深入理解Embedding Models(嵌入模型):从原理到实战(上)

🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、嵌入模型是什么
2、在NLP、推荐系统、知识图谱等领域的广泛应用
二、Embedding 的基本概念
1、什么是 Embedding
2、向量空间的意义
3、低维稠密表示 vs 高维稀疏表示(One-Hot)
三、主流的嵌入模型类型
1、词嵌入(Word Embedding)
2、文本/句子嵌入(Text/Sentence Embedding)
3、图嵌入(Graph Embedding)
一、引言
1、嵌入模型是什么
🌟 什么是嵌入模型(Embedding Model)?
想象你去超市买水果 🍎🍌🍇,每种水果都有不同的特点,比如颜色、甜度、大小……那么怎么让机器也能“理解”这些特点呢?这就需要把这些“特点”变成数字,方便机器处理!
这就是嵌入模型的作用 ——
👉 把“文字、图片、音频”等信息变成一串有意义的数字(我们称之为“向量” 📊)。
🧠 一个类比:给每个词一个“身份证”
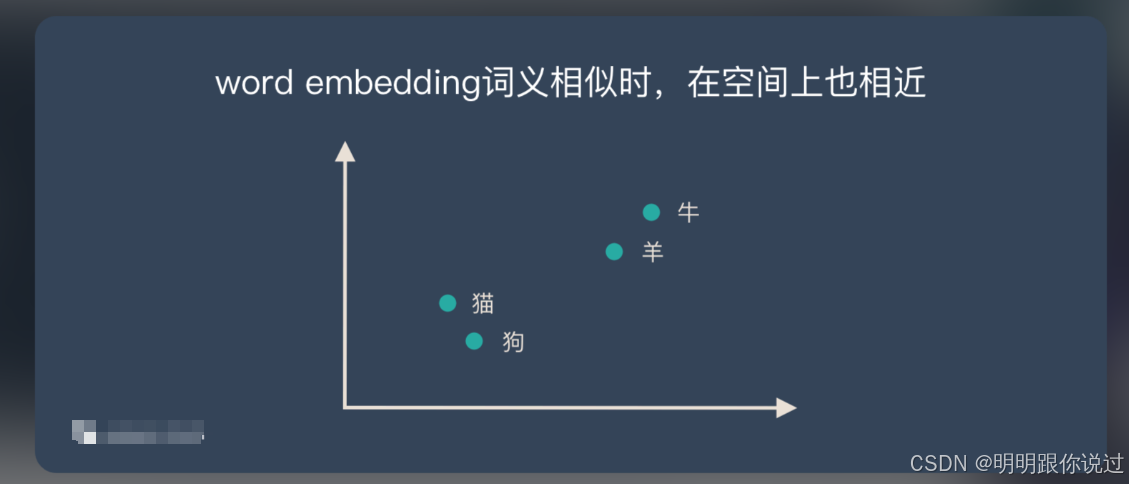
比如词语 “猫 🐱” 和 “狗 🐶”,人类知道它们都属于动物,性格温顺,是宠物。
嵌入模型就会把它们变成相近的数字向量,比如:
猫: [0.5, 0.7, 0.2, 0.1]
狗: [0.6, 0.8, 0.1, 0.2]看!它们的“数字长相”很像 ➡️ 说明“意义”也很像!
