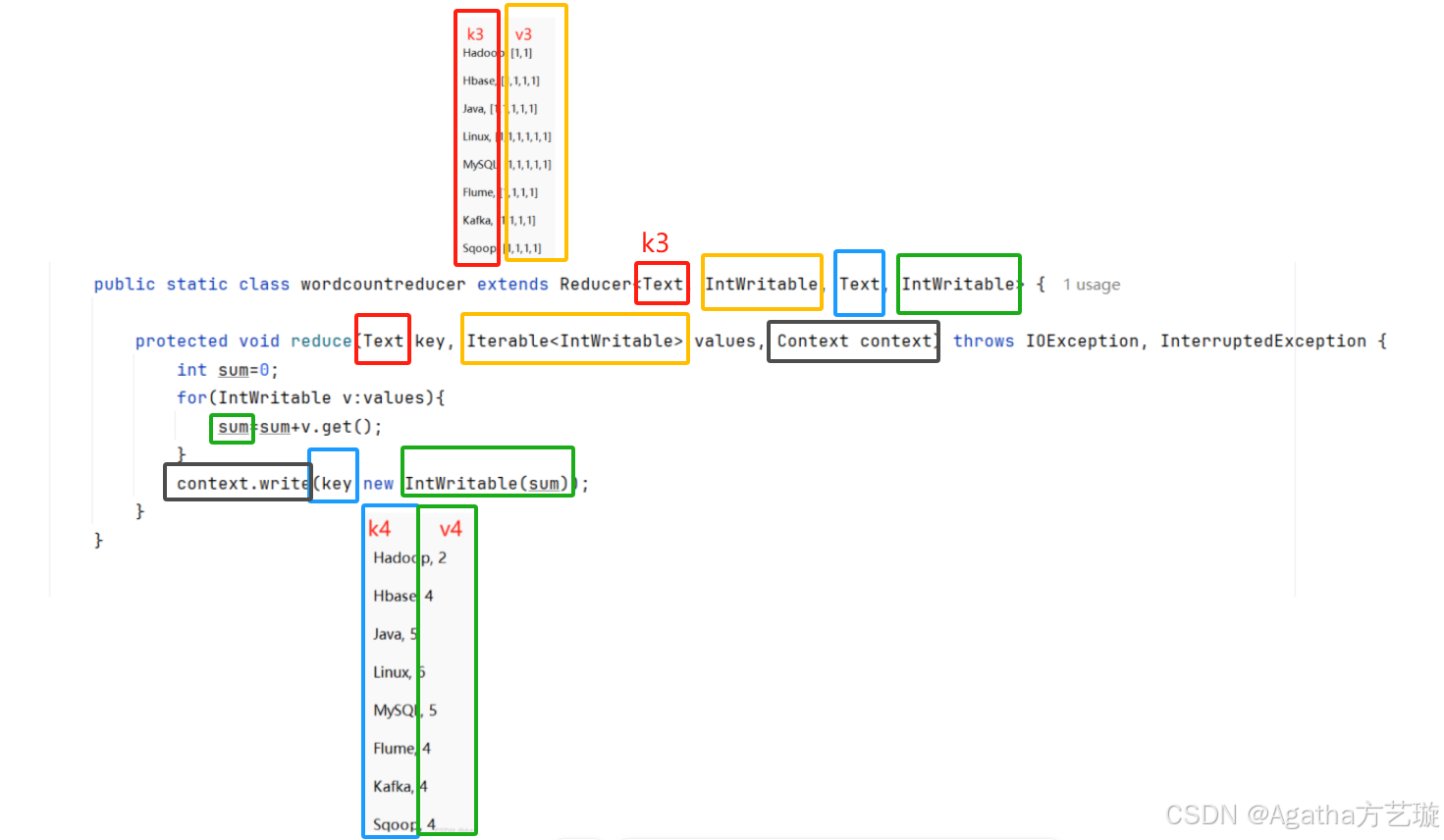
//创建类取名wordcountreducer并继承Reducerpublic static class wordcountreducer extends Reducer<Text, IntWritable, Text, IntWritable> {//重写reduce方法并写需要的业务逻辑protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {//设置一个变量用于计数,初始为0int sum=0;//将v3的数组的值进行循环相加for(IntWritable v:values){//最终得到计数的值sum=sum+v.get();}//将k3直接转成k4,将sum作为v4context.write(key,new IntWritable(sum));}}
6、主函数实现代码运行
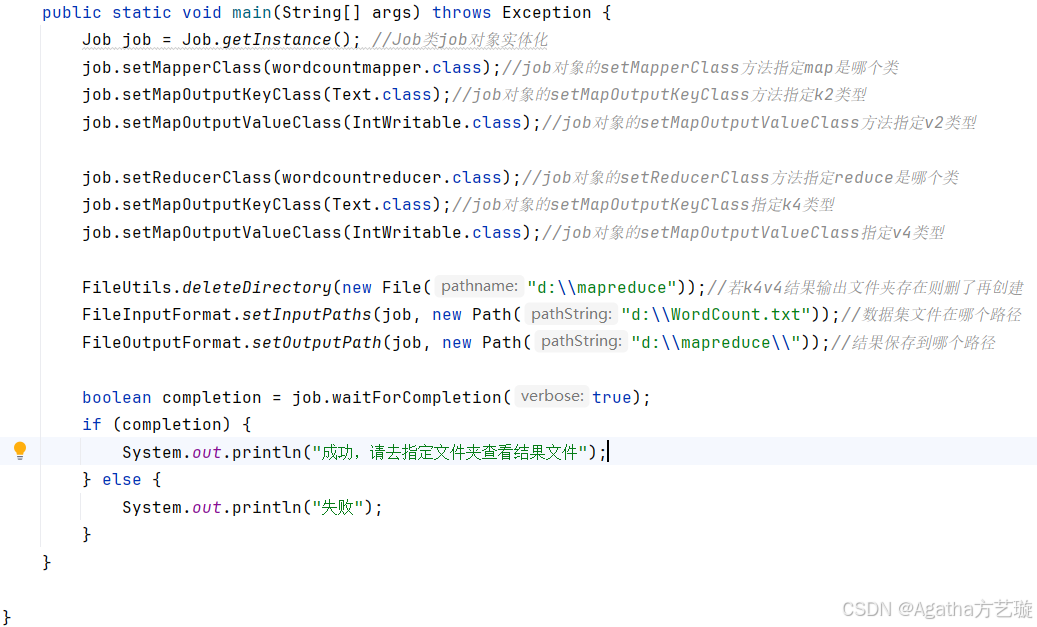
public static void main(String[] args) throws Exception {Job job = Job.getInstance(); //Job类job对象实体化job.setMapperClass(wordcountmapper.class);//job对象的setMapperClass方法指定map是哪个类job.setMapOutputKeyClass(Text.class);//job对象的setMapOutputKeyClass方法指定k2类型job.setMapOutputValueClass(IntWritable.class);//job对象的setMapOutputValueClass方法指定v2类型job.setReducerClass(wordcountreducer.class);//job对象的setReducerClass方法指定reduce是哪个类job.setMapOutputKeyClass(Text.class);//job对象的setMapOutputKeyClass指定k4类型job.setMapOutputValueClass(IntWritable.class);//job对象的setMapOutputValueClass指定v4类型FileUtils.deleteDirectory(new File("d:\\mapreduce"));//若k4v4结果输出文件夹存在则删了再创建FileInputFormat.setInputPaths(job, new Path("d:\\WordCount.txt"));//数据集文件在哪个路径FileOutputFormat.setOutputPath(job, new Path("d:\\mapreduce\\"));//结果保存到哪个路径boolean completion = job.waitForCompletion(true);if (completion) {System.out.println("成功,请去指定文件夹查看结果文件");} else {System.out.println("失败");}}
附上整个完整代码:
import java.io.File;
import java.io.IOException;
