Algolia - Docsearch的申请配置安装【以踩坑解决版】
👨🎓博主简介
🏅CSDN博客专家
🏅云计算领域优质创作者
🏅华为云开发者社区专家博主
🏅阿里云开发者社区专家博主
💊交流社区:运维交流社区 欢迎大家的加入!
🐋 希望大家多多支持,我们一起进步!😄
🎉如果文章对你有帮助的话,欢迎 点赞 👍🏻 评论 💬 收藏 ⭐️ 加关注+💗
文章目录
- 简述
- 配置
- 注册
- 使用
- 官方申请
- 申请成功发送邮件
- 调试爬取
- 网站测试搜索
- 配置完成 - 总结回顾
推荐我的网站此文章:https://liuchenyang.top/document/other/docsearch.html
简述
文档参考:
- VitePress官方
- VuePress 不用Algolia 全文搜索那就缺了灵魂
结合自己操作记录来修改成vuepress-theme-hope主题的docsearch配置。
其实也有很多热门的爬虫搜索引擎,而Algolia的 Algolia DocSearch 是直接集成在VuePress中的,我们来看看有多么强大吧。
配置
这里配置的是vuepress主题的,最新版Hope主题自带algolia插件,无需安装,请在theme.ts里定位到plugins设置。
- 插件版本注意事项
如果不是最新版本,在安装@vuepress/plugin-docsearch插件的时候需要适配当前版本,具体是如何适配自己的版本不确定,只能在package.json配置文件中去修改版本号来试,然后我安装了个70版本的,但是配置好之后搜索有点问题,问题:搜索的结果无法点击,然后我就一点一点往上升级到了rc74的版本,就可以了,指定升级插件版本命令为:pnpm add -D @vuepress/plugin-docsearch@2.0.0-rc.74,安装的时候会自动删除原版本更新成配置文件中指定的版本或指定下载的版本,如果安装好访问页面空白的话,大概率就是版本的问题。