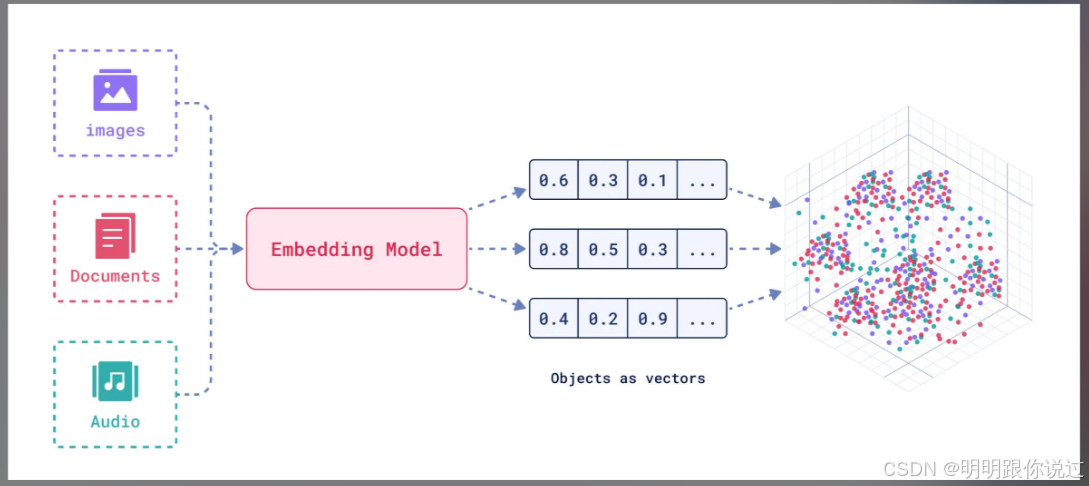
2、在NLP、推荐系统、知识图谱等领域的广泛应用
📚 1. NLP(自然语言处理)中的应用
嵌入模型是让AI“理解语言”的第一步!🧠
✅ 应用场景:
-
语义搜索 🔍:用户输入“首都机场怎么走”,模型知道“首都机场 = 北京机场”,帮你找到最佳路线。
-
问答系统 🤖:提问“Python怎么读文件”,模型会找出含有类似问题的文档或段落。
-
情感分析 ❤️😠:通过文字向量判断语气是积极、消极还是中性。
🎯 2. 推荐系统中的应用
你喜欢的电影、音乐、商品……嵌入模型统统帮你搞懂你的喜好!🍿🎵🛍️
✅ 应用场景:
-
用户画像 👤:把用户的行为转成向量,理解你是谁。
-
内容相似度推荐 💡:比如“你喜欢《复仇者联盟》,那你可能也喜欢《正义联盟》”。
-
冷启动解决方案 🧊➡️🔥:新用户或新商品也能快速推荐,不再尴尬!
🧠 3. 知识图谱中的应用
把“知识”变成可计算的图谱,嵌入模型帮你串联点与点之间的联系 🕸️
✅ 应用场景:
-
实体链接:知道“苹果”是“水果”不是“公司”,上下文决定。
-
关系预测:模型预测“爱因斯坦–出生地–德国”这样的三元组。
-
图谱补全:根据已有知识推断未知的联系。
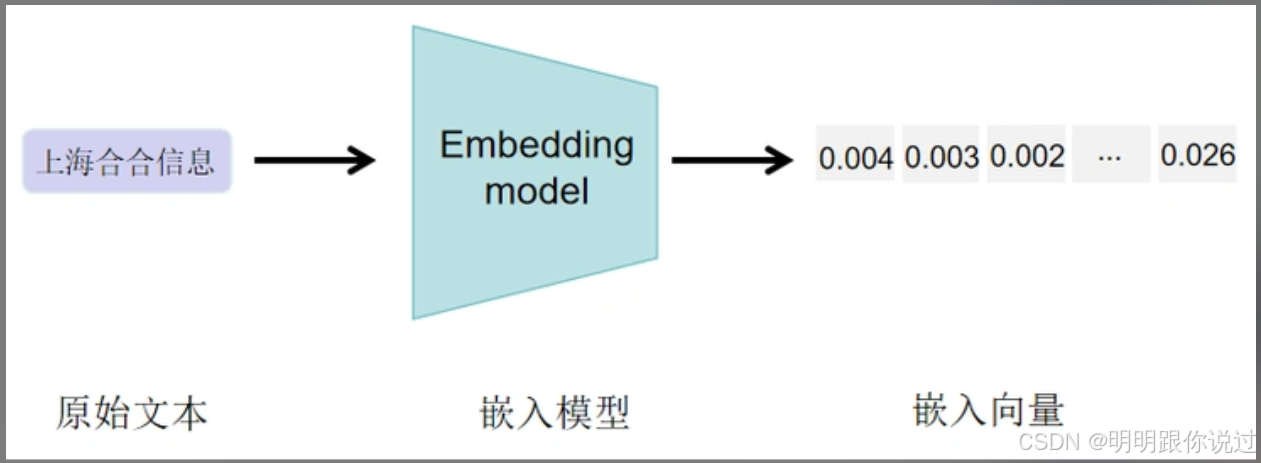
二、Embedding 的基本概念
1、什么是 Embedding
🧩 什么是 Embedding?
