第十六次博客打卡
今天学习的是经典算法,堆排序。
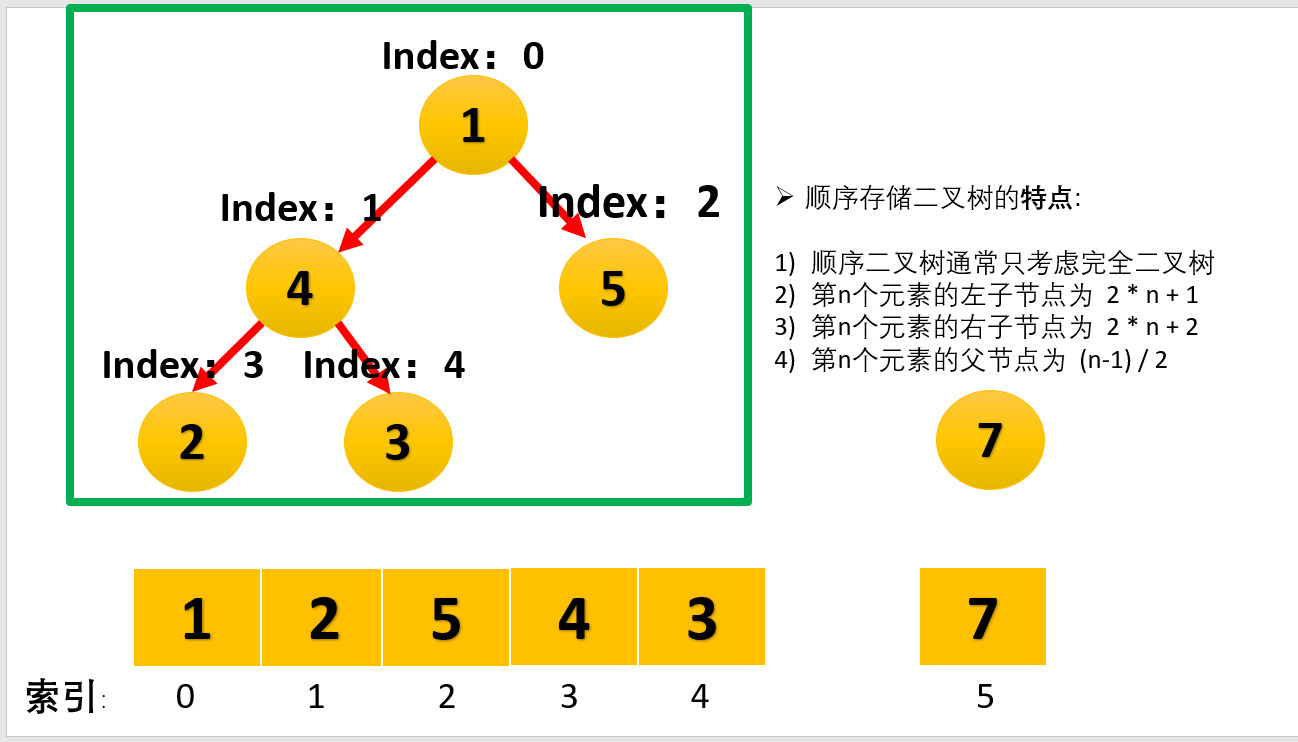
堆排序是一种基于堆数据结构的排序算法,以下是关于堆排序的详细介绍:
堆的定义和性质
-
定义
- 堆通常是一个可以被看作完全二叉树的数组对象。在堆中,每个元素都有一个键值(key),并且堆分为两种类型:最大堆和最小堆。
-
性质
- 堆的高度是[ \log_2n ](n是堆中元素的数量)。这是因为堆是完全二叉树,其高度和元素数量有这种对数关系。
- 堆的存储结构一般采用数组,对于数组中的第i个元素(从1开始计数),它的左子节点是第2i个元素,右子节点是第2i + 1个元素,父节点是第[ \lfloor i/2 \rfloor ]个元素。这种存储方式可以方便地通过下标来访问元素的父子关系。
堆排序的算法步骤
-
构建堆(建堆)
- 从最后一个非叶子节点开始(即数组中第[ \lfloor n/2 \rfloor ]个元素,n是数组长度),向前逐个调整节点,使其满足堆的性质。对于最大堆,如果一个节点的值小于它的子节点,就将它与较大的子节点交换,然后继续调整这个子节点,直到该子树满足最大堆的性质。
-
堆排序过程
- 将堆顶元素(最大堆中是最大值,最小堆中是最小值)与堆的最后一个元素交换,这样最大值(或最小值)就到了它最终的位置。
- 然后将堆的大小减1(因为最后一个位置已经排好序了),并且重新调整剩下的堆,使其满足堆的性质。这个过程重复进行,直到堆的大小为1,整个数组就变成了有序的。
堆排序的时间复杂度和空间复杂度
- 时间复杂度
堆排序的总时间复杂度是O(nlogn)。 - 空间复杂度
- 堆排序是一种原地排序算法,它只需要一个常数级别的额外空间来存储一些临时变量(如交换元素时的中间变量等),所以空间复杂度是O(1)。
堆排序在实际应用中,由于其时间复杂度稳定,且不需要额外的存储空间,被广泛用于一些对空间要求严格且需要稳定排序时间的场景。