plugins: {docsearch:({appId: "<APP_ID>",apiKey: "<API_KEY>",indexName: "<INDEX_NAME>",locales: {"/": {placeholder: "搜索文档",translations: {button: {buttonText: "搜索文档",buttonAriaLabel: "搜索文档",},modal: {searchBox: {resetButtonTitle: "清除查询条件",resetButtonAriaLabel: "清除查询条件",cancelButtonText: "取消",cancelButtonAriaLabel: "取消",},startScreen: {recentSearchesTitle: "搜索历史",noRecentSearchesText: "没有搜索历史",saveRecentSearchButtonTitle: "保存至搜索历史",removeRecentSearchButtonTitle: "从搜索历史中移除",favoriteSearchesTitle: "收藏",removeFavoriteSearchButtonTitle: "从收藏中移除",},errorScreen: {titleText: "无法获取结果",helpText: "你可能需要检查你的网络连接",},footer: {selectText: "选择",navigateText: "切换",closeText: "关闭",searchByText: "搜索提供者",},noResultsScreen: {noResultsText: "无法找到相关结果",suggestedQueryText: "你可以尝试查询",reportMissingResultsText: "你认为该查询应该有结果?",reportMissingResultsLinkText: "点击反馈",},},},},},}),},
注册
由于配置还缺关键Key,所以还需要注册账号,也方便我们后期对数据进行管理