Embedding(嵌入),就是把**“人类能理解的信息”变成“机器能理解的数字”**!
通俗点说,它就像是👇:
🎤 “翻译器” —— 把文字、图像、用户等各种信息,翻译成有意义的向量(数字串)
🔧 常见的 Embedding 类型
| 类型 | 描述 |
|---|---|
| 词向量(Word Embedding) | 把每个“词”变成一个向量,如 Word2Vec、GloVe、FastText |
| 句子/段落向量 | 把整句话转成向量,如 Sentence-BERT |
| 图像/音频嵌入 | 把图像、声音转成向量,用于图像识别、声音分类等 |
| 用户/商品嵌入 | 在推荐系统中把用户/商品行为编码成向量 |
Embedding 是 AI 世界中的“通用翻译器”,把各类数据转化为“意义相关的向量” ✨,让机器理解、处理、比较各种信息变得可能!
2、向量空间的意义
🧭 什么是向量空间?
向量空间(Vector Space) 就像是一个**“坐标世界”** 🗺️
在这个世界里,每个词、句子、图片、用户…都被表示成一个“点”(即向量 📍),大家都有自己的“坐标”。
✨ 举个例子:词语世界地图
想象我们建了一个二维世界,词语是地图上的点:
开心 😊
|
| 爱情 ❤️
|
愤怒 😡 ------------- 仇恨 😠
你发现没?
-
“开心”和“爱情”在地图上靠得近 👉 表示它们语义相近
-
“愤怒”和“仇恨”也在一起 👉 也有相似的情绪
-
“开心”和“仇恨”距离远 👉 意义不同
这就是向量空间的魅力!🌌
🧠 Embedding 向量放在向量空间里,有啥用?
✅ 距离表示相似度
-
向量之间越近 ➡️ 意义越相似
-
向量之间越远 ➡️ 意义越不同
比如:
“苹果 🍎” 和 “香蕉 🍌” 的向量夹角小(近) → 都是水果
“苹果 🍎” 和 “MacBook 💻” 的向量略远 → 一个是水果,一个是电子产品
✅ 方向表示语义关系
向量不只有“位置”,还有“方向”!
著名例子来了 💥:
Embedding(“国王”) - Embedding(“男人”) + Embedding(“女人”) ≈ Embedding(“女王”)
👑 – 👨 + 👩 ≈ 👸
这说明嵌入空间甚至学会了“性别”这种抽象概念!
| 概念 | 通俗解释 |
|---|---|
| 向量空间 | 像一个巨大的地图,所有数据都变成“点”放在里面 |
| 向量的距离 | 表示语义的相近程度 |
| 向量的方向 | 表示词之间的语义关系 |
| 用途 | 相似度计算、搜索推荐、语言推理、知识补全等 |
✅ 一句话总结:
向量空间 = 一个“语义地图世界” 🗺️,每个词或概念都是一个点,我们可以通过“距离”和“方向”来理解它们的关系。
3、低维稠密表示 vs 高维稀疏表示(One-Hot)
🔍 一句话概括
One-Hot 是“傻瓜式编号”,Embedding 是“聪明的表达”。
一个是高维且稀疏,另一个是低维且稠密。✅
🎯 什么是高维稀疏表示(One-Hot)?
🔤 举例:词表中有 10,000 个词
每个词都用一个只有一个 1,其它全是 0 的向量来表示。
比如:
| 词语 | One-Hot 向量(长度 10,000) |
|---|---|
| 猫 🐱 | [0, 0, 0, ..., 1, ..., 0] |
| 狗 🐶 | [0, 0, 0, ..., 0, 1, ..., 0] |
👉 这样的向量是:
-
📏 高维(非常长,比如 10k、100k…)
-
⚪ 稀疏(只有一个 1,其他都是 0)
-
🧱 没有语义信息(“猫”和“狗”之间毫无关系)
🧠 什么是低维稠密表示(Embedding)?