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;public class WordCount {//创建类取名wordcountmapper并继承Mapperpublic static class wordcountmapper extends Mapper<LongWritable, Text, Text, IntWritable> {//重写map方法并写需要的业务逻辑protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//把v1行数据转成字符串提出来到line变量里String line = value.toString();//把line的字符串按照我们文件是逗号进行分割,然后存储到字符串数组strings里面String[] strings = line.split(",");//通过for循环把数组里面的单词一个一个循环拿出来放到str变量里for (String str : strings) {//循环时把str单词存为k2,并赋值1作为v2context.write(new Text(str), new IntWritable(1));}}}//创建类取名wordcountreducer并继承Reducerpublic static class wordcountreducer extends Reducer<Text, IntWritable, Text, IntWritable> {//重写reduce方法并写需要的业务逻辑protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {//设置一个变量用于计数,初始为0int sum=0;//将v3的数组的值进行循环相加for(IntWritable v:values){//最终得到计数的值sum=sum+v.get();}//将k3直接转成k4,将sum作为v4context.write(key,new IntWritable(sum));}}public static void main(String[] args) throws Exception {Job job = Job.getInstance(); //Job类job对象实体化job.setMapperClass(wordcountmapper.class);//job对象的setMapperClass方法指定map是哪个类job.setMapOutputKeyClass(Text.class);//job对象的setMapOutputKeyClass方法指定k2类型job.setMapOutputValueClass(IntWritable.class);//job对象的setMapOutputValueClass方法指定v2类型job.setReducerClass(wordcountreducer.class);//job对象的setReducerClass方法指定reduce是哪个类job.setMapOutputKeyClass(Text.class);//job对象的setMapOutputKeyClass指定k4类型job.setMapOutputValueClass(IntWritable.class);//job对象的setMapOutputValueClass指定v4类型FileUtils.deleteDirectory(new File("d:\\mapreduce"));//若k4v4结果输出文件夹存在则删了再创建FileInputFormat.setInputPaths(job, new Path("d:\\WordCount.txt"));//数据集文件在哪个路径FileOutputFormat.setOutputPath(job, new Path("d:\\mapreduce\\"));//结果保存到哪个路径boolean completion = job.waitForCompletion(true);if (completion) {System.out.println("成功,请去指定文件夹查看结果文件");} else {System.out.println("失败");}}}