进入 Algolia官网 ,点击 Login 注册账号
可以选择 NO ACCOUNT YET? ,也可以直接用GitHub和谷歌账号关联注册
注册比较简单,就不讲了
网站打不开,挂一个梯子即可

使用
请按自己的需求,参照下面教程,选其一使用
| 使用方式 | 区别说明 |
|---|---|
| 官方申请 | 申请时需要提交链接、邮箱及仓库(可选) ,等待周期较长,通过后会自动爬取,直接配置使用即可 |
| Docker | 需自备服务器且安装好docker,有一定动手能力,需要每次手动爬取。步骤繁琐本次不做演示 |
| Github Actions | 准备一个公开或者私密的仓库,配置好爬虫数据的格式,Actions自动爬取 |
官方申请
直接在 DocSearch官网,点 Apply 申请
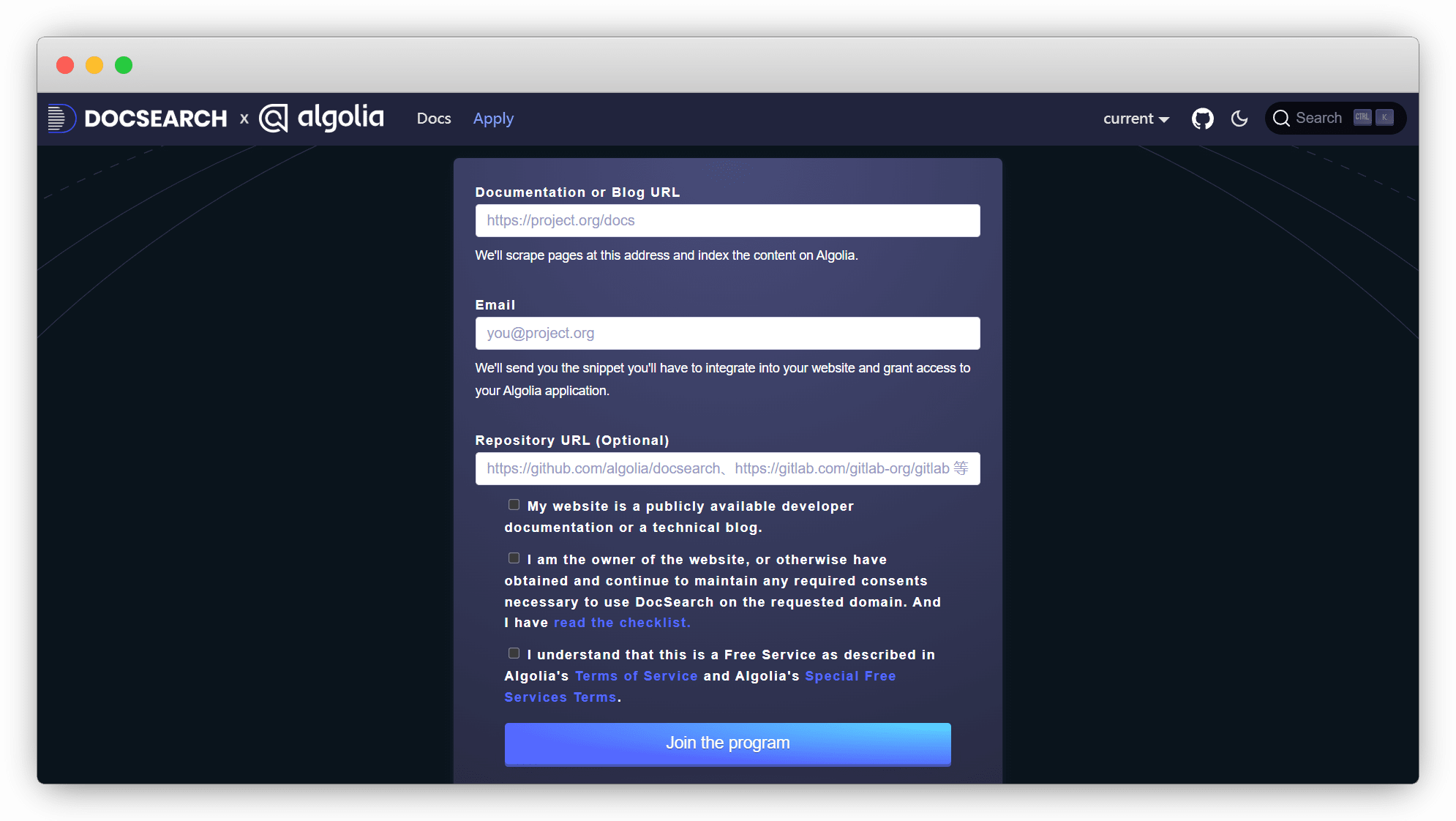
打开后填写网站地址、邮箱和仓库地址(可选)等信息,然后勾选上下面三项,并提交即可。
等待跳转成功就好,没有跳转,就挂个梯子
之后就静待邮件,最快等待6-7小时,慢则半个多月,在邮件中会给我们一个邀请链接,复制并打开。
官方邮箱地址:support@algolia.com
申请成功发送邮件
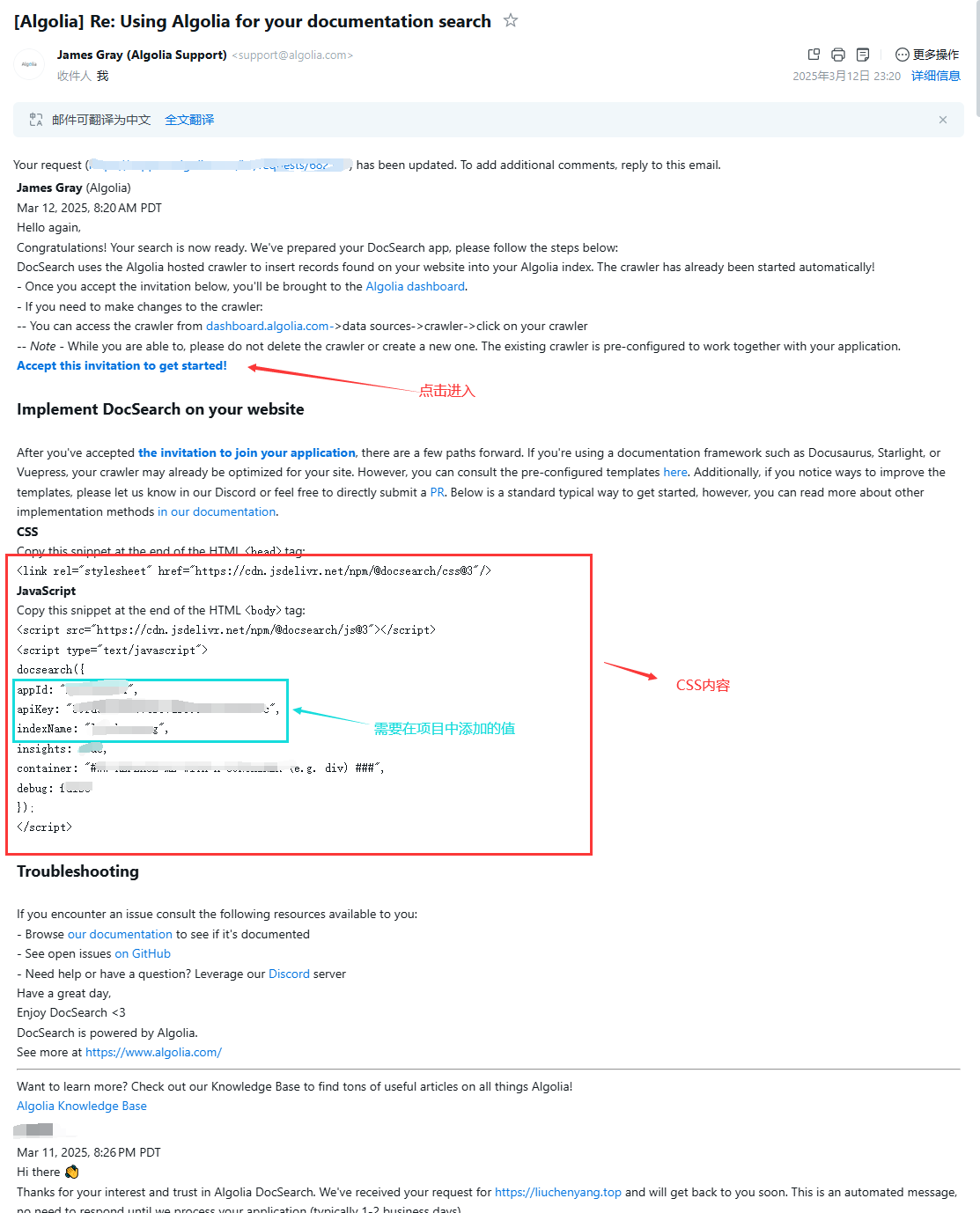
申请成功之后,将邮件中的addId、apiKey、indexName值放到项目配置中。
就这么简单么,so easy !当你以为一切顺利万事大吉的时候,然而,很可能你的全文搜索还不可以用。可能一搜还都是找不到结果,那这是为何呢,文章还未结束,配置还在进行,且往下看!
调试爬取
然后我们登陆 https://dashboard.algolia.com/apps/DJTP2DCRA4/dashboard 打开管理后台,点击左侧选项栏里的 Search,进去后会有个弹窗按钮,点 Accept 接受即可
没有弹窗的,去邮箱复制邀请链接打开应该就有了;
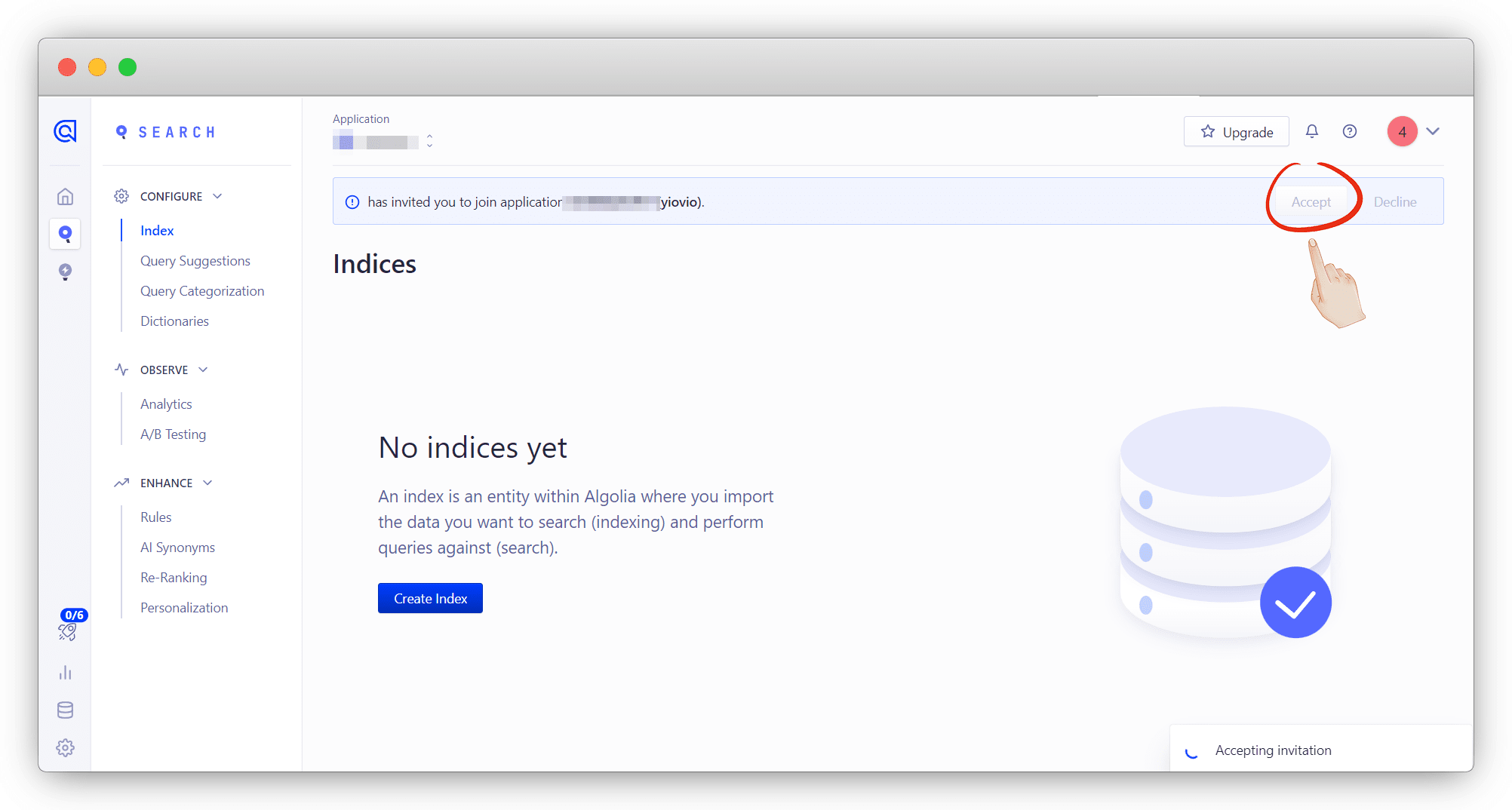