📊 同样的“猫”和“狗”,Embedding 表示是:
| 词语 | 向量(长度 100~300) |
|---|---|
| 猫 🐱 | [0.12, 0.56, 0.03, ...] |
| 狗 🐶 | [0.13, 0.54, 0.05, ...] |
这样的向量是:
-
📏 低维(比如 100维、300维)
-
⚫ 稠密(每个位置都有实数,不是大量0)
-
🤝 包含语义关系(“猫”和“狗”的向量靠近)
🆚 形象类比
| 类别 | One-Hot(高维稀疏) | Embedding(低维稠密) |
|---|---|---|
| 🧠 智商 | “死记硬背” 📘 | “理解含义” 🧠 |
| 📏 维度 | 非常高(几千几万)📈 | 很低(几十~几百)📉 |
| ⚪ 稀疏性 | 绝大多数是 0 | 所有维度都有值 |
| 📦 存储 | 浪费空间 💾 | 节省空间 💡 |
| 📊 表达力 | 没有语义关系 | 有丰富语义关系 |
| 💬 猫 vs 狗 | 毫无联系 | 意义相似,向量相近 |
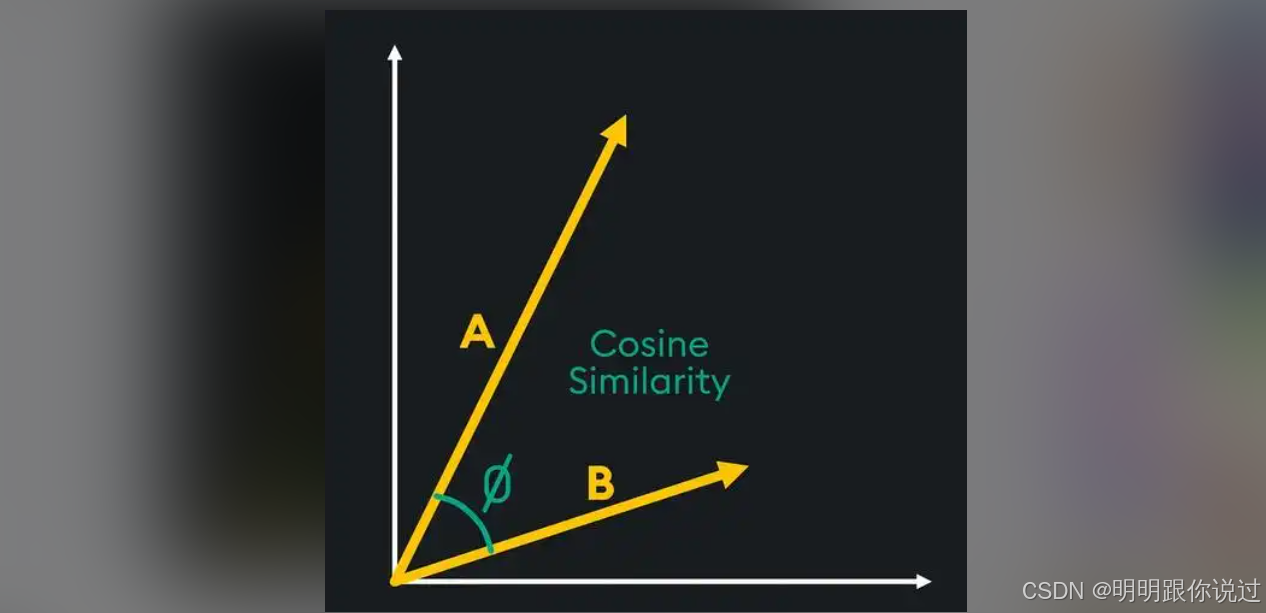
| 🤔 计算相似度 | 没法比 | 可以用余弦距离b |
🚀 为什么 Embedding 更高级?
因为它能“压缩信息 + 表达语义”!就像是:
✈️ 从地图上的城市编码(One-Hot)
➡️ 转换成城市之间的实际位置和关系(Embedding)
✅ 总结一张图理解(文字版):
One-Hot ➤ [0, 0, 1, 0, 0, 0, ..., 0] 🔺 高维、稀疏、没有语义
Embedding ➤ [0.12, 0.35, 0.78, ..., 0.05] 🔻 低维、稠密、有语义
💡 一句话总结:
One-Hot 是“身份卡号📇”,Embedding 是“性格特征表 🧬”——
前者只知道“你是谁”,后者还知道“你像谁”!

三、主流的嵌入模型类型
1、词嵌入(Word Embedding)
🧠 什么是词嵌入?
词嵌入(Word Embedding)就是把每个“词语”转成一个带有语义的向量,让机器能理解词语之间的关系和含义。
它是 Embedding 技术的起点,也是 NLP 的重要基石!
🌟 主流词嵌入模型大合集
我们按照时间顺序 + 关键特性介绍👇
1️⃣ One-Hot Encoding(早期原始方法)🔲
-
🚧 特点:每个词一个高维稀疏向量(只有一个1)
-
🤔 问题:维度太高 + 没有语义
📌 举例:
词表有5个词 → “猫” = [0, 0, 1, 0, 0]
但“猫”和“狗”没有任何“关系”,全靠人脑理解 😵💫
2️⃣ Word2Vec(2013)💥【开创纪元】
✨ Google 出品,超经典!
-
🧪 两种模型:
-
CBOW(Continuous Bag of Words):用上下文预测中间词
-
Skip-Gram:用一个词预测上下文(更适合少量数据)
-
-
📏 输出:每个词一个固定长度的向量(如 300维)
-
💡 能捕捉“词义相似性”和“语义关系”
🧠 著名示例:
向量("国王") - 向量("男人") + 向量("女人") ≈ 向量("女王")
📌 优点:
-
快速、简单
-
学出来的词向量质量好,能迁移到其他任务
3️⃣ GloVe(2014)📐【统计派代表】
🏫 斯坦福大学提出,全名是 Global Vectors for Word Representation
-
🧠 不依赖“局部上下文”,而是分析词共现矩阵
-
🧮 把“词与词之间出现频率”转化为“向量空间距离”
-
比 Word2Vec 更“全球视野”
📌 举例:
-
“冰”和“水”共现频率高 → 向量相近
-
“冰”和“火”共现少 → 向量较远
4️⃣ FastText(2016)⚡【词内部结构也考虑!】
🔬 Facebook 提出,改进 Word2Vec 的不足
-
🎯 考虑子词结构,能表示未登录词(OOV)!
-
例如:“happiness” 会被拆成 “happ”, “ppi”, “pin”, ..., “ess”
-
更适合处理拼写变化多的语言(如德语、俄语)
📌 优点:
-
能表示生僻词、拼写错误词
-
向量更丰富
5️⃣ ELMo(2018)🦎【语境感知,句子级别词向量】
Embeddings from Language Models
-
🔁 每个词的向量会根据上下文变化
-
使用双向 LSTM 建模上下文
-
一个词可以在不同句子中拥有不同向量!
📌 举例:
-
“bank” 在:
-
“river bank” 表示 河岸
-
“money bank” 表示 银行
-
两个向量会不同!
-
6️⃣ BERT Embedding(2018+)🚀【大模型时代来临】
✨ Google 的 BERT 模型不仅能用于 NLP任务,还能作为超强嵌入器!
-
利用 Transformer 架构,深入建模上下文
-
双向编码器:同时看左边和右边上下文
-
词向量不仅有“局部语义”,还有“上下文深意”
📌 优点:
-
可用于句子嵌入、段落嵌入
-
可迁移、可微调
✅ 表格总结:词嵌入模型对比
| 模型 | 上下文感知 | OOV支持 | 原理 | 代表优势 |
|---|---|---|---|---|
| One-Hot | ❌ | ❌ | 编号 | 简单但没语义 |
| Word2Vec | ❌ | ❌ | 上下文窗口预测 | 快速有效,广泛应用 |
| GloVe | ❌ | ❌ | 共现矩阵 + 词频统计 | 全局统计视角 |
| FastText | ❌ | ✅ | 子词向量组成词向量 | OOV友好 |
| ELMo | ✅ | 部分 | 双向LSTM建模上下文 | 语境感知词义 |
| BERT | ✅✅ | ✅ | Transformer语义编码 | 深度语义理解,预训练大模型 |

2、文本/句子嵌入(Text/Sentence Embedding)
🧠 什么是文本/句子嵌入?