这样就自动完成了Application创建;
然后查看对应的 index 数据,如果 Browse 这里没有显示数据,那需要点击这里的刷新看看,有数据即可;
如果刷新之后如果还是没有显示数据,那说明爬取的数据可能有问题,导致没有生成对应的 Records;
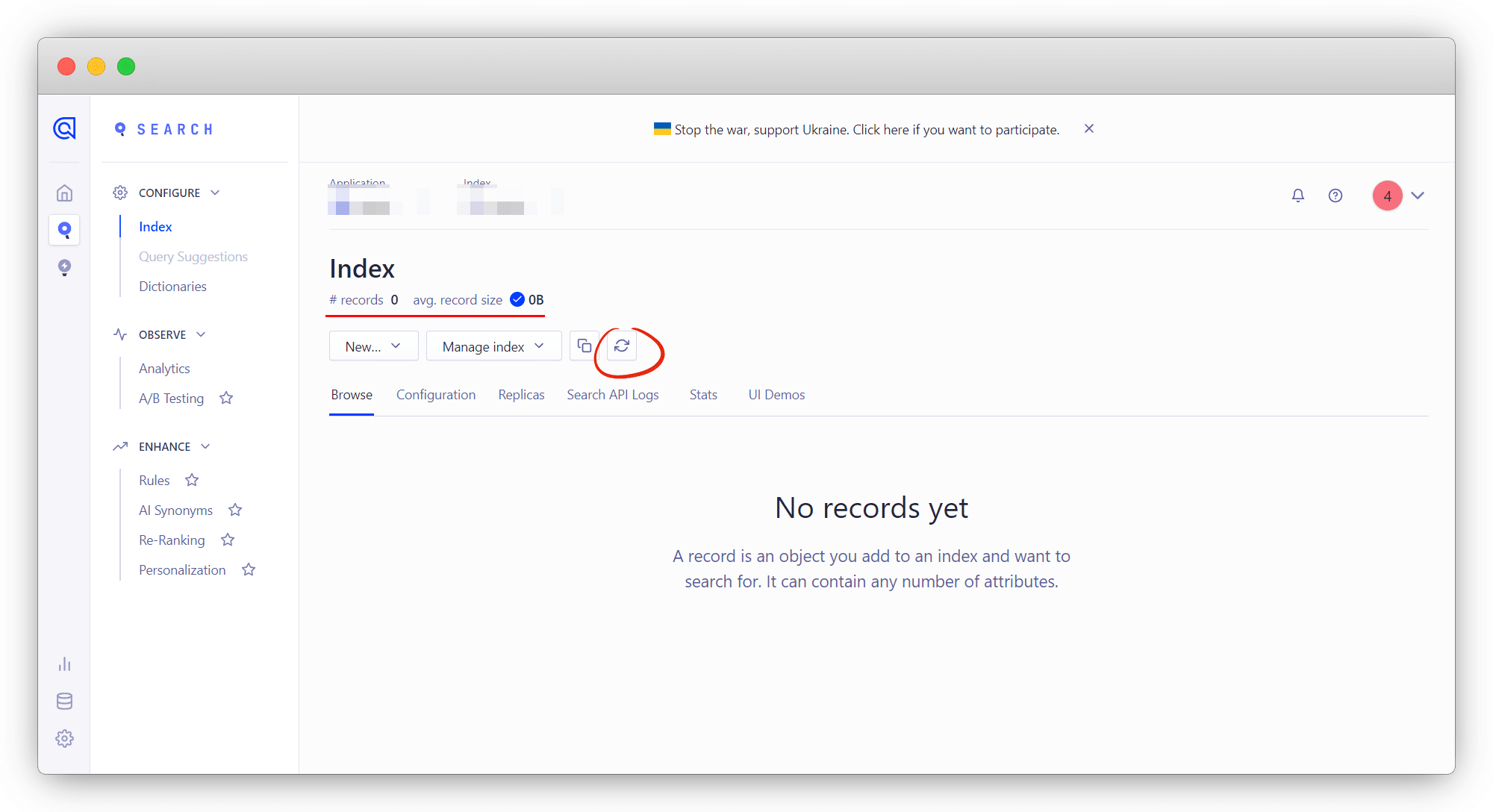
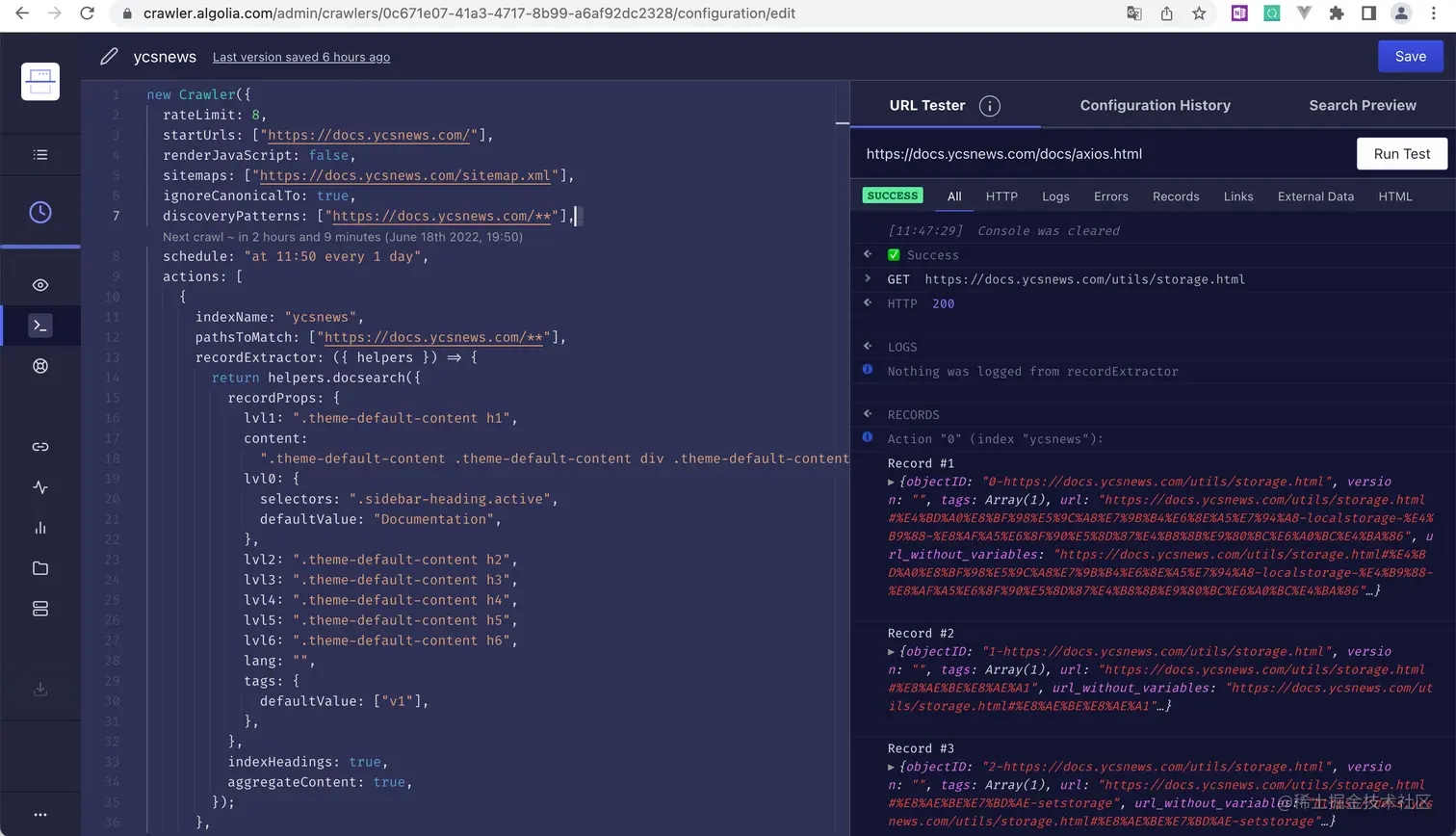
这个时候要使用官方工具进行调试,进入调试工具地址,打开调试台,点击进入爬虫详情;
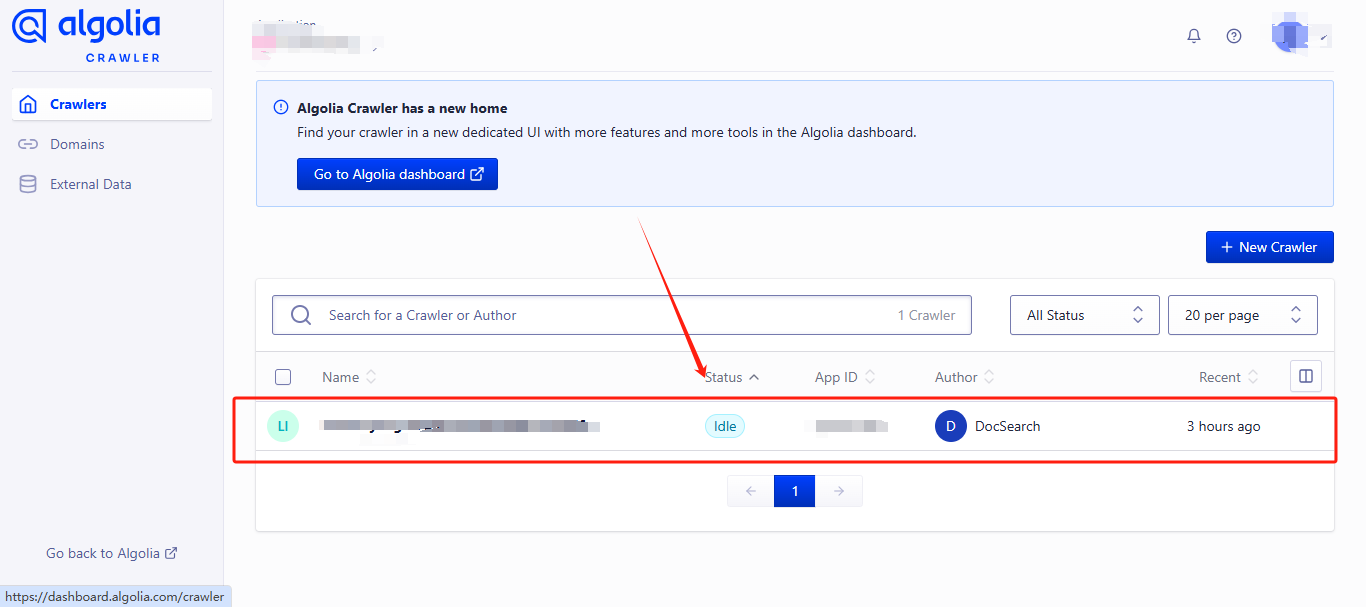
进来之后在点击 Overview 菜单,发现爬虫数据是有的,但 Records 为 0,那大概是爬虫提取数据的逻辑有问题;
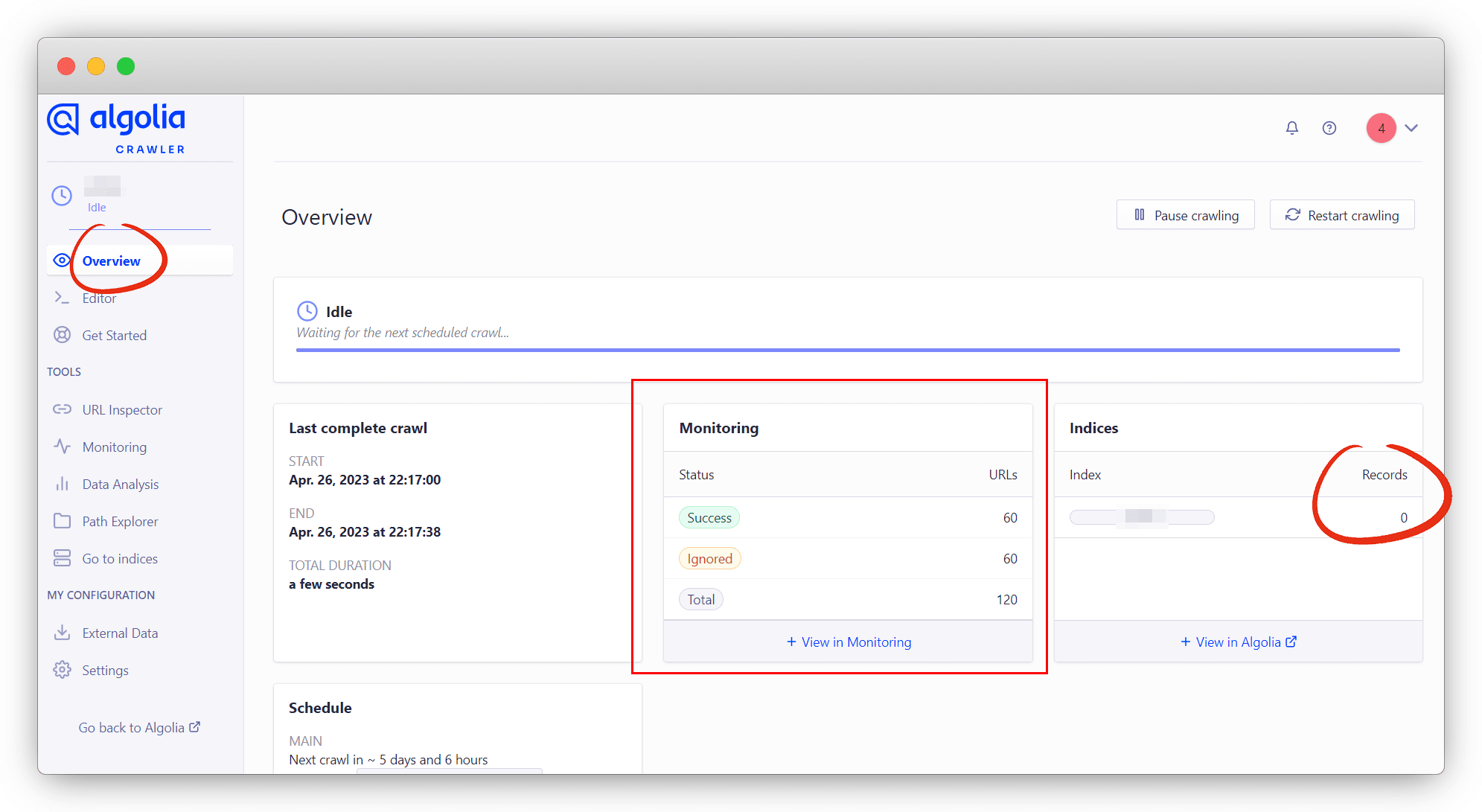
点击左侧选项栏中的 Editor,查看具体的爬虫逻辑,可以根据 vuepress 官方提供的模版参考查看问题:vuepress官方爬虫配置,这里我是直接整个复制粘贴成官方的然后进行个别地方修改就可以了;
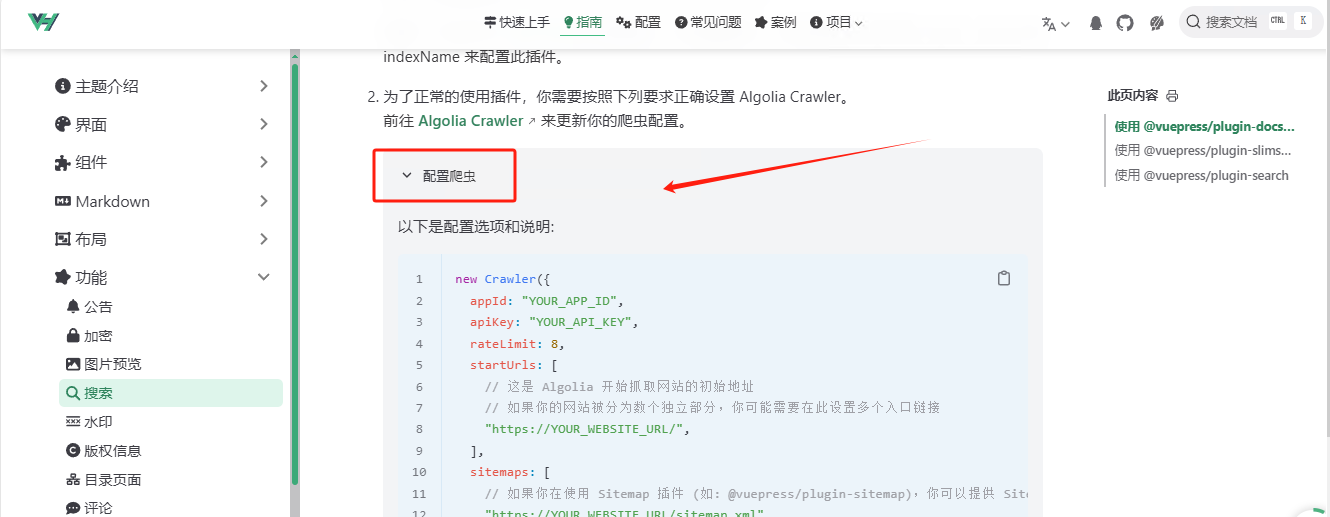
除了指定位置,其他不要乱改,特别是apikey不要改!和你申请的apikey不是同一个用途
如果你网址有别名解析或者重定向了,也只能用你申请时的网址
- 官方爬虫设置
new Crawler({appId: "YOUR_APP_ID",apiKey: "YOUR_API_KEY",rateLimit: 8,startUrls: [// 这是 Algolia 开始抓取网站的初始地址// 如果你的网站被分为数个独立部分,你可能需要在此设置多个入口链接"https://YOUR_WEBSITE_URL/",],sitemaps: [// 如果你在使用 Sitemap 插件 (如: @vuepress/plugin-sitemap),你可以提供 Sitemap 链接"https://YOUR_WEBSITE_URL/sitemap.xml",],ignoreCanonicalTo: false,exclusionPatterns: [// 你可以通过它阻止 Algolia 抓取某些 URL],discoveryPatterns: [// 这是 Algolia 抓取 URL 的范围"https://YOUR_WEBSITE_URL/**",],// 爬虫执行的计划时间,可根据文档更新频率设置schedule: "at 02:00 every 1 day",actions: [// 你可以拥有多个 action,特别是你在一个域名下部署多个文档时{// 使用适当的名称为索引命名indexName: "YOUR_INDEX_NAME",// 索引生效的路径pathsToMatch: ["https://YOUR_WEBSITE_URL/**"],// 控制 Algolia 如何抓取你的站点recordExtractor: ({ $, helpers }) => {// 以下是适用于 vuepress-theme-hope 的默认选项选项return helpers.docsearch({recordProps: {lvl0: {selectors: [".vp-sidebar-link.active", "[vp-content] h1"],defaultValue: "Documentation",},lvl1: "[vp-content] h1",lvl2: "[vp-content] h2",lvl3: "[vp-content] h3",lvl4: "[vp-content] h4",lvl5: "[vp-content] h5",lvl6: "[vp-content] h6",content: "[vp-content] p, [vp-content] li",},recordVersion: "v3",});},},],initialIndexSettings: {// 控制索引如何被初始化,这仅当索引尚未生成时有效// 