文本嵌入 = 把整段文字或一句话表示成一个“有语义的向量”📦,并且捕捉整体意思!
之前的词嵌入是:“猫”“狗”这样的单词向量
现在的句子嵌入是:“我喜欢这只猫 🐱”这样的整句话向量!
📍为什么需要句子嵌入?
有时候,单词的意义不能直接推导出句子的意义:
比如:
-
“他太牛了!”
-
“他太牛了……”
👉 虽然词一样,但情绪、意思完全不同!
所以我们需要上下文感知的嵌入向量来理解整句话/段落🌈
🔧 主流的文本嵌入方法有哪些?
下面介绍主流几种方式👇
1️⃣ 平均词向量(Avg Word2Vec)🧮
-
把句子中的所有词的向量求平均
-
非常简单,但忽略了语序、语法、上下文 ❌
例子:
“我爱自然语言处理” → 平均(“我” + “爱” + “自然” + “语言” + “处理”)的词向量
✅ 优点:快
❌ 缺点:不懂语义结构,表达力弱
2️⃣ Universal Sentence Encoder(USE)🔵
-
Google 推出,用深层网络捕捉语义
-
输出一个固定维度的句子向量(默认 512 维)
✅ 优点:结构更深,能理解常见表达
❌ 缺点:对长文本支持不够好
3️⃣ Sentence-BERT(S-BERT)💎
BERT 的句子嵌入专用升级版!
-
用 Siamese 网络结构,让 BERT 生成语义相似度可比的句向量
-
适合做语义匹配、检索、聚类等任务!
例子:
| 句子A | 句子B | 相似度 |
|---|---|---|
| “我想订一张去上海的票” 🚄 | “帮我买去上海的车票” 🚌 | 0.95 |
| “我喜欢狗” 🐶 | “苹果很好吃” 🍎 | 0.10 |
✅ 优点:句子相似度效果拔群
✅ 能用余弦相似度直接对比
❌ 推理相对慢,模型较大
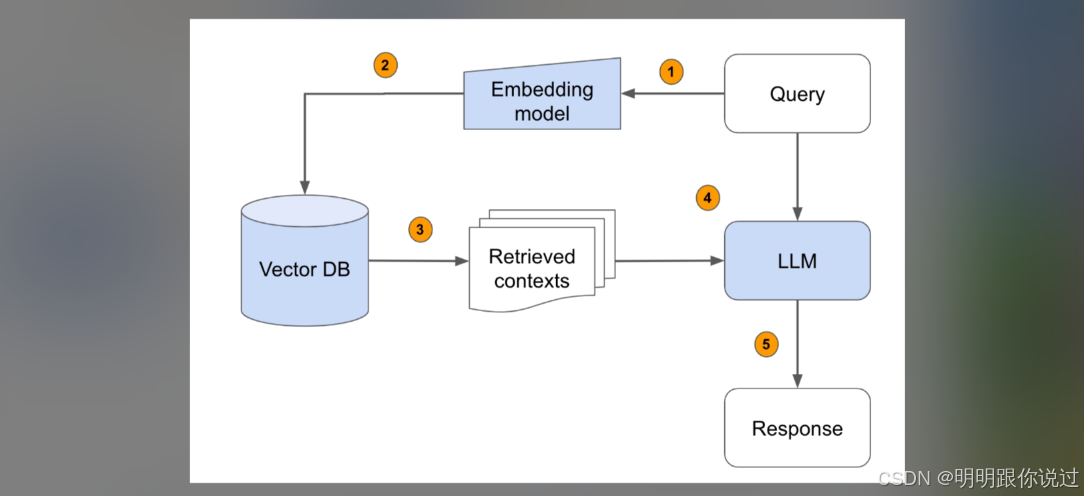
3、图嵌入(Graph Embedding)
🧠 什么是图嵌入(Graph Embedding)?
图嵌入 = 把图中的“节点”、“边”或“整个子图”用向量表示出来🧩,并尽可能保留它在图结构中的关系!
这就好比:
-
原来是一个错综复杂的“朋友圈关系网”👫👬
-
图嵌入之后 → 每个人变成了一个可以比较的向量 📦
✨ 向量中的距离、方向可以反映:
-
你跟谁更亲密
-
谁跟谁是“同一挂的”
-
谁是“核心人物”...