你可能需要在修改后手动删除并重新生成新的索引YOUR_INDEX_NAME: {attributesForFaceting: ["type", "lang"],attributesToRetrieve: ["hierarchy", "content", "anchor", "url"],attributesToHighlight: ["hierarchy", "hierarchy_camel", "content"],attributesToSnippet: ["content:10"],camelCaseAttributes: ["hierarchy", "hierarchy_radio", "content"],searchableAttributes: ["unordered(hierarchy_radio_camel.lvl0)","unordered(hierarchy_radio.lvl0)","unordered(hierarchy_radio_camel.lvl1)","unordered(hierarchy_radio.lvl1)","unordered(hierarchy_radio_camel.lvl2)","unordered(hierarchy_radio.lvl2)","unordered(hierarchy_radio_camel.lvl3)","unordered(hierarchy_radio.lvl3)","unordered(hierarchy_radio_camel.lvl4)","unordered(hierarchy_radio.lvl4)","unordered(hierarchy_radio_camel.lvl5)","unordered(hierarchy_radio.lvl5)","unordered(hierarchy_radio_camel.lvl6)","unordered(hierarchy_radio.lvl6)","unordered(hierarchy_camel.lvl0)","unordered(hierarchy.lvl0)","unordered(hierarchy_camel.lvl1)","unordered(hierarchy.lvl1)","unordered(hierarchy_camel.lvl2)","unordered(hierarchy.lvl2)","unordered(hierarchy_camel.lvl3)","unordered(hierarchy.lvl3)","unordered(hierarchy_camel.lvl4)","unordered(hierarchy.lvl4)","unordered(hierarchy_camel.lvl5)","unordered(hierarchy.lvl5)","unordered(hierarchy_camel.lvl6)","unordered(hierarchy.lvl6)","content",],distinct: true,attributeForDistinct: "url",customRanking: ["desc(weight.pageRank)","desc(weight.level)","asc(weight.position)",],ranking: ["words","filters","typo","attribute","proximity","exact","custom",],highlightPreTag:'<span class="algolia-docsearch-suggestion--highlight">',highlightPostTag: "</span>",minWordSizefor1Typo: 3,minWordSizefor2Typos: 7,allowTyposOnNumericTokens: false,minProximity: 1,ignorePlurals: true,advancedSyntax: true,attributeCriteriaComputedByMinProximity: true,removeWordsIfNoResults: "allOptional",},},
});
配置完成后,点击右上角的 save 进行保存在;然后找个自己的文档的链接,粘贴到URL Tester里,点击RUN Test测试下,看是否能成功,成功则进行下一步,否则继续调整抓取规则,指导能抓取成功!如下图,多测几个链接,保证都可用。
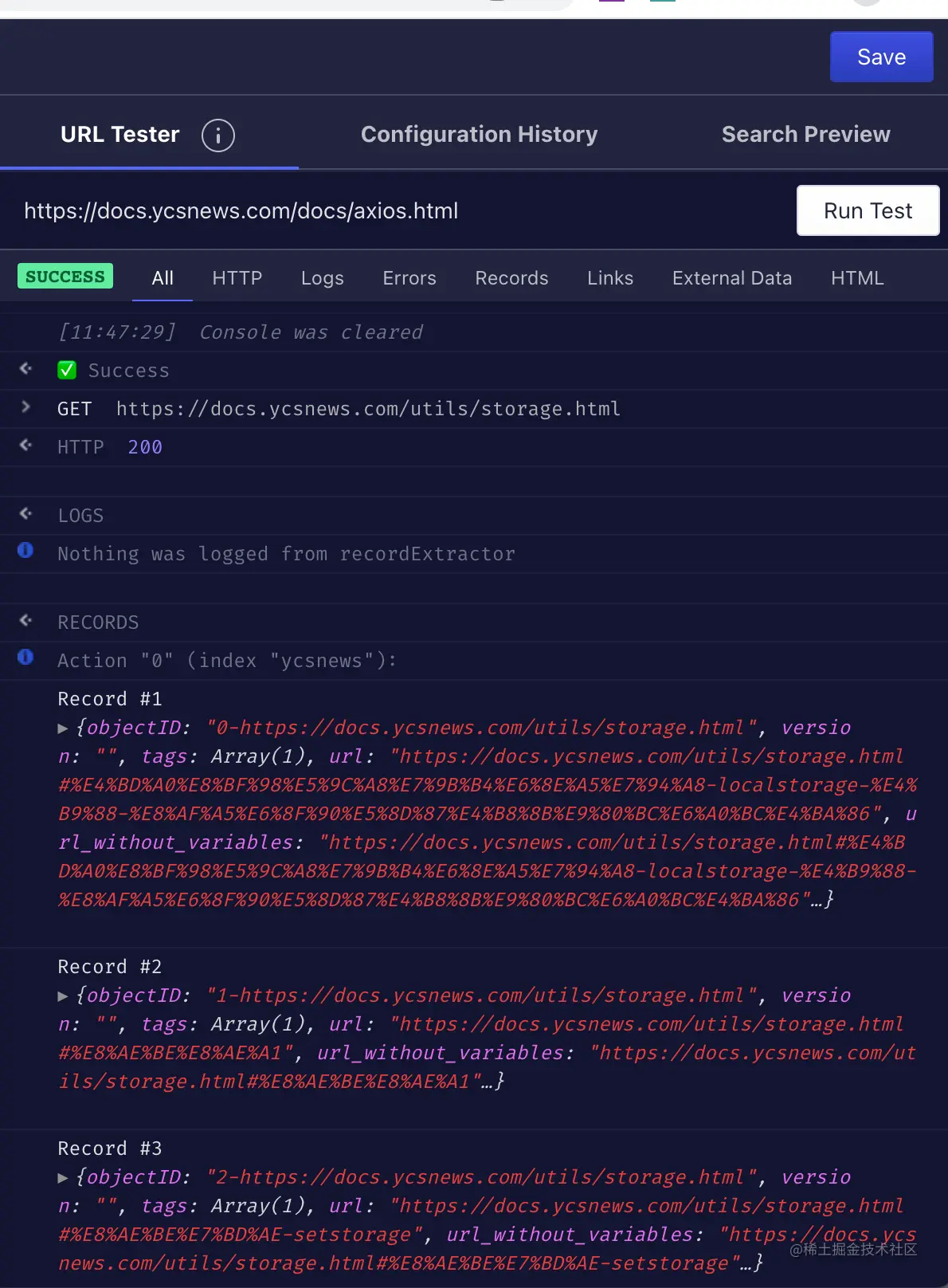
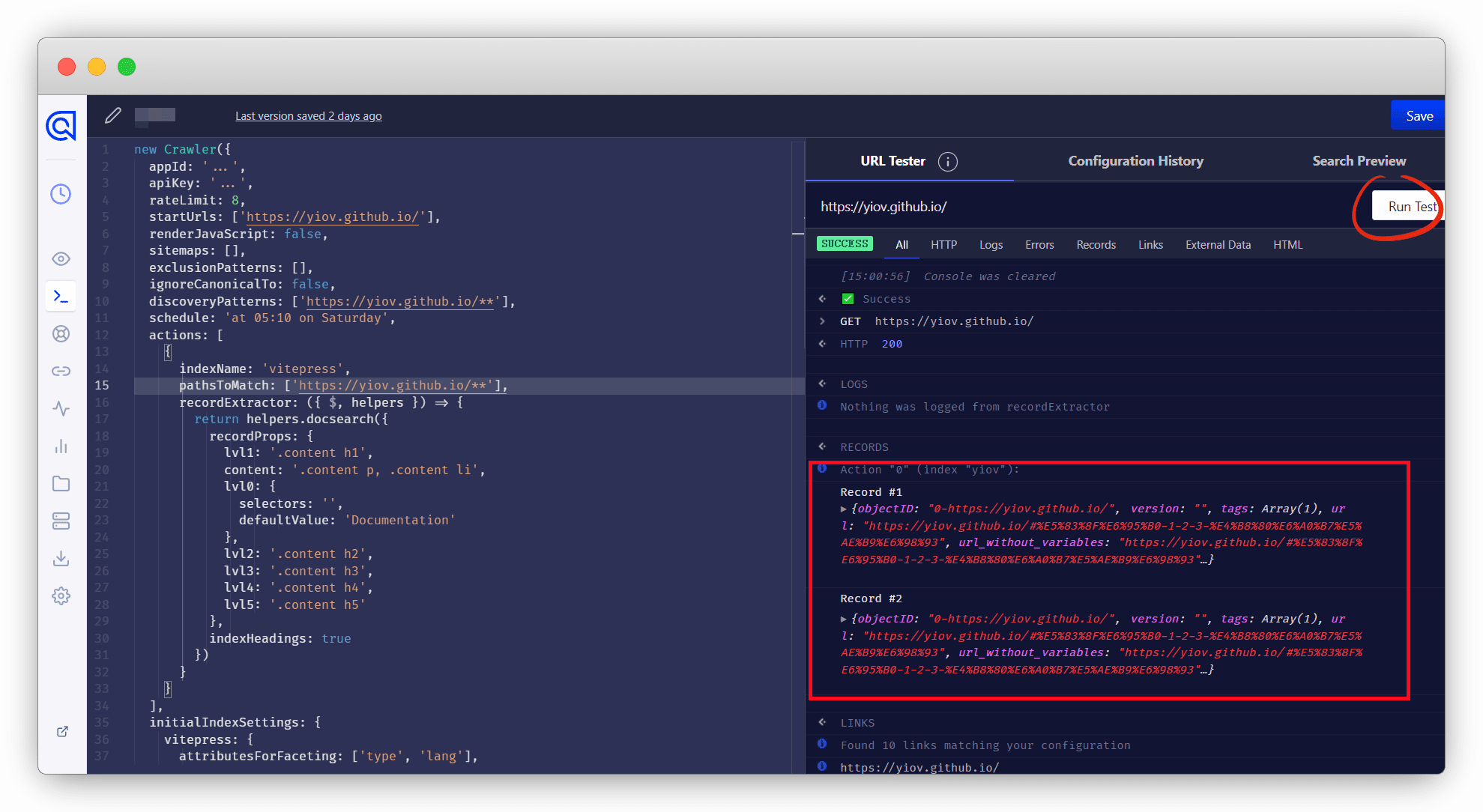
链接测试完成后,可以在 Search Preview 里可以搜素看看,能搜索到自己的内容就可以了;
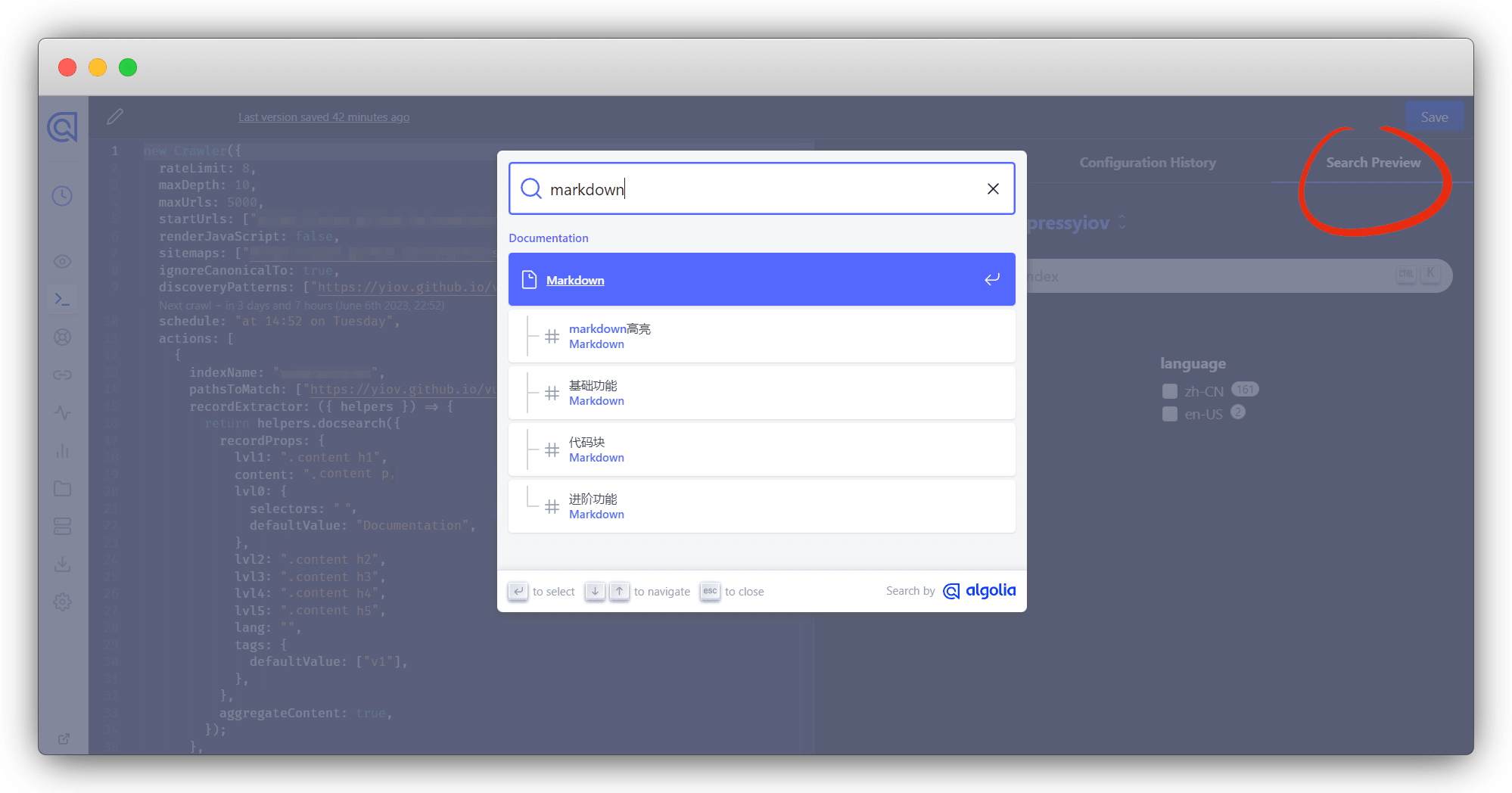
然后返回到 Overview 菜单, 点击右上角的 Restart crawling 按钮,重新进行抓取,爬取成功之后会发送邮件,文章少爬取的就快,成功后,下面的 Indices 栏会显示 Records 数;
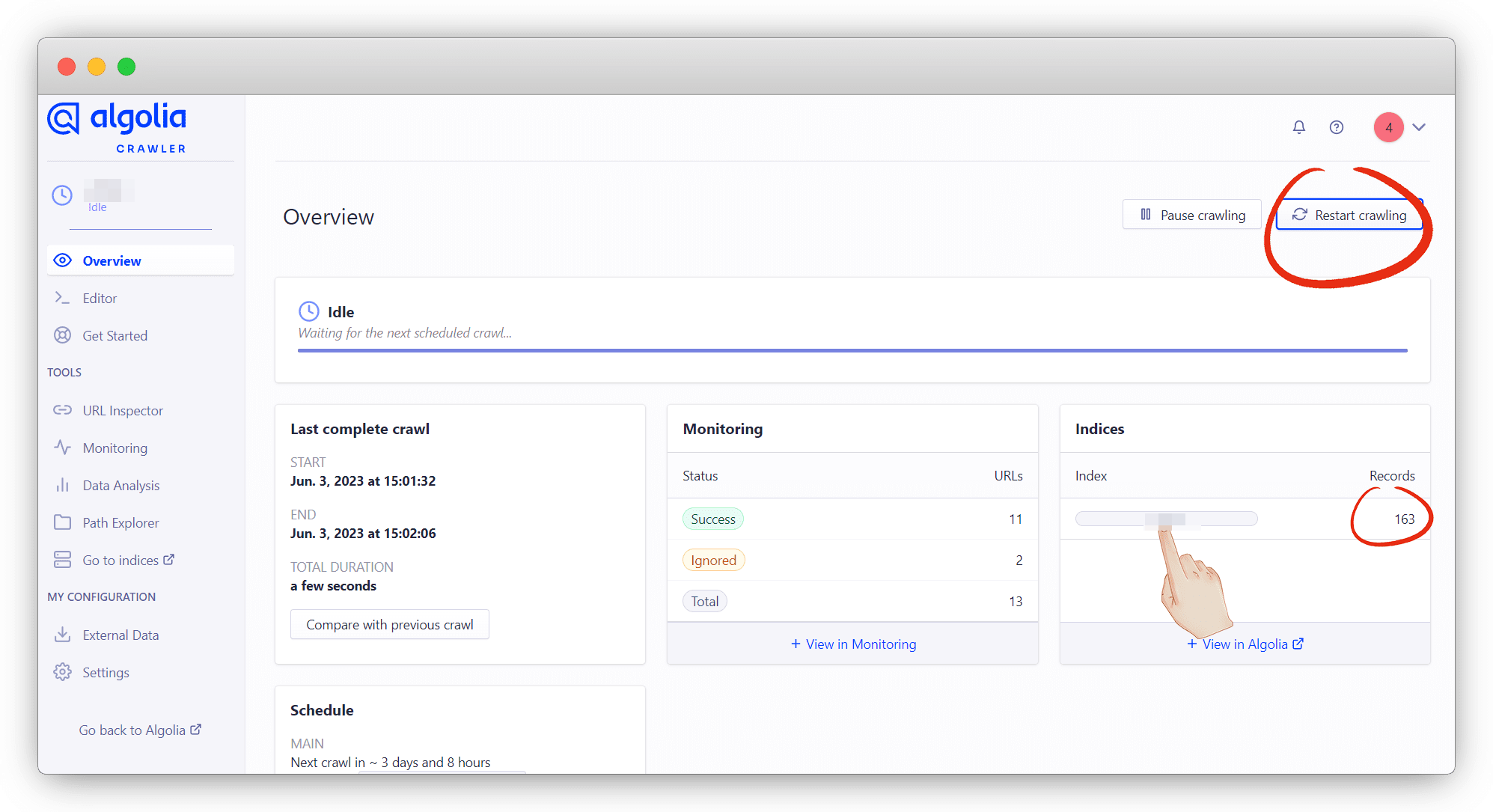
然后在返回点击index回到algolia,看数据是否同步过来就可以了,前面做完没问题这个同步正常也是会没问题的;
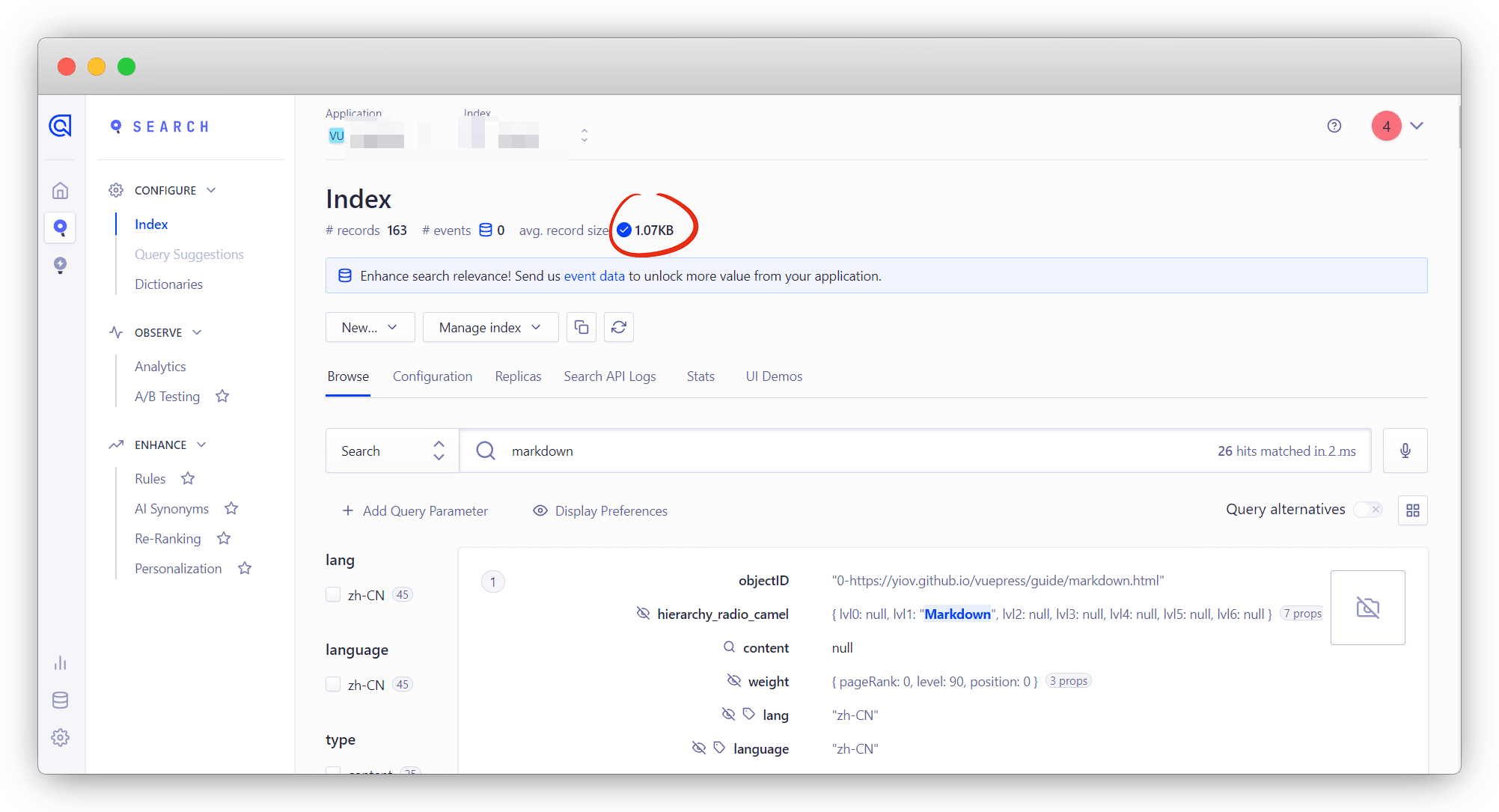
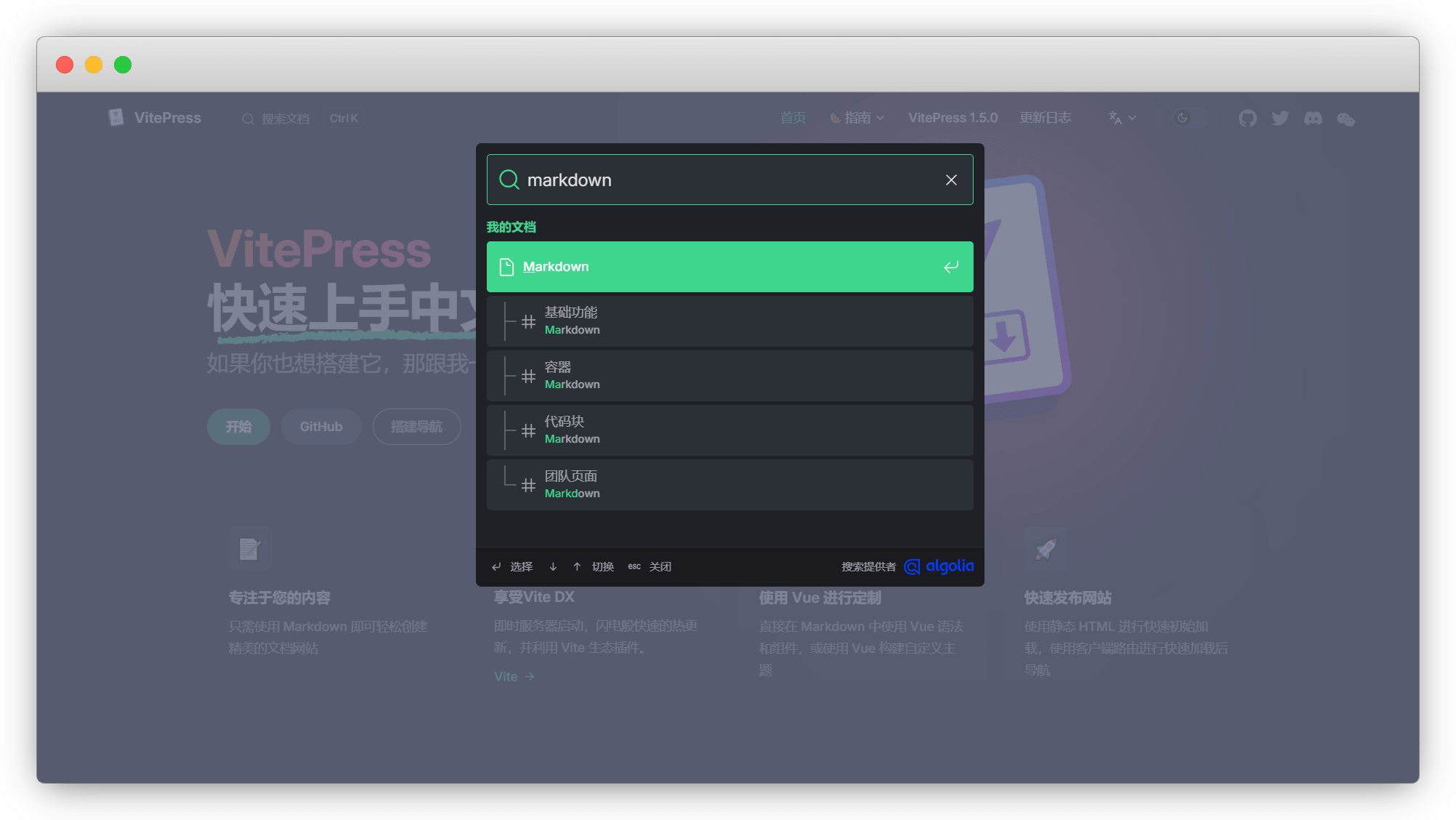
网站测试搜索
此时再去自己的网站试试,应该就可以了,如果不行,就重复爬取一下数据,再等一等再试!
配置完成 - 总结回顾
对于 vuepress 来说,就是安装个插件配置参数的事,可还是让人耽误了好些时间。官方文档中并未对常见的一些问题予以说明,还需咱们自己踩坑,希望大家也能将自己日常踩的坑分享出来,避免更多的人,无休止的耗费精力。祝大家一切顺利,所踩之坑,皆能被填平!
据说,点免费Star的人都被领导加鸡腿了!😄 ToLiucyLinux私域源码