🕸️ 图是啥样的结构?
图(Graph)由:
-
节点(Node):可以是人、物品、网页、实体……
-
边(Edge):可以是朋友关系、点击行为、引用关系、血缘……
📌 举个例子:
A —— B —— C
\ |
\ D
\ /
E — F
这个图里,谁跟谁连接、谁更靠近,都蕴含着信息!
🎯 为什么要做图嵌入?
原始图结构不容易直接输入到机器学习模型中 ⛔
🟢 用嵌入后就可以:
-
比较节点之间的相似度(相似的人、商品、网页)
-
做分类(比如给节点打标签)
-
做聚类(找出“圈子”、“兴趣组”)
-
用于推荐系统(物以类聚,人以群分!)
🔧 图嵌入怎么做?主流方法一网打尽 🕸️👇
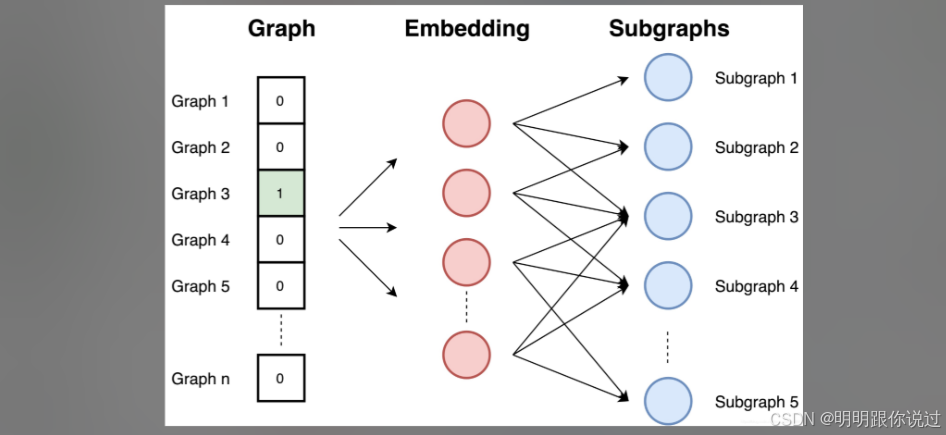
1️⃣ 基于随机游走:DeepWalk / node2vec 🚶♂️🚶♀️
-
想象一个人在图中“乱走”收集路径(就像在朋友圈逛吃逛吃😄)
-
把这些路径当成“句子”输入 Word2Vec 做词嵌入!
-
相邻/常一起出现的节点 → 嵌入会相近
📌 特点:
-
简单易用
-
保留局部结构(谁和谁经常一起出现)
🧠 应用:社交推荐、实体匹配
2️⃣ 基于邻居聚合:GCN / GAT 等图神经网络 🧠
让每个节点不断“向邻居学习”📡,获取更多信息!
-
GCN(Graph Convolutional Network):像卷积神经网络那样聚合邻居特征
-
GAT(Graph Attention Network):给不同邻居分配不同的“注意力权重”
📌 特点:
-
强大、表达力强
-
可用于有监督学习(如节点分类、边预测)
🧠 应用:推荐系统、知识图谱补全、蛋白质交互预测等
3️⃣ 结构保持法:HOPE / SDNE 🏗️
-
HOPE:保持节点之间的距离或相似度
-
SDNE(深度自编码器):用深度学习提取非线性结构特征
📌 特点:
-
更关注“结构信息”
-
一般用于无监督图表示
🧪 图嵌入向量都可以干什么?
| 应用场景 | 示例 |
|---|---|
| 社交推荐 | 找到和你兴趣相近的好友、关注人 🤝 |
| 电商推荐 | 根据商品-用户点击图推荐你想买的 💸 |
| 知识图谱补全 | 猜测“谁是谁的导师?”🤓 |
| 文献引用预测 | 哪篇论文最有可能引用某篇研究 🧾 |
| 图分类 | 判断一个图是社交网还是诈骗团伙 🕵️♂️ |
✅ 总结一句话:
图嵌入 = 把复杂的网络关系变成简单好用的向量📦,让机器也能“看图识人/物/关系”🕵️♀️📈!
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!